Resumen
La mayoría del QA de soporte se construye sobre una mentira por omisión: revisas del 1 al 3% de las conversaciones a mano y luego hablas de "calidad" como si esa muestra representara al otro 97%. No lo hace. Hacer QA de soporte con IA significa puntuar cada conversación automáticamente según tu rúbrica, de modo que la cobertura deja de ser el cuello de botella.
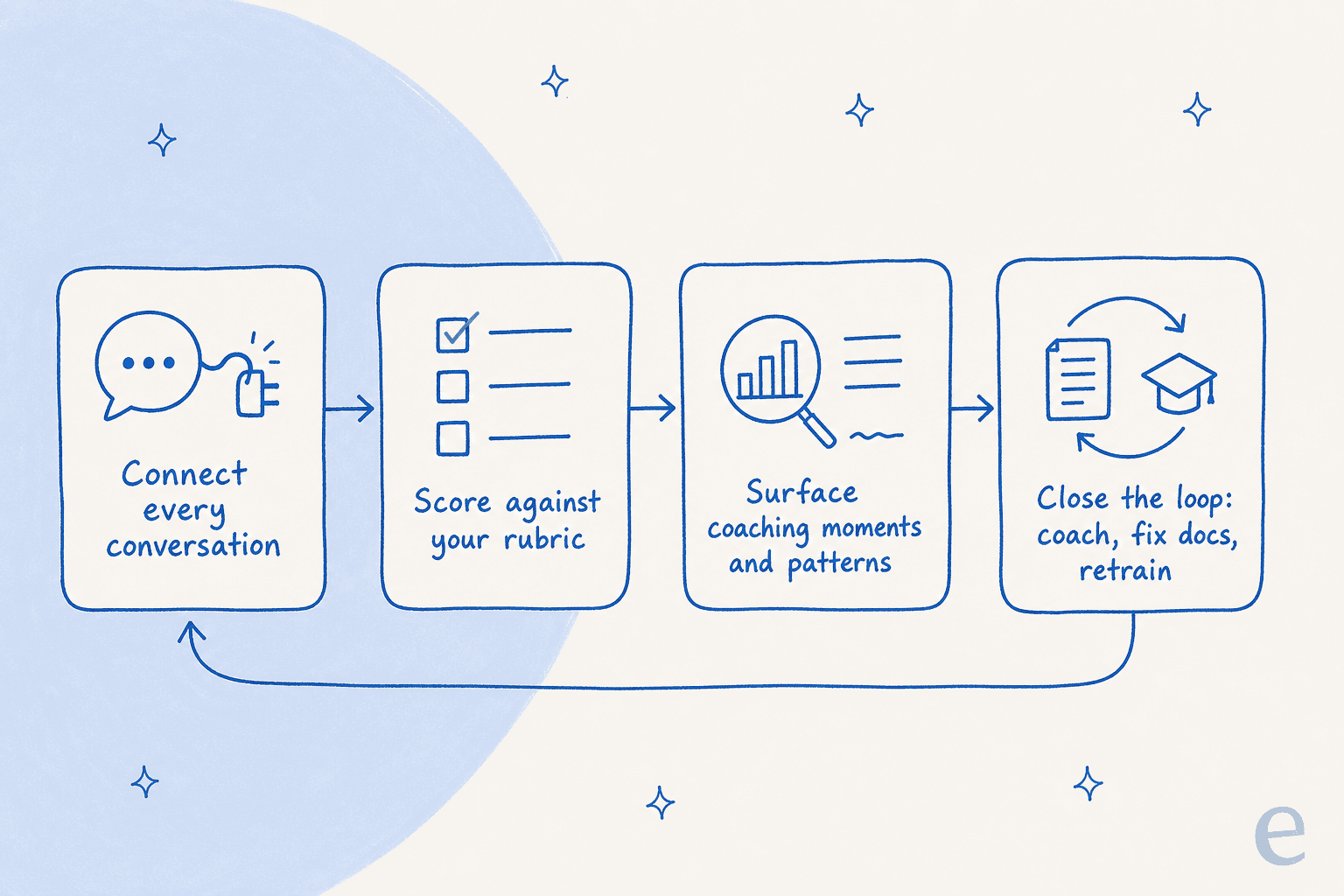
En la práctica, el flujo de trabajo son cinco pasos: escribe qué aspecto tiene una buena respuesta, conecta todo tu historial de conversaciones, deja que la IA las puntúe todas, detecta los momentos de coaching y los patrones recurrentes que el muestreo manual habría pasado por alto, y cierra el ciclo entrenando a los agentes y corrigiendo la documentación detrás de los fallos.
El paso que todo el mundo se salta: hacer QA del agente de IA también. He visto a un bot que sonaba convincente dar una respuesta equivocada, así que antes de confiar en la automatización con tickets en vivo, puntúala contra tus tickets pasados primero. El agente de helpdesk de IA de eesel ejecuta esa simulación sobre tu propio historial, que es lo más parecido a una revisión de QA antes de salir en vivo.
Qué es realmente el QA de soporte y por qué la versión manual está rota
El QA de soporte es el control de calidad para las conversaciones con clientes. Tomas una rúbrica (¿fue correcta la respuesta? ¿fue el tono adecuado? ¿resolvió realmente el problema?) y calificas las conversaciones según ella, y luego usas lo que encuentras para entrenar a los agentes y corregir las lagunas. Bien hecho, es la manera en que un equipo de soporte mejora en lugar de simplemente volverse más rápido, y se vincula con todo, desde la gestión de SLA hasta el ahorro de costes de soporte.
Aquí está el problema con el que he convivido en la cola: la versión manual solo examina una pequeña porción. Un analista de QA saca un puñado de tickets por agente a la semana, los puntúa en una hoja de cálculo y pasa a otra cosa. Si tu equipo gestiona unos pocos miles de conversaciones al mes, estás revisando quizás el 2% de ellas. El 98% que no abriste podría estar lleno de respuestas amables, seguras y completamente equivocadas, y tu programa de QA nunca lo sabría.
Esa pequeña porción no solo es pequeña, también está sesgada. Los analistas se inclinan por los tickets que son fáciles de puntuar, los más recientes o los que ya han sido marcados. El caso límite verdaderamente extraño, el que sigilosamente hizo que un cliente se fuera, rara vez llega a la muestra. Así que acabas entrenando a los agentes sobre un 2% aleatorio mientras los patrones que realmente mueven el CSAT se esconden en la parte que nadie lee.
El QA manual también es lento e inconsistente. Dos revisores puntúan la misma conversación de forma diferente. Para cuando llega una nota de coaching, el agente ya ha gestionado 400 tickets más. Nada de esto es culpa del analista; es un problema matemático: los humanos no pueden leerlo todo, así que leen una muestra, y una muestra no puede decirte nada sobre toda tu cola.
Qué cambia cuando la IA gestiona tu QA
El cambio es simple de enunciar y difícil de exagerar: puntuar el 100% de las conversaciones cuesta aproximadamente el mismo esfuerzo que puntuar el 2%. Una vez que una IA lee cada conversación según tu rúbrica, la cobertura deja de ser algo que racionas.
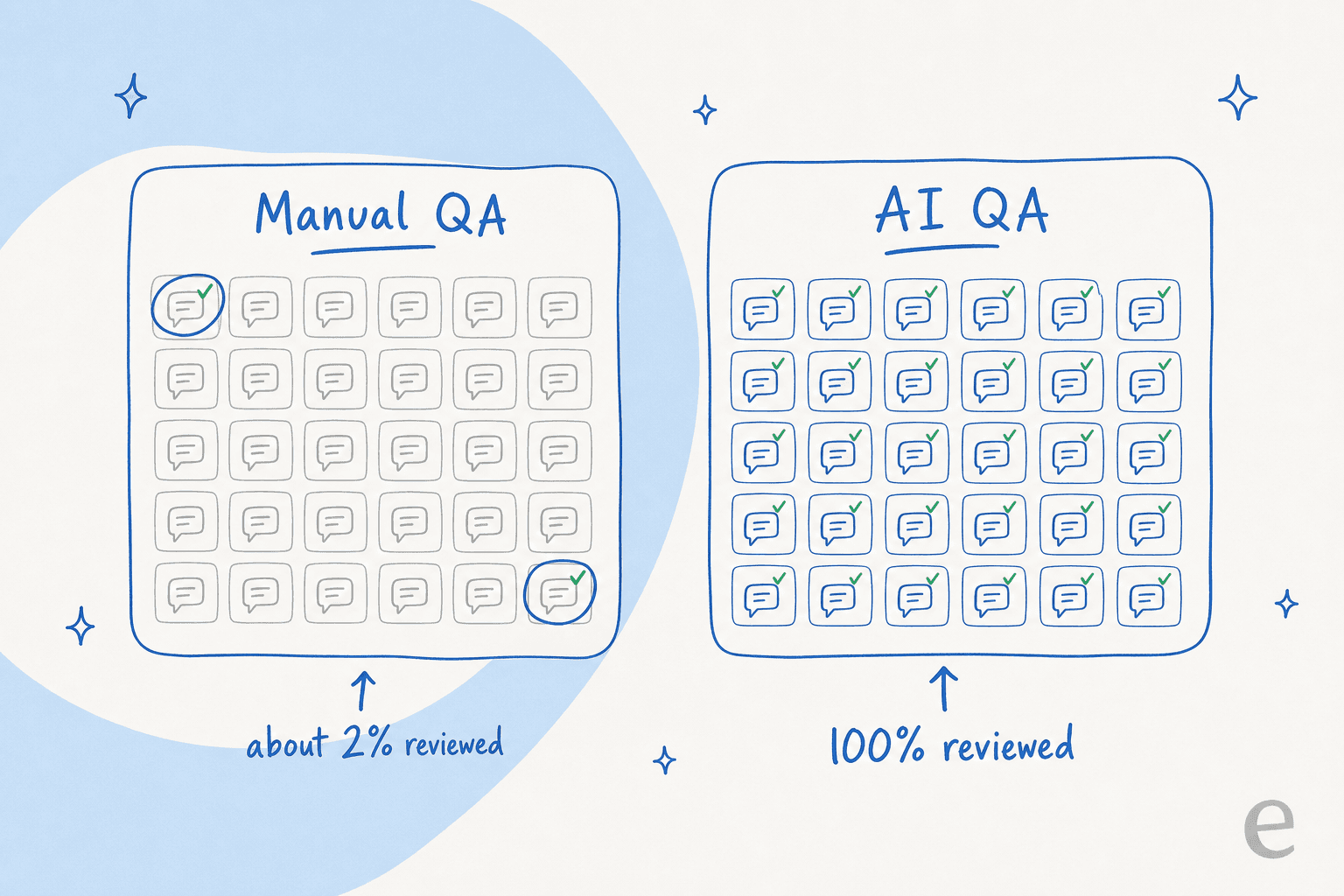
Tres cosas cambian a la vez. Primero, el sesgo de muestreo desaparece, porque no hay muestra: la IA califica toda la cola con una rúbrica consistente. Segundo, el ciclo de retroalimentación se acelera: una conversación puede ser puntuada minutos después de cerrarse, no al final de un ciclo de revisión. Tercero, el QA deja de ser una revisión puntual y se convierte en una métrica de soporte que puedes seguir a lo largo del tiempo, por agente, por tema, por canal.
Lo que no cambia: el juicio sigue siendo responsabilidad de las personas. La IA lo lee todo y marca lo que parece incorrecto; un humano decide qué hacer al respecto. Esa división del trabajo es la misma que hace que la IA frente al soporte humano funcione en cualquier otro contexto: las máquinas para el volumen, las personas para las decisiones que requieren criterio. También es por eso que el QA encaja de forma tan natural junto a un copiloto de IA en tu flujo de trabajo de soporte: los mismos datos de conversación sirven a ambos.
Cómo hacer QA de soporte con IA, paso a paso
Hacerlo bien es simplemente aplicar la IA y la automatización en soporte a la calidad en lugar del volumen, y no necesitas un equipo de datos para ello. Todo son cinco pasos, y el ciclo importa tanto como los pasos, porque el QA solo vale la pena si los hallazgos vuelven al trabajo.
Paso 1: Escribe qué aspecto tiene una respuesta "buena"
El QA es tan bueno como su rúbrica, y una rúbrica para IA tiene que ser explícita, sin "lo reconocerás cuando lo veas". Especifica las pocas cosas según las que se calificará cada respuesta. En la práctica son unas cinco dimensiones: si era factualmente correcta, si el tono era adecuado, si resolvió el problema, si seguía la política y si citaba una fuente real en lugar de inventarse algo.
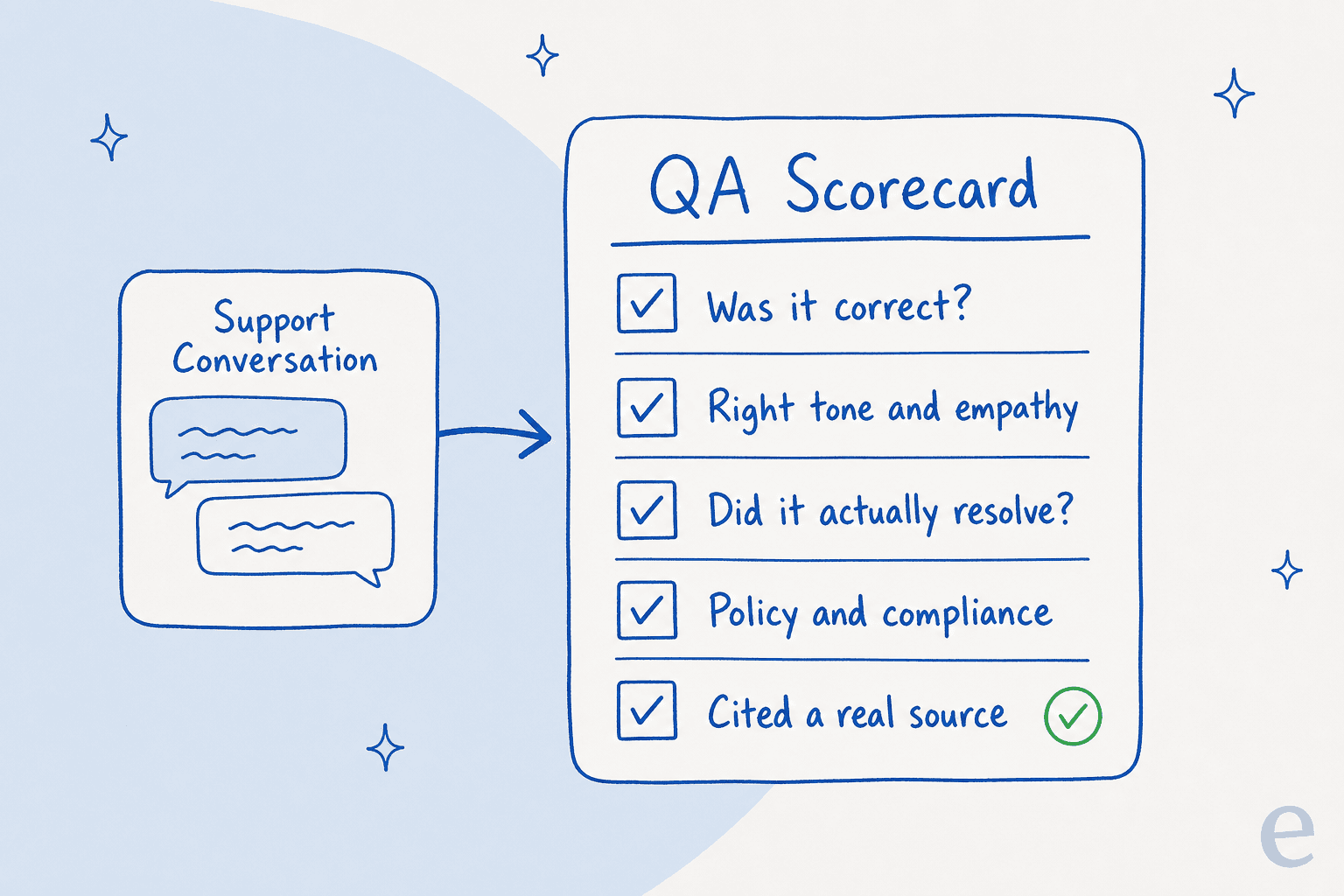
Mantenla concisa. Una rúbrica con 30 criterios es una rúbrica que nadie aplica de manera consistente, ni humano ni IA. El criterio de las fuentes importa más de lo que la gente espera: una respuesta segura sin fuente detrás es exactamente el tipo de cosa que se ve bien en una hoja de cálculo y resulta ser una alucinación cuando la compruebas.
Paso 2: Conecta cada conversación, no una muestra
Apunta la IA a todo tu historial de conversaciones, no a una exportación de los tickets marcados de la semana pasada. Eso normalmente significa conectar tu helpdesk directamente para que las conversaciones cerradas fluyan automáticamente, tanto si usas Zendesk, Freshdesk, Gorgias o Help Scout.

Aquí es también donde entra tu base de conocimientos. Una puntuación de QA de "incorrecto" solo es útil si sabes si el agente estaba equivocado o si lo estaba la documentación. Proporcionar a la IA tanto las conversaciones como el material fuente que debería haber usado le permite distinguir entre ambos casos, que es la diferencia entre entrenar a una persona y corregir un artículo de chatbot de base de conocimientos.
Paso 3: Puntuación automática según la rúbrica
Ahora la IA lee cada conversación y la puntúa en tus dimensiones. El resultado que buscas no es un número único, sino un desglose: esta conversación obtuvo una puntuación baja en resolución, esta acertó en la respuesta pero el tono era incorrecto, este lote falló en la misma política. Las tendencias importan más que cualquier calificación individual.

Trata la primera semana de puntuaciones como calibración, no como doctrina. Lee un bloque de las calificaciones de la IA frente a tu propio criterio y ajusta la rúbrica donde sea demasiado estricta o demasiado permisiva. Después de un par de pasadas las puntuaciones se estabilizan, y confiarás en ellas como confiarías en un segundo analista, con la comprobación ocasional por muestreo. Esta es la misma disciplina detrás del seguimiento del tiempo de primera respuesta o cualquier otro número de soporte: la métrica solo es útil cuando crees en ella.
Paso 4: Detecta momentos de coaching y patrones
Puntuar todo no sirve de nada si el resultado es un muro de números. El beneficio está en que la IA puede extraer las conversaciones que un humano debería revisar realmente: los tres tickets de esta semana en los que un agente prometió algo fuera de la política, el tema en el que todas las respuestas puntuaron bajo, el nuevo empleado cuyo tono falla con los reembolsos.
Esa es la capa de coaching, y es donde el QA se gana su lugar. En lugar de "aquí hay cinco tickets aleatorios que califiqué", el responsable del equipo recibe "aquí están los momentos específicos que merecen una conversación, agrupados por lo que tienen en común". Los patrones recurrentes también alimentan directamente el resto de tu operación: un tema que sigue puntuando bajo suele ser una brecha de clasificación de tickets o de escalada, no un problema de personas. Corrige la documentación o la regla de etiquetado de tickets que está detrás y a menudo también reduces el volumen de tickets al mismo tiempo.
Paso 5: Cierra el ciclo
Un QA que no cambia nada es teatro. El último paso es retroalimentar los hallazgos: entrena a los agentes que la IA marcó, reescribe la documentación detrás de los fallos recurrentes y actualiza la rúbrica a medida que tu producto y tus políticas cambian.

Cuando parte de tu soporte está automatizado, cerrar el ciclo también significa corregir a la propia IA. Las buenas herramientas aprenden de esas correcciones, de modo que una corrección que haces una vez evita que el mismo fallo se repita. Eso convierte el QA de un informe retrospectivo en algo que mejora activamente la automatización del servicio de atención al cliente semana tras semana.
Lo que todo el mundo olvida: hacer QA del propio agente de IA
Aquí está el punto que la mayoría de los artículos sobre "IA para QA" omiten, y es el que más me importa tras más de tres años poniendo agentes de IA en colas de soporte en vivo. Si vas a dejar que la IA gestione tickets, esa IA necesita pasar el QA antes de tocar a un cliente, y la mayoría de los equipos nunca ejecutan esa comprobación.
He visto a un bot que sonaba convincente responder una pregunta de manera equivocada con total convicción. Un responsable de suplementos DTC nos planteó el riesgo claramente: una IA que responde "lo siento, no lo sé" a todo es inútil, pero una IA que adivina es peor, porque nadie puede releer 7.000 tickets para atrapar las suposiciones. La respuesta a ambas situaciones es el QA: el agente solo debe gestionar aquello de lo que está seguro, y deberías puntuar su trabajo de la misma manera que puntúas el de un humano.
Así que incorporamos esa comprobación. Antes de que un agente de eesel salga en vivo, puedes ejecutarlo en una simulación contra tus tickets pasados reales y ver su calidad y cobertura por tema, sin que ningún cliente se vea involucrado. Cuando auditamos un agente contra el tráfico real de Zendesk de un cliente, obtuvo alrededor del 93% en precisión de clasificación y detectó el 100% del spam sin falsos positivos, pero las respuestas en borrador solo eran direccionalmente correctas el 88% de las veces, con una tasa de errores factuales del 7%. Ese 7% es la razón exacta por la que haces QA de la IA: se ve genial en conjunto y aun así necesita un umbral de confianza y un humano en el ciclo para los casos difíciles. Las mismas puntuaciones aparecen luego en vivo en tus analíticas del agente, así que el QA de la IA nunca realmente se detiene.
Esta es también la respuesta más honesta a "¿puedo confiar en ella?" No confías por fe, la sometes a QA, la configuras para que redacte en lugar de enviar automáticamente donde su confianza es baja, y amplías su autonomía a medida que las puntuaciones lo justifican. Esa es la diferencia entre una demo y un despliegue.
Errores comunes que evitar
Algunas trampas en las que veo caer a los equipos cuando llevan el QA a la IA:
- Tratar la puntuación de la IA como definitiva. Es un primer pase, no un veredicto. Compruébala por muestreo, especialmente al principio, de la misma manera que calibrarías a un analista nuevo.
- Una rúbrica demasiado grande. Treinta criterios suenan rigurosos y puntúan de manera inconsistente. Cinco dimensiones precisas superan a treinta difusas.
- Puntuar conversaciones sin cerrar el ciclo. Si nada cambia (sin coaching, sin correcciones en la documentación, sin actualizaciones de la rúbrica) has creado un informe muy detallado que nadie aplica.
- Olvidar hacer QA de la automatización. Si la IA está respondiendo tickets, es el "agente" de mayor volumen que tienes. No puntuarlo es el mayor punto ciego de todos.
- Confundir el QA con el CSAT. Un cliente puede calificar una conversación con cinco estrellas después de recibir una respuesta equivocada con total convicción. El QA comprueba si la respuesta era realmente correcta, por eso quieres tanto tus puntuaciones de QA como tu informe CSAT de Gorgias o el CSAT de Freshdesk, no uno sustituyendo al otro.
Prueba eesel para el QA de soporte
Si quieres hacer QA de soporte con IA sin tener que unir tres herramientas diferentes, esto es exactamente para lo que está diseñado el agente de helpdesk de IA de eesel. Se conecta a tu helpdesk y base de conocimientos existentes, lee tus conversaciones pasadas, y (esta es la parte que importa para el QA) te permite ejecutar una simulación sobre tickets históricos reales para que puedas ver la calidad y la cobertura antes de que nada salga en vivo.

En lo que respecta al software de servicio de atención al cliente con IA, la parte útil para el QA es que el mismo motor que puntúa los borradores de un agente de IA es el que lee las conversaciones de tu equipo, de modo que el QA de los humanos y el QA de la automatización conviven en un solo lugar en lugar de en dos hojas de cálculo. Funciona como un compañero de equipo que se incorpora en una tarde y ya conoce tu centro de ayuda, con unos precios basados en el uso que no te cobran por asiento por el privilegio de revisar tus propios tickets. Gratis para probar.
Preguntas frecuentes
¿Qué es el QA de soporte y en qué se diferencia el QA de soporte con IA?
¿Puede la IA puntuar conversaciones de soporte con precisión?
¿Qué porcentaje del volumen de soporte debería revisar con QA de IA?
¿El QA de soporte con IA reemplaza a mis analistas de QA?
¿Cómo hago QA de un agente de soporte de IA?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.