Qu'est-ce que DiffusionGemma ?
DiffusionGemma est un modèle de la famille ouverte Gemma de Google qui génère du texte avec un processus de diffusion plutôt qu'avec l'approche autorégressive derrière presque tous les chatbots que vous avez utilisés. Il a été publié par Google DeepMind le 10 juin 2026 comme un modèle expérimental à poids ouverts sous Apache 2.0, la fiche officielle du modèle se trouvant sur le site de DeepMind.
Voici la fiche technique principale :
| Attribut | DiffusionGemma |
|---|---|
| Publié | 10 juin 2026 |
| Licence | Apache 2.0 (poids ouverts) |
| Architecture | Construit sur Gemma 4, Mixture-of-Experts |
| Taille | 25,2 Md de paramètres totaux, ~3,8 Md actifs par étape (« 26B A4B ») |
| Génération | Débruite des blocs de 256 jetons en parallèle |
| Entrée / sortie | Multimodal en entrée (texte/image/vidéo), texte en sortie |
| Vitesse | >1 000 jetons/s sur un H100, jusqu'à 4x plus vite que des modèles AR comparables |
| Matériel | ~52 Go de VRAM en BF16, ~28 Go en INT8, exécutable à partir de ~18 Go quantifié |
La plupart de ces chiffres proviennent de la couverture du lancement par MarkTechPost et du guide de déploiement de Spheron, le détail sur les blocs parallèles venant de l'article de Digg. L'étiquette « 26B A4B » est l'abréviation de Google : un modèle Mixture-of-Experts de classe 26B qui n'active qu'environ 3,8 Md de paramètres à chaque étape donnée, ce qui explique en partie pourquoi il est peu coûteux à exécuter rapidement.
La raison pour laquelle c'est important, ce ne sont pas les scores des benchmarks. C'est qu'un laboratoire de pointe a livré un véritable modèle de langage à diffusion, téléchargeable. Pendant des années, la diffusion a été la méthode dominante pour les images et la vidéo (pensez à Midjourney, Sora) tandis que le texte est resté obstinément autorégressif, la même famille qui anime des assistants du quotidien comme ChatGPT et Claude. DiffusionGemma est l'un des signaux les plus clairs à ce jour que le côté texte rattrape son retard.
Comment DiffusionGemma fonctionne réellement
Les grands modèles de langage standard sont autorégressifs. Comme le formule Inception Labs, ils « génèrent du texte de gauche à droite, un jeton à la fois, où un jeton ne peut pas être généré tant que tout le texte qui le précède n'a pas été généré. » Chaque mot attend celui d'avant, donc une longue réponse signifie une longue séquence de passes avant à travers des milliards de paramètres. C'est de là que vient la latence.
La diffusion renverse cela. L'approche dominante pour le texte est la diffusion masquée : vous partez d'un bloc de jetons tous masqués, et un transformeur prédit les versions démasquées, puis affine sa supposition sur une poignée de passes. Google le décrit comme générant du texte « de la manière dont fonctionne la diffusion d'images : plutôt que de prédire le texte directement, le modèle apprend à générer des sorties en affinant le bruit étape par étape, de sorte qu'il peut itérer rapidement sur une solution et corriger les erreurs pendant la génération. »
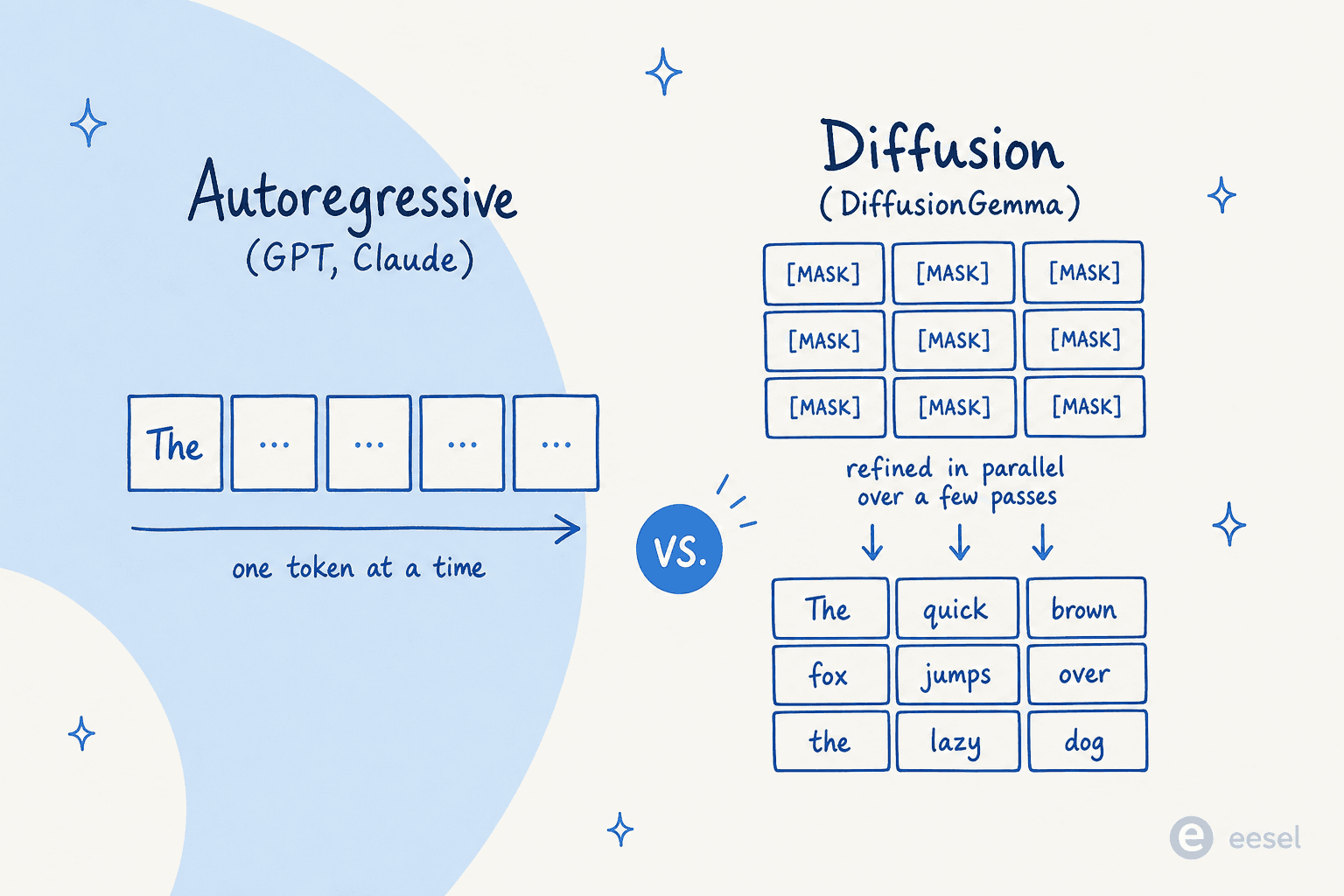
Une précision, parce que le nom fait trébucher les gens. La diffusion ne remplace pas ici le transformeur ; elle remplace l'autorégression. Comme l'a expliqué un commentaire très cité de Hacker News de l'utilisateur synapsomorphy :
« La diffusion n'est pas à la place des transformeurs, elle est à la place de l'autorégression. Les précédents LLM de diffusion comme Mercury utilisent toujours un transformeur, mais il n'y a pas de masquage causal, donc l'ensemble de l'entrée est traité d'un coup et la génération de la sortie est évidemment différente. »
Les avantages pratiques de la génération en parallèle sont au nombre de trois : la vitesse brute, la capacité à corriger les erreurs en cours de génération et le remplissage naturel (parce que le modèle peut voir le contexte des deux côtés d'un trou, il excelle à éditer le milieu d'une séquence, pas seulement à ajouter à la fin). Andrej Karpathy a signalé la nouveauté tôt, notant que la diffusion « ne va pas de gauche à droite, mais tout d'un coup. Vous partez du bruit et le débruitez progressivement en un flux de jetons. »
DiffusionGemma vs Gemini Diffusion : ne les confondez pas
Celui-ci piège presque tout le monde, parce que Google a livré deux choses de diffusion de texte en environ un an et leur a donné des noms quasi identiques.
Gemini Diffusion a été présenté à la Google I/O en mai 2025 comme un modèle expérimental, accessible uniquement sur liste d'attente, fonctionnant sur l'infrastructure de Google. Vous ne pouvez pas le télécharger. DiffusionGemma, en revanche, est celui à poids ouverts que vous pouvez récupérer et exécuter vous-même.
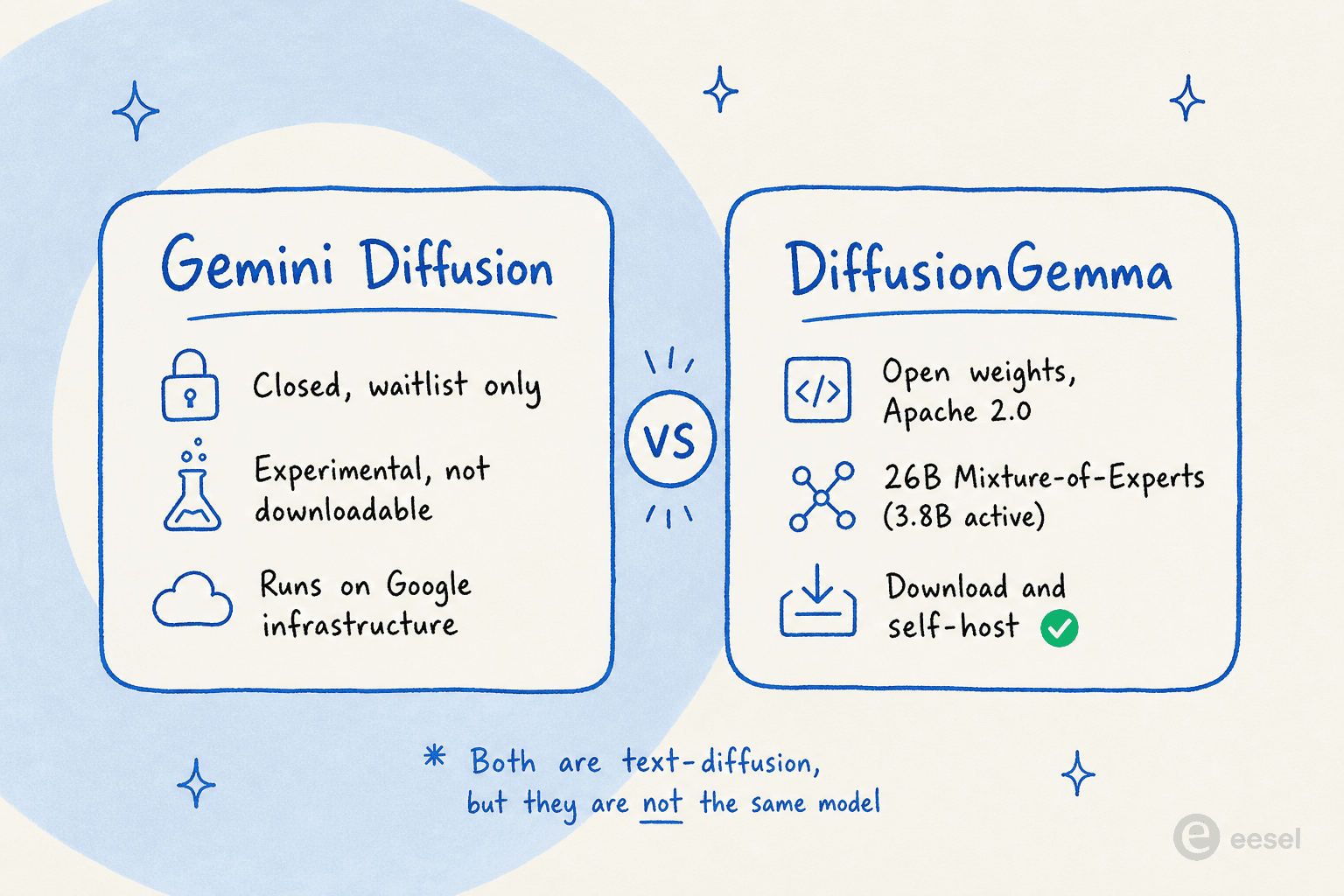
Le fait que Google ait livré à la fois un modèle fermé expérimental et une version à poids ouverts est en soi l'histoire : c'est le signal le plus fort que les modèles de langage à diffusion ont dépassé le stade de la curiosité de recherche. Quand un laboratoire de pointe ouvre le code d'une architecture, il parie que d'autres construiront dessus.
Les chiffres de vitesse (et pourquoi ils sont à peu près réels)
La vitesse est tout l'argumentaire, alors regardons les chiffres honnêtement. Les >1 000 jetons/s de DiffusionGemma se situent aux côtés de ses cousins de diffusion, et l'écart avec les modèles autorégressifs est important :
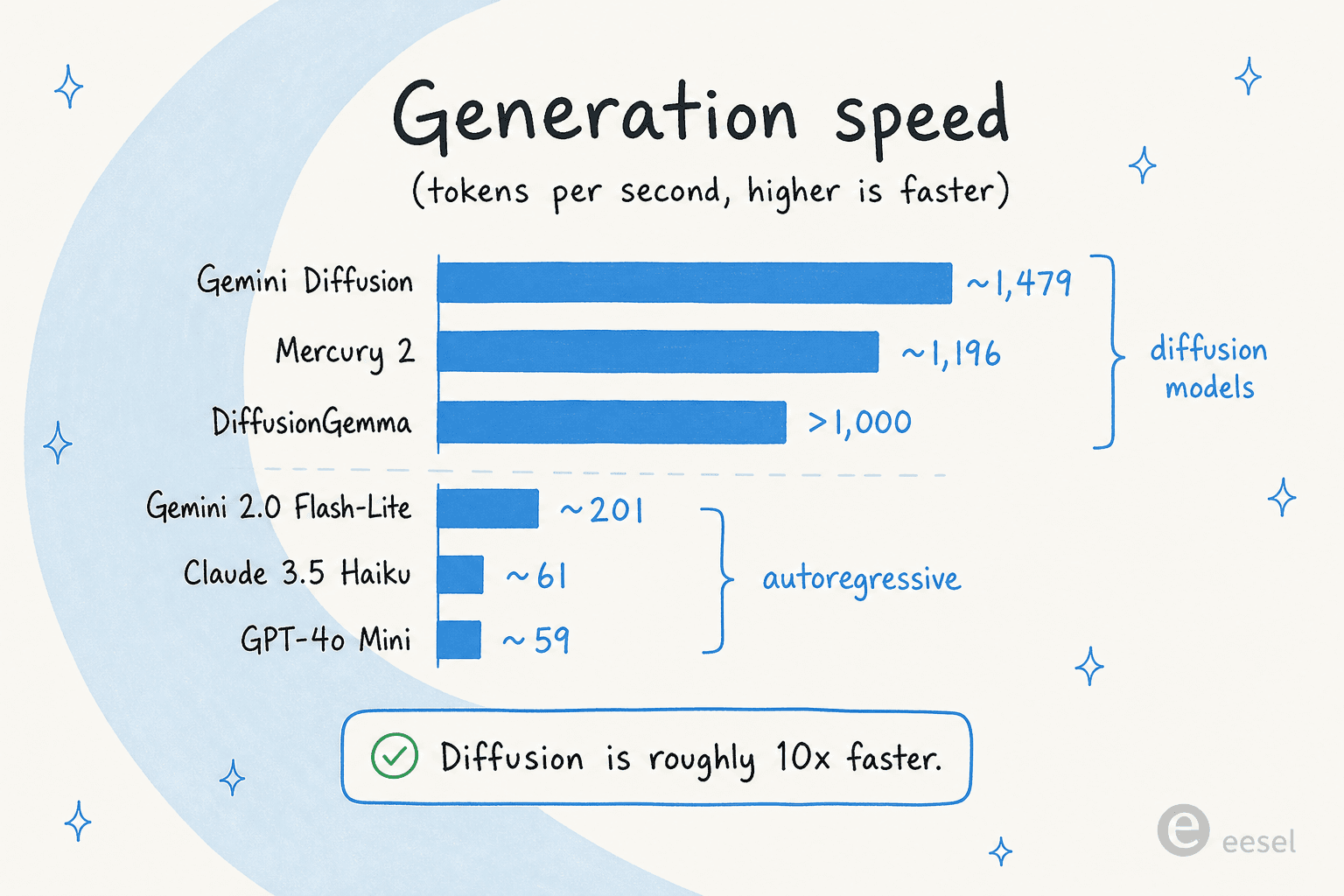
Quelques réserves gardent cela les pieds sur terre. Presque tous les chiffres sont mesurés sur un NVIDIA H100, et la plupart sont des affirmations de fournisseurs. Le seul étalon indépendant dans ce domaine, Artificial Analysis, a corroboré la vitesse des modèles Mercury d'Inception mais pas encore leur qualité. Pour DiffusionGemma précisément, les chiffres de >1 000 jetons/s et jusqu'à 4x proviennent de Google et d'articles de partenaires comme Yellow.com, pas encore de benchmarks tiers.
À titre de comparaison, les modèles autorégressifs que les gens utilisent réellement en production se situent bien plus bas en débit : selon les propres benchmarks d'Inception, GPT-4o Mini tourne autour de 59 jetons/s et Claude 3.5 Haiku autour de 61, Gemini 2.0 Flash-Lite optimisé pour la vitesse étant à environ 201. Donc le cadrage « environ 10x plus rapide » pour la diffusion tient, au moins sur le papier.
Là où il brille, et là où il ne brille pas
La lecture honnête est que la diffusion est réellement plus rapide sur le travail limité par le débit et parallélisable, mais que l'autorégression l'emporte encore pour beaucoup de ce dont les applications de production ont réellement besoin. La meilleure source unique ici est l'analyse de l'ingénieur Sean Goedecke sur les limites de la diffusion, et elle se transpose proprement en une décision.
Optez pour la diffusion quand la tâche est à fort volume et parallélisable : résumé en masse, classification, reformatage, traduction, ou boucles d'agent à faible latence où une réponse rapide par étape se cumule. La génération de code est particulièrement bien adaptée car la nature de remplissage de la diffusion correspond à la façon dont vous éditez du code, en générant le début et la fin d'un bloc dans la même passe.
Restez sur l'autorégression quand vous avez besoin de sorties courtes (la diffusion exécute toutes ses passes de débruitage quoi qu'il arrive, donc elle fait du travail supplémentaire pour produire une réponse de six jetons), de longues fenêtres de contexte (la diffusion ne peut pas réutiliser le cache clé-valeur aussi facilement, donc elle recalcule l'attention sur tout le contexte à chaque passe), ou d'un raisonnement en chaîne de pensée difficile. Sur ce dernier point, Goedecke avance l'argument le plus tranchant :
« Une raison d'être globalement sceptique quant au potentiel des modèles de diffusion à raisonner est précisément qu'ils font beaucoup moins de travail par jeton que les modèles autorégressifs. C'est tout simplement moins d'espace pour que le modèle "réfléchisse". »
Sean Goedecke, "Strengths and limitations of diffusion language models"
DiffusionGemma lui-même confirme le compromis : il reste en dessous du Gemma 4 standard sur chaque benchmark publié. Un ingénieur écrivant sur les stacks d'agents de production a formulé de manière mémorable le reproche historique fait à la diffusion, à savoir que les premiers modèles « étaient rapides à la manière dont une horloge cassée est rapide, peu importe la vitesse à laquelle vous obtenez la mauvaise réponse » (dev.to). L'écart de qualité se resserre à petite et moyenne échelle, mais il reste visible à la pointe.
Le mouvement pragmatique auquel la plupart des équipes aboutiront n'est pas le remplacement, mais le routage : envoyez les étapes simples et à haute fréquence (recherches, mise en forme, classification) à un modèle de diffusion rapide et réservez un modèle autorégressif de pointe pour le raisonnement approfondi. C'est la même logique que choisir le bon outil pour une tâche plutôt qu'un seul helpdesk IA faisant tout.
Ce que DiffusionGemma signifie pour les équipes de support client
La diffusion semble parfaite pour le support. Le chat en direct et les agents de support IA sont exactement le cas à faible latence, orienté utilisateur, où l'écart entre une réponse d'une seconde et une réponse de plusieurs secondes décide si l'outil semble en temps réel ou comme « un service qu'on attend ». Pour les copilotes orientés client, une réponse en moins d'une seconde peut vraiment faire la différence entre l'adoption et l'abandon.
Mais voici ce que nous contesterions : pour une équipe de support, l'architecture du modèle compte bien moins que l'orchestration qui l'entoure. Deux réserves s'appliquent directement à ce cas d'usage.
D'abord, les vraies réponses de support s'appuient sur un long contexte et la récupération, et le long contexte est précisément le point faible de la diffusion. Une bonne réponse n'est pas une génération à partir de zéro ; c'est une réponse fondée sur votre base de connaissances, votre historique de tickets et vos documents de politique. La récupération et l'ancrage comptent davantage pour la qualité de la réponse que de savoir si les jetons finaux sont sortis de gauche à droite ou en parallèle, ce qui est au cœur de la question RAG vs LLM.
Ensuite, la qualité et la fiabilité l'emportent sur la vitesse brute pour tout ce qui est orienté client. Un modèle plus rapide branché sur des connaissances obsolètes ou de faibles règles d'escalade ne fait que produire de mauvaises réponses plus vite. C'est le problème de l'horloge cassée, appliqué au support.

Donc, si vous êtes un responsable du support qui lit au sujet de DiffusionGemma et qui se demande s'il vous le faut : probablement pas directement. Ce que vous voulez, c'est une plateforme qui réussit l'ancrage, les garde-fous et les intégrations de helpdesk, et qui bénéficie ensuite discrètement de quel que soit le modèle le plus rapide et le meilleur sous le capot. La latence est un levier parmi d'autres, et c'est rarement celui qui freine votre taux de résolution. La plus grande question est généralement le coût par ticket par rapport à un humain qui le traite.
Essayez eesel
eesel AI vend des coéquipiers IA qui vivent à l'intérieur de votre helpdesk existant (Zendesk, Freshdesk, HubSpot, Gorgias, Front) et gèrent le support de niveau 1 en apprenant de vos tickets passés et de vos documents d'aide dès le premier jour. La raison pour laquelle c'est pertinent ici : eesel est délibérément agnostique vis-à-vis du modèle, donc le débat d'architecture ci-dessus est un débat que vous n'avez pas à gagner. Ce qu'il réussit, c'est l'orchestration qui fait réellement bouger les chiffres, comme le routage basé sur la confiance qui rédige au lieu d'envoyer lorsqu'il n'est pas sûr, et un mode de simulation qui s'exécute sur vos tickets passés pour que vous puissiez voir la couverture avant de passer en production. Gridwise a vu 73 % des demandes de niveau 1 résolues dès le premier mois, et la tarification est à l'usage à partir de 0,40 $ par ticket résolu sans frais par siège, donc vous payez pour des résultats plutôt que pour des heures de GPU.
Foire aux questions
Qu'est-ce que DiffusionGemma en termes simples ?
DiffusionGemma est-il identique à Gemini Diffusion ?
À quelle vitesse DiffusionGemma fonctionne-t-il par rapport à un LLM normal ?
Puis-je utiliser DiffusionGemma pour le support client ?
Combien coûte l'exécution de DiffusionGemma ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








