Wofür Sie wirklich bezahlen
Das häufigste Missverständnis bei den Hugging Face Preisen ist, den Kontoplan-Preis als Gesamtkosten zu betrachten. Das ist er nicht. Wie der 2026-Kostenleitfaden von Metacto es ausdrückt: „Diese Pläne decken nicht die vollen Kosten für den Betrieb Ihrer Modelle ab – betrachten Sie es als den Eintrittspreis für einen Vergnügungspark; Sie müssen trotzdem für die Fahrten bezahlen."
Der Kontoplan – Kostenlos, PRO, Team, Enterprise – ist Ihr Hub-Abonnement. Er deckt Repository-Hosting, Speicherkontingente, Kollaborationsfunktionen und Governance-Kontrollen ab. Das Ausführen von Modellen ist eine separate Abrechnung, aufgeteilt auf drei unterschiedliche Systeme: Spaces (Demo- und App-Hosting mit optionaler GPU), Inference Providers (serverlose Weiterleitung zu Drittanbieter-Modell-APIs) und Inference Endpoints (dedizierte, dauerhaft laufende Infrastruktur, die Sie kontrollieren).
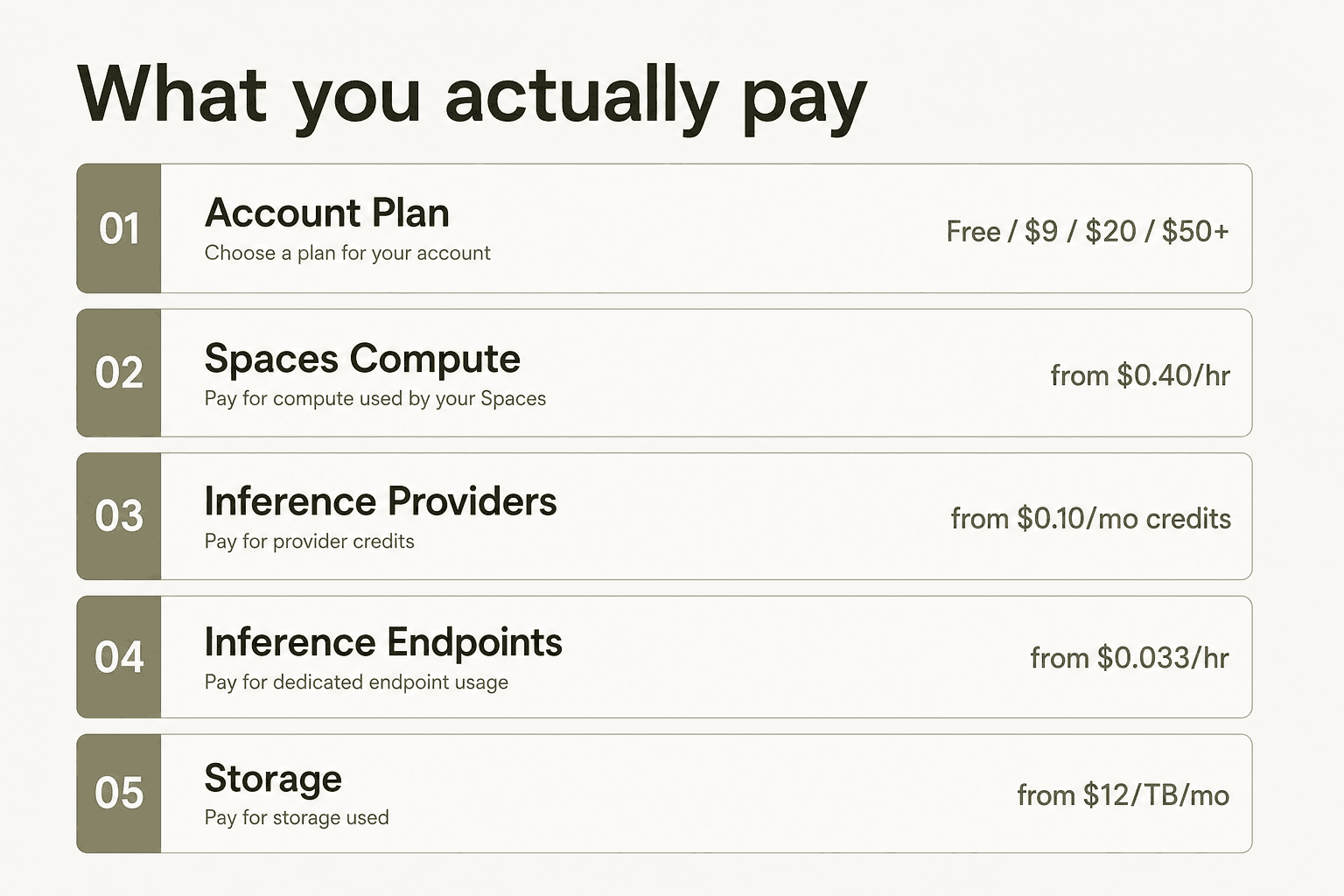
Das Verständnis dieser Trennung ist die Voraussetzung, um jeden Hugging Face Preistag korrekt zu lesen.
Kontopläne
Kostenlos
Der Gratis-Tarif ist großzügiger als die meisten Menschen erwarten. Sie erhalten Zugang zu über 2 Mio. Modellen, 500.000+ Datensätzen und über 1 Mio. Spaces auf dem Hub, 100 GB privaten Repository-Speicher, Community-ZeroGPU-Zugang und $0,10/Monat an Inference Provider-Guthaben. Dieses Guthaben reicht in der Produktion nicht weit, ist aber für kleine Experimente ausreichend.
Was Sie nicht bekommen: kein SSO, keine Audit-Logs, keine Ressourcengruppen, keine Prioritätswarteschlange. Die Rate-Limits der Inference-API sind deutlich strenger als bei bezahlten Plänen. Der Gratis-Tarif ist genau richtig für alle, die das Ökosystem kennenlernen oder gelegentliche Experimente durchführen – nicht für Teams, die Produktionsdienste betreiben.
PRO - $9/Monat
Das ist der klarste Sprung in der Preis-Leistung auf der Preisseite. Für $9/Monat bietet PRO:
- 8× Ihr ZeroGPU-Kontingent mit Top-Queue-Priorität (40 Min./Tag vs. 5 Min./Tag im Gratis-Tarif)
- 1 TB privaten Speicher (erhöht von 100 GB)
- $2/Monat Inference Provider-Guthaben (20× der kostenlosen Menge)
- Spaces Dev Mode - SSH- und VS Code-Zugang in Ihren Space für schnelle Iteration ohne Neubereitstellung
- Privaten Dataset Viewer für die Arbeit mit nicht-öffentlichen Trainingsdaten
- Früher Zugang zu neuen Hub-Funktionen und einem PRO-Abzeichen
Die ZeroGPU-Kontingenterhöhung ist der Hauptvorteil. ZeroGPU gibt jedem Nutzer Zugang zu einem gemeinsamen Pool aus Nvidia RTX Pro 6000 Blackwell-GPUs ohne stündliche Gebühr – aber Gratis-Tarif-Nutzer erschöpfen ihr Kontingent nach etwa 5 Minuten GPU-Zeit pro Tag. PRO erhöht das auf 40 Minuten mit Prioritätsplanung.
SaaSLens bewertete Hugging Face mit 4,7/5 in ihrer Bewertung vom März 2026 und nannte es „eine unserer am höchsten bewerteten Optionen für Einzelgründer", wobei der PRO-Plan speziell als „GPU-Zugang auf Enterprise-Niveau für den Preis von ein paar Tassen Kaffee pro Monat" hervorgehoben wurde. Das ist eine faire Einschätzung. Wir würden PRO immer dann wählen, wenn wir GPU-gestützte Demos betreiben müssen, ohne für dedizierte Infrastruktur zu bezahlen.
Team - $20/Nutzer/Monat
Team ist der erste organisationsweite Plan. Die Abrechnung erfolgt pro Sitz: Jedes Mitglied Ihrer Hugging Face Organisation zahlt $20/Monat. Zusätzlich zu den PRO-Vorteilen für alle Mitglieder der Organisation erhalten Sie:
- 12 TB öffentlichen Basisspeicher + 1 TB/Sitz öffentlich + 1 TB/Sitz privat
- $2/Monat Inference Provider-Guthaben pro Sitz (gemeinsam genutzt in der gesamten Organisation)
- Abrechnungskontrollen auf Organisationsebene für Inference Providers – Ausgabenlimits festlegen, bestimmte Anbieter deaktivieren
- Prioritäts-Support vom Hugging Face Team
- Alle Mitglieder erhalten die 8× ZeroGPU-Kontingenterhöhung
Die Abrechnungskontrollen für Inference Providers sind wirklich nützlich für Forschungsteams, bei denen Einzelpersonen versehentlich hohe Kosten durch teure Frontier-Modelle verursachen könnten. Administratoren können das monatliche Ausgabenlimit der Organisation begrenzen und bestimmte Anbieter deaktivieren.
Ein wichtiger Vorbehalt: Team enthält kein SSO, keine Audit-Logs und keine Ressourcengruppen. Diese sind nur in Enterprise verfügbar. Wenn Ihr Team eine Verbindung zu Ihrem Unternehmens-Identity-Provider herstellen oder Compliance-Berichte erstellen muss, ist Team unabhängig von der Mitgliederzahl nicht ausreichend.
Enterprise - ab $50/Nutzer/Monat
Enterprise ist der Bereich, in dem der Governance-Stack freigeschaltet wird. Der Betrag von $50/Nutzer/Monat ist die Untergrenze – große Verträge mit Volumenengagements, Jahresabrechnung und individuellen SLAs werden mit dem Hugging Face Vertriebsteam ausgehandelt. Bekannte Enterprise-Kunden sind unter anderem NVIDIA, Google, OpenAI, Meta, Salesforce, IBM Research, Shopify und Roblox.
Die Funktionen, die Teams zu dieser Stufe treiben:
SSO verbindet Ihren Identity-Provider – Okta, Azure AD, Google Workspace oder jeden SAML/OpenID Connect-kompatiblen IdP. Enterprise Plus fügt SCIM für automatisierte Benutzerbereitstellung hinzu.
Audit-Logs zeichnen jede Organisationsaktion auf – wer was, von wo und zu welchem Zeitpunkt geändert hat – mit Benutzerattribution, IP-Adresse und Standort. Nützlich für SOC 2 Typ II-Prüfungen und DSGVO-Compliance-Dokumentation.
Ressourcengruppen ermöglichen es Administratoren, Repositories benannten Gruppen zuzuweisen und pro Nutzer READ-, WRITE- oder CONTRIBUTOR-Zugang zu gewähren – nützlich, um Forschungs-, Produktions- und experimentelle Arbeitsbereiche innerhalb einer einzigen Organisation zu trennen.
Repository-Analysen zeigen Download-Trends, Modellnutzung und Datensatzzugriffe in der gesamten Organisation in einem einzigen Dashboard – praktisch, um zu verstehen, welche internen Modelle tatsächlich verwendet werden.
Datenresidenz ermöglicht Ihnen die Auswahl und Überprüfung der geografischen Region, in der Ihre Repositories gespeichert werden – relevant für DSGVO- und Datensouveränitätsanforderungen. Enterprise Plus fügt Netzwerksicherheitskontrollen und IP-Allowlisting hinzu.
Der Speicher für Enterprise ist erheblich: 200 TB öffentlicher Basisspeicher + 1 TB/Sitz, skalierbar bis zu 1 PB für große Verträge.
Planvergleich auf einen Blick
| Kostenlos | PRO | Team | Enterprise | |
|---|---|---|---|---|
| Preis | $0 | $9/Monat | $20/Nutzer/Monat | $50+/Nutzer/Monat |
| Privater Speicher | 100 GB | 1 TB | 1 TB/Sitz | 1 TB/Sitz |
| Öffentlicher Speicher | Best-Effort | Bis zu 10 TB | 12 TB + 1 TB/Sitz | 200 TB + 1 TB/Sitz |
| Inference-Guthaben | $0,10/Monat | $2,00/Monat | $2,00/Sitz/Monat | $2,00/Sitz/Monat |
| ZeroGPU-Kontingent | Standard | 8× + Priorität | 8× (alle Mitglieder) | 8× (alle Mitglieder) |
| Spaces Dev Mode | Nein | Ja | Ja | Ja |
| Privater Dataset Viewer | Nein | Ja | Ja | Ja |
| Org-Abrechnungskontrollen | Nein | Nein | Ja | Ja |
| SSO | Nein | Nein | Nein | Ja |
| Audit-Logs | Nein | Nein | Nein | Ja |
| Ressourcengruppen | Nein | Nein | Nein | Ja |
| Repository-Analysen | Nein | Nein | Nein | Ja |
| Datenresidenz | Nein | Nein | Nein | Ja |
| Prioritäts-Support | Nein | Nein | Ja | Ja (dediziert) |
| Jahresverträge | Nein | Nein | Nein | Ja |
Spaces Hardware-Preise
Spaces sind interaktive ML-Apps und Demos, die auf dem Hub gehostet werden. Das CPU-Basic-Angebot ist kostenlos; GPU-Angebote werden stündlich und nutzungsbasiert abgerechnet, solange der Space läuft.
| Hardware | vCPU | RAM | Beschleuniger | VRAM | Stündlich |
|---|---|---|---|---|---|
| CPU Basic | 2 | 16 GB | - | - | Kostenlos |
| CPU Upgrade | 8 | 32 GB | - | - | $0,03 |
| ZeroGPU | dynamisch | dynamisch | RTX Pro 6000 Blackwell | bis zu 96 GB | Kostenlos* |
| T4 - small | 4 | 15 GB | T4 | 16 GB | $0,40 |
| T4 - medium | 8 | 30 GB | T4 | 16 GB | $0,60 |
| L4 (1×) | 8 | 30 GB | L4 | 24 GB | $0,80 |
| L4 (4×) | 48 | 186 GB | L4 | 96 GB | $3,80 |
| L40S (1×) | 8 | 62 GB | L40S | 48 GB | $1,80 |
| L40S (4×) | 48 | 382 GB | L40S | 192 GB | $8,30 |
| L40S (8×) | 192 | 1.534 GB | L40S | 384 GB | $23,50 |
| A10G - small | 4 | 15 GB | A10G | 24 GB | $1,00 |
| A10G - large | 12 | 46 GB | A10G | 24 GB | $1,50 |
| A100 - large | 12 | 142 GB | A100 | 80 GB | $2,50 |
| 4× A100 | 48 | 568 GB | A100 | 320 GB | $10,00 |
| 8× A100 | 96 | 1.136 GB | A100 | 640 GB | $20,00 |
*ZeroGPU ist innerhalb des Kontingents kostenlos. PRO- und Team/Enterprise-Org-Mitglieder erhalten das 8-fache des Standardkontingents. Überschreitungen werden mit $1 pro 10 Minuten berechnet.
Spaces wechseln nach 48 Stunden Inaktivität auf dem kostenlosen CPU-Angebot in den Ruhezustand. Bezahlte GPU-Spaces laufen weiter, bis Sie sie pausieren – ein T4-small, der 30 Tage läuft, kostet $288. Es gibt kein automatisches Abschalten.
Wissenswert: Community GPU-Förderungen sind für qualifizierende Nebenprojekte verfügbar. Wenn Sie offene Forschung veröffentlichen und dauerhaften GPU-Zugang benötigen, lohnt es sich, einen Antrag zu stellen, bevor Sie sich für einen bezahlten Tarif entscheiden.
Inference Providers (serverlos)
Inference Providers ermöglicht es Ihnen, API-Aufrufe an über 45.000 Modelle bei mehr als 18 Inferenz-Partnern weiterzuleiten – Groq, Fireworks, Mistral, Cohere, Nebius, SambaNova und andere – über einen einzigen einheitlichen Endpunkt unter router.huggingface.co/v1. Hugging Face gibt die Anbieterpreise ohne Aufschlag weiter.
Monatliches Guthaben nach Plan, angewendet bei der Weiterleitung über Hugging Face:
| Plan | Monatliches Guthaben |
|---|---|
| Kostenlos | $0,10 |
| PRO | $2,00 |
| Team / Enterprise (pro Sitz) | $2,00 |
Sobald das Guthaben aufgebraucht ist, wird die Nutzung nutzungsbasiert abgerechnet. Sie können entweder HF Ihr Konto belasten lassen (einfacher, monatliches Guthaben wird angewendet) oder Ihren eigenen Anbieter-API-Schlüssel mitbringen und den Anbieter direkt bezahlen (keine HF-Guthaben anwendbar, aber Sie kontrollieren die Abrechnungsbeziehung direkt).
Team- und Enterprise-Orgs können Ausgabenlimits festlegen und bestimmte Anbieter aus den Org-Einstellungen deaktivieren – nützlich zur Kostenkontrolle, wenn einzelne Mitglieder teure Frontier-Modelle betreiben.
Hugging Face betreibt auch sein eigenes hf-inference-Backend – die ursprüngliche „Inference API (serverlos)" – jetzt fokussiert auf CPU-gebundene Aufgaben wie Embeddings, Textklassifikation und kleinere Modelle (BERT, GPT-2). Der Betrieb von Llama 3.1 70B oder einem aktuellen LLM erfolgt über einen Drittanbieter.
Inference Endpoints (dediziertes Deployment)
Inference Endpoints ist für Teams gedacht, die vorhersehbare Latenz und dedizierte Infrastruktur benötigen – kein Kaltstart, keine gemeinsame Warteschlange, Autoscaling-Deployments auf AWS, Azure oder GCP. Sie wählen die Hardware, Hugging Face verwaltet den Container und die Skalierung.
Das Abrechnungsmodell ist dasjenige, das am häufigsten überrascht. Endpoints werden minutenweise zum Instanzpreis multipliziert mit der Anzahl aktiver Replikate abgerechnet – unabhängig vom Anfragevolumen. Das ist keine Abrechnung pro Anfrage oder pro Token.
GPU-Instanzpreise (AWS)
| GPU | Anzahl | VRAM | Stündlich |
|---|---|---|---|
| T4 | 1 | 14 GB | $0,50 |
| T4 | 4 | 56 GB | $3,00 |
| L4 | 1 | 24 GB | $0,80 |
| L40S | 1 | 48 GB | $1,80 |
| A100 | 1 | 80 GB | $2,50 |
| A100 | 4 | 320 GB | $10,00 |
| A100 | 8 | 640 GB | $20,00 |
| H100 | 1 | 80 GB | $4,50 |
| H100 | 4 | 320 GB | $18,00 |
| H100 | 8 | 640 GB | $36,00 |
| H200 | 1 | 141 GB | $5,00 |
| B200 | 1 | 179 GB | $9,25 |
| B200 | 8 | 1.432 GB | $74,00 |
| RTX PRO 6000 | 1 | 96 GB | $2,75 |
GCP- und Azure-Optionen sind ebenfalls mit leicht unterschiedlichen Preisen pro Hardware-Stufe verfügbar. Die vollständige Tabelle einschließlich CPU- und Beschleuniger-Instanzen (Inferentia2, TPU v5e) finden Sie auf der Inference Endpoints Preisseite.
Konkrete Kostenbeispiele
Dauerhaft laufender CPU-Endpoint - AWS 2-vCPU, 1 Replikat:
- $0,067/Std. × 730 Stunden = ~$49/Monat
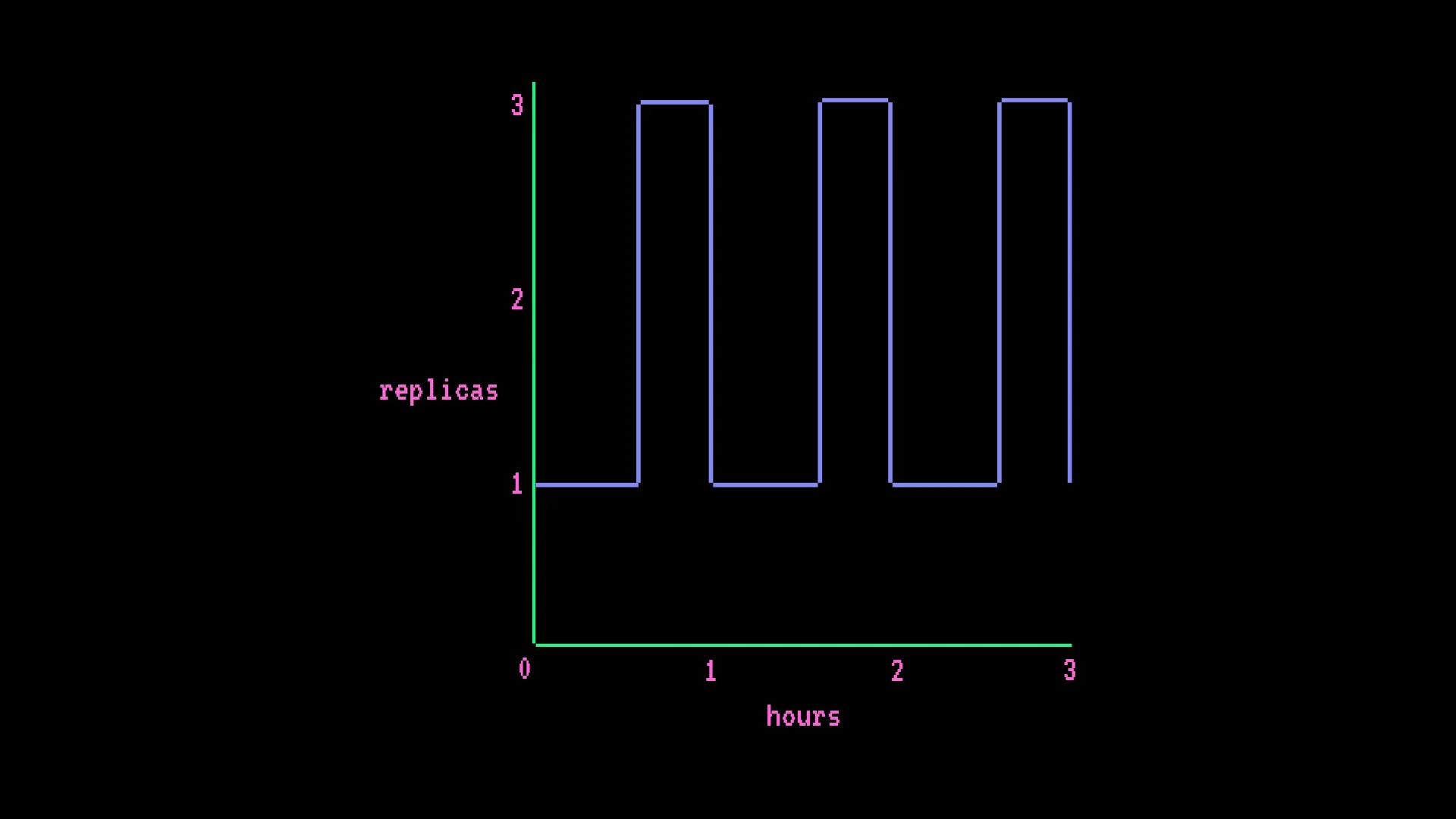
GPU-Endpoint mit Autoscaling - AWS T4 x1, min. 1 Replikat, max. 3, mit 15-minütigen Spitzen jede Stunde:
- $0,50 × (730 Std. × 1 + 182,5 Std. × 2 zusätzliche Replikate) = $547,50/Monat
Die Abrechnungsformel: Stundensatz × ((Stunden × Mindest-Replikate) + (Scale-up-Stunden × zusätzliche Replikate))
Dieses Always-on-Modell ist die häufigste Quelle für unerwartete Rechnungen. Eine Frage in den Hugging Face Foren mit über 3.700 Aufrufen verdeutlicht die Verwirrung gut:
„Ich bin etwas verwirrt über das Preismodell. Angenommen, ich deploye ein Modell auf einer CPU-Basic-Maschine ($0,06/Stunde). Zahle ich also, solange das Modell deployt ist, oder zahle ich nur für die Rechenzeit (z. B. ich stelle 2 Anfragen und jede Anfrage dauert 10 Sekunden, zahle ich also nur für die 20 Sekunden)?"
Die Antwort lautet: Sie zahlen, solange das Modell deployt ist, nicht pro Anfrage. Diese Unterscheidung überrascht viele.
Speicherpreise
Speicher auf dem Hub ist eine eigene Abrechnungsebene, die pro TB pro Monat berechnet wird. Die Preise variieren je nach Volumen und ob Repositories öffentlich oder privat sind:
| Volumen | Öffentlicher Preis | Privater Preis |
|---|---|---|
| Basis | $12/TB/Monat | $18/TB/Monat |
| 50 TB+ | $10/TB/Monat | $16/TB/Monat |
| 200 TB+ | $9/TB/Monat | $14/TB/Monat |
| 500 TB+ | $8/TB/Monat | $12/TB/Monat |
Egress und CDN-Lieferung sind ohne Aufpreis inbegriffen – was im Vergleich zu AWS S3 mit ~$23/TB/Monat und separaten Egress-Gebühren gut abschneidet.
Jeder bezahlte Plan beinhaltet sinnvollen Basisspeicher, bevor Pro-TB-Gebühren anfallen:
- PRO: bis zu 10 TB öffentlich + 1 TB privat
- Team: 12 TB öffentlicher Basisspeicher + 1 TB/Sitz öffentlich + 1 TB/Sitz privat
- Enterprise: 200 TB öffentlicher Basisspeicher + 1 TB/Sitz, skalierbar bis zu 1 PB für große Verträge
Öffentliche Speicher-Add-ons für bezahlte Pläne: 1 TB für $12/Monat, 5 TB für $60/Monat, 10 TB für $120/Monat, 50 TB für $500/Monat. Privater Speicher über die enthaltenen Limits hinaus wird nutzungsbasiert ab $18/TB/Monat berechnet.
Die Abrechnungsfallen, die Sie kennen sollten
Es gibt keine eingebauten Ausgabenlimits für Spaces oder Inference Endpoints. Inference Provider-Ausgaben können auf Organisationsebene bei Team und Enterprise begrenzt werden, aber GPU-Spaces und dedizierte Endpoints haben keinen automatischen Abschalter. Ein Forum-Thread vom April 2025 beschreibt eine Rechnung, die über Nacht von $78,22 auf $519,24 anstieg:
„Es gibt einen plötzlichen Anstieg von ~1.100 Stunden innerhalb von weniger als 24 Stunden, was technisch unmöglich ist. Selbst bei kontinuierlicher GPU-Nutzung: Maximum möglich = 24 Stunden/Tag pro Instanz. Diese Spitze würde Dutzende parallele Instanzen implizieren, was nicht der Fall ist."
Ob Abrechnungsfehler oder unkontrollierter Prozess – der Nutzer hatte keine Möglichkeit, das Risiko vorab zu begrenzen. Die Lehre: Legen Sie manuelle Pause-Richtlinien für GPU-Spaces fest und halten Sie die Mindest-Replikate für Inference Endpoints so niedrig wie vertretbar.
Stunden- und Monatssätze stimmen nicht immer überein. Ein Thread vom Oktober 2024 stellte eine echte Inkonsistenz fest: Die mittlere Stufe für persistenten Speicher ist mit $0,03/Stunde angegeben, was ~$21,60/Monat impliziert – aber die tatsächliche Monatsgebühr beträgt $25. Es lohnt sich, die monatlichen Gesamtbeträge zu überprüfen, anstatt aus den Stundenzahlen hochzurechnen.
Inference Endpoints rechnen immer ab. Wenn das Mindest-Replikat-Kontingent Ihres Endpoints 1 beträgt, zahlen Sie den Hardware-Preis rund um die Uhr unabhängig vom Traffic-Volumen. Das überrascht Teams, die an serverlose Preismodelle gewöhnt sind, bei denen Leerlaufzeit nichts kostet.
Compute-Kosten im Vergleich
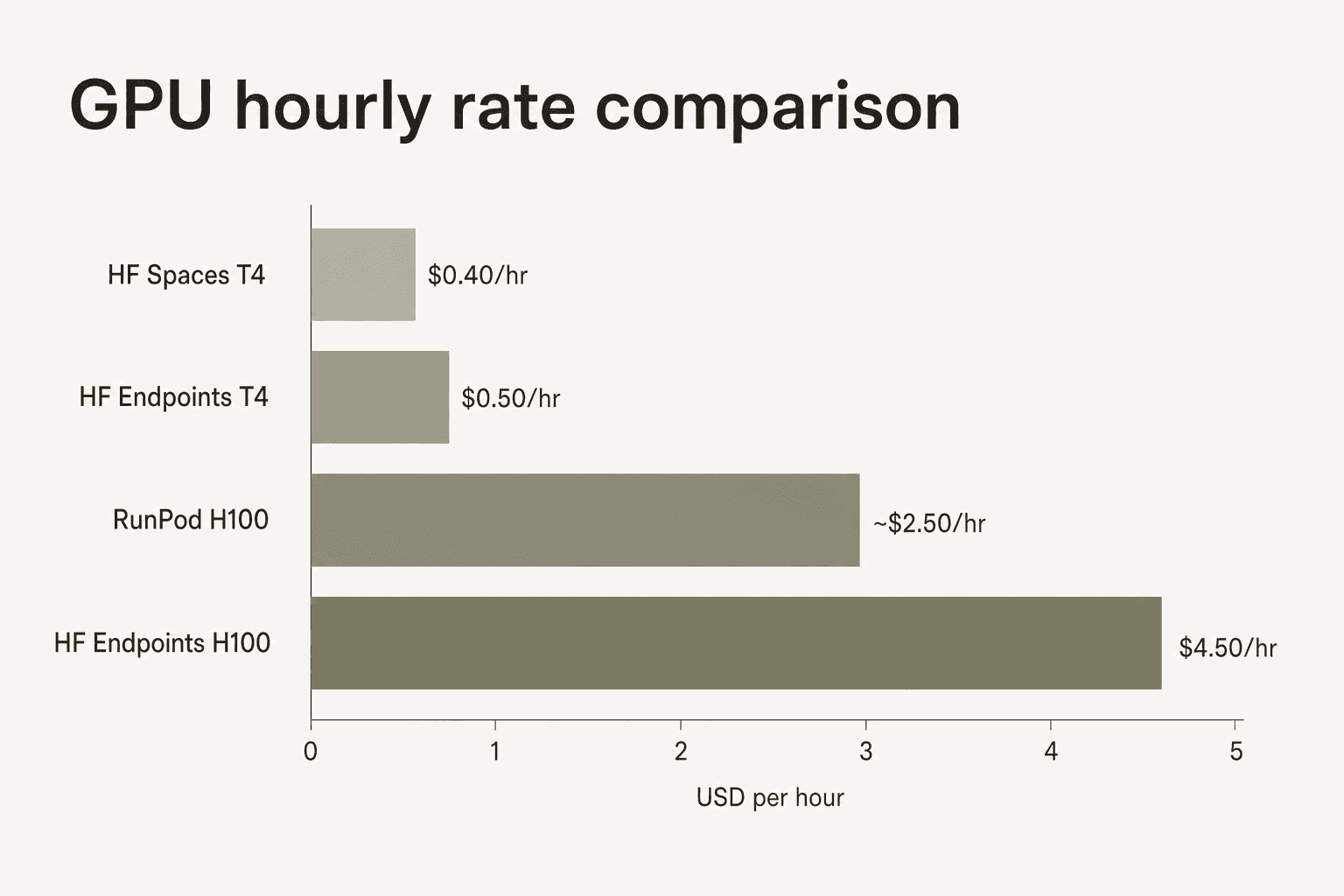
Hugging Face Inference Endpoints kosten im Vergleich zu Commodity-GPU-Anbietern einen Komfort-Aufschlag. Eine H100 auf HF Dedicated Endpoints kostet je nach Cloud-Region $4,50–$10/Stunde; dieselbe Hardware bei RunPod kostet $2–3/Stunde. Die Community-Bewertungsdaten weisen konsistent auf diese Lücke hin – „GPU-Compute-Kosten summieren sich schnell" taucht als wiederkehrende Kritik auf – während gleichzeitig darauf hingewiesen wird, dass Hub-Integration, Modellverfügbarkeit und die fehlende Notwendigkeit des Infrastrukturmanagements den Aufpreis für Teams rechtfertigen, die im HF-Ökosystem bleiben möchten.
Für CPU-gebundene Workloads (Embeddings, Klassifikation, kleinere Modelle) sieht die Kalkulation anders aus – HF-Preise sind wettbewerbsfähig und verwaltete Infrastruktur spart Engineering-Zeit. Der Aufpreis zeigt sich am deutlichsten bei High-GPU-Workloads, wo Together AI und ähnliche Anbieter bessere Compute-Wirtschaftlichkeit für Teams bieten, die nicht die Modellregistrierung und das Deployment-Tooling des Hubs benötigen.
Der Inference Playground ist der einfachste Weg, Modelle auszuprobieren, bevor Sie sich für eine Compute-Stufe entscheiden – er ermöglicht es Ihnen, Anbieter über die Browser-UI zu testen, ohne eine Abrechnungseinrichtung zu benötigen.
Welcher Plan und welches Produkt zu Ihrer Situation passt
Kostenlos – Modelle erkunden, gelegentliche Experimente durchführen, das Ökosystem kennenlernen. Die Modellregistrierung und der ZeroGPU-Zugang machen es wirklich nützlich, ohne etwas auszugeben.
PRO für $9/Monat – aktive individuelle Entwicklung, bei der Sie die ZeroGPU-Kontingenterhöhung, mehr privaten Speicher oder den Spaces Dev Mode benötigen. Bei diesem Preis ist es für jeden, der regelmäßig ML-Arbeit durchführt, schwer dagegen zu argumentieren.
Team für $20/Nutzer/Monat – echte Teams, die an Modellen oder Datensätzen zusammenarbeiten. Die Abrechnungskontrollen auf Organisationsebene für Inference Providers und der gemeinsame Speicher werden in diesem Maßstab wichtig.
Enterprise für $50+/Nutzer/Monat – SSO, Audit-Logs oder Compliance-Anforderungen. Bezahlen Sie Enterprise nicht, weil Ihr Team groß ist – bezahlen Sie dafür, wenn Sie den Governance-Stack tatsächlich benötigen.
Inference Providers – praktischer serverloser Zugang zu Drittanbieter-Modellen zu Anbieterpreisen, ohne Infrastruktur verwalten zu müssen. Die $2/Monat Guthaben reichen in der Produktion nicht weit, aber die einheitliche API ist hervorragend für Evaluierung und Prototyping.
Inference Endpoints – dedizierte Hardware mit vorhersehbarer Latenz und Autoscaling. Budget für Always-on-Abrechnung einplanen, Mindest-Replikate konservativ festlegen und manuelle Pause-Richtlinien implementieren. Nicht die richtige Standardwahl für Traffic-arme oder experimentelle Deployments.
Wenn Sie das breitere Ökosystem vergleichen, behandelt Hugging Face Alternativen sieben weitere Plattformen, die für das Modell-Deployment einen Blick wert sind.
eesel ausprobieren
Wenn Sie Hugging Face für KI im Kundensupport in Betracht ziehen – Automatisierung von Ticket-Antworten, Aufbau eines Helpdesk-Agenten, Abwehr wiederkehrender Anfragen – bietet eesel einen direkteren Weg. Statt Modell-Hosting-Infrastruktur über fünf Abrechnungsbereiche zu verwalten, deployt eesel vollständig autonome KI-Agenten direkt in Zendesk, Slack, Freshdesk und über 100 anderen Tools. Sie briefen den Agenten in natürlicher Sprache, er löst Tickets von Anfang bis Ende, und die Preisgestaltung skaliert mit der Nutzung bei $0,40 pro Aufgabe statt nach Compute-Stunden. Kein GPU-Management, keine Abrechnungsspitzen, keine Inference Endpoints zu konfigurieren.
Starten Sie mit $50 kostenlosen Guthaben – keine Kreditkarte erforderlich →
Häufig gestellte Fragen
Wie viel kostet Hugging Face?
Ist Hugging Face kostenlos nutzbar?
Was ist im Hugging Face PRO-Plan enthalten?
Wie viel kostet Hugging Face Enterprise?
Wie funktioniert die Abrechnung bei Hugging Face Inference Endpoints?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.