
Resumen
Claude Sonnet 5 es el nuevo modelo de gama media de Anthropic, y el titular es el valor: alcanza una calidad cercana a Opus en tareas de codificación y agénticas a aproximadamente la mitad del precio (3 $/15 $ por millón de tokens, con tarifas introductorias de 2 $/10 $ hasta agosto). Mantiene la ventana de contexto de 1M de tokens, activa el pensamiento adaptativo por defecto y añade un nuevo ajuste de esfuerzo xhigh.
Para quien dirige un equipo de soporte, lo interesante no es el benchmark. Es que un modelo más económico y casi tan bueno como Opus hace que "vamos a construir nuestro propio bot de soporte sobre la API" suene más tentador que en años. Habiendo visto a clientes reales intentar exactamente eso, mi opinión es directa: el modelo nunca fue la parte difícil. Sonnet 5 te da un motor inteligente por pocos céntimos; un agente de soporte en el que tus clientes puedan realmente confiar requiere recuperación de información, barreras de seguridad, acciones, escalado y pruebas envueltas alrededor de ese motor. Eso es el 80% que la API no te entrega.
Si quieres toda esa infraestructura sin construirla, eesel se conecta con tu helpdesk actual, aprende de tus tickets anteriores y te permite simular sobre historial real antes de que salga una sola respuesta en vivo. El modelo que hay debajo sigue siendo cada vez más barato y mejor; el trabajo que lo rodea es de donde viene la confianza.
Qué es realmente Claude Sonnet 5
Me dedico a construir integraciones y APIs, así que cuando sale un modelo nuevo leo la documentación antes que el hilo de lanzamiento. Esto es lo que dice la documentación oficial de Anthropic sobre Claude Sonnet 5, sin el maquillaje de marketing.

Anthropic anunció Sonnet 5 a finales de junio de 2026 como "nuestro Sonnet más agéntico hasta la fecha", y lo convirtió en la opción por defecto desde el primer día para los usuarios gratuitos y Pro de Claude. Es el nivel equilibrado de la familia Claude 5. Funciona con una ventana de contexto de 1M de tokens y hasta 128K tokens de salida, el mismo límite que el nivel Opus. La propuesta es que alcanza una calidad cercana a Opus específicamente en tareas de codificación y agénticas, el tipo de trabajo de varios pasos que usa herramientas y que realiza un agente de soporte, mientras cuesta mucho menos ejecutarlo. El planteamiento aproximado de Anthropic es que Sonnet 5 con esfuerzo medium es comparable al anterior Sonnet 4.6 con high, y Sonnet 5 con high es comparable a 4.6 con max. En otras palabras, obtienes más por el mismo ajuste.
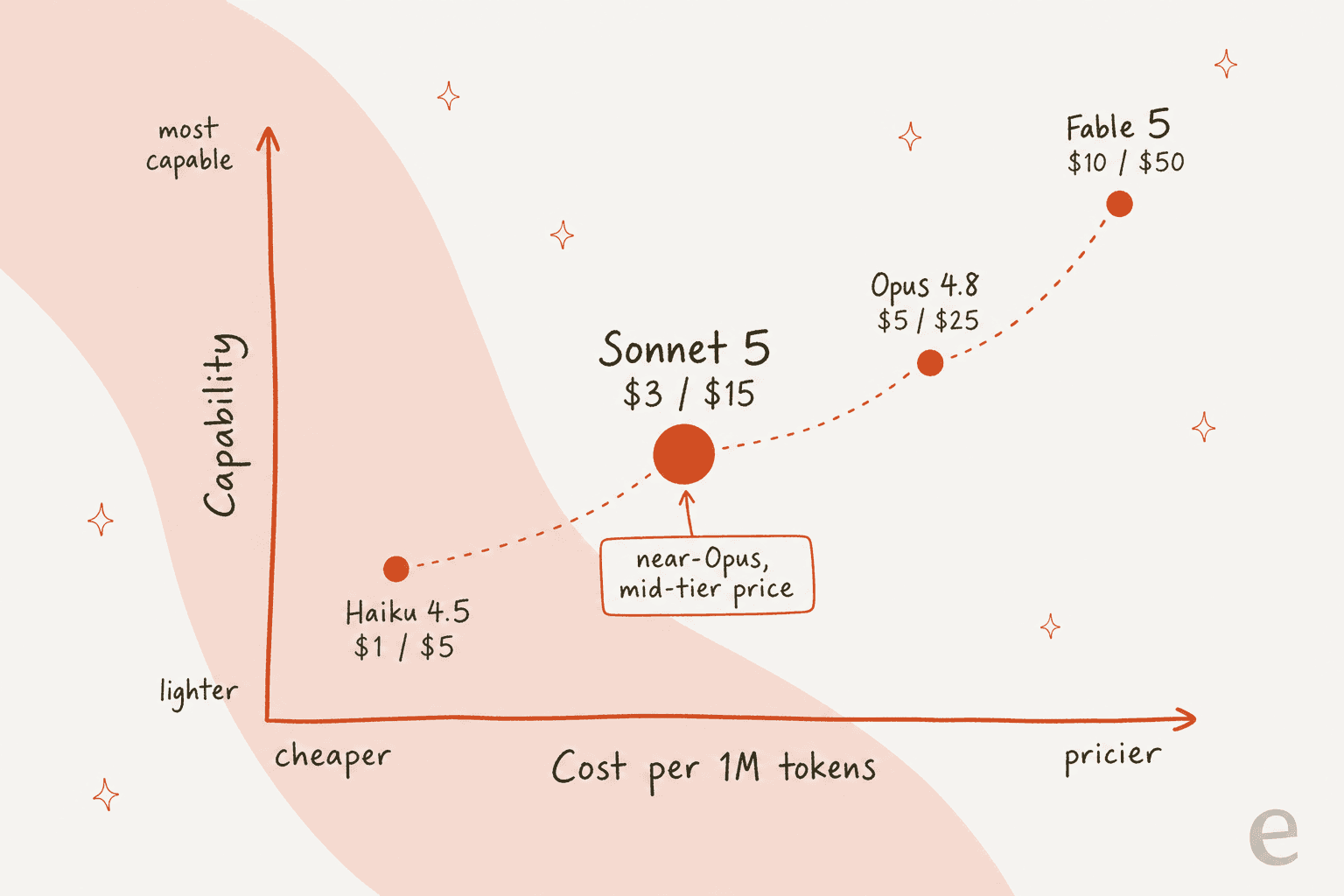
Dónde se ubica dentro de la familia es la verdadera historia. Anthropic ahora ofrece cuatro niveles públicos, y Sonnet 5 es el que más equipos pondrán realmente en producción.
Hay algunas novedades bajo el capó, y son más importantes de lo que sugiere el número de versión:
- El pensamiento adaptativo está activado por defecto. Ya no configuras un "presupuesto de pensamiento" fijo en tokens. El modelo decide cuánto razonar en cada solicitud, y tú lo ajustas con un dial de
efforten su lugar. - El esfuerzo
xhighllega al nivel Sonnet. Sonnet 5 es el primer modelo Claude de nivel equilibrado con el ajustexhigh, que Anthropic recomienda para las ejecuciones de codificación y agénticas más difíciles. Es el mismo dial en el que se apoya Claude Code. - Visión de alta resolución. Sonnet 5 lee imágenes de hasta 2576px en el lado más largo, útil si tus flujos de soporte incluyen capturas de pantalla o recibos.
- Un nuevo tokenizador. Más sobre esto a continuación, porque cambia tu factura sin que te des cuenta.
Precio de Claude Sonnet 5
Aquí está la parte que todo el mundo vino a buscar. El precio de la API de Sonnet 5 es de 3 $ por millón de tokens de entrada y 15 $ por millón de salida, con tarifas introductorias de 2 $/10 $ vigentes hasta el 31 de agosto de 2026. En el lado de consumo, Sonnet es el nivel "equilibrado" dentro de una suscripción de Claude.
Comparado con sus hermanos, el argumento de valor queda claro:
| Modelo | Entrada ($/1M) | Salida ($/1M) | Contexto | Ideal para |
|---|---|---|---|---|
| Haiku 4.5 | $1 | $5 | 200K | Tareas rápidas, económicas y sencillas |
| Claude Sonnet 5 | $3 (intro $2) | $15 (intro $10) | 1M | Codificación y trabajo agéntico a gran escala |
| Opus 4.8 | $5 | $25 | 1M | El trabajo autónomo más exigente y de largo horizonte |
| Fable 5 | $10 | $50 | 1M | El razonamiento más demandante |
Así que Sonnet 5 es aproximadamente un 40% más económico que Opus 4.8 tanto en entrada como en salida, mientras reclama la mayor parte de su capacidad en las tareas que ejecuta un agente de soporte. Para una cola que procesa millones de tokens al mes, esa diferencia se acumula rápido.
Pero hay una trampa que no aparece en la lista de precios. Sonnet 5 usa un nuevo tokenizador que cuenta aproximadamente un 30% más de tokens para el mismo texto que contaba Sonnet 4.6. El precio por token es menor, pero cada conversación ahora es más tokens, así que tu coste real por ticket resuelto puede terminar siendo distinto de lo que sugiere un cálculo rápido de servilleta.
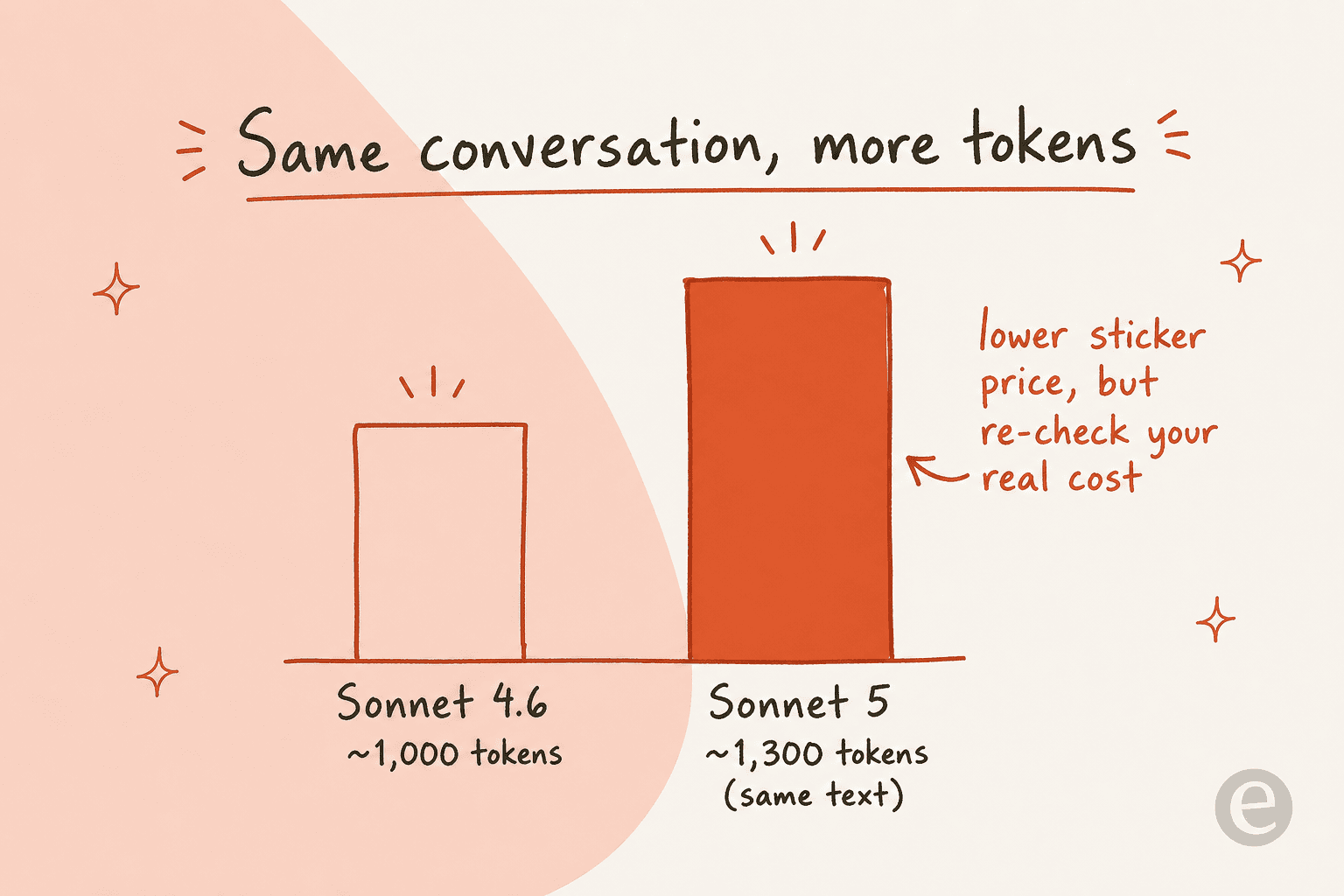
Este es ya el debate en vivo sobre Sonnet 5. Los entusiastas lo llaman trabajo de nivel Opus a precios de Sonnet, pero análisis más agudos en X señalan que, una vez que termina el descuento introductorio y se ejecuta con esfuerzo alto, el coste por tarea puede llegar a superar al de Opus 4.8 en índices independientes. Ambas cosas pueden ser ciertas: el precio de etiqueta es menor, el recuento de tokens es mayor, y el esfuerzo ajusta el total en cualquier dirección.
Las reacciones prácticas apuntan en la misma dirección. En un hilo de primeras impresiones en r/ClaudeAI (más de 90 comentarios a pocas horas del lanzamiento), un desarrollador abrió con exactamente la disyuntiva de la que trata todo este artículo:
"Lleva usando Sonnet 5 con esfuerzo [xhigh] unos 30 minutos, principalmente en tareas que delegaría a Opus 4.8..."
hilo de primeras impresiones, r/ClaudeAI
Esa es la señal que vale la pena vigilar: gente recurriendo a Sonnet 5 para trabajo que antes le entregaban a Opus. Si eso se sostiene en tus tickets es una pregunta que ningún benchmark puede responder, que es precisamente el punto de la siguiente sección.
El movimiento práctico: mide el uso de tokens en tus propios tickets contra claude-sonnet-5 en lugar de reutilizar una cifra que tenías para un modelo anterior. Si estás intentando modelar el coste total de propiedad específicamente para soporte, el desglose sobre el coste de un agente de soporte con IA es mejor punto de partida que las matemáticas de tokens en bruto, porque la mayor parte del coste de un agente de soporte nunca es el modelo.
Qué cambió desde Sonnet 4.6
Si estás actualizando una integración existente en lugar de empezar de cero, hay cuatro cosas que vale la pena conocer antes de cambiar la cadena del modelo:
- El pensamiento funciona de forma diferente. El antiguo control fijo de
budget_tokensha desaparecido en Sonnet 5. Omitir el ajuste de pensamiento ahora ejecuta el pensamiento adaptativo automáticamente, mientras que antes se ejecutaba sin pensamiento. Si nunca lo tocaste, tus solicitudes empezarán a razonar más sin que lo notes (y usarán más de tu presupuesto de salida), así que dale un poco de margen amax_tokens. - El esfuerzo es tu dial principal. Mantén
highcomo valor por defecto y recurre axhighen las ejecuciones agénticas más difíciles. Bájalo amediumolowpara tareas económicas y sensibles a la latencia, como el etiquetado de tickets o la clasificación de intención. - El cambio de tokenizador es real. Como se mencionó antes, vuelve a establecer tu recuento base de tokens. Esta es la forma más común en que una migración sorprende al equipo de finanzas.
- La visión mejoró. La entrada de imágenes de alta resolución es automática. Útil si clasificas tickets que llegan como capturas de pantalla.
Nada de esto es dramático si ya trabajas sobre la API de Claude. Es un cambio de cadena de modelo más un reajuste, no una reescritura. La plataforma de desarrolladores de Claude mantiene la misma forma de solicitud que tenía para la familia Opus 4.x.
Qué significa Sonnet 5 si diriges un equipo de soporte
Aquí es donde un modelo más barato y más inteligente se vuelve genuinamente interesante, y genuinamente engañoso.
Cada vez que se lanza un modelo potente, una ola de equipos piensa lo mismo: el modelo es tan bueno y tan barato ahora que deberíamos construir nuestro propio bot de soporte sobre la API y saltarnos al proveedor. Lo entiendo. Como alguien que escribe este tipo de código, montar una llamada a Sonnet 5 que responda una pregunta de soporte es una tarde satisfactoria.
La trampa es que la llamada al modelo es el 20% fácil. Todo lo que hace que una IA sea segura para poner delante de clientes reales está bajo la línea de flotación, y nada de eso viene en la respuesta de la API.

No estoy adivinando esto. He visto a clientes marcharse para construir internamente sobre la API de Claude directamente, y el patrón es consistente: la demo funciona en una semana, y luego la larga cola de recuperación de información, control de alucinaciones, enrutamiento y escalado se come los siguientes seis meses. Un líder de ingeniería que eligió comprar en lugar de construir lo dijo sin rodeos:
"Podríamos intentar escribir nuestra propia aplicación de LLM, pero no queríamos invertir nuestro tiempo en eso. Queríamos algo que no tuviéramos que mantener."
Karel, líder de ingeniería en GENERAL BYTES
El modo de fallo más aterrador no es que un modelo en bruto dé una respuesta equivocada. Es que dé una respuesta equivocada con confianza. En más de tres años poniendo IA en colas de soporte en vivo, el peor patrón que he visto es un bot que suena seguro de sí mismo y le dice tranquilamente algo falso a un cliente, o narra un trabajo que nunca hizo realmente. Por eso exactamente cualquier despliegue serio debería simularse primero contra tus tickets históricos, para que veas las cifras de precisión y cobertura antes de que las vea un cliente real, no después. Un benchmark de modelo te dice que el motor es rápido; no te dice nada sobre cómo se comporta tu bot específico en tus tickets específicos.
Así que la lectura honesta de Sonnet 5 para soporte es esta: hace que el motor sea más barato y mejor, lo cual es genial, y no cambia casi nada del 80% difícil. Ya sea que construyas o compres, presupuesta tu tiempo para las partes que la API no ofrece: enrutamiento, barreras de seguridad, escalado a humanos y pruebas, porque ahí es donde realmente se gana o se pierde la confianza del cliente.
Prueba eesel
Si la conclusión honesta es "quiero calidad de nivel Sonnet 5 en mis tickets sin construir el otro 80%", ese es exactamente el hueco que llena eesel. Funciona como un nuevo miembro del equipo de soporte que se conecta a Zendesk, Freshdesk, Gorgias, Help Scout o Intercom en pocos minutos y ya conoce tu centro de ayuda y tus tickets anteriores.
La parte que más importa dado todo lo anterior: eesel te permite simular sobre miles de tus tickets históricos reales antes de salir en vivo, así que ves las cifras de resolución y cobertura de antemano en lugar de descubrirlas con un cliente real. El enrutamiento basado en confianza mantiene a la IA en los tickets que puede manejar y entrega el resto a una persona, que es la barrera de seguridad que convierte un modelo ingenioso en un compañero de equipo de confianza. Eso no es un benchmark que eesel esté persiguiendo; es la razón por la que equipos como Gridwise resolvieron el 73% de las solicitudes de nivel 1 en su primer mes.

El precio se basa en el uso, alrededor de 0,40 $ por ticket gestionado, sin cuotas por asiento y sin mínimo de plataforma, y puedes probar eesel gratis. Sea cual sea el modelo que haya debajo, ya sea Sonnet 5 hoy o su sucesor el año que viene, el trabajo que lo rodea es lo que realmente resuelve el ticket.
Preguntas frecuentes
¿Qué es Claude Sonnet 5?
¿Cuánto cuesta Claude Sonnet 5?
¿Es Claude Sonnet 5 mejor que Opus 4.8?
¿Puedo construir un agente de soporte al cliente con Claude Sonnet 5?
¿Cuál es la diferencia entre Claude Sonnet 5 y Sonnet 4.6?
xhigh, mejora a visión de alta resolución y usa un nuevo tokenizador que cuenta aproximadamente un 30% más de tokens para el mismo texto. Ese último punto es clave para presupuestar, así que vuelve a comprobar tu coste real por conversación en lugar de reutilizar estimaciones antiguas. Más sobre la elección de modelo en la guía sobre el mejor chatbot de IA.
Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








