
Qu'est-ce que Claude Fable 5 ?
Claude Fable 5 est la cinquième génération de modèles d'Anthropic et la moitié publique d'une paire de deux modèles (l'autre, Mythos 5, est le même modèle avec les garde-fous retirés, réservé à des partenaires de recherche validés). Anthropic le présente comme « un modèle de niveau Mythos conçu pour vos projets les plus ambitieux et de longue durée », conçu pour gérer « des tâches complexes, asynchrones et s'étalant sur plusieurs jours que les modèles précédents ne pouvaient pas tenir ».
Voici ce qui compte une fois qu'on enlève le bruit du jour du lancement :
- Il est au sommet de l'échelle. Fable 5 se situe au-dessus d'Opus 4.8, qui se situe au-dessus de Sonnet 4.6. Si vous avez lu notre aperçu de Claude, voici le nouveau plafond.
- Il coûte le double d'Opus. 10 $ par million de tokens d'entrée, 50 $ par million de sortie, exactement 2x les 5 $ / 25 $ d'Opus 4.8. Les tokens d'entrée mis en cache bénéficient d'une remise de 90 %, et l'inférence aux États-Unis uniquement comporte un supplément de 1,1x.
- Il est grand. Une fenêtre de contexte de 1 000 000 de tokens, 128 000 tokens de sortie maximum et une date de coupure des connaissances en janvier 2026.
- Il est partout. Disponible sur claude.ai, l'API Claude, Amazon Bedrock et Claude Platform sur AWS et Microsoft Foundry, ainsi que Claude Code et Claude Managed Agents.
L'histoire des benchmarks étaye le battage, du moins sur le papier. La comparaison d'Anthropic elle-même place Fable 5 bien devant le reste de la pointe :
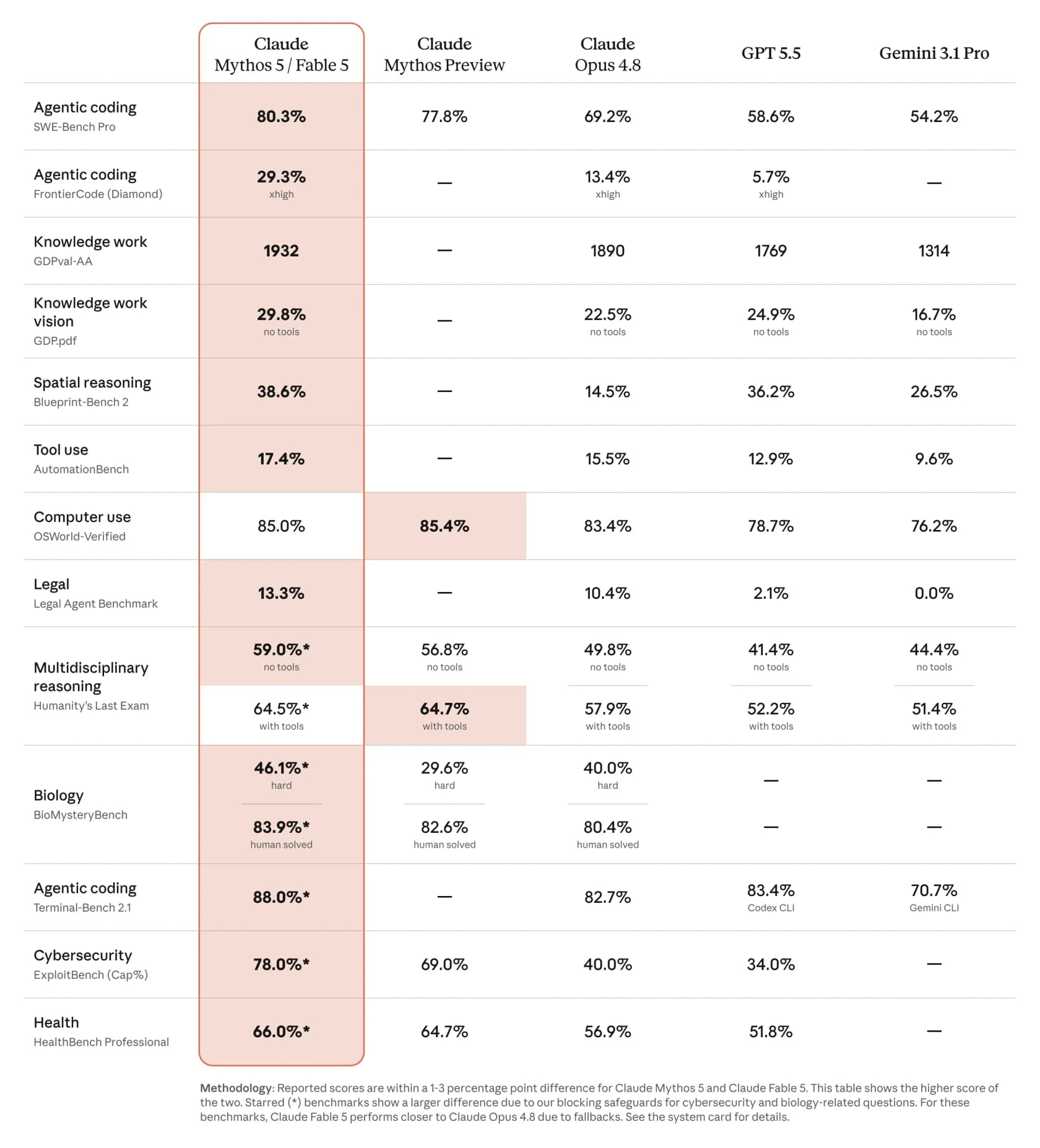
Sur SWE-Bench Pro (codage agentique), Fable 5 obtient 80,3 % contre 69,2 % pour Opus 4.8, GPT 5.5 étant à 58,6 % et Gemini 3.1 Pro à 54,2 %. CNBC a rapporté l'écart comme « plus de 10 % supérieur à Claude Opus 4.8 » sur certains benchmarks. Chiffres réels, avance réelle. Le hic, c'est ce qu'il en coûte pour les obtenir, et nous y reviendrons.
Ce qui le rend vraiment différent pour les entreprises
Beaucoup de lancements de modèles, ce sont quelques points de benchmark et un communiqué de presse. Fable 5 fait quelque chose de plus précis : il est conçu pour tourner longtemps sans se déliter. C'est la capacité qui devrait intéresser les entreprises, pas le classement.
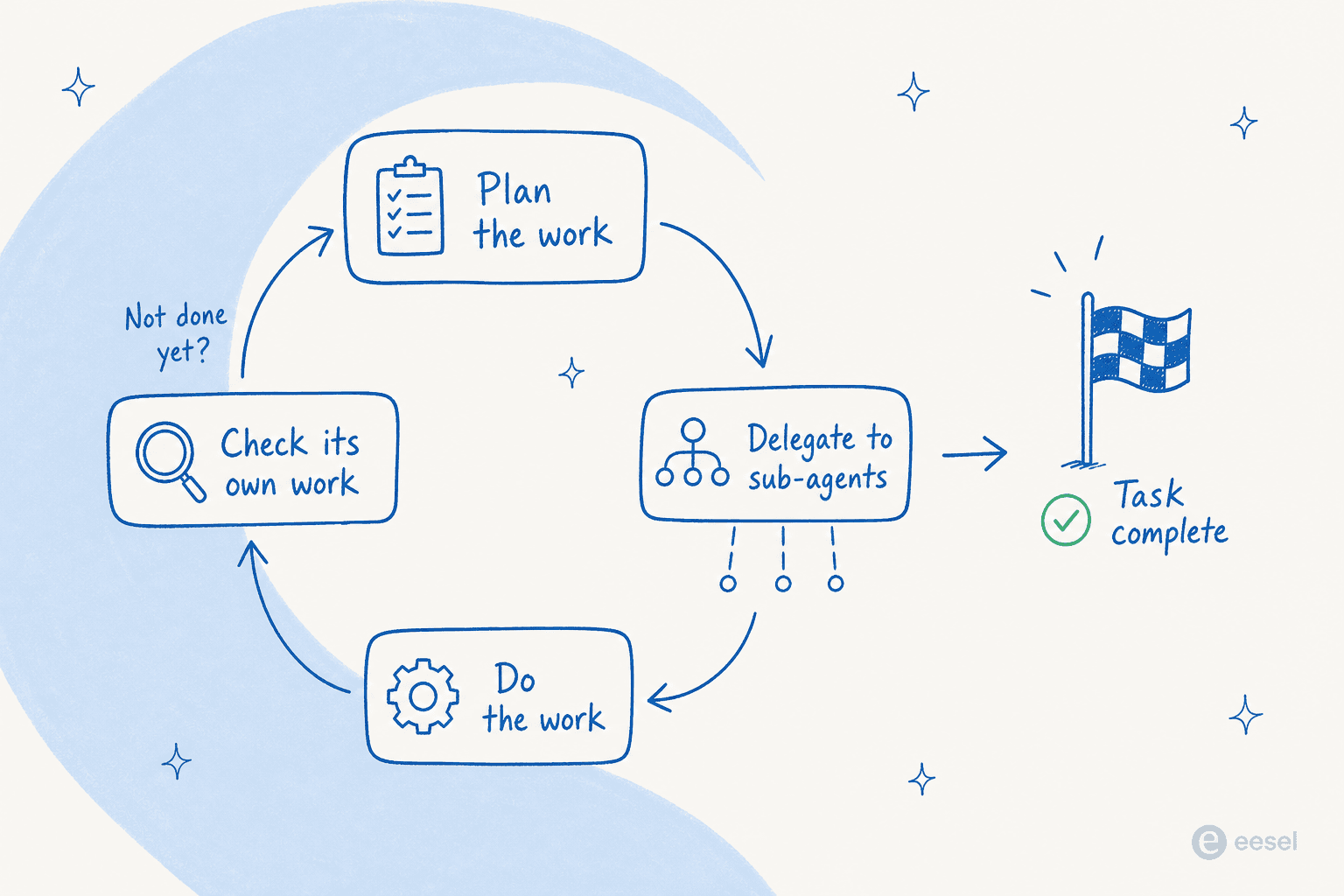
Il peut travailler des jours, pas des minutes
Le cas d'usage phare est le travail autonome sur le long terme. Faites tourner Fable 5 dans un harnais d'agents comme Claude Code ou Claude Managed Agents et, selon les mots d'Anthropic, « il peut travailler des jours d'affilée : planifier à travers les étapes, déléguer à des sous-agents et vérifier son propre travail ». Stripe l'a dirigé vers une base de code Ruby de 50 millions de lignes et a exécuté une migration sur l'ensemble en une journée.
Cette boucle — planifier, déléguer, travailler, vérifier, recommencer — est la partie qui est véritablement nouvelle. Les modèles précédents flanchaient sur les tâches à plusieurs étapes ; celui-ci garde son équilibre.
Les tests indépendants correspondent au marketing. Le développeur Simon Willison a passé cinq heures et demie avec lui et a conclu :
« This is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do. »
Il lit les documents en désordre que votre équipe possède réellement
Fable 5 « comprend les diagrammes, les graphiques et les tableaux imbriqués dans les fichiers et les PDF », ce qu'Anthropic positionne autour du travail financier, juridique et analytique. Un utilisateur de Hacker News a rapporté qu'il signalait correctement « fait / partiellement fait / manquant » à travers un PDF de 50 pages de spécifications denses et interconnectées. Pour toute entreprise assise sur une pile de contrats, de fiches techniques ou de documents de politique, c'est plus utile qu'un point de plus sur un benchmark de codage.
Il teste son propre travail
Anthropic commercialise Fable comme « minutieux, proactif, et testant son propre travail », et les fournisseurs de cloud décrivent une boucle planifier / vérifier / affiner intégrée. L'autocorrection est la différence entre un agent que vous devez surveiller et un que vous pouvez laisser seul, ce qui est exactement ce qui compte lorsque vous automatisez du travail réel.
Le hic que personne ne met sur la landing page
C'est ici que nous mettrions un coup de frein. Fable 5 est puissant, mais les premières 24 heures d'utilisation en conditions réelles ont fait remonter des problèmes très concrets, et ils coûtent tous de l'argent.
Il dévore le budget rapidement. Simon Willison a relevé une seule journée de tests à 110,42 $ de dépenses en tokens. Un utilisateur du plan Max a épuisé sa limite d'utilisation de 5 heures en 20 minutes en faisant tourner 1 000 sous-agents ; un autre a brûlé toute une fenêtre de 5 heures en moins de 8 minutes plus 15 $ de dépassement. Quand un modèle coûte le double et travaille bien plus dur par tâche, la facture grimpe vite.
Pour être juste, il y a un contre-récit qu'il vaut la peine de garder à l'esprit : le responsable des évaluations de Canva a constaté que Fable utilisait environ la moitié des tokens d'Opus 4.8 dans leurs harnais agentiques internes, si bien que le coût réel peut finir à peu près au même niveau une fois l'efficacité prise en compte. La leçon n'est pas « Fable est inabordable », c'est « vos coûts dépendent entièrement de la façon dont vous le faites tourner ».
Son routage de sécurité peut se déclencher à tort. Pour les sujets de cybersécurité, de biologie et de chimie, Fable exécute des classificateurs qui redirigent silencieusement la réponse vers Opus 4.8 à la place. Anthropic affirme qu'au moins 95 % des sessions tournent entièrement sur Fable sans aucun repli, mais ces 5 % incluent des faux positifs : un utilisateur de l'automatisation de laboratoire s'est vu refuser un protocole de base de manipulation de liquides sans rien de risqué dedans. Si votre entreprise évolue dans un secteur technique, testez avant de vous engager.
Le prix que vous voyez aujourd'hui pourrait ne pas durer. Fable est gratuit sur les plans Pro, Max, Team et seat-Enterprise uniquement jusqu'au 22 juin 2026, après quoi il passe aux crédits d'utilisation. Construisez votre flux de travail en partant du prix au compteur, pas de la promo de lancement.
Rien de tout cela ne fait de Fable 5 un mauvais modèle. Cela en fait un outil de pointe avec une économie d'outil de pointe, et cela a des conséquences directes sur la façon dont vous le déploieriez réellement.
Ce que Claude Fable 5 signifie pour le support client
C'est là que nous vivons, alors soyons précis. Si vous dirigez une équipe de support, devriez-vous vous soucier de Fable 5 ?
Pour l'essentiel : pas autant que le battage le suggère. Voici la vérité inconfortable sur l'IA pour le service client : pour les tickets de niveau 1, le modèle est rarement le goulot d'étranglement. Un Opus 4.8 bien ancré, ou même Sonnet 4.6, répond déjà correctement à l'écrasante majorité des questions du type « où est ma commande », « comment réinitialiser mon mot de passe », « quelle est votre politique de remboursement ». Payer le double pour que Fable 5 y réponde, c'est comme louer une voiture de Formule 1 pour le trajet de l'école.
Ce qui décide vraiment du bon fonctionnement de votre agent de help desk IA, c'est tout ce qui entoure le modèle :
- Connaît-il votre entreprise ? Un modèle ne vaut que ce sur quoi il est ancré. Le gain vient de l'entraînement sur vos tickets passés et vos documents d'aide, pas d'un modèle de base plus intelligent.
- Sait-il quand se taire ? Les modèles bruts répondent avec assurance même lorsqu'ils ont tort, ce qui est précisément pourquoi les chatbots donnent de mauvaises réponses. Les agents en production ont besoin d'un routage basé sur la confiance afin que les questions à faible confiance soient rédigées ou escaladées, et non envoyées automatiquement.
- Pouvez-vous lui faire confiance avant la mise en production ? Vous devez voir le taux d'erreur sur vos propres tickets d'abord, et non le découvrir devant les clients.
Ce dernier point est celui qui importe le plus aux acheteurs. Les responsables de support à qui nous parlons ne demandent pas une IA qui répond à tout ; ils demandent une IA qui connaît ses limites. Comme l'a formulé la responsable CX d'une entreprise de compléments alimentaires DTC lors d'un entretien client, l'IA ne répondra jamais à 100 % des questions, alors ce qu'ils veulent vraiment, c'est un agent qui ne traite que les tickets dont il est sûr et laisse le reste tranquille. C'est une capacité produit, pas une capacité modèle.
Fable 5 ne résout rien de tout cela pour vous. Un modèle brut sans récupération, sans routage et sans tests est un stagiaire sûr de lui avec accès à votre bouton de réponse. Le palier du modèle est le moindre de vos soucis.
Construire ou acheter : devriez-vous câbler Fable 5 vous-même ?
C'est la vraie décision pour une entreprise, et elle revient sans cesse. « Anthropic vient de sortir un modèle incroyable, pourquoi ne pas simplement construire notre bot de support sur l'API ? »
Vous pouvez. C'est aussi un projet plus grand qu'il n'y paraît. Le modèle vous donne de l'intelligence. Il ne vous donne pas la connexion à votre help desk, les garde-fous, l'environnement de simulation, le reporting ou la maintenance continue. Tout cela vous revient à construire et à posséder.
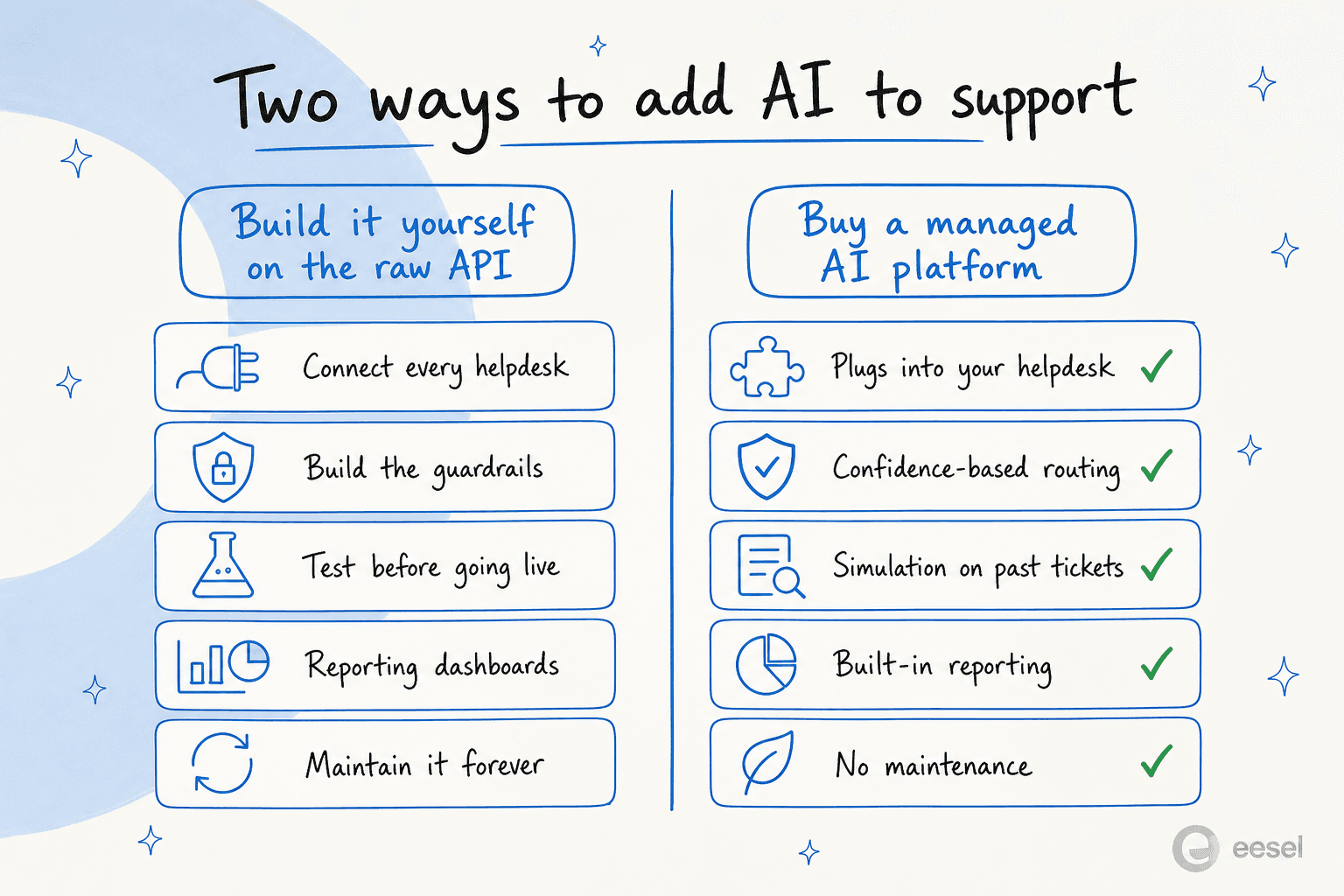
Nous voyons comment cela se passe, car « on va juste le construire sur l'API Claude » est l'une des raisons les plus courantes que donnent les équipes techniques avant d'acheter. Certaines le font vraiment. Plusieurs qui ont essayé sont ensuite passées à l'achat, parce que maintenir une application LLM maison s'est avéré être un travail dont personne ne voulait. Un client a résumé le calcul :
« We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain. »
La bonne façon d'y penser : un modèle de pointe est la couche la plus basse de la pile, pas la pile entière. Tout ce qui le transforme en un agent prêt pour le client se pose par-dessus, et c'est cette partie qui prend du temps.
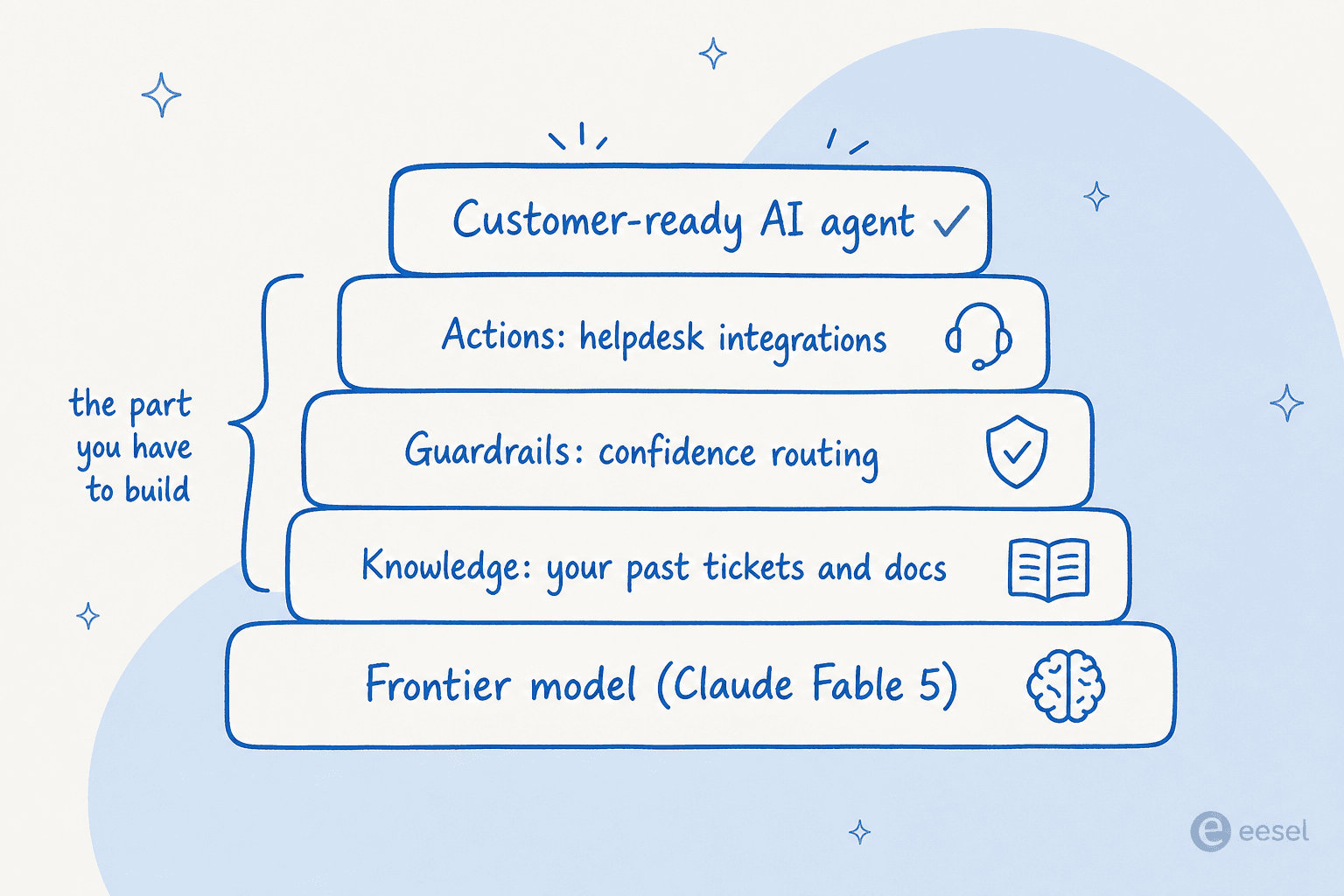
Si le produit principal de votre équipe est l'IA, construisez sans hésiter. Si votre produit principal est autre chose, et que vous voulez simplement que les tickets soient bien traités, acheter les couches au-dessus du modèle est presque toujours plus rapide, moins cher et moins fragile. C'est la même logique que celle qui sous-tend le choix de n'importe quel agent IA plutôt qu'un chatbot à règles : vous voulez le résultat, pas le contrat de maintenance.
Essayez eesel
eesel AI est la couche qui se pose au-dessus des modèles de pointe comme Claude pour que vous n'ayez pas à la construire. Elle se branche sur votre help desk existant (Zendesk, Freshdesk, HubSpot, Gorgias, Front et plus de 100 intégrations), apprend de vos tickets passés et de vos documents d'aide dès le premier jour, et répond dans plus de 80 langues, le tout avec une tarification à l'usage qui démarre à 0,40 $ par ticket sans frais par siège.
Le facteur différenciant qui compte ici, c'est justement la partie que Fable 5 ne peut pas vous donner tout seul : un mode simulation qui fait tourner l'agent sur des milliers de vos tickets passés afin que vous voyiez exactement comment il aurait répondu, et quel serait votre taux de résolution, avant qu'un seul client ne lui parle. C'est ainsi que Gridwise a atteint 73 % des demandes de niveau 1 résolues dès le premier mois, avec des résultats apparus au cours d'un essai de 7 jours.

Vous obtenez l'intelligence de la pointe, sans le projet d'ingénierie. Vous pouvez commencer gratuitement avec 50 $ d'utilisation et sans carte de crédit.
Foire aux questions
Qu'est-ce que Claude Fable 5 et est-il bon pour les entreprises ?
Combien coûte Claude Fable 5 ?
Devrais-je construire mon propre agent de support sur l'API Claude Fable 5 ?
Claude Fable 5 est-il meilleur que Claude Opus 4.8 pour le support client ?
Que se passe-t-il lorsque Claude Fable 5 se trompe sur une question de support ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








