Customer service performance review examples & phrases
Riellvriany Indriawan
Katelin Teen
Last edited July 4, 2026

What a customer service performance review actually measures
The mistake I see most often is a review that's really just one number in disguise: "solid quarter, 4 out of 5, keep it up." That tells the agent nothing they can act on. A review earns its place when it separates out the distinct things an agent is actually good (or shaky) at, so the feedback lands somewhere specific.
In practice that's five or six competencies. Each one is a different muscle, and a strong agent is rarely equally strong across all of them, which is exactly what a good review surfaces.
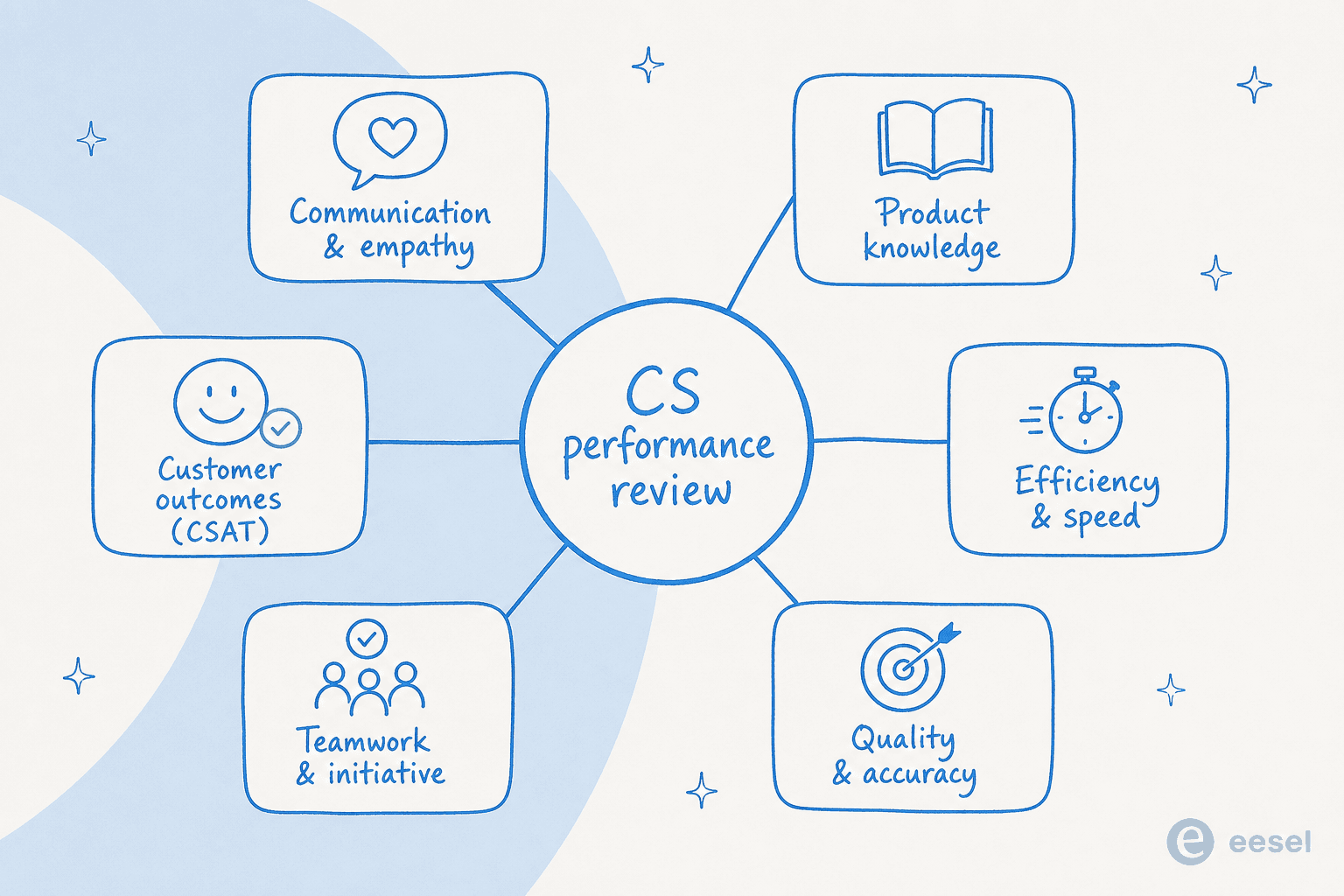
- Communication and empathy how clearly and warmly they write or speak, especially under pressure. This is where empathy in customer service shows up in the transcript.
- Product and technical knowledge whether they actually know the answer or route around not knowing it.
- Efficiency and productivity speed and throughput, held against quality so the two don't trade off.
- Quality and accuracy did the reply solve the issue, correctly, the first time.
- Teamwork, initiative and reliability the stuff that doesn't show in a ticket: covering shifts, flagging a bug, improving a macro.
- Customer outcomes the CSAT and resolution numbers the whole thing rolls up to.
Reviewing on all of these keeps you honest. A fast agent with a low quality score and a slow agent with a spotless one need very different conversations, and a single blended rating hides both. If you want a picture of what "exceeds" looks like in practice, our roundup of excellent customer service examples is a useful benchmark to review against.
The metrics worth putting in the review
Numbers are what make a review defensible. If an agent disagrees with "communication needs work," a transcript and a CSAT trend end the argument; "I just feel like it does" doesn't. CX research firm SQM has found that only three metrics pass all seven criteria for a strong KPI, so anchor the review on those and treat the rest as supporting evidence.
| Metric | What it tells you in a review | Watch out for |
|---|---|---|
| CSAT | Whether customers left happy | Low response rates skew it; read it as a trend, not a verdict |
| First contact resolution | Whether issues got solved in one go | Can be gamed by marking things "solved" early |
| QA score | Reply quality against your rubric | Only useful if the rubric scores outcomes, not scripted phrases |
| Resolution rate | Share of assigned tickets actually closed | Volume without quality is a red flag, not a win |
| Average handle time | Speed per contact | Never review in isolation, it trades off against quality |
| Escalation rate | Judgment on when to hand off | Too low can mean over-reaching, too high can mean under-skilled |
The point isn't to track all six for every agent, it's to pick the two or three that fit their role and hold them steady across the whole team. Our roundup of customer service KPIs breaks down how each one behaves, the customer service metrics guide covers how AI-assisted teams read them differently, and if you're pulling the trend data from surveys, our notes on survey analysis and product survey questions help keep CSAT honest. Where the numbers come from matters too, good contact center management and modern customer communication software surface most of this automatically.
Performance review phrase bank
Below is a filterable set of review phrases you can lift and adapt. Pick a competency, then a rating level, to see phrasing that stays specific instead of sliding into "great team player." Every line is a template, so drop in the real number or ticket before you use it.
The written-out versions below go deeper on each competency, with the phrasing patterns I reach for most.
Communication and empathy
This is the competency customers feel first. A technically correct reply that reads as cold still lands as bad service, so review the tone as seriously as the accuracy. The strongest evidence here is a rescued ticket: a thread that started angry and ended resolved.
- Exceeds: "Turns tense threads around. On the [shipping delay] escalation, acknowledged the frustration first, then fixed it, and the customer replied to thank them by name."
- Meets: "Warm, clear, on-brand writing. No tone complaints this cycle, CSAT held at [92%]."
- Needs work: "Replies are accurate but clipped. Adding one line of acknowledgement up front, like the empathy statements we use on refunds, would lift the customer experience."
If de-escalation is a recurring gap, that's a coaching plan, not a one-line ding, our guide on dealing with angry customers is a good starting point to build one from.
Product and technical knowledge
Depth of knowledge is what lets an agent resolve instead of route. Review it by looking at what they escalate: the pattern of "couldn't answer this" tells you exactly where the gap is.
- Exceeds: "The team's [integrations] expert. Documented [4] fixes that became shared macros."
- Meets: "Answers standard questions without escalating and keeps saved replies current."
- Needs work: "Escalated [8] tickets already covered in the help center. Let's schedule a docs walkthrough."
Efficiency and productivity
Speed only means something next to quality, so never review it alone. An agent clearing 40 tickets a day with a 70% QA score isn't a top performer, they're creating rework. Handle time also depends on the call center technology they're working with, so factor the tooling in before you pin a slow number on the person.
- Exceeds: "[30%] above team handle rate with quality above [90%]."
- Meets: "Steady volume, first response time under [2 hours]."
- Needs work: "Handle time [40%] over target on tickets that had a saved reply, let's lean on the macro library."
Quality and accuracy
This is the one metric I'd never let slide, because a confident wrong answer erodes trust faster than a slow right one. Pull the evidence straight from your QA scorecard, per the customer service evaluation rubric, and treat the QA score as one performance metric among several rather than the whole story.
- Exceeds: "[96%] QA score, every reviewed reply solved the issue in one touch."
- Meets: "[88%] QA score, reliable first contact resolution."
- Needs work: "[2] replies had an incorrect policy detail, let's add a policy self-check."
Teamwork, initiative and reliability
The work that never shows up in a ticket count: covering shifts, flagging bugs, improving the knowledge base. Reviewing it signals that the invisible glue work counts.
- Exceeds: "Covered [3] shifts during the outage unprompted and flagged the bug that led to a permanent fix."
- Meets: "Dependable, shares answers in the team channel, keeps commitments."
- Needs work: "Works solo, rarely surfaces recurring issues, let's own one process improvement this quarter."
Areas for improvement, phrased so they coach
The improvement section is where reviews go wrong most often, either too soft to be useful or too blunt to be heard. The pattern that works: behaviour, evidence, next action, always about the work.

- Instead of "needs to be more empathetic," write: "On [3] billing tickets the reply skipped the acknowledgement step, which correlated with lower CSAT. Let's use the empathy-first template on refunds."
- Instead of "too slow," write: "Handle time ran [40%] over target, concentrated on tickets with an existing macro. Goal: bring it within [10%] of target by end of Q3 using the macro library."
- Instead of "should take more initiative," write: "Owns their queue well but rarely surfaces recurring issues. Goal: propose one workflow improvement this quarter and share it with the team."
Each of those is a SMART goal in disguise: specific, measurable, and tied to a number the agent can actually move. That's the difference between feedback the agent nods at and forgets, and feedback that changes next quarter's numbers.
A full sample customer service performance review
Here's how the pieces fit into one review. Adapt the numbers and the voice, this is a structure, not a script.
Agent: [Name] · Period: Q2 2026 · Reviewer: [Manager]
Summary. A strong, steady quarter. [Name] is one of the most reliable writers on the team and a first port of call for [billing] questions. The growth area is speed on routine tickets, where saved replies aren't being used to full effect.
Communication and empathy (Exceeds). CSAT held at [94%] across [380] tickets. Notably rescued the [enterprise renewal] escalation, an angry thread that ended with a 5-star rating and a thank-you by name.
Quality and accuracy (Meets). QA score of [89%], above the [85%] team average. Two policy errors on [returns] tickets, both corrected same-day, flagged as a small focus area below.
Efficiency (Needs work). Average handle time ran [35%] over target, concentrated on tickets that had an existing macro. This is the quarter's main growth area.
Teamwork (Meets). Dependable, covered [2] shifts unprompted, and keeps the [billing] macros current.
Goals for Q3.
- Bring average handle time within [10%] of target by leaning on the macro library.
- Add a policy self-check step on [returns] tickets to hold accuracy above [90%].
- Document one new [billing] workflow for the shared knowledge base.
Notice there's no surprise in it. Every rating traces to a number or a specific ticket the agent could look up themselves, which is the whole game, a review should confirm what the data already showed, not spring a verdict.
How AI changes what you review agents on
This is the part most review templates haven't caught up to yet. When an AI agent handles the tier-1 volume, the tickets landing on a human are, by definition, the harder ones the AI wasn't confident about. So reviewing an agent on raw ticket count starts measuring the wrong thing, they're handling fewer tickets, but each one is thornier.
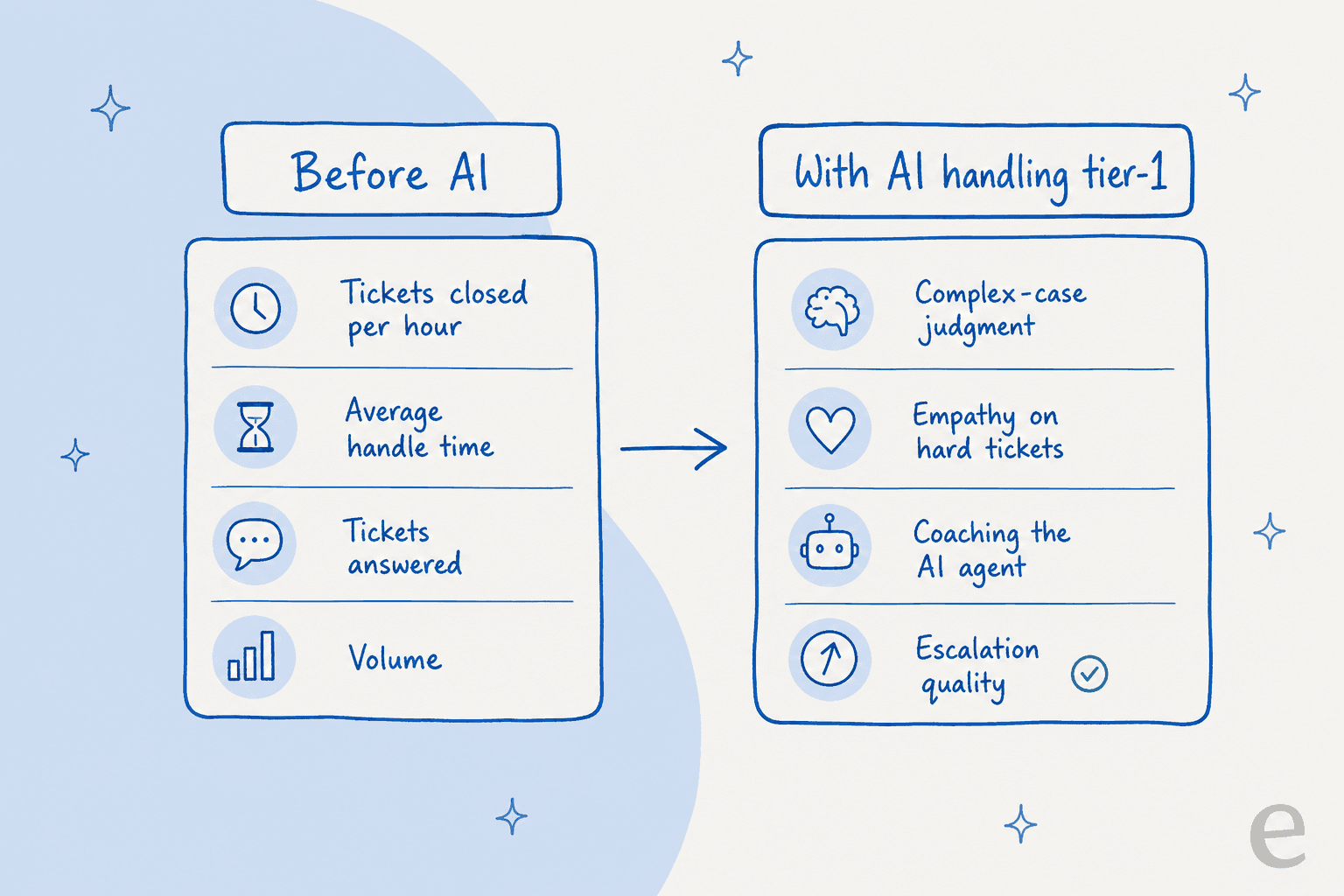
The competencies that rise to the top are judgment ones: how well the agent edits an AI-drafted reply, when they override it, and how cleanly they escalate. It's the same shift you see when you look at real AI agent examples in the wild, the routine work automates and the human moves up the value chain. One CX lead at a DTC supplements brand on Shopify (around 7,000 tickets a month) put the underlying principle to us plainly:
"The AI will never be able to answer 100% of the questions... I need an AI who is only handling the tickets that it's confident to handle and all the other ones, leave them alone."
That's the review-worthy skill now: the human owns the tickets the AI leaves alone, and how well they own them is the thing to score. A service desk lead at a logistics SaaS running eesel in copilot mode described the shift on the drafting side:
"It is getting us to the right articles really quickly and easily, as well as curating well-formed responses with consistent, on-brand tone, still keeping our own style and still keeping that human touch."
When the draft is already on-brand, the review question moves from "did they write it well?" to "did they know when to keep the human touch and when to trust the draft?" That judgment is harder to fake and more valuable to develop, which is exactly why it belongs at the top of a modern scorecard. The data to score it, draft acceptance, override patterns, escalation quality, lives in your AI tool's activity and reports view rather than the raw ticket log, and it feeds naturally into the customer service workflow you're already running.
Common mistakes when writing these reviews
A few traps I'd steer around, most of them the reason a review lands flat:
- Recency bias. Grading the whole quarter on last week's tickets. Pull the full-period data and let it argue, not your memory.
- One blended number. A single "4 out of 5" hides the fast-but-sloppy and the slow-but-precise agent alike. Score the competencies separately.
- Trait language instead of behaviour. "Not a team player" is unactionable and feels personal, "rarely surfaces recurring issues" points at a fixable behaviour. For phrasing that stays constructive, our customer service feedback examples and notes on a voice of customer program are worth a look.
- No number, no ticket. Every claim should trace to evidence the agent can look up. If it can't, it's an opinion, and opinions get argued with.
- Goals with no metric. "Communicate better" isn't a goal, "raise CSAT from 88% to 92%" is. Tie every goal to a number, the same way our customer experience strategy guide ties initiatives to outcomes.
Get those five right and the review does its actual job: not judging the past quarter, but improving the next one.
Try eesel for the data behind the review
Half the work of a fair performance review is having the evidence in one place. eesel plugs an AI agent into your existing helpdesk, resolves the tier-1 tickets it's confident about, drafts replies for the rest, and gives you a reports view of exactly what it handled versus what it handed to a human, which is the same data you'd score an agent's judgment against.

Because pricing is usage-based (around 40 cents a ticket, no per-seat fees), you can start on a slice of your queue and see the numbers before rolling it wider. It's free to try, and you can simulate it against your own historical tickets first, so the resolution rate you'd put in any review is one you've actually seen, not one you're hoping for.
Frequently Asked Questions
What are good customer service performance review examples?
What should a customer service performance review include?
How do you write constructive feedback in a customer service performance review?
What are examples of SMART goals for a customer service performance review?
How should I review an agent who uses an AI assistant?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








