Was ist DiffusionGemma?
DiffusionGemma ist ein Modell aus Googles offener Gemma-Familie, das Text mit einem Diffusions-Prozess generiert statt mit dem autoregressiven Ansatz hinter fast jedem Chatbot, den du genutzt hast. Es wurde von Google DeepMind am 10. Juni 2026 als experimentelles Open-Weights-Modell unter Apache 2.0 veröffentlicht, wobei die offizielle Model Card auf DeepMinds Website lebt.
Hier ist das wichtigste Datenblatt:
| Attribut | DiffusionGemma |
|---|---|
| Veröffentlicht | 10. Juni 2026 |
| Lizenz | Apache 2.0 (Open Weights) |
| Architektur | Aufbauend auf Gemma 4, Mixture-of-Experts |
| Größe | 25,2 Mrd. Gesamtparameter, ~3,8 Mrd. aktiv pro Schritt ("26B A4B") |
| Generierung | Entrauscht Blöcke von 256 Tokens parallel |
| Eingabe / Ausgabe | Multimodal ein (Text/Bild/Video), Text aus |
| Geschwindigkeit | >1.000 Tok/s auf einer H100, bis zu 4x schneller als vergleichbare AR-Modelle |
| Hardware | ~52 GB VRAM bei BF16, ~28 GB bei INT8, lauffähig ab ~18 GB quantisiert |
Die meisten dieser Zahlen stammen aus MarkTechPosts Launch-Berichterstattung und dem Spheron-Deployment-Leitfaden, mit dem Detail zu den parallelen Blöcken aus Diggs Artikel. Das Kürzel "26B A4B" ist Googles Bezeichnung: ein Mixture-of-Experts-Modell der 26B-Klasse, das auf jedem gegebenen Schritt nur etwa 3,8 Mrd. Parameter feuert, was ein Teil davon ist, warum es günstig schnell zu betreiben ist.
Der Grund, warum das eine große Sache ist, sind nicht die Benchmark-Werte. Es ist, dass ein Frontier-Lab ein echtes, herunterladbares Diffusions-Sprachmodell ausgeliefert hat. Jahrelang war Diffusion die dominierende Methode für Bilder und Video (denk an Midjourney, Sora), während Text hartnäckig autoregressiv blieb, dieselbe Familie, die alltägliche Assistenten wie ChatGPT und Claude antreibt. DiffusionGemma ist eines der klarsten Signale bisher, dass die Textseite aufholt.
Wie DiffusionGemma tatsächlich funktioniert
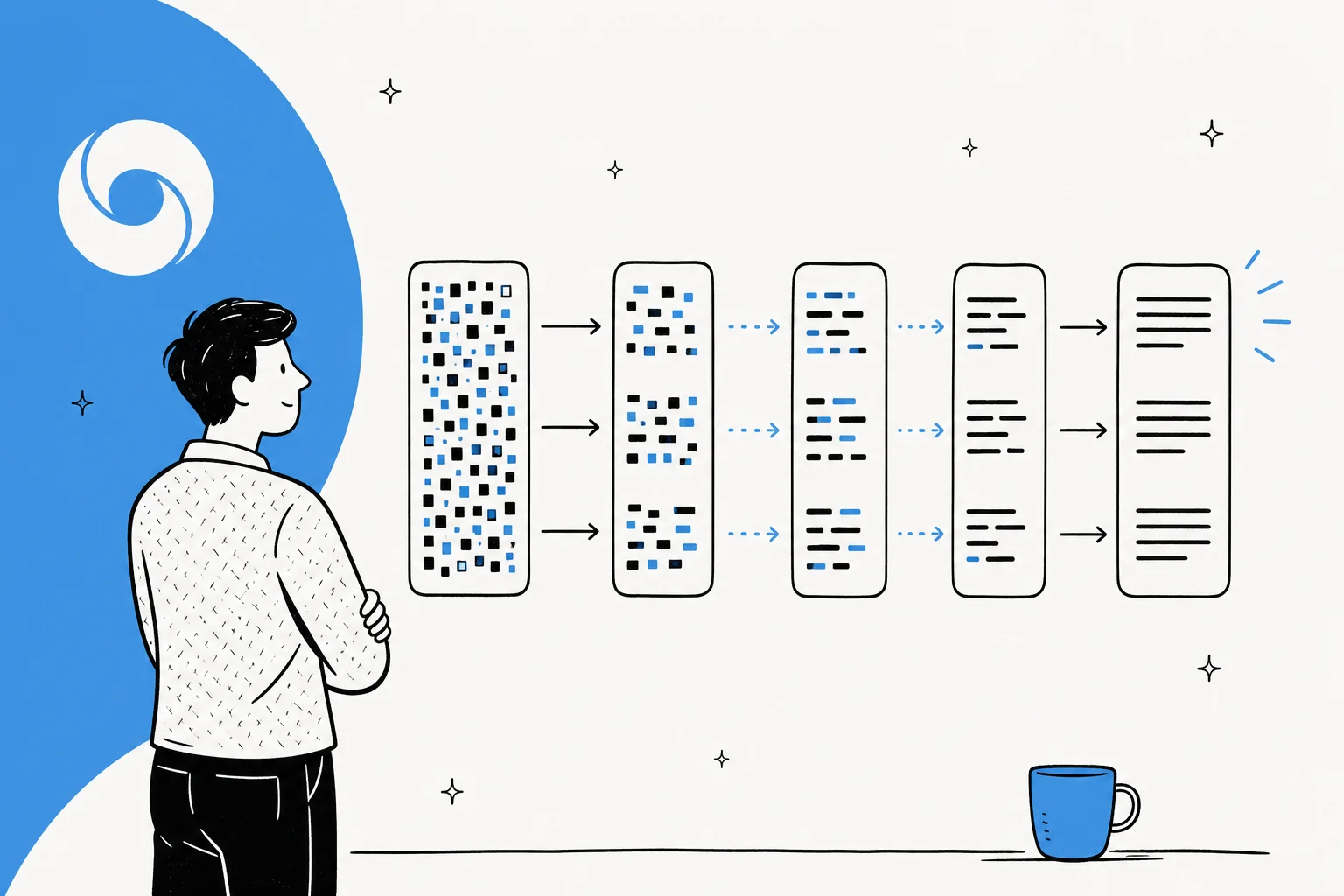
Standard-Large-Language-Models sind autoregressiv. Wie Inception Labs es ausdrückt, "generieren sie Text von links nach rechts, ein Token nach dem anderen, wobei ein Token nicht generiert werden kann, bis der gesamte Text davor generiert wurde." Jedes Wort wartet auf das davor, sodass eine lange Antwort eine lange Abfolge von Vorwärtsdurchläufen durch Milliarden von Parametern bedeutet. Daher kommt die Latenz.
Diffusion dreht das um. Der dominierende Ansatz für Text ist maskierte Diffusion: Du beginnst mit einem Block von Tokens, die alle maskiert sind, und ein Transformer sagt die unmaskierten Versionen voraus, dann verfeinert er seine Vermutung über eine Handvoll Durchläufe. Google beschreibt es so, dass Text "so generiert wird, wie Bilddiffusion funktioniert: Statt Text direkt vorherzusagen, lernt das Modell, Ausgaben zu generieren, indem es Rauschen Schritt für Schritt verfeinert, sodass es schnell an einer Lösung iterieren und während der Generierung fehlerkorrigieren kann."
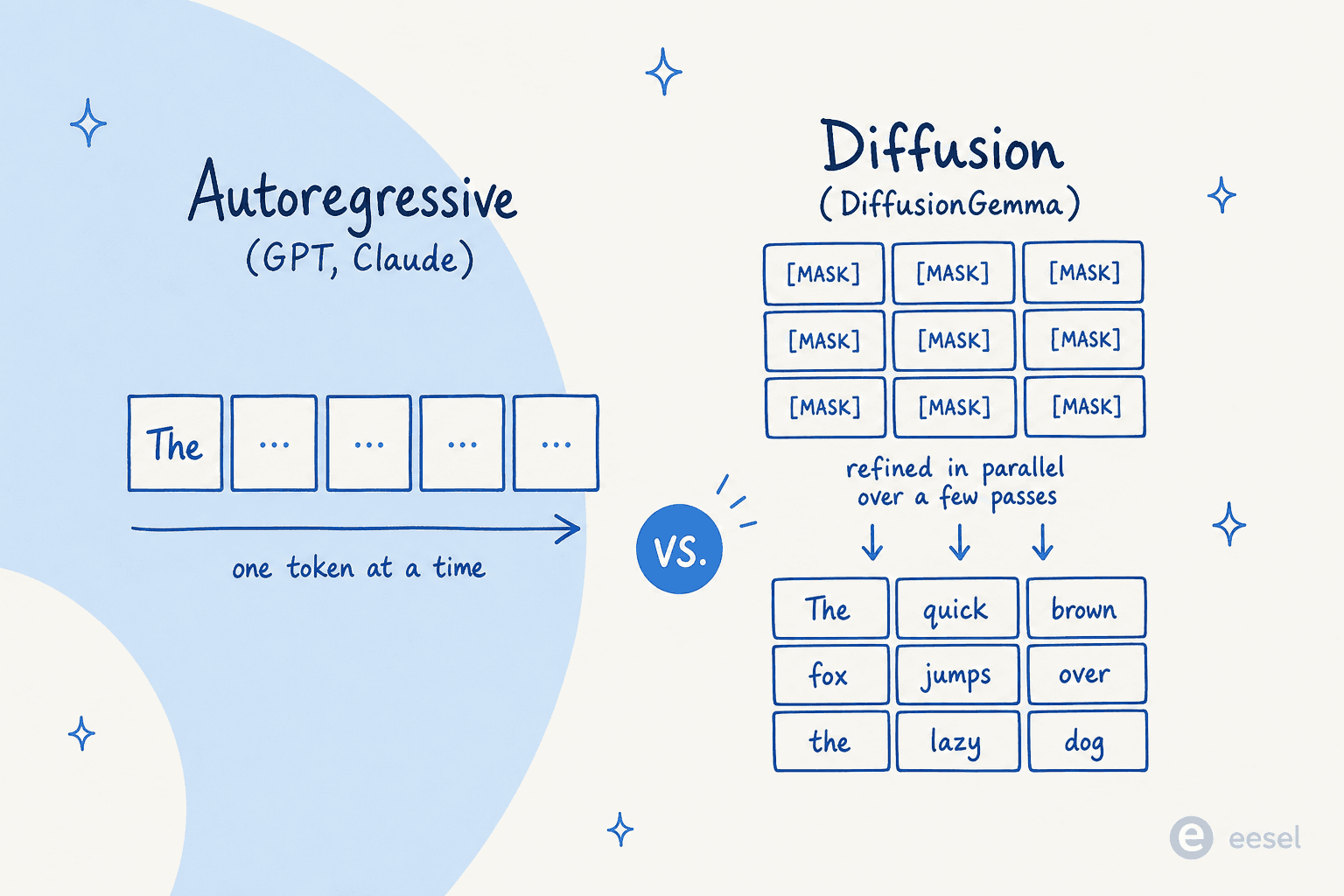
Eine Klarstellung, weil der Name die Leute stolpern lässt. Diffusion ersetzt hier nicht den Transformer; sie ersetzt die Autoregression. Wie ein vielzitierter Hacker-News-Kommentar von Nutzer synapsomorphy es erklärte:
"Diffusion ist nicht an der Stelle von Transformern, sie ist an der Stelle der Autoregression. Frühere Diffusions-LLMs wie Mercury nutzen immer noch einen Transformer, aber es gibt keine kausale Maskierung, sodass die gesamte Eingabe auf einmal verarbeitet wird und die Ausgabegenerierung offensichtlich anders ist."
Die praktischen Vorteile der parallelen Generierung sind dreifach: rohe Geschwindigkeit, die Fähigkeit zur Fehlerkorrektur mitten in der Generierung und natürliches Infilling (weil das Modell Kontext auf beiden Seiten einer Lücke sehen kann, ist es gut darin, die Mitte einer Sequenz zu bearbeiten, nicht nur ans Ende anzuhängen). Andrej Karpathy wies früh auf die Neuheit hin und merkte an, dass Diffusion "nicht von links nach rechts geht, sondern alles auf einmal. Du beginnst mit Rauschen und entrauschst es allmählich zu einem Token-Strom."
DiffusionGemma vs. Gemini Diffusion: nicht verwechseln
Das erwischt fast jeden, weil Google innerhalb von etwa einem Jahr zwei Textdiffusions-Dinge ausgeliefert und ihnen nahezu identische Namen gegeben hat.
Gemini Diffusion wurde im Mai 2025 auf der Google I/O als experimentelles, nur per Warteliste zugängliches Modell gezeigt, das auf Googles Infrastruktur läuft. Du kannst es nicht herunterladen. DiffusionGemma hingegen ist das Open-Weights-Modell, das du herunterladen und selbst betreiben kannst.
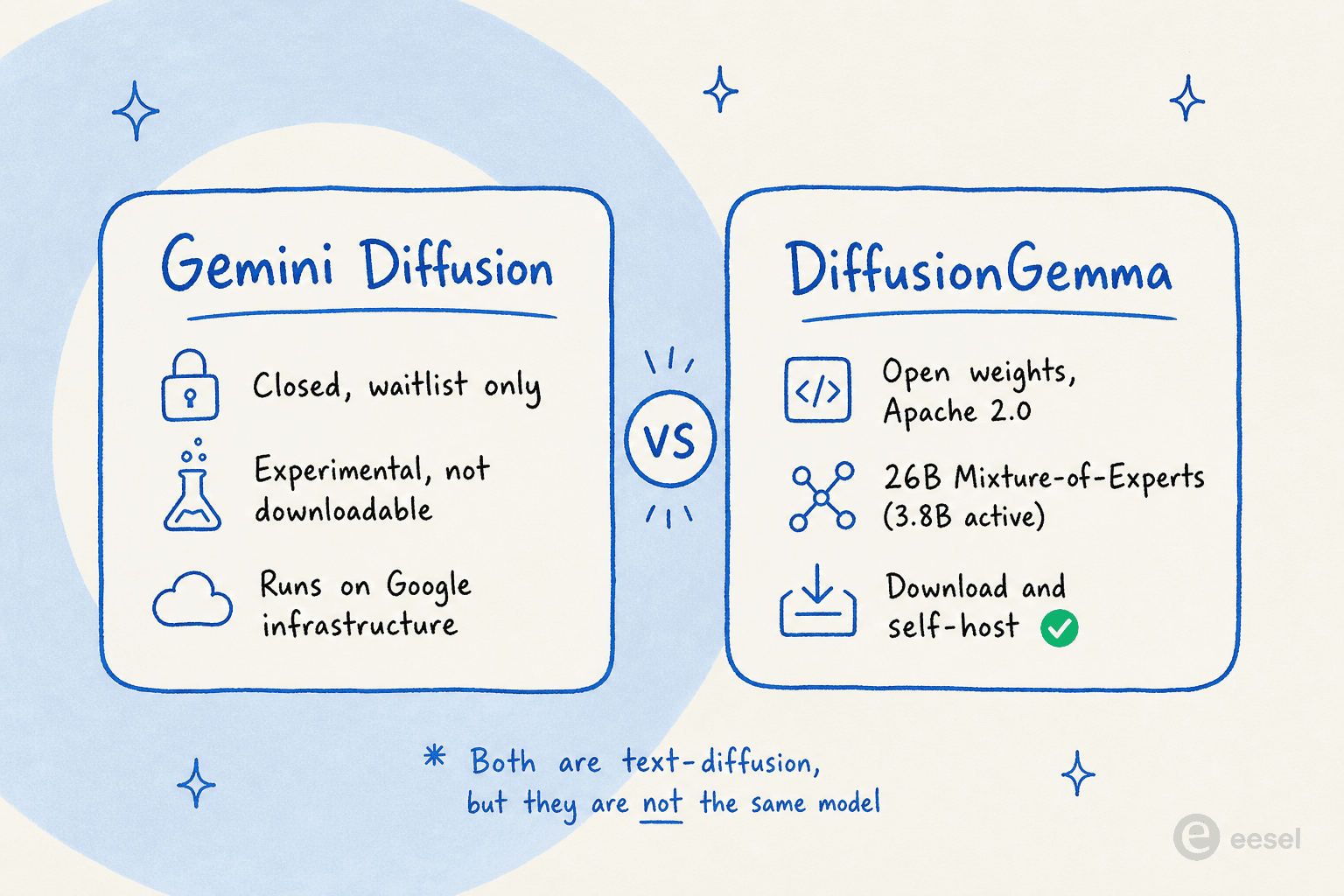
Die Tatsache, dass Google sowohl ein experimentelles geschlossenes Modell als auch ein Open-Weights-Release ausgeliefert hat, ist selbst die Geschichte: Es ist das stärkste Signal, dass Diffusions-Sprachmodelle das Stadium der Forschungskuriosität hinter sich gelassen haben. Wenn ein Frontier-Lab eine Architektur als Open Source freigibt, wettet es darauf, dass andere Leute darauf aufbauen werden.
Die Geschwindigkeitszahlen (und warum sie halbwegs echt sind)
Geschwindigkeit ist der gesamte Pitch, also schauen wir uns die Zahlen ehrlich an. DiffusionGemmas >1.000 Tok/s reihen sich neben seinen Diffusions-Verwandten ein, und der Abstand zu autoregressiven Modellen ist groß:
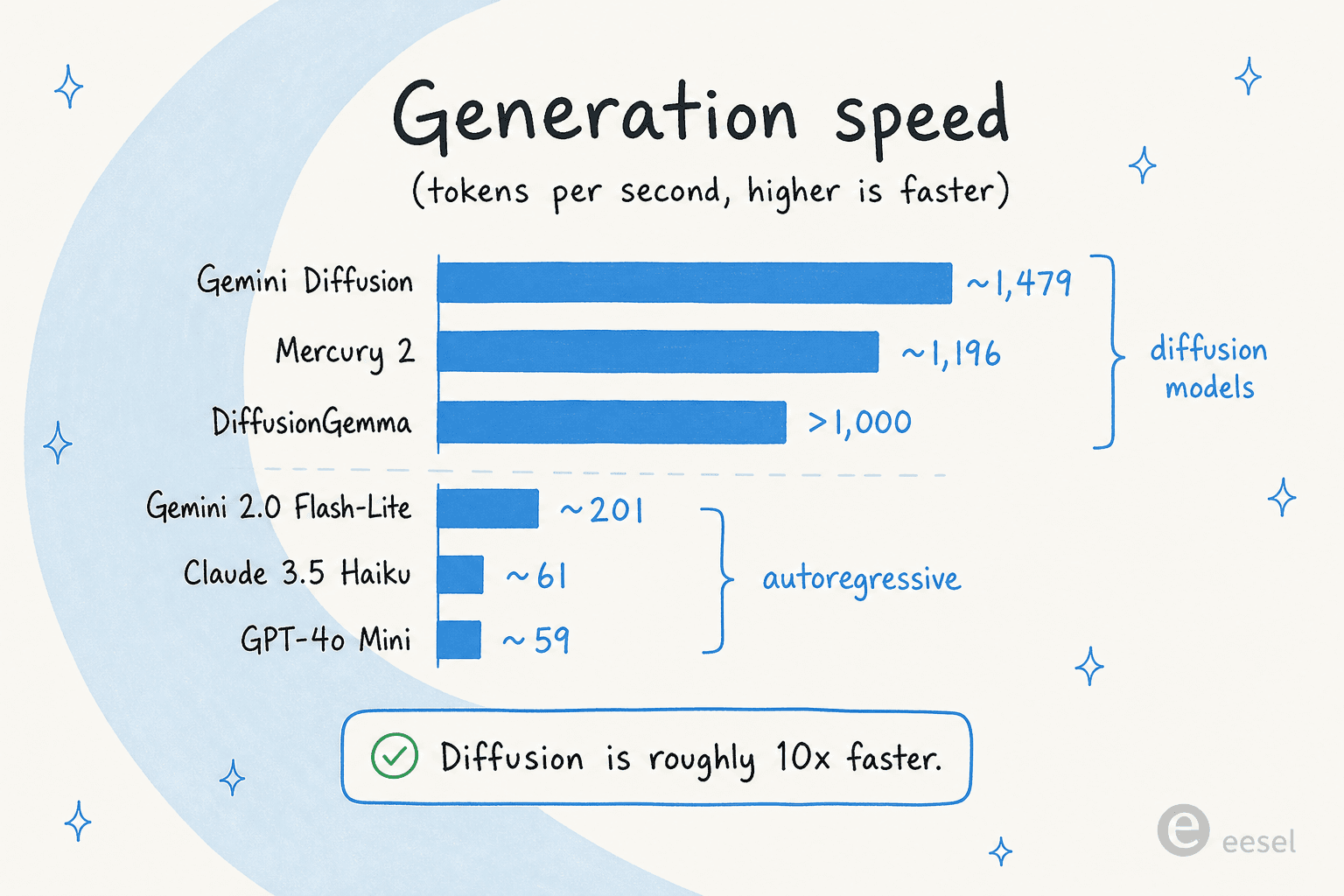
Ein paar Einschränkungen halten das geerdet. Fast jede Zahl wird auf einer NVIDIA H100 gemessen, und die meisten sind Herstellerangaben. Der eine unabhängige Maßstab in diesem Bereich, Artificial Analysis, hat die Geschwindigkeit von Inceptions Mercury-Modellen bestätigt, aber noch nicht deren Qualität. Speziell für DiffusionGemma stammen die >1.000 Tok/s und die Bis-zu-4x-Zahlen von Google und Partner-Artikeln wie Yellow.com, noch nicht von Drittanbieter-Benchmarks.
Zum Vergleich: Die autoregressiven Modelle, die Leute tatsächlich in der Produktion nutzen, liegen beim Durchsatz weit niedriger: gemäß Inceptions eigenen Benchmarks laufen GPT-4o Mini bei rund 59 Tok/s und Claude 3.5 Haiku bei rund 61, wobei das geschwindigkeitsoptimierte Gemini 2.0 Flash-Lite bei etwa 201 liegt. Die "etwa 10x schneller"-Einordnung für Diffusion hält also, zumindest auf dem Papier.
Wo es glänzt und wo nicht
Die ehrliche Einschätzung ist, dass Diffusion bei durchsatzgebundener, parallelisierbarer Arbeit wirklich schneller ist, aber Autoregression bei vielem, was Produktions-Apps tatsächlich brauchen, immer noch gewinnt. Die beste einzelne Quelle hier ist die Aufschlüsselung von Ingenieur Sean Goedecke zu den Grenzen der Diffusion, und sie lässt sich sauber auf eine Entscheidung übertragen.
Greif zur Diffusion, wenn die Aufgabe hochvolumig und parallelisierbar ist: Massen-Zusammenfassung, Klassifizierung, Umformatierung, Übersetzung oder latenzarme Agent-Loops, bei denen sich eine schnelle Antwort pro Schritt aufsummiert. Codegenerierung ist besonders gut geeignet, weil Diffusions Infilling-Natur dazu passt, wie du Code bearbeitest, indem der Anfang und das Ende eines Blocks im selben Durchlauf generiert werden.
Bleib bei Autoregression, wenn du kurze Ausgaben brauchst (Diffusion durchläuft unabhängig davon alle ihre Entrauschungsdurchläufe, also leistet sie zusätzliche Arbeit, um eine Sechs-Token-Antwort zu produzieren), lange Kontextfenster (Diffusion kann den Key-Value-Cache nicht so leicht wiederverwenden, also berechnet sie die Attention über den gesamten Kontext bei jedem Durchlauf neu) oder hartes Chain-of-Thought-Reasoning. Zu letzterem Punkt macht Goedecke das schärfste Argument:
"Ein Grund, dem Potenzial von Diffusionsmodellen zum Reasoning grundsätzlich skeptisch gegenüberzustehen, ist genau, dass sie pro Token viel weniger Arbeit leisten als autoregressive Modelle. Das ist einfach weniger Raum für das Modell, um zu 'denken'."
Sean Goedecke, "Strengths and limitations of diffusion language models"
DiffusionGemma selbst bestätigt den Kompromiss: Es bleibt in jedem veröffentlichten Benchmark unter dem Standard-Gemma 4. Ein Ingenieur, der über Produktions-Agent-Stacks schrieb, brachte den historischen Vorwurf gegen Diffusion einprägsam auf den Punkt, dass frühe Modelle "schnell waren auf die Weise, wie eine kaputte Uhr schnell ist, es spielt keine Rolle, wie schnell du die falsche Antwort bekommst" (dev.to). Die Qualitätslücke schließt sich bei kleiner und mittlerer Skala, aber an der Frontier ist sie immer noch sichtbar.
Der pragmatische Schritt, bei dem die meisten Teams landen werden, ist nicht Ersatz, sondern Routing: Sende einfache, hochfrequente Schritte (Nachschlagen, Formatieren, Klassifizieren) an ein schnelles Diffusionsmodell und reserviere ein Frontier-autoregressives Modell für tiefes Reasoning. Es ist dieselbe Logik dahinter, das richtige Werkzeug für eine Aufgabe zu wählen, statt dass ein KI-Helpdesk alles macht.
Was DiffusionGemma für Kundensupport-Teams bedeutet
Diffusion klingt perfekt für Support. Live-Chat und KI-Support-Agenten sind genau der latenzarme, nutzerorientierte Fall, bei dem der Abstand zwischen einer Ein-Sekunden- und einer Mehr-Sekunden-Antwort entscheidet, ob sich das Tool in Echtzeit anfühlt oder wie "ein Dienst, auf den man wartet." Für kundenorientierte Copiloten kann eine Antwort im Sub-Sekunden-Bereich wirklich der Unterschied zwischen Akzeptanz und Aufgabe sein.
Aber hier ist das, dem wir widersprechen würden: für ein Support-Team zählt die Modellarchitektur weit weniger als die Orchestrierung drumherum. Zwei Einschränkungen treffen direkt auf diesen Anwendungsfall zu.
Erstens stützen sich echte Support-Antworten auf langen Kontext und Retrieval, und langer Kontext ist genau die Schwachstelle der Diffusion. Eine gute Antwort ist keine Generierung von Grund auf; sie ist eine gegründete Antwort über deine Wissensdatenbank, Ticket-Historie und Richtliniendokumente. Das Retrieval und die Erdung zählen mehr zur Antwortqualität als die Frage, ob die finalen Tokens von links nach rechts oder parallel herauskamen, was der Kern der RAG vs. LLM-Frage ist.
Zweitens schlagen Qualität und Zuverlässigkeit rohe Geschwindigkeit bei allem Kundenorientierten. Ein schnelleres Modell, das an veraltetes Wissen oder schwache Eskalationsregeln angeschlossen ist, produziert nur schneller falsche Antworten. Das ist das Kaputte-Uhr-Problem, angewendet auf Support.

Wenn du also eine Support-Leitung bist, die über DiffusionGemma liest und sich fragt, ob du es brauchst: wahrscheinlich nicht direkt. Was du willst, ist eine Plattform, die Erdung, Leitplanken und Helpdesk-Integrationen richtig macht und dann still von dem Modell profitiert, das unter der Haube am schnellsten und besten ist. Latenz ist ein Hebel unter vielen, und sie ist selten der, der deine Lösungsquote zurückhält. Die größere Frage sind meist die Kosten pro Ticket gegenüber einem Menschen, der es bearbeitet.
Probiere eesel
eesel AI verkauft KI-Teamkollegen, die in deinem bestehenden Helpdesk (Zendesk, Freshdesk, HubSpot, Gorgias, Front) leben und Tier-1-Support übernehmen, indem sie ab dem ersten Tag aus deinen vergangenen Tickets und Hilfeartikeln lernen. Der Grund, warum es hier relevant ist: eesel ist bewusst modellagnostisch, sodass die Architekturdebatte oben eine ist, die du nicht gewinnen musst. Was es richtig macht, ist die Orchestrierung, die die Zahlen tatsächlich bewegt, wie konfidenzbasiertes Routing, das entwirft statt zu senden, wenn es unsicher ist, und ein Simulationsmodus, der gegen deine vergangenen Tickets läuft, sodass du die Abdeckung sehen kannst, bevor du live gehst. Gridwise sah 73 % der Tier-1-Anfragen im ersten Monat gelöst, und die Preise sind nutzungsbasiert ab 0,40 $ pro gelöstem Ticket ohne Gebühren pro Sitzplatz, sodass du für Ergebnisse zahlst statt für GPU-Stunden.
Häufig gestellte Fragen
Was ist DiffusionGemma einfach erklärt?
Ist DiffusionGemma dasselbe wie Gemini Diffusion?
Wie schnell ist DiffusionGemma im Vergleich zu einem normalen LLM?
Kann ich DiffusionGemma für den Kundensupport nutzen?
Wie viel kostet der Betrieb von DiffusionGemma?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








