L'IA peut-elle écrire des release notes ? Un regard honnête sur ce qui fonctionne et ce qui ne fonctionne pas
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Dernière modification June 22, 2026

Alors, l'IA peut-elle vraiment écrire des release notes ?
Version courte : elle peut rédiger le brouillon, et elle s'en tire étonnamment bien. La version longue est la plus intéressante.
Je rédige beaucoup de contenu chez eesel avec l'IA dans la boucle, et je suis aussi assez proche du côté support pour voir ce qui se passe la semaine suivant le lancement d'un produit. Il y a un schéma récurrent. Une équipe publie une version genuinement bonne, puis les tickets « attends, où est passé ce bouton ? » et « vous avez changé comment X fonctionne ? » commencent à arriver, parce que la release note était soit un mur de messages de commit fix: null check, soit n'a jamais été rédigée. Les release notes sont la déflexion de support la moins coûteuse que vous écrirez jamais, et elles sont la première chose sautée sous la pression des délais. C'est exactement le vide que l'IA est bonne à combler.
Mais « peut-elle le faire » et « devriez-vous lui faire confiance sans surveillance » sont des questions différentes. La chose la plus utile que j'aie lue en préparant cet article n'était pas une page de fournisseur, c'était un fil Ask HN de janvier 2026 sur l'automatisation des release notes, où de vrais ingénieurs en ont débattu. Ce débat cartographie tout le territoire, donc je vais m'appuyer dessus.
« Release notes IA » désigne trois choses différentes
Quand les gens demandent si l'IA peut écrire des release notes, ils imaginent généralement un seul workflow. Il y en a en réalité trois, qui se situent sur un spectre allant de « à peine IA » à « entièrement rédigé par un modèle ».
1. Assemblage de modèles. C'est le moins coûteux et le plus courant, et c'est seulement vaguement de l'« IA ». Les release notes générées automatiquement de GitHub extraient une liste de pull requests fusionnées, une liste de contributeurs et un lien vers le changelog complet, avec des catégories pilotées par des labels de PR dans un fichier release.yml. Notez ce qu'il lit : des pull requests fusionnées, pas des commits. Les commits directs vers la branche par défaut n'apparaissent pas. C'est un assemblage déterministe, pas un modèle qui rédige de la prose, ce qui le rend fiable mais aussi un peu plat.
2. LLM à partir de la source. Ici un modèle lit votre signal structuré et rédige l'entrée. L'IA de Linear fait cela depuis les issues : sa documentation décrit l'utilisation d'un « agent Linear pour analyser l'ensemble des issues incluses dans une version particulière » et générer des notes sur un modèle chaque fois qu'une version arrive en production. Une vague d'outils plus petits fait de même depuis les commits et PRs, les lancements Show HN décrivent tous la même forme : « connectez GitHub, l'IA génère, partagez avec les clients ».
3. Rédacteur de contenu IA complet. Il s'agit de traiter la release note comme n'importe quelle autre pièce de contenu : vous remettez au rédacteur de contenu IA polyvalent le matériel brut plus votre ton de marque et le laissez produire une publication soignée orientée client. C'est la même catégorie que les outils de rédaction IA que vous utiliseriez pour un blog. Plus de contrôle sur le ton, plus de risque de rater la voix, et le plus proche de la façon dont vous géreriez un pipeline de contenu pour des articles de blog.
La plupart des équipes devraient commencer au niveau 1 ou 2 et ne passer au niveau 3 que lorsque les release notes constituent une vraie surface marketing. Si vous voulez le guide mécanique complet de chaque niveau, le guide complémentaire sur le générateur de release notes IA approfondit les outils.
Où l'IA brille vraiment
Laissez-moi d'abord être généreux, car l'avantage est réel et les sceptiques de Hacker News l'ont quelque peu sous-estimé.
Regroupement et mise en forme. Trier trente PRs fusionnées en Added, Fixed, Changed et Security est un travail ennuyeux et mécanique qu'un modèle fait instantanément et de façon constante. C'est le gain de temps individuel le plus important, et le moins risqué.
Traduire le jargon en bénéfice. Un bon modèle transforme « corrigé race condition dans la file de réessai des webhooks » en « corrigé un problème où certains webhooks pouvaient se déclencher deux fois ». C'est une vraie compétence, et c'est le même muscle qu'un rédacteur technique de blog qui réécrit du jargon technique pour un lecteur plus large.
Débit. Un développeur ayant publié un Show HN sur un outil de release notes GenAI a rapporté qu'il avait « réduit le temps consacré à la génération de release notes d'environ 70% pour l'équipe de gestion des versions de notre produit chez Microsoft ». C'est auto-rapporté par le créateur, pas un benchmark indépendant, donc traitez-le comme un point de données de praticien plutôt que comme une vérité absolue, mais la direction est juste : le travail fastidieux se compresse beaucoup.
C'est aussi là qu'apparaît la question build versus achat. Vous pourriez connecter votre propre script à l'API OpenAI ou Anthropic, et beaucoup d'outils Show HN sont exactement cela. Mais comme l'a dit un client eesel, Karel chez GENERAL BYTES, à propos d'une autre construction IA :
Nous pourrions essayer d'écrire notre propre application LLM, mais nous ne voulions pas y investir notre temps. Nous voulions quelque chose que nous n'aurions pas à maintenir.
Cet instinct est généralement juste. Un script de week-end pour résumer les commits est amusant ; le maintenir à travers les changements de modèles, les limites de débit et les cas limites est un vrai travail.
Où ça échoue silencieusement
Maintenant la partie honnête, et c'est là que la communauté Hacker News a gagné sa place.
Les messages de commit ne sont pas du texte destiné aux clients. L'objection la plus tranchante est venue de weinzierl :
Les messages de commit sont un espace privé où les développeurs communiquent. Les messages ne devraient jamais se retrouver chez le client sans filtrage et distillation approfondis.
C'est le risque central. Pointez une IA sur des commits bruts et vous n'obtenez pas seulement du bruit, vous risquez de divulguer un nom de projet interne, une description embarrassante de bug, ou un détail de sécurité que vous n'aviez pas l'intention de publier. L'entrée sûre est toujours la couche curatée (une pull request, une issue liée), jamais le diff brut.
Déchets en entrée, déchets en sortie, mais plus bruyants. nitwit005 a exécuté des notes entièrement automatisées depuis des tags git et les a trouvées « malheureusement inutiles parce que les gens n'ajoutent pas les bons tags sur les choses, donc tout le monde finit par éditer manuellement ». L'automatisation amplifie la discipline que vous avez déjà. Si vos descriptions de PR sont des stubs d'un mot, l'IA vous donne des stubs d'un mot soignés.
Elle ne sait pas ce qu'il faut omettre. Un sceptique de longue date, insin, a exprimé le verdict clairement :
Je n'ai jamais vu un ensemble de release notes auto-générées que j'aimais ; une liste de PRs ne suffit pas.
L'édition est surtout une soustraction : savoir que le refactoring interne et la mise à jour de dépendance n'appartiennent pas à une page client, tandis que le petit changement d'interface que tout le monde remarquera y appartient. Ce jugement est ce que le modèle ne peut pas encore faire de façon fiable pour vous. La même discipline d'édition de contenu s'applique à tout brouillon IA.
Il y avait même un commentaire d'une ligne bien tourné de ok1984 pour le rêve entièrement automatisé : « automatiser les release notes, c'est comme enregistrer un audio et le rejouer à chaque fois que vous présentez votre enfant à quelqu'un. » Certaines communications sont censées être humaines.
Le workflow qui fonctionne vraiment : générer, puis affiner
La solution n'est donc ni « l'IA rédige les release notes » ni « les humains rédigent les release notes ». C'est un relais. L'opérateur le plus crédible dans ce fil, richard_obrien (qui a révélé qu'il gère un outil de release notes), a résumé la condition préalable :
Les équipes qui réussissent le mieux avec l'automatisation de ce processus traitent les PRs GitHub ou Jira, Azure DevOps, Linear, les issues GitHub comme la source de vérité. De plus, leurs descriptions d'issues/PR tendent à décrire clairement le problème et la solution.
Voici la boucle qui en découle.
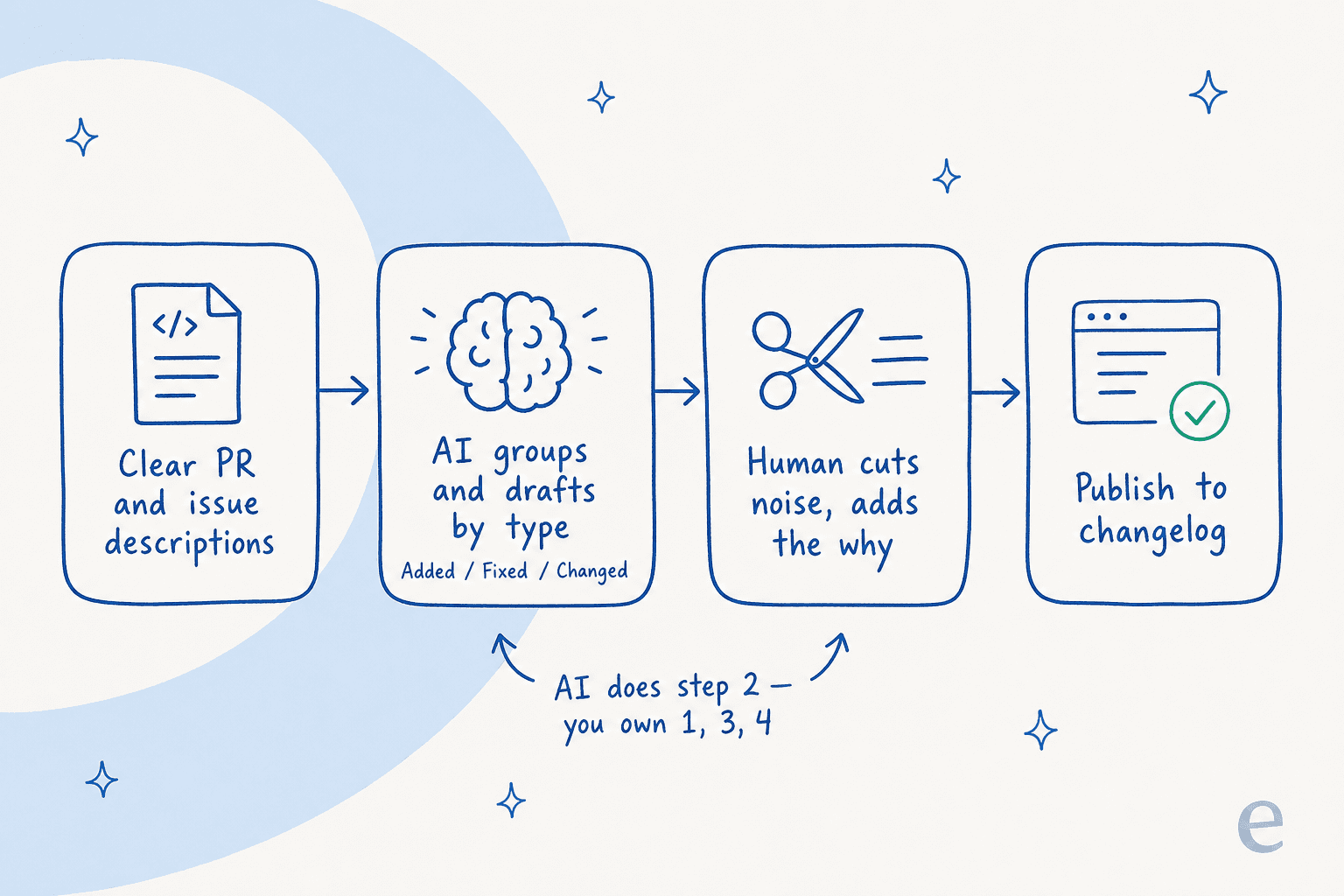
- Corrigez la source d'abord. Rédigez les descriptions de PR et d'issues comme si le client allait les lire, parce qu'il le fera de plus en plus. C'est l'étape sans glamour qui détermine tout ce qui suit.
- Laissez l'IA rédiger par type. Passez les PRs fusionnées (pas les commits) au modèle et demandez-lui de les regrouper en Added, Fixed, Changed, Security. C'est l'étape d'économie de 70% du temps.
- Coupez et ajoutez le pourquoi. Un humain supprime le bruit interne et ajoute la ligne de contexte que le modèle ne peut pas connaître : pourquoi cela importe à l'utilisateur, quoi faire à ce sujet. C'est là que la voix d'un bon rédacteur mérite sa place.
- Publiez là où les gens regardent. Envoyez la note dans votre changelog et votre centre d'aide, pas seulement dans un tag git.
Vous possédez les étapes 1, 3 et 4. L'IA possède l'étape 2. Obtenez cette division correctement et vous gardez la vitesse sans le risque. Si vous passez à l'échelle sur de nombreuses versions, cela commence à ressembler à tout autre pipeline de production de contenu, et les mêmes outils qui automatisent la création de contenu s'appliquent.
La moitié que tout le monde oublie : les release notes sont un canal de support
Voici la partie qui transforme un joli à-avoir en vrai ROI, et c'est la raison pour laquelle je m'y intéresse depuis le côté support.
Une release note n'est pas vraiment un document, c'est une réponse à une question que vos clients sont sur le point de poser : « qu'est-ce qui a changé, et dois-je faire quelque chose ? » S'ils ne trouvent pas la note, ils demandent à votre équipe de support à la place. C'est le pic de tickets que je vois après chaque version livrée sans bonnes notes.
Donc la dernière étape dans la boucle ci-dessus (publier là où les gens regardent) est celle qui rapporte. Quand vos release notes vivent dans votre centre d'aide et votre base de connaissance, deux bonnes choses se produisent simultanément.
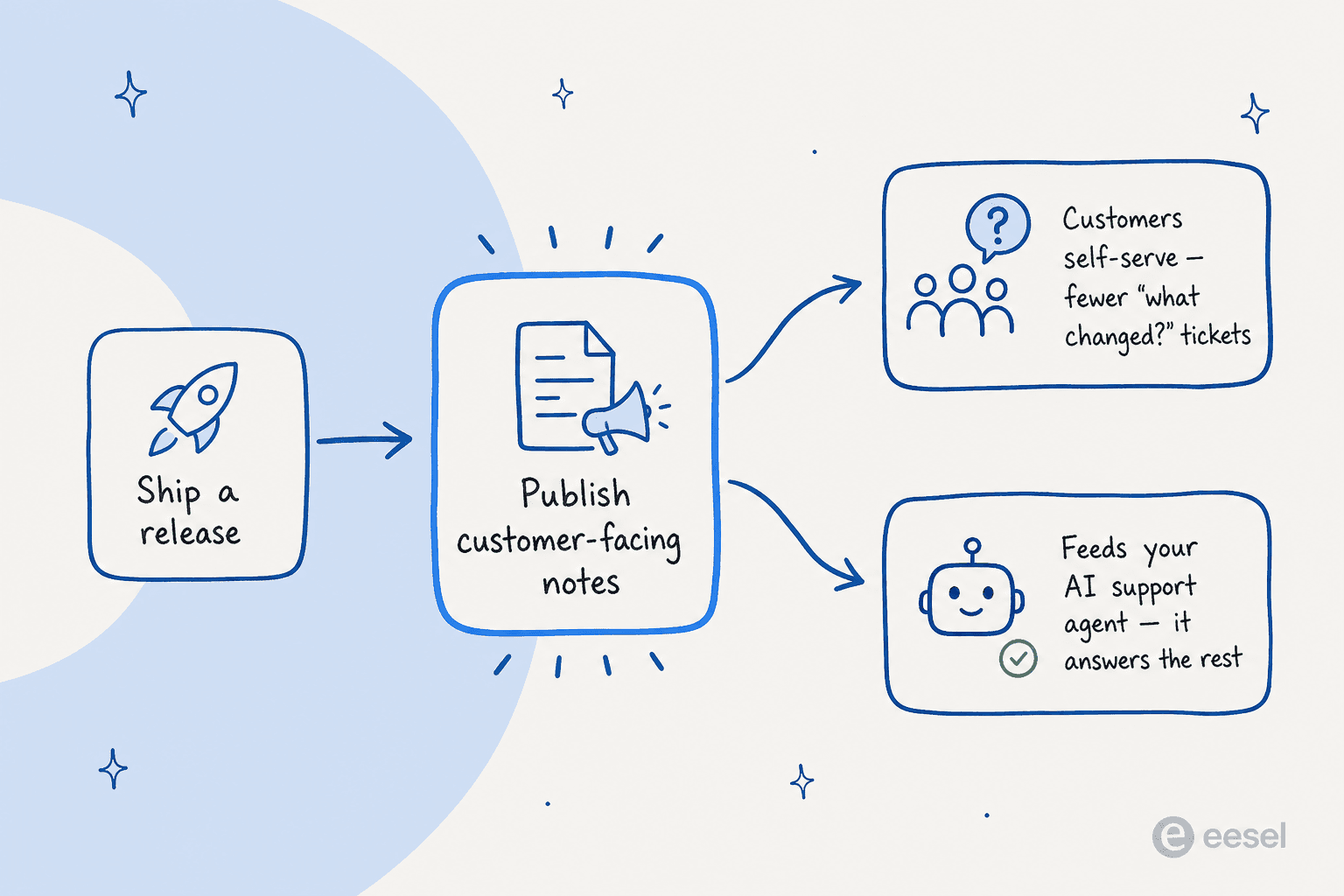
Premièrement, les clients se servent eux-mêmes, ce qui est tout l'objectif. Deuxièmement, et c'est la partie facile à manquer, vos notes deviennent des données d'entraînement pour votre agent de support IA. Un agent qui a lu votre dernière release note peut répondre « la nouvelle fonctionnalité d'export est-elle disponible ? » sans qu'un humain n'intervienne. Les notes qui restent dans un CHANGELOG.md que personne ne lie ne font rien pour la déflexion du support.
C'est la même raison pour laquelle maintenir le contenu d'aide à jour est important : un agent de support IA n'est aussi bon que la chose la plus récente qu'il a lue, et les release notes sont le signal le plus frais que vous produisez. C'est aussi pourquoi les release notes appartiennent à votre configuration plus large de gestion des connaissances, pas dans un silo, et pourquoi il vaut la peine de pointer un assistant de documentation IA vers elles.
Essayez eesel
Je serai direct sur la place d'eesel, parce que ce n'est pas un générateur de release notes dédié et je ne prétendrai pas que c'en est un. Deux choses qu'il fait bien autour de ce problème.
Premièrement, le rédacteur de contenu IA d'eesel peut prendre votre travail publié et rédiger la version orientée client, le même workflow de niveau 3 ci-dessus, avec votre voix et vos sources. Deuxièmement, et plus important encore, une fois ces notes publiées, eesel se connecte à votre centre d'aide et aux tickets passés pour que son agent de support IA réponde aux questions « qu'est-ce qui a changé ? » pour vous. Nous avons passé des années à placer des agents IA sur des files de support en direct, et nous simulons chaque déploiement contre vos tickets historiques avant qu'il ne soit mis en production, pour que vous puissiez voir exactement quelles questions de version il gérera avant de répondre à un seul client.

Si la release note est la réponse, eesel s'assure que la question n'atteint jamais un humain. C'est gratuit à essayer, et vous pouvez le pointer vers votre base de connaissance existante en quelques minutes pour voir ce qu'il dévie.