サポートQAとは何か、そして手作業版がなぜ機能しないのか
サポートQAは顧客との会話の品質保証です。ルーブリック(回答は正確だったか?トーンは適切だったか?実際に問題を解決したか?)を使って会話を評価し、その結果をエージェントのコーチングとギャップの修正に活用します。うまく行えば、サポートチームが単に速くなるのではなく、より良くなる方法であり、SLA管理からサポートコスト削減まですべてと結びついています。
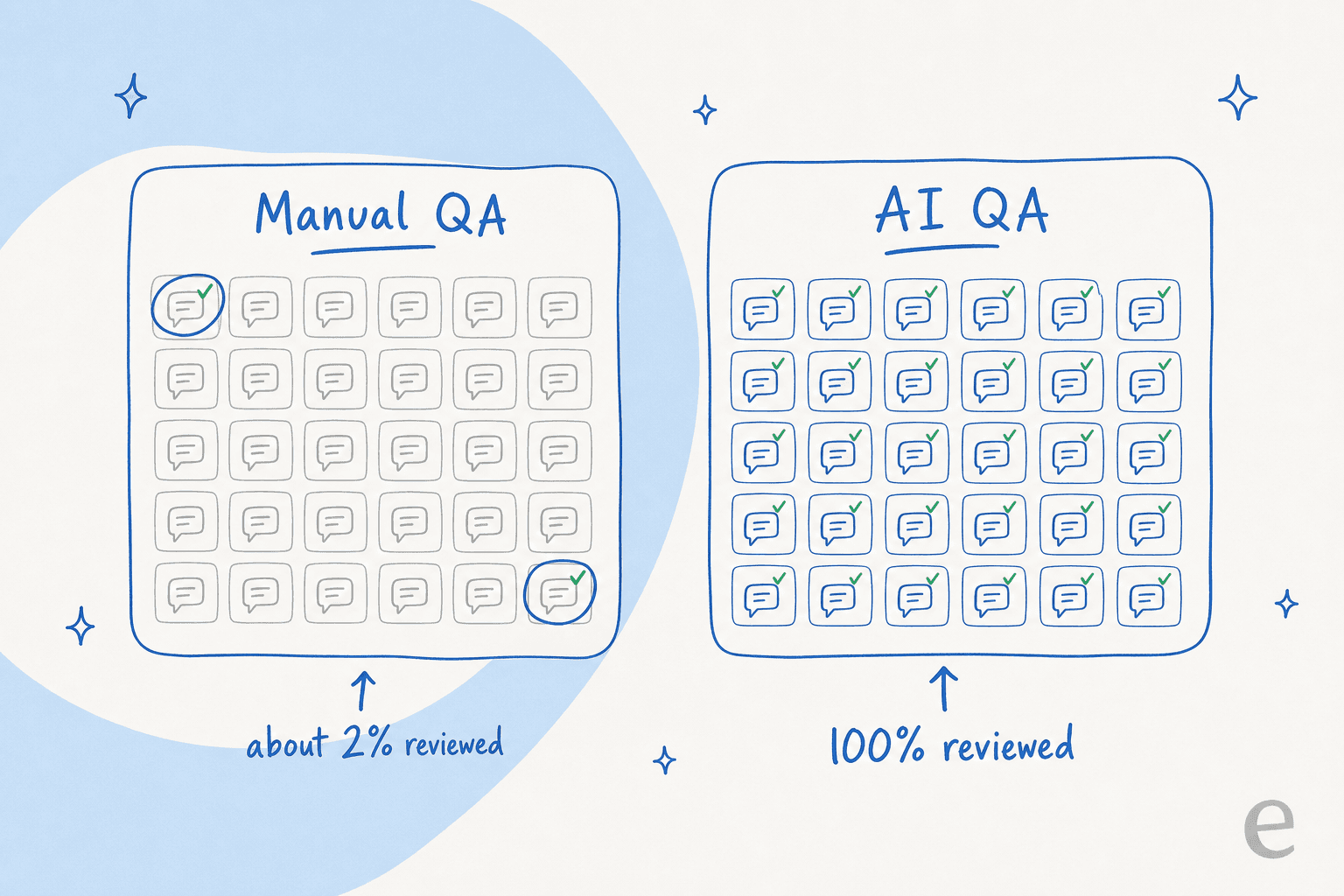
問題はここにあります:手作業版は常にほんの一部しか見ません。QAアナリストは週に数枚のチケットをエージェントごとに取り出し、スプレッドシートでスコアリングして先へ進みます。チームが月に数千の会話を処理する場合、おそらくその2%しかレビューしていません。開かなかった98%は丁寧で自信満々だが完全に間違った回答で溢れているかもしれませんが、QAプログラムはそれを知ることはありません。
そのわずかな部分は小さいだけでなく、偏っています。アナリストはスコアリングしやすく、最近のもの、またはすでにフラグが立てられているチケットに引き寄せられます。静かに顧客を失ったような真に奇妙なエッジケースは、サンプルに入ることはほとんどありません。その結果、誰も読まない部分にCSATを実際に動かすパターンが隠れている状態で、ランダムな2%についてエージェントをコーチングすることになります。
手作業QAは遅く一貫性もありません。2人のレビュアーが同じ会話を異なるようにスコアリングします。コーチングメモが届く頃には、エージェントはさらに400枚のチケットを処理しています。これはアナリストのせいではなく、数学的な問題です:人間はすべてを読むことができないため、サンプルを読みますが、サンプルはキューについて教えてくれません。
AIがQAを担当すると何が変わるか
変化は一言で言えば、そして過小評価できないほど重要です:会話の100%をスコアリングするコストは、2%をスコアリングするのとほぼ同じです。AIがルーブリックに対してすべての会話を読むと、カバレッジはもはや配分するものではなくなります。
3つのことが同時に変わります。まず、サンプリングバイアスがなくなります。サンプルがないため、AIは1つの一貫したルーブリックでキュー全体を評価します。次に、フィードバックループが短縮されます:会話はレビューサイクルの終わりではなく、クローズしてから数分後にスコアリングできます。第3に、QAはスポットチェックでなくなり、時間の経過とともに、エージェント別、トピック別、チャネル別にトレンドを追える本物のサポート指標になります。
変わらないこと:判断は依然として人間のものです。AIはすべてを読んでおかしいと思われるものにフラグを立て、人間がそれについて何をするかを決めます。その分業はAI対人間のサポートをどこでも機能させるのと同じで、機械が量をこなし、頭脳が必要な判断を人間が担います。また、QAがサポートワークフローにおけるAIコパイロットの隣に自然に位置する理由でもあります:同じ会話データが両方を支えます。
AIでサポートQAを行う方法、ステップバイステップ
これをうまく行うことは、品質に向けられたサポートにおけるAIと自動化に過ぎず、データチームは必要ありません。全体は5つのステップで、ループはステップと同じくらい重要です。なぜなら、QAは発見事項が仕事に還流される場合にのみ価値があるからです。
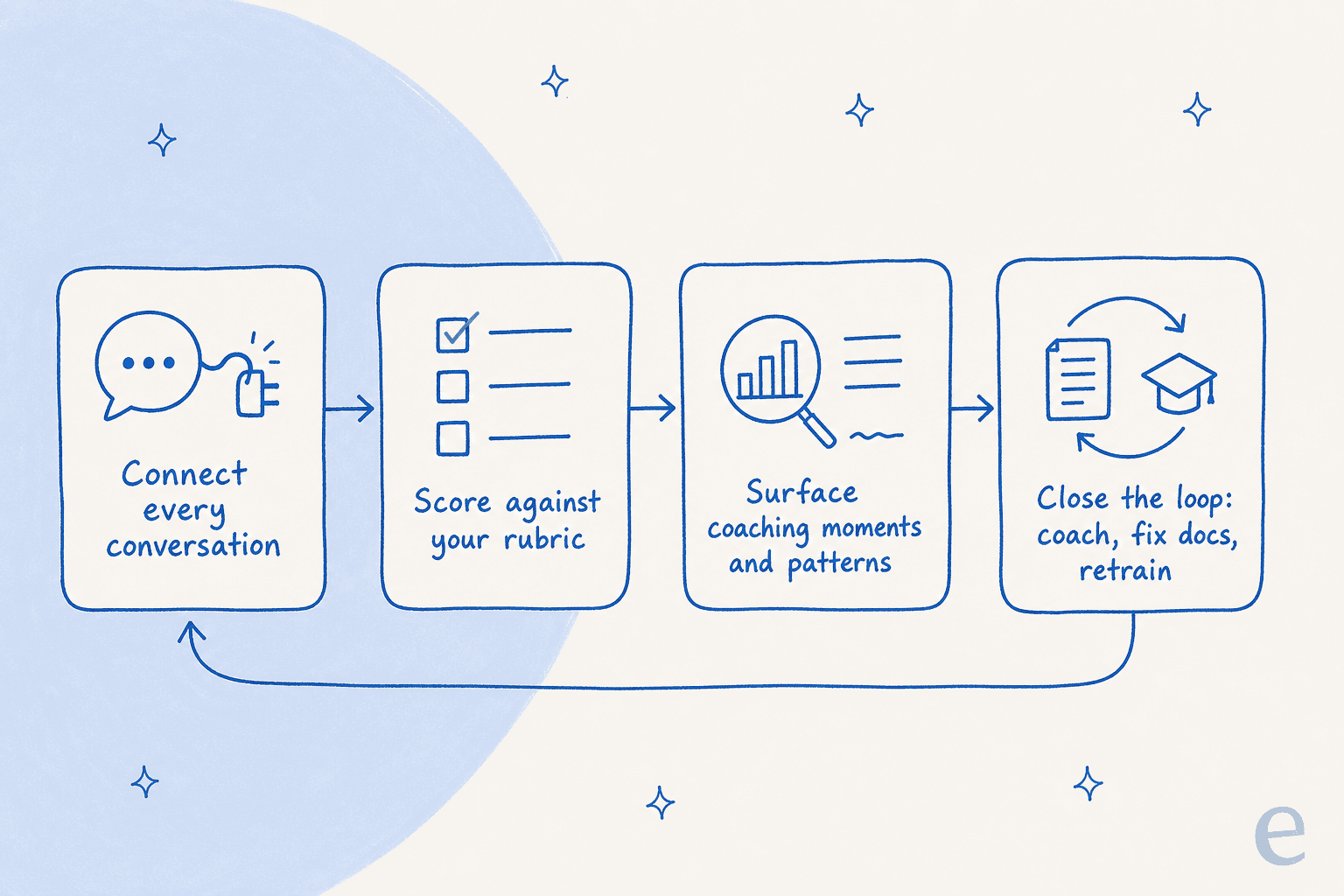
ステップ1:「良い」がどのようなものかを書き留める
QAはルーブリックと同じくらい良く、AIルーブリックは明示的でなければなりません。「見ればわかる」では不十分です。すべての回答が評価されるいくつかのことを明記してください。実際には約5つの次元です:事実として正確だったか、トーンは適切だったか、問題を解決したか、ポリシーに従ったか、何かを作り上げるのではなく実際のソースを引用したか。
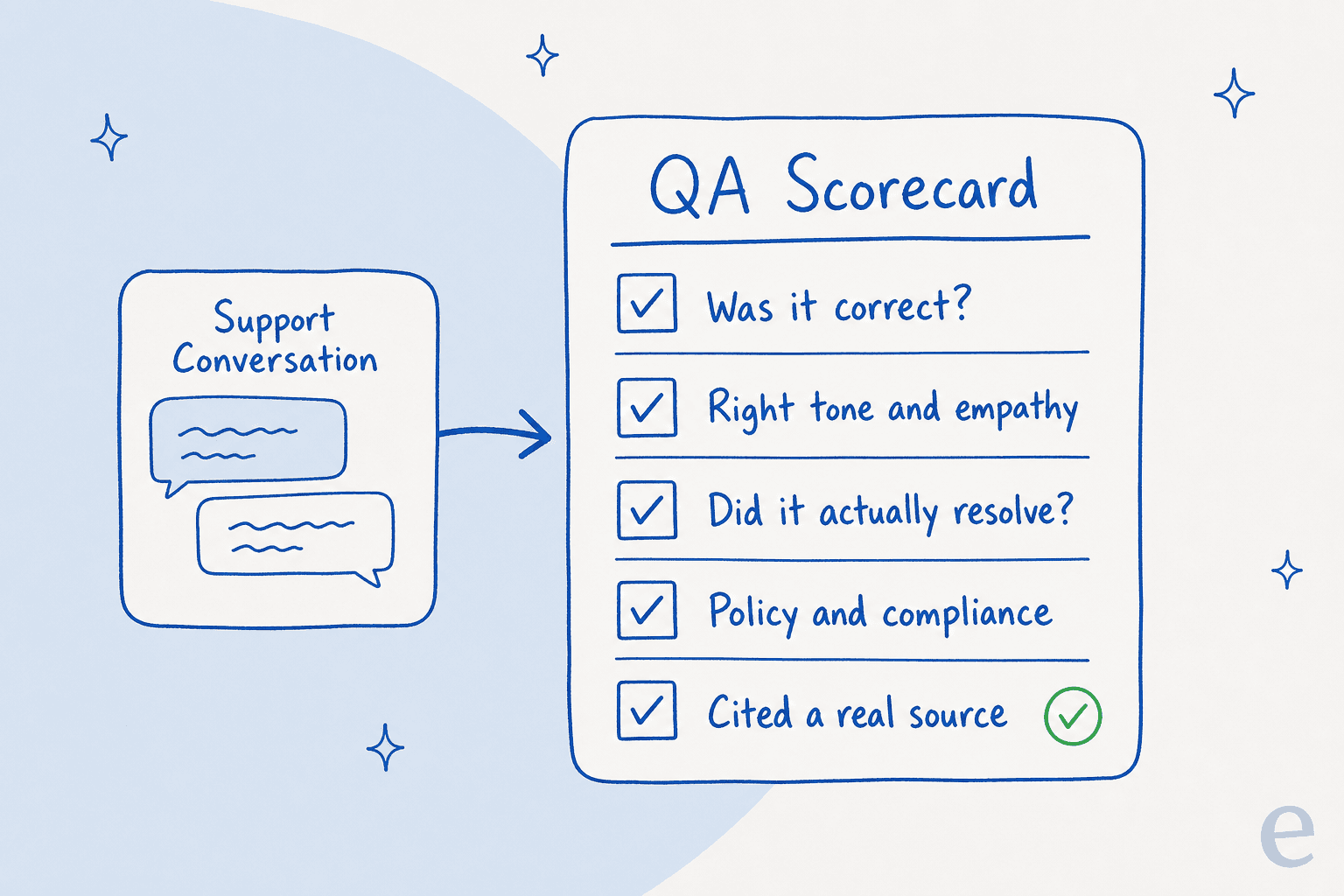
シンプルに保ってください。30の基準を持つルーブリックは誰も一貫して適用しません。人間でもAIでも。ソーシングの項目は人々が期待する以上に重要です:背後にソースのない自信満々の回答は、スプレッドシートでは問題なく見えますが、確認すると幻覚であることが判明するものです。
ステップ2:サンプルではなく、すべての会話を接続する
AIを先週のフラグ付きチケットのエクスポートではなく、会話履歴全体に向けてください。通常、これはZendesk、Freshdesk、Gorgias、またはHelp Scoutを使用しているかどうかにかかわらず、クローズした会話が自動的に流れ込むようにヘルプデスクを直接接続することを意味します。

ここでナレッジベースも登場します。「間違い」というQAスコアは、エージェントが間違ったのかドキュメントが間違ったのかを知っている場合にのみ有用です。AIに会話と使用すべきだったソース資料の両方を提供することで、その2つを区別でき、それが人をコーチングすることとナレッジベースチャットボットの記事を修正することの違いです。
ステップ3:ルーブリックに対して自動スコアリングする
AIが各会話を読んで次元ごとにスコアリングします。必要な出力は単一の数字ではなく、内訳です:この会話は解決でスコアが低く、こちらは回答は完璧だがトーンがずれていて、このバッチはすべて同じポリシーで失敗した。傾向は個々の評価よりも重要です。

最初の1週間のスコアを福音ではなくキャリブレーションとして扱ってください。AIの評価の一部を自分の判断と照らし合わせて読み、厳しすぎたり甘すぎたりする部分のルーブリックを調整します。数回のパスの後、スコアが落ち着き、時々のスポットチェックで2人目のアナリストを信頼するのと同じように信頼できるようになります。これは最初の応答時間やその他のサポート数値の追跡と同じ規律です:指標はそれを信じた時にのみ有用です。
ステップ4:コーチングの瞬間とパターンを浮き彫りにする
すべてをスコアリングしても、出力が数字の壁では意味がありません。利益は、AIが人間が実際に見るべき会話を引き出せることです:今週エージェントがポリシー外のことを約束した3枚のチケット、すべての回答がスコアが低いトピック、返金でトーンが崩れる新入社員。
それがコーチング層であり、QAが価値を発揮する場所です。「スコアリングした5枚のランダムなチケットです」ではなく、チームリーダーは「共通点によってグループ化された、会話する価値のある特定の瞬間です」を受け取ります。繰り返しパターンも残りの業務に直結します:スコアが低いトピックは通常、人の問題ではなくチケットトリアージまたはエスカレーションのギャップです。その背後にあるドキュメントやチケットタグ付けルールを修正することで、多くの場合同時にチケット量を削減できます。
ステップ5:ループを閉じる
何も変わらないQAは演劇です。最後のステップは発見事項を還流させることです:AIがフラグを立てたエージェントをコーチングし、繰り返しのミスの背後にあるドキュメントを書き直し、製品とポリシーの変化に合わせてルーブリックを更新します。

サポートの一部が自動化されている場合、ループを閉じることはAI自体を修正することも意味します。良いツールはそれらの修正から学習するため、一度行った修正が同じミスの繰り返しを防ぎます。これにより、QAが後ろ向きの成績表から、週ごとにカスタマーサービス自動化を積極的に改善するものへと変わります。
誰もが忘れること:AI自体をQAする
ほとんどの「QA向けAI」の記事が省略する部分があり、3年以上AIエージェントをライブサポートキューに導入してきた経験から、私が最も気にしている部分です。AIにチケットを処理させるなら、そのAIは顧客に触れる前にQAに合格する必要があり、ほとんどのチームはそのチェックを実行しません。
自信満々に聞こえるボットが完全な確信を持って間違った回答をするのを見てきました。あるDTCサプリメントのリードは私たちにリスクを率直に説明しました:「すみません、わかりません」とすべてに答えるAIは役に立たないが、推測するAIはさらに悪い、なぜなら誰も7,000枚のチケットを再読して推測を見つけられないからです。その答えはどちらもQAです:エージェントは自信を持っていることだけを処理すべきで、その仕事を人間のスコアリングと同様にスコアリングすべきです。
そこで私たちはそのチェックを組み込みました。eeselエージェントがライブになる前に、実際の過去のチケットに対してシミュレーションで実行し、顧客なしでトピック別の品質とカバレッジを確認できます。あるお客様の実際のZendeskトラフィックに対してエージェントを監査した際、トリアージ精度で約93%、偽陽性ゼロでスパムを100%検出しましたが、下書き回答が方向性として正しかったのは88%のみで、7%の事実誤り率がありました。その7%がAIをQAする理由全体です:集計では素晴らしく見えるものの、難しいことに対しては信頼度閾値と人間のループが依然として必要です。同じスコアはエージェント分析にライブで表示されるため、AIのQAは本当に止まることがありません。
これはまた「信頼できますか?」という最も正直な答えでもあります。信仰で信頼するのではなく、QAし、信頼度が低い場合は自動送信ではなく下書きに設定し、スコアが獲得するにつれて自律性を広げます。それがデモとデプロイの違いです。
避けるべき一般的なミス
チームがQAをAIに移行する際に陥るいくつかの罠:
- AIのスコアを最終的なものとして扱う。 それは最初のパスであり、判決ではありません。特に初期は、新しいアナリストをキャリブレーションするのと同じようにスポットチェックしてください。
- 大きすぎるルーブリック。 30の基準は厳格に聞こえますが、一貫性なくスコアリングされます。5つの鋭い次元が30の曖昧なものより優れています。
- 会話をスコアリングしてもループを閉じない。 何も変わらない場合(コーチングなし、ドキュメント修正なし、ルーブリック更新なし)、誰も行動しない非常に徹底的なレポートを作成したことになります。
- 自動化のQAを忘れる。 AIがチケットに回答しているなら、それは最も量が多い「エージェント」です。スコアリングしないことが最大の盲点です。
- QAをCSATと混同する。 顧客は自信満々に間違った回答をもらった後、会話に5つ星をつけることがあります。QAは回答が実際に正確だったかを確認するため、QAスコアとGorgias CSATレポートまたはFreshdesk CSATの両方が必要で、どちらかが代替するわけではありません。
サポートQAのためにeeselを試す
3つのツールを組み合わせずにAIでサポートQAを行いたい場合、これはまさにeeselのAIヘルプデスクエージェントが構築されていることです。既存のヘルプデスクとナレッジベースに接続し、過去の会話を読み、(QAにとって重要な部分は)本物の過去のチケットに対してシミュレーションを実行できるため、何もライブになる前に品質とカバレッジを確認できます。

AIカスタマーサービスソフトウェアの中で、QAに役立つ部分は、AIエージェントの下書きをスコアリングするのと同じエンジンがチームの会話を読むため、人間のQAと自動化のQAが2つのスプレッドシートではなく1か所に存在することです。午後に接続してすでにヘルプセンターを知っているチームメイトのように機能し、自分のチケットをレビューする特権のためにシートごとに課金されない使用量ベースの価格設定です。無料でお試しいただけます。
よくある質問
サポートQAとは何ですか?またAIサポートQAとの違いは?
AIはサポートの会話を正確にスコアリングできますか?
サポート量のどのくらいをAIでQAすべきですか?
AIサポートQAはQAアナリストの代わりになりますか?
AIサポートエージェント自体をどのようにQAしますか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.