
Qu'est-ce que Gemma 4 exactement ?
Je construis les agents IA chez eesel, et j'ai passé ces dernières années à observer comment les modèles ouverts sont passés de « amusants à tester » à « assez bons pour être mis devant un client payant ». Nous faisons tourner des agents sur des files de support en direct tous les jours ; un client, Smava, traite plus de 100 000 tickets en allemand par mois via un agent automatisé. Donc à chaque fois que Google sort un nouveau modèle ouvert, je le lis avec une seule question : pourrait-on vraiment lui faire confiance pour répondre à un client sans surveillance humaine ?
Gemma 4 est la réponse la plus intéressante à cette question que j'aie vue de la part d'un modèle ouvert.
En termes simples, Gemma est la gamme de modèles ouverts de Google DeepMind — les cousins plus petits et téléchargeables des modèles Gemini fermés. Gemma 4 est « construit à partir de la même recherche et technologie de pointe que Gemini 3 pour maximiser l'intelligence par paramètre », selon le post de lancement de Google. Le mot clé est open-weight : Google publie les fichiers du modèle, vous pouvez donc les faire tourner sur votre propre ordinateur portable, serveur ou téléphone sans qu'aucun appel API ne sorte de votre réseau.
Il est aussi multimodal. Chaque modèle gère les entrées texte et image, les plus petits ajoutent l'audio natif, et la fiche modèle indique un cutoff d'entraînement en janvier 2025 avec support de plus de 140 langues. Si vous avez lu notre article sur RAG versus LLMs, Gemma 4 est la moitié « LLM » de cette image — le moteur de raisonnement que vous pointeriez vers vos propres connaissances.
Les cinq tailles, et laquelle vous convient
Gemma 4 n'est pas un modèle, ce sont cinq, triés selon l'endroit où ils sont censés tourner. C'est la partie qui vaut la peine d'être comprise avant tout le reste, car choisir la mauvaise taille est l'erreur la plus courante que je vois commettre.
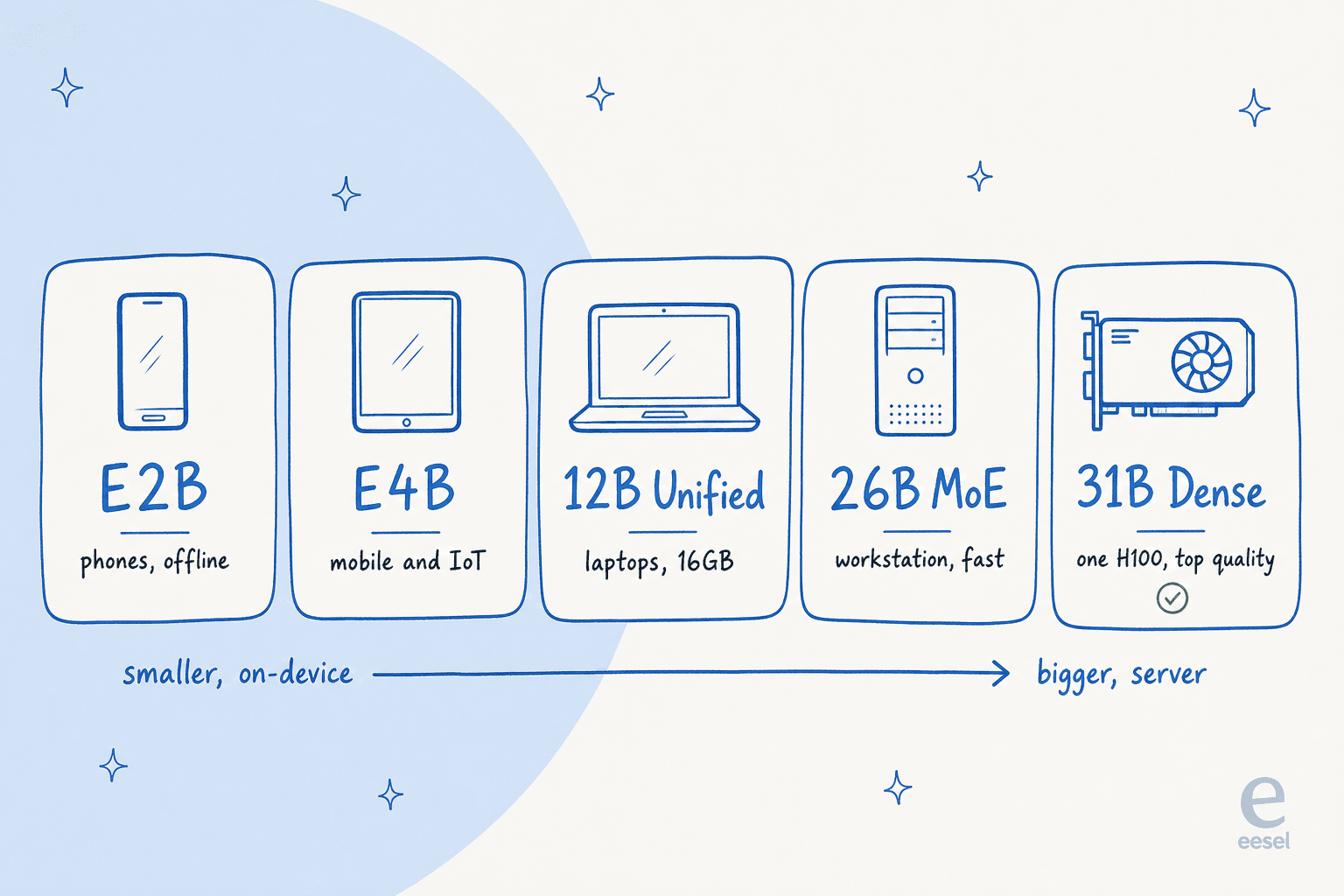
Voici la gamme complète, avec les spécifications tirées directement de la fiche modèle :
| Modèle | Paramètres effectifs | Contexte | Modalités | Fonctionne sur |
|---|---|---|---|---|
| E2B | 2,3B (5,1B avec embeddings) | 128K | Texte, image, audio | Téléphones, Raspberry Pi, edge |
| E4B | 4,5B (8B avec embeddings) | 128K | Texte, image, audio | Téléphones haut de gamme, IoT |
| 12B Unified | 11,95B | 256K | Texte, image, audio | Ordinateurs portables (~16 Go) |
| 26B A4B (MoE) | 25,2B total, 3,8B actifs | 256K | Texte, image | Station de travail, faible latence |
| 31B Dense | 30,7B | 256K | Texte, image | Un H100 de 80 Go, qualité maximale |
Le « E » dans E2B et E4B signifie paramètres effectifs. Ces modèles utilisent une astuce appelée Per-Layer Embeddings pour maintenir leur empreinte mémoire réduite, ce qui permet à un téléphone de les faire tourner hors ligne avec une latence quasi nulle. Google les a construits avec l'équipe Pixel ainsi que Qualcomm et MediaTek, donc ils sont optimisés pour du vrai silicium mobile, pas juste une démo.
Le 12B Unified est le petit nouveau, ajouté le 3 juin 2026. C'est l'option « prête pour laptop » et le premier modèle de taille moyenne de Google avec entrée audio native. Le 31B Dense est le vaisseau amiral de la qualité brute et la base depuis laquelle tout le monde fait du fine-tuning.
Celui du milieu, le 26B, est le plus ingénieux du groupe. Il mérite sa propre section.
Comment un modèle de 26B rivalise avec des modèles 20 fois plus grands
Le 26B est un modèle Mixture-of-Experts (MoE), et le comprendre est la meilleure façon de saisir pourquoi Gemma 4 est important.
Un modèle « dense » classique active tous les paramètres pour chaque token qu'il traite. Un modèle MoE divise ses paramètres en de nombreux petits « experts » et, pour chaque token, n'active que la poignée dont il a vraiment besoin. Voici sa structure :
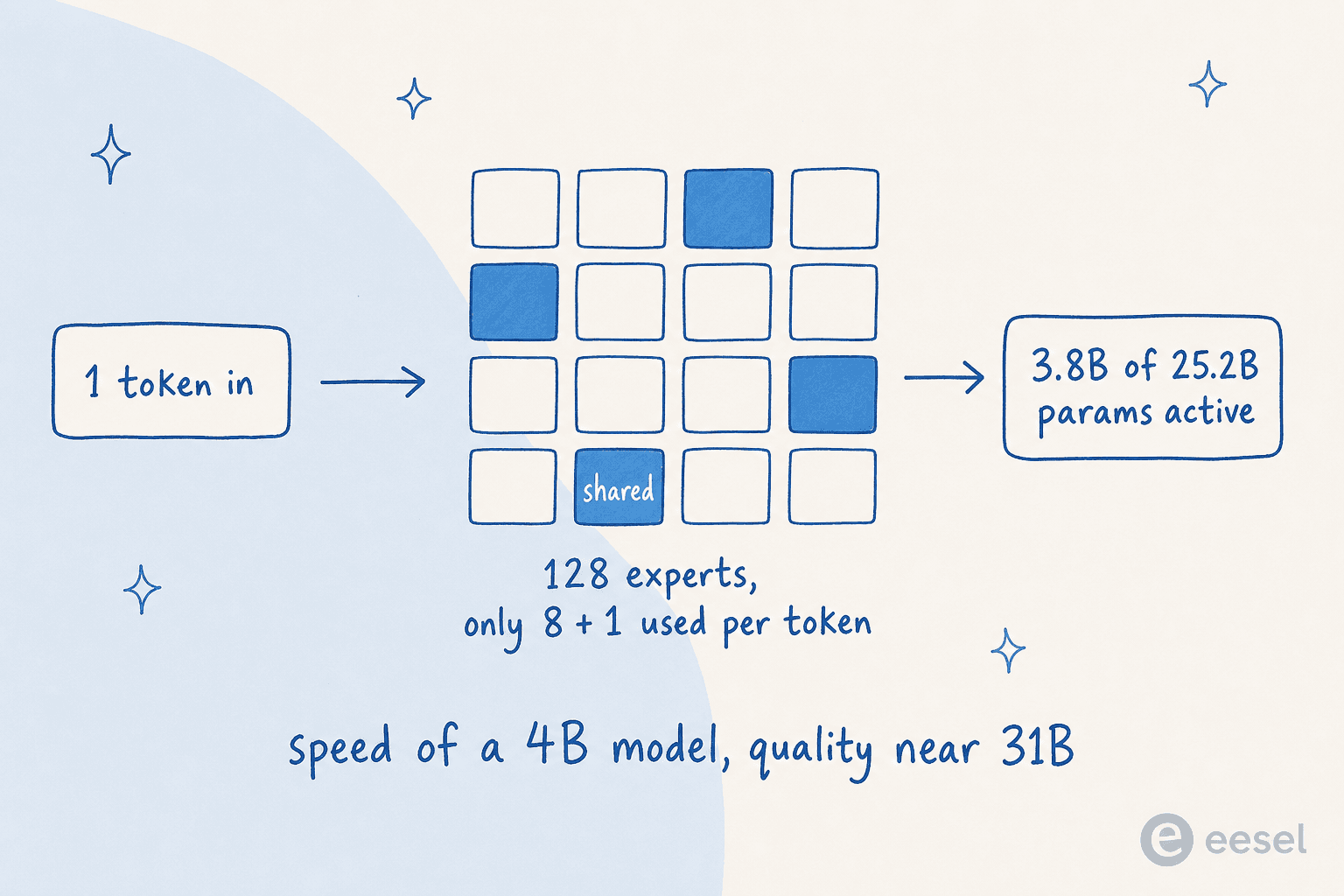
Le 26B de Gemma 4 a 25,2B de paramètres totaux mais seulement 3,8B actifs par token, en passant par 8 de ses 128 experts plus un expert partagé. Le résultat pratique : il tourne environ aussi vite qu'un modèle dense de 4B tout en répondant avec une qualité plus proche du 31B. (Une mise en garde à garder en tête : les 25,2B paramètres doivent toujours être chargés en mémoire pour le routage, donc MoE vous économise du calcul, pas de la RAM.)
Pourquoi est-ce important ? Parce que cela brise l'ancienne hypothèse selon laquelle « plus intelligent » signifie « plus grand et plus lent ». Regardez où les modèles Gemma 4 de taille moyenne se positionnent dans le propre graphique de Google sur les performances versus la taille :
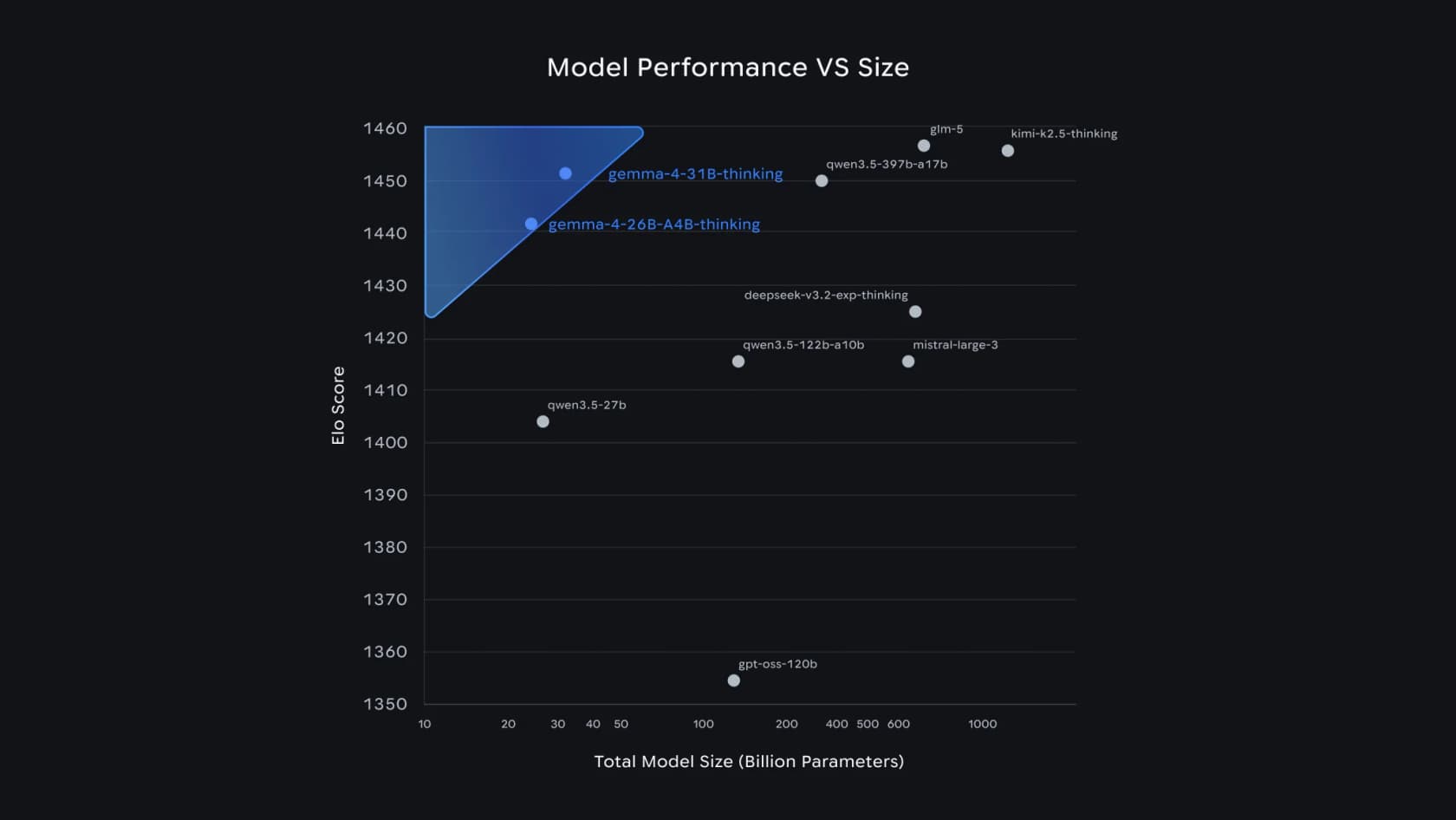
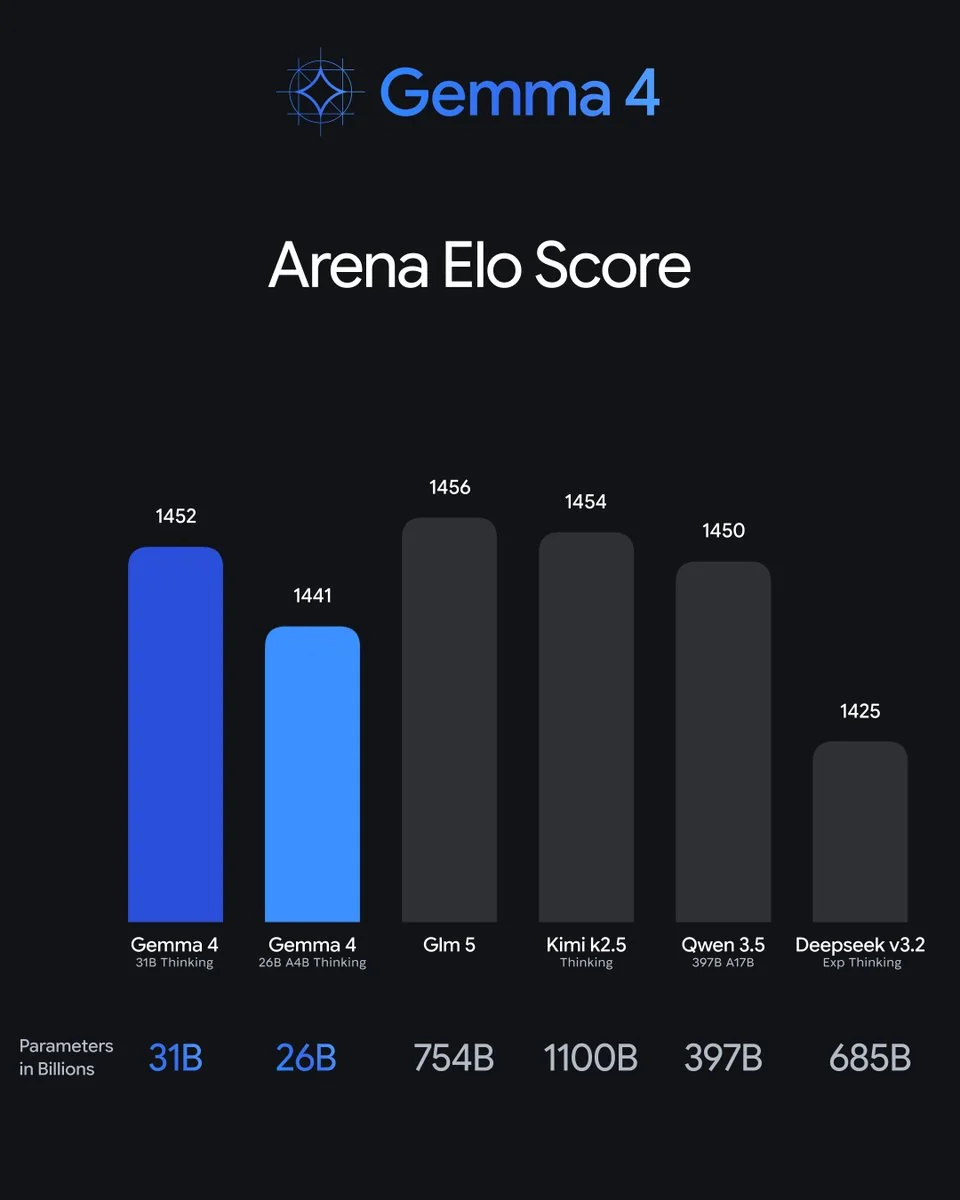
Le 31B est le 3e modèle ouvert du classement texte d'Arena AI, et le 26B MoE prend la 6e place, ce qui permet à Google d'affirmer que Gemma 4 « surpasse des modèles 20 fois plus grands ». Pour une équipe de support, la leçon n'est pas le rang dans le classement, c'est que cette qualité tient sur du matériel que vous possédez.
Ce que « poids ouverts » signifie vraiment (et pourquoi la licence a changé)
On utilise « ouvert » de façon imprécise, donc soyons précis, car c'est là que Gemma 4 a fait son plus grand pas.
Les modèles Gemma précédents étaient distribués sous des « Conditions d'utilisation Gemma » personnalisées. Gemma 4 est passé à une licence standard Apache 2.0. Dans les termes de Google, elle est « commercialement permissive » et accorde « un contrôle total sur vos données, votre infrastructure et vos modèles ». Le PDG de Hugging Face, Clément Delangue, a qualifié ce changement de « grande étape ».
Voici la différence que cette licence fait en pratique :
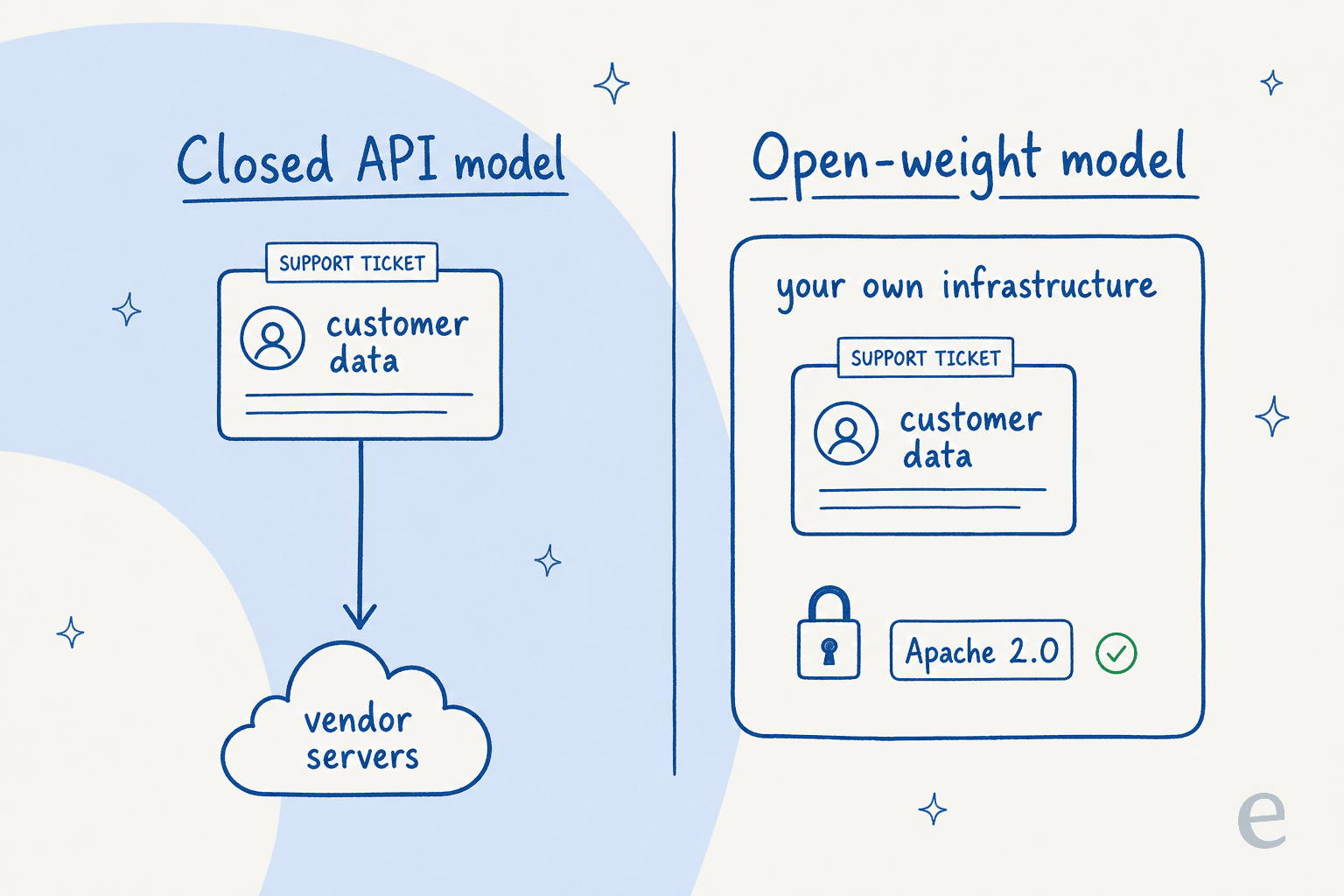
Avec un modèle d'API fermé, chaque message client que vous traitez est envoyé aux serveurs du fournisseur. Avec un modèle à poids ouverts sous Apache 2.0, vous pouvez tout faire tourner dans votre propre infrastructure — sur site ou dans votre propre cloud — et les données ne sortent jamais. Pour toute personne dans un secteur réglementé, ce contrôle de résidence des données est la seule raison de s'intéresser aux modèles ouverts. C'est la même raison pour laquelle les gens se tournent vers les systèmes de ticketing open source et les plateformes de chatbot open source.
Pour le passage à l'échelle, Google propose Gemma 4 sur Vertex AI, Cloud Run et GKE, et il fonctionne dès le premier jour avec les outils que les self-hosters utilisent déjà, comme Ollama, llama.cpp, vLLM et LM Studio.
Les benchmarks, et où Gemma 4 brille vraiment
Place aux chiffres. Google publie un tableau de benchmarks complet comparant les modèles Gemma 4 instruction-tuned face au Gemma 3 27B de la génération précédente :
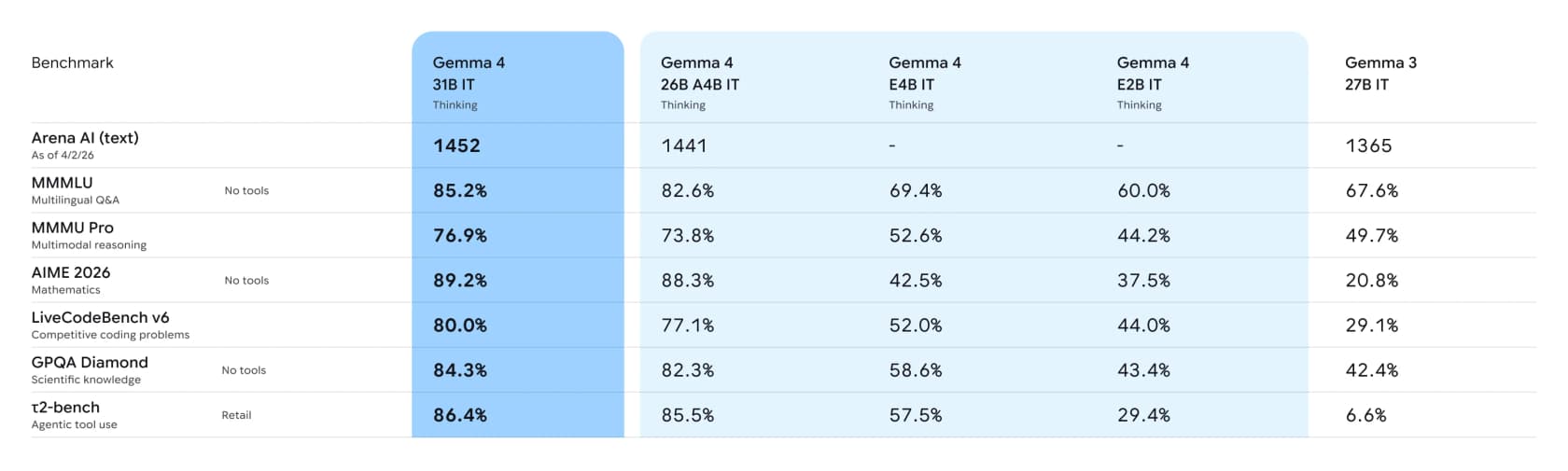
La ligne que je soulignerais est l'utilisation agentique d'outils. Sur le benchmark τ2-bench retail, qui teste si un modèle peut réellement appeler des outils pour accomplir une tâche, le modèle 31B obtient 86,4% contre 6,6% pour Gemma 3. Ce n'est pas une amélioration incrémentale, c'est un saut générationnel, et c'est la capacité qui transforme un chatbot en quelque chose qui peut réellement accomplir du travail.
Il tient aussi face aux géants fermés. Sur Arena Elo, le 31B avec 1452 se retrouve juste derrière des modèles avec 15 à 35 fois plus de paramètres :
Sur le plan architectural, la note intéressante tirée de la lecture de Sebastian Raschka est que Gemma 4 est « pratiquement inchangé » par rapport à Gemma 3 sous le capot, donc le saut est « probablement dû au jeu de données d'entraînement et à la recette ». En d'autres termes, Google a obtenu ce saut grâce à de meilleures données, pas à une nouvelle architecture — ce qui est une performance discrètement impressionnante.
Comment c'est en pratique
Les benchmarks c'est une chose. Que disent vraiment les personnes qui font tourner Gemma 4 tous les jours ? J'ai cherché dans les communautés de modèles locaux, parce que c'est là que vivent les avis sans filtre.
Les éloges sont cohérents : c'est rapide, léger en mémoire et ça ne s'épanche pas.
« Rapide comme l'éclair sur un M4Max, et incroyablement intelligent pour sa vitesse. Ne détruit pas votre charge mémoire. Ne raisonne pas pendant des heures (et ne bouffe pas tout le budget de tokens) comme Qwen... C'est parfait pour openclaw, hermes, claude code etc. J'ADORE ce modèle en local. C'est mon modèle par défaut maintenant. » — u/styles01 sur r/LocalLLaMA
Le point « ne raisonne pas pendant des heures » revient sans cesse. Un self-hoster qui fait tourner les 26B et 31B pour un cas d'usage multimodal a donné de vrais chiffres, rapportant environ 149 tokens/sec sur le 31B et 88 sur le 26B, et ajoutant que « les benchmarks ne capturent vraiment pas à quel point il délire moins que les plus grands ».
Mais voici la vraie limitation, et c'est la raison pour laquelle je ne mettrais pas Gemma 4 brut sur une file live sans supervision :
« Je suis d'accord, c'est bien meilleur dans tout sauf le coding. [...] Cependant il souffre beaucoup quand les poids ou le cache kv sont dans une autre quantisation que la native. » — u/fragment_me sur r/LocalLLM
Donc la lecture communautaire se résume à ceci : Gemma 4 est un excellent modèle de chat et de suivi d'instructions qui performe bien au-dessus de son poids, avec deux mises en garde — le coding et les workflows agentiques sont ses points faibles, et il se dégrade notablement si on le fait tourner avec une quantisation différente de la native. Bon à savoir avant de le choisir pour une tâche.
Ce que cela signifie pour le support client
Voici où ça devient pratique pour quiconque gère une équipe de support. Un modèle ouvert comme Gemma 4 est un ingrédient fantastique. Il n'est pas, à lui seul, un agent de support.
Un modèle brut n'a aucune idée de votre politique de remboursement, ne peut pas voir vos tickets passés, et n'est pas connecté à votre helpdesk. Le mettre devant les clients sans supervision produit exactement le mode d'échec contre lequel on travaille depuis des années : un bot qui parle avec assurance mais donne silencieusement la mauvaise réponse. Le modèle est le moteur ; le vrai produit c'est tout ce qui l'entoure — la connaissance, le routage sécurisé, la connexion à vos outils, et la capacité de le tester avant de le mettre en production.
C'est ce vide qui justifie l'existence de plateformes comme la nôtre. Le mouvement open-weight vous donne le contrôle sur la couche modèle, mais la plupart des équipes de support ne veulent pas non plus devenir une équipe ML ops. La meilleure réponse pour la plupart des gens est d'obtenir les bénéfices du contrôle des données et de l'apprentissage sans rouler l'infrastructure à la main — c'est la ligne que je tracerais entre un modèle et une plateforme de service client IA.
Essayez eesel pour le support IA
Si la lecture sur Gemma 4 vous a fait penser « je veux que l'IA réponde à mes tickets, mais à mes conditions », c'est exactement le problème pour lequel eesel a été conçu.
L'agent helpdesk IA d'eesel se connecte aux outils que vous utilisez déjà — Zendesk, Freshdesk, Gorgias, Slack et plus de 100 autres — et apprend de vos tickets et docs d'aide dès le premier jour, pour que des années d'historique deviennent immédiatement de la connaissance. La partie qui répond directement à la question « pourrait-on lui faire confiance ? » avec laquelle j'ai ouvert : vous pouvez simuler l'agent sur des milliers de vos tickets historiques pour voir exactement comment il aurait répondu, avant qu'un seul client ne le voie. C'est ainsi que Gridwise a résolu 73 % des demandes de niveau 1 dès son premier mois.

C'est basé sur l'usage, à partir de 0,40 $ par ticket sans frais par siège, et vous pouvez démarrer avec 50 $ d'utilisation gratuite sans carte de crédit. Que le modèle sous le capot soit Gemma 4 ou autre chose, ce que vous voulez vraiment c'est un agent auquel vous pouvez faire confiance sur votre file. Essayez eesel et voyez comment il gère la vôtre.
Questions Fréquentes
Qu'est-ce que Gemma 4 ?
Gemma 4 est-il gratuit ?
Quelles sont les tailles de modèles Gemma 4 ?
Gemma 4 peut-il fonctionner sur un ordinateur portable ou un téléphone ?
Gemma 4 est-il bon pour le support client ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








