
En bref
Les modèles d'IA basés sur la diffusion renversent la façon dont la génération fonctionne. Au lieu d'écrire un mot après l'autre, ils partent de bruit ou d'espaces réservés masqués et raffinent toute la sortie en parallèle sur quelques passes de débruitage. C'est la même idée que celle derrière les outils d'image comme Stable Diffusion, désormais portée au texte.
L'argument phare, c'est la vitesse. Les modèles de langage à diffusion comme Mercury d'Inception et Gemini Diffusion de Google tournent à environ 1 000 à 1 500 tokens par seconde, soit à peu près 10 fois plus vite que les modèles autorégressifs optimisés pour la vitesse sur le même matériel. Ils peuvent aussi réviser les tokens précédents et combler le milieu d'une séquence, ce que les modèles classiques de gauche à droite ne savent pas faire.
Le bémol : ils restent en retrait par rapport aux modèles autorégressifs comme GPT et Claude sur le raisonnement difficile et le long contexte, et l'écosystème est jeune. Pour l'instant, la stratégie intelligente est le routage, pas le remplacement. Et si vous dirigez une équipe de support, l'architecture importe bien moins que les connaissances, les garde-fous et les intégrations qui enveloppent le modèle.
Qu'est-ce qu'un modèle d'IA basé sur la diffusion ?
Un modèle de diffusion est un modèle génératif qui apprend à construire des données en inversant un processus progressif d'ajout de bruit. L'idée vient de la physique : on définit une chaîne d'étapes qui ajoutent lentement du bruit aléatoire à des données réelles, puis on entraîne un réseau à inverser ce processus et à reconstruire des échantillons à partir du bruit. Les travaux fondateurs sont ceux de Sohl-Dickstein et al. (2015) et l'article de 2020 sur les denoising diffusion probabilistic models.
Il y a deux moitiés. Dans le processus direct, on prend une image réelle et on ajoute un peu de bruit gaussien encore et encore jusqu'à ce qu'elle devienne du pur bruit statique. Cette partie ne demande aucun apprentissage ; sa seule fonction est de fabriquer des paires d'entraînement. Dans le processus inverse, un réseau de neurones apprend à défaire une étape de bruit à la fois. Au moment de la génération, on part d'un bruit aléatoire et on exécute le réseau de façon répétée, chaque passe retirant un peu plus de bruit jusqu'à ce qu'un résultat cohérent émerge.
Voici l'intuition qui fait tilt. Imaginez filmer une sculpture de glace en train de fondre en flaque, puis passer le film à l'envers : on part d'une flaque informe et, image par image, on la recongèle en sculpture. Parce que le modèle travaille sur toute la toile à chaque étape, il peut continuer à corriger ses erreurs antérieures au fur et à mesure.
C'est la technique qui alimente l'essentiel de la génération moderne d'images, de vidéos et d'audio. La diffusion se trouve derrière Sora, Midjourney et Riffusion, ainsi que DALL-E 2, Imagen et Stable Diffusion. Le fil conducteur : tous partent du bruit et débruitent de façon itérative vers un résultat, guidés par votre prompt.
Comment les LLM autorégressifs génèrent du texte
Pour comprendre pourquoi la diffusion est une grande affaire pour le texte, il faut le contraste. Presque chaque grand modèle de langage que vous avez utilisé, y compris ChatGPT, Claude, Gemini et Llama, est un modèle autorégressif. Il génère le texte de gauche à droite, un token à la fois, et un token ne peut pas être produit tant que tout ce qui le précède n'existe pas.
Deux conséquences découlent de cette conception, et toutes deux comptent pour la comparaison :
- La latence est séquentielle. Produire chaque token nécessite une passe avant complète à travers des milliards de paramètres, si bien que les longues sorties (pensez aux longues traces de raisonnement) gonflent directement le temps d'attente et le coût.
- Pas de retour en arrière. Une fois qu'un token est émis, il est figé. Le modèle ne peut pas réviser un mot antérieur à la lumière d'un mot ultérieur. Cette habitude unidirectionnelle est mise en cause pour des bizarreries comme la malédiction de l'inversion, où un modèle sait que « A est B » mais trébuche sur « B est A ».
L'avantage, c'est que la sortie de longueur variable est facile : le modèle émet simplement un token de fin de séquence dès qu'il a terminé. Cette flexibilité est l'une des raisons pour lesquelles l'autorégression est restée dominante pour le texte.
Comment les modèles de langage à diffusion génèrent du texte différemment
Les modèles de langage à diffusion (dLLM) portent la recette de l'image au texte. Au lieu de pixels-depuis-le-bruit, ils font des tokens-depuis-les-masques. Google DeepMind le décrit simplement : plutôt que de prédire le texte directement, le modèle apprend à générer des sorties en raffinant le bruit étape par étape, ce qui lui permet d'itérer rapidement sur une solution et de corriger ses erreurs pendant la génération.
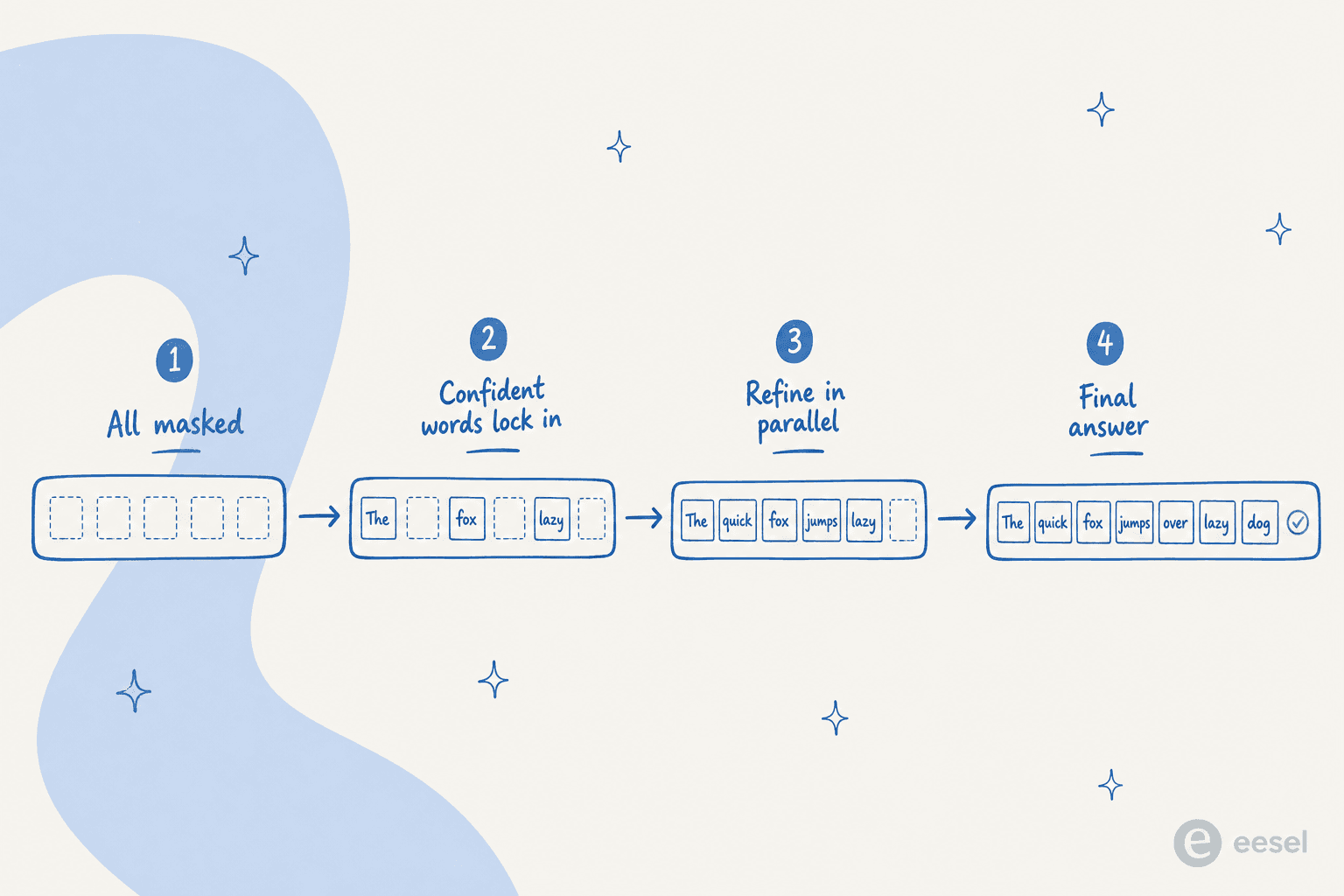
L'approche dominante pour le texte est la diffusion masquée. Dans LLaDA, un modèle de diffusion ouvert de 8 milliards de paramètres, le processus direct masque des tokens et le processus inverse utilise un « prédicteur de masque » de type transformer pour remplir tous les tokens masqués d'un coup, simulant une diffusion d'un état entièrement masqué vers un état entièrement écrit. Une lignée antérieure, Diffusion-LM, utilisait plutôt une diffusion continue sur les vecteurs de mots.
La différence phare est le décodage parallèle. Un dLLM génère les tokens en parallèle plutôt qu'un à la fois, et le transformer sous-jacent peut modifier plusieurs tokens à la fois pour améliorer globalement la réponse. Parce que la formulation est non autorégressive, elle permet aussi une génération dans n'importe quel ordre : le modèle peut d'abord verrouiller les mots dont il est sûr n'importe où dans la séquence, puis combler le reste.
L'une des explications les plus claires est d'ailleurs venue d'un développeur sur Hacker News, qui a tranché dans la confusion du « la diffusion remplace les transformers » :
« Malgré le nom, les modèles de langage à diffusion ont peu à voir avec la diffusion d'images et sont bien plus proches de BERT et du bon vieux modèle de langage masqué... pour générer quelque chose à partir de zéro, on commence par fournir au modèle uniquement des [MASK]... en 10 étapes, vous aurez généré une séquence entière. » nvtop, dans la discussion sur Gemini Diffusion sur Hacker News
Cette vision parallèle et bidirectionnelle explique aussi pourquoi un modèle de diffusion peut voir le contexte des deux côtés d'un trou. LLaDA, par exemple, bat GPT-4o sur une tâche de complétion de poème à l'envers, surmontant la malédiction de l'inversion qui fait trébucher les modèles de gauche à droite.
Autorégressif vs diffusion : la différence fondamentale
Si vous ne devez retenir qu'une image de cet article, retenez celle-ci. Les modèles autorégressifs construisent une phrase comme une course de relais, chaque mot passant le témoin au suivant. Les modèles de diffusion la construisent comme le développement d'un Polaroid, l'image entière émergeant d'un coup et se précisant à chaque passe.
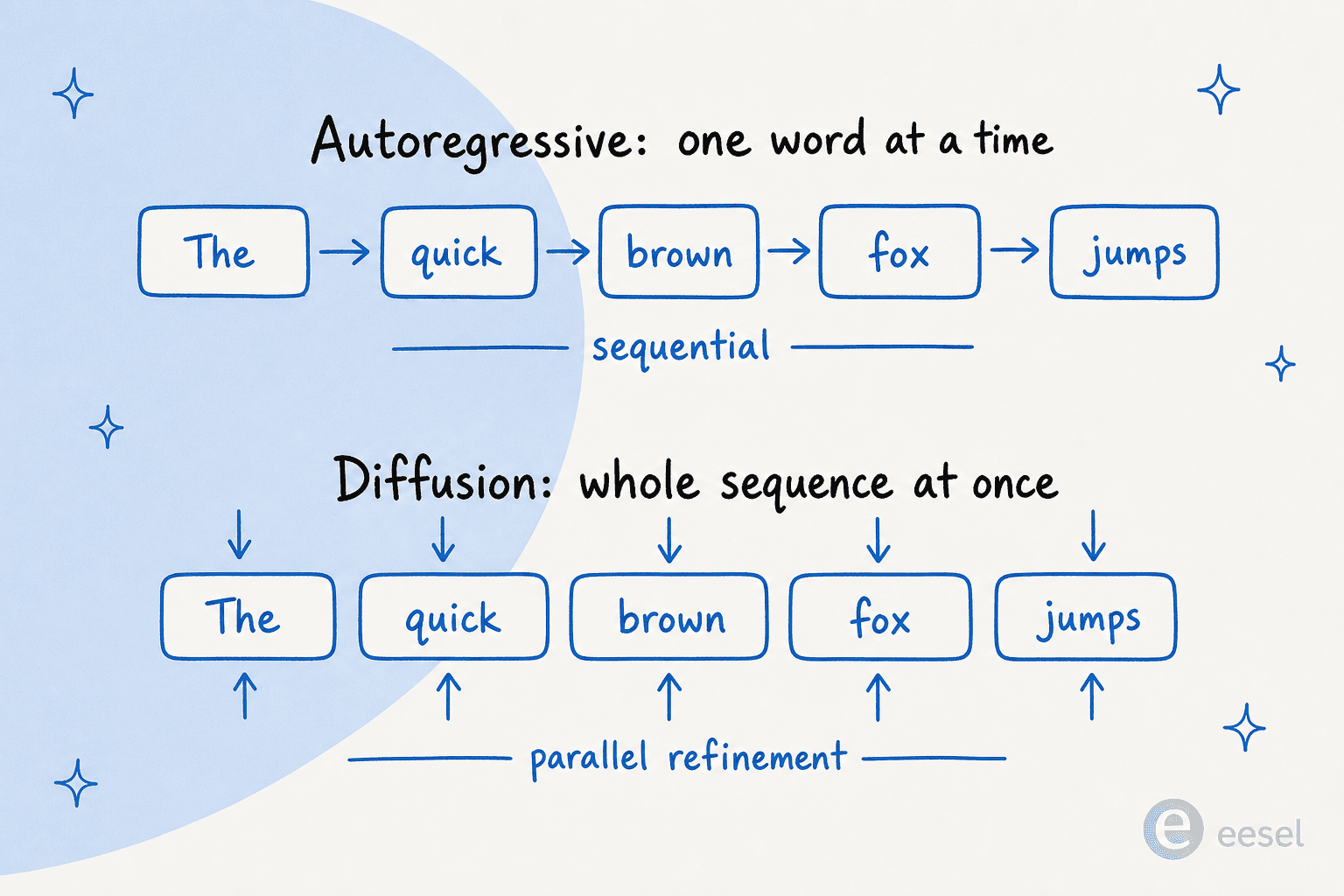
Voici comment les deux se comparent sur les dimensions qui comptent vraiment pour un acheteur :
| Dimension | Autorégressif (GPT, Claude, Gemini) | Diffusion (Mercury, Gemini Diffusion) |
|---|---|---|
| Ordre de génération | De gauche à droite, un token à la fois | Toute la séquence en parallèle, dans n'importe quel ordre |
| Vitesse | Des dizaines à ~200 tokens/s | ~1 000 à ~1 500 tokens/s |
| Peut réviser les tokens précédents ? | Non, une fois émis c'est figé | Oui, sur les passes de débruitage |
| Édition et remplissage | Maladroit (ajout seulement) | Naturel (conditionne des deux côtés) |
| Raisonnement difficile | Plus fort aujourd'hui | En retrait, surtout à l'échelle de pointe |
| Long contexte | Plus efficace (réutilise le cache KV) | Plus faible (recalcule l'attention à chaque passe) |
| Longueur de sortie | Variable, flexible | Souvent des blocs de longueur fixe |
| Maturité de l'écosystème | Cinq ans d'outillage | Précoce, en évolution rapide |
Notez la symétrie : les atouts de la diffusion (vitesse, révision, remplissage) et ses faiblesses (profondeur de raisonnement, long contexte, maturité) remontent toutes à la même cause racine. Travailler sur toute la séquence en parallèle est ce qui la rend rapide et éditable, et aussi ce qui rend le long contexte et le raisonnement étape par étape plus difficiles.
Le gain de vitesse, et le bémol
Les chiffres de vitesse sont véritablement frappants, et ils ne sont pas que du marketing. Le développeur et blogueur sur les LLM Simon Willison a obtenu l'accès à Gemini Diffusion via la liste d'attente et l'a essayé :
« La fonctionnalité clé, c'est donc la vitesse. J'ai franchi la liste d'attente et je viens de l'essayer et waouh, ils ne plaisantent pas sur sa rapidité. » Simon Willison, premières impressions de Gemini Diffusion
Voici comment le débit se compare entre quelques modèles, avec les références autorégressives pour le contexte :
| Modèle | Type | Débit (tokens/s) | Source |
|---|---|---|---|
| Gemini Diffusion | Diffusion | ~1 479 (hors surcoût) | Éditeur |
| Mercury 2 (Inception) | Diffusion | ~1 196 en pic | Artificial Analysis |
| Mercury Coder Mini | Diffusion | 1 109 | Éditeur, corroboré par AA |
| Gemini 2.0 Flash-Lite | Autorégressif | ~201 | Selon Inception |
| Claude 4.5 Haiku | Autorégressif | ~89 | Selon Inception |
| GPT-5 Mini | Autorégressif | ~71 | Selon Inception |
Deux choses à garder honnêtes ici. Premièrement, la plupart des chiffres de débit sont mesurés sur un NVIDIA H100 et beaucoup sont des affirmations des éditeurs ; Artificial Analysis est la principale source indépendante, et elle a corroboré la vitesse de Mercury mais pas encore sa qualité. Deuxièmement, l'avantage de vitesse est réel mais conditionnel. Une génération de haute qualité nécessite généralement de nombreuses étapes de débruitage, et réduire naïvement ces étapes dégrade fortement la qualité, si bien que la vitesse doit être dépensée avec soin.
Et l'écart de qualité est encore visible, surtout sur les tâches difficiles. Gemini Diffusion obtient 40,4 % contre 56,5 % sur GPQA Diamond, et 69,1 % contre 79,0 % sur Global MMLU face à Flash-Lite, même s'il devance sur certains benchmarks de code et de maths. L'avis honnête d'un ingénieur qui travaille sur des piles d'agents en production mérite d'être cité, car il nomme directement le problème historique :
« [Les anciens modèles de langage à diffusion] étaient rapides à la manière dont une horloge cassée est rapide : peu importe la vitesse à laquelle vous obtenez la mauvaise réponse. » vainkop, « Mercury 2 and the End of Autoregressive Monopoly »
Son verdict pour les équipes d'aujourd'hui est mesuré : c'est un moment où il faut « suivre de près et se préparer à bouger vite », pas un moment où il faut « réécrire votre pile d'agents immédiatement ».
Les modèles qui mènent la charge
Le domaine est passé de curiosité de recherche à produits commercialisés en un éclair. Le signal de financement est puissant : Inception Labs, fondée par Stefano Ermon de Stanford, a levé 50 M$ en novembre 2025 auprès d'une liste stratégique qui comprend Nvidia, M12 de Microsoft, Databricks et Snowflake, plus les business angels Andrew Ng et Andrej Karpathy. Quand les acteurs de l'infrastructure parient, c'est qu'ils estiment que la vitesse est exploitable.
| Modèle | Qui | Statut | Ce qui se distingue |
|---|---|---|---|
| Mercury / Mercury 2 | Inception Labs | API en ligne, 0,25 $ / 0,75 $ par 1M de tokens | Premier LLM à diffusion commercial ; ~1 196 tok/s |
| Gemini Diffusion | Google DeepMind | Expérimental, liste d'attente | Qualité ~Gemini 2.0 Flash-Lite à plusieurs fois la vitesse |
| DiffusionGemma | Google DeepMind | Poids ouverts (Apache 2.0), juin 2026 | Mélange d'experts 26B ; >1 000 tok/s, en dessous de Gemma 4 en qualité |
| LLaDA 8B | ML-GSAI (recherche) | Poids ouverts | MMLU 65,9, rivalisant à peu près avec Llama3 8B |
| Dream 7B | HKU NLP + Huawei | Poids ouverts | Domine les tâches de planification (Sudoku 81,0 vs 21,0 pour Qwen) |
Une rapide clarification, car les noms se ressemblent à s'y méprendre : « Gemini Diffusion » (fermé, liste d'attente) et « DiffusionGemma » (poids ouverts) sont deux sorties différentes de Google. La première est un modèle hébergé expérimental présenté à Google I/O 2025 ; la seconde est un modèle 26B téléchargeable publié le 10 juin 2026 sous licence Apache 2.0, qui génère en débruitant des blocs de 256 tokens en parallèle et reste en dessous du Gemma 4 standard sur tous les benchmarks publiés. La vitesse échangée contre la qualité, ouvertement.
Le schéma récurrent à travers tout cela : un avantage de débit de plus de 10x qui réduit l'écart de qualité aux petite et moyenne échelles (LLaDA rivalisant à peu près avec Llama3 8B, Mercury compétitif sur le code) mais qui se voit encore à la pointe. Le principal cas d'usage aujourd'hui est la génération de code et les boucles agentiques à faible latence, où la vitesse du décodage parallèle se cumule.
Pourquoi les modèles d'IA basés sur la diffusion comptent pour les entreprises
La vitesse n'est pas une métrique de vanité dès lors qu'on place un modèle dans un produit. Le cadrage le plus clair vient de l'expérience en production : dans les systèmes autorégressifs, la latence se cumule en chaîne.
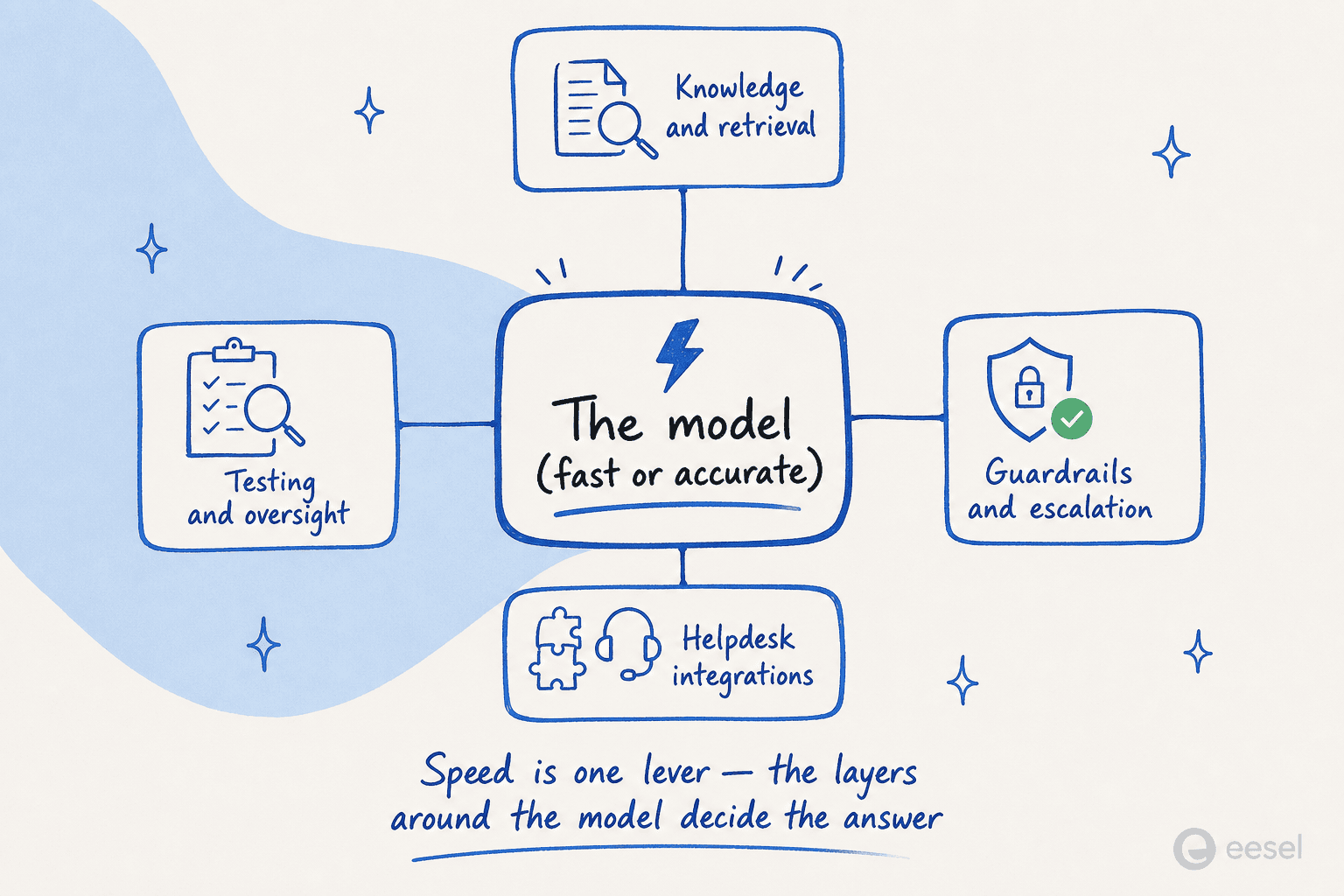
Comme l'a décrit un ingénieur, une seule étape d'agent qui appelle le modèle trois fois (raisonner, planifier, agir) représente trois passes séquentielles ; enchaînez-en quelques-unes et vous êtes à sept ou huit secondes, ce qui « n'est pas un agent en temps réel, c'est un traitement par lots lent ». Une génération plus rapide par étape rend abordables des chaînes d'agents IA plus profondes. Le même article note que les équipes plafonnent actuellement la profondeur des chaînes à trois ou cinq étapes pour rester sous leur SLA ; avec une inférence à la vitesse de la diffusion, des chaînes de dix étapes commencent à paraître viables.
Quelques endroits concrets où la vitesse paie :
- Chat en temps réel et copilotes. Des réponses en moins d'une seconde sont, comme le dit cet ingénieur, « la différence entre l'adoption et l'abandon » pour une couche d'assistant dans un produit SaaS.
- Texte par lots à fort volume. La synthèse, la classification, le reformatage et la traduction sont limités par le débit et parallélisables, ce qui est exactement là où la diffusion brille.
- Assistants de programmation. La nature de remplissage de la diffusion convient aux modifications de code, en générant le début et la fin d'un bloc dans la même passe et en éditant le milieu.
Il y a ensuite le coût. Une génération plus rapide sur le même matériel signifie un coût d'inférence par token plus faible, et le cofondateur d'Inception soutient que l'approche « effectue plus de calculs par unité de mémoire transférée », ce qui ouvre de nouvelles façons de réduire les coûts d'inférence de l'IA sur du matériel plus ancien. Pour les équipes qui font des centaines de milliers d'appels d'agents par jour, cela se cumule. Le tarif public de Mercury 2, 0,25 $ par million de tokens en entrée et 0,75 $ par million en sortie, est véritablement bon marché.
Mais voici la partie que la plupart des articles passent sous silence. Pour la plupart des applications en production, les modèles autorégressifs restent le choix par défaut, et pour de bonnes raisons : ils gèrent le long contexte plus efficacement, ils raisonnent plus profondément (la diffusion fait moins de travail par token, il y a donc moins de place pour « réfléchir ») et ils ont cinq ans d'outillage derrière eux. La démarche pragmatique n'est pas le remplacement mais le routage : envoyer les étapes simples et à haute fréquence (recherche, mise en forme, classification) vers un modèle de diffusion rapide, et réserver les modèles autorégressifs de pointe au raisonnement approfondi. Comparez cela à l'économie des agents IA face aux agents humains et l'attrait est évident : faire davantage de travail bon marché à moindre coût.
Ce que cela signifie pour le support client par IA
Le support client ressemble au cas d'usage parfait pour la diffusion à première vue. Le chat en direct et les agents de support IA sont précisément le scénario à faible latence et orienté utilisateur où l'écart entre une seconde et plusieurs secondes décide si l'expérience semble réactive ou poussive. Un modèle plus rapide devrait signifier des réponses plus vives dans votre chatbot IA.
Le recadrage qui mérite qu'on s'y attarde : pour une équipe de support, l'architecture du modèle importe bien moins que l'orchestration qui l'entoure. Une vraie réponse de support n'est presque jamais une génération à partir de zéro. C'est une réponse ancrée dans votre base de connaissances, l'historique des tickets et vos documents de politique. Cela place la faiblesse de la diffusion, la gestion du long contexte, directement sur le chemin du cas d'usage du support, et cela signifie que la qualité de la récupération, la fraîcheur des connaissances et les garde-fous déterminent la réponse bien plus que le fait que les tokens finaux aient été émis de gauche à droite ou en parallèle.
Pour le dire crûment : un modèle plus rapide branché sur des connaissances obsolètes ou des règles d'escalade faibles ne fait que produire de mauvaises réponses plus vite. Le problème de l'horloge cassée, appliqué au support. C'est aussi pourquoi les problèmes des chatbots IA se résument si rarement au modèle de base et si souvent à l'ancrage, aux tests et aux indicateurs que vous suivez réellement.
Le conseil vraiment utile, donc, c'est de rester agnostique vis-à-vis du modèle. Choisissez une couche qui laisse le modèle sous-jacent s'améliorer en dessous de vous, qu'il s'agisse d'un modèle de diffusion plus rapide l'an prochain ou d'un modèle autorégressif plus intelligent. Les équipes qui tireront le plus profit de la diffusion sont celles qui ont d'abord bâti sur une orchestration solide et ont traité le modèle comme un composant interchangeable.
Essayez eesel
C'est exactement ainsi qu'eesel AI est conçu. Plutôt que de miser sur une seule architecture de modèle, eesel est la couche d'orchestration : il apprend de vos anciens tickets, de vos documents d'aide et de votre outillage dès le premier jour, puis rédige des réponses, trie et fait remonter les cas à travers le helpdesk que vous utilisez déjà, avec un routage basé sur la confiance afin que les réponses peu sûres restent des brouillons plutôt que de partir en ligne.

Le facteur différenciant qui compte pour ce sujet : un mode simulation qui exécute l'agent sur vos anciens tickets afin que vous puissiez voir la couverture et combler les lacunes avant la mise en ligne, ce qui est la façon d'empêcher un modèle rapide d'expédier avec assurance de mauvaises réponses. Il fonctionne sur plus de 100 intégrations et plus de 80 langues, de sorte que quel que soit le modèle le plus rapide ou le plus intelligent l'an prochain, votre configuration de support continue de fonctionner. Vous pouvez essayer eesel gratuitement, sans carte bancaire.
Questions fréquentes
Qu'est-ce qu'un modèle d'IA basé sur la diffusion, en termes simples ?
En quoi les modèles de langage à diffusion diffèrent-ils des LLM autorégressifs comme GPT ou Claude ?
Les modèles d'IA basés sur la diffusion sont-ils réellement plus rapides que les LLM classiques ?
Mon entreprise devrait-elle passer à un modèle de langage à diffusion ?
L'architecture du modèle a-t-elle de l'importance pour le support client par IA ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








