
Alors qu'est-ce que Cursor Origin exactement ?
Origin est la propre forge Git de Cursor : une plateforme construite de zero pour heberger, reviser et collaborer sur du code, en competition directe avec GitHub. La formule de Cursor dans le post de lancement est aussi claire que possible :
Nous lancons le stockage de code et l'hebergement git. Origin donne aux equipes et aux agents un endroit pour heberger, reviser et collaborer sur du code. Disponible cet automne. Rejoignez la liste d'attente.
Le slogan sur la page produit est "une forge Git pour l'ere agentique," avec une ligne de texte de soutien : "Le code se deplace plus vite que toute infrastructure n'a ete construite pour le gerer. Origin a ete concu pour ce moment." C'est essentiellement tout le site public aujourd'hui, un slogan et un bouton de liste d'attente.
Il a ete demonte sur scene par Tomas Reimers, cofondateur de Graphite, la startup de revue de code que Cursor a acquise. Ce detail compte plus qu'il n'y parait, et j'y reviendrai. Si vous decouvrez Cursor, c'est l'editeur de code natif IA construit sur un fork de VS Code, et Origin est son passage de "ou vous ecrivez du code" a "ou vit votre code."
Pourquoi construire un tout nouvel hote Git ?
C'est la question qui vaut la peine d'etre examinee, car "Cursor a clone GitHub" est la lecture paresseuse et elle rate l'essentiel.
Git, et GitHub par-dessus, a ete concu autour du rythme humain. Un developpeur ouvre une branche, ecrit du code pendant quelques heures, ouvre une pull request, attend qu'un coequipier la revise, puis fusionne. Tout le rythme se mesure en heures et en jours, et c'est tres bien, car une personne ne peut taper qu'a une certaine vitesse.
Les agents IA brisent cette hypothese. Comme l'a formule la synthese d'AlphaSignal, "des dizaines ou des centaines d'entre eux peuvent cloner, brancher, commiter et rebaser la meme base de code simultanement, en quelques secondes," ce qui est "un profil de charge fondamentalement different de tout ce pour quoi GitHub a ete architecturalement concu." Une fois que vous faites tourner des flottes d'outils de codage agentique, le goulot d'etranglement ne reside plus dans la vitesse a laquelle vous pouvez ecrire du code, mais dans la rapidite a laquelle vous pouvez heberger, reviser et fusionner en securite ce que les machines produisent.
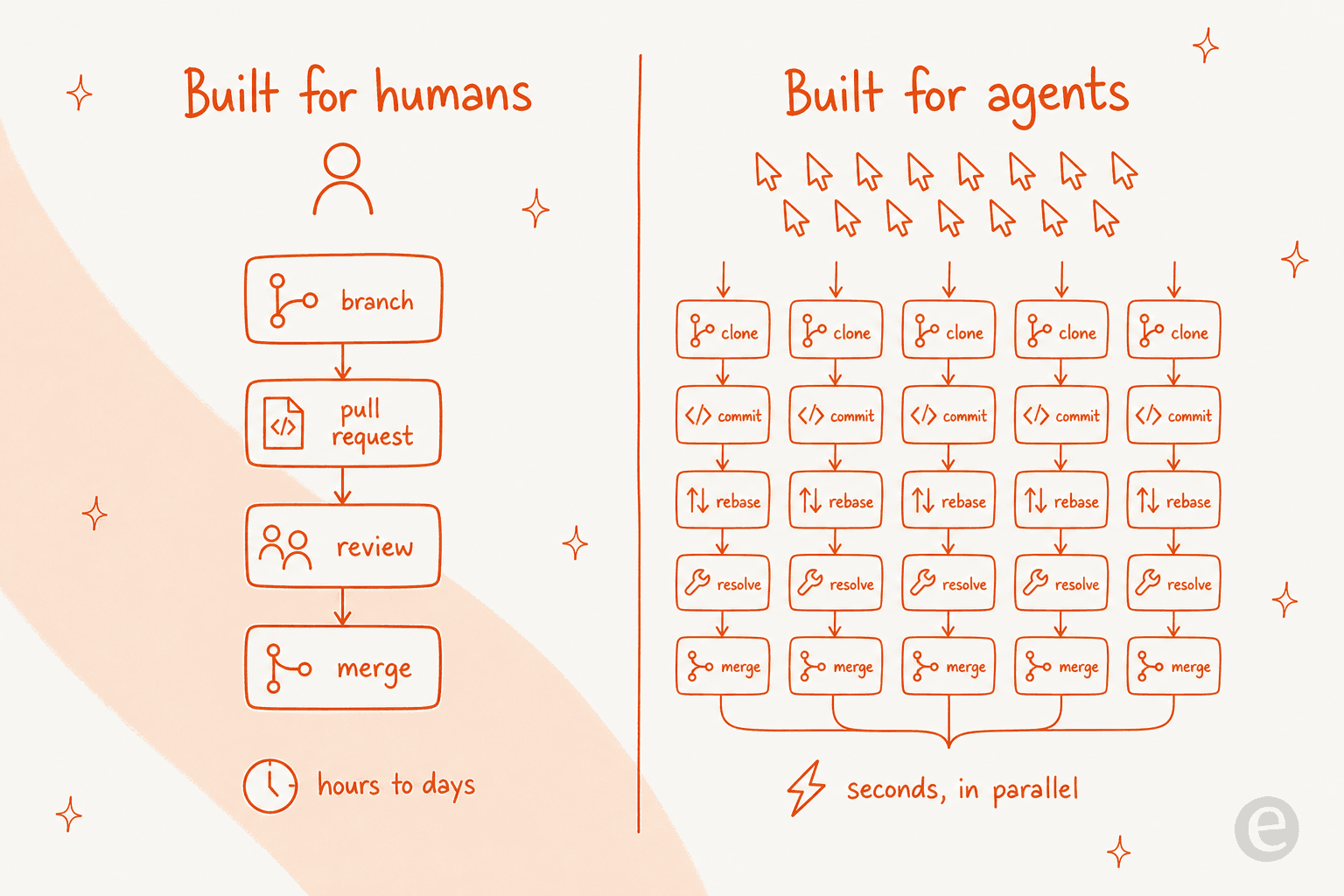
Le pari d'Origin est donc que la prochaine piece d'infrastructure a reconstruire est la forge elle-meme. L'analyste Mark K l'a formule comme "la tentative de Cursor d'un concurrent de GitHub natif pour les agents," construit autour de "la coordination, la revue et la fusion securisee de code genere par des agents a grande echelle." C'est la meme logique derriere beaucoup d'infrastructure d'agents IA en ce moment : les outils que nous avons construits pour les personnes commencent a craquer des que le logiciel, pas une personne, est le principal utilisateur.
Ce qu'il y a vraiment sous le capot
Cursor n'a pas encore publie de vraie documentation, donc le tableau des fonctionnalites vient de la demo de lancement et des personnes qui etaient dans la salle. Voici ce qui a ete montre ou annonce :
- Compatibilite Git, afin qu'il fonctionne avec les outils git standard plutot que d'imposer un nouveau flux de travail.
- Extensibilite via API et MCP, decrite par swyx comme "extensible avec api et mcp," pour que les agents puissent piloter la forge de maniere programmatique.
- Resolution integree des conflits de fusion geree par des agents, plus la resolution agentique des echecs de CI/build ("resolution integree des conflits de fusion et resolution des echecs de co par agent").
- Une architecture de stockage hybride NVMe + S3 qui, selon la couverture de Digg, "prend en charge des replicas infinies."
- Heritage des pull requests empilees de Graphite, pour gerer de nombreux changements dependants en parallele.
Les chiffres de la demo sur scene sont les accroches. Nick Dobos a extrait des diapositives que "cursor origin prend en charge 22,6 commits par seconde (dans un seul depot)," et la demo aurait traite des centaines de milliers de clones par heure, le type de charge qu'AlphaSignal a note que cela "stresserait toute infrastructure d'hebergement Git existante."

Une note rapide d'honnetete : un chiffre de "296 000+ clones" largement partage a circule dans la couverture, mais l'unite et le laps de temps ont ete tronques dans le titre de la source originale, donc je le traiterais comme une affirmation d'echelle plutot qu'un benchmark precis jusqu'a ce que Cursor publie ses propres chiffres.
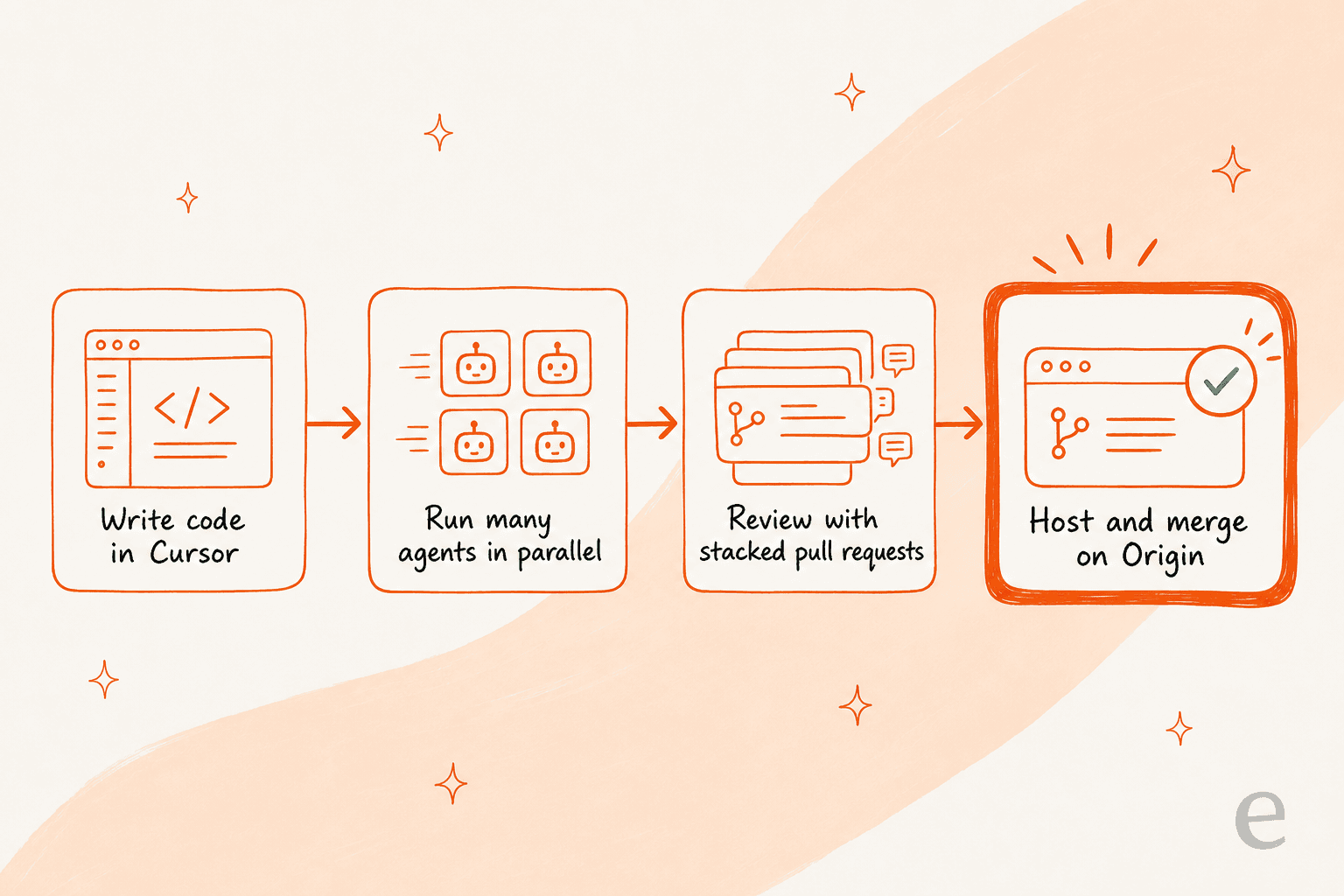
La ou Origin s'inscrit vraiment, c'est comme la derniere piece d'un stack que Cursor a discreetement assemble. Mark K a decrit l'image complete comme une "usine logicielle IA" : ecrire du code dans Cursor, faire tourner des agents en parallele, reviser avec des flux de travail empiles a la maniere de Graphite, puis heberger et fusionner sur Origin. L'acquisition de Graphite est ce qui rend cette couche de revue et de fusion credible, et c'est pourquoi je lis Origin moins comme un clone de GitHub et plus comme Cursor qui boucle la boucle de son propre flux de travail de codage agentique.
Le probleme : un lancement mince et un vrai probleme de confiance
C'est la ou je mettrais un frein. Le lancement a ete bruyant, le post officiel a attire plus de 3 millions de vues, mais la surface reelle du produit est un slogan et un formulaire d'inscription. Hacker News ne l'a pas laisse passer : "Je n'ai jamais vu une liste d'attente pour si peu d'informations," a ecrit un commentateur. La liste d'attente elle-meme aurait plante sous la charge au lancement, ce qui est soit un mauvais signe, soit un signe adapte pour un produit axe sur le debit.
L'objection plus profonde est celle que je trouve la plus interessante, car c'est la meme que j'entends constamment dans le support. Si les agents font des commits 22,6 fois par seconde, qui revise vraiment tout ca ? Du fil HN :
En quoi c'est different de Github... comment ca gere la generation de code IA a la vitesse d'une machine ? Est-ce qu'il y a encore un humain dans la boucle pour reviser le code bacle de l'IA ?
C'est tout l'enjeu. Accelerer la vitesse a laquelle les machines peuvent ecrire et fusionner du code ne vous sert a rien si personne ne peut garantir que le code est correct. "L'agent resout le conflit de fusion automatiquement" semble formidable jusqu'a ce que l'agent le resolve mal et le deploie a la vitesse d'une machine.
Et puis il y a la confiance en Cursor lui-meme. Une tranche vocale de la reaction sur r/cursor concernait moins les fonctionnalites et plus le fait de confier une base de code :
Je vais utiliser Cursor pour construire mon propre serveur Git et l'heberger sur AWS avant de donner mon code a un depot heberge par X
Ce commentaire (la reference a "X" est la propre lecture du commentateur sur qui est derriere Cursor, selon le fil, pas quelque chose que Cursor a confirme) fait echo a une inquietude plus large qui a emerge de facon repetee : que le vrai produit est votre code en tant que donnees d'entrainement. Jusqu'a ce que Cursor publie les conditions de traitement des donnees d'Origin, je classerais la question de la confidentialite sous "encore ouverte," pas "c'est bon."
Ce qu'Origin nous dit vraiment sur l'ere agentique
Prenez du recul par rapport a la plomberie Git et Origin est un signal. L'infrastructure construite pour les humains est reconstruite des que les agents deviennent les utilisateurs principaux. Ce n'est pas un constat propre a Cursor, c'est un schema, et je le dis parce que j'ai vecu la version cote support ces dernieres annees en construisant eesel AI.
Le helpdesk avait exactement le meme probleme avant Git. Des outils comme Zendesk et Freshdesk ont ete concus autour d'un agent humain qui prend un ticket a la fois. Introduisez un agent IA dans ce monde et les memes questions que Hacker News pose sur Origin apparaissent mot pour mot : qui revise le resultat, que se passe-t-il quand il est confiant mais faux, et mes donnees sont-elles utilisees pour entrainer le modele de quelqu'un. Nous avons observe un bot au ton assure donner des mauvaises reponses en silence, c'est pourquoi nous faisons maintenant en sorte que chaque equipe simule un deploiement contre ses propres tickets historiques avant qu'une seule reponse en direct ne parte, et pourquoi les reponses a faible confiance sont redigees pour un humain plutot qu'envoyees. Le debit n'a jamais ete la partie difficile. C'etait la confiance.
C'est aussi pourquoi l'instinct build-versus-buy qu'Origin declenche ("je vais juste heberger mon propre serveur Git sur AWS") merite un second regard. Nous l'entendons des equipes techniques tout le temps du cote support, et celles qui essaient vraiment arrivent generalement au meme endroit ou l'un de nos clients est arrive :
Nous aurions pu essayer d'ecrire notre propre application LLM mais nous ne voulions pas y investir notre temps. Nous voulions quelque chose que nous n'aurions pas a maintenir.
C'est un responsable technique d'une societe de distributeurs automatiques de Bitcoin qui a choisi d'acheter plutot que de construire, dans une etude de cas. Origin, c'est Cursor qui fait le pari inverse au niveau de l'infrastructure, en pariant que l'hebergement de code a l'echelle des agents est un probleme suffisamment difficile pour que les equipes paient quelqu'un d'autre pour le faire tourner. Si c'est vrai depend entierement de savoir s'ils resolvent le probleme de revue et de confiance, pas celui des commits par seconde.
Donc, devriez-vous vous preoccuper de Cursor Origin ? Si vous gerez une organisation d'ingenierie serieuse qui mise beaucoup sur les agents de Cursor, inscrivez-vous sur la liste d'attente et observez attentivement, surtout les conditions relatives aux donnees. Si vous etes une equipe de support, IT ou operations qui se demande si ca change quelque chose pour vous, ca ne le fait pas, du moins pas directement. Vous n'avez pas besoin d'un nouvel hote Git pour mettre des agents IA au travail. Vous avez besoin d'agents qui s'integrent deja aux outils que vous avez, et des garde-fous pour leur faire confiance.
Essayez eesel AI
Cursor Origin reconstruit l'infrastructure de code pour l'ere agentique. Du cote support, eesel AI fait l'equivalent depuis un moment : un agent IA qui vit dans le helpdesk, Slack et les docs que vous utilisez deja, apprend de vos tickets passes des le premier jour et gere le travail de niveau 1 sans que vous ayez a migrer quoi que ce soit.
La difference avec une liste d'attente, c'est que vous pouvez vraiment le faire tourner. Gridwise avait eesel qui resolvait 73% de ses demandes de niveau 1 le premier mois, avec des resultats qui arrivent lors d'un essai de 7 jours, et chaque deploiement commence par une simulation contre votre vrai historique de tickets pour que vous voyiez la couverture et la precision avant qu'une seule reponse en direct ne parte. C'est la partie dont l'ere agentique depend vraiment, pas les commits par seconde.

Si vous voulez des agents IA que vous pouvez mettre au travail aujourd'hui plutot que d'attendre l'automne, Essayez eesel.
Questions frequemment posees
Qu'est-ce que Cursor Origin ?
Quand Cursor Origin sera-t-il disponible ?
Cursor Origin est-il un concurrent de GitHub ?
Mon code est-il en securite sur Cursor Origin ?
Ai-je besoin de Cursor Origin pour utiliser des agents IA au travail ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.




