
Kurzzusammenfassung
Wenn Sie den Support bei einem SaaS-Unternehmen leiten, fehlt Ihnen das Wissen nicht - es ist verstreut: ein Teil im Help Center, ein Teil in Notion oder Confluence, vieles davon in Google Docs und alten Tickets, die niemand die Zeit hat, in Artikel umzuwandeln. Eine KI-Wissensdatenbank vereint all das und beantwortet Fragen direkt, anstatt dem Leser eine Linkliste zum Durchlesen zu geben.
Die zwei Dinge, die eine echte von einer Demo-Losung unterscheiden: Sie antwortet aus Ihren Quellen mit einem Quellennachweis bei jeder Antwort, und sie weiss, wann sie besser schweigt. Ein Bot, der selbstsicher eine falsche Antwort uber Ihre API oder Ihre Ruckerstattungsrichtlinie erfindet, richtet mehr Schaden an als gar kein Bot. Die Losung ist konfidenzbasiertes Routing plus die Moglichkeit, das System anhand echter vergangener Tickets zu testen, bevor ein Kunde es sieht.
Ich entwickle die KI-Agenten bei eesel, daher beschreibt der Rest dieses Artikels, wie ich eine solche Losung fur ein SaaS-Team tatsachlich aufbauen wurde, was sie kostet und wo sie noch an Grenzen stoesst.
Mein Ausgangspunkt
Ich arbeite an den Agenten bei eesel, und ich habe die letzten drei-plus Jahre damit verbracht zu beobachten, was passiert, wenn man KI auf die Wissensdatenbank eines SaaS-Unternehmens richtet - uber Tausende von Live-Tickets und echten Einfuhrungen hinweg. Das schliesslich auch den unangenehmen Teil ein. Wir haben beobachtet, wie ein selbstbewusst formulierter Bot einem Kunden sagte: "Ja, das unterstutzen wir" - fur etwas, das das Produkt schlichtweg nicht kann, einfach weil ein Help-Dokument "wir unterstutzen alle Modelle" sagte. Diese eine Erfahrung ist der Grund, warum alles im Folgenden darauf ausgerichtet ist, genau das zu vermeiden.
Es gibt aber auch den guten Teil. Eine Gig-Economy-Analytics-App auf Zendesk loste 73 % der Tier-1-Anfragen in ihrem ersten Monat mit uns. Ein Zahlungsunternehmen verzeichnete bis zu 80 % Zeitersparnis beim Auffinden von Antworten in seiner Dokumentation. Eines unserer groessten Deployments betreibt still und leise einen KI-Helpdesk-Agenten uber mehr als 100.000 deutschsprachige Tickets pro Monat. Ich bin also nicht neutral, aber ich wurde lieber erklaren, wo eine KI-Wissensdatenbank ihren Wert beweist und wo nicht, als Ihnen eine Fantasie zu verkaufen.
"Im ersten Monat lost eesel 73 % unserer Tier-1-Anfragen. Unser Team hat die Losung wahrend unseres 7-Tage-Tests schnell implementiert und Ergebnisse erzielt. Antworten sind einfach zu korrigieren und anzupassen."
Kim Simpson, Gridwise (G2-Bewertung)
Was eine KI-Wissensdatenbank wirklich ist
Wenn man das Marketing weglasst, ist es eine Schicht, die zwei Aufgaben erfullt, die Ihr aktuelles Help Center nicht kann.
Erstens liest sie alles auf einmal. Nicht nur veroffentlichte Hilfeartikel, sondern Ihre internen Runbooks, Ihre Google Docs, Ihre Produktspezifikationen und Ihre historischen Tickets. Zweitens antwortet sie, anstatt nur zu suchen. Fragen Sie ein normales Help Center "Wie rotiere ich meinen API-Schlussel?", erhalten Sie eine Suchergebnisseite. Fragen Sie eine KI-Wissensdatenbank, erhalten Sie die drei Schritte aus dem richtigen Dokument - mit einem Link zu diesem Dokument, damit der Leser es uberprufen kann.
Der zugrundeliegende Mechanismus ist Retrieval-Augmented Generation, kurz RAG. Das Modell antwortet nicht aus seinem eigenen Gedachtnis; es ruft zuerst die relevanten Passagen aus Ihrem Inhalt ab und schreibt dann eine Antwort, die auf ihnen basiert. Wenn Sie die tiefere Erklarung mochten, warum das wichtig ist, haben wir RAG versus ein reines LLM und Retrieval versus hybride Suche speziell fur den Support aufgeschlusselt. Die Kurzversion: Die Verankerung der Antwort in Ihren Dokumenten ist das, was Erfindungen verhindert. Meistens.
Viele Teams beginnen klein, indem sie eine ChatGPT-Wissensdatenbank oder einen der KI-Dokumentationsassistenten einrichten, die wir getestet haben, und wechseln dann zu einer zweckgebundenen Losung fur den Support, sobald das Volumen real wird.
Warum SaaS ein Sonderfall ist
SaaS-Support hat ein Wissenproblem, das sich in seiner Form von anderen Branchen, etwa dem Einzelhandel, unterscheidet. Drei Dinge machen es schwieriger.
Ihr Wissen lebt an mehr Orten. Ein SaaS-Unternehmen halt selten alles in einem ordentlichen Help Center. Produktdokumentationen sind in Confluence, Anleitungen sind in Notion, technische Antworten sind in Slack-Threads, und die echten Antworten auf die schwierigen Fragen stecken in gelosten Tickets. Eine Meeting-Produktivitats-SaaS, mit der wir arbeiten, brachte es auf den Punkt: Ihre Agenten mussten fruher durch Notion, Google Docs und das Help Center graben, um ein einzelnes Ticket zu beantworten.
Ihr Produkt andert sich wochentlich. Ein Hilfedokument, das fur die Benutzeroberflache des letzten Quartals geschrieben wurde, ist schlimmer als gar kein Dokument, weil der Bot es selbstsicher prasentieren wird. SaaS-Dokumente veralten schneller als fast jede andere Kategorie, weshalb die Erkennung veralteter Inhalte Teil des Systems sein muss und kein Nachgedanke.
Ihre Dokumente sind oft fur den falschen Leser geschrieben. Ich habe eine Wissensdatenbank gesehen, die vollstandig fur Administratoren geschrieben war, wahrend jedes eingehende Ticket von Endbenutzern kam. Der Inhalt war technisch korrekt und praktisch nutzlos, und ein naiver Bot verstarkt diese Diskrepanz nur.
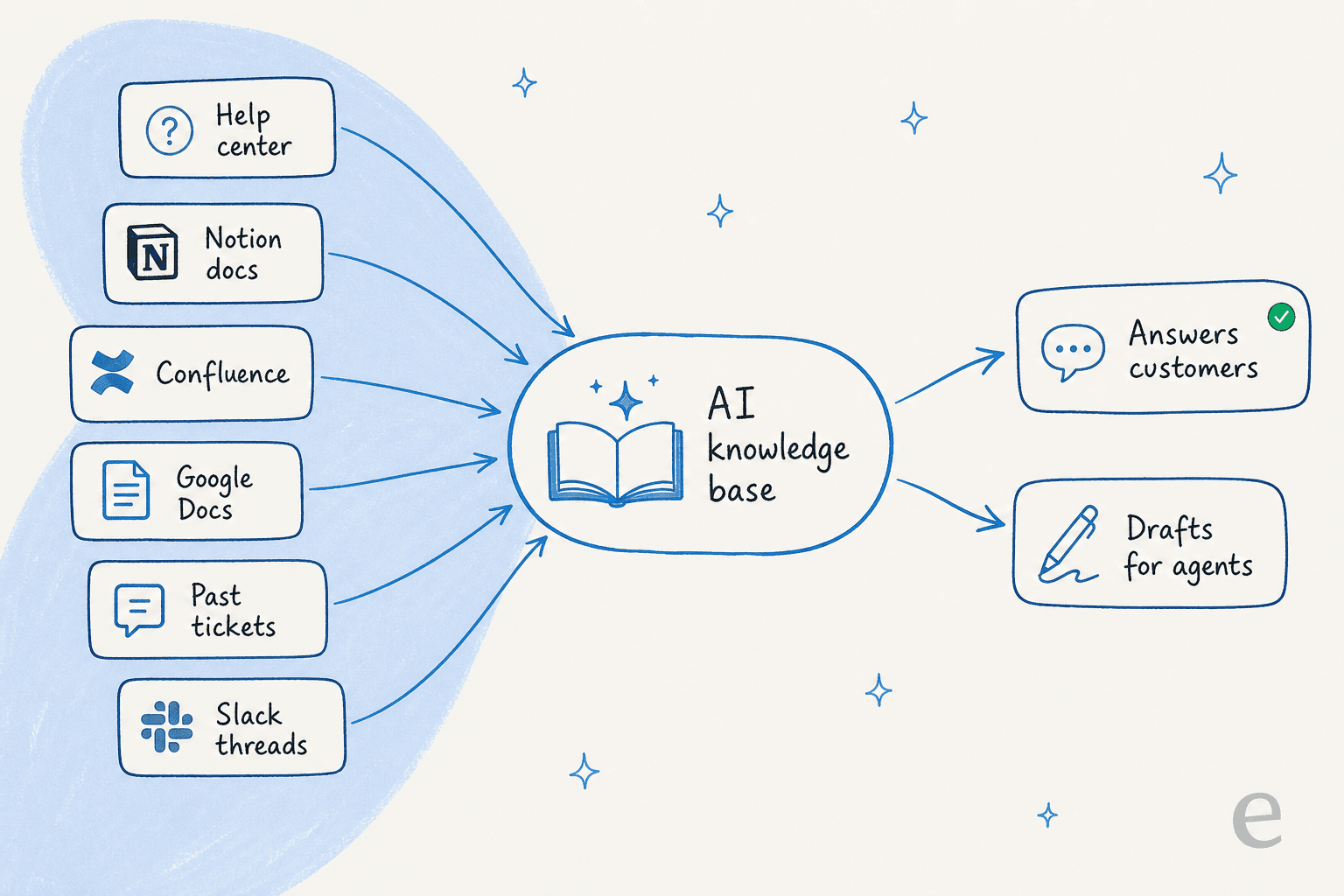
Das ist der Teil, den man leicht unterschatzt. Die KI ist selten der Engpass; der Zustand Ihres Wissens ist es. Das Prufen und Aufraumen Ihrer Quelldokumente, bevor Sie irgend etwas aktivieren, ist die einzelne Massnahme mit dem hochsten Hebel, und es lohnt sich, unseren Leitfaden zum KI-gestutzten Wissensdatenbankmanagement zu lesen, bevor Sie beginnen.
Der Teil, den alle falsch machen: Genauigkeit
Hier ist das, was KI-Wissensdatenbankprojekte zum Scheitern bringt - und es ist nicht die Modellqualitat. Es ist das Vertrauen. Eine selbstsicher falsche Antwort uber Abrechnung, Sicherheit oder die Fahigkeiten Ihres Produkts genugt, und Ihr Team glaubt dem Bot nicht mehr, Ihre Kunden vertrauen Ihrem Support nicht mehr, und Sie haben Budget ausgegeben, um die Dinge zu verschlechtern.
Wir haben das erlebt. Fruher hat ein Bot ohne harte Konfidenzschwelle ein Abonnementdetail erfunden und an einen echten Kunden geschickt, weil die Suche leer zuruck kam und das Modell die Lucke aus seinen Trainingsdaten fullte. Das ist der Fehlerfall, gegen den Sie entwerfen. Die Abwehrmassnahmen, die wirklich funktionieren:
- Beschranken Sie die Suche auf kuratierte Quellen. Der Bot zieht nur aus Inhalten, die Sie genehmigt haben, nicht aus dem gesamten ungefilterten Archiv.
- Zitieren Sie die Quelle bei jeder Antwort. Wenn der Leser klicken und nachpruefen kann, uberlebt das Vertrauen gelegentliche Fehler.
- Routing nach Konfidenz. Eine Frage mit geringer Konfidenz sollte keine selbstsichere Antwort erhalten. Sie sollte zu einem Entwurf fur einen Menschen werden oder zu einer Eskalation, mit dem vollstandigen Gesprach angehangen, damit niemand alles neu erklaren muss.
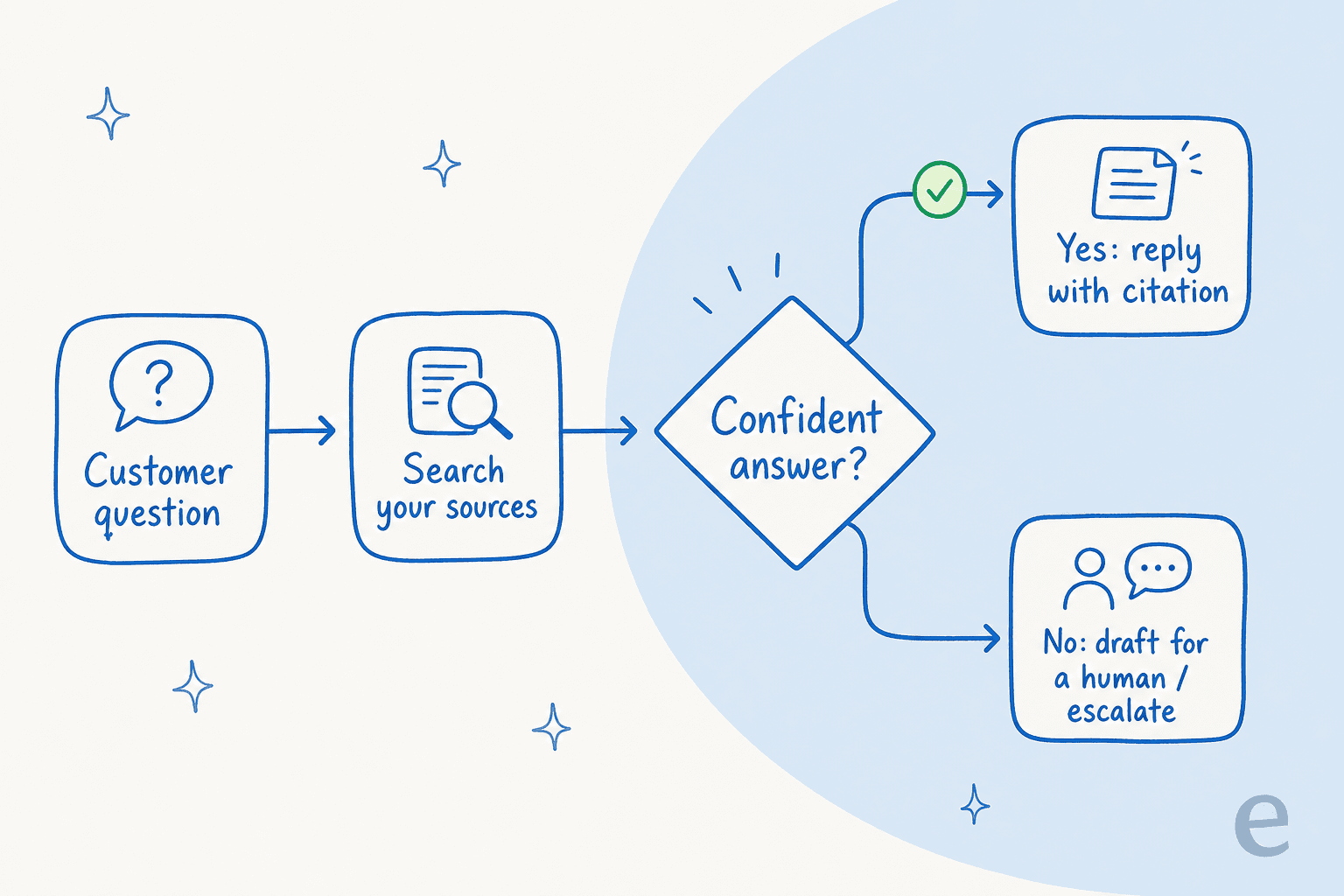
Der letzte Punkt ist das Entscheidende. Ein SaaS-Grunder, der ein Legal-Tech-Produkt betreibt, sagte, der Grund, warum sie KI uberhaupt nutzen konnten, sei, dass sie "genaue Einschrankungen bei der Quellennutzung" festlegen und transparente Zitate erhalten konnten. Ein anderer Kunde auf einer SMS-Plattform fasste die Anforderung treffend zusammen:
"Es antwortet selbstsicher, aber nicht zu selbstsicher, und das Training war super einfach."
Kellen Brown, Textla (G2-Bewertung)
"Selbstsicher, aber nicht zu selbstsicher" ist genau die Linie, die Sie abstimmen. Wenn Ihre engere Auswahl an Tools Ihnen nicht zeigen kann, wie sie den Fall Ich weiss es nicht behandeln, ist das die Demo, um die Sie bitten sollten. Wir haben untersucht, warum Bots das falsch machen, in warum Chatbots falsch antworten.
So wurde ich eine fur ein SaaS-Team aufbauen
Angenommen, Ihre Dokumentation ist in akzeptablem Zustand, hier ist die Reihenfolge, die ich tatsachlich befolgen wurde.
1. Verbinden Sie Ihre Quellen, einschliesslich vergangener Tickets
Beginnen Sie damit, das System auf alles zu richten: Ihr Help Center, Ihre Confluence- und Notion-Bereiche, Google Docs und - ganz wichtig - Ihre gelosten Tickets. Fur SaaS-Support ist das Training auf historischen Tickets meist die grosste Erschliessung, denn dort leben die echten Antworten auf die heiklen Fragen - formuliert, wie Ihr Team sie tatsachlich formuliert. eesel verbindet sich mit uber 100 Quellen und Ihrem bestehenden Helpdesk, also ist das Konfiguration, keine Migration.
Ein D2C-SaaS, mit dem wir arbeiten, wahlte uns speziell, weil sie "CSVs, Zendesk und Google Docs als Quellen" verknupfen konnten, um das Beste aus Dokumentation zu machen, die nach ihren Worten verstreut war. Das ist der normale Ausgangszustand. Der Punkt ist nicht, alles erst in ein Tool zu bringen; es geht darum, dass die KI uber das Durcheinander lesen kann, das Sie bereits haben.
2. Simulieren Sie anhand vergangener Tickets, bevor jemand es sieht
Dies ist der Schritt, den die meisten Tools uberspringen und auf den ich nicht verzichten wurde. Bevor der Agent ein Live-Gesprach beruhrt, fuhren Sie ihn gegen einige Tausend Ihrer historischen Tickets aus und schauen Sie sich die Zahlen an: Welchen Prozentsatz hatte er gelost, wo hatte er sich verwirrt, welche Themen haben keine Abdeckung. Sie konnen die Losungsrate und die Fehlerquote fur Ihren Traffic sehen, bevor ein einziger Kunde damit konfrontiert wird.
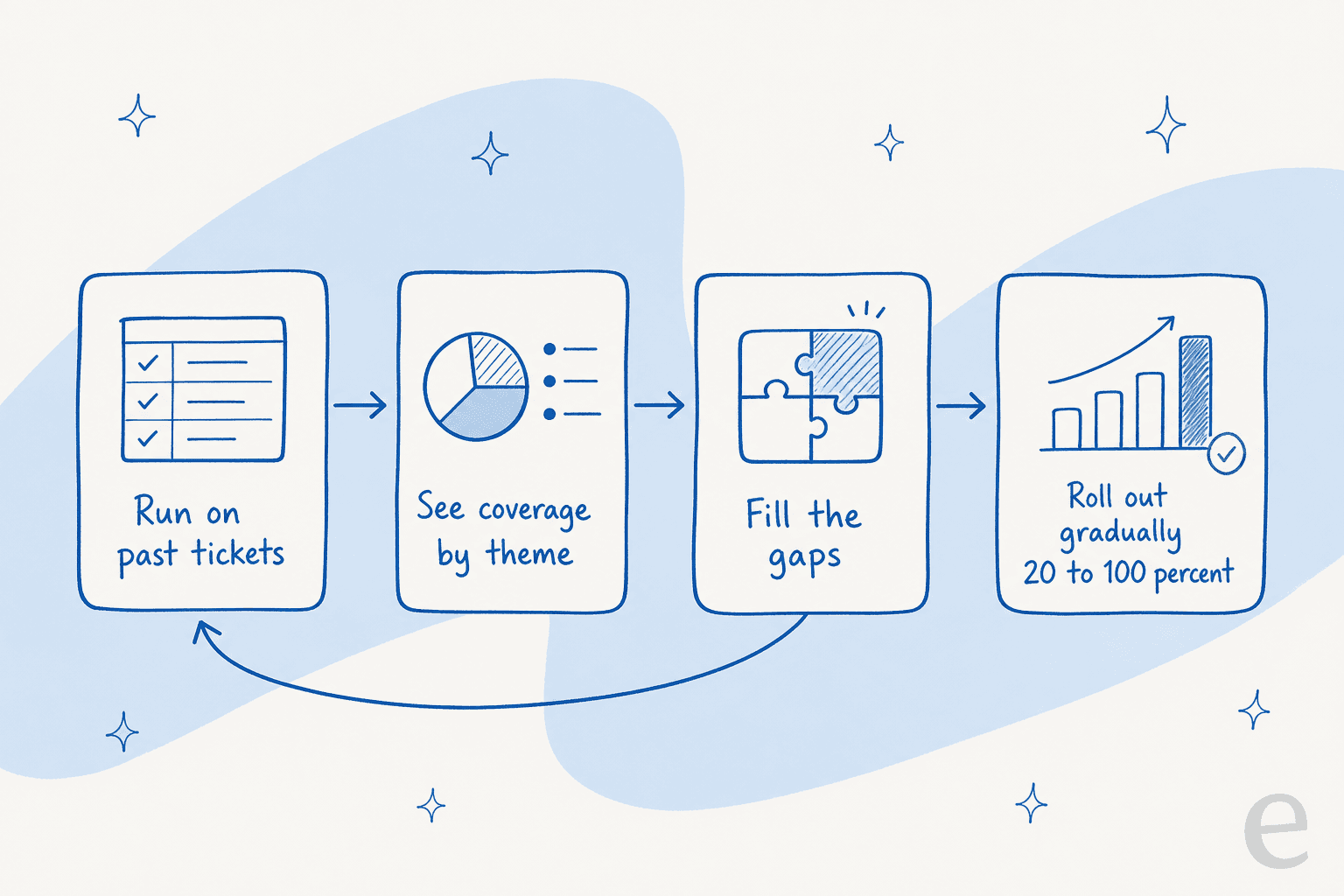
In einer echten Kreuzvalidierung auf Live-Zendesk-Traffic haben wir 93 % Triage-Genauigkeit gemessen und eine 7-prozentige sachliche Fehlerquote erkannt, bevor wir vollstandig autonom gingen - genau die Art von Information, die man in der Simulation und nicht in der Produktion finden mochte. Fullen Sie die Lucken, die die Simulation aufzeigt (die KI kann sogar die fehlenden Artikel fur Sie entwerfen), und fuhren Sie dann erneut aus.
3. Schrittweise einfuhren, nicht alles auf einmal
Schalten Sie nicht alles auf einmal auf autonom. Beginnen Sie damit, dass der Agent Antworten fur die menschliche Uberprufung entwirft oder nur einige wenige risikoarme Ticket-Typen bearbeitet, und erhohen Sie dann die Autonomie, wenn die Zahlen es rechtfertigen. Da eesel pro bearbeitetem Ticket abrechnet, kostet das Routing von nur 200 Ihrer 1.000 monatlichen Tickets auch nur 200 Tickets und keine Plattformgebuhren. Eine schrittweise Einfuhrung ist auch einfach gutes Change Management; Ihr Team vertraut dem System mehr, wenn es beobachtet hat, wie es sich bewahrte.

4. In einfacher Sprache abstimmen und Lucken beobachten
Sobald es live ist, sollten Sie keinen Ingenieur benotigen, um es anzupassen. Den Agenten anzuweisen "Versprich keine Ruckerstattungen, leite diese an einen Menschen weiter" sollte ein Satz sein, keine Konfigurationsdatei. Und das Reporting sollte Ihnen zeigen, welche Fragen schwache Antworten erhalten, damit Sie das zugrundeliegende Dokument korrigieren und den Kreis zwischen Support und Ihrer Wissensdatenbank schliessen konnen.

Selbst bauen oder kaufen?
Besonders fur SaaS-Teams gibt es immer die Option "Wir bauen es einfach auf der Claude- oder OpenAI-API", und manchmal ist das die richtige Entscheidung. Aber der Wartungsaufwand ist der Teil, den die Leute unterschatzen: Suchqualitat, Evaluierungen, Quellensynchronisierung, Konfidenzschwellen und die Helpdesk-Anbindung sind ein Produkt, kein Wochenendprojekt. Ein Engineering-Lead bei einem Krypto-Hardware-Unternehmen mit einer Wissensdatenbank von uber 300 Artikeln beschrieb den Kompromiss gut:
"Wir konnten versuchen, unsere eigene LLM-Anwendung zu schreiben, wollten aber unsere Zeit nicht darin investieren. Wir wollten etwas, das wir nicht warten mussen."
Karel, GENERAL BYTES (Fallstudie)
Wenn Ihr Differenzierungsmerkmal Ihre Support-KI ist, bauen Sie sie. Wenn Ihr Differenzierungsmerkmal Ihr eigentliches Produkt ist, ist der Kauf der Schicht und die Investition Ihrer Ingenieure in die Roadmap meist der bessere Tausch. Wir haben den breiteren Markt in unseren Ubersichten beste KI-Wissensdatenbanktools und Wissensmanagement fur den Support verglichen.
Was es kostet
Preisgestaltung ist der Punkt, an dem SaaS-Teams verbrennen, weil die Abrechnungseinheit wichtiger ist als der Preis selbst. Pro-Benutzer-Tools sehen bei funf Agenten gunstig aus und werden bei funfzig schmerzhaft. Pro-Resolution- und Pro-Conversation-Modelle verhalten sich erneut unterschiedlich. So funktioniert das nutzungsbasierte Modell von eesel.
| Plan / Artikel | Preis | Was Sie erhalten |
|---|---|---|
| Kostenlose Testversion | 0 $ | 50 $ kostenloses Guthaben plus 2 kostenlose Blog-Generierungen, alle Funktionen freigeschaltet, keine Kreditkarte |
| Leichte Aufgabe | Kostenlos | Dashboard-Fragen und einfache Suchen |
| Regulare Aufgabe | 0,40 $ pro Stuck | Ein Ticket oder eine Chat-Sitzung, unabhangig von der Nachrichtenanzahl |
| Schwere Aufgabe | 4,00 $ pro Stuck | Ein Blog-Post-Entwurf pro Durchlauf |
| Pay-as-you-go | ab 0,40 $ / Ticket | Keine Plattformgebuhren, keine Gebuhren pro Benutzer, kein monatliches Minimum |
| Jahresvertrag | 25 % Rabatt | Verpflichtung zu 300 $+/Monat fur das Jahr |
| Enterprise | 1.000 $/Monat + Nutzung | Dedizierter Ingenieur, hohere KB-Limits, SSO, HIPAA, BAA |
Das Wichtige: Sie werden pro bearbeitetem Ticket oder Chat abgerechnet, nicht pro Benutzer und nicht pro Nachricht. Ein 20-Nachrichten-Gesprach zahlt immer noch als eine Aufgabe. So sieht das in der Praxis aus:
| Tickets pro Monat | Monatliche Kosten |
|---|---|
| 100 | 40 $ |
| 500 | 200 $ |
| 1.000 | 400 $ |
| 2.500 | 1.000 $ |
Und Sie werden nie fur Tickets berechnet, die Ihre Menschen bearbeiten, sodass ein teilweiser Rollout eine teilweise Rechnung hat. Wenn Sie die Sparseite der Gleichung uberpruefen mochten, analysiert unsere Analyse zu KI-Einsparungen die Zahlen fur echte Teams.
Wo es noch Grenzen hat
Ich habe Ehrlichkeit versprochen, also: Eine KI-Wissensdatenbank ist nur so gut wie das Wissen. Wenn Ihre Dokumente dunn, widersprachlich oder fur die falsche Zielgruppe geschrieben sind, gilt das auch fur den Bot - und kein Modell-Tuning behebt ein Inhaltsproblem. Sie wird auch nicht Ihr Team ersetzen. Das richtige Gedankenmodell ist ein Copilot und Ersthelfer, wobei die wirklich schwierigen, urteilsintensiven Tickets weiterhin an Menschen gehen. Wenn Sie in einer fruhen Phase sind und Ihr Volumen gering ist, konnte die ehrliche Antwort lauten "noch nicht"; unser KI-Support-Skalierungsleitfaden erlautert, wann es Sinn zu machen beginnt.
Und eine Offenlegung, da wir mit den meisten dieser Helpdesks integrieren: Ich arbeite bei eesel, also gewichten Sie meine Einschatzung entsprechend. Ich habe versucht, Sie auf die Fragen hinzuweisen, die Sie jedem Anbieter stellen sollten, nicht nur die, die uns schmeicheln.
Probieren Sie eesel fur Ihre SaaS-Wissensdatenbank aus
eesel ist eine KI-Schicht, die auf Ihrem bestehenden Helpdesk sitzt - egal ob das Zendesk, Freshdesk, Front, Gorgias oder HubSpot ist. Es liest Ihre verstreuten Dokumente und vergangenen Tickets, antwortet mit Quellenangaben und lasst Sie das Ganze auf historischen Tickets simulieren, bevor Sie live gehen - damit Sie die Losungsrate sehen, bevor Ihre Kunden es tun. Es ist Self-Service, nutzungsbasiert, und Sie konnen kostenlos starten, ohne Verkaufsgesprach.
Der schnellste Weg, es zu beurteilen, ist, es auf Ihr eigenes Wissen zu richten und eine Simulation auf Ihren echten Tickets durchzufuhren. Starten Sie kostenlos und sehen Sie, wie Ihre Losungsrate aussieht, bevor Sie auch nur einen Dollar investieren.
Haufig gestellte Fragen
Was ist eine KI-Wissensdatenbank fur SaaS?
Wie unterscheidet sich eine KI-Wissensdatenbank von einer normalen Help-Center-Suche?
Wie verhindere ich, dass eine KI-Wissensdatenbank halluziniert?
Was kostet eine KI-Wissensdatenbank fur ein SaaS-Unternehmen?
Kann eine KI-Wissensdatenbank aus unseren vergangenen Support-Tickets lernen?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.







