Entonces, ¿puede la IA realmente hacer QA de soporte?
Respuesta corta: sí, y mejor que la versión manual en la dimensión que más importa: la cobertura.
Construyo los agentes de IA que hacen esto, así que déjame ser preciso sobre lo que significa ese "sí". El QA de soporte tradicional consiste en un analista que extrae un puñado de tickets por agente por semana, los puntúa en una hoja de cálculo y pasa a otra cosa. Si tu equipo gestiona unos miles de conversaciones al mes, eso supone revisar quizás el 2% de ellas, y un 2% sesgado, porque los revisores tienden hacia los tickets que son fáciles de puntuar. El caso límite extraño que silenciosamente perdió a un cliente casi nunca llega a la muestra.
La IA lo invierte. Una vez que un modelo lee cada conversación frente a tu rúbrica, puntuar el 100% de las conversaciones cuesta aproximadamente el mismo esfuerzo que puntuar el 2%. La cobertura deja de ser algo que raciones. La trampa es que "leer todo" y "juzgar todo correctamente" son dos afirmaciones distintas. La IA clava la primera. La segunda es donde mantienes a un humano en el bucle.
Lo que la IA hace bien (y las pruebas)
Aquí es donde el QA con IA es genuinamente sólido, y prefiero mostrarte números reales antes que adjetivos.
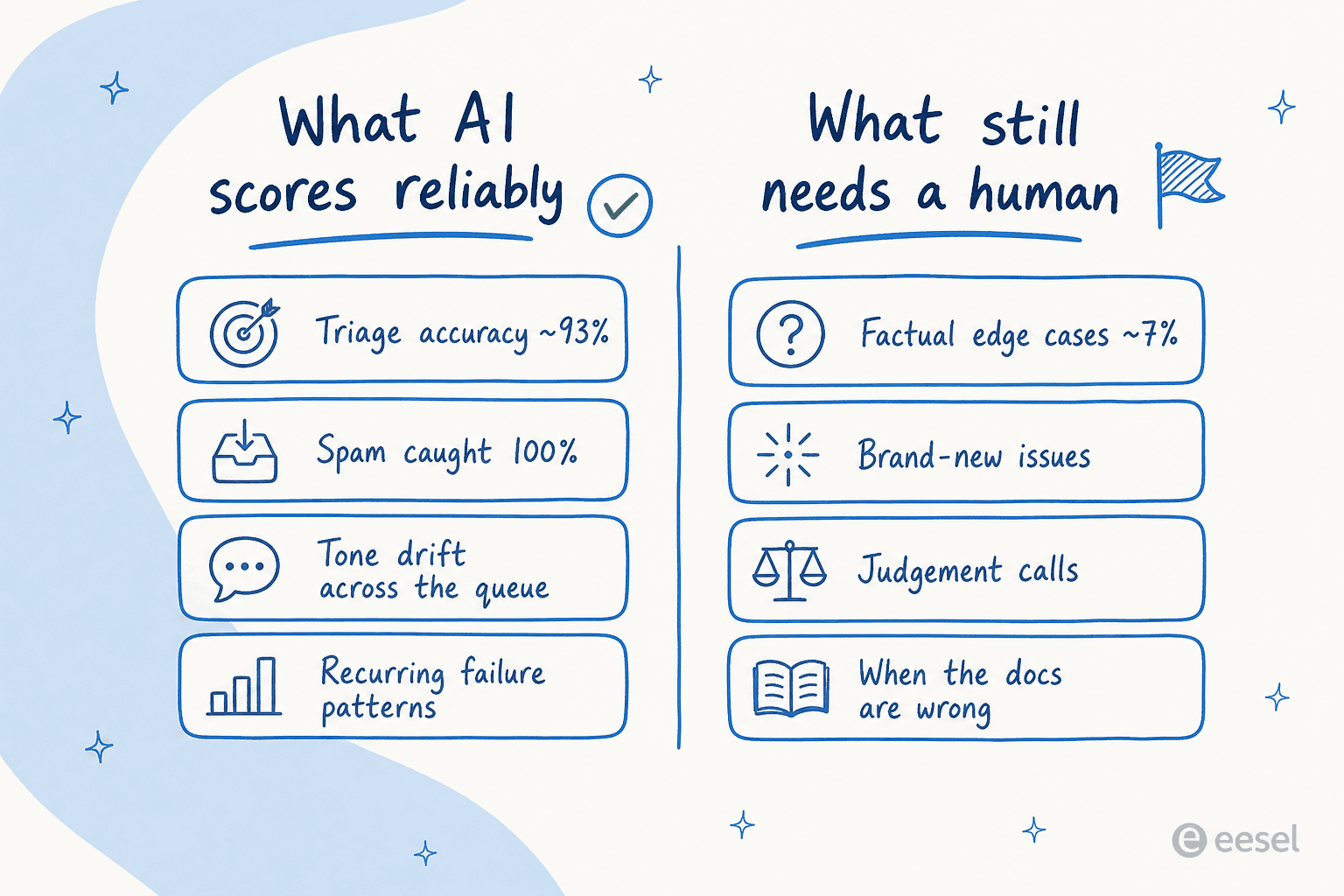
Cuando ejecutamos un agente contra el tráfico real de Zendesk de un cliente, obtuvo aproximadamente un 93% en precisión de clasificación y detectó el 100% del spam sin falsos positivos, en una bandeja de entrada que era un 22% spam. Categoría por categoría fue aún más preciso: borradores útiles en devoluciones y reembolsos el 93,8% de las veces, reclamaciones de garantía el 96,4%, consultas de producto y consultas de estado de reembolso el 100%. Esos son los tickets repetitivos y con muchos patrones que el QA existe para mantener consistentes, y un modelo que ha leído tu historial es excelente detectando cuándo una respuesta se desvía del patrón.
La misma fortaleza se aplica a tus humanos. La IA es muy buena en las cosas que un revisor cansado pasa por alto: el tono que falla en los reembolsos, una política que un agente sigue interpretando sutilmente mal, un tema donde cada respuesta puntúa bajo porque el documento de ayuda subyacente está desactualizado. Esos son patrones, y los patrones son lo que un modelo que lee toda la cola encuentra y que una muestra del 2% estructuralmente no puede. Además, nunca se aburre en el ticket 4.000, lo que no puedo decir de ningún turno de QA humano.
Cómo puntúa realmente la IA una conversación
Esta es la parte que la gente imagina que es una caja negra, y realmente no lo es. El mecanismo es la misma rúbrica que usaría un revisor humano, simplemente aplicada a todo.
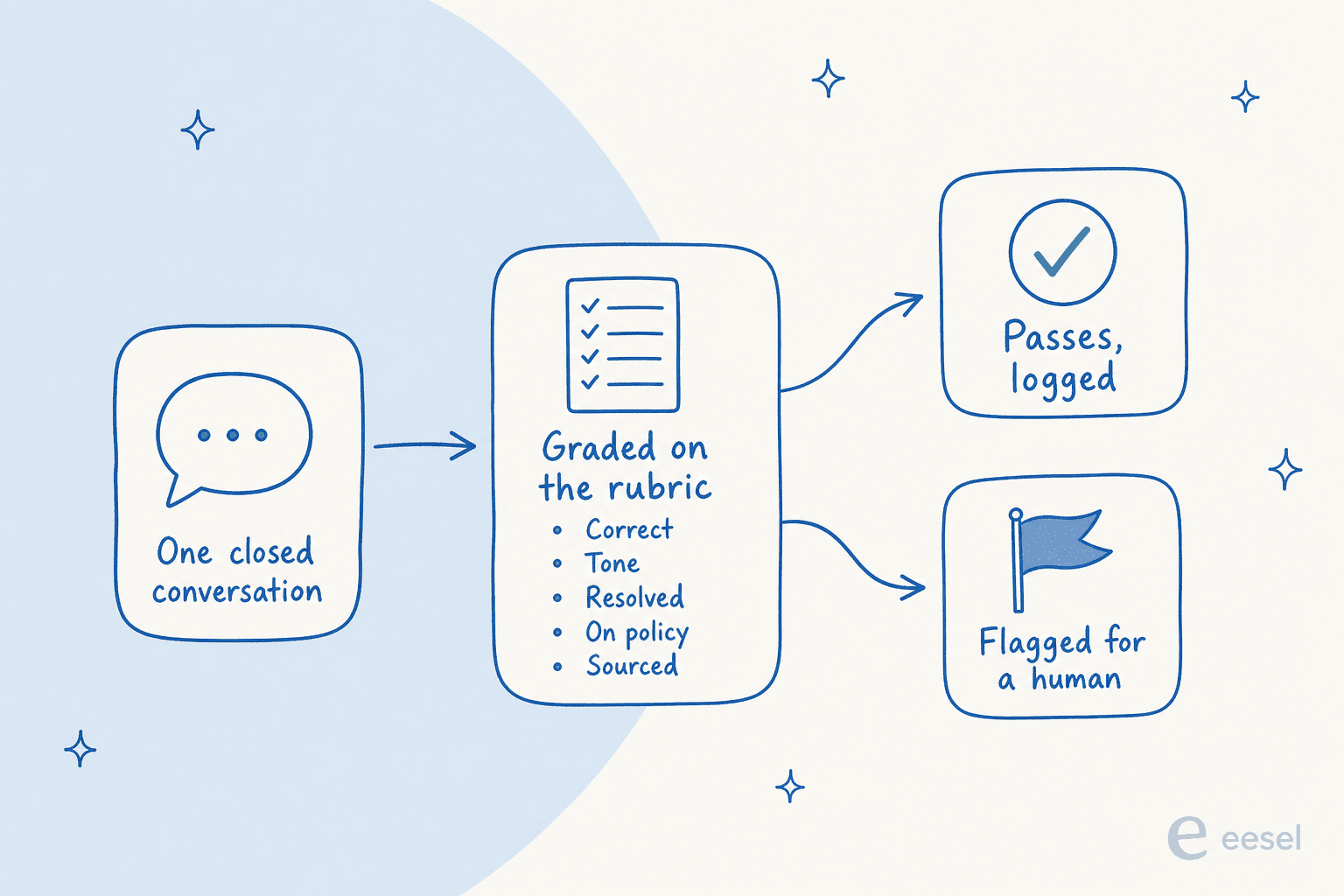
Entra una conversación cerrada. La IA la evalúa en un puñado de dimensiones explícitas: ¿era factualmente correcta?, ¿el tono era el adecuado?, ¿realmente resolvió el problema?, ¿siguió la política?, ¿citó una fuente real en lugar de inventarse algo? Las conversaciones que aprueban se registran; las que puntúan bajo se marcan para que una persona las revise. El resultado que quieres no es un número único, sino un desglose que puedes monitorizar con el tiempo, para poder ver que este lote falló todo en la misma política o que un tema está arrastrando tus puntuaciones hacia abajo.
Dos cosas determinan el éxito o el fracaso. Primero, la rúbrica tiene que ser explícita, sin "ya lo sabrás cuando lo veas." Cinco dimensiones precisas superan a treinta vagas, tanto para la IA como para el humano. Segundo, tienes que alimentarla tanto con las conversaciones como con la base de conocimiento de la que debería haber venido la respuesta. Una puntuación de "incorrecto" solo es útil si sabes si el agente se equivocó o si la documentación era incorrecta, y esa distinción es la diferencia entre formar a una persona y reescribir un artículo. Si quieres la guía completa, escribimos un paso a paso sobre cómo hacer QA de soporte con IA.
Dónde el QA con IA todavía necesita un humano
Ahora la otra mitad honesta, porque un artículo de QA que solo lista puntos fuertes es exactamente el tipo de cosa que el QA con IA supuestamente debería detectar.
Volvamos a esa auditoría. Los borradores del agente eran correctos en dirección el 88% de las veces, pero solo el 12% eran suficientemente buenos para que un agente los enviara tal cual, y había una tasa de error factual del 7%. Analiza la brecha y es revelador: alrededor del 65% de las reescrituras eran solo de longitud y tono (la IA escribió ocho frases donde el equipo envía tres), alrededor del 20% necesitaban datos que la IA no podía ver (una consulta al ERP o de logística), y solo alrededor del 5% eran casos donde la IA estaba directamente equivocada. Así que la mayor parte de lo que "necesita un humano" es solucionable con mejor entrenamiento, pero esa última fracción de error factual es la parte que nunca automatizas completamente.
El ejemplo más claro que he visto: la IA de un equipo les decía con confianza a los clientes "sí, soportamos tu modelo" para productos que en realidad no estaban en su base de datos, porque el centro de ayuda decía "soportamos todos los modelos." La IA no estaba alucinando, estaba repitiendo fielmente un documento que era incorrecto. Ninguna cantidad de calidad del modelo lo detecta por sí sola. Un humano que lee el patrón marcado lo detecta en cinco minutos. Esa es la verdadera división del trabajo en IA vs soporte humano: la IA lee todo y saca a la superficie el patrón sospechoso, una persona decide lo que significa y soluciona la causa raíz.
Así que las cosas en las que mantener a un humano: problemas nuevos sin precedentes en tu historial, decisiones que requieren juicio como una excepción de buena voluntad, todo lo que depende de contexto de negocio que vive en la cabeza de alguien en lugar de en tu documentación, y la calibración periódica de las propias puntuaciones de la IA. Trata la calificación de la IA como la opinión de un segundo analista, no como un veredicto final, y obtienes la cobertura sin los puntos ciegos.
La prueba que la mayoría de equipos omite: ¿puede la IA hacerse QA a sí misma?
Aquí está el punto que la mayoría de artículos sobre "IA para QA" pasan por alto, y es el que más me importa. Si vas a dejar que la IA gestione tickets, esa IA tiene que pasar el QA antes de tocar a un cliente, y la mayoría de equipos nunca ejecutan esa comprobación.
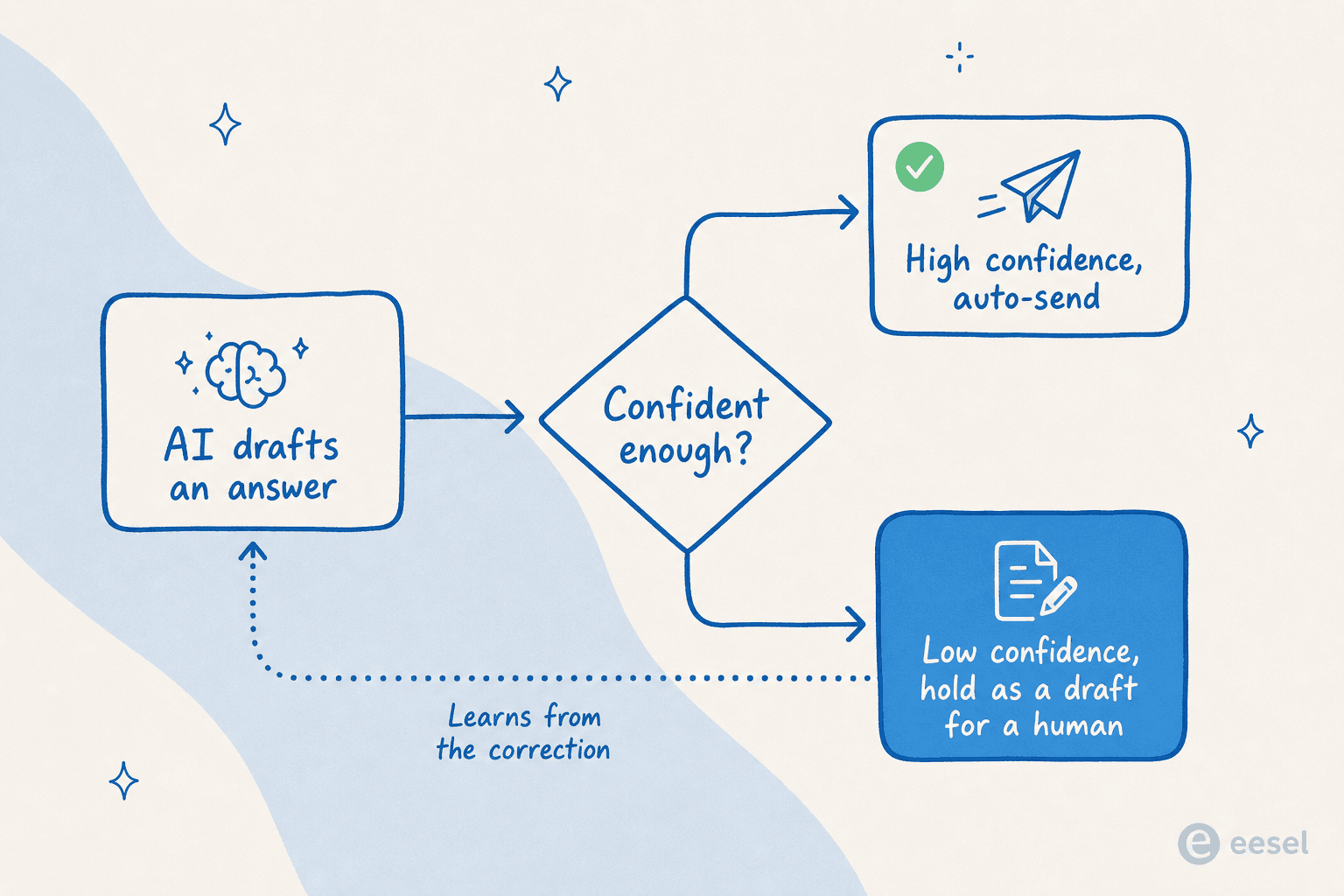
El mecanismo es el enrutamiento basado en confianza. El agente solo envía automáticamente las respuestas sobre las que tiene confianza; cualquier cosa por debajo del umbral la retiene como borrador para un humano, y aprende de la corrección para que el mismo error no se repita. Un responsable de suplementos DTC nos planteó las apuestas perfectamente: una IA que responde "lo siento, no lo sé" a todo es inútil, pero una IA que adivina es peor, "porque nadie puede releer 7.000 tickets para detectar las suposiciones." El QA es la respuesta a ambos.
Así que integramos la comprobación en el despliegue. Antes de que un agente de eesel entre en producción, lo ejecutas en una simulación contra tus tickets pasados reales y ves su calidad y cobertura por tema, sin que ningún cliente esté involucrado. Así es como obtuvimos los números del 93% y el 7% en primer lugar, del lado seguro del cristal. Una vez que está activo, las mismas puntuaciones aparecen en tus analíticas del agente, por lo que el QA sobre la automatización nunca se detiene realmente.

Esta es también la respuesta más honesta a "¿puedo confiar en él?" No confías en él por fe. Le haces QA, lo configuras en modo borrador en lugar de envío automático donde su confianza es baja, y amplías su autonomía a medida que las puntuaciones lo justifican. Esa es la línea entre una demo y un despliegue.
Cómo los equipos usan el QA con IA en el día a día
En la práctica se asienta en un bucle, y el bucle importa más que cualquier puntuación individual. La IA puntúa cada conversación cuando se cierra. Saca a la superficie los momentos de formación que un humano debería revisar, agrupados por lo que tienen en común, en lugar de cinco tickets aleatorios. Un líder de equipo actúa sobre los patrones: formando a los agentes que fueron marcados, corrigiendo la documentación detrás de los errores repetidos, actualizando las reglas de etiquetado de tickets y escalación que un tema de baja puntuación expone. Corrige la documentación detrás de un error recurrente y a menudo reduces el volumen de tickets al mismo tiempo.
En cuanto a herramientas, tienes dos grupos. Las plataformas dedicadas de QA como Zendesk QA (el producto antes conocido como Klaus) y MaestroQA puntúan conversaciones automáticamente y alimentan flujos de trabajo de formación, y son una buena opción si el QA es una función independiente para ti. El otro grupo es el software de atención al cliente con IA que incluye el QA junto al agente que hace el trabajo, de modo que el mismo motor que puntúa las conversaciones de tu equipo es el que hace el QA de los borradores de la IA. Un último punto de referencia que vale la pena mencionar: el QA no es CSAT. Un cliente puede dar cinco estrellas a una respuesta confiadamente incorrecta, así que quieres tanto tus puntuaciones de QA como tu informe de CSAT, no uno sustituyendo al otro.
Prueba eesel para el QA de soporte
Si quieres QA de soporte con IA sin unir tres herramientas, eso es exactamente para lo que está construido el agente de helpdesk con IA de eesel. Se conecta a tu helpdesk existente, lee tus conversaciones pasadas y tu base de conocimiento, y te permite ejecutar una simulación sobre tickets históricos reales para que puedas ver la calidad y la cobertura antes de que nada entre en producción.

La parte útil para el QA es que el mismo motor que puntúa los borradores de un agente de IA es el que lee las conversaciones de tu equipo, por lo que el QA sobre humanos y el QA sobre automatización viven en un solo lugar en lugar de en dos hojas de cálculo. Se integra en una tarde, ya conoce tu centro de ayuda, y los precios basados en uso no te cobran por puesto por el privilegio de revisar tus propios tickets. Gratis para probar.
Preguntas frecuentes
¿Puede la IA hacer control de calidad en soporte con precisión?
¿Cómo puntúa realmente la IA una conversación de soporte?
¿Qué no puede hacer la IA en el control de calidad de soporte?
¿Qué porcentaje de mi volumen de soporte puede cubrir la IA en QA?
¿Puede la IA hacer QA también a un agente de soporte de IA?
¿El QA de soporte con IA reemplaza a mis analistas de QA?
¿Qué herramientas pueden hacer control de calidad de soporte con IA?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.