AIでサポートエスカレーションに対応する方法
Alicia Kirana Utomo
Katelin Teen
最終更新 June 17, 2026

エスカレーションは後から考える問題ではなく、難しい部分
ほとんどの「AIエージェントをデプロイする」ガイドが飛ばしている点があります。AIエージェントの印象的な部分(適切に回答すること)は簡単な80%です。顧客があなたを信頼するかどうかを決める部分は退屈な20%:いつ止まって人を呼び込むかを知ることです。r/AI_Agentsで最も引用されているスレッドの一つがこれを完璧に表現しており、タイトルだけがサブレディット全体で引用されています:"AIエージェントを構築する最も難しい部分は、人間に引き継がせること"。元の投稿者の主張:誰もがより賢く自律的なエージェントに最適化し、いつどのように諦めるべきかという地味なエンジニアリングは誰もやらないということです。
顧客はこのギャップをすぐに感じ取ります。ほぼすべての「このチャットボットが嫌い」というバイラルな話は、AIが愚かだということではなく、逃げ道のない状態に閉じ込められることについてであることに注目してください。コミュニティは脆いトリガーを回避する方法さえ学んでいます。r/lifehacksのVerizonトリックのように:「人間と話す」と言っても何も起きず、罵倒するとすぐにキューに入れられます。a16zがカテゴリ全体をフレームした時、Sarah Wangはユーザーの本当の痛みから始めました:「あなたが何に怒っているかを理解するようにプログラムされていない非知的なチャットボットに怒りを打ち込んできた。」引き継ぎこそが製品なのです。
そのため、このガイドはエスカレーションをファーストクラスの設計問題として扱います。トリガーごとに解説し、次にハンドオフ、次に測定、そして最もよく見るミスを紹介します。このハウツーと並行して概念的な深掘りをしたい場合は、AIチャットエスカレーションの概要がよく合います。また、異なるツールがどう対応するかを比較する場合は、チャットボットエスカレーションのまとめがプラットフォームごとに解説しています。
AIエージェントはいつエスカレーションすべきか?5つのトリガー
エスカレーションのルールは1つではなく5つあり、最良のシステムはすべてを設定しています。1つだけ実装するチーム(通常は信頼スコアの閾値)は最終的に顧客が閉じ込められる結果になります。この件について一つだけ読むなら、AIから人間への引き継ぎのタイミングの解説をお読みください。
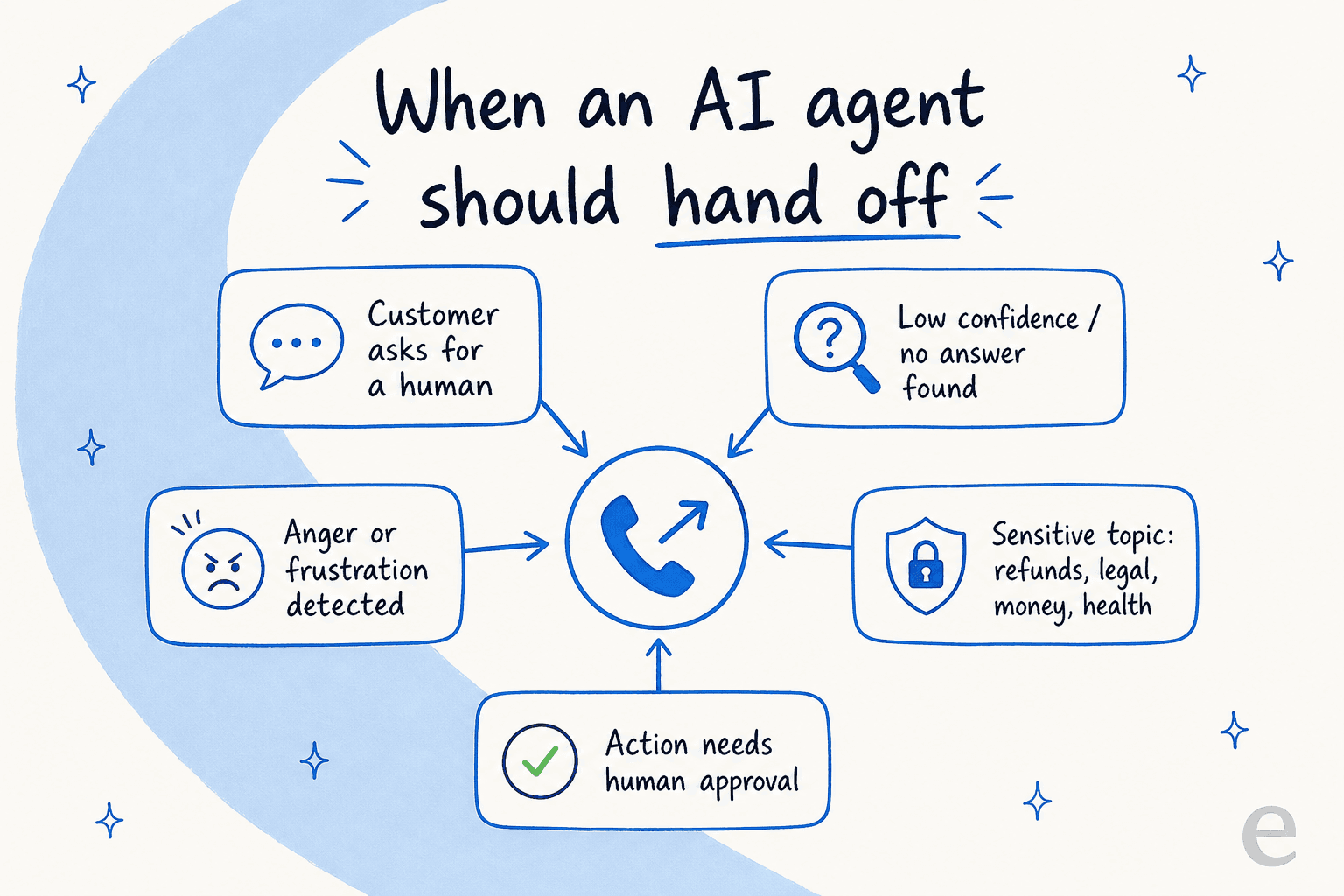
- 人間への明示的なリクエスト。 交渉の余地はなく、チームが最もよく破るルールです。顧客が人を求めた時は、確認ループなし、再試行なしで即座にエスカレーションします。Salesforceはこれをトピック分類器レイヤーで設定し、"内部ロジックをバイパスして即座にハンドオフを発動する"ようにしています。Salesforce AIエスカレーションガイドでそのフローを詳しく解説しています。このパスを埋め込むのは信頼を破壊する最速の方法の一つです。
- 低信頼スコアまたは知識のギャップ。 モデルがインテントを理解しているかどうかわからない場合、またはドキュメントから何も見つからなかった場合は、推測するのではなく引き継ぐべきです。Gorgiasはこれを明確に文書化しています:そのAIは接続されたソースを"超えて推測しない"、「関連する回答が見つからない場合は推測するのではなく引き継ぐ」とあります。
- フラストレーションまたは敵対的な感情。 「これは役に立っていない」などのフレーズは、顧客が怒ってやめる前に謝罪して引き継ぐサインです。Social Intentsはこれを明示的に監視することを推奨するパターンとして挙げています。
- 機密トピック(信頼スコアに関わらず)。 返金、請求争議、法的脅迫、詐欺、医療的な質問、資金移動または身元確認に関わるすべてのもの。Gorgiasは"自傷、暴力の脅迫、法的措置の脅迫、および財務口座の詳細を含むリクエスト"への言及でハンドオーバーをハードコードしています。CX Todayはこれを「リスクスコアリング」と呼び、信頼スコアとは別のものです:自信満々なボットであっても、チャージバックを自動的に解決すべきではありません。
- 人間の承認が必要なアクション。 不可逆的なもの(返金の発行、データの削除、割引の承認)はエージェントがどれだけ確信していても必ずエスカレーションすべきです。重要なのは、その承認ルールはAIの判断ではなくワークフローに存在すべきだということです。AIが自身のアクションに承認が必要かどうかを決定できると、説得力のあるプロンプトでその決定を覆させることができるからです。
あるeesel顧客が営業電話でこの目標全体をうまく要約しました。Zendesk上で月200〜250チケットを処理するバス追跡サービスのサポートマネージャーは、AIに「Zendeskの受信チケットの60%を処理し、本物の人間を引き込むタイミングを知ってほしい」と言いました。最後の節がすべての仕事です。人を引き込むタイミングを知ることが、信頼できるAIヘルプデスクエージェントと、静かに人々を苛立たせるデフレクションマシンを分けるものです。
ステップ1:信頼スコアだけをトリガーとして頼らない
信頼スコアルーティングは摩擦が最も少ないトリガーであり、最も調整を誤りやすいものでもあります。罠は、モデルの信頼スコアが体系的に過大評価されていることです。Digital Appliedの2026年エスカレーションガイドによると、RLHFで訓練されたモデルはキャリブレーションが不適切で、主張された90%の信頼スコアは実際の精度では75%程度に対応することが多いとあります。安易な閾値を設定すると、自信満々だが誤った回答の流れを送り出すことになります。
解決策は信頼スコアを捨てることではなく、3つの入力の一つにすることです。CX Todayのモデルが最も明確です:信頼スコア(インテントを理解しているか、回答が正しいか)、リスク(自信があっても自動化するには機密すぎるか)、努力(再試行、繰り返しインテント、増加するフラストレーション、「エージェント」キーワード)を組み合わせます。努力は過小評価されているものです。繰り返しの試みは顧客がすでに不信感に陥っていることを意味するため、優れたシステムは努力を自動化を早期に終了する理由として扱います。
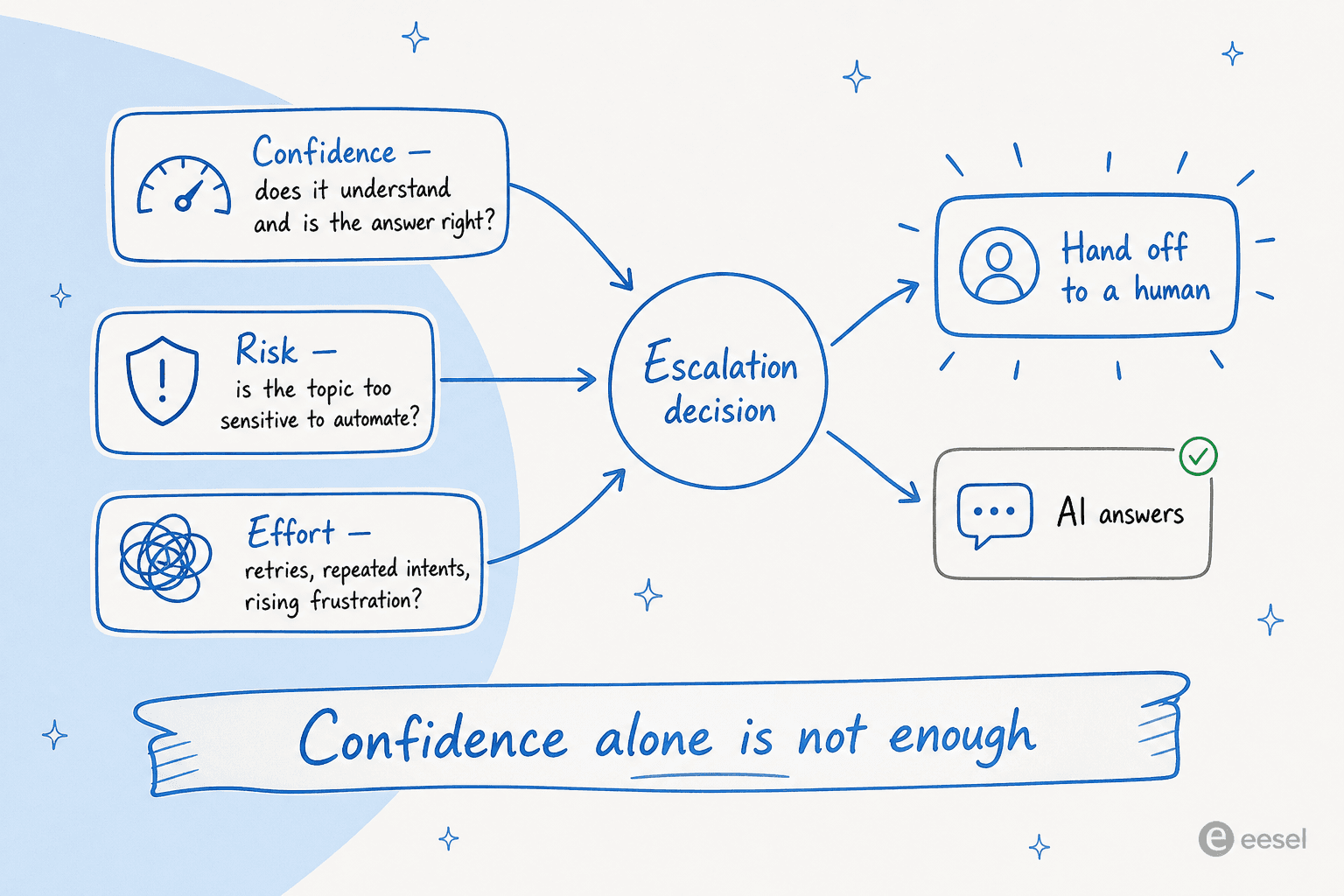
その上での2つの実践的な手順:
- 送信前にセカンドモデルのQAゲートを追加する。 Gorgiasはすべての下書き回答を別の確認でラップしています:"セカンドAIモデルが信頼スコアを測定し、回答が閾値を満たさない場合は送信されない。" これが「エスカレーションせずにハルシネートする」という失敗に対する最良の防御策です。
- 高リスクインテントには高い閾値を使用する。 Social Intentsは、信頼スコアが連続して2回閾値を下回った場合にエスカレーションすることを提案しており、返金、請求、キャンセルはリスクの低い質問よりも厳しい基準が適用されます。
数値の調整についてより深く理解したい場合は、AIレスポンスの信頼スコア閾値の設定についての記事全体を書きました。短いバージョン:閾値は一度設定する定数ではなく、再調整する出発点です。
これは買い手から最も多く聞く反論でもあり、良い直感です。Gorgiasで月約7,000チケットを処理するDTCサプリメントブランドのCXリードは、正確にこう言いました:
「AIは100%の質問に答えることは絶対にできないけど、もし試みて『ごめんなさい、これはわかりません』と答えるだけなら、7,000チケット全部を確認することはできない…信頼できるチケットだけを処理して、それ以外はすべてそのままにしておくAIが必要だ。」
その「そのままにしておく」が信頼スコアルーティングの設計全体のブリーフィングです。エージェントの仕事はすべてを試みることではなく、ある領域を確実に担当し、残りをきれいにルーティングすることです。
ステップ2:AIが絶対に触れてはいけないものを決める
トリガーを調整する前に、常に人間に行くカテゴリの周りに厳しい境界線を引いてください。これはポリシーであり確率ではなく、信頼スコアに委ねるべきではありません。
ほとんどのチームにとって、「常にエスカレーション」リストは次のようなものです:法的争議または法的措置への言及、詐欺とチャージバックの言語、医療・健康上の質問、そして書かれたポリシーの外での判断を必要とするもの。サブスクリプションや請求の争議も通常ここに属します。Gorgiasは出発点として借用できるデフォルトのハンドオーバートピックリストを公開しています。
同様に重要なのは逆側:チームが特定のチケットタイプを自動化から完全に除外できるようにすること。これは私たち自身のオンボーディング会話で常に出てくるテーマで、管理者は「AIを通したくない特定のチケットがある」などと言います。良い設定はそれを尊重します。たとえばWISMOとパスワードリセットにAIを限定し、返金とアカウント変更は初日から人間のみにしておき、信頼を築きながらスコープを広げていけるべきです。この段階的な自律性アプローチは、ティア1サポートデフレクションに対する考え方の核心です:狭く始め、実証し、拡大する。
ステップ3:ハンドオフを温かくする、トランスクリプトの垂れ流しではなく
ここがほとんどのエスカレーションシステムが静かに失敗する場所です。ルーティングロジックは機能し、チケットは移動し、そして人間はゼロから始まります。そのコールドリスタートこそが顧客が「自動化は私の時間を無駄にしただけ」と感じる体験であり、人間の引き継ぎのベストプラクティスガイドが最も時間を費やしている唯一の点です。
ここでの数字は残酷です。消費者の73%が、情報を繰り返す必要があることはサポートの最も苛立たしい部分の一つだと言っています、特に転送後、PwCの調査によるとBlueTweakが引用しています。そして約70%の顧客がエスカレーション時にエージェントが自分の履歴を知っていることを期待していますが、実際にそのデータをきれいに渡せるツールを持つチームは約34%に過ぎないと言っています。この2つの数字の差が信頼が死ぬ場所です。
これを最もよく表現した実践者はNavdeep Singh Gillで、ヒューマンAIハンドオフに関するLinkedInの長文記事でこう述べています:
「コンテキストを失うハンドオフは仕事を転送しない。仕事を破壊する…エージェントをデプロイする前に聞いてみてください:『このエージェントが引き継いだ時、顧客は自分を繰り返す必要があるか?』もしそうなら、あなたはハンドオフを構築していません。余分なステップを持つ放棄を構築したのです。」
では、ウォームハンドオフが実際に持つものは何でしょうか?生のチャットログではなく、それは単なる非構造化データです。構造化されたコンテキストパッケージ。r/AI_Customer_Supportのサポートリードが4つのアーティファクトを挙げています:チケットに添付されたAI生成のサマリー、完全なチャット履歴(最後のメッセージだけでなく)、顧客がフラストレーションを感じている場合の感情フラグ、そして人間が問題を解決しているのか期待値をリセットしているだけなのかがわかるような明確なエスカレーション理由タグ。
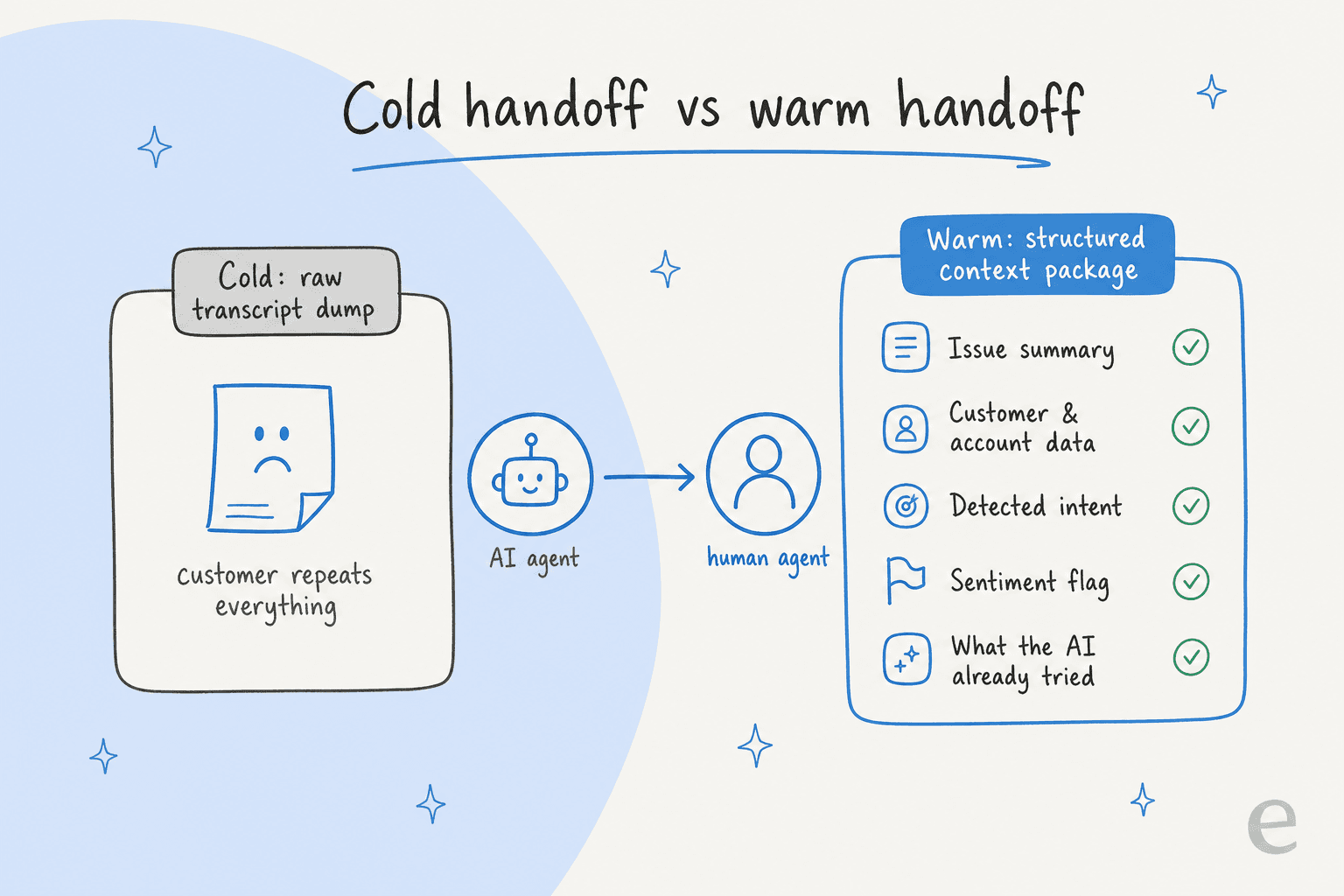
大きな違いをもたらす細かい点がいくつかあります:
- 人間の最初の行でボットの作業を認識する。 「こんにちは、Janeさん、パスワードのリセットについてボットとチャットしていたのを確認しました。お手伝いします」は、新たな出発点を示す汎用的な「どのようにお手伝いできますか?」より優れています。
- すべてのエスカレーションされたチケットにルーティング用のタグを付ける。 一貫したタグ(Gorgiasは
ai_handoverを使用)により、ダウンストリームルールが手動でトリアージする必要なく、自動的にハンドオフを正しいチームに送ることができます。Zendesk上にいる場合は、ZendeskのAIエージェントハンドオフ設定がこれを詳しく説明しており、ループに人間を入れずにルーティングが行われるようチケットに自動タグ付けもできます。
適切に行われたコンテキストは解決を加速さえします:完全なコンテキストを持つエスカレーションを受けた人間は、ゼロから始めるものよりも意味のある速さで解決すると報告されており、アナリストが引用した数字では35〜45%の範囲(方向性は明らかです)。
ステップ4:顧客に何が起きているかを伝える
コンテキストとは別の失敗の表面:顧客はAIと人間の間で何が起きているかまったく知らない。転送中の沈黙は人々に忘れられたのではないかと疑わせます。
修正は簡単です。黙って切り替えるのではなく、「もちろんです。お手伝いできる担当者におつなぎします」などと言い、待ち時間があれば期待値を設定します(「あなたは2番目です、約1〜2分です」)。Social Intentsはこの安心感は非常に少ない労力で多くの効果をもたらすと述べています。そして逃げ道を常に見えるようにしておいてください。なぜなら80%の人は人間のオプションがあることを知っている場合にのみチャットボットを使用し、30%は一度の悪いボット体験の後に競合他社に切り替えるからです。
同じプレイブックからもう一つのルール:最初に正しいチームにルーティングする。ハンドオフの最悪のバージョンは、「申し訳ありませんが、別の部署に転送する必要があります」とすぐに言う人間に届くことです。ツールのインテント駆動ルーティングがその2番目の信頼破壊的なハンドオフを防ぐものであり、顧客がリアルタイムで待っているライブチャットデフレクションで最も重要です。これらのパターンをさらに収集したAIハンドオフフローの会話デザイン例と、GorgiasユーザーがAIハンドオーバー体験を制御するガイドでは文言を細かく調整できます。
ステップ5:デフレクション率だけでなく、ハンドオフを測定する
デフレクション(または「コンテインメント」)率だけを測定すると、罠に向けて最適化してしまいます。古典的なバージョンはAIサービスデスクの運用に関するr/sysadminスレッドに登場しました:
「わあ、今月5,000件の問題を処理した!高価な人間のキューに届かなかった5,000チケット。ただし半分はボットの「回答」が実際には何も解決しなかったため、2日後に再チケットを作成し、今やバックログと怒ったユーザーが増えた。」
それが一段落でデフレクションをバニティメトリクスとして使う問題です。低いCSATを伴う高いデフレクション率は、幸せな顧客を伴う低いデフレクション率より悪いです。ハンドオフ率は「結果と組み合わせた時にのみ意味を持つ」とBlueTweakが述べています。
実際に追跡する価値のある指標:
| 指標 | 何がわかるか |
|---|---|
| インテント別エスカレーション率 | どのトピックが自動化に最も失敗するかを示し、知識を追加すべき場所がわかる |
| CSATデルタ(自動化対エスカレーション) | エスカレーションされたチャットのスコアが低い場合、問題はほぼ常にエージェントではなくハンドオフにある |
| 再連絡率(24〜48時間) | 隠れた失敗の最も信頼できるシグナル:実際には解決していない「回答」 |
| ハンドオフ後の初回解決 | 人間が一度で解決するのに十分なコンテキストを継承したかどうか |
| オプトアウト後の人間までの時間 | AIを離れた後に顧客がどれだけ待つか |
これについてはAIコンテインメント率とエスカレーション品質の測定とAIデフレクションと人間デフレクションの違いのガイドで詳しく解説しています。一貫したメッセージ:量と並行して質を追跡してください、さもなくば量の数字が嘘をつきます。指標自体を初めて知る場合は、デフレクション率とは何か、どう改善するかから始めてください。

最後に、月次レビューの習慣を作ってください:フラグ付きとエスカレーションされたチケットのサンプルを読み、繰り返しのハンドオーバークラスターを探し(それらは知識のギャップ)、再調整します。誤ルーティングは来月のポリシー更新の入力になります。
避けるべき一般的なエスカレーションミス
最初から回避できるよう、最もよく見る失敗モードの簡単なフィールドガイドです:
- エスカレーションせずにハルシネートする。 QAゲートがないため、信頼スコアの低い回答が送信され、CSATが静かに崩壊します。
- 「理解できない」ループ。 失敗した試みを2〜3回に制限してください;終わりのない再試行ループは顧客が怒ってやめる原因です。Freshdeskはそのセットアップドキュメントでこれらの"フラストレーションを招く終わりのないループ"について明示的に警告しています。
- 非同期ブラックホール。 技術的には「エスカレーション済み」、それからフォローアップなしでキューに入れられます。r/AnthropicのポスターはAIに"担当者が手一杯だ…すぐにメールで連絡します"と言われて結局連絡がなかったと述べています。エスカレーションシアターは正直さより悪いです。
- ループバック。 顧客を失敗した同じ自動化フローに再ルーティングする。信頼は急速に崩壊します。
- 過剰エスカレーション。 逆の失敗。承認リクエストが頻繁に発動すると、人々は読むのをやめてすべてを反射的に承認し、目的を損ない、独自の攻撃面になります。
eeselでのエスカレーション対応方法
私たちはハンドオフが製品であるという信念でeeselを構築しました。ここでピースがどのように組み合わさるかを説明します(どこが適合していてどこが適合していないか)。
まず、ライブ公開前にシミュレーションを行います。 これは手放したくない部分です。eeselのAIヘルプデスクエージェントはシミュレーションで数千の過去のチケットに対して実行され、1人の顧客が見る前に、予測される解決率、エスカレーション率、そして引き継いでいたであろう会話を正確に確認できます。信頼スコアの閾値を推測して期待するのではなく、実際の履歴に対して調整します。
次に、制御はデフォルトであり、アップセルではありません。 AIがどのチケットタイプに触れるかを決定し、常に人間に行くトピックを設定し、信頼を構築しながら自律性を段階的に付与します。ルールエンジンではなく自然言語でこれらすべてを設定できます。

3番目に、ハンドオフはデザインによってウォームです。 eeselはヘルプセンターの記事だけでなく、解決済みのチケットから学ぶため、エスカレーションされたチケットはサマリー、履歴、そして理由タグを直接正しいエージェントに運びます。再紹介なし。フローは既存のヘルプデスク内に存在します:Zendesk上ではハンドオフに自動タグ付けとルーティングを行い、FreshdeskまたはHelp Scoutを使用するチームでも同様に機能します。
これが実際の規模で機能するのを見てきました。あるeeselのデプロイは月100,000件以上のドイツ語チケットで完全自動化されたZendeskエージェントを実行しており、エスカレーションが確実でなければ維持できないチケット自動化の規模です。Gridwiseはeeselが7日間のトライアル中に最初の月にティア1リクエストの73%を解決するのを見ました。これらすべてに共通するのは、AIがすべてに答えたのではなく、自分の領域を知り、残りをきれいに引き継いだということです。
正直な注意点:過去のチケットやドキュメントのコーパスがまだない場合、どのツール(私たちも含め)も知識を構築している間は最初により多くエスカレーションに依存します。それは予想されることで、だからこそ最初にシミュレーションすることが重要で、驚くのではなく目を開けて入ることができます。まだオプションを評価中なら、最も安いAIヘルプデスクアプリのまとめとカスタマーサービス自動化のためのAIガイドが良い次の読み物です。
サポートエスカレーションにeeselを試す
サポートキューにAIを設定して、初日からエスカレーションを適切に処理したい場合、eeselはまさにこのために構築されています。過去のチケットから学習し、ローンチ前にエスカレーションと解決率をシミュレーションでき、AIが触れるものをコントロール下に置き、既存のヘルプデスクにウォームでタグ付きのハンドオフを渡すため、どの顧客も自分を繰り返す必要がありません。
クレジットカード不要で、数分でヘルプデスクを接続して過去のチケットでシミュレーションを実行できます。AIヘルプデスクエージェントページで実際に確認するか、料金を確認してください(使用量ベースで、シートごとの料金はありません)。

よくある質問
AIでサポートチケットをエスカレーションするとはどういう意味ですか?
AIエージェントはいつ人間にエスカレーションすべきですか?
AIサポートエージェントがエスカレーションしすぎたり少なすぎたりするのを防ぐにはどうすればよいですか?
エスカレーション時にAIは人間にどのような情報を渡すべきですか?
AIが処理するチケットとエスカレーションするチケットを制御できますか?
AIエスカレーションが機能しているかどうかはどうやって測定しますか?
AIエスカレーションはZendesk、Freshdesk、Gorgiasで機能しますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.







