
Was ist ein diffusionsbasiertes KI-Modell?
Ein Diffusionsmodell ist ein generatives Modell, das lernt, Daten aufzubauen, indem es einen schrittweisen Verrauschungsprozess umkehrt. Die Idee stammt aus der Physik: Man definiert eine Kette von Schritten, die echten Daten langsam zufälliges Rauschen hinzufügen, und trainiert dann ein Netzwerk, diesen Prozess umzukehren und Samples aus dem Rauschen zu rekonstruieren. Die grundlegende Arbeit ist Sohl-Dickstein et al. (2015) und das Paper aus dem Jahr 2020 zu Denoising Diffusion Probabilistic Models.
Es gibt zwei Hälften. Im Vorwärtsprozess nimmt man ein echtes Bild und fügt immer wieder ein wenig Gaußsches Rauschen hinzu, bis es zu reinem Rauschen wird. Dieser Teil erfordert kein Lernen; seine einzige Aufgabe ist es, Trainingspaare zu erzeugen. Im Rückwärtsprozess lernt ein neuronales Netzwerk, einen Rauschschritt nach dem anderen rückgängig zu machen. Bei der Generierung startet man von zufälligem Rauschen und lässt das Netzwerk wiederholt laufen, wobei jeder Durchlauf ein wenig mehr entfernt, bis ein kohärentes Ergebnis entsteht.
Hier ist die Intuition, die es klick machen lässt. Stellen Sie sich vor, Sie filmen eine Eisskulptur, die zu einer Pfütze schmilzt, und spielen den Film dann rückwärts ab: Sie starten von einer formlosen Pfütze und frieren sie Bild für Bild wieder zur Skulptur ein. Weil das Modell bei jedem Schritt an der gesamten Leinwand arbeitet, kann es frühere Fehler unterwegs immer wieder korrigieren.
Das ist die Technik, die die meiste moderne Bild-, Video- und Audiogenerierung antreibt. Diffusion steckt hinter Sora, Midjourney und Riffusion, ebenso wie hinter DALL-E 2, Imagen und Stable Diffusion. Der rote Faden: Sie alle starten von Rauschen und entrauschen iterativ in Richtung eines Ergebnisses, gesteuert von Ihrem Prompt.
Wie autoregressive LLMs Text erzeugen
Um zu verstehen, warum Diffusion für Text eine große Sache ist, braucht man den Kontrast. Fast jedes große Sprachmodell, das Sie verwendet haben, darunter ChatGPT, Claude, Gemini und Llama, ist ein autoregressives Modell. Es erzeugt Text von links nach rechts, ein Token nach dem anderen, und ein Token kann erst erzeugt werden, wenn alles davor existiert.
Aus diesem Design folgen zwei Konsequenzen, und beide sind für den Vergleich relevant:
- Die Latenz ist sequenziell. Die Erzeugung jedes Tokens erfordert einen vollständigen Vorwärtsdurchlauf durch Milliarden von Parametern, sodass lange Ausgaben (denken Sie an lange Schlussfolgerungsketten) direkt aufblähen, wie lange Sie warten und wie viel Sie zahlen.
- Es gibt kein Zurück. Ist ein Token einmal heraus, ist es festgelegt. Das Modell kann ein früheres Wort nicht im Licht eines späteren überarbeiten. Diese unidirektionale Gewohnheit wird für Eigenheiten wie den Umkehrfluch verantwortlich gemacht, bei dem ein Modell "A ist B" weiß, aber bei "B ist A" stolpert.
Der Vorteil ist, dass eine variable Ausgabelänge leicht fällt: Das Modell gibt einfach ein End-of-Sequence-Token aus, sobald es fertig ist. Diese Flexibilität ist einer der Gründe, warum Autoregression bei Text dominant geblieben ist.
Wie Diffusions-Sprachmodelle Text anders erzeugen
Diffusions-Sprachmodelle (dLLMs) übertragen das Bild-Rezept auf Text. Statt Pixel-aus-Rauschen machen sie Tokens-aus-Masken. Google DeepMind beschreibt es unverblümt: Statt Text direkt vorherzusagen, lernt das Modell, Ausgaben zu erzeugen, indem es Rauschen Schritt für Schritt verfeinert, sodass es schnell an einer Lösung iterieren und während der Generierung Fehler korrigieren kann.
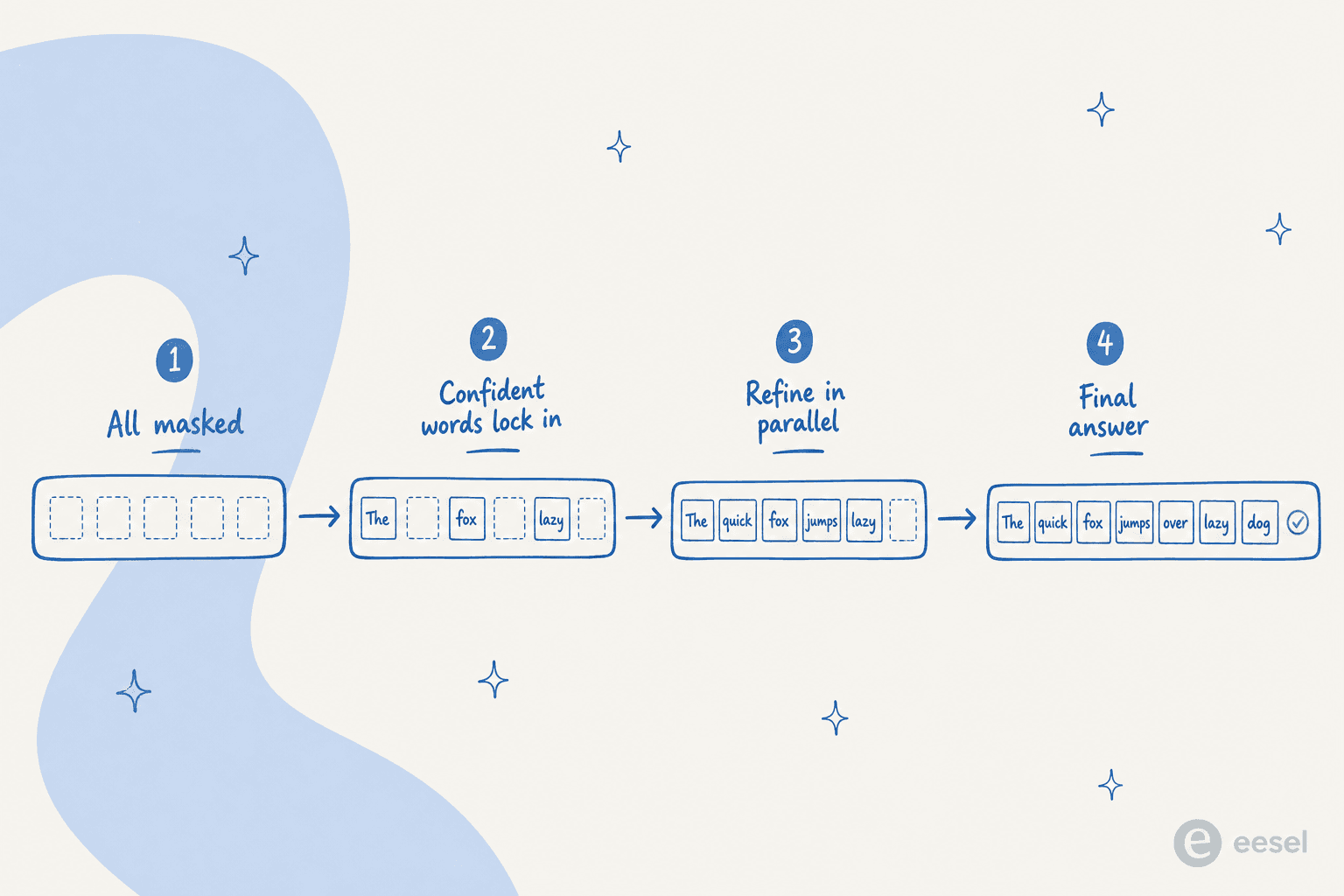
Der dominante Ansatz für Text ist maskierte Diffusion. In LLaDA, einem offenen 8B-Diffusionsmodell, maskiert der Vorwärtsprozess Tokens, und der Rückwärtsprozess nutzt einen Transformer-"Mask-Predictor", um alle maskierten Tokens auf einmal aufzufüllen, was Diffusion von vollständig maskiert zurück zu vollständig geschrieben simuliert. Eine frühere Richtung, Diffusion-LM, nutzte stattdessen kontinuierliche Diffusion über Wortvektoren.
Der entscheidende Unterschied ist das parallele Decoding. Ein dLLM erzeugt Tokens parallel statt einzeln, und der zugrunde liegende Transformer kann mehrere Tokens gleichzeitig verändern, um die Antwort global zu verbessern. Weil die Formulierung nicht autoregressiv ist, erlaubt sie auch Generierung in beliebiger Reihenfolge: Das Modell kann zuerst die Wörter festlegen, bei denen es sich sicher ist, an beliebiger Stelle in der Sequenz, und dann den Rest auffüllen.
Eine der klarsten Erklärungen kam tatsächlich von einem Entwickler auf Hacker News, der die Verwirrung um "Diffusion ersetzt Transformer" auf den Punkt brachte:
"Trotz des Namens haben Diffusions-LMs wenig mit Bild-Diffusion zu tun und sind viel näher an BERT und gutem alten Masked Language Modeling... um etwas von Grund auf zu generieren, füttert man das Modell zunächst mit lauter [MASK]s... in 10 Schritten hat man eine ganze Sequenz erzeugt." nvtop, in der Gemini-Diffusion-Diskussion auf Hacker News
Diese parallele, bidirektionale Sichtweise ist auch der Grund, warum ein Diffusionsmodell den Kontext auf beiden Seiten einer Lücke sehen kann. LLaDA zum Beispiel schlägt GPT-4o bei einer Aufgabe zur Vervollständigung umgekehrter Gedichte und überwindet den Umkehrfluch, der Modelle ins Stolpern bringt, die von links nach rechts arbeiten.
Autoregressiv vs. Diffusion: der Kernunterschied
Wenn Sie sich aus diesem Beitrag ein Bild merken, dann dieses. Autoregressive Modelle bauen einen Satz wie ein Staffellauf, bei dem jedes Wort an das nächste übergibt. Diffusionsmodelle bauen ihn wie das Entwickeln eines Polaroids, bei dem das gesamte Bild auf einmal auftaucht und mit jedem Durchlauf schärfer wird.
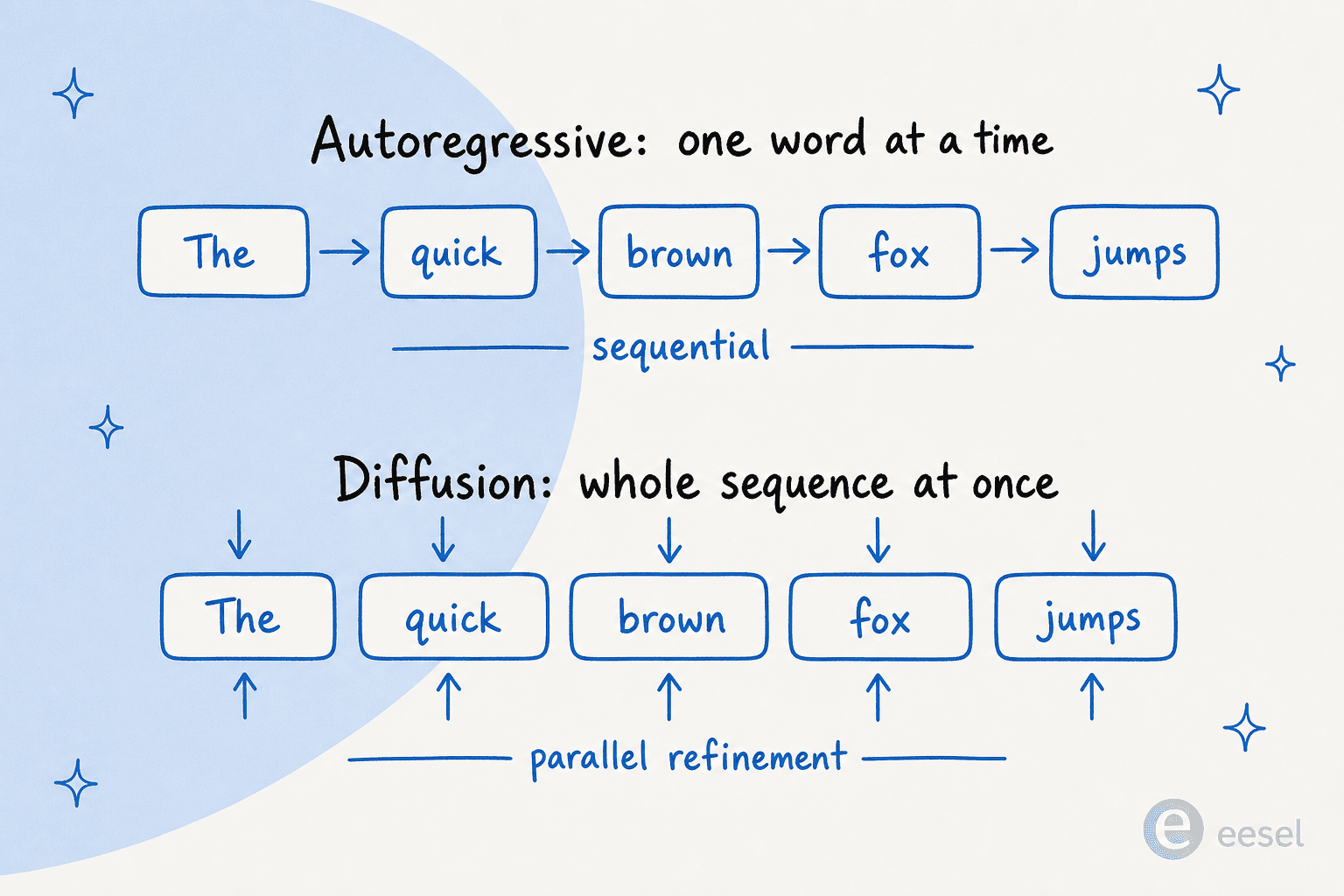
So schneiden die beiden bei den Dimensionen ab, die einen Käufer tatsächlich interessieren:
| Dimension | Autoregressiv (GPT, Claude, Gemini) | Diffusion (Mercury, Gemini Diffusion) |
|---|---|---|
| Generierungsreihenfolge | Von links nach rechts, ein Token nach dem anderen | Gesamte Sequenz parallel, beliebige Reihenfolge |
| Geschwindigkeit | Zehn bis ~200 Tokens/Sek. | ~1.000 bis ~1.500 Tokens/Sek. |
| Kann frühere Tokens überarbeiten? | Nein, einmal ausgegeben ist es festgelegt | Ja, über Entrauschungs-Durchläufe hinweg |
| Bearbeiten und Auffüllen | Umständlich (nur anhängend) | Natürlich (bedingt auf beide Seiten) |
| Schwieriges Schlussfolgern | Heute stärker | Hinkt hinterher, besonders im Spitzenmaßstab |
| Langer Kontext | Effizienter (verwendet KV-Cache wieder) | Schwächer (berechnet Attention bei jedem Durchlauf neu) |
| Ausgabelänge | Variabel, flexibel | Oft Blöcke fester Länge |
| Reife des Ökosystems | Fünf Jahre Tooling | Früh, schnelllebig |
Beachten Sie die Symmetrie: Die Stärken der Diffusion (Geschwindigkeit, Überarbeitung, Auffüllen) und ihre Schwächen (Tiefe des Schlussfolgerns, langer Kontext, Reife) lassen sich beide auf dieselbe Grundursache zurückführen. Parallel an der gesamten Sequenz zu arbeiten, macht sie schnell und bearbeitbar, und macht zugleich langen Kontext und schrittweises Schlussfolgern schwieriger.
Der Geschwindigkeitsgewinn, und der Haken
Die Geschwindigkeitszahlen sind wirklich beeindruckend, und sie sind nicht alle Marketing. Der Entwickler und LLM-Blogger Simon Willison kam von der Gemini-Diffusion-Warteliste herunter und probierte es aus:
"Das Schlüsselmerkmal ist also Geschwindigkeit. Ich bin durch die Warteliste gekommen und habe es gerade ausprobiert, und wow, sie haben nicht übertrieben, was die Geschwindigkeit angeht." Simon Willison, erste Eindrücke von Gemini Diffusion
So vergleicht sich der Durchsatz über einige Modelle hinweg, mit den autoregressiven Vergleichswerten zur Einordnung:
| Modell | Typ | Durchsatz (Tokens/Sek.) | Quelle |
|---|---|---|---|
| Gemini Diffusion | Diffusion | ~1.479 (ohne Overhead) | Anbieter |
| Mercury 2 (Inception) | Diffusion | ~1.196 Spitzenwert | Artificial Analysis |
| Mercury Coder Mini | Diffusion | 1.109 | Anbieter, von AA bestaetigt |
| Gemini 2.0 Flash-Lite | Autoregressiv | ~201 | Laut Inception |
| Claude 4.5 Haiku | Autoregressiv | ~89 | Laut Inception |
| GPT-5 Mini | Autoregressiv | ~71 | Laut Inception |
Zwei Dinge, die man hier ehrlich halten sollte. Erstens werden die meisten Durchsatzwerte auf einer NVIDIA H100 gemessen, und viele sind Anbieterangaben; Artificial Analysis ist die wichtigste unabhängige Quelle, und sie hat Mercurys Geschwindigkeit bestätigt, aber noch nicht seine Qualität. Zweitens ist der Geschwindigkeitsvorteil real, aber bedingt. Hochwertige Generierung braucht in der Regel viele Entrauschungsschritte, und ein naives Kürzen der Schritte verschlechtert die Qualität stark, sodass die Geschwindigkeit sorgfältig eingesetzt werden muss.
Und die Qualitätslücke ist nach wie vor sichtbar, besonders bei schwierigen Aufgaben. Gemini Diffusion erreicht 40,4 % gegenüber 56,5 % bei GPQA Diamond und 69,1 % gegenüber 79,0 % bei Global MMLU im Vergleich zu Flash-Lite, obwohl es bei einigen Code- und Mathematik-Benchmarks führt. Die ehrliche Einschätzung eines Ingenieurs, der an produktiven Agenten-Stacks arbeitet, ist es wert, zitiert zu werden, weil sie das historische Problem direkt benennt:
"[Frühere Diffusions-LMs] waren schnell in der Art, wie eine kaputte Uhr schnell ist
es ist egal, wie schnell man die falsche Antwort bekommt." vainkop, "Mercury 2 and the End of Autoregressive Monopoly"
Sein Urteil für Teams heute ist abgewogen: Dies ist ein "genau beobachten und bereit sein, schnell zu handeln"-Moment, kein "schreiben Sie Ihren Agenten-Stack sofort um"-Moment.
Die Modelle, die vorangehen
Der Bereich entwickelte sich rasch von einer Forschungskuriosität zu ausgelieferten Produkten. Das Finanzierungssignal ist laut: Inception Labs, gegründet von Stanfords Stefano Ermon, sammelte im November 2025 50 Mio. USD ein von einer strategischen Liste, zu der Nvidia, Microsofts M12, Databricks und Snowflake gehören, dazu die Angel-Investoren Andrew Ng und Andrej Karpathy. Wenn die Infrastruktur-Akteure wetten, glauben sie, dass die Geschwindigkeit bereitstellbar ist.
| Modell | Wer | Status | Was hervorsticht |
|---|---|---|---|
| Mercury / Mercury 2 | Inception Labs | API live, 0,25 / 0,75 USD pro 1 Mio. Tokens | Erstes kommerzielles Diffusions-LLM; ~1.196 Tok/Sek. |
| Gemini Diffusion | Google DeepMind | Experimentell, Warteliste | ~Gemini 2.0 Flash-Lite-Qualität bei mehrfacher Geschwindigkeit |
| DiffusionGemma | Google DeepMind | Offene Gewichte (Apache 2.0), Juni 2026 | 26B Mixture-of-Experts; >1.000 Tok/Sek., bei Qualität unter Gemma 4 |
| LLaDA 8B | ML-GSAI (Forschung) | Offene Gewichte | MMLU 65,9, etwa auf Augenhöhe mit Llama3 8B |
| Dream 7B | HKU NLP + Huawei | Offene Gewichte | Dominiert Planungsaufgaben (Sudoku 81,0 vs. Qwens 21,0) |
Eine kurze Klarstellung, weil die Namen verwirrend ähnlich sind: "Gemini Diffusion" (geschlossen, Warteliste) und "DiffusionGemma" (offene Gewichte) sind zwei verschiedene Google-Veröffentlichungen. Das erste ist ein experimentelles gehostetes Modell, das auf der Google I/O 2025 gezeigt wurde; das zweite ist ein herunterladbares 26B-Modell, das am 10. Juni 2026 unter Apache 2.0 veröffentlicht wurde, das durch das parallele Entrauschen von Blöcken von 256 Tokens generiert und bei jedem veröffentlichten Benchmark unter dem Standard-Gemma 4 bleibt. Geschwindigkeit gegen Qualität, offen eingetauscht.
Das wiederkehrende Muster über all diese hinweg: ein Durchsatzvorteil von mehr als dem 10-fachen, der die Qualitätslücke im kleinen und mittleren Maßstab verkleinert (LLaDA etwa auf Augenhöhe mit Llama3 8B, Mercury wettbewerbsfähig bei Code), aber an der Spitze immer noch sichtbar ist. Der primäre Anwendungsfall ist heute Code-Generierung und latenzarme, agentische Schleifen, in denen sich die Geschwindigkeit des parallelen Decodings summiert.
Warum diffusionsbasierte KI-Modelle für Unternehmen wichtig sind
Geschwindigkeit ist keine Eitelkeitskennzahl, sobald man ein Modell in ein Produkt einbaut. Die klarste Einordnung kommt aus der Produktionserfahrung: Latenz in autoregressiven Systemen summiert sich in Ketten.
Wie es ein Ingenieur beschrieb, ist ein einzelner Agentenschritt, der das Modell dreimal aufruft (schlussfolgern, planen, handeln), drei sequenzielle Durchläufe; verkettet man ein paar davon, ist man bei sieben oder acht Sekunden, was "kein Echtzeit-Agent ist, sondern ein langsamer Batch-Job". Schnellere Generierung pro Schritt macht tiefere KI-Agenten-Ketten bezahlbar. Derselbe Beitrag merkt an, dass Teams die Kettentiefe derzeit auf drei bis fünf Schritte begrenzen, um unter ihrem SLA zu bleiben; mit Diffusions-Geschwindigkeit bei der Inferenz fangen Ketten mit zehn Schritten an, machbar auszusehen.
Ein paar konkrete Stellen, an denen sich die Geschwindigkeit auszahlt:
- Echtzeit-Chat und Copilots. Antworten im Sub-Sekunden-Bereich sind, wie es dieser Ingenieur ausdrückt, "der Unterschied zwischen Akzeptanz und Aufgabe" für eine Assistenzebene in einem SaaS-Produkt.
- Textverarbeitung in großem Volumen. Zusammenfassen, Klassifizieren, Umformatieren und Übersetzen sind durchsatzgebunden und parallelisierbar, also genau dort, wo Diffusion glänzt.
- Coding-Assistenten. Die auffüllende Natur der Diffusion passt zu Code-Bearbeitungen, indem sie den Anfang und das Ende eines Blocks im selben Durchlauf erzeugt und die Mitte bearbeitet.
Dann ist da noch der Kostenaspekt. Schnellere Generierung auf derselben Hardware bedeutet geringere Inferenzkosten pro Token, und Inceptions Mitgründer argumentiert, der Ansatz "führt mehr Berechnungen pro übertragener Speichereinheit durch", was neue Wege eröffnet, die KI-Inferenzkosten auf älterer Hardware zu senken. Für Teams, die hunderttausende Agentenaufrufe pro Tag ausführen, summiert sich das. Mercury 2s öffentliche Preisgestaltung von 0,25 USD pro Million Eingabe-Tokens und 0,75 USD pro Million Ausgabe-Tokens ist wirklich günstig.
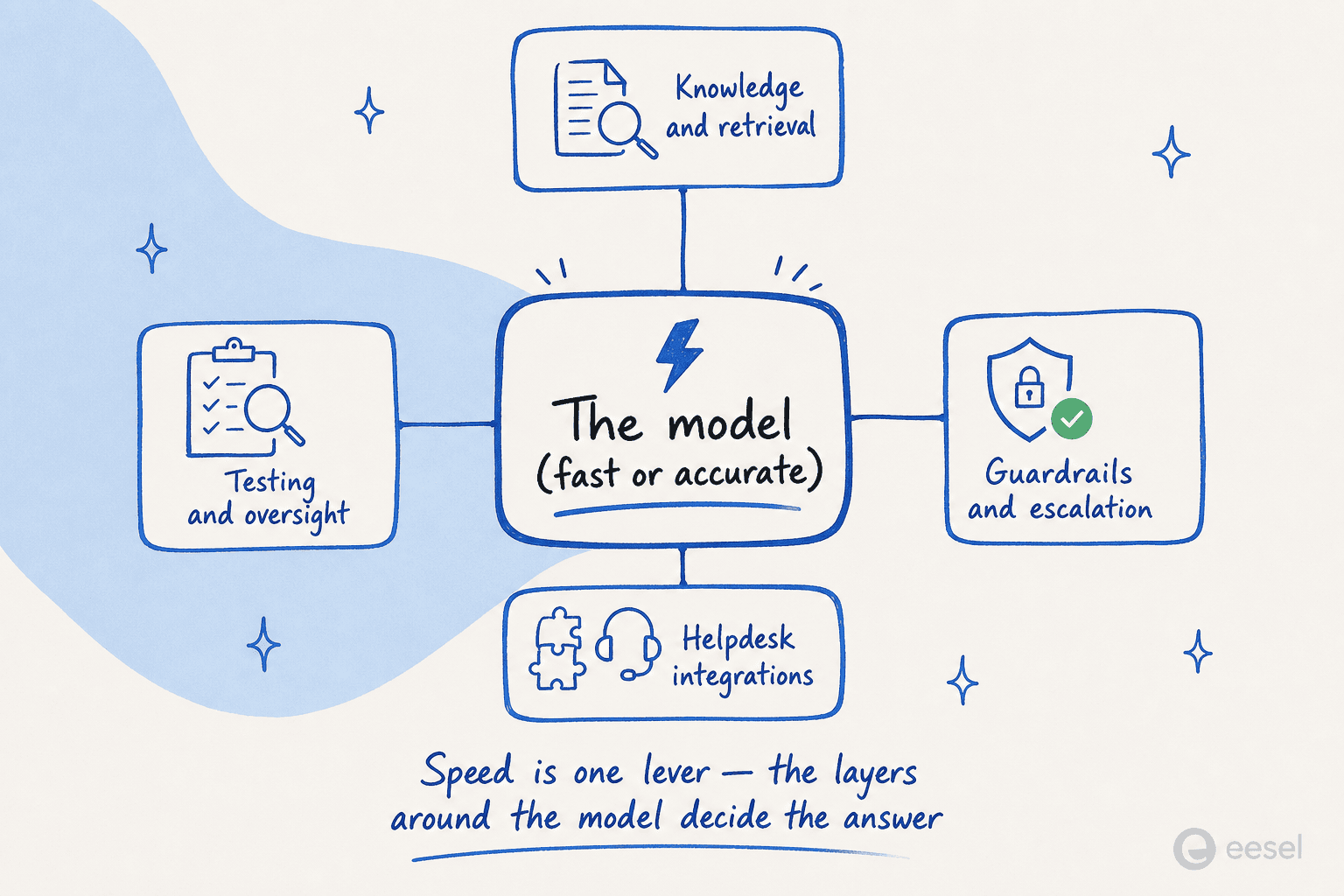
Aber hier ist der Teil, den die meiste Berichterstattung überspringt. Für die meisten produktiven Anwendungen bleiben autoregressive Modelle der Standard, und das aus gutem Grund: Sie verarbeiten langen Kontext effizienter, sie schlussfolgern tiefer (Diffusion leistet weniger Arbeit pro Token, sodass weniger Raum zum "Denken" bleibt), und sie haben fünf Jahre Tooling im Rücken. Der pragmatische Zug ist nicht Ersatz, sondern Routing: die einfachen, hochfrequenten Schritte (nachschlagen, formatieren, klassifizieren) an ein schnelles Diffusionsmodell senden und Spitzen-autoregressive Modelle für das tiefe Schlussfolgern reservieren. Vergleichen Sie das mit der Ökonomie von KI-Agenten gegenüber menschlichen Agenten, und der Reiz liegt auf der Hand: mehr von der günstigen Arbeit günstig erledigen.
Was es für den KI-Kundensupport bedeutet
Kundensupport sieht auf den ersten Blick wie der perfekte Diffusions-Anwendungsfall aus. Live-Chat und KI-Support-Agenten sind genau das latenzarme, benutzerorientierte Szenario, in dem die Lücke zwischen einer Sekunde und mehreren Sekunden entscheidet, ob sich das Erlebnis reaktionsschnell oder träge anfühlt. Ein schnelleres Modell sollte schnellere Antworten in Ihrem KI-Chatbot bedeuten.
Der Gedanke, bei dem man verweilen sollte: Für ein Support-Team spielt die Modellarchitektur eine weit geringere Rolle als die Orchestrierung rundherum. Eine echte Support-Antwort ist fast nie eine Generierung von Grund auf. Es ist eine fundierte Antwort, die sich auf Ihre Wissensdatenbank, den Ticketverlauf und Richtliniendokumente stützt. Das stellt die Schwäche der Diffusion, den Umgang mit langem Kontext, direkt in den Weg des Support-Anwendungsfalls, und es bedeutet, dass Retrieval-Qualität, Aktualität des Wissens und Schutzmechanismen die Antwort weit stärker bestimmen als die Frage, ob die letzten Tokens von links nach rechts oder parallel ausgegeben wurden.
Klar gesagt: Ein schnelleres Modell, das mit veraltetem Wissen oder schwachen Eskalationsregeln verdrahtet ist, produziert eben nur schneller falsche Antworten. Das Kaputte-Uhr-Problem, angewendet auf den Support. Das ist auch der Grund, warum Probleme mit KI-Chatbots so selten am Basismodell liegen und so oft an der Fundierung, am Testen und an den Kennzahlen, die Sie tatsächlich verfolgen.
Der wirklich nützliche Rat lautet also, modellagnostisch zu bleiben. Wählen Sie eine Ebene, die es dem zugrunde liegenden Modell erlaubt, sich unter Ihnen zu verbessern, sei es ein schnelleres Diffusionsmodell nächstes Jahr oder ein klügeres autoregressives. Die Teams, die am meisten von Diffusion profitieren werden, sind diejenigen, die zuerst auf solider Orchestrierung aufgebaut und das Modell als austauschbare Komponente behandelt haben.
eesel ausprobieren
Genau so ist eesel AI gebaut. Statt auf eine einzige Modellarchitektur zu setzen, ist eesel die Orchestrierungsebene: Es lernt vom ersten Tag an aus Ihren vergangenen Tickets, Hilfedokumenten und Tools, entwirft dann Antworten, triagiert und eskaliert über den Helpdesk, den Sie bereits nutzen, mit konfidenzbasiertem Routing, sodass Antworten mit geringer Konfidenz als Entwürfe bleiben, statt live zu gehen.

Das Unterscheidungsmerkmal, das für dieses Thema zählt: ein Simulationsmodus, der den Agenten gegen Ihre vergangenen Tickets laufen lässt, sodass Sie die Abdeckung sehen und Lücken schließen können, bevor Sie live gehen, was verhindert, dass ein schnelles Modell selbstbewusst falsche Antworten ausliefert. Es läuft über 100+ Integrationen und 80+ Sprachen hinweg, sodass Ihr Support-Setup weiterfunktioniert, egal welches Modell nächstes Jahr am schnellsten oder klügsten ist. Sie können eesel kostenlos ausprobieren, keine Kreditkarte nötig.
Häufig gestellte Fragen
Was ist ein diffusionsbasiertes KI-Modell in einfachen Worten?
Wie unterscheiden sich Diffusions-Sprachmodelle von autoregressiven LLMs wie GPT oder Claude?
Sind diffusionsbasierte KI-Modelle wirklich schneller als normale LLMs?
Sollte mein Unternehmen auf ein Diffusions-Sprachmodell umsteigen?
Spielt die Modellarchitektur für den KI-Kundensupport eine Rolle?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








