
En bref
Claude Opus 4.8 est le modele phare d'Anthropic dans la categorie Opus et, pour les entreprises, il represente une amelioration modeste mais tangible par rapport au 4.7 : plus honnete, un nouveau reglage d'effort et le meme tarif de $5 / $25 par million de tokens. Le seul vrai inconvenient : il consomme des tokens plus rapidement.
Voici ce que la plupart des articles sur "Claude Opus 4.8 pour les entreprises" omettent. Apres plus de trois ans a deployer de l'IA sur des files d'attente de support en production, je peux vous dire que le modele est le moteur, pas la voiture. Acheter un modele plus intelligent ne vous donne pas un flux de travail professionnel fonctionnel. Le modele a toujours besoin de vos donnees, de vos garde-fous et d'un moyen de le tester avant qu'il touche un client — c'est exactement la lacune que remplit une plateforme comme eesel AI.
Voici donc une lecture pratique du point de vue de l'operateur : ce qui a reellement change, ce que cela coute une fois tout comptabilise, quand construire sur l'API ou acheter, et ce qu'un modele de frontier fait (et ne fait pas) pour votre equipe.
Je deploie l'IA sur de vraies files de support — voici mon analyse pour les entreprises
Je vais commencer la ou la plupart des articles sur les modeles ne commencent pas, parce que c'est ce qui determine si Opus 4.8 change quelque chose pour votre entreprise. J'ai passe des annees a observer comment les modeles de frontier rencontrent de vraies files de support desordonnees, et la lecon ne change jamais : le modele est rarement la partie difficile.
Deux chiffres pour etayer cela, tous deux issus de nos propres deployments. Gridwise a vu eesel resoudre 73% de ses demandes de niveau 1 le premier mois, avec des resultats obtenus dans un essai de 7 jours. Smava fait tourner un agent Zendesk entierement automatise traitant plus de 100 000 tickets en allemand par mois. Aucun de ces resultats ne vient du choix du modele le plus intelligent. Ils proviennent d'un entrainement sur des tickets resolus, d'un routage par confiance et d'une simulation contre un historique reel avant la mise en production.
Donc quand un nouvel Opus arrive, la question qui compte pour une entreprise n'est pas "est-il plus intelligent sur un benchmark ?". C'est "est-ce que ca change ce que j'enverrais reellement dans la boite de reception d'un client, ou sur le bureau de mon equipe ?". Examinons Opus 4.8 sous cet angle.
Ce qu'est Claude Opus 4.8 en termes professionnels
Claude Opus 4.8 est le dernier modele de la famille Opus d'Anthropic — le niveau haute capacite de Claude. Il est sorti le 28 mai 2026 en tant que successeur d'Opus 4.7, et dans l'API vous l'appelez comme claude-opus-4-8. Si vous preferez l'explication generale plutot que l'angle professionnel, nous avons ecrit un article separe sur ce qu'est Claude Opus 4.8.
Les specifications cles qui importent a un acheteur : une fenetre de contexte d'1M de tokens au tarif standard, jusqu'a 128k tokens de sortie, et une reflexion adaptative que le modele gere lui-meme (sans interrupteur de pensee etendue a surveiller). Il lit du texte et des images, gere plus de 80 langues, et son entrainement va jusqu'en janvier 2026 (apercu des modeles). Anthropic le deploie partout des le premier jour, y compris AWS Bedrock, Vertex AI et Microsoft Foundry — ce qui compte si votre equipe achats a deja un cloud prefere.
Le cadrage d'Anthropic pour decrire ce bond est rafraichissant de modestie. L'annonce le qualifie d'"amelioration modeste mais tangible par rapport a son predecesseur", et c'est la bonne attente a fixer en interne. C'est une version de polish et de corrections, pas un saut generationnel, et les corrections sont la ou reside la valeur pour les entreprises.
Ce qui a reellement change pour les acheteurs dans Opus 4.8
Quelques changements meritent d'etre connus si vous decidez sur quoi standardiser votre equipe, plutot que de simplement l'utiliser pour discuter.
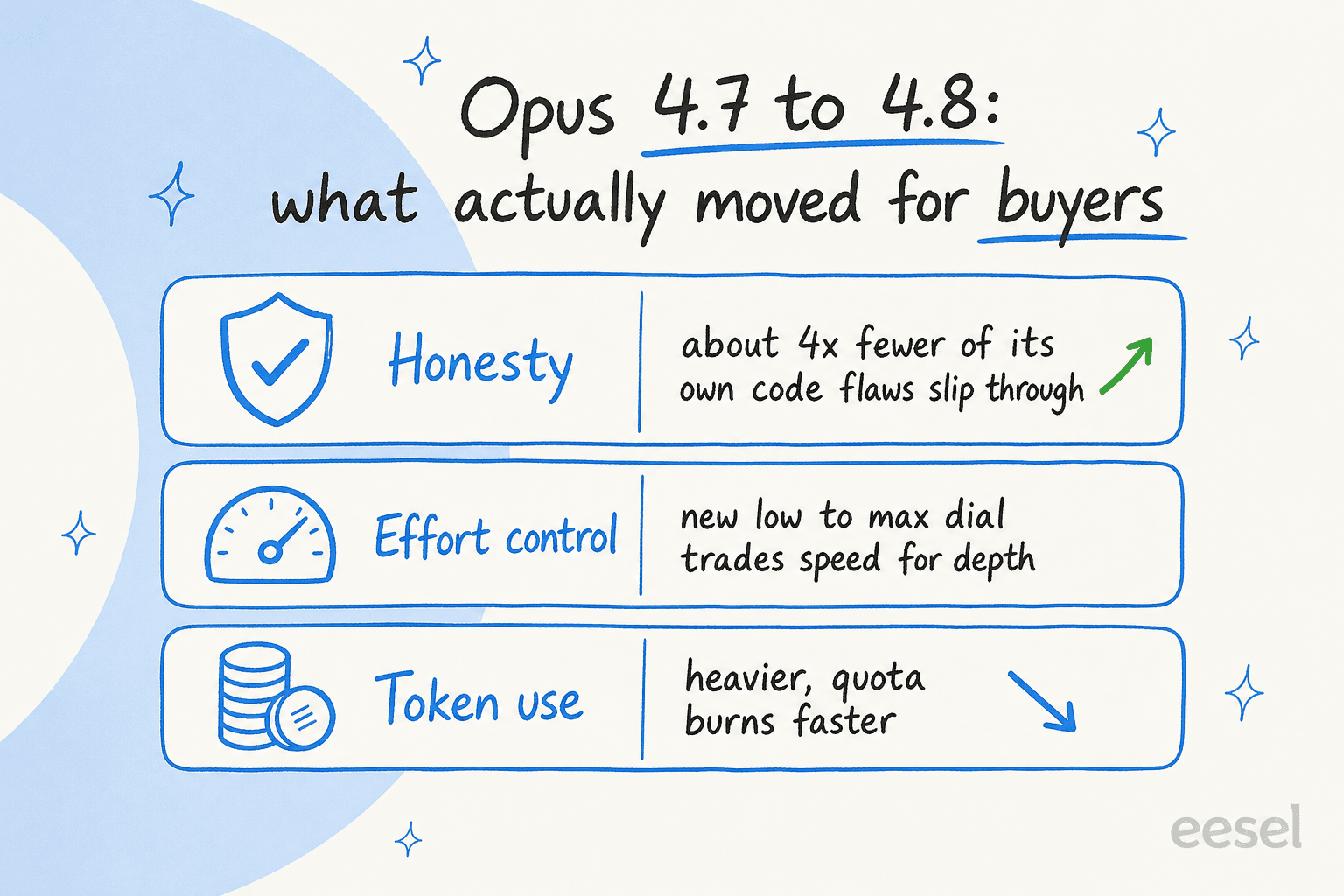
L'honnetete a vraiment progresse. Anthropic appelle cela "l'une des ameliorations les plus notables", et c'est ce pour quoi je paierais dans un contexte professionnel. Opus 4.8 serait environ quatre fois moins susceptible que le 4.7 de laisser passer des defauts dans son propre code sans commentaire, et il est plus dispose a signaler une incertitude qu'a inventer une reponse avec confiance. Partout ou une mauvaise reponse a un cout — en finance, juridique, support reglemente — "vous dit quand il n'est pas sur" l'emporte sur un point de plus dans un benchmark de programmation.
Un nouveau controle d'effort. Il existe maintenant un reglage qui definit l'intensite du travail du modele, de low a max, avec high par defaut (annonce). Pour une entreprise, c'est un levier budgetaire : montez-le pour les analyses difficiles, baissez-le pour les taches routinieres a fort volume ou la vitesse et le cout comptent plus que la profondeur.
Travail agentique a long terme. Dans Claude Code, Opus 4.8 peut planifier un travail, lancer des centaines de sous-agents en parallele dans une session, puis verifier le resultat avant de rendre compte — oriente vers le travail a l'echelle d'une base de code comme les grandes migrations (post dynamic-workflows). Si vous dirigez une organisation d'ingenierie, c'est l'essentiel. La System Card indique que les performances sont "superieures a celles d'Opus 4.7 dans presque toutes les evaluations".
Le probleme : il consomme beaucoup. La plainte la plus repandue de la communaute est qu'Opus 4.8 epuise les limites d'utilisation, en partie parce qu'Opus 4.7 et les versions ulterieures utilisent un nouveau tokeniseur qui "peut utiliser jusqu'a 35% de tokens supplementaires pour le meme texte fixe". Donc meme avec un prix catalogue inchange, votre cout reel par tache peut augmenter. Prevoyez-le dans votre budget.
Tarifs de Claude Opus 4.8 pour les entreprises
Les tarifs sont la partie facile, car ils n'ont pas bouge. Opus 4.8 est a $5 par million de tokens en entree et $25 par million de tokens en sortie, identique a Opus 4.7 (page de tarifs). Il existe aussi un mode rapide qui fonctionne a 2,5 fois la vitesse et, selon Anthropic, coute nettement moins que le mode rapide sur les modeles precedents.
Voici la gamme complete a mi-2026, qui est le contexte dont vous avez besoin pour choisir reellement un modele pour une charge de travail :
| Modele | Entree / sortie (par 1M de tokens) | Contexte | Ideal pour |
|---|---|---|---|
| Claude Fable 5 | $10 / $50 | 1M | Le modele le plus capable d'Anthropic largement disponible |
| Claude Opus 4.8 | $5 / $25 | 1M | Meilleur niveau Opus ; raisonnement complexe, agents long terme |
| Claude Opus 4.7 / 4.6 | $5 / $25 | 1M | Les generations Opus precedentes |
| Claude Sonnet 4.6 | $3 / $15 | 1M | Meilleur equilibre vitesse/intelligence |
| Claude Haiku 4.5 | $1 / $5 | 200k | Le plus rapide et economique pour les taches simples a fort volume |
Ce qu'il faut signaler aux finances : le prix catalogue par token est la plus petite ligne de votre vraie facture. La majeure partie du cout d'exploitation d'un modele en production, c'est tout ce qui l'entoure. C'est le pieges dans lequel je vois les entreprises tomber.
Si les tarifs sont votre seule raison de lire, notre guide des tarifs Claude va niveau par niveau, et les tarifs Claude Pro couvre les plans par poste sur lesquels votre equipe est peut-etre deja. Pour le calcul specifique au support, cout d'un agent IA vs. agent humain est la comparaison la plus utile qu'un taux de token brut.
Construire sur l'API ou acheter une plateforme ?
C'est la vraie decision que la plupart des entreprises affrontent quand un modele comme Opus 4.8 arrive, et la reponse honnete depend de ce que vous construisez.
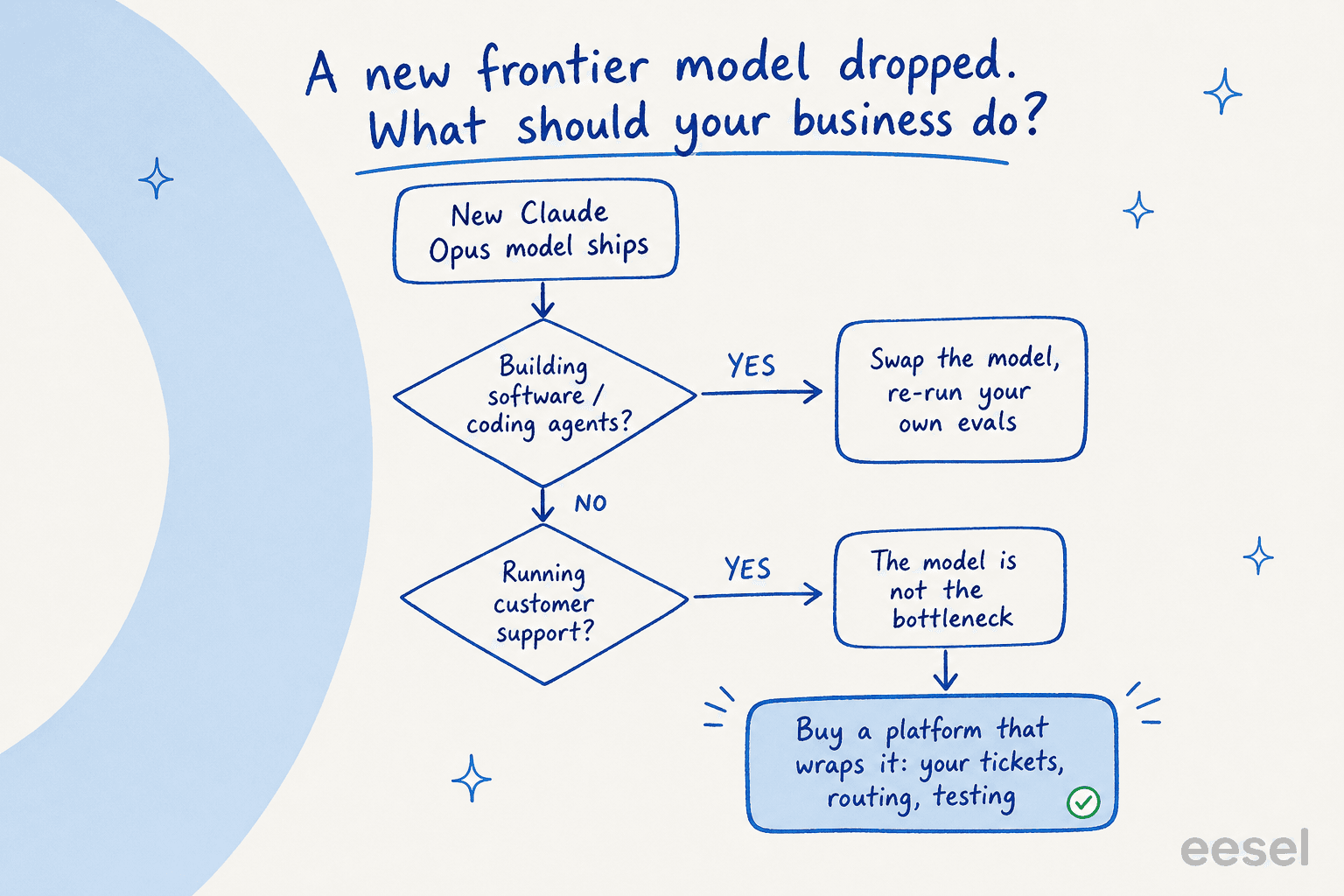
Si vous livrez un produit logiciel ou un workflow de programmation, construire directement sur l'API Claude est souvent le bon choix — echangez le nouveau modele, re-executez vos propres evaluations, livrez. Le modele est le produit dans ce cas.
Pour un workflow professionnel comme le support client, c'est l'inverse. J'ai vu beaucoup d'equipes competentes l'apprendre a la dure. Nous avons vu des clients partir pour connecter l'API Claude eux-memes, en se disant que si Opus est si bon, ils peuvent l'appeler directement. Quelques mois plus tard, la realite de la maintenance s'installe. Un responsable ingenierie qui a choisi d'acheter plutot que de construire a exprime le calcul clairement :
"Nous aurions pu essayer d'ecrire notre propre application LLM, mais nous ne voulions pas investir notre temps dans ca. Nous voulions quelque chose que nous n'aurions pas a maintenir."
C'est tire de l'etude de cas GENERAL BYTES, une equipe d'ingenierie dans une entreprise de hardware crypto qui a choisi d'acheter plutot que de construire. C'est la version la plus courante de l'histoire : l'appel API est trivial, et la recuperation, les garde-fous et la maintenance sont le vrai travail. Le meme schema apparait dans les decisions RAG vs. LLM — le modele est rarement la ou se trouve le travail.
Ce qu'un modele plus intelligent fait (et ne fait pas) pour le support
C'est la ou j'arrive a ce que je connais vraiment. Si vous gerez une equipe de support, la tentation quand Opus 4.8 arrive est de penser "super, le support IA vient de s'ameliorer". Parfois. Mais il vaut la peine d'etre precis sur ce dont est reellement fait le logiciel de service client IA, car un modele de frontier n'en est qu'une partie.
Un agent de support en production, c'est le modele plus beaucoup d'echafaudage peu glamour qu'Opus 4.8 n'inclut tout simplement pas :
- Votre savoir, pas celui du modele. La date de coupure d'entrainement de janvier 2026 d'Opus 4.8 ne sait rien de votre politique de remboursement ou de la panne de la semaine derniere. Un agent utile apprend de vos tickets passes, de vos docs d'aide et de vos macros — ce qui est l'angle mort de la connaissance generale du monde. (Qu'est-ce que le RAG couvre le cote recuperation.)
- Routage base sur la confiance. Les gains d'honnetete dans Opus 4.8 sont reels, mais vous ne voulez quand meme pas qu'un modele decide seul quand repondre en direct. Vous voulez qu'il redige quand il est incertain et qu'il envoie automatiquement uniquement quand il est sur — c'est un garde-fou au niveau systeme, pas un parametre du modele.
- Un moyen de tester avant la mise en production. Avant qu'un seul client voie une reponse IA, vous voulez l'executer sur des milliers de vos tickets reels et resolus et voir exactement ou il aurait eu juste ou faux. Un modele plus recent ne vous donne pas ca ; la simulation si.
- Escalade propre et actions. Etiquetage, triage, consultation d'une commande, transfert a un humain. Ca vit dans vos integrations helpdesk, pas dans le modele brut.
C'est pourquoi "quel modele est le meilleur ?" est generalement la mauvaise question pour une equipe de support. Nous avons constate qu'un systeme bien construit sur un modele de niveau intermediaire bat souvent un modele de frontier brut sans echafaudage — c'est tout l'argument dans quel LLM est le meilleur pour les cas d'usage support. Qu'Opus 4.8 soit plus honnete est une bonne nouvelle ; ca ne change simplement pas la forme du travail ni ne deplace le taux de resolution seul. Si vous evaluez la meilleure IA pour le service client ou examinez les alternatives a Claude pour un workflow, le modele est la partie bon marche et facile. Le reste, c'est le travail.
Une divulgation, car c'est la moindre des choses : nous construisons sur des modeles de frontier comme Claude, donc j'ai un interet ici. C'est aussi pourquoi je suis sur que le modele n'est pas l'avantage concurrentiel — j'ai vu la difference qu'un systeme bien construit fait aupres de centaines d'equipes utilisant l'IA pour le service client.
Essayez eesel
Si vous avez lu jusqu'ici, vous etes probablement moins interesse par les deltas de benchmark et plus interesse par la question de savoir si l'IA peut retirer du travail de facon sure de la pile de votre equipe. C'est ce que fait eesel AI : il se pose par-dessus des modeles de frontier comme Claude (pour que vous obteniez un raisonnement de classe Opus sans posseder aucune de la plomberie), apprend de vos tickets passes et de vos docs d'aide, route par confiance pour ne repondre automatiquement que quand il est sur, et vous permet de simuler sur votre vrai historique de tickets avant de parler a un client. La tarification est basee sur l'usage sans frais par poste, donc un mois plus calme coute moins.

Vous pouvez connecter votre helpdesk et avoir une simulation en cours en quelques minutes. Essayez eesel et pointez-le sur vos propres tickets pour voir ce qu'il resoudrait vraiment — aucun modele plus intelligent requis.
Questions frequemment posees
Claude Opus 4.8 est-il adapte a un usage en entreprise ?
Combien coute Claude Opus 4.8 pour une entreprise ?
Mon entreprise devrait-elle construire sur l'API Claude Opus 4.8 ou acheter une plateforme ?
Qu'est-ce qui a change dans Claude Opus 4.8 par rapport a Opus 4.7 ?
Claude Opus 4.8 peut-il gerer mon support client seul ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








