Control de calidad para soporte con IA: cómo confiar realmente en tu agente de IA
Riellvriany Indriawan
Katelin Teen
Última edición June 19, 2026

Qué significa el control de calidad cuando el agente es IA
El QA de soporte tradicional es un juego de muestreo. Un líder de equipo revisa tal vez el 2-5 % de los tickets de la semana pasada, los puntúa según una rúbrica (¿el agente lo resolvió? ¿fue amable? ¿siguió la política?) y entrena a los humanos que fallaron. Funciona porque los humanos son en su mayoría consistentes y fallan de maneras predecibles.
Un agente de IA rompe dos de esas suposiciones. Maneja un volumen mucho mayor del que cualquier proceso de muestreo manual fue diseñado para cubrir, y falla de maneras poco familiares. Un nuevo empleado humano rara vez inventa una política de devoluciones sobre la marcha; una IA sin base sólida lo hará, y en una oración segura y bien redactada que parece exactamente una respuesta correcta. Por eso el QA deja de ser "entrenar a los casos extremos" y se convierte en "verificar el sistema", más parecido al tipo de evaluación de agentes de IA que harías en cualquier pipeline automatizado.
El cambio de perspectiva que importa: el control de calidad de un agente de IA ocurre en dos lugares, antes de salir al mercado y después, no es un informe mensual que lees una vez que el daño ya está hecho.
Por qué la tasa de deflexión es la métrica que te miente
Si solo haces QA a un número, que no sea la tasa de deflexión. Cuenta las conversaciones que no llegaron a un humano, agrupando en silencio dos resultados muy diferentes: clientes a los que la IA realmente ayudó y clientes que se rindieron.
Los profesionales del soporte lo sienten en sus entrañas. Una responsable de operaciones en r/CustomerExperience describió el modo de fallo claramente:
"A mi jefe le encantan nuestros números de deflexión, pero yo no me fío de ellos. Intenté sacar un informe sobre tickets que se reabrieron en 24 horas, pero los clientes simplemente abren OTRO ticket en lugar de usar el cerrado. Hace parecer que el bot hizo un buen trabajo cuando en realidad solo enfadó al cliente."
Una respuesta en un hilo relacionado fue aún más directa: "Un bot puede 'completar con éxito' un chat, pero si el usuario envía un ticket por correo 20 minutos después, ese bot fue una basura."
Ese es el problema de optimizar solo para la deflexión de nivel 1. El silencio no es lo mismo que la resolución. La métrica que realmente quieres es la resolución combinada con las tasas de reapertura y contacto repetido, para que un cliente que se fue frustrado aparezca como una pérdida en lugar de esconderse dentro de un bonito número de dashboard.
Las métricas que realmente indican si tu soporte con IA es bueno
Ningún número único hace el trabajo. Las buenas métricas de soporte con IA funcionan como un panel, donde cada una detecta un fallo que las demás pasan por alto:
- Tasa de resolución es el titular, pero defínela honestamente como "problema del cliente resuelto sin un humano", no "conversación terminada". Este es el número que vale la pena pronosticar y rastrear con el tiempo. La tasa de resolución es lo más parecido a una única fuente de verdad.
- Tasa de errores factuales es la métrica específica de IA. De una muestra calificada, ¿cuántas respuestas estaban seguramente equivocadas? Esta es tu comprobación de alucinaciones, y es la métrica que la mayoría de los equipos olvida construir.
- Calidad de escalación pregunta si el agente transfirió de manera limpia y en el momento correcto. Una transferencia a un humano limpia en un ticket difícil es un buen resultado, no un fracaso.
- Tasa de reapertura y contacto repetido es el detector de mentiras para la deflexión. Si los tickets "resueltos" siguen volviendo, no estaban resueltos.
- CSAT de IA, medido por separado del CSAT humano. Rastrea el CSAT de IA de forma independiente para que una buena puntuación del bot no sea sostenida por tus mejores agentes humanos, ni al revés.
Así se ve un proceso de calificación real cuando le pones números. Cuando el equipo hizo QA en un ensayo —un minorista online alemán de joyería con aproximadamente 1.000 tickets al mes en Zendesk y Shopify— el panorama fue específico en lugar de vago: 93 % de precisión en la clasificación, 100 % de detección de spam sin falsos positivos en el 22 % del buzón que era basura, pero solo el 12 % de los borradores lo suficientemente buenos para enviar sin tocar y una tasa de errores factuales del 7 %. Esa distribución te dice exactamente dónde invertir la próxima semana, algo que ningún número de deflexión podría hacer.

El mismo hilo de Reddit al que sigo volviendo tenía a alguien que describió casi exactamente este panel. Como un practicante de Reddit que había hablado con muchos equipos de soporte lo formuló: "La tasa de deflexión queda bien en los dashboards, pero oculta problemas de calidad. Mejores métricas serían: tasa de resolución automatizada, CSAT de IA vs. humano, tiempo de escalación, tasa de reapertura tras respuestas del bot." Cuando las personas que ejecutan la automatización de Zendesk real y las que la construyen llegan a la misma lista, esa es la lista.
QA antes del lanzamiento: simula contra tus propios tickets
Esta es la parte que la mayoría de los equipos omite, y la más valiosa de esta publicación entera. No tienes que descubrir si tu IA es buena lanzándola sobre clientes reales y leyendo las respuestas enojadas. Puedes saberlo primero.
El método es la simulación: toma el agente, apúntalo contra miles de tus tickets históricos ya resueltos y haz que genere la respuesta que habría enviado, luego compárala con lo que tu equipo humano realmente hizo. Como ya sabes la respuesta correcta, obtienes una previsión de la tasa de resolución, una lista de temas en los que la IA tiene dudas y una tasa de errores factuales, todo sin un solo cliente real en el radio de impacto. Es la versión segura de las pruebas adversariales, ejecutada contra tu historial real de tickets en lugar de un conjunto de pruebas sintético.
Esto no es teórico para nosotros. eesel ejecuta un modo de simulación que hace exactamente esto antes de que cualquier agente salga al mercado, y la razón de su existencia son las cicatrices. He visto a un bot que suena seguro dar silenciosamente una respuesta incorrecta, y también lo ha visto cualquiera que haya desplegado uno. Uno de nuestros clientes, un equipo danés de telemática vehicular en Zendesk, sufrió la versión clásica desde el principio: porque su base de conocimiento decía "soportamos todos los modelos", la IA alegremente le decía a los clientes que soportaba marcas de coches que en realidad no estaban en su base de datos. La única forma fiable de detectar esa clase de error es ver las respuestas incorrectas antes que los clientes, contra tus propios tickets.
QA después del lanzamiento: muestrear, calificar y ajustar
Una vez que estás en vivo, el control de calidad se convierte en un ritmo. Extrae una muestra fresca de conversaciones reales cada semana, califícalas según el panel anterior y retroalimenta lo que aprendas al agente. Tu helpdesk ya guarda el material en bruto: la mayoría de las plataformas exponen registros de conversaciones de los que puedes extraer una muestra, y un buen panel de análisis convierte eso en una tendencia en lugar de una lectura puntual.

La calificación en sí no tiene que ser pesada. Aprueba y rechaza respuestas con una razón ("demasiado formal", "omitió la política de devoluciones") y asegúrate de que esa señal realmente entrene al agente en lugar de desaparecer en el vacío. Un número sorprendente de compradores nos hace exactamente esta pregunta durante la evaluación, alguna versión de "¿rastrean si apruebo o rechazo respuestas y cambia algo?" Si el ciclo de retroalimentación es real, cada pasada de QA mejora las respuestas de la semana siguiente. Si no lo es, estás calificando en el vacío.
Una cosa a vigilar: cómo se comporta el agente cuando algo se rompe, como la API de tu helpdesk siendo limitada a mitad de una conversación. Amogh, el fundador de eesel, tiene una frase al respecto que se quedó grabada en nuestro equipo: si un fallo es silencioso, es "clase de fallo silencioso, la peor clase para la confianza". Una IA que falla ruidosamente y transfiere está haciendo el trabajo del QA por ti; una que falla silenciosamente y adivina es exactamente lo que tu muestra semanal existe para detectar.
Lo más difícil: confiar en que la IA sabe lo que no sabe
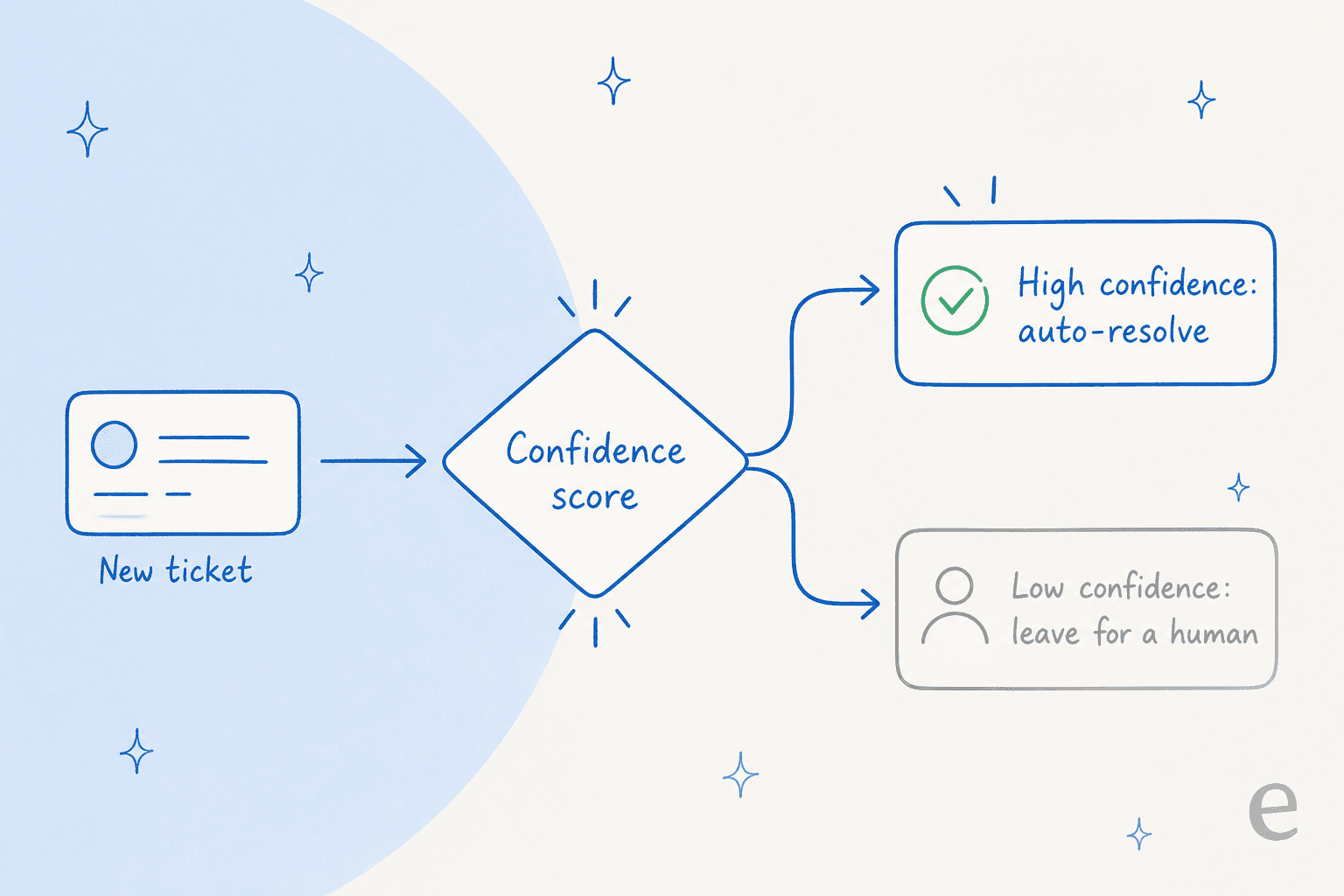
Todas las métricas anteriores se vuelven más fáciles en el momento en que la IA deja de intentar responderlo todo. Esta es la cosa más común que escucho de los equipos que nos evalúan, y vale más que cualquier actualización de modelo.
Una responsable de CX en una marca de suplementos DTC en Gorgias, gestionando unos 7.000 tickets al mes, lo expresó mejor de lo que yo jamás podría: la IA nunca va a responder el 100 % de las preguntas, pero si lo intenta y simplemente dice "lo siento, no sé", nadie puede revisar 7.000 tickets para ver si realmente hizo un buen trabajo. Lo que querían era una IA que "solo gestione los tickets para los que tiene confianza y todos los demás los deje en paz."
Eso es el enrutamiento basado en confianza, y es el control de QA de mayor impacto que tienes. Cuando el agente solo habla por encima de un umbral de confianza y enruta silenciosamente el resto a un humano, tu tasa de errores factuales baja, tus escalaciones se vuelven significativas y las respuestas que necesitas evaluar son un conjunto más pequeño y de mayor calidad. El mismo hilo de Reddit tenía una advertencia aguda: un practicante recordó a todos que no "caigan en el discurso de 'cero alucinaciones'" mientras reencuadraba toda la conversación alrededor de la resolución frente a la deflexión. El enrutamiento por confianza es cómo llegas ahí honestamente: no afirmando que la IA nunca se equivoca, sino manteniéndola callada cuando podría hacerlo.
Para los equipos regulados esto no es negociable. El cofundador de una empresa de tecnología legal nos dijo que solo podían adoptar la IA porque podían "establecer límites exactos sobre las fuentes y siempre proporciona citas transparentes", la diferencia entre ser útil y cruzar a dar asesoramiento legal. Las citas y los umbrales de confianza no son características, son el QA.
Un flujo de trabajo de QA que realmente puedes ejecutar
Si quieres un punto de partida concreto, aquí está el ciclo que configuraría para cualquier equipo que esté desplegando un agente de IA, ya sea en Zendesk, Freshdesk o cualquier helpdesk con IA:
- Simula primero. Antes del lanzamiento, reproduce el agente contra unos miles de tickets pasados y lee una muestra de las respuestas hipotéticas. Establece tu umbral de lanzamiento en la tasa de resolución pronosticada, no en corazonadas.
- Lanza de forma limitada. Activa el agente para uno o dos temas seguros, no para toda la cola de tickets. El enrutamiento por confianza facilita esto.
- Califica semanalmente. Muestrea conversaciones reales, puntúalas en resolución, errores factuales y calidad de escalación, y rechaza las malas respuestas con una razón que entrene al agente.
- Vigila los detectores de mentiras. Rastrea las tasas de reapertura y contacto repetido junto a la deflexión para que un cliente frustrado no pueda ocultarse como una victoria.
- Alerta ante la deriva. Configura el monitoreo para que una caída repentina de calidad te avise entre revisiones.
Ejecuta eso durante un mes y tendrás algo que la mayoría de las historias de "desplegamos una IA" nunca consiguen: una respuesta defendible a "¿cómo sabes que es buena?"
Prueba eesel para un soporte con IA que puedas controlar de verdad
La mayor parte de esta publicación simplemente describe cómo funciona eesel, porque el control de calidad es aquello alrededor de lo que construimos el producto. Conectas tu helpdesk y tu base de conocimiento, eesel se entrena con tus tickets y documentos pasados, y antes de salir al mercado su modo de simulación reproduce el agente en miles de tus conversaciones históricas para que puedas pronosticar la tasa de resolución y leer las respuestas incorrectas en privado. Tras el lanzamiento, el enrutamiento basado en confianza mantiene al agente callado en todo aquello de lo que no está seguro, y los informes te muestran qué calificar cada semana.

Es gratis probarlo y puedes ejecutar una simulación completa con tus propios tickets antes de comprometerte a nada, que es el QA más honesto que existe: ver cómo habría respondido a tus clientes reales y luego decidir. Prueba eesel y empieza con una simulación.
Preguntas frecuentes
¿Qué es el control de calidad del soporte al cliente con IA?
¿Cómo se mide la calidad de un agente de soporte con IA?
¿Es la tasa de deflexión una buena métrica para el control de calidad del soporte con IA?
¿Cómo se evita que un agente de soporte con IA alucine?
¿Con qué frecuencia se debe hacer QA al agente de soporte con IA?
¿Se puede probar un agente de soporte con IA antes de salir al mercado?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








