KI-Kundenfeedback-Analyse: So funktioniert sie und wo sie sich lohnt
Alicia Kirana Utomo
Katelin Teen
Zuletzt bearbeitet June 19, 2026

Kurzfassung
KI-Kundenfeedback-Analyse richtet ein Sprachmodell auf jedes Ticket, jede Bewertung, Umfrage und jeden Chat, der gesammelt wird, gruppiert sie in Themen, bewertet Stimmungen und priorisiert, was tatsächlich die Kontakte antreibt. Sie ersetzt die Tabellenkalkulation, die ein Support-Leiter früher von Hand an einer Stichprobe von Tickets ausfüllte – mit dem Unterschied, dass sie alle liest und sich nie langweilt.
Der Grund, warum das wichtig ist, liegt nicht in einem schöneren Dashboard. Es liegt daran, dass die Analyse von Feedback in vollem Umfang Probleme aufdeckt, die man sonst nur als vages „Wir werden immer beschäftigter" spüren würde. Eine wiederkehrende Verwirrung, eine Dokumentation für die falsche Zielgruppe, ein Rückerstattungsprozess, den niemand versteht. Sobald man das Thema sehen kann, kann man das dahinterliegende Problem beheben, und diese Tickets hören auf einzugehen.
Ich baue KI-Agenten bei eesel, wo das Lesen von Support-Gesprächen in diesem Ausmaß die tägliche Arbeit ist (ein einziger Kunde läuft über 100.000 Tickets pro Monat durch eesel). Die Kurzversion: Lassen Sie eine KI Ihre letzten Monate an Tickets clustern, bevor Sie irgendetwas automatisieren, behandeln Sie Stimmung als Trendsignal statt als Urteil über eine einzelne Nachricht, und schließen Sie den Kreislauf immer zurück in Ihre Hilfeinhalte.
Das Nützlichste, was KI einem Kunden je gesagt hat
Ein Support-Manager, mit dem ich zusammenarbeitete, hatte ein Problem, das er nicht benennen konnte. Sein Ticketvolumen stieg langsam an, sein Team fühlte sich überlastet, und sein Help-Center war auf dem Papier umfassend. Als ich eine Analyse über seine historischen Tickets durchführte, war das Muster fast peinlich klar: Seine gesamte Wissensdatenbank war für Administratoren geschrieben, aber fast jedes Ticket stammte von Endbenutzern. Dasselbe Produkt, falsche Zielgruppe, und jede Lücke dazwischen wurde zu einem Support-Kontakt.
Er hatte es nicht gesehen, weil kein Mensch jedes Ticket liest. Man liest die, die vor einem liegen, erinnert sich an die lauten, und die langsame Hintergrunddrift bleibt unsichtbar. Das ist das ganze Argument für KI-Kundenfeedback-Analyse in einer Geschichte: nicht „KI beantwortet Tickets" (das tut sie auch), sondern KI sagt Ihnen, was Ihre Kunden die ganze Zeit versucht haben zu sagen – aggregiert, bevor Sie es selbst lesen mussten.
Ich habe die letzten Jahre damit verbracht, den Teil davon zu entwickeln, der wirklich funktionieren muss, und was ich am stärksten hinterfragen würde, ist die Idee, dass dies eine Reporting-Funktion ist. Es ist eine Feedback-Engine. Richtig gemacht, verändert sie, woran Ihr Team nächste Woche arbeitet.
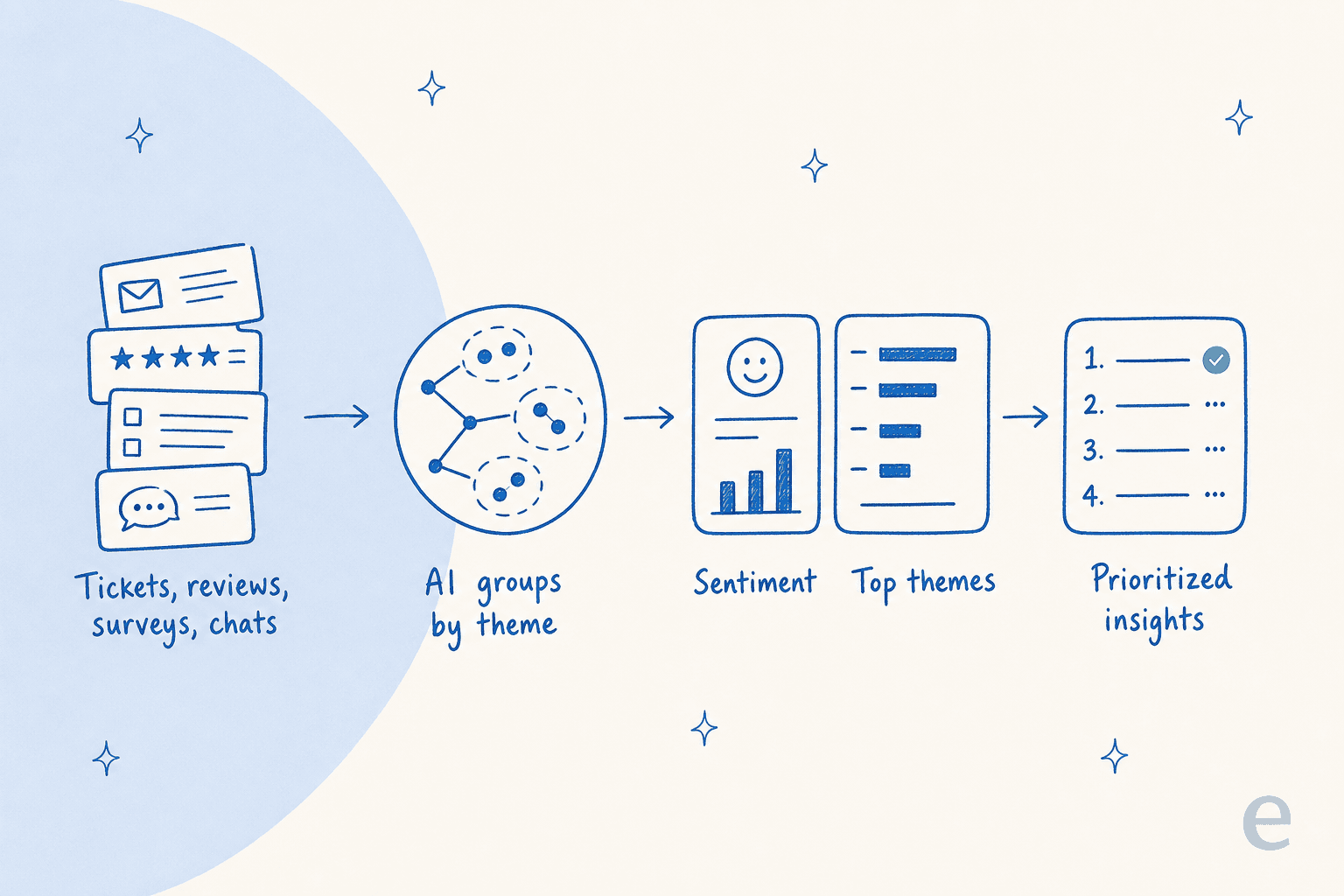
Was KI-Kundenfeedback-Analyse eigentlich ist
Abseits des Marketings sind es drei Aufgaben, die automatisch erledigt werden.
Erstens Themenentdeckung: Das Modell liest den Text jedes Gesprächs und gruppiert diese nach dem, worum es tatsächlich geht, ohne dass Sie die Kategorien vordefinieren müssen. Das ist der Teil, den manuelles Tagging nicht leisten kann, denn eine menschliche Tag-Liste enthält nur die Probleme, an die jemand bereits gedacht hat.
Zweitens Stimmungsbewertung: Jede Nachricht wird auf ihren Ton hin gelesen, sodass Sie beobachten können, wie Frustration im Laufe der Zeit steigt und fällt, anstatt aus den wütenden Nachrichten zu raten, an die Sie sich zufällig erinnern.
Drittens Priorisierung: Themen werden nach Volumen, Trend und Negativität gerankt, sodass das Problem, das Ihre Woche auffrisst, nach oben steigt, statt im langen Schwanz verborgen zu bleiben.
Wer sich mit Kundendienst-KPIs oder KI-Kundendienst-Metriken beschäftigt hat, wird bemerken, dass diese verfolgen, wie man abschneidet (Antwortzeit, Lösungsrate). Feedback-Analyse verfolgt warum Menschen überhaupt schreiben, was die Ebene unterhalb der Metriken ist. Sie hängt eng mit Ticket-Triage zusammen, aber Triage leitet ein Ticket im Moment weiter, während die Analyse über Tausende von Tickets geht.
Wo das Feedback bereits liegt
Sie müssen nichts Neues sammeln. Das Feedback häuft sich bereits an den Stellen an, an denen Kunden mit Ihnen kommunizieren, und die erste wirkliche Aufgabe besteht darin, diese Quellen in einer einzigen Ansicht zu verbinden.
Die üblichen Quellen, ungefähr in der Reihenfolge ihrer Offenheit:
- Helpdesk-Tickets in Zendesk, Freshdesk, Gorgias oder HubSpot. Die reichhaltigste Quelle, weil Menschen ihr tatsächliches Problem beschreiben.
- Live-Chat- und Chatbot-Protokolle, wo die Sprache noch unverblümter als per E-Mail ist.
- Bewertungen auf G2, Capterra, Trustpilot und in den App Stores, die zu den Extremen neigen, aber öffentlich sichtbar sind.
- Umfragekommentare von NPS und CSAT, wo das Freitextfeld weit wichtiger ist als die Bewertung.
- Social- und Community-Nachrichten, die die Leute erwischen, die nie ein Ticket öffnen.
In einer Zendesk-Automatisierungsfallstudie beschrieb ein CTO die Wahl eines Tools, weil es „das Beste aus unserer umfangreichen Dokumentation machen kann, auch wenn sie über CSVs, Zendesk und Google Docs verteilt ist". Das ist derselbe Instinkt: Der Wert liegt nicht in einem einzigen Kanal, sondern darin, sie zusammen zu lesen. Dieselbe verbundene Quellbasis ist das, was eine gute KI-Wissensdatenbank und saubere Ticket-Triage antreibt.
Wie es intern funktioniert
Hier ist der Teil, den ich tatsächlich aufbaue, so erklärt, wie ich es einem Teamkollegen erklären würde.
Ein Gespräch kommt herein. Das Modell liest den vollständigen Text, nicht nur eine Betreffzeile, und erzeugt gleichzeitig mehrere Dinge: eine kurze Zusammenfassung, was der Kunde möchte, eine Vermutung über die Absicht, die Sprache und eine Stimmungseinschätzung. Dann vergleicht es dieses Gespräch mit den anderen und clustert ähnliche zusammen, sodass tausend unterschiedlich formulierte „Wo ist meine Bestellung"-Nachrichten zu einem Thema mit einer Zählung daneben zusammenfallen. Schließlich rankt es diese Themen, sodass eine kleine, aber schnell wachsende Beschwerde ein großes, aber flaches Problem überpriorisieren kann.
Die Modellierungsentscheidungen sind hier wichtig, und wenn Sie tiefer in die Frage einsteigen möchten, welche Modelle für diese Art von Arbeit geeignet sind, gibt es eine Anleitung zu welchem LLM am besten für Support-Anwendungsfälle geeignet ist. Die Kurzversion: Die Lese-und-Cluster-Aufgabe ist gut innerhalb dessen, was aktuelle Modelle zuverlässig leisten – solange Menschen bei den Entscheidungen bleiben, nicht nur bei der Analyse.
Die ehrliche Einschränkung: Stimmung bei einer einzelnen Nachricht ist verrauscht. Sarkasmus, gemischte Botschaften, ein höflicher Kunde, der tatsächlich wütend ist. Bei einem Ticket behandeln Sie es als Hinweis. Über zehntausend Tickets hinweg mittelt sich das Rauschen heraus und der Trend ist vertrauenswürdig. Das ist dasselbe Prinzip hinter zuversichtlichen KI-Helpdesk-Agenten und Agent-Assist-Tools: Handeln Sie bei dem, was das System sicher weiß, leiten Sie den Rest an einen Menschen weiter.
Manuelles Tagging vs. KI-Analyse
Wenn Ihr Team bereits Tickets von Hand taggt, kennen Sie die Schwachstellen: Es wird in einer ruhigen Woche erledigt und in einer geschäftigen übersprungen, die Tag-Liste erstarrt, und wenn jemand den Bericht liest, ist der Moment bereits vergangen. KI macht Tagging nicht besser – sie beseitigt den Grund, warum Sie es überhaupt getan haben.
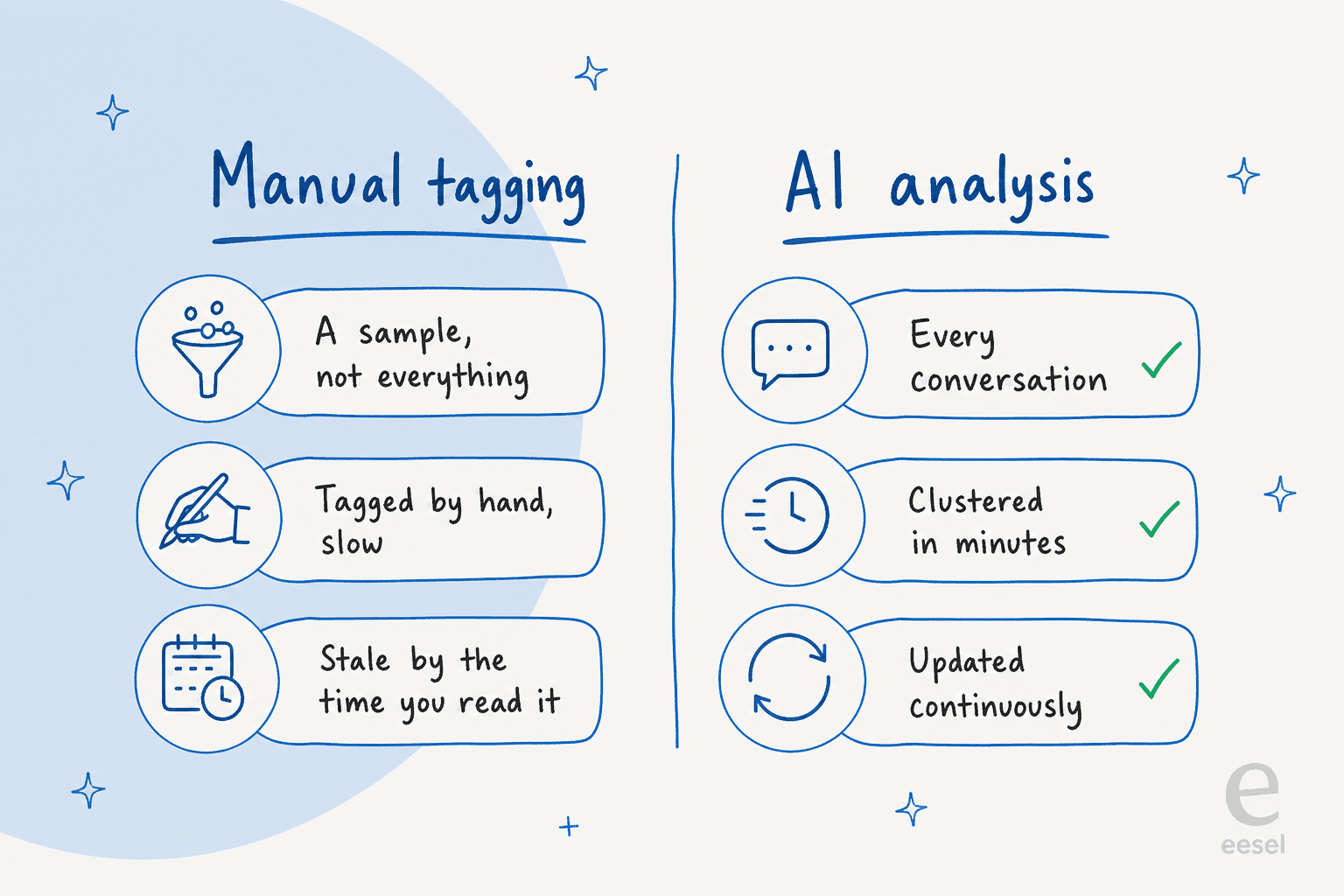
Der praktische Unterschied ist Abdeckung und Aktualität. Manuelles Tagging gibt Ihnen eine Stichprobe, die bereits alt ist; KI gibt Ihnen jedes Gespräch, kontinuierlich aktualisiert. Das ist am wichtigsten genau dann, wenn Sie am wenigsten Kapazitäten haben – dasselbe Argument hinter Kundenservice-Automatisierung im Allgemeinen und den Kosteneinsparungen, die sie freisetzt. Wenn Sie die breitere Abwägung wägen, ist KI vs. Mensch im Support ein nützlicher Rahmen: Das menschliche Urteil rückt vor, um zu entscheiden, was mit einem Thema zu tun ist, anstatt es zu beschriften.
Was Sie tatsächlich davon lernen können
Hier wird es konkret. Einige Dinge, die ich immer wieder bei der Analyse auftauchen sehe:
- Wissenslücken. Ein Thema mit hohem Volumen und negativer Stimmung bedeutet meist einen fehlenden oder verwirrenden Hilfeartikel. Dies ist der direkt umsetzbarste Befund und fließt direkt in die Wissensdatenbank-Verwaltung ein.
- Zielgruppenmismatches, wie die Geschichte von Administratoren vs. Endbenutzern oben, wo die Dokumentation existiert, aber an den falschen Leser gerichtet ist.
- Neue Probleme, eine Beschwerde, die letzte Woche drei Tickets hatte und diese Woche dreißig. Frühzeitiges Erkennen ist der Unterschied zwischen einer stillen Reparatur und einem Brand.
- Produktsignal, die Anfragen und Verwirrungen, die eigentlich keine Support-Probleme sind. An das richtige Team weitergeleitet, ist dies eine der günstigsten Produktforschungen, die Sie je bekommen werden.
- Was sicher zu automatisieren ist. Sobald Sie sehen können, welche Themen ein hohes Volumen und geringes Risiko haben, wissen Sie genau, wo ein KI-Support-Agent zuerst eingesetzt werden sollte.
Wenn Sie konkrete Muster möchten, stützt sich das KI-Agent-Beispiele-Roundup genau auf diese Art der themenebene Analyse. Das tun auch die Zusammenfassungen zu den besten Kundendienst-KI-Plattformen und zu Unternehmen, die KI für Support nutzen.
Den Kreislauf schließen
Analyse, die in einem Dashboard endet, ist ein Hobby. Analyse, die in einem geänderten Hilfeartikel endet, ist ein System. Der Witz ist der Kreislauf: alles lesen, ein wiederkehrendes Thema erkennen, den dahinterliegenden Artikel reparieren oder schreiben, und beobachten, wie diese Tickets nachlassen.
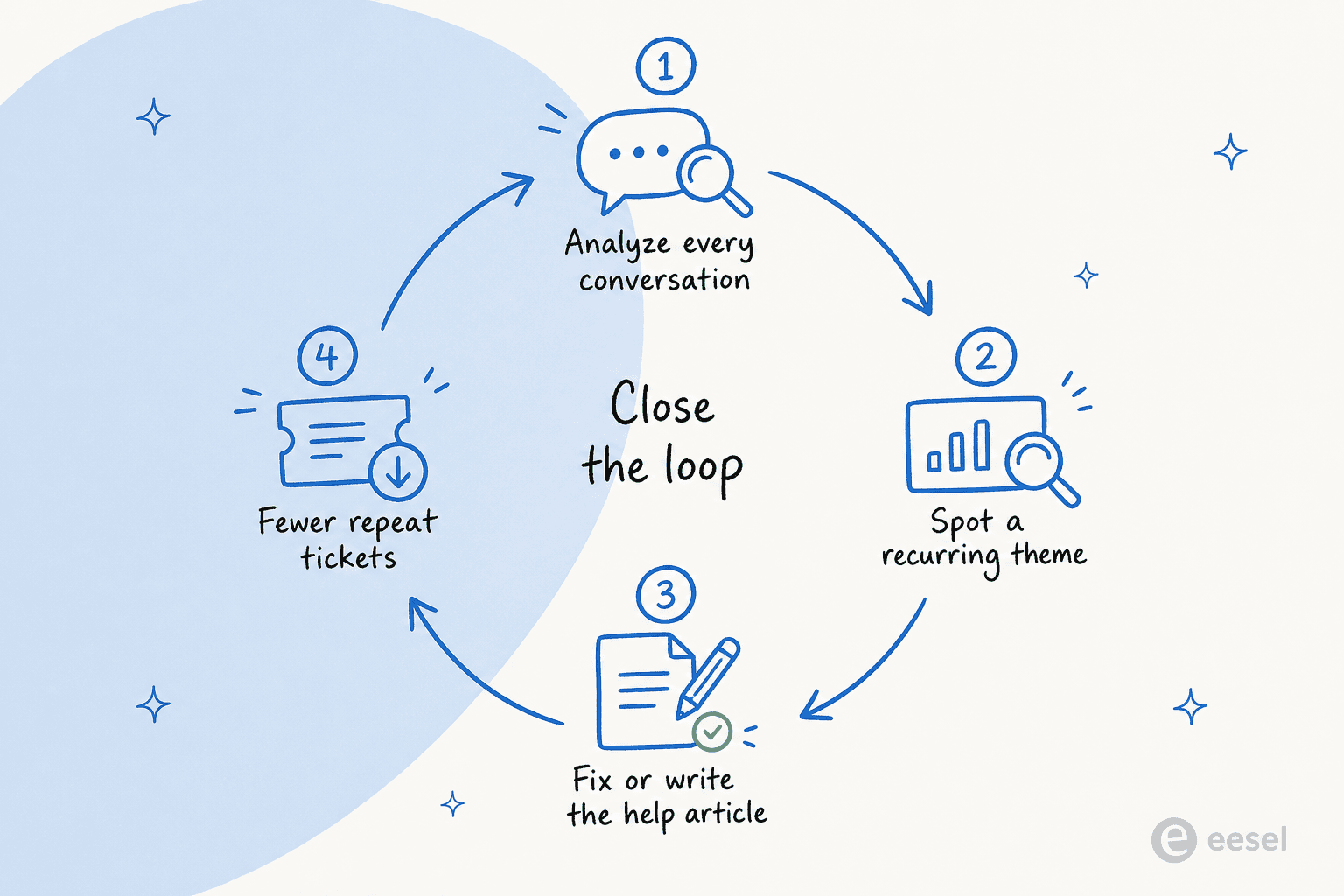
Die besten Setups schließen diesen Kreislauf automatisch: Dasselbe System, das die Lücke erkennt, kann den Artikel zum Ausfüllen entwerfen und ihn dann zur Genehmigung an einen Menschen weiterleiten. So hört eine Support-Wissensdatenbank auf, etwas zu sein, das man „irgendwann wirklich aktualisieren sollte", und wird etwas, das sich jede Woche verbessert. Das ist auch der Grund, warum ich argumentieren würde, dass Feedback-Analyse und Ticket-Deflection dasselbe Projekt sind, von zwei Enden betrachtet: Deflection ist das, was passiert, wenn der Kreislauf eine Weile lang geschlossen wurde.
So starten Sie, ohne alles auf einmal umzusetzen
Der Fehler, den ich am häufigsten sehe, ist, dass Teams versuchen, alles zu instrumentieren, bevor sie irgendetwas betrachtet haben. Tun Sie das nicht. Hier ist die Reihenfolge, in der ich tatsächlich vorgehen würde.
- Führen Sie es zuerst über die Geschichte aus. Richten Sie die Analyse auf Ihre letzten zwei oder drei Monate an Tickets und lassen Sie sie clustern, bevor Sie eine einzige Live-Einstellung ändern. eesels Simulation macht genau das und wiederholt vergangene Tickets, sodass Sie Ihre echte Themenstruktur und Abdeckungslücken im Voraus sehen können.
- Lesen Sie die fünf wichtigsten Themen. Nicht den Bericht, sondern die tatsächlichen Tickets in den Top-Clustern. Hier überprüfen Sie, ob das Modell die Dinge so gruppiert hat, wie ein Mensch es tun würde.
- Beheben Sie eine Sache. Wählen Sie das Thema mit dem höchsten Volumen und der negativsten Stimmung und beheben Sie den dahinterliegenden Hilfeinhalt. Messen Sie, ob dieses Thema schrumpft.
- Automatisieren Sie dann die sicheren. Da Sie jetzt wissen, welche Themen ein hohes Volumen und geringes Risiko haben, ist das der Ort, wo ein KI-Helpdesk-Agent zuerst seinen Nutzen beweist.
Wenn Sie noch entscheiden, ob Sie ein Tool kaufen oder Ihr eigenes aufbauen wollen, deckt der Build vs. Buy-Leitfaden den Kompromiss ehrlich ab. Ein Kunde brachte den Kauffall in seiner Fallstudie direkt auf den Punkt: „Wir könnten versuchen, unsere eigene LLM-Anwendung zu schreiben, aber wir wollten unsere Zeit nicht dafür investieren. Wir wollten etwas, das wir nicht warten müssen."
Einige Fehler, die es zu vermeiden gilt
- Stimmung als Urteil behandeln. Es ist ein Trendsignal. Eskalieren Sie kein einzelnes Ticket, weil das Modell es als „negativ" eingestuft hat.
- Den historischen Durchlauf überspringen. Direkt live zu gehen, ohne Ihre echte Themenkarte zu sehen, bedeutet, blind zu automatisieren. Das ist dieselbe Disziplin, von der gutes KI-Kundenservice-Workflow-Design abhängt.
- Erkenntnisse in einem Bericht sterben lassen. Wenn sich in Ihrem Hilfeinhalt oder Routing nichts ändert, haben Sie ein sehr teures schreibgeschütztes Dashboard gebaut. Schließen Sie den Kreislauf oder lassen Sie es bleiben.
- Die interne Seite vergessen. Dieselbe Analyse funktioniert bei Ihrer internen Wissensdatenbank und Mitarbeiterfragen, nicht nur bei kundenseitigen Tickets.
eesel für Kundenfeedback-Analyse ausprobieren
Wenn Sie den beschriebenen Kreislauf möchten, ohne ihn selbst aufzubauen, ist dies der Teil, an dem ich arbeite. eesel AI verbindet sich mit dem Helpdesk, den Sie bereits betreiben, liest Ihre vergangenen und aktuellen Tickets und clustert sie in Themen und Stimmungen, um dann den Hilfeinhalt zu entwerfen, der die gefundenen Lücken schließt. Das Unterscheidungsmerkmal, auf das ich hinweisen würde, ist der Simulationsmodus: Bevor irgendetwas live geht, wiederholt er Ihre historischen Tickets und zeigt Ihnen die Abdeckung nach Thema, sodass Sie genau sehen, wie Ihr Feedback aussieht und was sicher automatisiert werden kann, bevor Sie sich festlegen.

Es ist nutzungsbasiert mit transparenter Preisgestaltung und einer kostenlosen Testversion, sodass Sie es über Ihre eigenen Tickets laufen lassen und die Themen selbst beurteilen können. Probieren Sie eesel aus und sehen Sie, was Ihre Kunden Ihnen die ganze Zeit gesagt haben.
Häufig gestellte Fragen
Was ist KI-Kundenfeedback-Analyse?
Wie unterscheidet sich KI-Feedback-Analyse vom manuellen Tagging?
Welche Quellen kann KI für das Kundenfeedback analysieren?
Kann der KI-Kundenstimmungsanalyse wirklich vertraut werden?
Wie reduziert Feedback-Analyse das Ticketvolumen?
Benötige ich ein separates Analyse-Tool oder kann mein Helpdesk das leisten?
Wie starte ich mit KI-Kundenfeedback-Analyse?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.