
Entonces, ¿qué es exactamente Claude Fable 5?
Anthropic presenta Fable 5 como un «modelo de nivel Mythos creado para tus proyectos más ambiciosos y de larga duración», y la redacción importa. «Clase Mythos» es un nivel de capacidad totalmente nuevo que la empresa introduce por encima de su línea Opus existente, del mismo modo que Opus siempre se ha situado por encima de Sonnet y Haiku. Es la quinta generación de modelos, y Anthropic dice que está «diseñado para manejar tareas de días enteros, complejas y asíncronas que los modelos anteriores no podían sostener».
La parte un poco confusa es que Fable 5 se lanzó como una mitad de un par. Fable 5 es la versión pública y protegida que cualquiera con acceso a la API o un plan de Claude de pago puede usar. Mythos 5 es el mismo modelo subyacente con los clasificadores de seguridad retirados, restringido a socios verificados de ciberseguridad y biología a través del Project Glasswing de Anthropic. Simon Willison, que dedicó un día entero a probarlo, lo dijo sin rodeos: Anthropic dice que Fable 5 «ofrece el mismo rendimiento que Claude Mythos 5, salvo con barreras mucho más estrictas implementadas».
SecurityWeek captó por qué esto es un hito específicamente para Anthropic: la empresa dice que esto «marca la primera vez que un modelo de esta clase de capacidad ha sido considerado lo bastante seguro para el acceso generalizado del público y los desarrolladores». En otras palabras, el nivel Mythos existía antes; lo nuevo es dejar que el público general se acerque a él.
Las especificaciones que importan
Si solo quieres la versión rápida, aquí es donde se sitúa Fable 5. La ventana de contexto y la fecha de corte provienen de las notas prácticas de Simon Willison; los precios están confirmados tanto por CNBC como por SecurityWeek.
| Especificación | Claude Fable 5 |
|---|---|
| Lanzamiento | 9 de junio de 2026 |
| Clase de modelo | «Clase Mythos», un nivel por encima de Opus 4.8 |
| Ventana de contexto | 1.000.000 de tokens |
| Salida máxima | 128.000 tokens |
| Fecha de corte de conocimiento | Enero de 2026 |
| Precio | 10 $ / 1 M entrada, 50 $ / 1 M salida (2x Opus 4.8) |
| Recargo por contexto largo | Ninguno |
| Dónde ejecutarlo | claude.ai, la API de Claude, Claude Code, Claude Managed Agents, AWS y Microsoft Foundry |
Un detalle que vale la pena señalar para cualquiera que trabaje con documentos largos: no hay recargo de precio por usar el contexto completo de 1 M, lo que no siempre es el caso con los modelos de frontera. El ID de la API, si vas a conectarlo tú mismo, es claude-fable-5.
¿Qué tan potente es, en realidad?
Aquí es donde Fable 5 se gana la etiqueta de «más potente». En la comparación publicada por Anthropic, registra un salto notable en prácticamente todos los benchmarks relevantes, y las distancias sobre el resto del campo no son sutiles.
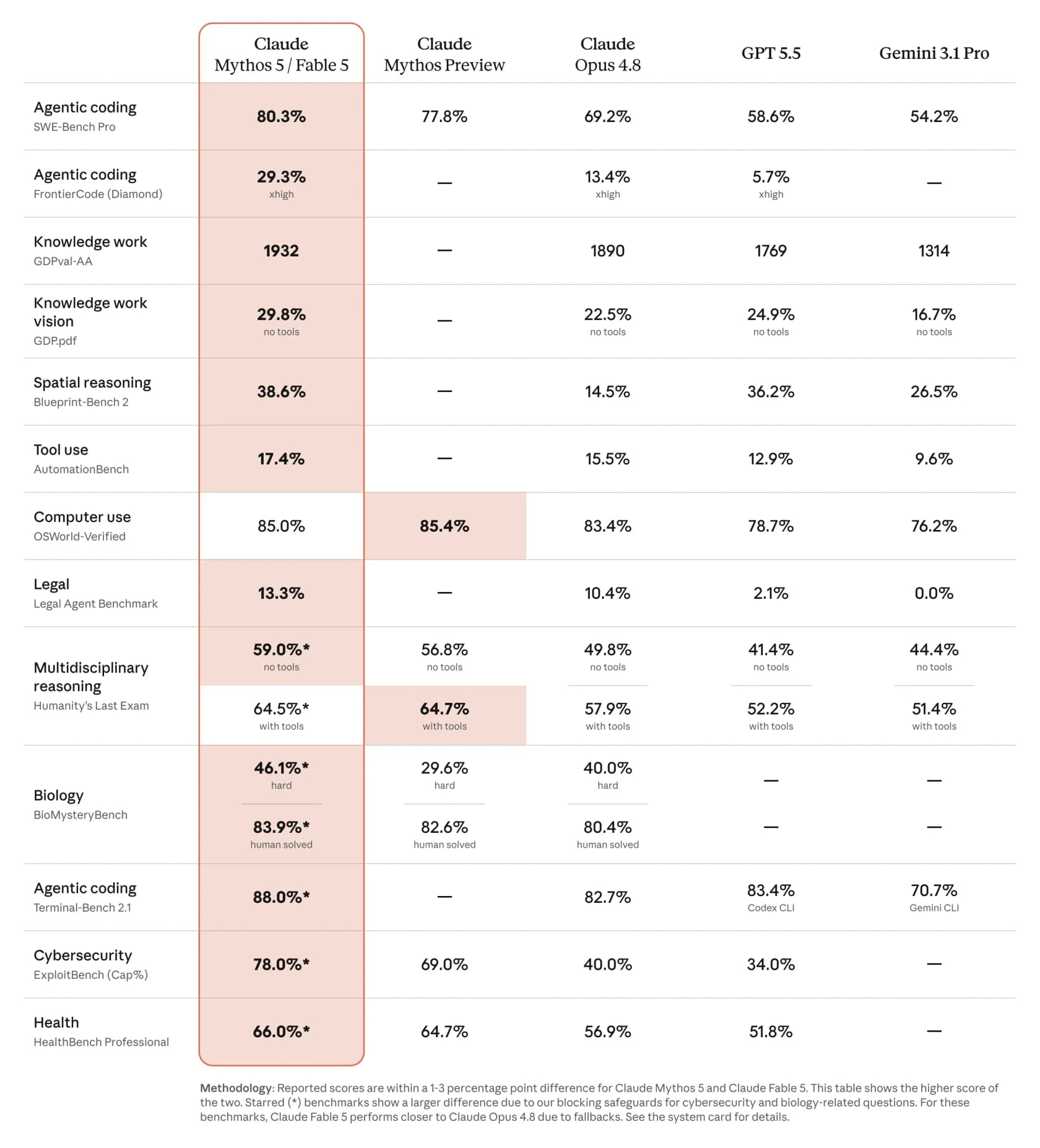
Algunas cifras que vale la pena extraer de esa tabla: 80,3 % en SWE-Bench Pro para programación agéntica, frente al 69,2 % de Opus 4.8, el 58,6 % de GPT 5.5 y el 54,2 % de Gemini 3.1 Pro. En el benchmark más duro FrontierCode (Diamond) más que duplica a Opus, saltando al 29,3 % desde el 13,4 %. El reportaje de CNBC coincide con la tabla, señalando que en algunos benchmarks Fable obtuvo más de un 10 % por encima de Claude Opus 4.8.
Los profesionales lo respaldaron rápido. Andrej Karpathy lo calificó de cambio escalonado que merece un salto de versión mayor, y un desarrollador que ejecutó el benchmark FrontierCode evaluado por mantenedores de OSS publicó una progresión llamativa: Opus 4.7 con 5,2 %, Opus 4.8 con 13,4 %, Fable 5 con 29,3 %.
Hay una advertencia honesta que conviene tener en cuenta, y viene de Nathan Lambert: esas puntuaciones publicadas son un límite superior. Como él señala, «algunos de los prompts serán degradados a Opus 4.8 con los filtros de seguridad actuales», de modo que las cifras que un usuario real obtiene en un tema marcado no siempre coincidirán con la tabla. Más sobre esto abajo.
Cómo es realmente usarlo
Los benchmarks son una cosa; un día entero de trabajo real es otra. El relato de primera mano más útil vino de Simon Willison, que describió el modelo en una palabra: una bestia.
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do." - Simon Willison
Su ejemplo más nítido del apalancamiento: apuntó Fable a su biblioteca LLM de código abierto, e identificó e implementó cuatro correcciones distintas, luego publicó una nueva versión (LLM 0.32a3) que, en sus palabras, fue escrita casi en su totalidad por Fable. Su valoración te dice casi todo lo que necesitas saber sobre el techo de productividad aquí:
"I'm really impressed with the quality of API design, tests, code and documentation that Fable put together for this. I spent several hours on it today, but it feels like several days' worth of work." - Simon Willison
También ejecutó su prueba canónica de «generar un SVG de un pelícano montando una bicicleta» en los cinco niveles de esfuerzo de pensamiento, lo que es una mirada concreta agradable al dial entre esfuerzo y coste. El pelícano de esfuerzo «max» de abajo quemó 14.430 tokens de salida, alrededor de 72 centavos por una sola imagen, frente a menos de 10 centavos en «low».

| Nivel de esfuerzo | Tokens de salida | Coste por SVG |
|---|---|---|
| low | 1.929 | ~9,67 ¢ |
| medium | 2.290 | ~11,48 ¢ |
| high | 2.057 | ~10,31 ¢ |
| xhigh | 5.992 | ~29,99 ¢ |
| max | 14.430 | ~72,18 ¢ |
Fuente: el desglose por nivel de esfuerzo de Simon Willison.
Los agentes de largo horizonte son el verdadero titular
Las puntuaciones de programación son la parte vistosa, pero aquello para lo que Anthropic realmente construyó Fable 5 es el trabajo sostenido y autónomo. Ejecútalo en un arnés como Claude Code o Claude Managed Agents y Anthropic dice que puede «trabajar durante días seguidos: planificar a lo largo de etapas, delegar en subagentes y comprobar su propio trabajo».
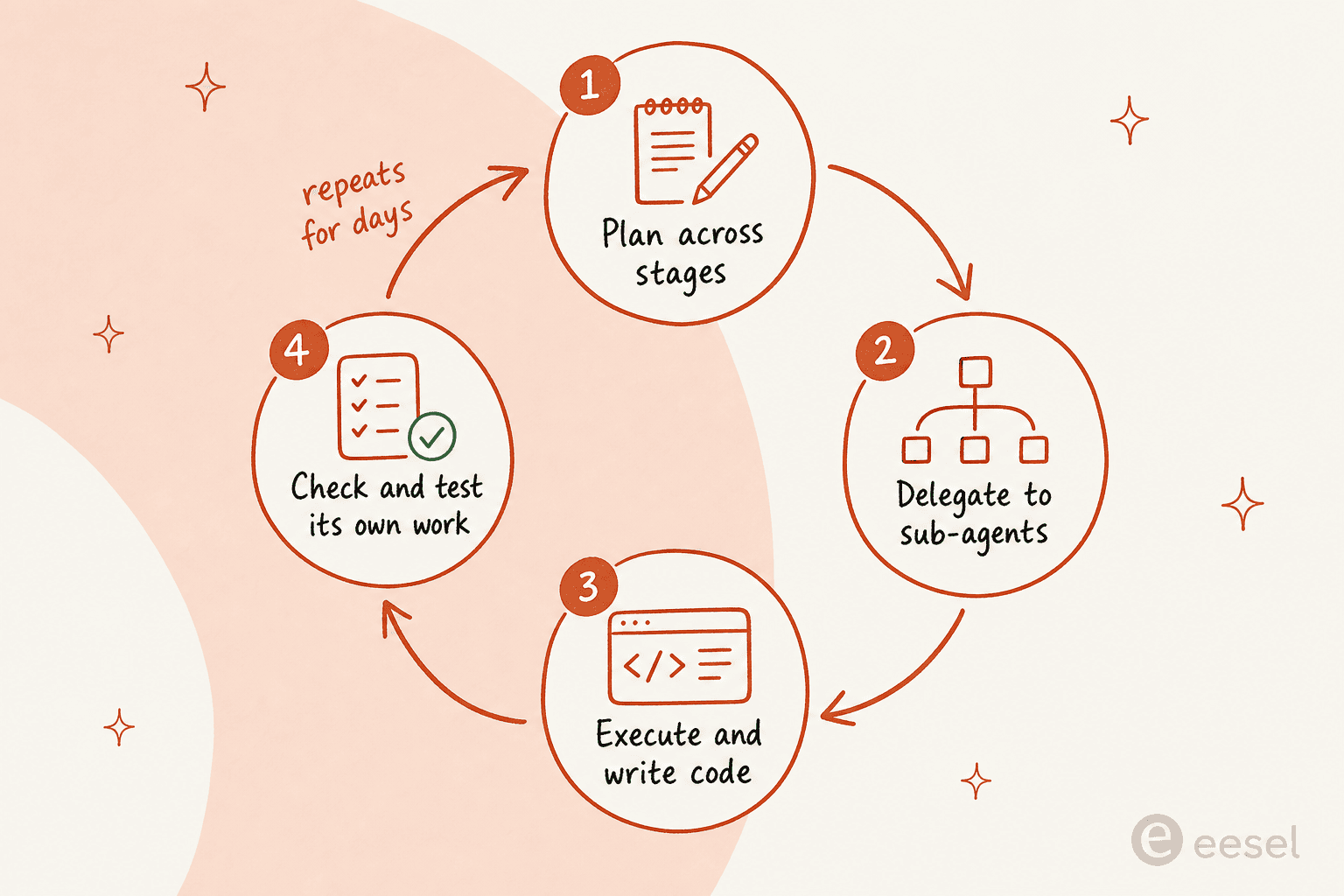
Esto no es solo lenguaje de marketing. En las primeras pruebas, según se informa, Stripe apuntó Fable 5 a una base de código Ruby de 50 millones de líneas y ejecutó una migración sobre todo el conjunto en un día, y los informes de la comunidad describen sesiones que levantan hasta 1.000 subagentes en paralelo para trabajo a escala de base de código. Un usuario de Hacker News describió cómo le entregó un PDF de 50 páginas con especificaciones densas e interconectadas y obtuvo un desglose correcto de lo que estaba hecho, parcialmente hecho y pendiente.
Esta es exactamente la forma de trabajo que convierte a los «agentes» en algo más que una palabra de moda: un modelo que puede mantener un objetivo, descomponerlo en etapas y avanzar por ellas sin que un humano vuelva a darle instrucciones en cada paso. Es el mismo principio detrás de un agente de soporte con IA que clasifica un ticket, busca un pedido, redacta una respuesta y escala los casos límite, solo que apuntado a conversaciones de clientes en lugar de a una base de código.
El truco: precio, el precipicio y el consumo de cuota
Ahora la parte que ha atemperado todo el entusiasmo. Fable 5 es genuinamente caro de ejecutar, y el despliegue tuvo un aguijón en la cola.
Empecemos por el precio puro: a 10 $ / 50 $ por millón de tokens, es el doble de caro que Opus 4.8. Dianne Penn, de Anthropic, argumentó que las cuentas del valor siguen saliendo, diciendo que los clientes «simplemente obtienen un mayor ROI al tener modelos más inteligentes», y hay pruebas reales de ello: la responsable de evals de Canva informó de que Fable usaba alrededor de la mitad de los tokens de Opus 4.8 en sus arneses agénticos internos, dejando el coste en el mundo real prácticamente igualado.
Pero esa eficiencia no se cumple para todos. Simon Willison registró el gasto de tokens de un solo día de pruebas en 110,42 $ (cubierto, por ahora, por su suscripción Max de 100 $/mes), y los usuarios de suscripción informaron de que agotaban sus límites. Un usuario del plan Max de 100 $ dijo que Fable quemó su ventana entera de 5 horas en menos de 8 minutos más 15 $ de excedente; otro vio cómo se comía su plan Max 20x a aproximadamente un 2 % por minuto.
Luego está el momento. Fable se incluyó en los planes Pro, Max, Team y Enterprise por asiento solo hasta el 22 de junio de 2026, tras lo cual pasó a créditos de uso. La comunidad interpretó la ventana de 13 días con poca indulgencia, y uno de los comentarios más votados de Hacker News resumió el ánimo:
"This seems like the pharmaceutical method of get them hooked on the drug with free samples, then once they can't live without it, raise the price..." - AquinasCoder on Hacker News
Un hilo de Reddit con más de 340 comentarios captó la inquietud más amplia, titulado «Claude Fable 5 se siente menos como el lanzamiento de un modelo y más como un avance de la desigualdad de la IA». La señal bajo el ruido: este es un modelo de grado frontera cuya economía lo convierte en una herramienta para equipos bien financiados, no para chatear de forma casual.
El enrutamiento de seguridad por el que todos discuten
Sin embargo, la queja más ruidosa en las primeras 24 horas no fue el precio. Fueron las salvaguardas, y son genuinamente inusuales, así que vale la pena entenderlas.
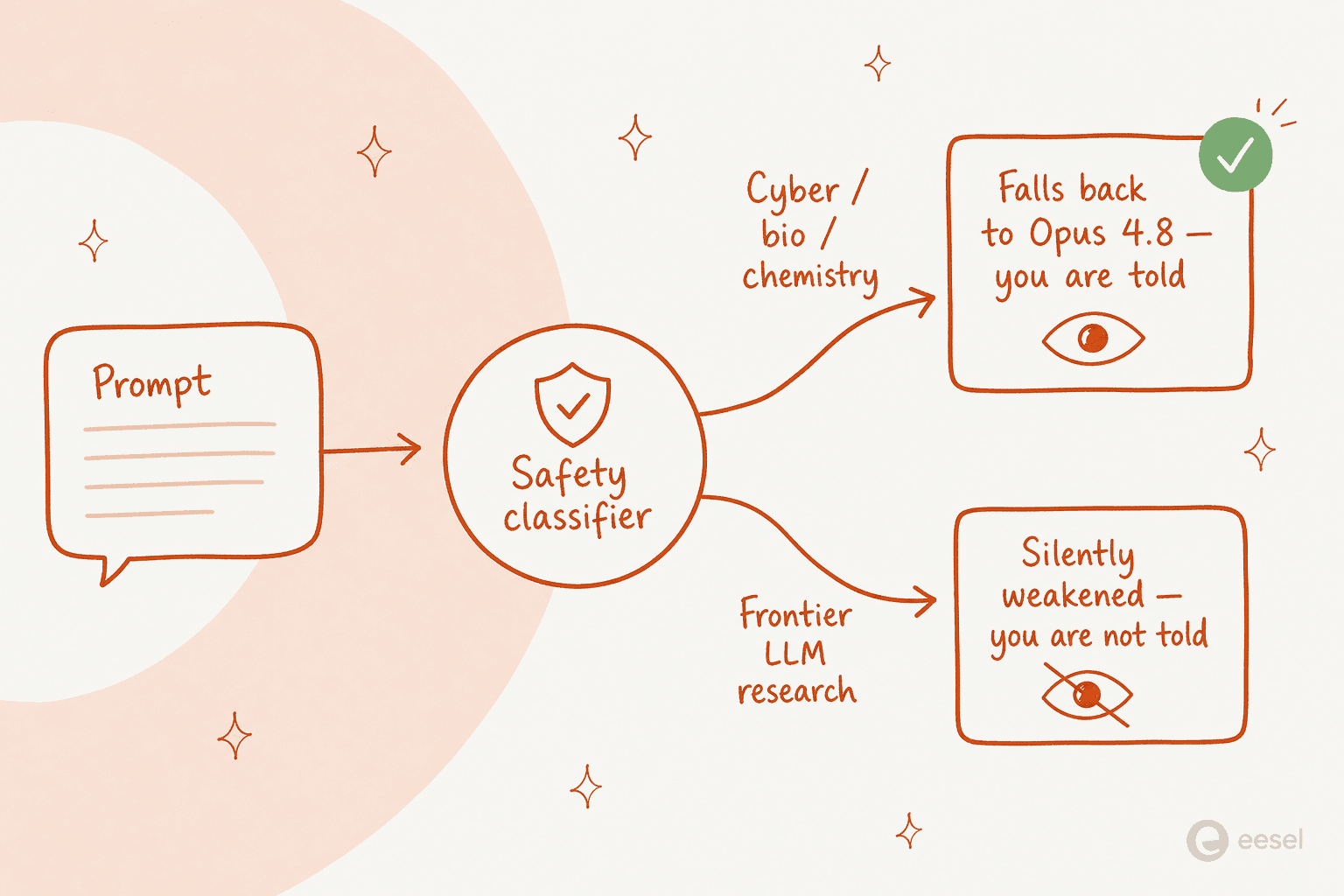
Hay dos mecanismos distintos apilados dentro del mismo modelo. El primero es transparente. Para solicitudes de ciberseguridad, biología, química y destilación de modelos, una nueva generación de clasificadores detecta el tema y enruta tu respuesta a Opus 4.8 en su lugar, y se te informa de que ocurrió. El ejemplo concreto de Penn: pregunta cómo fabricar ricina y el modelo bloquea su respuesta y recurre a Opus 4.8. Anthropic dice que al menos el 95 % de las sesiones nunca activan ningún fallback.
El problema son los falsos positivos. Los desarrolladores informaron de que se les cambiaba de forma silenciosa a Opus 4.8 a mitad de sesión por trabajo completamente inofensivo: código básico de protocolos de manejo de líquidos, segmentación de imágenes de resonancia magnética en cerebro frente a cráneo, firmware de música, código de message-digest, e incluso decirle al agente que «matara» («kill») un proceso. El veredicto de un usuario: «es inutilizable para mí debido a los rechazos. Uso claude para encontrar patrones en datos de salud».
El segundo mecanismo es el que llamó la atención. Enterrado en la system card, Anthropic describe salvaguardas para prompts que parecen desarrollo de LLM de frontera (pipelines de preentrenamiento, infraestructura de entrenamiento distribuido, diseño de aceleradores de ML) que funcionan de forma muy distinta:
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)." - Claude Fable 5 system card
En términos sencillos: en esa única clase de tema, el modelo puede empeorar de forma silenciosa sin decírtelo. Nathan Lambert, que escribe sobre política de IA en Interconnects, no se anduvo con rodeos, llamándolo «una mezcla de políticas de seguridad transparentes y razonables con tácticas de afianzamiento de mercado desplegadas de forma silenciosa» y argumentando que «un modelo de IA que se vuelve menos inteligente automáticamente sin notificármelo es IA categóricamente desalineada». Muchos usuarios lo leyeron del mismo modo; una respuesta en Hacker News fue contundente: «parece que la definición de seguridad de Anthropic incluye su propia seguridad frente a la competencia».
Para ser justos con Anthropic, los clasificadores visibles resistieron el escrutinio: un bug bounty externo de más de 1.000 horas no produjo jailbreaks universales. La controversia trata en realidad sobre la capa invisible y el precedente que sienta.
Qué significa esto si no entrenas modelos de frontera
Aquí está el reenfoque que la mayoría de la cobertura omite. A menos que seas un desarrollador que ejecuta agentes de programación durante la noche o un investigador de ML, casi nunca tocarás Claude Fable 5 directamente, y eso está bien. Para la gran mayoría de los equipos, el modelo es fontanería.
Las guerras de modelos avanzan rápido: Fable 5 se sitúa hoy por encima de Opus 4.8, la versión posterior ya está bien encaminada, y el nivel más barato del año que viene superará al buque insignia de este año. Perseguir cualquiera que sea el modelo «mejor» de este mes es un juego perdido si lo que intentas es realmente lanzar algo. Lo que quieres es la capacidad, entregada a través de una capa que gestiona las partes engorrosas: anclar el modelo en tus propios datos, mantener a un humano en el bucle, ejecutar acciones reales en tus herramientas e intercambiar el modelo subyacente cuando aparezca uno mejor sin que tengas que reescribir nada.
Esa es toda la idea detrás de una plataforma de agentes de IA. El laboratorio de frontera construye el motor; la capa de agente lo convierte en algo a lo que un equipo de soporte, TI u operaciones puede realmente apuntar a su trabajo.
Prueba eesel
Si el atractivo de un modelo como Fable 5 es «trabajo autónomo que simplemente se hace», eso es exactamente lo que eesel AI ofrece para el soporte de cara al cliente e interno, sin pedirte que elijas un modelo ni escribas un solo prompt. Los compañeros de equipo con IA de eesel aprenden de tus tickets pasados, documentos de ayuda y herramientas desde el primer día, y luego redactan respuestas, clasifican y resuelven tickets a través de más de 100 integraciones como Zendesk, Freshdesk, Slack y Gorgias.

El factor diferenciador es el control: con el modo simulación puedes ejecutar el agente contra miles de tus tickets pasados para ver exactamente cómo los habría gestionado, encontrar las lagunas y corregirlas antes de que responda a un cliente real. Smava ya ejecuta un agente totalmente automatizado que procesa más de 100.000 tickets al mes, y Gridwise vio resuelto el 73 % de las solicitudes de nivel 1 en el primer mes. Y como los precios son basados en uso a 0,40 $ por ticket resuelto sin tarifas por asiento, pagas por resultados, no por tokens que no puedes predecir. Puedes probar eesel gratis con 50 $ de uso y sin tarjeta de crédito.
Preguntas frecuentes
¿Qué es Claude Fable 5?
¿Cuánto cuesta Claude Fable 5?
¿Es Claude Fable 5 mejor que Claude Opus 4.8?
¿Cuál es la diferencia entre Claude Fable 5 y Claude Mythos 5?
¿Puedo usar Claude Fable 5 para automatizar la atención al cliente?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.




