¿Qué es MiniMax M3?
MiniMax M3 es un modelo de lenguaje grande de propósito general que MiniMax describe como „un modelo de programación y agéntico frontier construido sobre una arquitectura de atención novedosa (MSA) con 1M de contexto." Reemplaza a la línea M2 anterior (M2, M2.1, M2.5, M2.7), que permanecen disponibles, y es el primer modelo de MiniMax entrenado para ser multimodal desde el primer paso, por lo que acepta entradas de imagen y video e incluso puede operar un ordenador de escritorio.
MiniMax en sí es un laboratorio de IA chino cuyo lema es "Intelligence with everyone", con una línea de productos que va mucho más allá del texto, con video (Hailuo), voz y música. M3 es el buque insignia de texto y agentes de esa línea. Si has estado siguiendo la oleada de modelos sólidos provenientes de China, M3 se ubica en la misma conversación que Qwen y Kimi K2.5, y es uno de los lanzamientos open-weight más interesantes del año.
El lanzamiento oficial expuso la propuesta de valor claramente en la cuenta X de MiniMax:
"Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities... Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1... MiniMax Sparse Attention scales context to 1M... Natively Multimodal from Step Zero"
Una nota sobre el nombre antes de continuar: no hay ningún modelo llamado literalmente "MiniMax 3." El nombre oficial es MiniMax M3, y eso es lo que cubre esta guía.
Cómo funciona MiniMax M3: atención dispersa y una ventana de 1M de tokens
Lo más interesante de M3 no es un benchmark, sino la arquitectura que le permite leer un millón de tokens sin que el costo se dispare. Esta es la parte que encuentro genuinamente ingeniosa, así que déjame explicar cómo funciona.
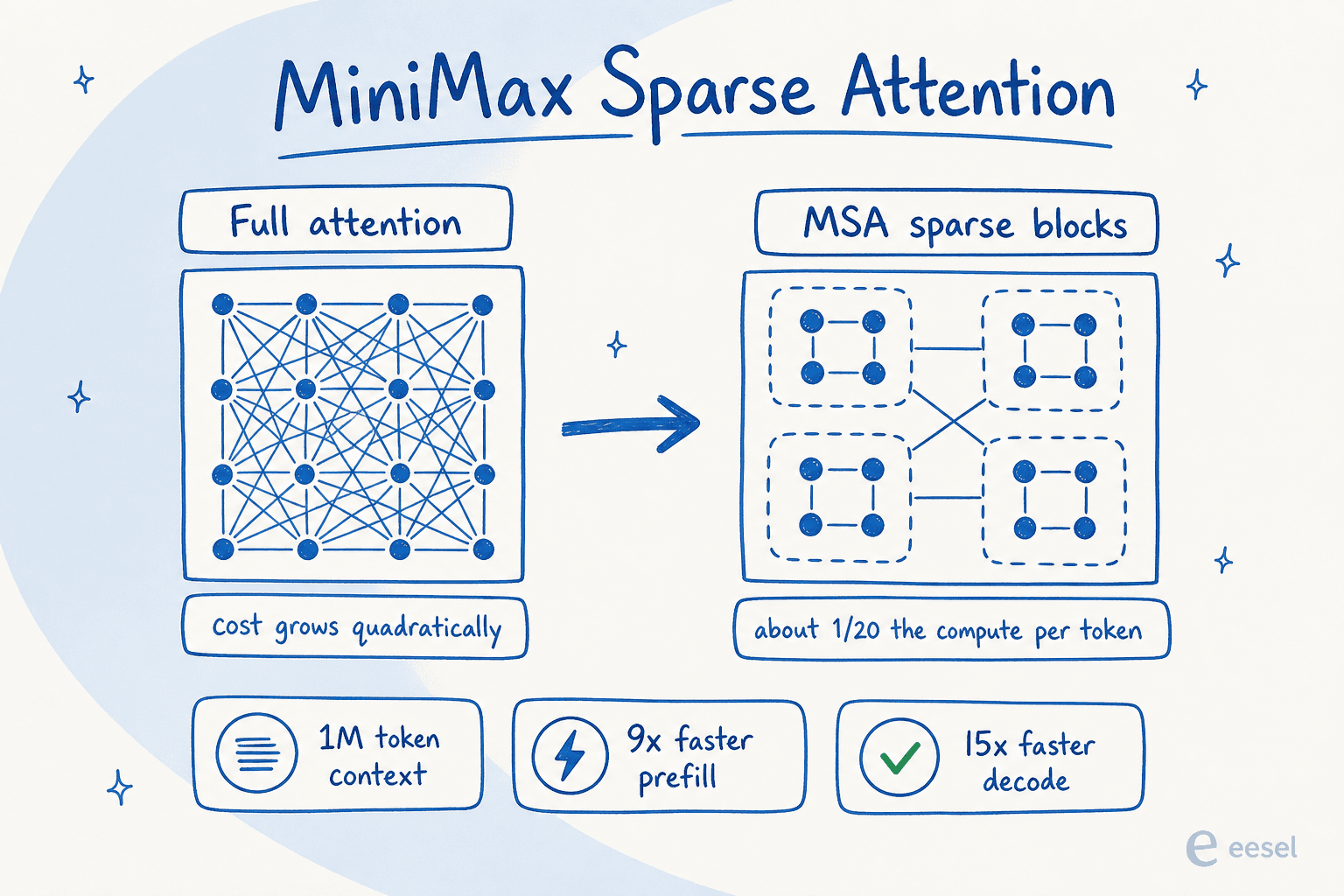
Bajo el capó, M3 es un modelo Mixture-of-Experts con alrededor de 428B parámetros totales y aproximadamente 23B activados por token, por lo que solo ejecuta una fracción de sí mismo en cada solicitud. Sobre eso está el verdadero titular: MiniMax Sparse Attention (MSA), un nuevo diseño de atención que divide el contexto en bloques y solo atiende a los relevantes en lugar de comparar cada token con todos los demás.
Eso importa porque la atención normal se vuelve cuadráticamente más costosa a medida que crece el contexto, razón por la cual las ventanas de contexto largas suelen ser lentas y caras. MiniMax informa que MSA reduce el cómputo por token a aproximadamente 1/20, con más de 9 veces más velocidad de prefilling y 15 veces más de decoding con 1M de contexto en comparación con M2, mientras mantiene el rendimiento de atención completa en la mayoría de las capacidades en sus ablaciones. El resultado es una ventana de contexto de 1.000.000 de tokens (con un mínimo garantizado de 512K), frente a 204.800 en la línea M2.
Algunas otras cosas que vale la pena saber sobre cómo se comporta M3:
- Modos de razonamiento. Un parámetro
thinkingte permite establecer el razonamiento enenabled,adaptive(el modelo decide) odisabledpara baja latencia, y ambos modos comparten el mismo precio. - Multimodalidad nativa. Porque fue entrenado con texto, imagen y video entrelazados "desde el Paso 0," M3 fusiona las modalidades más profundamente que un modelo con visión añadida posteriormente.
- Diseñado para trabajo de largo horizonte. En las demostraciones propias de MiniMax, M3 funcionó de forma autónoma durante casi 12 horas para reproducir un artículo de investigación, y pasó unas 24 horas optimizando un kernel CUDA a lo largo de 147 envíos de benchmark y 1.959 llamadas a herramientas.
El método completo está en el informe técnico de M3 si quieres la profundidad.
¿Qué tan bueno es MiniMax M3? Los benchmarks
MiniMax posiciona a M3 como alcanzando la frontera en ingeniería de software y ejecución de terminal, y lo compara con modelos cerrados como GPT-5.5, Gemini 3.1 Pro y Claude Opus. Aquí están las puntuaciones publicadas del anuncio:
| Benchmark | Qué mide | MiniMax M3 |
|---|---|---|
| SWE-Bench Pro | Correcciones de software del mundo real | 59,0% |
| Terminal-Bench 2.1 | Tareas agénticas de línea de comandos | 66,0% |
| MCP Atlas | Uso de herramientas sobre el protocolo agente | 74,2% |
| SWE-fficiency | Cambios de código eficientes | 34,8% |
| KernelBench Hard | Optimización de kernels GPU | 28,8% |
| PostTrainBench | Entrenamiento autónomo de modelos | 37,1 (#3) |
| Video-MME (512 frames) | Comprensión de video | 84,6 |
Un poco de honestidad sobre lo que significan estos resultados. En el benchmark de entrenamiento autónomo de modelos PostTrainBench, M3 quedó en tercer lugar, ligeramente detrás de Claude Opus 4.7 (42,4) y GPT-5.5 (39,3), pero por delante de todo lo demás. Ese es el patrón general: M3 es excelente para un modelo open-weight y competitivo en programación, pero no lidera la frontera cerrada. La anterior familia M2 ya había empujado las puntuaciones open-weight más alto en índices independientes, y M3 es un claro paso adelante desde allí.
Si quieres el contexto más amplio de cómo se comparan estos modelos, nuestras guías sobre alternativas a Claude y alternativas a Gemini cubren el lado de los modelos cerrados de la comparación.
¿Cuánto cuesta MiniMax M3?
Aquí es donde M3 se gana su reputación. El precio es la razón por la que los desarrolladores siguen mencionándolo.
MiniMax vende M3 de dos maneras. La primera es un Token Plan de suscripción, actualizado en el lanzamiento en tres niveles, donde texto, imagen, voz y música todos toman de un único grupo de uso compartido:
| Token Plan | Precio / mes | Aprox. tokens M3 / mes |
|---|---|---|
| Plus | $20 | ~1,7B tokens |
| Max | $50 | ~5,1B tokens |
| Ultra | $120 | ~9,8B tokens |
MiniMax enmarca el nivel de entrada como "$20 = 10x Claude Pro" en rendimiento, lo que es marketing, pero dice mucho sobre el enfoque: máximos tokens por dólar. Es el mismo posicionamiento de bajo costo que ves en los precios de Qwen y el resto del grupo open-weight.
La segunda forma es la API de pago por uso, con precio por longitud de entrada. Las llamadas con menos de 512K tokens de entrada obtienen la tarifa estándar; cualquier cosa por encima se factura a una tarifa de contexto largo más alta para trabajo con repositorios completos y documentos ultra-largos. El pensamiento activado o desactivado cuesta lo mismo, y hay un nivel de servicio priority disponible para cargas de trabajo sensibles a la latencia. Los desarrolladores en r/LLMDevs informan que la tarifa por token en el lanzamiento era de $0,60/$2,40 por millón hasta 512K, lo que los coloca, en sus palabras, en "territorio DeepSeek."
La otra mitad de la historia de costos es la licencia. M3 es open-weight bajo la MiniMax Community License: gratis para uso no comercial, con el uso comercial requiriendo un crédito visible "Built with MiniMax M3" y, por encima de 20M$/año en ingresos, autorización previa por escrito. Así que es open-weight, no open source, una distinción que la comunidad se apresura a señalar. Para una comparación de costos pura contra otras opciones de pago, nuestra lista de herramientas de IA baratas y la guía de precios de Kimi K2.5 son puntos de referencia útiles.
Lo que los desarrolladores dicen realmente sobre MiniMax M3
Los benchmarks publicados solo dicen tanto. La señal más útil proviene de desarrolladores que ejecutan M3 en trabajo real, y el veredicto es consistente: una opción de fuerte relación calidad-precio, no un reemplazo de los modelos frontier.
La versión más clara del argumento de valor en realidad proviene de alguien que cambió al predecesor M2.7, en r/openclaw:
"claude is a slightly better model. better reasoning, better depth on hard problems. that's just how it is. but minimax m2.7 delivers exceptionally well for what i actually use it for, at a fraction of the cost... sometimes good enough is actually great when it's reliable and affordable."
Sobre M3 específicamente, un desarrollador en r/opencode lo expresó así después de probar otros modelos chinos primero:
"I started using Kimi 2.6, then GLM 51, then DeepSeek4. But now after trying minimax m3 I am really impressed. It seems to think very deeply and really do a good job following directions... It seems to have flown a lot under the radar."
Eso corresponde aproximadamente a donde M3 se ubica en el mercado: pesos abiertos, capacidad cercana al nivel Sonnet, a precios de nivel value.
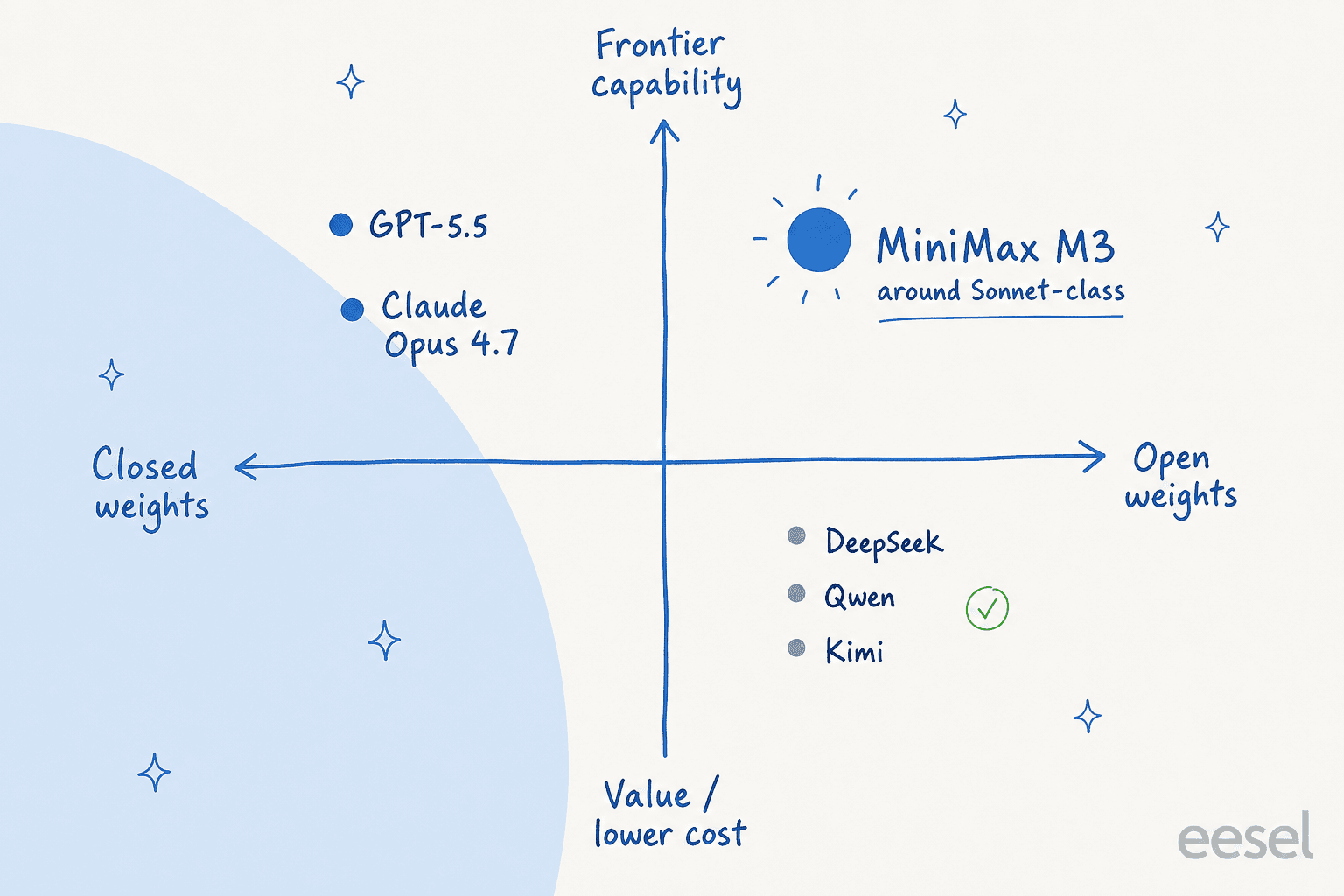
No todo son elogios, sin embargo, y la crítica merece tomarse en serio si estás pensando en producción. La queja más común es la fiabilidad bajo presión. Un tester en r/hermesagent encontró M3 errático:
"I feel like it is much more chaotic and verbose, as well as hallucinations being more common. Now it just suddenly keeps stopping mid action... Right now I wouldn't use it in production."
También hay una preocupación recurrente sobre retención de datos sobre la API alojada, con usuarios señalando que no pudieron encontrar una opción clara para que los datos del prompt no se usen en el entrenamiento. Ese es exactamente el tipo de cosa que importa más para datos de clientes que para un proyecto de hobby, y es una razón importante por la que a la comunidad de auto-alojamiento le agrada que los pesos estén en Hugging Face.
El truco: un gran modelo aún no es un agente de soporte
Aquí está el reencuadre con el que quiero que te vayas, porque es lo que la gente pasa por alto cuando se lanza un nuevo modelo brillante. Un modelo como M3 es un motor fantástico. Pero un motor no es un coche, y un modelo sin procesar no es un agente de soporte al cliente.
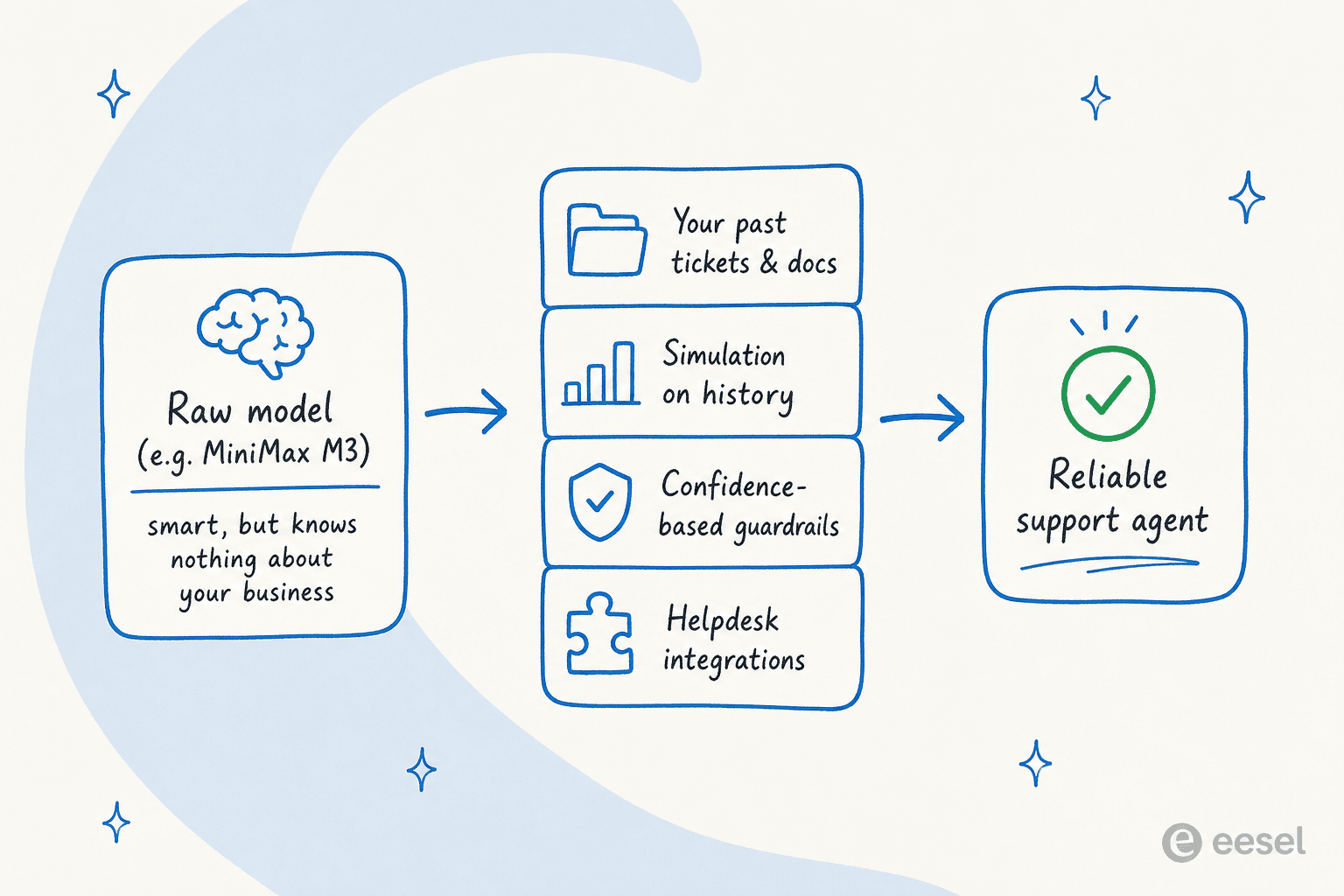
He pasado los últimos años en eesel observando lo que ocurre cuando apuntas un modelo de lenguaje a una cola de soporte en vivo, y el modo de fallo es siempre el mismo: el modelo suena seguro y se equivoca en los detalles, porque no conoce tu política de reembolsos, tus últimos 50.000 tickets resueltos ni qué respuesta es segura enviar sin que un humano la lea primero. El modelo más inteligente en el ranking aún alucina tu hora límite de envío si nadie le enseñó. Por eso cada implementación de eesel se ejecuta en simulación contra tickets históricos antes de responder a un solo cliente.
Así que las preguntas relevantes para el soporte no son "qué puntuó M3 en SWE-Bench." Son: ¿puede aprender de mis tickets y documentos reales, puedo probarlo de forma segura antes de que salga en vivo, y qué le impide enviar con confianza una respuesta incorrecta? Esas son preguntas de producto, no preguntas de modelo, y son en las que está construido nuestro resumen de la mejor IA para servicio al cliente.
El mismo punto aparece siempre que un chatbot responde incorrectamente, y es por qué el costo de un agente de IA frente a un humano depende mucho más de cuán fiablemente resuelve tickets que del precio por token del modelo.
eesel: la capa que convierte un modelo en un compañero de soporte
Exactamente esta brecha es la que eesel está diseñado para cerrar. En lugar de pedirte que elijas un modelo y confíes, eesel se sienta en la parte superior de tu helpdesk como un compañero de IA que aprende de tus tickets pasados, documentos de ayuda y herramientas desde el primer día, luego redacta, clasifica y resuelve el trabajo de nivel 1 con las barreras que hacen que sea seguro dejarlo funcionando.

El diferenciador concreto es el modo de simulación: ejecutas el agente contra miles de tus tickets reales pasados, ves exactamente qué habría respondido y dónde están los vacíos, los completas y solo entonces sales en vivo, con enrutamiento basado en confianza que mantiene las respuestas de baja confianza como borradores en lugar de envíos. Así es como equipos como Smava ejecutan un agente de Zendesk completamente automatizado con más de 100.000 tickets alemanes al mes, y cómo Gridwise alcanzó un 73% de resolución de nivel 1 en su primer mes. Se conecta a más de 100 integraciones, responde en más de 80 idiomas y funciona con precios basados en uso de $0,40 por ticket sin tarifas por asiento.
Si llegaste aquí eligiendo un modelo para soporte, el mejor punto de partida es la capa, no el ranking. Puedes probar eesel gratis, sin tarjeta de crédito, y ver cómo resuelve tus propios tickets en simulación antes de tocar a un solo cliente. Es la misma lección detrás de cada implementación de IA de servicio al cliente que he visto funcionar: el modelo es intercambiable, la fiabilidad no.
Preguntas frecuentes
¿Qué es MiniMax M3 en términos sencillos?
¿MiniMax M3 es realmente de código abierto?
¿Cuánto cuesta MiniMax M3?
¿MiniMax M3 es bueno para programar?
¿Puedo usar MiniMax M3 para soporte al cliente?
¿Cómo maneja MiniMax M3 un contexto de 1 millón de tokens?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.