
Je pilote l'IA sur de vraies files de support — voici ma lecture honnête
Je vais commencer là où la plupart des explications de modèles ne commencent pas, parce que c'est la partie qui compte vraiment. J'ai passé des années à observer des modèles de frontière affronter des files de support réelles et désordonnées, et le schéma ne change jamais : le modèle est rarement la partie difficile.
Quelques chiffres issus de nos propres déploiements pour l'illustrer. Un client, Gridwise, a vu eesel résoudre 73 % de ses demandes de niveau 1 le premier mois, avec des résultats pendant un essai de 7 jours. Un autre, Smava, gère un agent Zendesk entièrement automatisé traitant plus de 100 000 tickets en allemand par mois. Rien de tout cela ne venait du choix du modèle le plus intelligent. Cela venait de l'entraînement sur des tickets résolus, du routage par niveau de confiance et de la simulation sur l'historique réel avant la mise en production.
Alors quand un nouveau Opus sort, la question qui m'importe n'est pas « est-il plus intelligent sur un benchmark ». C'est « est-ce que cela change ce que j'enverrais réellement dans la boîte de réception d'un client ». Regardons Opus 4.8 sous cet angle.
Qu'est-ce que Claude Opus 4.8 ?
Claude Opus 4.8 est le dernier modèle de la famille Opus d'Anthropic, le niveau haute capacité de Claude. Anthropic l'a publié le 28 mai 2026 et le présente comme un « collaborateur plus efficace » qui « s'appuie sur Opus 4.7 avec des améliorations sur l'ensemble des benchmarks ». Dans l'API, vous l'appelez avec l'identifiant de modèle claude-opus-4-8.
Les spécifications principales se résument facilement : une fenêtre de contexte de 1M tokens au prix standard, jusqu'à 128k tokens en sortie, et une réflexion adaptative que le modèle contrôle lui-même (il n'y a plus de bascule de réflexion étendue séparée à gérer). Il lit le texte et les images, gère plus de 80 langues, et ses données d'entraînement vont jusqu'en janvier 2026 (vue d'ensemble des modèles).
La présentation qu'Anthropic fait de cette évolution est d'un discret rafraîchissant. L'annonce la qualifie d'« amélioration modeste mais tangible de son prédécesseur », ce qui correspond également au titre du fil Hacker News. Si vous vous souvenez des grands sauts générationnels, ce n'en est pas un. C'est une version de polissage et de corrections, et c'est très bien ; les corrections sont la partie intéressante.
Les nouveautés d'Opus 4.8
Quelques changements méritent d'être connus, surtout si vous choisissez un modèle sur lequel développer plutôt que simplement discuter.
L'honnêteté a reçu une vraie mise à niveau. Anthropic appelle cela « l'une des améliorations les plus importantes », et c'est celle pour laquelle je paierais vraiment. On rapporte qu'Opus 4.8 est environ quatre fois moins susceptible qu'Opus 4.7 de laisser passer des défauts dans son propre code sans les signaler, et il est plus enclin à indiquer l'incertitude plutôt que d'inventer une réponse avec assurance. Pour quiconque déploie l'IA dans un contexte où une mauvaise réponse a un coût, « vous dit quand il n'est pas sûr » vaut plus qu'un point supplémentaire sur un benchmark de codage.
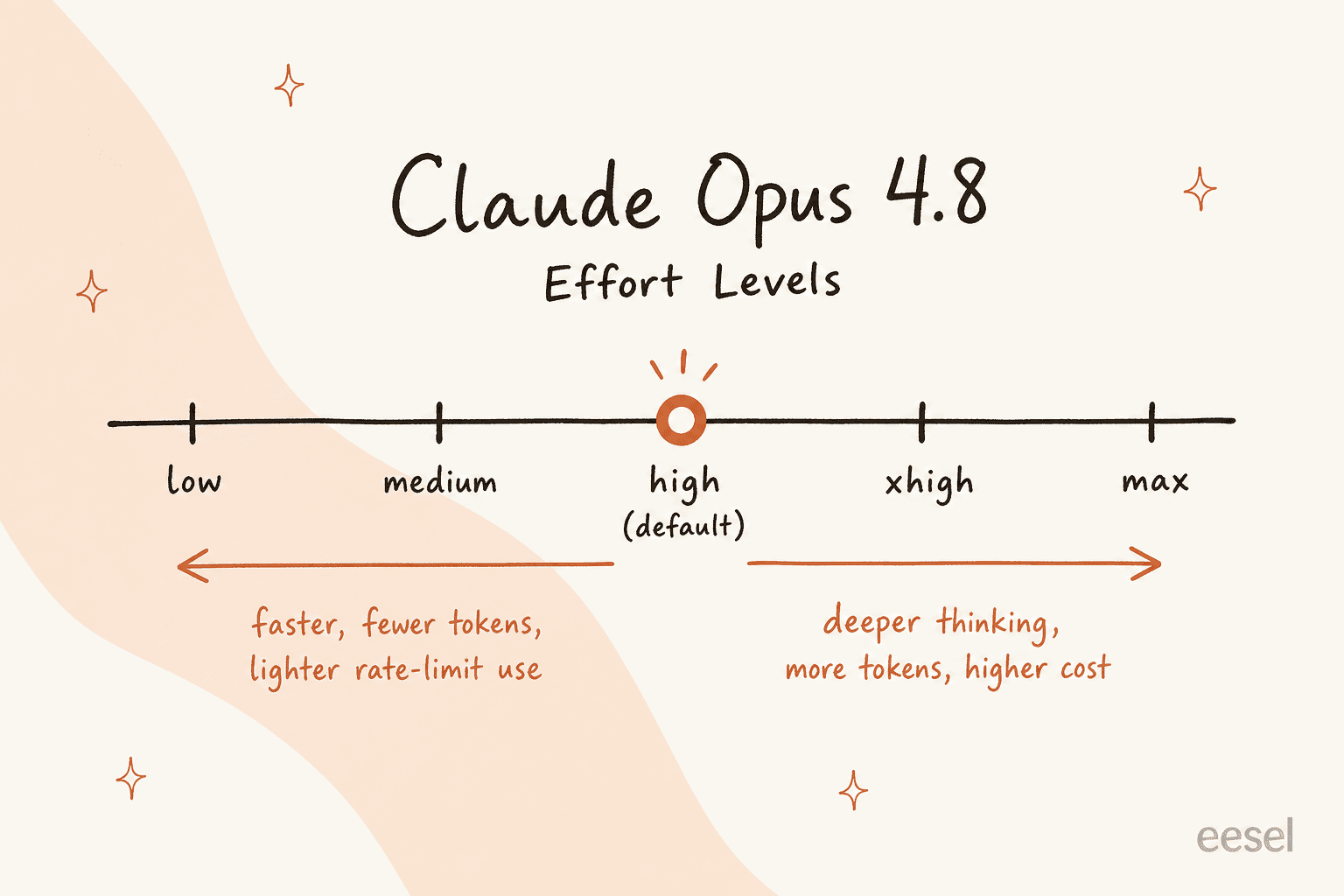
Un contrôle d'effort. Il y a désormais un réglage qui définit l'intensité du travail du modèle sur une réponse, de low à max (avec xhigh entre high et max). La valeur par défaut est high. Montez-le pour un raisonnement plus profond, baissez-le pour la vitesse et une utilisation plus légère. Le compromis est réel et vaut la peine d'être compris avant de l'intégrer dans quoi que ce soit.
Workflows dynamiques dans Claude Code. Dans Claude Code, Opus 4.8 peut planifier un travail, déployer des centaines de sous-agents parallèles en une session, puis vérifier leur sortie avant de rendre compte — orienté vers des travaux à l'échelle d'un codebase tels que des migrations sur des centaines de milliers de lignes. Si vous utilisez les sous-agents de Claude Code, c'est la fonctionnalité à essayer.
Instructions système en cours de tâche. Pour les développeurs, l'API Messages accepte désormais des entrées system à l'intérieur du tableau de messages, ce qui permet de mettre à jour les instructions, les permissions ou les budgets de tokens en cours d'exécution sans casser le cache de prompt. Petit changement, vraiment pratique si vous créez des agents.
Une voix plus chaleureuse. Les premiers testeurs la décrivent comme plus facile à collaborer et plus efficace pour maintenir le contexte et le style tout au long d'une longue session. Le revers apparaît dans la réaction de la communauté ci-dessous.
Tarifs de Claude Opus 4.8 et positionnement
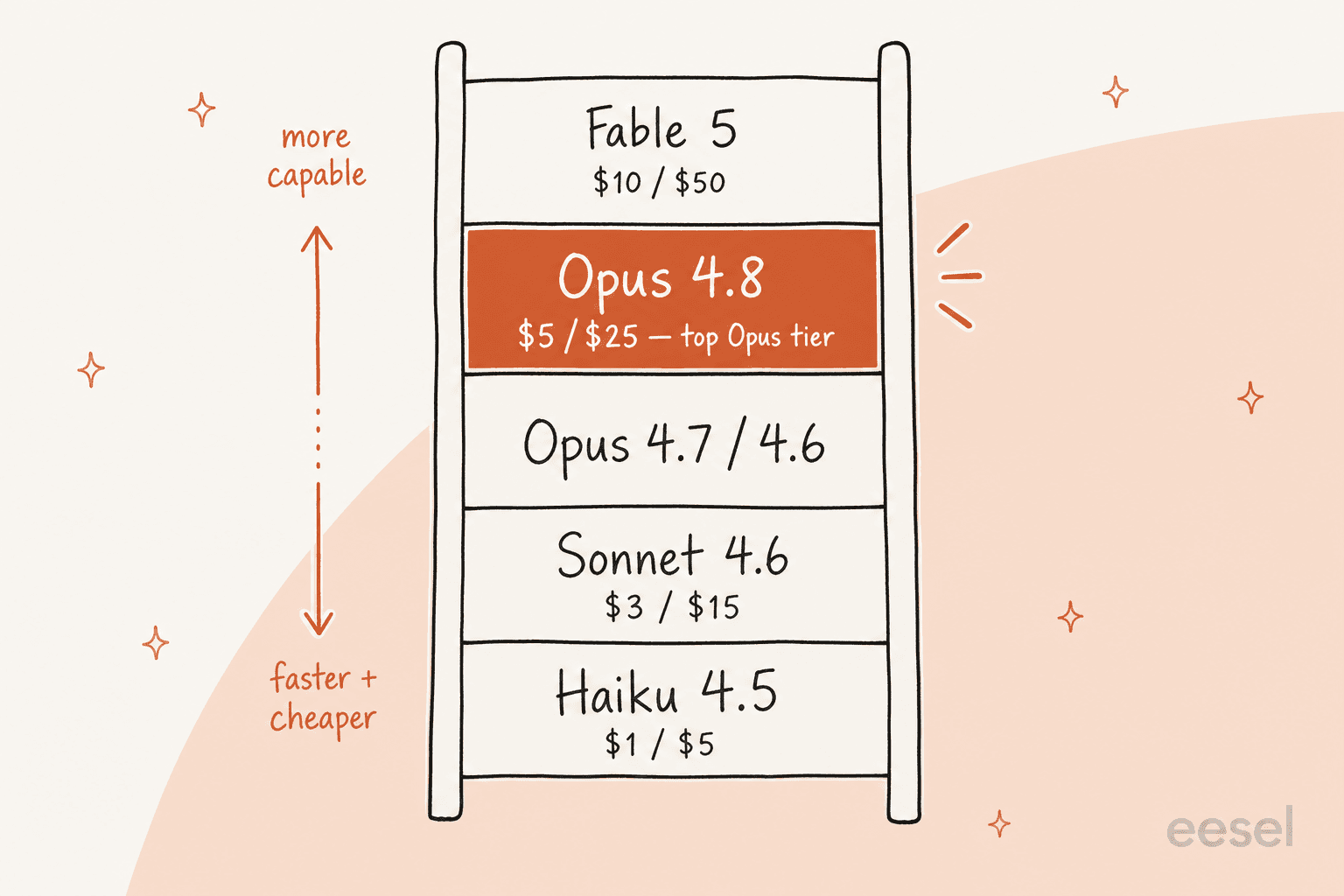
Les tarifs sont la partie simple, car ils n'ont pas bougé. Opus 4.8 est à 5 $ par million de tokens en entrée et 25 $ par million de tokens en sortie, exactement comme Opus 4.7 (page de tarification). Il y a aussi un mode rapide qui tourne à 2,5 fois la vitesse et, selon Anthropic, coûte notablement moins que le mode rapide sur les modèles précédents.
Voici la gamme Claude dans son ensemble à mi-2026, le contexte dont vous avez besoin pour réellement choisir un modèle :
| Modèle | Entrée / sortie (par 1M tokens) | Contexte | Idéal pour |
|---|---|---|---|
| Claude Fable 5 | 10 $ / 50 $ | 1M | Le modèle le plus performant et largement disponible d'Anthropic |
| Claude Opus 4.8 | 5 $ / 25 $ | 1M | Meilleur niveau Opus ; raisonnement complexe, agents longue durée |
| Claude Opus 4.7 / 4.6 | 5 $ / 25 $ | 1M | Les générations Opus précédentes |
| Claude Sonnet 4.6 | 3 $ / 15 $ | 1M | Meilleur équilibre vitesse/intelligence |
| Claude Haiku 4.5 | 1 $ / 5 $ | 200k | Le plus rapide et le moins cher, pour les tâches simples à volume élevé |
Ce qu'il faut noter : Opus 4.8 est le modèle le plus puissant du niveau Opus, mais il n'est plus au sommet de toute la pile. Environ deux semaines après son lancement, Anthropic a sorti Claude Fable 5 comme son modèle largement disponible le plus performant, au double du prix. Opus 4.8 est donc la valeur sûre haute capacité ; Fable 5 est l'option « le budget n'est pas un problème, donnez-moi le meilleur absolu ». Nous avons mis en face à face la génération précédente et ses concurrents dans Gemini 3 Pro vs Claude Opus 4.6 si vous voulez un aperçu de la position des modèles Anthropic.
Un piège de coût à signaler, car il surprend les gens : Opus 4.7 et les versions suivantes utilisent un nouveau tokenizer qui « peut utiliser jusqu'à 35 % de tokens supplémentaires pour le même texte fixe ». Ainsi, même avec un prix affiché inchangé, votre coût réel par tâche peut augmenter par rapport à un modèle plus ancien. Ce détail explique beaucoup des grognements de la communauté, ce qui m'amène à la partie suivante. (Si les tarifs sont votre seule raison de lire, notre guide des tarifs Claude détaille niveau par niveau.)
Ce que les gens disent vraiment
La lecture la plus claire de la réaction de la communauté est qu'Opus 4.8 est le correctif d'un 4.7 que les gens n'aimaient ouvertement pas. Les prises de position « retour à la forme » sont partout et correspondent à notre revue Claude sur le long terme. Un développeur, quelques heures après l'avoir testé sur r/ClaudeAI, l'a bien formulé :
« 4.8 est précis, réfléchit vite et n'a rien hallucin. Quand il ne sait pas quelque chose, il me demande directement au lieu d'inventer. Ça ressemble à ce que 4.6 aurait dû évoluer pour devenir. »
Cela correspond aux affirmations d'honnêteté d'Anthropic et c'est le positif le plus répété. Mais deux tensions honnêtes méritent d'être soulevées, car ce sont le genre de choses qu'une page marketing ne vous dira pas.
Premièrement, il est gourmand. La plainte la plus fréquente est qu'Opus 4.8 épuise rapidement les limites d'utilisation, en partie à cause de ce nouveau tokenizer. Comme l'a noté un utilisateur dans un fil comparant Opus 4.8 à GPT-5.5 :
« Opus 4.8 est une bête, bien meilleur que 4.7 à l'exécution mais aussi en conception je trouve ; le vrai problème c'est les tokens, il en consomme beaucoup plus et pour la première fois j'ai atteint une limite dans mon abonnement maximum. »
Deuxièmement, l'autonomie n'est pas magique. Les utilisateurs expérimentés qui exécutent des tâches longues et difficiles rapportent qu'Opus 4.8 a toujours besoin d'un cadrage précis, un architecte de systèmes quantitatifs notant que « pour utiliser Opus 4.8 efficacement, l'humain doit encore beaucoup réfléchir. Il faut définir plus, guider plus et maintenir soi-même plus du contexte ». Et le revers des gains d'honnêteté célébrés est qu'une minorité vocale le trouve trop prudent ou trop apologétique pour le travail créatif ouvert. Rien de tout cela n'est accablant. C'est simplement l'image calibrée : un modèle puissant, honnête, gourmand en tokens qui récompense les instructions claires.
Ce qu'un modèle plus intelligent signifie réellement pour le support client
Voici ce que je connais vraiment. Si vous gérez une équipe de support, la tentation quand un modèle comme Opus 4.8 arrive est de penser « super, le support IA vient de s'améliorer ». Parfois. Mais le modèle est le moteur, pas la voiture, et il vaut la peine d'être précis sur ce dont est vraiment fait le logiciel de service client IA.
J'ai vu beaucoup d'équipes techniquement compétentes arriver à la même conclusion à la dure. Nous avons vu des clients partir pour intégrer l'API Claude eux-mêmes, raisonnant que si Opus est si bon, ils peuvent l'appeler directement. Quelques mois plus tard, la réalité de la maintenance s'impose. Un responsable ingénierie qui a choisi d'acheter plutôt que de construire a résumé le calcul clairement : il pouvait écrire sa propre application LLM, mais il « ne voulait pas investir du temps là-dedans » et voulait « quelque chose que nous n'aurions pas à maintenir ».
C'est parce qu'un agent de support en production, c'est le modèle plus une quantité importante d'échafaudage peu glamour :
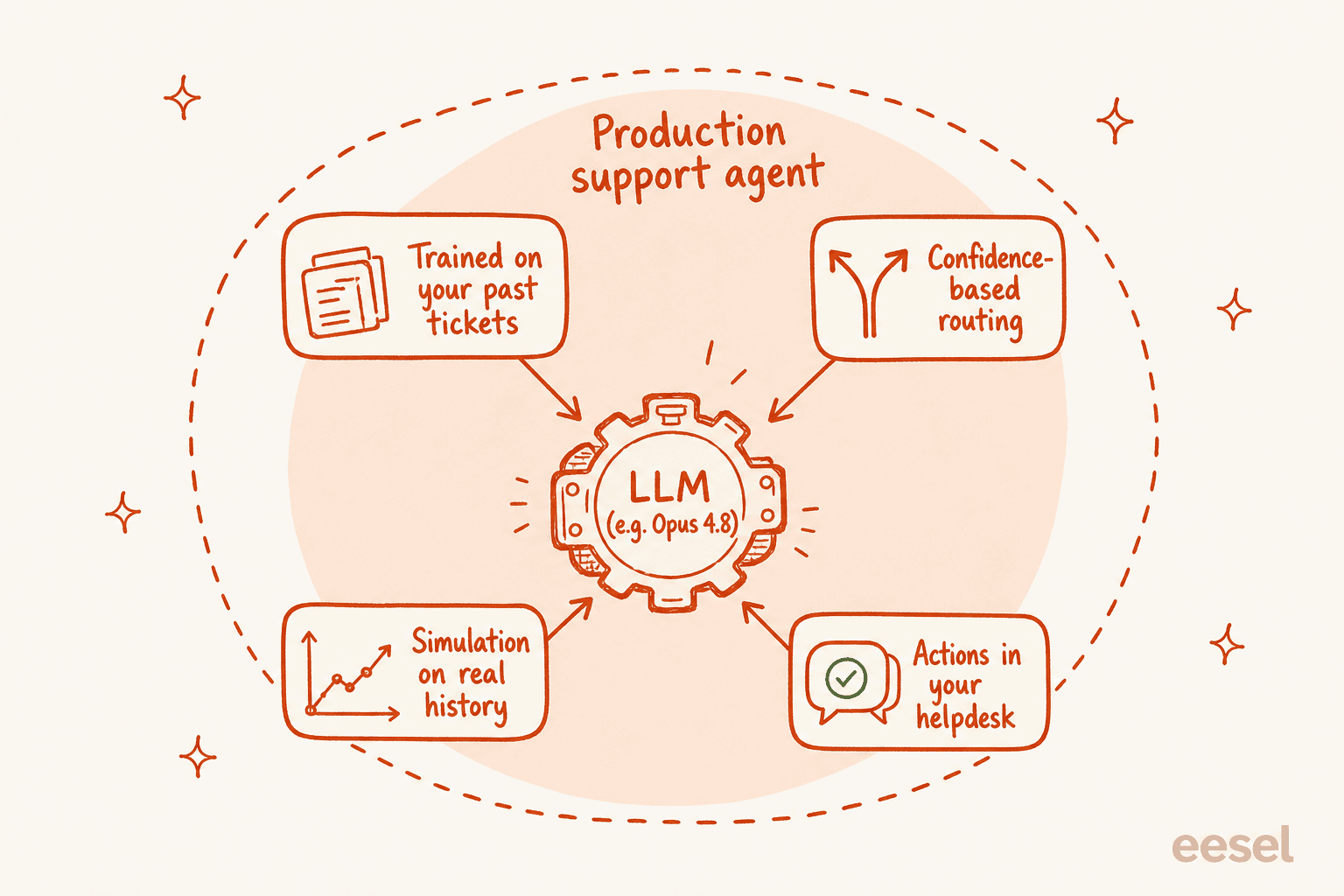
- Votre connaissance, pas celle du modèle. La date de coupure d'entraînement d'Opus 4.8 en janvier 2026 ne sait rien de votre politique de remboursement ou de la panne de la semaine dernière. Un agent utile apprend de vos anciens tickets, de vos docs d'aide et de vos macros — pas de la connaissance générale du monde.
- Routage basé sur la confiance. Les gains d'honnêteté dans Opus 4.8 sont réels, mais vous ne voulez toujours pas qu'un modèle décide seul quand répondre en direct. Vous voulez qu'il rédige quand il n'est pas sûr et n'envoie automatiquement que quand il est confiant — c'est un garde-fou au niveau système, pas un paramètre du modèle.
- Un moyen de tester avant la mise en production. Avant qu'un seul client ne voie une réponse IA, vous voulez faire tourner le système sur des milliers de vos tickets réels et résolus et voir exactement où il aurait eu raison ou tort. Choisir un modèle plus récent ne vous donne pas ça ; la simulation si.
- Des actions, pas seulement des réponses. Tagger, trier, chercher une commande, escalader proprement vers un humain. Tout cela vit dans vos intégrations helpdesk, pas dans le modèle brut.
C'est aussi pourquoi « quel modèle est le meilleur » est la mauvaise question pour le support. Nous avons constaté qu'un système bien construit sur un modèle de niveau intermédiaire surpasse généralement un modèle de frontière brut sans échafaudage — c'est tout le sens de notre article sur quel LLM est le meilleur pour les cas d'usage de support. Qu'Opus 4.8 soit plus honnête est une bonne nouvelle — cela ne change tout simplement pas la forme du travail. Si vous pesez le développement de votre propre support IA contre l'achat d'une plateforme, le modèle est la partie simple et bon marché. Le reste, c'est le travail.
Essayez eesel
Si vous avez lu jusqu'ici, vous êtes probablement moins intéressé par les deltas de benchmarks et plus par la question de savoir si l'IA peut prendre en charge des tickets de votre équipe en toute sécurité. C'est exactement ce que fait eesel AI : il se pose au-dessus des modèles de frontière comme Claude (pour que vous obteniez le raisonnement de classe Opus sans gérer la plomberie), apprend de vos anciens tickets et docs d'aide, route par niveau de confiance pour n'envoyer automatiquement que quand il est sûr, et vous permet de simuler sur votre historique réel de tickets avant de parler à un client. La tarification est à l'usage sans frais par siège, donc un mois plus calme coûte moins plutôt que la même chose.

Vous pouvez connecter votre helpdesk et avoir une simulation en cours en quelques minutes. Essayez eesel et pointez-le sur vos propres tickets pour voir ce qu'il résoudrait vraiment.
Questions fréquentes
Qu'est-ce que Claude Opus 4.8 ?
Combien coûte Claude Opus 4.8 ?
Quelle est la différence entre Claude Opus 4.8 et Opus 4.7 ?
Claude Opus 4.8 est-il bon pour le support client ?
Devrais-je construire mon propre support IA sur l'API Claude Opus 4.8 ?
Où se situe Claude Opus 4.8 dans la gamme d'Anthropic ?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.





