
Qu'est-ce que MiniMax M3 ?
MiniMax M3 est un grand modèle de langage à usage général que MiniMax décrit comme « un modèle de codage et agentique frontier construit sur une architecture d'attention nouvelle (MSA) avec 1M de contexte. » Il remplace la ligne M2 précédente (M2, M2.1, M2.5, M2.7), qui restent toutes disponibles, et c'est le premier modèle MiniMax entraîné pour être multimodal dès la première étape, il prend donc des entrées d'image et de vidéo et peut même piloter un ordinateur de bureau.
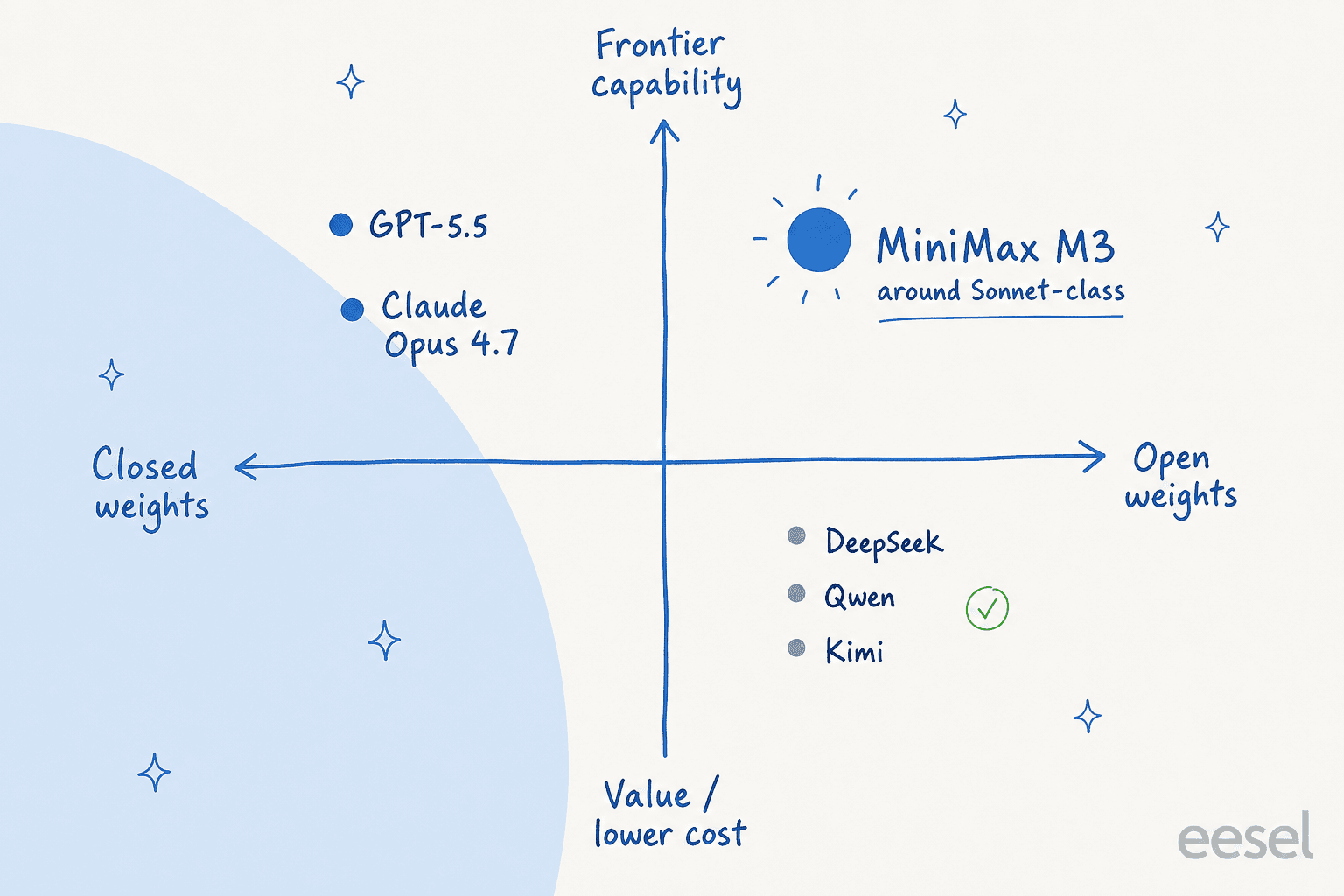
MiniMax elle-même est un laboratoire d'IA chinois dont le slogan est « Intelligence with everyone », avec une gamme qui va bien au-delà du texte : vidéo (Hailuo), parole et musique. M3 est le fer de lance texte et agents de cette gamme. Si vous avez suivi la vague de modèles puissants sortis de Chine, M3 s'inscrit dans la même conversation que Qwen et Kimi K2.5, et c'est l'un des lancements open-weight les plus intéressants de l'année.
Le lancement officiel a exposé clairement la proposition sur le compte X de MiniMax :
« Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities... Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1... MiniMax Sparse Attention scales context to 1M... Natively Multimodal from Step Zero »
Une note sur le nom avant d'aller plus loin : il n'existe pas de modèle littéralement appelé « MiniMax 3 ». Le nom officiel est MiniMax M3, et c'est ce que ce guide couvre.
Comment fonctionne MiniMax M3 : attention creuse et fenêtre de 1M de tokens
Ce qui est le plus intéressant dans M3 n'est pas un benchmark, c'est l'architecture qui lui permet de lire un million de tokens sans que le coût explose. C'est la partie que je trouve vraiment astucieuse, alors laissez-moi expliquer comment cela fonctionne.
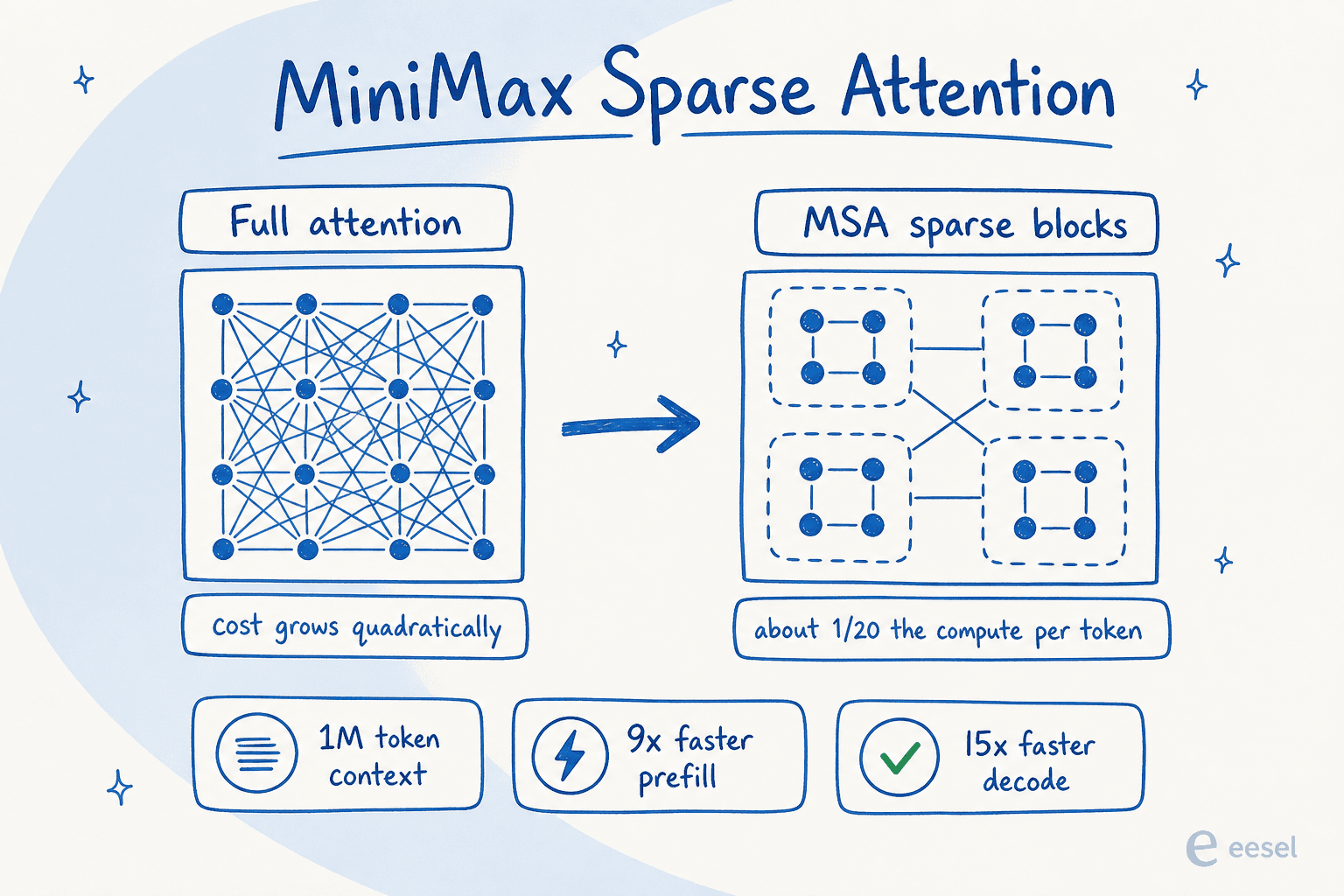
Sous le capot, M3 est un modèle Mixture-of-Experts avec environ 428 milliards de paramètres totaux et environ 23 milliards activés par token, donc il n'exécute qu'une fraction de lui-même pour n'importe quelle requête. Au-dessus se trouve le vrai titre : MiniMax Sparse Attention (MSA), une nouvelle conception d'attention qui partitionne le contexte en blocs et n'assiste qu'aux blocs pertinents au lieu de comparer chaque token à chaque autre token.
Cela est important car l'attention normale devient quadratiquement plus coûteuse à mesure que le contexte augmente, c'est pourquoi les longues fenêtres de contexte sont généralement lentes et chères. MiniMax rapporte que MSA réduit le calcul par token à environ 1/20, avec plus de 9 fois plus de vitesse de prefilling et 15 fois plus de vitesse de décodage à 1M de contexte par rapport à M2, tout en maintenant une attention complète sur la plupart des capacités dans leurs ablations. Le résultat est une fenêtre de contexte de 1 000 000 de tokens (avec un minimum garanti de 512K), contre 204 800 sur la ligne M2.
Quelques autres choses à savoir sur le comportement de M3 :
- Modes de réflexion. Un paramètre
thinkingpermet de régler le raisonnement surenabled,adaptive(le modèle décide) oudisabledpour une faible latence, et les deux modes partagent la même tarification. - Multimodalité native. Parce qu'il a été entraîné sur du texte, des images et de la vidéo entrelacés « dès l'Étape 0 », M3 fusionne les modalités plus profondément qu'un modèle avec la vision ajoutée après coup.
- Conçu pour le travail sur le long terme. Dans les propres démonstrations de MiniMax, M3 a fonctionné de manière autonome pendant près de 12 heures pour reproduire un article de recherche, et a passé environ 24 heures à optimiser un noyau CUDA sur 147 soumissions de benchmark et 1 959 appels d'outils.
La méthode complète se trouve dans le rapport technique M3 si vous voulez la profondeur.
À quel point MiniMax M3 est-il bon ? Les benchmarks
MiniMax positionne M3 comme atteignant la frontière en ingénierie logicielle et en exécution de terminal, et le compare à des modèles fermés comme GPT-5.5, Gemini 3.1 Pro et Claude Opus. Voici les scores publiés de l'annonce :
| Benchmark | Ce qu'il mesure | MiniMax M3 |
|---|---|---|
| SWE-Bench Pro | Corrections logicielles du monde réel | 59,0 % |
| Terminal-Bench 2.1 | Tâches agentiques en ligne de commande | 66,0 % |
| MCP Atlas | Utilisation des outils via le protocole agent | 74,2 % |
| SWE-fficiency | Modifications de code efficaces | 34,8 % |
| KernelBench Hard | Optimisation de noyaux GPU | 28,8 % |
| PostTrainBench | Entraînement autonome de modèles | 37,1 (#3) |
| Video-MME (512 images) | Compréhension vidéo | 84,6 |
Un peu d'honnêteté sur ce que cela signifie. Sur le benchmark d'entraînement autonome de modèles PostTrainBench, M3 est arrivé troisième au classement général, légèrement derrière Claude Opus 4.7 (42,4) et GPT-5.5 (39,3) mais devant tout le reste. C'est le schéma général : M3 est excellent pour un modèle open-weight et compétitif en codage, mais il ne mène pas la frontière fermée. La précédente famille M2 avait déjà poussé les scores open-weight plus haut sur des indices indépendants, et M3 est un clair pas en avant depuis.
Si vous souhaitez le contexte plus large de la façon dont ces modèles se comparent, nos guides sur les alternatives à Claude et les alternatives à Gemini couvrent le côté modèles fermés de la comparaison.
Combien coûte MiniMax M3 ?
C'est là que M3 forge sa réputation. La tarification est la raison pour laquelle les développeurs continuent de le mentionner.
MiniMax vend M3 de deux façons. La première est un Token Plan d'abonnement, mis à jour au lancement sur trois niveaux, où texte, image, parole et musique tirent tous d'un seul pool d'utilisation partagé :
| Token Plan | Prix / mois | Tokens M3 approx. / mois |
|---|---|---|
| Plus | 20 $ | ~1,7 milliard de tokens |
| Max | 50 $ | ~5,1 milliards de tokens |
| Ultra | 120 $ | ~9,8 milliards de tokens |
MiniMax présente le niveau d'entrée comme « 20 $ = 10x Claude Pro » en débit, ce qui est du marketing, mais cela dit l'angle : le maximum de tokens par dollar. C'est le même positionnement bas coût que vous voyez dans la tarification de Qwen et le reste du groupe open-weight.
La deuxième façon est l'API à l'utilisation, facturée à la longueur d'entrée. Les appels de moins de 512K tokens d'entrée bénéficient du tarif standard ; tout ce qui est au-delà est facturé à un tarif de contexte long plus élevé pour le travail sur des dépôts complets et des documents ultra-longs. La réflexion activée ou désactivée coûte la même chose, et un niveau de service priority est disponible pour les charges de travail sensibles à la latence. Les développeurs sur r/LLMDevs rapportent le tarif par token au lancement à 0,60 $/2,40 $ par million jusqu'à 512K, ce qui les place, selon leurs propres termes, dans le « territoire DeepSeek ».
L'autre moitié de l'histoire des coûts est la licence. M3 est open-weight sous la MiniMax Community License : gratuit pour une utilisation non commerciale, avec l'utilisation commerciale nécessitant un crédit visible « Built with MiniMax M3 » et, au-delà de 20 M$/an de revenus, une autorisation préalable écrite. Donc c'est open-weight, pas open source, une distinction que la communauté s'empresse de souligner. Pour une comparaison de coûts pure avec d'autres options payantes, notre liste des outils IA bon marché et le guide de tarification Kimi K2.5 sont des références utiles.
Ce que les développeurs disent vraiment de MiniMax M3
Les benchmarks publiés ne disent pas tout. Le signal le plus utile vient des développeurs qui exécutent M3 sur des travaux réels, et le verdict est cohérent : un choix à fort rapport qualité-prix, pas un remplacement de la frontière.
La version la plus claire de l'argument de valeur vient en fait de quelqu'un qui est passé au prédécesseur M2.7, sur r/openclaw :
« claude is a slightly better model. better reasoning, better depth on hard problems. that's just how it is. but minimax m2.7 delivers exceptionally well for what i actually use it for, at a fraction of the cost... sometimes good enough is actually great when it's reliable and affordable. »
Sur M3 spécifiquement, un développeur sur r/opencode l'a formulé ainsi après avoir d'abord essayé les autres modèles chinois :
« I started using Kimi 2.6, then GLM 51, then DeepSeek4. But now after trying minimax m3 I am really impressed. It seems to think very deeply and really do a good job following directions... It seems to have flown a lot under the radar. »
Cela correspond à peu près à l'endroit où M3 se situe sur le marché : poids ouverts, capacité proche du niveau Sonnet, à des prix de niveau value.
Ce ne sont pas que des éloges, cependant, et la critique mérite d'être prise au sérieux si vous pensez à la production. La plainte la plus courante est la fiabilité sous pression. Un testeur sur r/hermesagent a trouvé M3 erratique :
« I feel like it is much more chaotic and verbose, as well as hallucinations being more common. Now it just suddenly keeps stopping mid action... Right now I wouldn't use it in production. »
Il y a aussi une préoccupation récurrente concernant la rétention des données à propos de l'API hébergée, les utilisateurs notant qu'ils ne pouvaient pas trouver d'option claire pour s'opposer à l'utilisation des données de prompt pour l'entraînement. C'est exactement le genre de chose qui compte davantage pour les données clients que pour un projet de loisir, et c'est une grande raison pour laquelle la communauté d'auto-hébergement apprécie que les poids soient sur Hugging Face.
Le problème : un excellent modèle n'est pas encore un agent de support
Voici le recadrage avec lequel je veux que vous repartiez, car c'est ce que les gens manquent lorsqu'un nouveau modèle brillant est lancé. Un modèle comme M3 est un moteur fantastique. Mais un moteur n'est pas une voiture, et un modèle brut n'est pas un agent de support client.
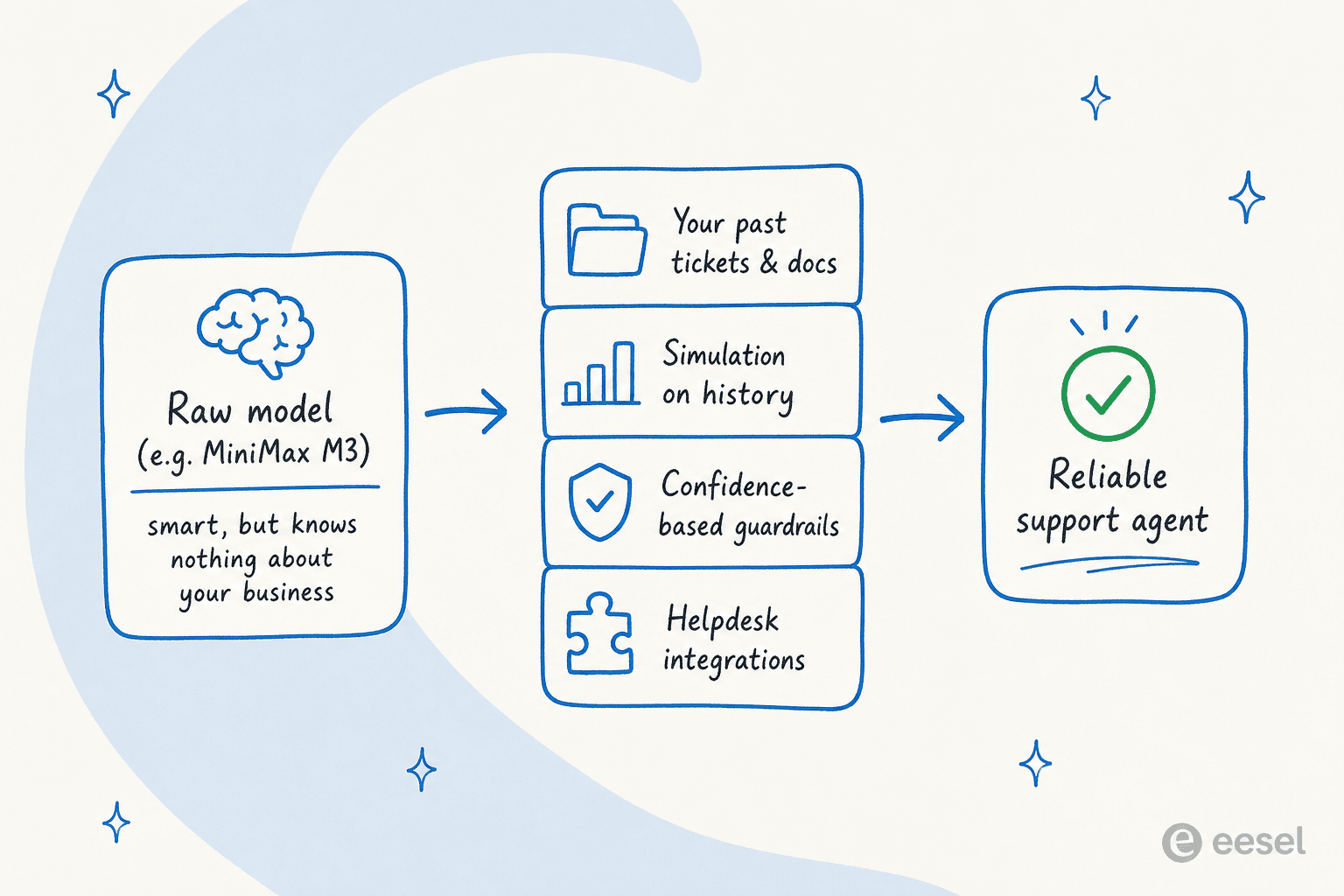
J'ai passé les dernières années chez eesel à observer ce qui se passe lorsqu'on pointe un modèle de langage sur une file d'attente de support en direct, et le mode d'échec est toujours le même : le modèle sonne confiant et se trompe sur les détails, parce qu'il ne connaît pas votre politique de remboursement, vos 50 000 derniers tickets résolus, ni quelle réponse est sûre à envoyer sans qu'un humain la lise d'abord. Le modèle le plus intelligent du classement hallucine quand même votre délai d'expédition si personne ne le lui a appris. C'est pourquoi chaque déploiement eesel tourne en simulation sur des tickets historiques avant de répondre à un seul client.
Donc les questions pertinentes pour le support ne sont pas « quelle note a obtenu M3 sur SWE-Bench ». Ce sont : peut-il apprendre de mes vrais tickets et documents, puis-je le tester en sécurité avant la mise en production, et qu'est-ce qui l'empêche d'envoyer en confiance une mauvaise réponse ? Ce sont des questions de produit, pas des questions de modèle, et ce sont celles autour desquelles notre récapitulatif du meilleur IA pour le service client est construit.
Le même point surgit chaque fois qu'un chatbot répond incorrectement, et c'est pourquoi le coût d'un agent IA par rapport à un humain dépend beaucoup plus de la façon dont il résout les tickets de manière fiable que du prix par token du modèle.
eesel : la couche qui transforme un modèle en coéquipier de support
C'est exactement cet écart qu'eesel est conçu pour combler. Au lieu de vous demander de choisir un modèle et de prier, eesel s'installe au-dessus de votre helpdesk comme un coéquipier IA qui apprend de vos tickets passés, docs d'aide et outils dès le premier jour, puis rédige, triage et résout le travail de niveau 1 avec les garde-fous qui le rendent sûr à laisser tourner.

Le différenciateur concret est le mode simulation : vous faites tourner l'agent sur des milliers de vos vrais tickets passés, vous voyez exactement ce qu'il aurait répondu et où sont les lacunes, vous les comblez, et seulement alors vous passez en production, avec un routage basé sur la confiance qui maintient les réponses à faible confiance comme des brouillons plutôt que des envois. C'est ainsi que des équipes comme Smava font tourner un agent Zendesk entièrement automatisé sur plus de 100 000 tickets allemands par mois, et comment Gridwise a atteint 73 % de résolution de niveau 1 dès son premier mois. Il se connecte à plus de 100 intégrations, répond dans plus de 80 langues et fonctionne avec une tarification à l'utilisation à 0,40 $ par ticket sans frais par siège.
Si vous êtes venu ici pour choisir un modèle pour le support, le meilleur point de départ est la couche, pas le classement. Vous pouvez essayer eesel gratuitement, sans carte de crédit, et regarder l'agent résoudre vos propres tickets en simulation avant de toucher un seul client. C'est la même leçon derrière chaque déploiement de IA de service client que j'ai vu fonctionner : le modèle est interchangeable, la fiabilité ne l'est pas.
Questions fréquentes
Qu'est-ce que MiniMax M3 en termes simples ?
MiniMax M3 est-il vraiment open source ?
Combien coûte MiniMax M3 ?
MiniMax M3 est-il bon pour le codage ?
Puis-je utiliser MiniMax M3 pour le support client ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








Comment MiniMax M3 gère-t-il un contexte de 1 million de tokens ?