AIカスタマーサポートの品質保証:AIエージェントを本当に信頼するには
Riellvriany Indriawan
Katelin Teen
最終更新 June 19, 2026

エージェントがAIの場合の品質保証とは
従来のサポートQAはサンプリングのゲームです。チームリーダーが先週のチケットの2〜5%程度を抽出し、ルーブリックに沿って採点(問題を解決したか?丁寧だったか?ポリシーに従ったか?)し、失敗した人間をコーチングします。人間は概して一貫しており、予測可能な方法で失敗するため、これは機能します。
AIエージェントはそのうちの2つの前提を崩します。手動サンプリングプロセスが想定していたよりもはるかに多くのボリュームを処理し、見慣れない方法で失敗します。新入社員が返金ポリシーをその場ででっち上げることはほとんどありませんが、根拠のないAIはやってのけます。しかも、正確な回答と見分けがつかない自信に満ちた、よく書かれた文章で。そのためQAは「外れ値をコーチングする」ことではなく「システムを検証する」ことになり、任意の自動パイプラインで行うようなAIエージェント評価に近くなります。
重要な視点の転換:AIエージェントの品質保証は2つの場所で行われます。ライブ公開前と後です。損害が出た後に読む月次レポートではありません。
なぜデフレクション率はあなたに嘘をつくのか
QAを行う指標を1つだけ選ぶとしても、デフレクション率にしないでください。これは人間に到達しなかった会話を数えますが、そこには2つの全く異なる結果が静かに混在しています。AIが実際に助けた顧客と、諦めた顧客です。
サポートの実務者はこれを直感的に感じています。r/CustomerExperienceのオペレーションリーダーはこの失敗パターンを率直に述べています:
「上司はデフレクション数値を気に入っていますが、私は信用していません。24時間以内に再オープンされたチケットのレポートを作ろうとしましたが、顧客はクローズされたチケットを使う代わりに別のチケットを開きます。ボットが良い仕事をしたように見えますが、実際は顧客を怒らせただけです。」
関連するスレッドでの返信はさらに厳しいものでした:「ボットはチャットを『成功』させることができますが、ユーザーが20分後にメールチケットを送ってきたなら、そのボットはゴミです。」
これがティア1デフレクションだけを最適化することの問題全体です。沈黙は解決と同じではありません。本当に欲しい指標は、再オープン率と繰り返し連絡率と組み合わせた解決率であり、フラストレーションで離脱した顧客が損失として現れ、きれいなダッシュボードの数字の中に隠れないようにする必要があります。
AIサポートが優れているかを実際に示す指標
単一の数字では仕事になりません。優れたAIサポート指標はパネルとして機能し、それぞれが他の指標が見逃す失敗を捉えます:
- 解決率は見出しの数字ですが、「人間なしで顧客の問題が解決された」と正直に定義してください。「会話が終了した」ではありません。この数字は予測し、時間をかけて追跡する価値があります。解決率は単一の真実の源に最も近いものです。
- 事実誤り率はAI特有の指標です。採点されたサンプルの中で、自信を持って間違えた回答はいくつありましたか?これはハルシネーションチェックであり、多くのチームが構築を忘れる指標です。
- エスカレーションの質は、エージェントが適切なタイミングで適切にハンドオフしたかを問います。難しいチケットでの人間へのハンドオフは、失敗ではなく良い結果です。
- 再オープン率と繰り返し連絡率はデフレクションの嘘発見器です。「解決済み」チケットが繰り返し戻ってくる場合、解決されていなかったということです。
- AI CSATを人間のCSATとは別に測定する。 良いボットスコアがあなたの最高の人間エージェントに支えられてしまわないよう、また逆も同様にならないよう、AI CSATを単独で追跡してください。
数字を当てはめると実際の採点がどのように見えるかをご紹介します。チームがあるトライアルでQAを実施した際、ZendeskとShopifyで月約1,000件のチケットを処理するドイツのオンラインジュエリー小売業者では、曖昧ではなく具体的な結果が出ました:トリアージ精度93%、受信トレイの22%を占めるジャンクに対するスパム検出100%(誤検知ゼロ)、しかし変更なしで送信できるほど品質の高いドラフトはわずか12%、事実誤り率は7%でした。この分布から次の週にどこに時間を投資すべきかが正確にわかります。デフレクション率では絶対に得られない情報です。

私が何度も参照しているRedditスレッドでも、ほぼ同じパネルを挙げている人がいました。多くのサポートチームと話したあるRedditの実務者はこう言いました:「デフレクション率はダッシュボードでは見栄えが良いですが、品質問題を隠します。より良い指標は:自動化された解決率、AIと人間のCSAT、エスカレーションにかかる時間、ボット回答後の再オープン率です。」実際のZendesk自動化を運用する人々とそれを構築する人々が同じリストに行き着くなら、それが正しいリストです。
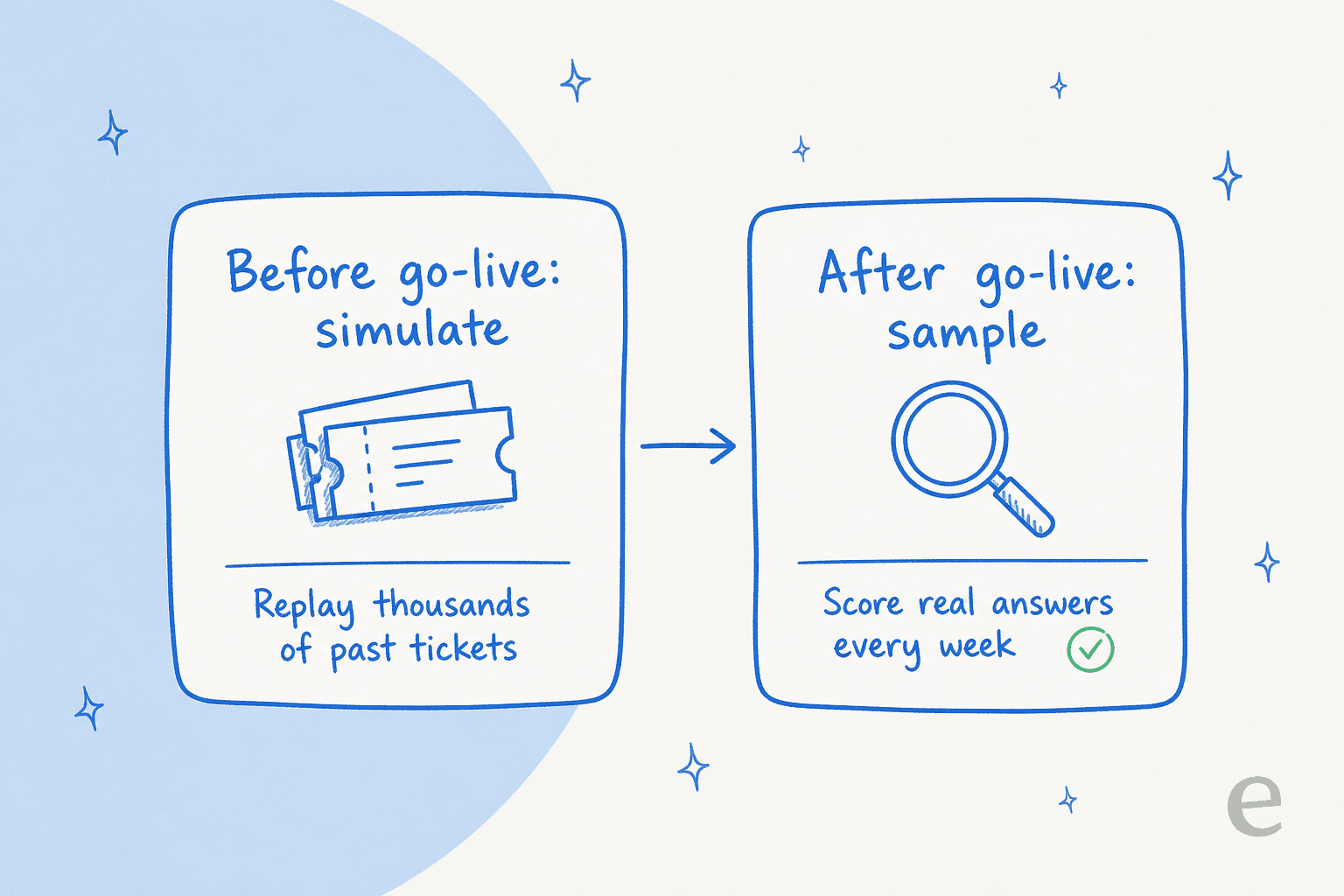
ライブ前のQA:自社チケットでシミュレーション
ここが多くのチームが省略する部分であり、この記事全体で最も価値ある内容です。実際の顧客にAIを解き放って怒りの返信を読むことで、AIが優れているかどうかを確認する必要はありません。事前に確認できます。
方法はシミュレーションです。エージェントを取り、過去に解決済みの何千ものチケットに対して実行し、送っていたであろう回答を生成させ、人間チームが実際に行ったことと比較します。正解がすでにわかっているため、解決率の予測、AIが苦手なトピックのリスト、事実誤り率が得られます。しかも、ライブの顧客を一人も巻き込むことなく。これは合成テストセットではなく、実際のチケット履歴に対して実行する敵対的テストの安全バージョンです。
これは私たちにとって理論上の話ではありません。eeselはエージェントがライブになる前にまさにこれを実行するシミュレーションモードを持っています。その存在理由は傷跡です。自信たっぷりに聞こえるボットが静かに誤った回答をするのを見てきました。デプロイした経験のある人は誰でも見てきています。当社の顧客の一つ、ZendeskのデンマークのテレマティクスチームもEarlyに古典的なバージョンに直面しました。ナレッジベースに「すべてのモデルをサポートしています」と記載されていたため、AIは実際にはデータベースにない自動車ブランドもサポートしていると顧客に愉快に伝えていたのです。そのクラスのバグを発見する唯一の確実な方法は、顧客より先に誤った回答を自社のチケットと照らし合わせて確認することです。
ライブ後のQA:サンプリング、採点、調整
ライブになったら、品質保証はリズムになります。毎週実際の会話の新しいサンプルを抽出し、上記のパネルに基づいて採点し、学んだことをエージェントにフィードバックします。ヘルプデスクはすでに原材料を保持しています。ほとんどのプラットフォームはサンプルを抽出できる会話ログを公開しており、優れた分析ダッシュボードがそれを1回限りの読み物ではなくトレンドに変えます。

採点自体は大掛かりなものである必要はありません。「フォームが堅すぎる」「返金ポリシーを見落とした」などの理由をつけて回答を承認または却下し、そのシグナルが空虚に消えるのではなく、実際にエージェントをトレーニングするようにしてください。驚くほど多くの購入候補者が評価中にまさにこの質問を尋ねます。「回答を承認または却下するかどうかを追跡していますか?それは何かを変えますか?」というバリエーションです。フィードバックループが機能しているなら、各QA作業が翌週の回答を改善します。機能していないなら、真空の中で採点しているに過ぎません。
注意すべき点:ヘルプデスクのAPIが会話の途中でスロットリングされるなど、何かが壊れたときのエージェントの振る舞いです。eeselの創設者であるAmoghには、チームに刻み込まれた言葉があります:失敗がサイレントならば、それは「サイレント失敗クラスで、信頼にとって最悪のクラスです」。大きな失敗を起こしてハンドオフするAIはQAの仕事を代わりにしてくれています。サイレントに失敗して推測するAIこそ、毎週のサンプルが存在する理由です。
最も難しい部分:AIが知らないことを知っていると信頼すること
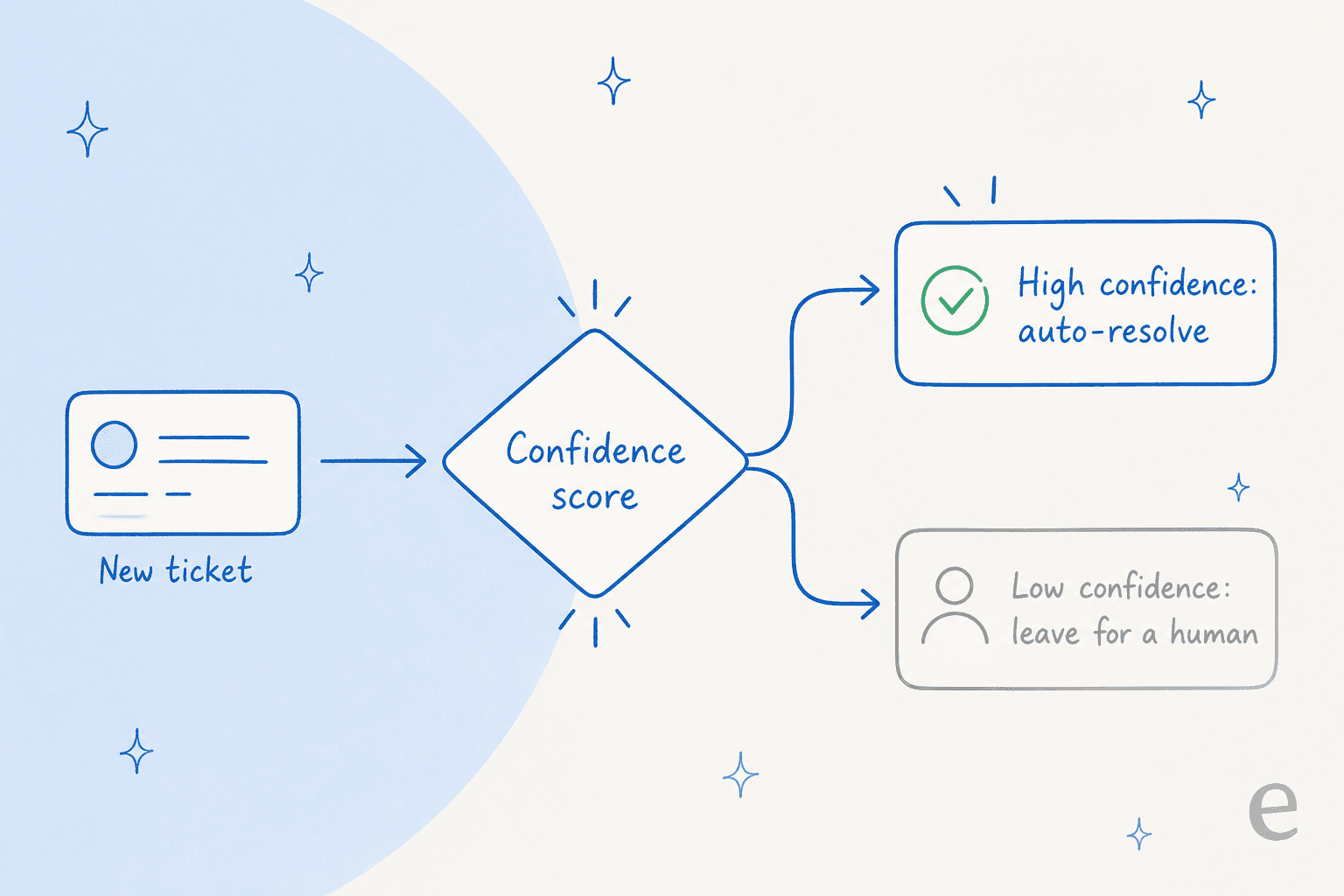
AIがすべてに答えようとするのをやめた瞬間、上記のすべての指標が楽になります。これは私たちを評価しているチームから最もよく聞くことであり、どんなモデルアップグレードよりも価値があります。
Gorgiasで月約7,000件のチケットを処理するDTCサプリメントブランドのCXリードは、私が表現できる以上にうまく言葉にしています:AIが100%の質問に答えることはありません。でも試みてただ「すみません、わかりません」と言うだけなら、誰も7,000件のチケットを振り返って本当に良い仕事をしたかどうか確認できません。彼らが求めていたのは「自信を持って対応できるチケットだけを処理し、その他はすべて放置する」AIでした。
それが信頼度ベースのルーティングであり、あなたが持つ最も影響力の高いQAコントロールです。エージェントが信頼度のしきい値を超えた場合にのみ発言し、それ以外は人間に静かにルーティングすると、事実誤り率が下がり、エスカレーションが意味を持ち、QAが必要な回答はより小さく、より高品質なセットになります。同じRedditスレッドには鋭い警告がありました。ある実務者は会話全体をデフレクションではなく解決を中心に再構成しながら、「ゼロハルシネーション」の主張に「乗るな」と皆に思い出させました。信頼度ルーティングはそこへ正直に到達する方法です。AIが決して間違えないと主張するのではなく、間違えるかもしれないときに黙らせることで。
規制を受けるチームにとって、これは交渉の余地がありません。あるリーガルテック企業の共同創業者は、「ソーシングに関する正確なガードレールを設定でき、常に透明な引用を提供する」からこそAIを採用できると私たちに語りました。役立つことと法的アドバイスを与えることの境界線です。引用と信頼度ゲートは機能ではなく、QAそのものです。
実際に実行できるQAワークフロー
具体的な出発点が必要なら、Zendesk、Freshdesk、またはAIを持つあらゆるヘルプデスクでAIエージェントを立ち上げるチームのために私が設定するループをご紹介します:
- まずシミュレーションする。 ローンチ前に、数千件の過去チケットに対してエージェントを実行し、想定される回答のサンプルを読む。勘ではなく、予測された解決率にゴーライブの基準を設定する。
- 狭くローンチする。 チケットキュー全体ではなく、確実な1〜2のトピックでエージェントをオンにする。信頼度ルーティングがこれを簡単にする。
- 毎週採点する。 実際の会話をサンプリングし、解決率、事実誤り、エスカレーションの質で採点し、エージェントをトレーニングする理由を添えて悪い回答を却下する。
- 嘘発見器を見る。 フラストレーションを感じた顧客が勝利として隠れてしまわないよう、デフレクションの隣に再オープン率と繰り返し連絡率を追跡する。
- ドリフトにアラートを設定する。 突然の品質低下が次のレビューまで待つのではなく、レビュー間にも知らせるようモニタリングを設定する。
1ヶ月間続けると、ほとんどの「AIをデプロイした」ストーリーが決して得られないものが得られます:「どうやって優れていると知るのですか?」という質問に対する説明責任ある回答です。
eeselで本当にQAできるAIサポートを試してみる
この記事の大部分はeeselがどのように動作するかを説明しているに過ぎません。品質保証こそ私たちがプロダクトを中心に構築したものだからです。ヘルプデスクとナレッジベースを接続すると、eeselはあなたの過去のチケットとドキュメントでトレーニングし、ライブ前にそのシミュレーションモードが何千もの過去の会話にエージェントを実行することで、解決率を予測し、誤った回答を非公開で確認できます。ローンチ後、信頼度ベースのルーティングがエージェントを確信できないことについて黙らせ、レポートが毎週何を採点すべきかを示します。

無料で試すことができ、何にもコミットする前に自分のチケットで完全なシミュレーションを実行できます。これが最も誠実なQAです:実際の顧客にどのように答えていたかを確認し、それから決定する。eeselを試す、シミュレーションから始めましょう。
よくある質問
AIカスタマーサポートの品質保証とは何ですか?
デフレクション率はAIサポート品質保証に適した指標ですか?
AIサポートエージェントのハルシネーションを防ぐには?
AIサポートエージェントのQAはどのくらいの頻度で行うべきですか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.