
Ce pour quoi vous payez vraiment
La principale erreur que font les gens avec les tarifs Hugging Face est de considérer le prix du plan de compte comme le coût total. Ce n'est pas le cas. Comme le formule le guide des coûts 2026 de Metacto : "Ces plans ne couvrent pas le coût total de l'exécution de vos modèles - pensez-y comme au prix d'entrée dans un parc d'attractions ; vous devez quand même payer les attractions."
Le plan de compte - Gratuit, PRO, Team, Enterprise - est votre abonnement Hub. Il couvre l'hébergement des dépôts, les allocations de stockage, les fonctionnalités de collaboration et les contrôles de gouvernance. L'exécution des modèles fait l'objet d'une facture séparée, répartie sur trois systèmes distincts : Spaces (hébergement de démos et d'applications avec GPU optionnel), Inference Providers (routage serverless vers des API de modèles tiers), et Inference Endpoints (infrastructure dédiée et toujours active que vous contrôlez).
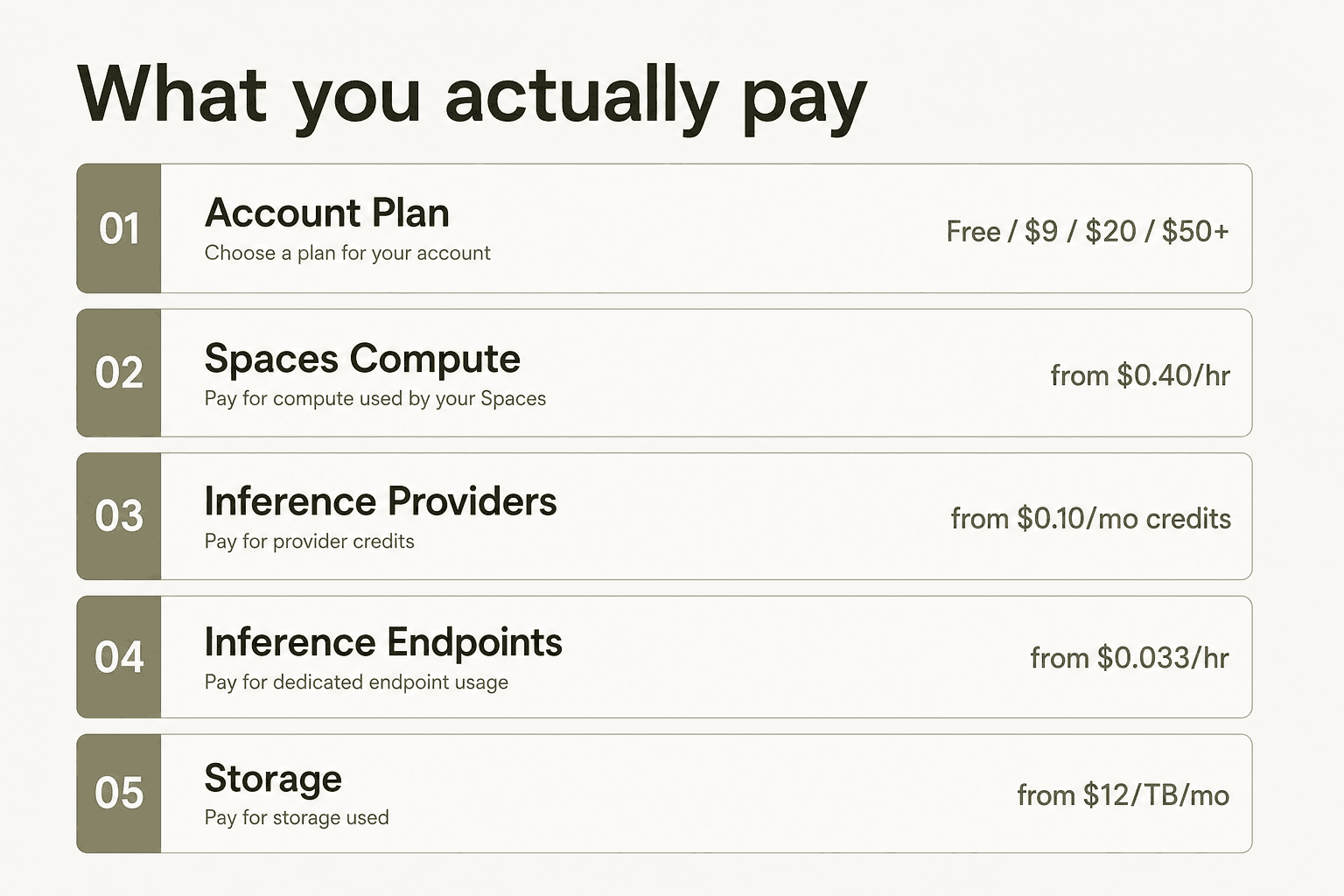
Comprendre cette séparation est indispensable pour lire correctement tout tarif Hugging Face.
Plans de compte
Gratuit
Le niveau gratuit est plus généreux que la plupart des gens ne l'imaginent. Vous accédez à plus de 2 millions de modèles, 500 000+ jeux de données et plus d'un million de Spaces sur le Hub, 100 Go de stockage de dépôt privé, l'accès ZeroGPU communautaire et 0,10 $/mois de crédits Inference Provider. Ce crédit ne va pas loin en production, mais il suffit pour de petites expériences.
Ce que vous n'obtenez pas : pas de SSO, pas de journaux d'audit, pas de groupes de ressources, pas de file d'attente prioritaire. Les limites de débit sur l'Inference API sont nettement plus strictes que sur les plans payants. Le niveau gratuit convient parfaitement à quiconque apprend l'écosystème ou réalise des expériences occasionnelles - pas aux équipes qui déploient des services en production.
PRO - 9 $/mois
C'est la mise à niveau la plus évidente sur la page de tarification. Pour 9 $/mois, PRO vous offre :
- 8× votre quota ZeroGPU avec priorité en tête de file (40 min/jour contre 5 min/jour en gratuit)
- 1 To de stockage privé (contre 100 Go)
- 2 $/mois de crédits Inference Provider (20× le montant gratuit)
- Spaces Dev Mode - accès SSH et VS Code dans votre Space pour une itération rapide sans redéploiement
- Visualiseur de jeux de données privés pour travailler avec des données d'entraînement non publiques
- Accès anticipé aux nouvelles fonctionnalités Hub et un badge PRO
L'augmentation du quota ZeroGPU est le principal attrait. ZeroGPU donne à chaque utilisateur l'accès à un pool partagé de GPU Nvidia RTX Pro 6000 Blackwell sans frais horaires - mais les utilisateurs du niveau gratuit atteignent leur quota en environ 5 minutes de temps GPU par jour. PRO pousse ce quota à 40 minutes avec une planification prioritaire.
SaaSLens a noté Hugging Face 4,7/5 dans sa revue de mars 2026, le qualifiant de « l'un de nos meilleurs choix pour les fondateurs solo », et soulignant spécifiquement que le plan PRO offre « un accès GPU de niveau entreprise pour le prix de deux cafés par mois ». C'est une évaluation juste. Nous opterions pour PRO dès que nous avons besoin d'exécuter des démos reposant sur GPU sans payer pour une infrastructure dédiée.
Team - 20 $/utilisateur/mois
Team est le premier plan au niveau de l'organisation. La facturation passe au mode par siège : chaque membre de votre organisation Hugging Face paie 20 $/mois. En plus des avantages PRO pour tous les membres de l'organisation, vous obtenez :
- 12 To de stockage public de base + 1 To/siège public + 1 To/siège privé
- 2 $/mois de crédits Inference Provider par siège (mutualisés au sein de l'organisation)
- Contrôles de facturation au niveau de l'organisation pour Inference Providers - définissez des limites de dépenses, désactivez des fournisseurs spécifiques
- Support prioritaire de l'équipe Hugging Face
- Tous les membres bénéficient de l'augmentation du quota ZeroGPU 8×
Les contrôles de facturation pour Inference Providers sont réellement utiles pour les équipes de recherche où des membres pourraient accidentellement accumuler des coûts sur des modèles frontier coûteux. Les administrateurs peuvent plafonner les dépenses mensuelles de l'organisation et désactiver des fournisseurs spécifiques.
Une mise en garde importante : Team n'inclut pas le SSO, les journaux d'audit ou les groupes de ressources. Ces fonctionnalités sont exclusivement Enterprise. Si votre équipe doit se connecter à votre fournisseur d'identité d'entreprise ou générer des rapports de conformité, Team ne suffira pas quelle que soit la taille de l'équipe.
Enterprise - à partir de 50 $/utilisateur/mois
Enterprise est le niveau où la pile de gouvernance se débloque. Le montant de 50 $/utilisateur/mois est le plancher - les grands contrats avec des engagements de volume, une facturation annuelle et des SLA personnalisés sont négociés avec l'équipe commerciale de Hugging Face. Les clients Enterprise notables incluent NVIDIA, Google, OpenAI, Meta, Salesforce, IBM Research, Shopify et Roblox.
Les fonctionnalités qui poussent les équipes vers ce niveau :
SSO connecte votre fournisseur d'identité - Okta, Azure AD, Google Workspace, ou tout IdP conforme SAML/OpenID Connect. Enterprise Plus ajoute SCIM pour le provisionnement automatisé des utilisateurs.
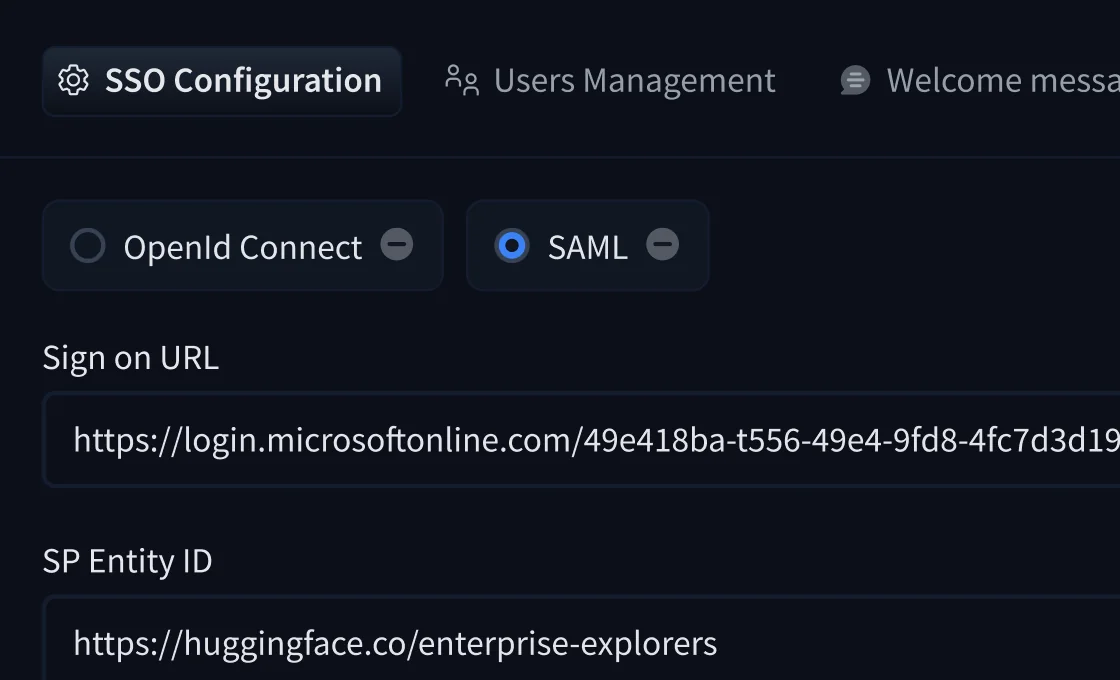
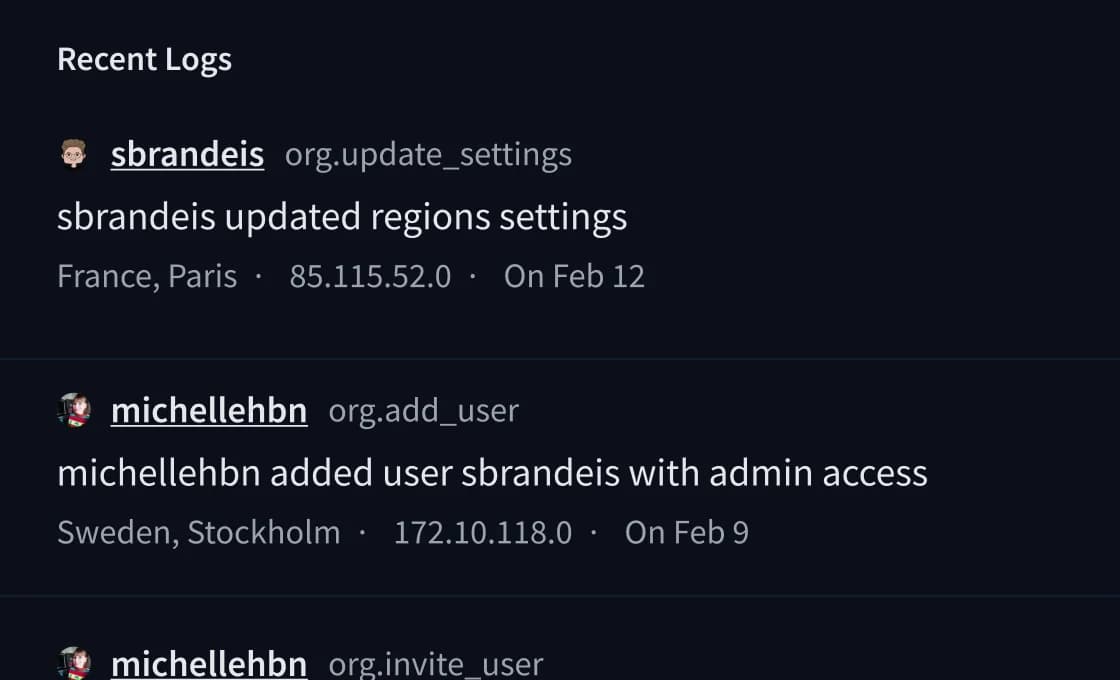
Les journaux d'audit enregistrent chaque action de l'organisation - qui a modifié quoi, depuis où, à quel moment - avec attribution d'utilisateur, adresse IP et localisation. Utile pour les revues SOC 2 Type II et la documentation de conformité RGPD.
Les groupes de ressources permettent aux administrateurs d'assigner des dépôts à des groupes nommés et d'accorder un accès READ, WRITE ou CONTRIBUTOR par utilisateur - utile pour séparer les espaces de travail de recherche, de production et d'expérimentation au sein d'une seule organisation.
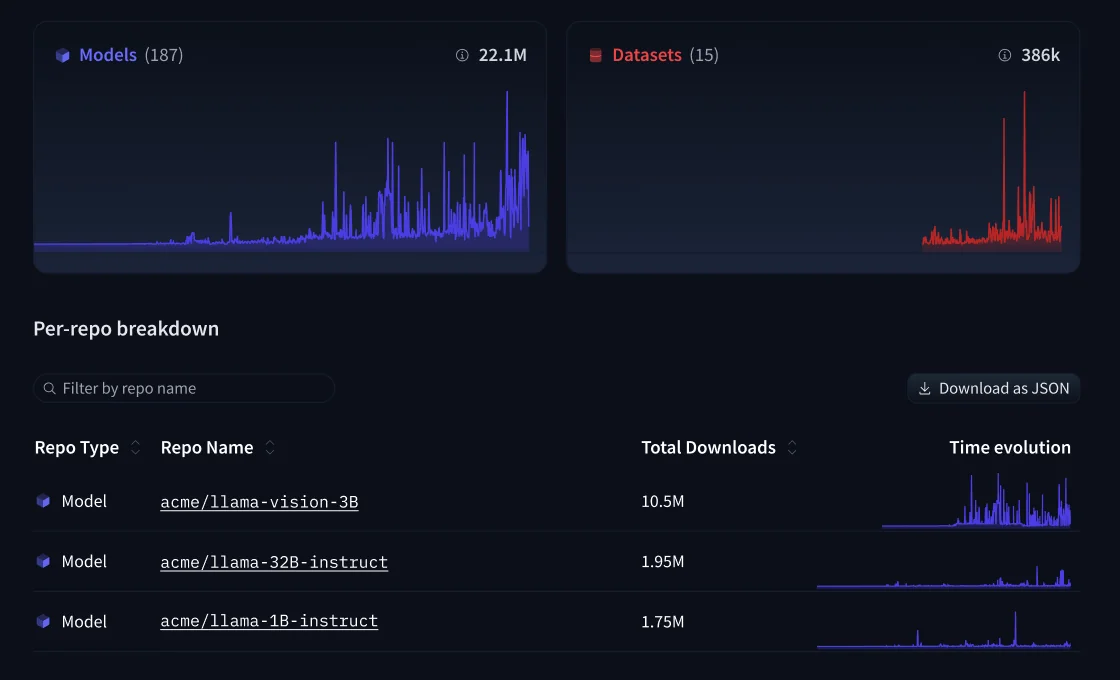
Les analyses de dépôt affichent les tendances de téléchargement, l'utilisation des modèles et l'accès aux jeux de données à travers l'organisation dans un tableau de bord unique - pratique pour comprendre quels modèles internes sont réellement utilisés.
La résidence des données vous permet de choisir et d'auditer la région géographique où vos dépôts sont stockés - pertinent pour les exigences RGPD et de souveraineté des données. Enterprise Plus ajoute des contrôles de sécurité réseau et des listes blanches d'IP.
Le stockage pour Enterprise est conséquent : 200 To de base public + 1 To/siège, pouvant atteindre 1 Po pour les grands contrats.
Comparaison des plans en un coup d'œil
| Gratuit | PRO | Team | Enterprise | |
|---|---|---|---|---|
| Prix | 0 $ | 9 $/mois | 20 $/utilisateur/mois | 50 $/utilisateur/mois et plus |
| Stockage privé | 100 Go | 1 To | 1 To/siège | 1 To/siège |
| Stockage public | Au mieux | Jusqu'à 10 To | 12 To + 1 To/siège | 200 To + 1 To/siège |
| Crédits d'inférence | 0,10 $/mois | 2 $/mois | 2 $/siège/mois | 2 $/siège/mois |
| Quota ZeroGPU | Standard | 8× + priorité | 8× (tous les membres) | 8× (tous les membres) |
| Spaces Dev Mode | Non | Oui | Oui | Oui |
| Visualiseur de jeux de données privés | Non | Oui | Oui | Oui |
| Contrôles de facturation org | Non | Non | Oui | Oui |
| SSO | Non | Non | Non | Oui |
| Journaux d'audit | Non | Non | Non | Oui |
| Groupes de ressources | Non | Non | Non | Oui |
| Analyses de dépôt | Non | Non | Non | Oui |
| Résidence des données | Non | Non | Non | Oui |
| Support prioritaire | Non | Non | Oui | Oui (dédié) |
| Contrats annuels | Non | Non | Non | Oui |
Tarification du matériel Spaces
Les Spaces sont des applications ML interactives et des démos hébergées sur le Hub. Le niveau CPU Basic est gratuit ; les niveaux GPU sont facturés à la demande à l'heure, pendant que le Space est en cours d'exécution.
| Matériel | vCPU | RAM | Accélérateur | VRAM | Horaire |
|---|---|---|---|---|---|
| CPU Basic | 2 | 16 Go | - | - | Gratuit |
| CPU Upgrade | 8 | 32 Go | - | - | 0,03 $ |
| ZeroGPU | dynamique | dynamique | RTX Pro 6000 Blackwell | jusqu'à 96 Go | Gratuit* |
| T4 - small | 4 | 15 Go | T4 | 16 Go | 0,40 $ |
| T4 - medium | 8 | 30 Go | T4 | 16 Go | 0,60 $ |
| L4 (1×) | 8 | 30 Go | L4 | 24 Go | 0,80 $ |
| L4 (4×) | 48 | 186 Go | L4 | 96 Go | 3,80 $ |
| L40S (1×) | 8 | 62 Go | L40S | 48 Go | 1,80 $ |
| L40S (4×) | 48 | 382 Go | L40S | 192 Go | 8,30 $ |
| L40S (8×) | 192 | 1 534 Go | L40S | 384 Go | 23,50 $ |
| A10G - small | 4 | 15 Go | A10G | 24 Go | 1,00 $ |
| A10G - large | 12 | 46 Go | A10G | 24 Go | 1,50 $ |
| A100 - large | 12 | 142 Go | A100 | 80 Go | 2,50 $ |
| 4× A100 | 48 | 568 Go | A100 | 320 Go | 10,00 $ |
| 8× A100 | 96 | 1 136 Go | A100 | 640 Go | 20,00 $ |
*ZeroGPU est gratuit dans les limites du quota. Les membres PRO et Team/Enterprise obtiennent 8× le quota standard. Le dépassement est facturé à 1 $ par 10 minutes.
Les Spaces entrent en veille après 48 heures d'inactivité sur le niveau CPU gratuit. Les Spaces GPU payants restent actifs jusqu'à ce que vous les mettiez en pause - un T4-small laissé actif pendant 30 jours coûte 288 $. Il n'y a pas d'arrêt automatique.
À noter : des subventions GPU communautaires sont disponibles pour les projets parallèles qualifiés. Si vous publiez de la recherche ouverte et avez besoin d'un accès GPU persistant, cela vaut la peine de postuler avant de vous engager dans un niveau payant.
Inference Providers (serverless)
Inference Providers vous permet de router des appels API vers plus de 45 000 modèles auprès de plus de 18 partenaires d'inférence - Groq, Fireworks, Mistral, Cohere, Nebius, SambaNova, et d'autres - via un point de terminaison unifié sur router.huggingface.co/v1. Hugging Face répercute les tarifs des fournisseurs sans majoration.
Crédits mensuels par plan, appliqués lors du routage via Hugging Face :
| Plan | Crédits mensuels |
|---|---|
| Gratuit | 0,10 $ |
| PRO | 2,00 $ |
| Team / Enterprise (par siège) | 2,00 $ |
Une fois les crédits épuisés, l'utilisation passe en paiement à l'usage. Vous pouvez soit laisser HF facturer votre compte (plus simple, les crédits mensuels s'appliquent), soit apporter votre propre clé API de fournisseur et payer le fournisseur directement (les crédits HF ne s'appliquent pas, mais vous contrôlez directement la relation de facturation).
Les organisations Team et Enterprise peuvent définir des limites de dépenses et désactiver des fournisseurs spécifiques depuis les paramètres de l'organisation - utile pour maîtriser les coûts quand des membres individuels exécutent des modèles frontier coûteux.
Hugging Face maintient également son propre backend hf-inference - l'original « Inference API (serverless) » - désormais centré sur les tâches liées au CPU comme les embeddings, la classification de texte et les modèles plus petits (BERT, GPT-2). L'exécution de Llama 3.1 70B ou de tout LLM de génération actuelle est routée via un fournisseur tiers.
Inference Endpoints (déploiement dédié)
Inference Endpoints est destiné aux équipes qui ont besoin d'une latence prévisible et d'une infrastructure dédiée - pas de démarrages à froid, pas de file d'attente partagée, des déploiements autoscaling sur AWS, Azure ou GCP. Vous choisissez le matériel, Hugging Face gère le conteneur et la mise à l'échelle.
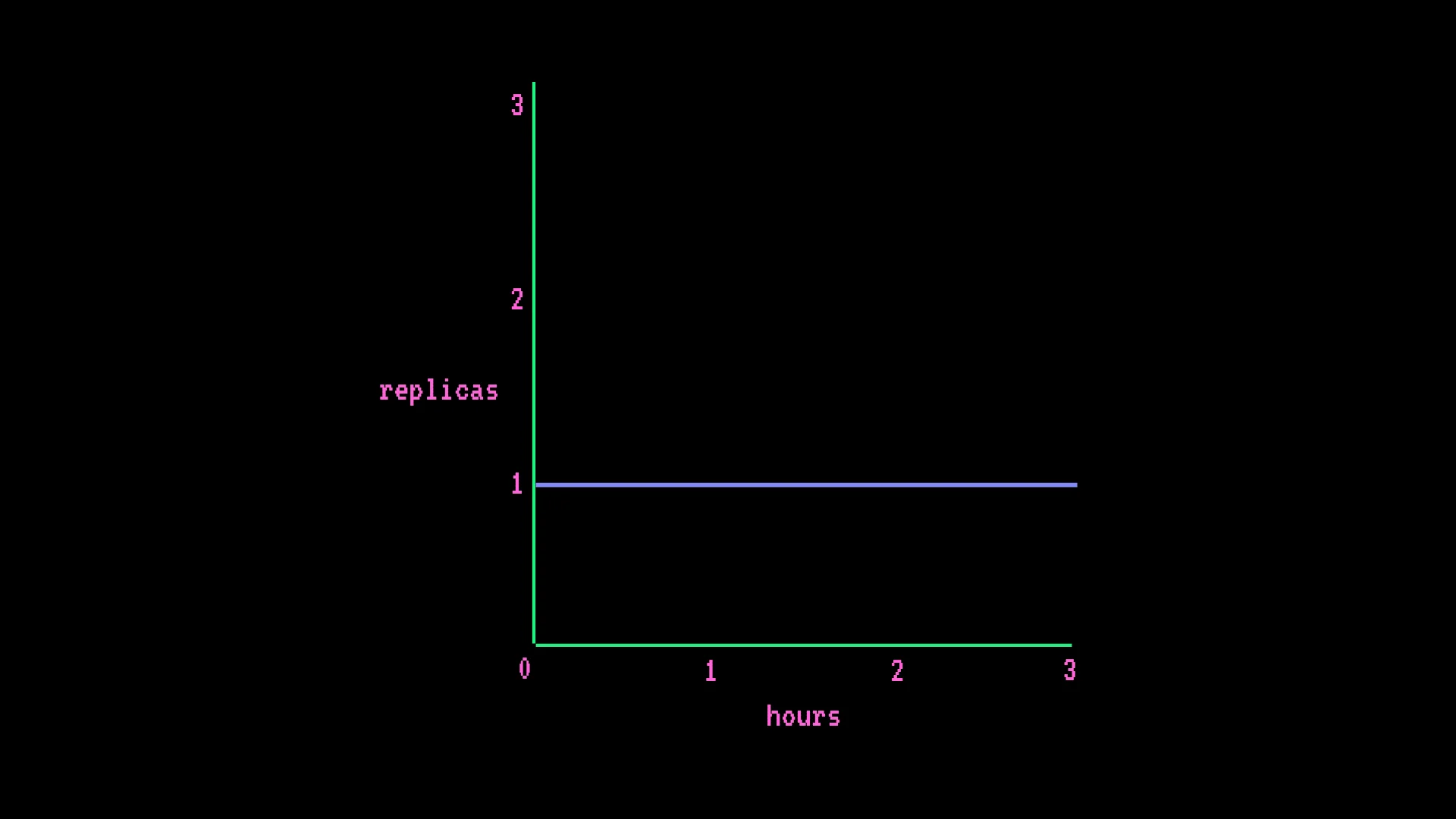
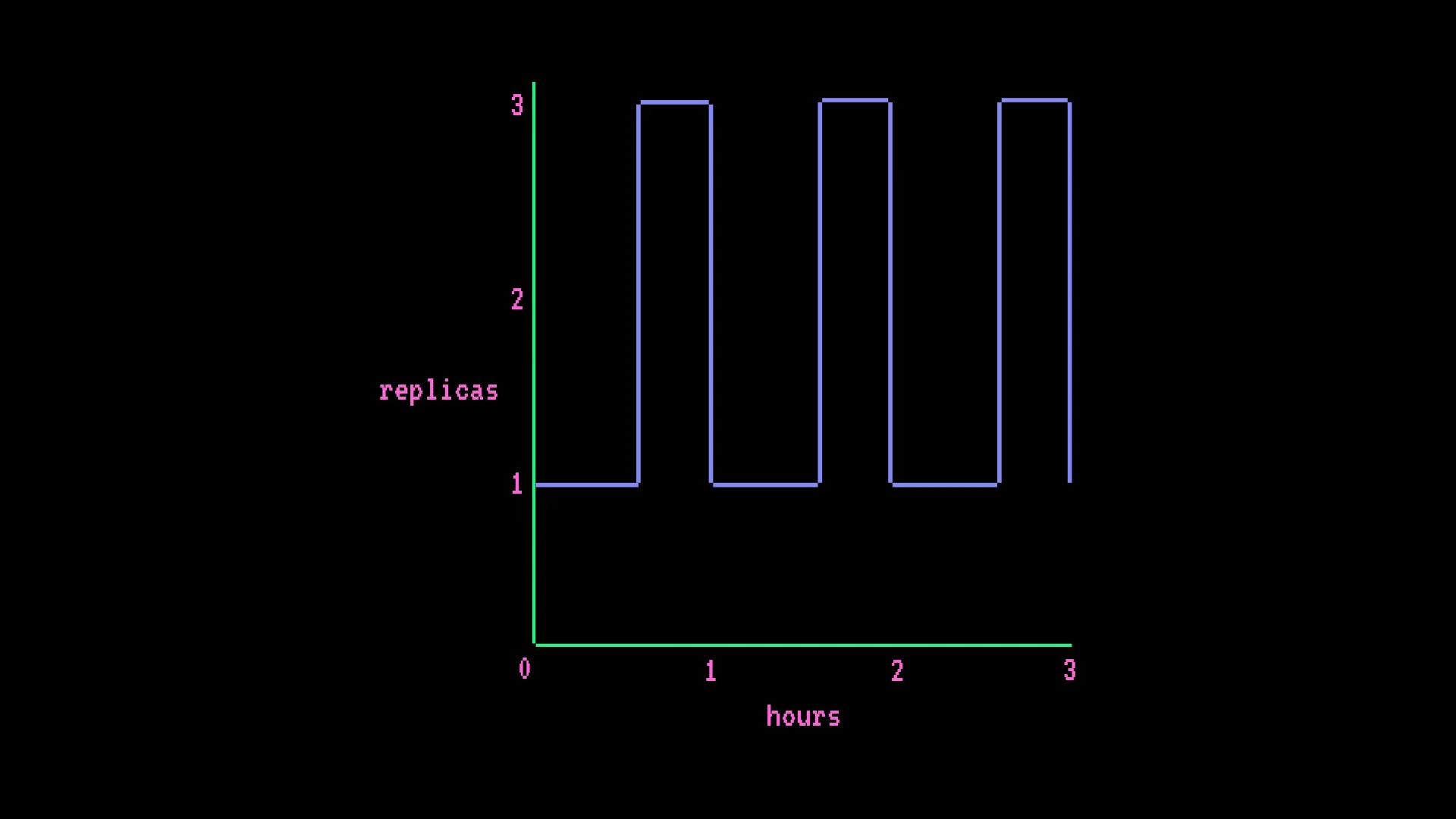
Le modèle de facturation est celui qui risque le plus de vous surprendre. Les Endpoints sont facturés à la minute au tarif de l'instance, multiplié par le nombre de réplicas actifs - indépendamment du volume de requêtes. Il ne s'agit pas d'une facturation par requête ou par token.
Tarification des instances GPU (AWS)
| GPU | Quantité | VRAM | Horaire |
|---|---|---|---|
| T4 | 1 | 14 Go | 0,50 $ |
| T4 | 4 | 56 Go | 3,00 $ |
| L4 | 1 | 24 Go | 0,80 $ |
| L40S | 1 | 48 Go | 1,80 $ |
| A100 | 1 | 80 Go | 2,50 $ |
| A100 | 4 | 320 Go | 10,00 $ |
| A100 | 8 | 640 Go | 20,00 $ |
| H100 | 1 | 80 Go | 4,50 $ |
| H100 | 4 | 320 Go | 18,00 $ |
| H100 | 8 | 640 Go | 36,00 $ |
| H200 | 1 | 141 Go | 5,00 $ |
| B200 | 1 | 179 Go | 9,25 $ |
| B200 | 8 | 1 432 Go | 74,00 $ |
| RTX PRO 6000 | 1 | 96 Go | 2,75 $ |
Les options GCP et Azure sont également disponibles avec des tarifs légèrement différents selon le niveau de matériel. Le tableau complet incluant les instances CPU et accélérateurs (Inferentia2, TPU v5e) se trouve sur la page de tarification Inference Endpoints.
Exemples de coûts concrets
Endpoint CPU toujours actif - AWS 2 vCPU, 1 réplica :
- 0,067 $/h × 730 heures = ~49 $/mois
Endpoint GPU avec autoscaling - AWS T4 x1, min 1 réplica, max 3, avec des pics de 15 minutes par heure :
- 0,50 $ × (730 h × 1 + 182,5 h × 2 réplicas supplémentaires) = 547,50 $/mois
La formule de facturation : tarif horaire × ((heures × réplicas min) + (heures de montée en charge × réplicas supplémentaires))
Ce modèle toujours actif est la source la plus courante de charges surprises. Une question sur les forums Hugging Face qui a attiré plus de 3 700 vues illustre bien la confusion :
« Je suis un peu perdu concernant le modèle de tarification. Disons que je déploie un modèle sur une machine CPU Basic (0,06 $/heure). Est-ce que je paye tant que le modèle est déployé ou est-ce que je paye uniquement pour le temps de calcul (par exemple, je fais 2 requêtes et chaque requête prend 10 secondes, donc je paye uniquement pour les 20 secondes) ? »
La réponse est : vous payez tant que le modèle est déployé, pas par requête. Cette distinction surprend beaucoup de monde.
Tarification du stockage
Le stockage sur le Hub est sa propre couche de facturation, facturée par To et par mois. Les tarifs varient selon le volume et le caractère public ou privé des dépôts :
| Volume | Tarif public | Tarif privé |
|---|---|---|
| Base | 12 $/To/mois | 18 $/To/mois |
| 50 To+ | 10 $/To/mois | 16 $/To/mois |
| 200 To+ | 9 $/To/mois | 14 $/To/mois |
| 500 To+ | 8 $/To/mois | 12 $/To/mois |
La sortie de données et la livraison CDN sont incluses sans frais supplémentaires - ce qui se compare favorablement à AWS S3 à environ 23 $/To/mois avec des frais de sortie séparés.
Chaque plan payant inclut un stockage de base significatif avant que les frais par To s'appliquent :
- PRO : jusqu'à 10 To public + 1 To privé
- Team : 12 To de base public + 1 To/siège public + 1 To/siège privé
- Enterprise : 200 To de base public + 1 To/siège, pouvant atteindre 1 Po pour les grands contrats
Options de stockage public supplémentaires pour les plans payants : 1 To à 12 $/mois, 5 To à 60 $/mois, 10 To à 120 $/mois, 50 To à 500 $/mois. Le stockage privé au-delà des limites incluses est facturé à l'usage à partir de 18 $/To/mois.
Les pièges de facturation à connaître
Il n'y a pas de plafonds de dépenses intégrés pour Spaces ou Inference Endpoints. Les dépenses Inference Provider peuvent être plafonnées au niveau de l'organisation sur Team et Enterprise, mais les Spaces GPU et les endpoints dédiés n'ont pas de coupe-circuit automatique. Un fil de forum d'avril 2025 décrivait une charge qui est passée de 78,22 $ à 519,24 $ du jour au lendemain :
« Il y a une augmentation soudaine de ~1 100 heures en moins de 24 heures, ce qui est techniquement impossible. Même avec une utilisation GPU continue : Maximum possible = 24 heures/jour par instance. Ce pic impliquerait des dizaines d'instances parallèles, ce qui n'est pas le cas. »
Qu'il s'agisse d'un bug de facturation ou d'un processus incontrôlé, l'utilisateur n'avait aucun moyen de limiter son exposition au préalable. La leçon : définissez des politiques de pause manuelle pour les Spaces GPU et maintenez le nombre minimum de réplicas des Inference Endpoints aussi bas que possible.
Les tarifs horaires et mensuels ne se réconcilent pas toujours clairement. Un fil d'octobre 2024 a relevé une vraie incohérence : le niveau de stockage persistant Medium est indiqué à 0,03 $/h, ce qui implique ~21,60 $/mois - mais la charge mensuelle réelle est de 25 $. Vérifiez les totaux mensuels plutôt que d'extrapoler à partir des chiffres horaires.
Les Inference Endpoints sont facturés en mode toujours actif. Si le nombre minimum de réplicas de votre endpoint est 1, vous payez le tarif matériel 24h/24, 7j/7, quelle que soit le volume de trafic. Cela surprend les équipes habituées aux modèles de tarification serverless où le temps d'inactivité ne coûte rien.
Comparaison des coûts de calcul
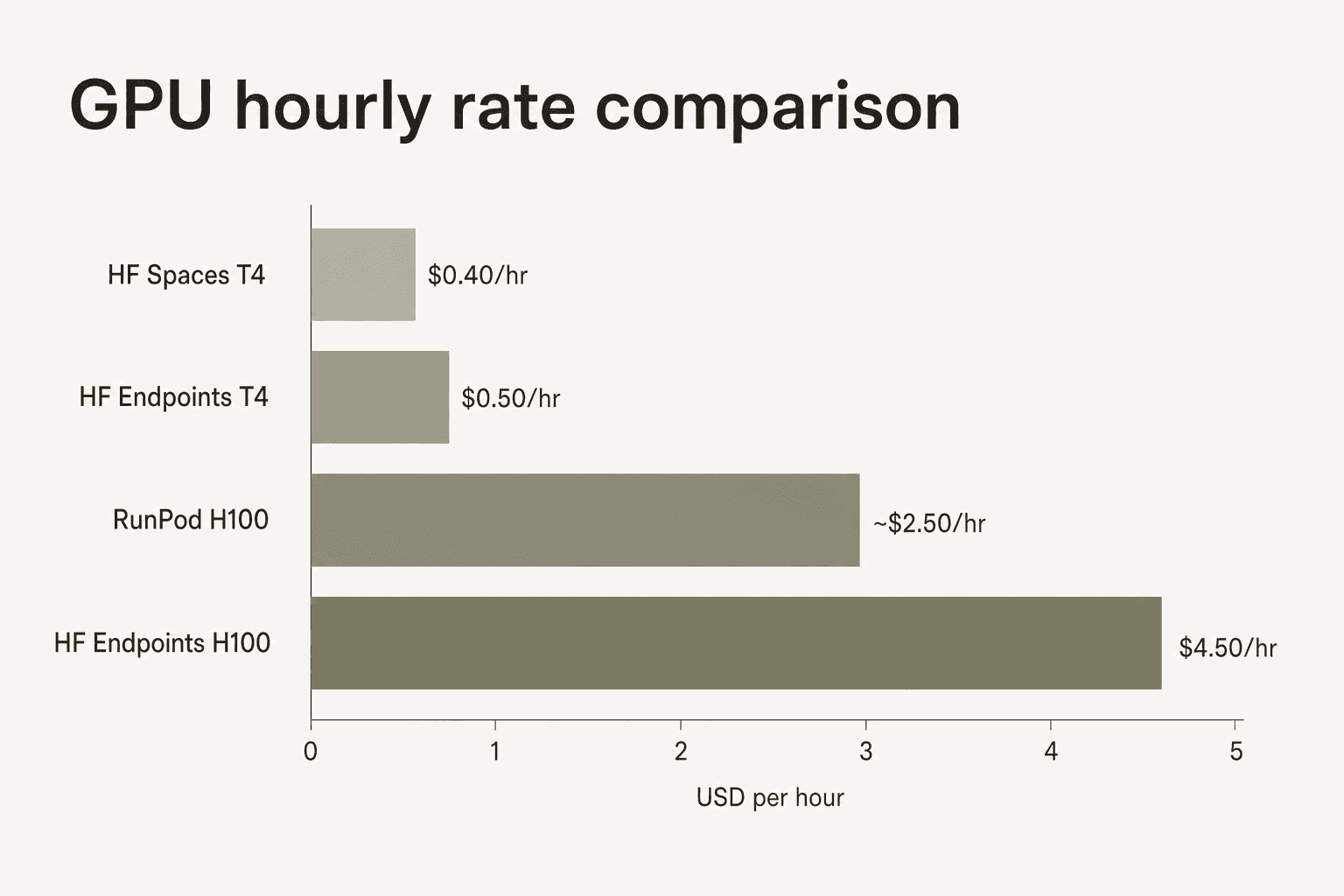
Les Inference Endpoints Hugging Face comportent une prime de commodité par rapport aux fournisseurs GPU génériques. Un H100 sur les Dedicated Endpoints HF coûte 4,50 à 10 $/h selon la région cloud ; le même matériel chez RunPod coûte 2 à 3 $/h. Les données des revues communautaires signalent systématiquement cet écart - « les coûts de calcul GPU s'accumulent rapidement » revient comme une critique récurrente - tout en notant que l'intégration Hub, la disponibilité des modèles et l'absence de gestion d'infrastructure justifient la prime pour les équipes qui souhaitent rester dans l'écosystème HF.
Pour les charges de travail liées au CPU (embeddings, classification, modèles plus petits), le calcul est différent - les tarifs HF sont compétitifs et l'infrastructure gérée économise du temps d'ingénierie. La prime apparaît le plus nettement pour les GPU hauts de gamme, où Together AI et des fournisseurs similaires offrent de meilleures économies de calcul brutes pour les équipes qui n'ont pas besoin du registre de modèles et des outils de déploiement du Hub.
L'Inference Playground est le moyen le plus simple d'essayer des modèles avant de s'engager dans un niveau de calcul - il vous permet de tester auprès de fournisseurs via l'interface web sans configuration de facturation.
Quel plan et quel produit correspond à votre situation
Gratuit - explorer des modèles, réaliser des expériences occasionnelles, apprendre l'écosystème. Le registre de modèles et l'accès ZeroGPU le rendent vraiment utile sans rien dépenser.
PRO à 9 $/mois - développement individuel actif où vous avez besoin de l'augmentation du quota ZeroGPU, de plus de stockage privé ou de Spaces Dev Mode. Difficile de trouver meilleur rapport qualité-prix pour quiconque fait régulièrement du ML.
Team à 20 $/utilisateur/mois - vraies équipes collaborant sur des modèles ou des jeux de données. Les contrôles de facturation au niveau de l'organisation pour Inference Providers et le stockage mutualisé commencent à avoir de l'importance à cette échelle.
Enterprise à 50 $/utilisateur/mois et plus - SSO, journaux d'audit ou exigences de conformité. Ne payez pas Enterprise parce que votre équipe est grande - payez-le quand vous avez réellement besoin de la pile de gouvernance.
Inference Providers - accès serverless pratique aux modèles tiers aux tarifs des fournisseurs, sans infrastructure à gérer. Les crédits de 2 $/mois n'iront pas loin en production, mais l'API unifiée est idéale pour l'évaluation et le prototypage.
Inference Endpoints - matériel dédié avec une latence prévisible et autoscaling. Prévoyez une facturation toujours active, définissez des réplicas minimum de manière conservatrice et mettez en place des politiques de pause manuelle. Pas la valeur par défaut idéale pour les déploiements à faible trafic ou expérimentaux.
Si vous comparez l'écosystème plus large, les alternatives à Hugging Face couvre sept autres plateformes qui méritent évaluation pour le déploiement de modèles.
Essayez eesel
Si vous envisagez Hugging Face pour l'IA dans le service client - automatiser les réponses aux tickets, créer un agent de helpdesk, dévier les requêtes répétitives - eesel offre un chemin plus direct. Plutôt que de gérer une infrastructure d'hébergement de modèles répartie sur cinq surfaces de facturation, eesel déploie des agents IA entièrement autonomes directement dans Zendesk, Slack, Freshdesk et plus de 100 autres outils. Vous briefez l'agent en langage naturel, il résout les tickets de bout en bout, et la tarification s'adapte à l'utilisation à 0,40 $ par tâche plutôt qu'en heures de calcul. Pas de gestion GPU, pas de pics de facturation, pas d'Inference Endpoints à configurer.
Commencez avec 50 $ de crédits gratuits - sans carte bancaire →
Questions fréquentes
Combien coûte Hugging Face ?
Hugging Face est-il gratuit ?
Qu'est-ce qu'inclut Hugging Face PRO ?
Combien coûte Hugging Face Enterprise ?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








Comment fonctionne la facturation des Inference Endpoints Hugging Face ?