
Entonces, ¿qué puede hacer realmente Claude Fable 5?
Claude Fable 5 es la quinta generación de modelos de Anthropic y un nuevo nivel de «clase Mythos» que se sitúa por encima de Claude Opus 4.8, que a su vez se sitúa por encima de Sonnet 4.6. Si has leído nuestra visión general de Claude, este es el nuevo techo. Se lanzó el 9 de junio de 2026 y funciona en claude.ai, la API de Claude, Claude Code, AWS y Microsoft Foundry.
Pero las especificaciones y los niveles no son realmente lo que la gente quiere decir cuando pregunta qué puede hacer. Se refieren a: ¿qué trabajo puedo entregarle y confiar en que lo terminará? Aquí está el mapa honesto de sus capacidades concretas, y luego repasaremos cada una.
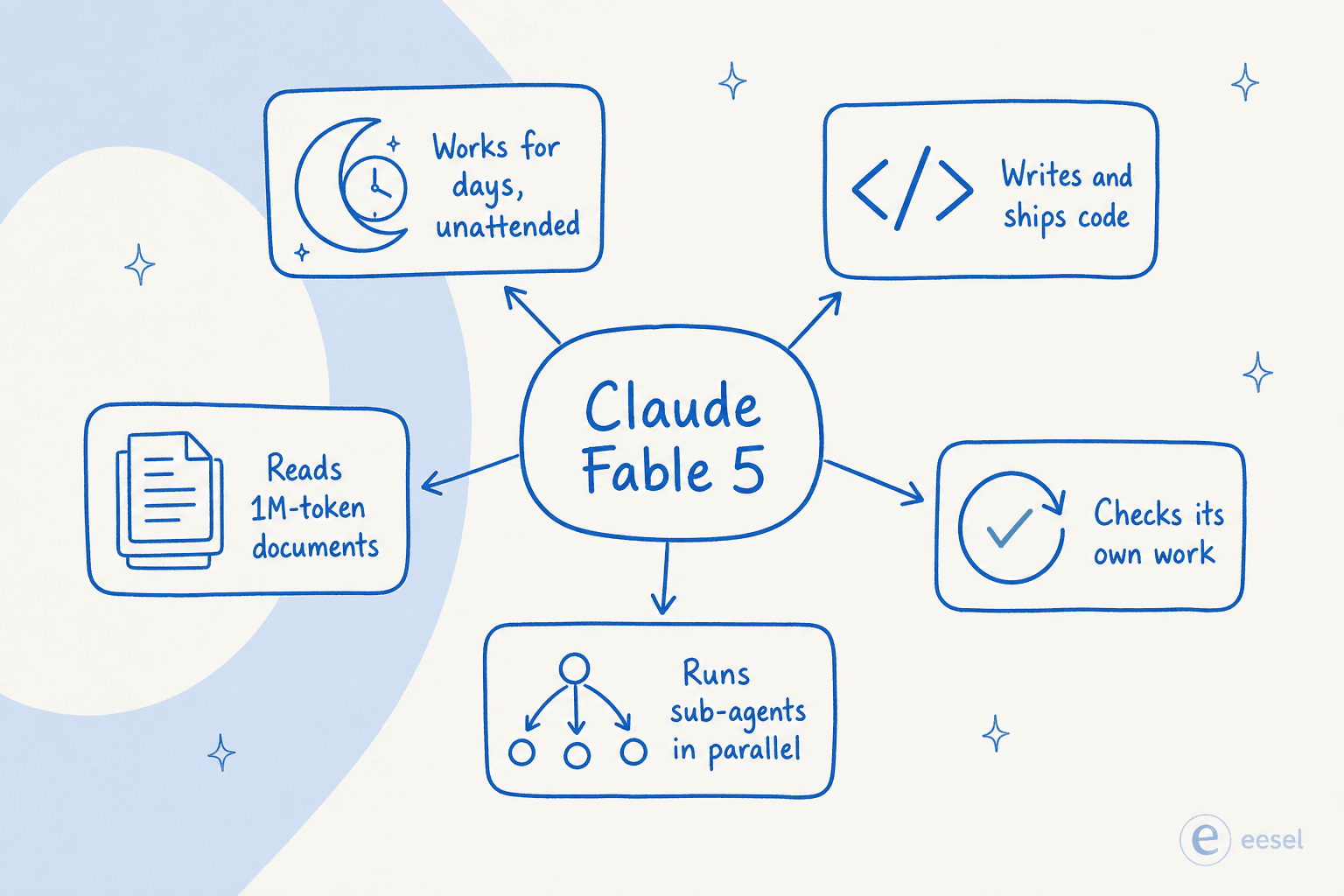
Funciona de forma autónoma durante días y luego revisa su propio trabajo
Esta es la capacidad en torno a la cual Anthropic construyó realmente Fable 5, y es la que más importa. Ejecútalo dentro de un harness como Claude Code o Claude Managed Agents y, en palabras de Anthropic, puede «trabajar durante días seguidos: planificando a lo largo de las etapas, delegando en subagentes y revisando su propio trabajo».
Ese bucle —planificar, luego delegar, luego trabajar, luego revisar— es la parte que realmente es nueva. Los modelos anteriores perdían el hilo en tareas largas de varias etapas; este mantiene el rumbo y, fundamentalmente, corrige sus propios deberes. Anthropic lo describe como «minucioso, proactivo y revisa su propio trabajo», y los proveedores de la nube detallan un bucle de planificar, revisar y refinar integrado. La autocorrección es la diferencia entre un agente al que tienes que vigilar y uno que puedes dejar ejecutándose toda la noche.
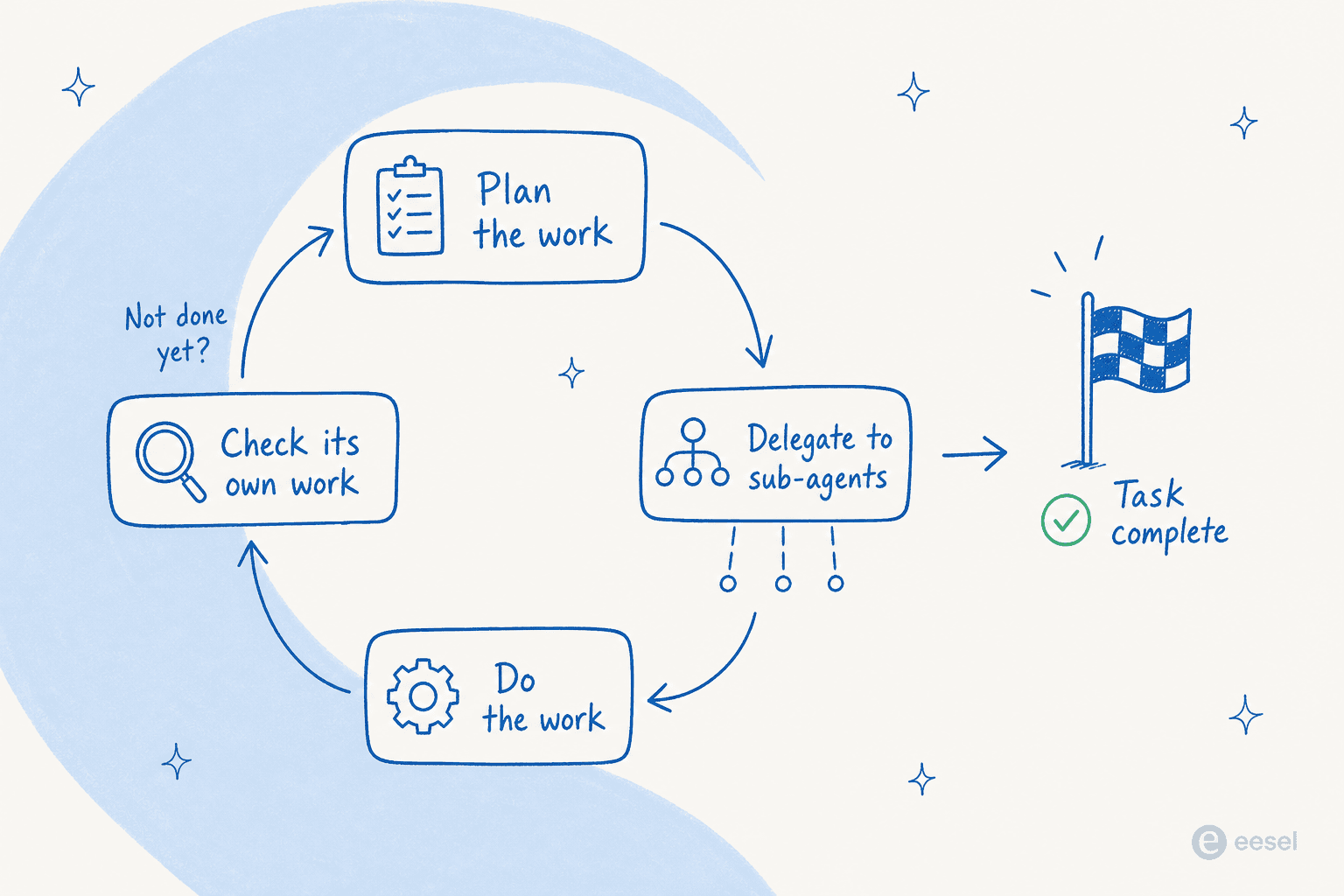
La escala que esto desbloquea es real. En las primeras pruebas, Stripe apuntó Fable 5 a una base de código Ruby de 50 millones de líneas y ejecutó una migración a lo largo de todo el proyecto en un día, y los informes de la comunidad describen sesiones que despliegan hasta 1.000 subagentes en paralelo para trabajo a escala de base de código. Esa capacidad de mantener un objetivo, dividirlo en etapas y avanzar a través de ellas es exactamente lo que separa a un agente de IA de un chatbot basado en reglas: uno termina el trabajo, el otro espera la siguiente instrucción.
Escribe y despliega código de nivel de producción
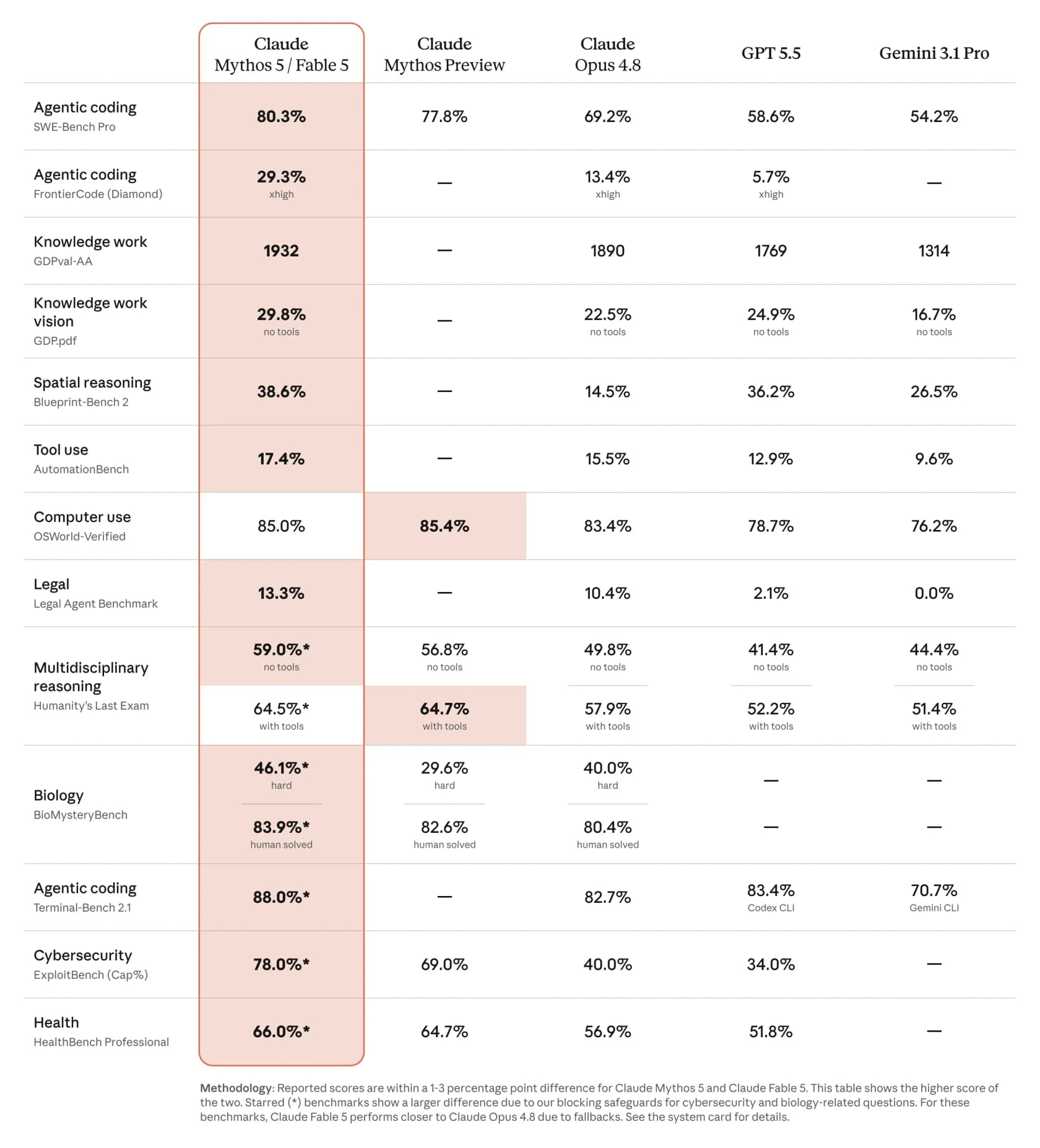
Lo más llamativo que puede hacer Claude Fable 5 es escribir software que realmente funciona. En la comparación publicada por Anthropic obtiene un 80,3 % en SWE-Bench Pro de codificación agéntica, frente al 69,2 % de Opus 4.8, con GPT 5.5 en el 58,6 % y Gemini 3.1 Pro en el 54,2 %. En el benchmark más duro FrontierCode (Diamond) más que duplica a Opus, saltando al 29,3 % desde el 13,4 %. CNBC informó de que la diferencia era de más de un 10 % por encima de Opus 4.8 en algunas pruebas.
Los números son una cosa; un día completo de trabajo real es otra. El desarrollador Simon Willison apuntó Fable a su librería LLM de código abierto, e identificó e implementó cuatro correcciones distintas, y luego desplegó una nueva versión escrita casi por completo por el modelo. Su veredicto resume el techo de productividad:
«Estoy muy impresionado con la calidad del diseño de la API, los tests, el código y la documentación que Fable elaboró para esto. Pasé varias horas en ello hoy, pero se siente como varios días de trabajo». - Simon Willison
No estaba solo. Andrej Karpathy lo llamó un salto cualitativo que merece un incremento de versión mayor, y un desarrollador que ejecutaba el benchmark FrontierCode publicó una progresión llamativa: Opus 4.7 en el 5,2 %, Opus 4.8 en el 13,4 %, Fable 5 en el 29,3 %. Si estás sopesando dónde se sitúa frente al resto del panorama, nuestra recopilación de las mejores herramientas de asistente de codificación con IA y las mejores herramientas de desarrollo con IA de Claude son una buena lectura a continuación.
Lee los documentos largos y desordenados que ya tienes
Mucho trabajo empresarial no es código, son documentos, y aquí es donde la ventana de contexto de 1.000.000 de tokens demuestra su valor. Fable 5 «entiende diagramas, gráficos y tablas anidados en archivos y PDF», algo que Anthropic enmarca en torno al trabajo financiero, legal y de análisis, y no hay recargo de precio por llenar ese contexto completo.
La prueba concreta vino de un usuario de Hacker News que le entregó un PDF de 50 páginas de especificaciones densas e interconectadas y recibió de vuelta un desglose correcto de lo que estaba hecho, parcialmente hecho y faltante:
«Le di un PDF de 50 páginas de especificaciones bastante densas e interconectadas y le pregunté cuáles se habían implementado... identificó correctamente lo que estaba hecho, lo que estaba parcialmente hecho y lo que faltaba». - Comentarista de Hacker News
Para cualquier equipo que esté sentado sobre una pila de contratos, documentos de políticas o una extensa base de conocimiento, eso es más útil en el día a día que otro punto en una tabla de clasificación de codificación. Es también el mismo músculo que usa un agente de soporte cuando lee tus documentos de ayuda y tickets pasados para responder a un cliente, solo que apuntado a documentos internos.
Lo que cuesta hacer todo esto
Aquí está la parte que modera el entusiasmo. Todo lo anterior se ejecuta a precios de herramienta frontera: 10 $ por millón de tokens de entrada y 50 $ por millón de salida, exactamente el doble que Opus 4.8. Los tokens de entrada en caché obtienen un descuento del 90 %, y hay un recargo de 1,1x para la inferencia solo en EE. UU., pero la tarifa principal es lo que vas a notar. Para ver cómo se compara Fable 5 con el resto de la gama, nuestra guía de precios de Claude desglosa cada nivel, y el plan Claude Pro es donde la mayoría de las personas lo conocen por primera vez.
| Especificación | Claude Fable 5 |
|---|---|
| Lanzamiento | 9 de junio de 2026 |
| Clase de modelo | «Clase Mythos», un nivel por encima de Opus 4.8 |
| Ventana de contexto | 1.000.000 de tokens |
| Salida máxima | 128.000 tokens |
| Fecha de corte de conocimiento | Enero de 2026 |
| Precio de entrada | 10 $ / 1 M de tokens (1 $ en caché) |
| Precio de salida | 50 $ / 1 M de tokens |
| Recargo por contexto largo | Ninguno |
Cuánto gastas realmente depende casi por completo de cuánto le dejes pensar. Simon Willison ejecutó su prueba de «dibuja un pelícano en una bicicleta» en los cinco niveles de esfuerzo de razonamiento, y el coste de una sola imagen osciló entre menos de 10 céntimos en «low» y unos 72 céntimos en «max». El nivel de esfuerzo es un dial que tú ajustas, y es la principal palanca de tu factura.
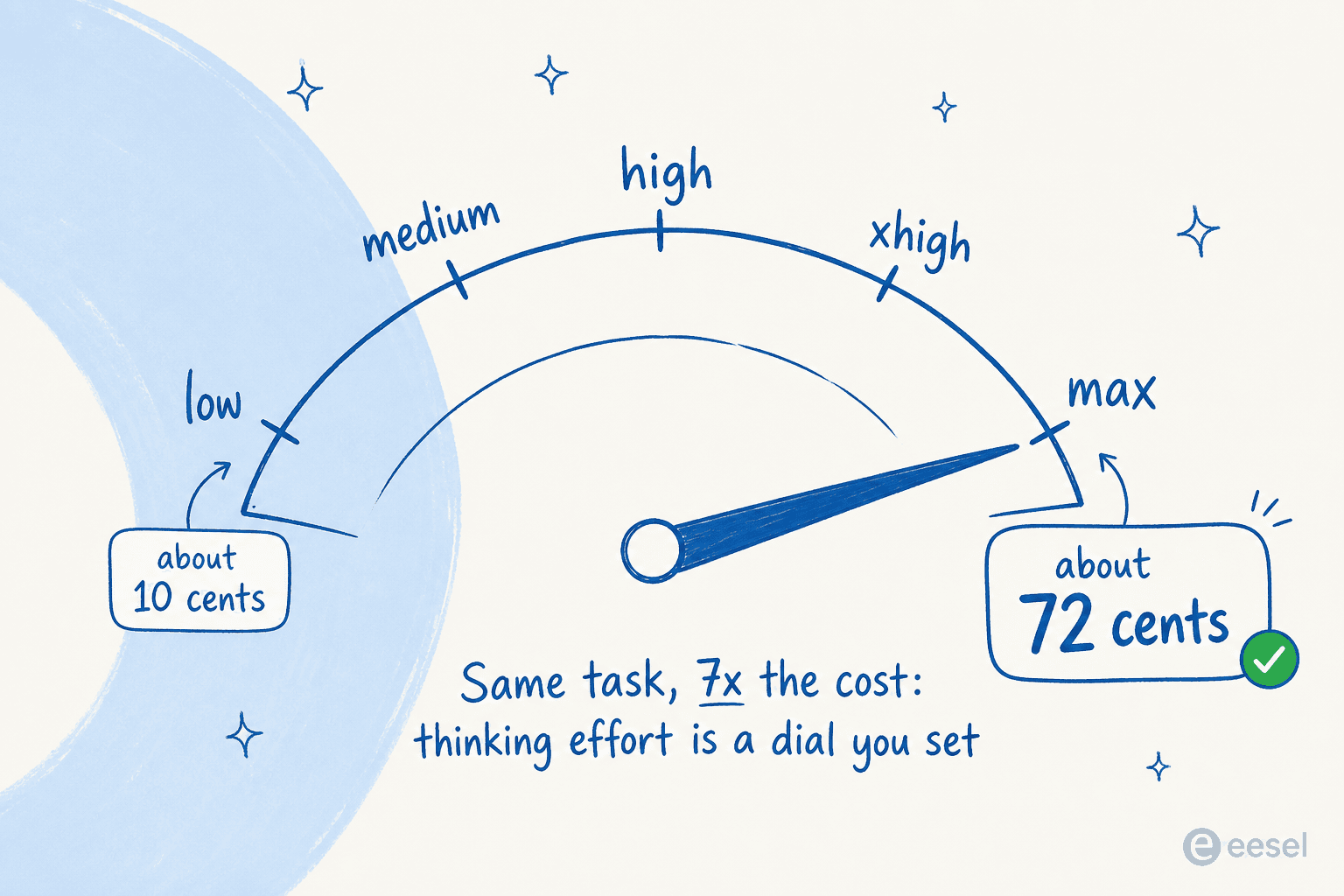
La factura se acumula rápido en el extremo alto. Willison registró un solo día de pruebas con 110,42 $ de gasto en tokens. Pero hay un contrapeso real: el responsable de evaluaciones de Canva descubrió que Fable usaba aproximadamente la mitad de los tokens de Opus 4.8 en sus harnesses agénticos internos, así que un modelo más inteligente que termina en menos pasos puede acabar con un coste real más o menos igual. La lección no es «Fable es inasequible», sino que tus costes dependen por completo de cómo lo ejecutes.
Lo que Claude Fable 5 no hará
Las capacidades cortan en ambos sentidos, y hay una cosa que Fable 5 deliberadamente no hará a plena potencia. Para prompts de ciberseguridad, biología, química y destilación de modelos, una nueva generación de clasificadores detecta el tema y enruta tu respuesta a Opus 4.8 en su lugar, y se te avisa de que ha ocurrido. Anthropic dice que al menos el 95 % de las sesiones nunca activan ningún fallback.
El problema son los falsos positivos. Algunos desarrolladores informaron de que se les cambiaba al modelo más débil a mitad de sesión para trabajo completamente inofensivo, incluido un usuario al que se le rechazó un protocolo básico de manipulación de líquidos sin nada arriesgado en él. El escritor de políticas de IA Nathan Lambert señaló un segundo mecanismo, más silencioso, para prompts que parecen investigación de IA frontera, donde el modelo puede volverse menos eficaz sin decírtelo. El consejo práctico: si tu trabajo se sitúa en un vertical técnico, pruébalo antes de comprometerte con él.
Lo que significa todo esto si diriges un equipo de soporte
Aquí es donde vivimos, así que seamos específicos. Dado todo lo que puede hacer Fable 5, ¿debería un responsable de soporte apresurarse a conectarlo a su helpdesk? En su mayor parte, no tanto como sugiere el bombo.
Aquí está la verdad incómoda sobre la IA para atención al cliente: para los tickets de nivel 1, el modelo rara vez es el cuello de botella. La mayoría de los equipos que buscan automatización de la atención al cliente están silenciosamente sobrevalorando qué modelo hay debajo. Un Opus 4.8 bien fundamentado o incluso Sonnet 4.6 ya responde correctamente la abrumadora mayoría de las preguntas de «dónde está mi pedido», «cómo restablezco mi contraseña», «cuál es vuestra política de reembolsos». Pagar el doble por Fable 5 para responderlas es como alquilar un coche de Fórmula 1 para llevar a los niños al colegio. Lo que realmente decide si tu agente de helpdesk con IA funciona es todo lo que está envuelto alrededor del modelo. Es el mismo patrón que separa las herramientas fuertes de cualquier recopilación de software de helpdesk con IA de las olvidables.
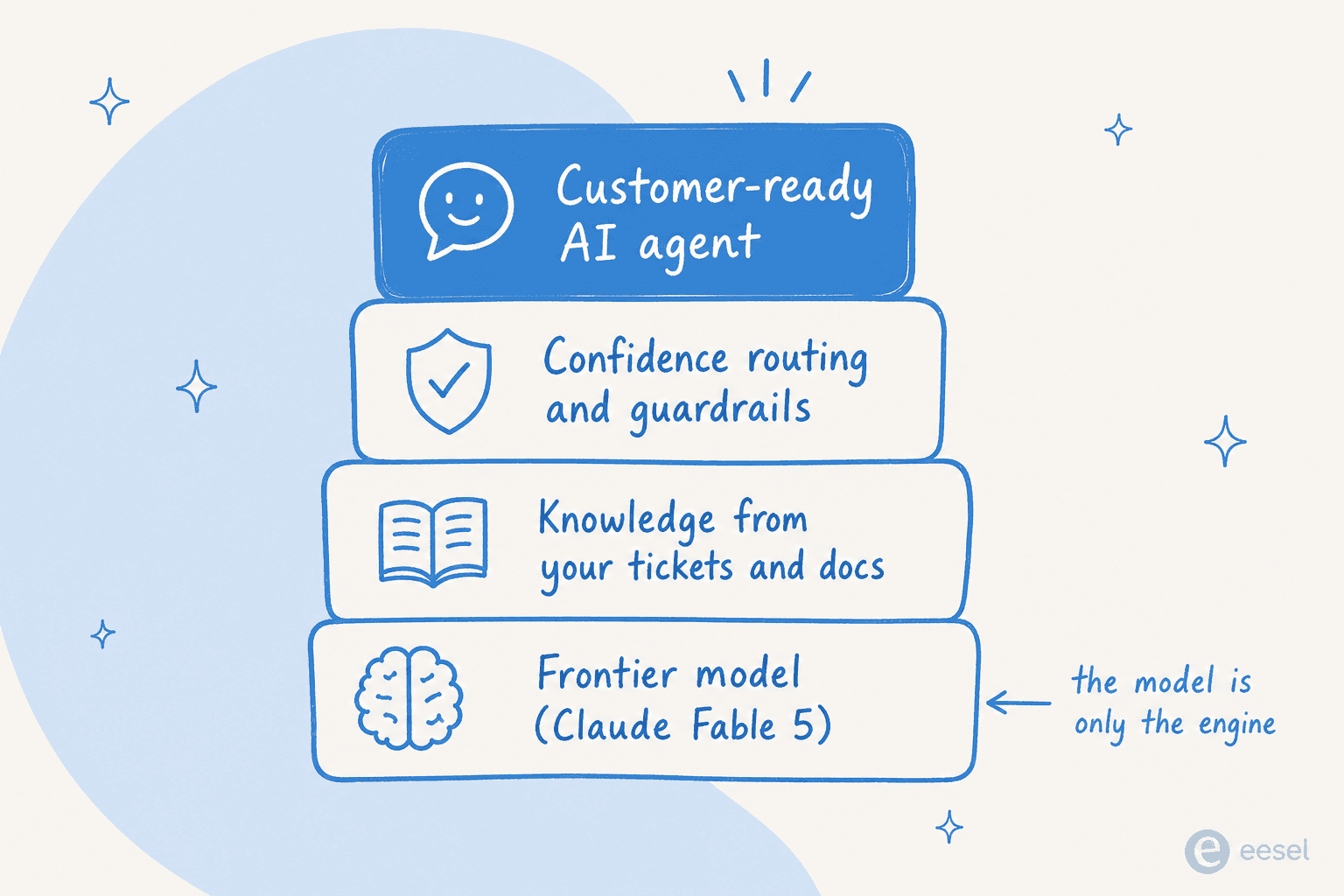
Tres cosas importan más que el nivel del modelo. Primero, ¿conoce tu negocio? La ventaja viene de entrenar con tus tickets pasados y documentos de ayuda, no de un modelo base más inteligente. Segundo, ¿sabe cuándo callar? Los modelos en bruto responden con confianza incluso cuando se equivocan, que es precisamente por qué los chatbots dan malas respuestas; los agentes de producción necesitan un enrutamiento basado en la confianza, el corazón de cualquier buena configuración de triaje de tickets, para que los tickets de baja confianza se redacten o escalen, no se envíen automáticamente. Como lo expresó el responsable de CX de un proveedor DTC de suplementos en una entrevista con clientes, la IA nunca responderá el 100 % de las preguntas, así que lo que realmente quieren es un agente que solo gestione los tickets en los que confía y deje el resto en paz. Eso es una capacidad de producto, no una capacidad del modelo.
Tercero, ¿puedes confiar en él antes de que se ponga en marcha? Eso apunta directamente a la pregunta de construir frente a comprar, que surge constantemente: «Anthropic acaba de lanzar un modelo increíble, ¿por qué no construir nuestro bot de soporte sobre la API?». Puedes. También es un proyecto más grande de lo que parece, porque el modelo te da inteligencia, pero no la conexión con el helpdesk, los guardarraíles, el entorno de simulación ni los informes. Varios equipos técnicos que lo intentaron se pasaron a comprar en su lugar:
«Podríamos intentar escribir nuestra propia aplicación de LLM, pero no queríamos invertir nuestro tiempo en eso. Queríamos algo que no tuviéramos que mantener». - Karel, GENERAL BYTES
Un modelo frontera es la capa inferior del stack, no todo el stack. Si tu producto principal es la IA, constrúyelo. Si es cualquier otra cosa y solo quieres que los tickets se respondan bien, comprar las capas por encima del modelo es más rápido, más barato y menos frágil, la misma lógica detrás de elegir cualquier IA para automatización de tickets en lugar de un script casero.
Prueba eesel
eesel AI es la capa que se sitúa encima de modelos frontera como Claude, así que obtienes la capacidad sin el proyecto de ingeniería. Se conecta a tu helpdesk existente (Zendesk, Freshdesk, HubSpot, Gorgias y más de 100 integraciones), aprende de tus tickets pasados y documentos de ayuda desde el primer día, y responde en triaje, redacción y resolución.

El diferenciador es la parte que Fable 5 no puede darte por sí solo: un modo de simulación que ejecuta el agente contra miles de tus tickets pasados para que veas exactamente cómo habría respondido, y cuál sería tu tasa de resolución, antes de que un solo cliente hable con él. Así fue como Gridwise llegó al 73 % de las solicitudes de nivel 1 resueltas en su primer mes. Y como el precio es basado en el uso, a 0,40 $ por ticket resuelto y sin tarifas por puesto, pagas por resultados, no por tokens que no puedes predecir. Puedes probar eesel gratis con 50 $ de uso y sin tarjeta de crédito.
Preguntas frecuentes
¿Qué puede hacer Claude Fable 5 que los modelos anteriores no podían?
¿Puede Claude Fable 5 escribir y ejecutar código por su cuenta?
¿Puede Claude Fable 5 gestionar preguntas de atención al cliente?
¿Cuánto cuesta ejecutar Claude Fable 5?
¿Qué no puede hacer Claude Fable 5?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.





