Was GLM-5.2 eigentlich ist
GLM-5.2 ist das neueste Flaggschiff-Modell von Z.ai, dem Unternehmen, das früher als Zhipu AI bekannt war, aus der Tsinghua-Universität im Jahr 2019 ausgegründet wurde und im Januar 2026 an der Hongkonger Börse an die Börse ging. Das kurze Datenblatt:
- Open Weights, MIT-Lizenz. Die Gewichte sind öffentlich auf Hugging Face und ModelScope verfügbar, ohne regionale Beschränkungen. Sie können es herunterladen und selbst betreiben.
- 753 Milliarden Parameter, ~40 Milliarden aktiv. Es ist ein Mixture-of-Experts-Modell, sodass pro Token nur ein Teil der Parameter aktiv ist.
- 1-Millionen-Token-Kontext. Ein 5-facher Sprung gegenüber GLM-5.1s 200K; Z.ai betont, dass es darauf trainiert ist, über lange, unübersichtliche Coding-Agent-Läufe hinweg zuverlässig zu bleiben – nicht nur nominell die Token zu akzeptieren.
- Für Long-Horizon-Arbeit entwickelt. Die gesamte Version 5.2 ist auf autonome Coding- und Engineering-Aufgaben ausgerichtet, die stundenlang laufen, mit einer neuen Aufwandssteuerung (
Maxfür Spitzenqualität,Highzur ungefähren Halbierung der Ausgabe-Token).
Kurz gesagt: Es ist ein Frontier-Klasse-Coding-Modell, das Sie legal auf Ihrer eigenen Hardware betreiben können. Diese Kombination erregt Aufmerksamkeit, weil es sie in dieser Qualität bisher wirklich nicht gab, und sie verändert, wie Teams über ihre Generative-KI-Budgets nachdenken.
Die Benchmarks und was sie einem Unternehmen sagen
Z.ais Hauptaussage ist, dass GLM-5.2 das stärkste Open-Source-Modell bei Standard-Coding-Benchmarks ist und das erste Open-Weights-Modell, das Terminal-Bench mit über 80 % überquert. Die Zahlen stützen diese Einschätzung.
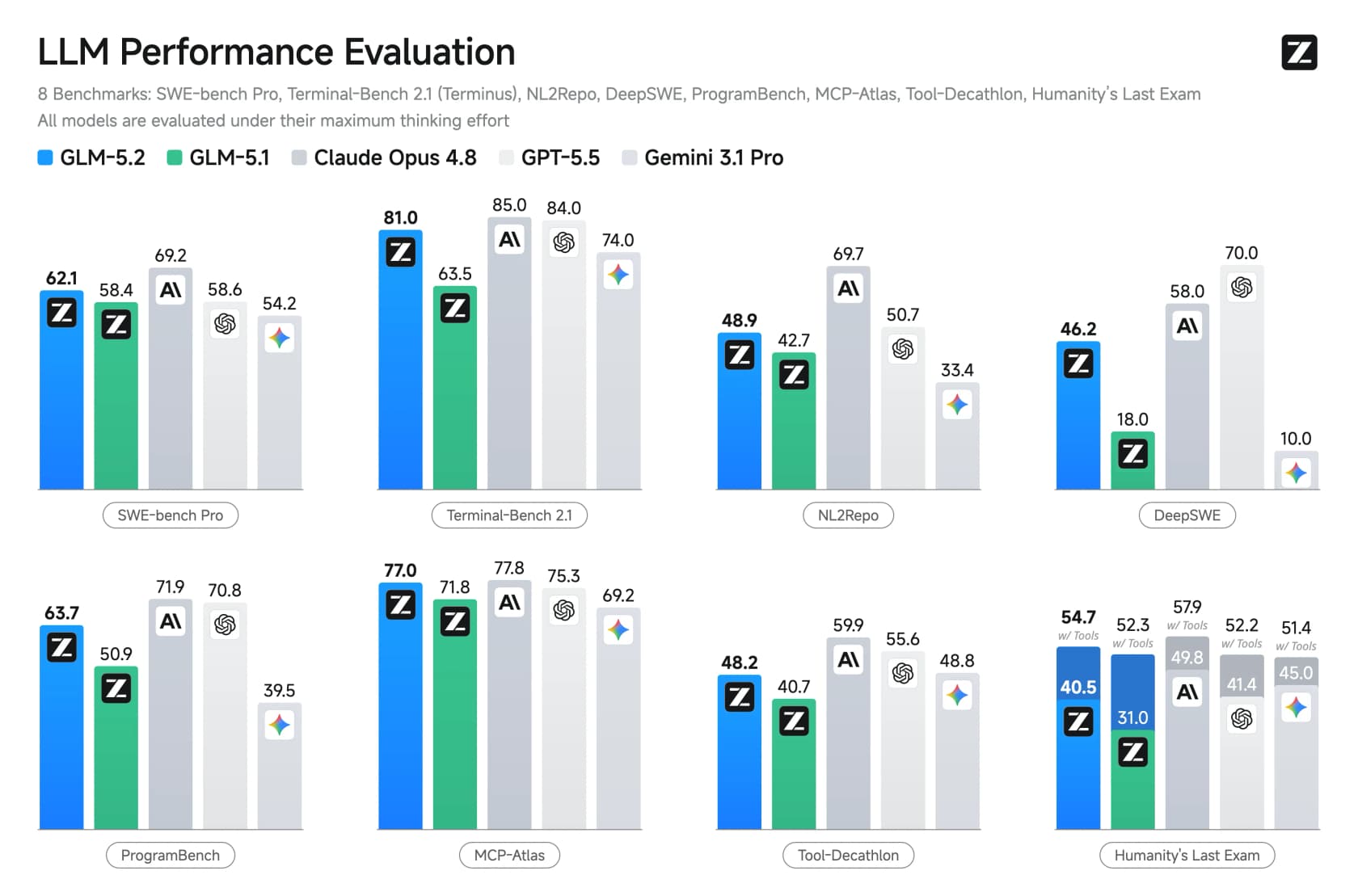
Bei der Standard-Coding-Suite erreicht GLM-5.2 62,1 bei SWE-bench Pro und 81,0 bei Terminal-Bench 2.1 – knapp hinter Opus 4.8 (85,0) und in mehreren Disziplinen vor GPT-5.5. Der Sprung von GLM-5.1 ist der Teil, der aufhorchen lassen sollte: Terminal-Bench stieg in einer Version von 63,5 auf 81,0.
Das Long-Horizon-Bild ist noch einseitiger – genau dort hat Z.ai seine Bemühungen konzentriert.
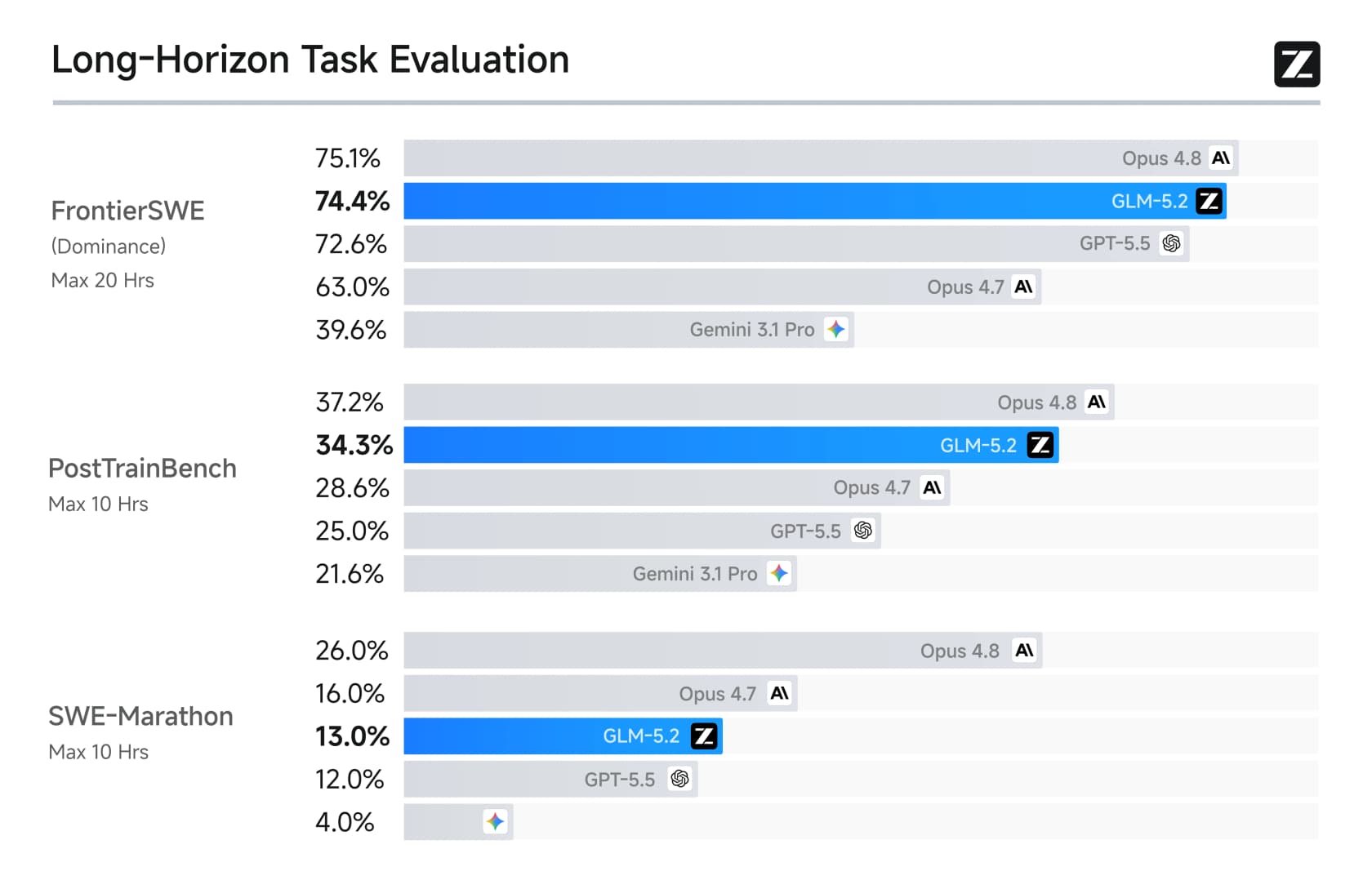
Bei FrontierSWE erreicht es 74,4 % – fast gleichauf mit Opus 4.8s 75,1 % und deutlich über GPT-5.5. Bekannte Fachleute haben es bemerkt. Jeremy Howard von fast.ai nannte es ein Meisterwerk:
„@Zai_org GLM 5.2 ist ein Meisterwerk! Es ist mindestens so gut wie Opus 4.8 und GPT... Es ist superschnell, günstig und nicht zu ausführlich. Es antwortet mit Nuancen und Urteilsvermögen und verarbeitet langen Kontext SEHR gut."
Graham Neubig, der an Coding-Agenten an der CMU arbeitet, ging noch weiter und schrieb, es sei „wahrscheinlich das erste Modell, das gut genug ist, um geschlossene Modelle vollständig aus dem Workflow zu verbannen." Das ist eine starke Aussage von jemandem, der keinen Grund hat, zu schmeicheln.
Hier ist jedoch der Vorbehalt, den ich auf den Tisch legen möchte. Die Benchmarks sind Coding-Benchmarks. Sie sagen uns, dass GLM-5.2 hervorragend darin ist, Code über lange Sitzungen zu schreiben und zu korrigieren; sie sagen uns sehr wenig darüber, wie es sich verhält, wenn es um 2 Uhr morgens einem verwirrten Kunden antwortet, wo der Fehlerfall kein fehlgeschlagener Test ist, sondern eine selbstsichere falsche Antwort, die niemand bemerkt. Mehr dazu weiter unten.
Die eigentliche Schlagzeile ist der Preis
Die Benchmarks bekommen die Aufmerksamkeit, aber der Preis ist es, der Unternehmen tatsächlich bewegt. GLM-5.2 kostet 1,40 $ pro Million Input-Token und 4,40 $ pro Million Output, gegenüber 5 $/30 $ für GPT-5.5 und 5 $/25 $ für Opus 4.8.
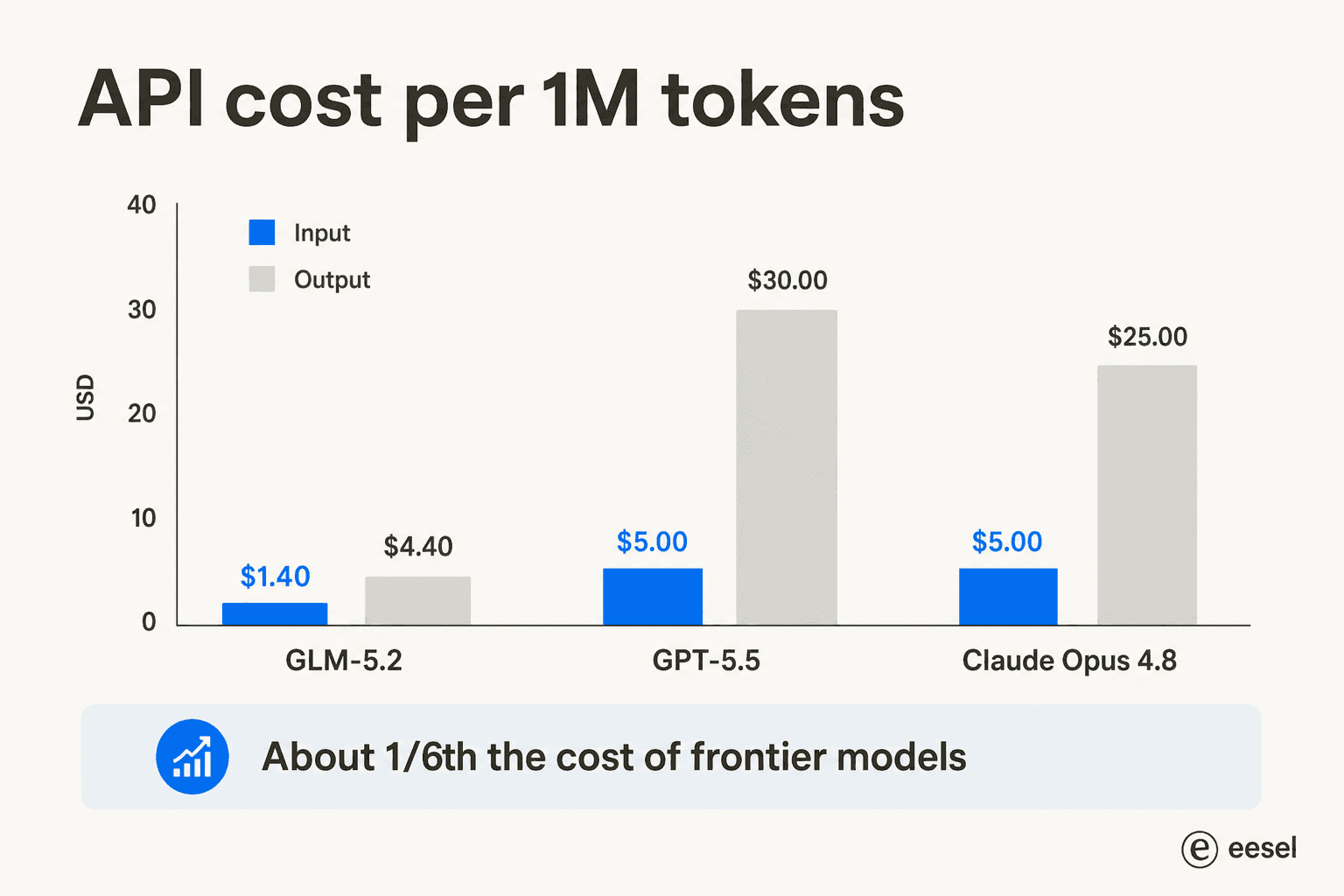
Dieser Unterschied ist die ganze Geschichte für viele Teams. Die Einschätzung auf Reddit und LinkedIn ist einheitlich: ein „billiger Frontier-Killer", den man für alltägliches Coding einsetzen kann. Nate Herkelman fasste die Stimmung in einem LinkedIn-Post zusammen: „GLM 5.2 in Claude Code bläst mir den Kopf weg (5x günstiger)."
Aber „günstig" verdient ein Sternchen, und es ist ein wichtiges für die Budgetplanung. GLM-5.2 ist ein schwerer Reasoner – es verbrennt viele Ausgabe-Token zum Nachdenken, besonders bei Max-Aufwand. Bei einer gemessenen, tokenbasierten API kann die Rechnung also schneller steigen als der Listenpreis suggeriert, wenn man den Aufwandslevel nicht im Blick behält. Der Pauschalplan existiert genau deshalb, um diese Kosten vorhersehbar zu machen – womit wir zur Zugangsfrage kommen.
Drei Möglichkeiten, GLM-5.2 für Ihr Unternehmen zu betreiben
Es gibt nicht den einen „GLM-5.2 für Unternehmen"-Weg, sondern drei – und sie passen zu sehr unterschiedlichen Teams.

| Zugangsweg | Preis | Am besten für |
|---|---|---|
| Z.ai API (Pay-per-Token) | 1,40 $ Input / 4,40 $ Output pro 1 Mio. | Integration in eigene App oder Agent; gemessene Nutzung |
| OpenRouter / Aggregatoren | ab 1,20 $ Input / 4,10 $ Output pro 1 Mio. | Gleiche Modell über geroutete Anbieter, oft etwas günstiger |
| GLM Coding Plan, Lite | 18 $/Monat (12,60 $/Monat jährlich) | Leichtes Coding in Claude Code und 20+ Tools |
| GLM Coding Plan, Pro | 72 $/Monat (50,40 $/Monat jährlich) | Tägliche Entwicklung an mittelgroßen Repos, 5x Lite-Nutzung |
| GLM Coding Plan, Max | 160 $/Monat (112 $/Monat jährlich) | Große Repos, intensive Nutzung, 20x Lite-Nutzung |
| Selbst-Hosting (Open Weights) | Kostenlos (MIT), plus Hardware | Vollständige Datenkontrolle, regulierte oder luftgetrennte Umgebungen |
Die Pay-per-Token-API ist der schnellste Weg, GLM-5.2 in das eigene Produkt zu integrieren. Sie wird sowohl mit OpenAI-kompatiblen als auch mit Anthropic-kompatiblen Endpunkten geliefert, sodass man Claude Code oder ein ähnliches Werkzeug direkt darauf ausrichten kann. Der GLM Coding Plan ist der Festpreisweg für Entwickler, die in einem Coding-Tool leben und eine vorhersehbare Monatsrechnung statt einer gemessenen bevorzugen.
Selbst-Hosting wird am meisten übertrieben dargestellt. Ja, die Gewichte sind kostenlos und MIT-lizenziert, was für regulierte Branchen tatsächlich eine große Sache ist. Aber ein 753-Milliarden-Modell betreibt man nicht auf einer freien GPU. Wie ein Entwickler auf r/LocalLLaMA es ausdrückte: der „massive 753B-Fußabdruck bedeutet, dass keiner von uns es zu Hause ohne einen Enterprise-Cluster betreiben kann." Realistisch gesehen spricht man von einem Multi-GPU-Server, also etwa Hardware im Wert von 150.000 $, bevor man Quantisierungskompromisse eingeht, die es zum Kriechen verlangsamen. Für die meisten Unternehmen bedeutet „selbst hosten" wirklich „auf einem Cloud-Anbieter hosten, dem wir vertrauen" – nicht „im Büro betreiben".
Wo GLM-5.2 passt – und wo ich vorsichtig wäre
Fügt man die Teile zusammen, ist das Bild ziemlich klar. Für interne Engineering-Arbeit ist GLM-5.2 ein klares Ja, zumindest für einen Pilotversuch: Agentic Coding, Refactoring, lange Debug-Sitzungen, automatisierte Recherche über eine große Codebasis. Die Qualität stimmt, der Preis ist ein Bruchteil der Alternativen, und wenn man kostensensibel ist, ist es schwer dagegen zu argumentieren. Wenn der Aufgabenmix einfacher ist, lohnt es sich, auch DeepSeek zu bepreisen, das für Routinearbeit noch günstiger ist.
Wo ich langsamer werden würde, ist alles Kundenseitige – und das ist der Teil, den die Benchmarks nicht abdecken.

Drei Dinge lassen mich vorsichtig sein, wenn es darum geht, ein rohes Modell – irgendein rohes Modell – auf Live-Kunden zu richten:
- Datenresidenz. GLM-5.2 ist ein Open-Weights-Modell eines in China ansässigen Labors, und Z.ai wurde 2025 auf die Entity List des US-Handelsministeriums gesetzt. Die Open Weights sind hier tatsächlich die Antwort, nicht das Problem – man kann selbst hosten oder über einen geprüften Anbieter routen, sodass Kundendaten nie die First-Party-API berühren. Aber das ist eine Entscheidung, die man bewusst treffen muss. Einige Teams bringen den Datenschutzpunkt laut vor, und sie haben Recht damit.
- Zuverlässigkeit. „Big-Model-Smell" ist real, und beeindruckende Coding-Scores bedeuten nicht, dass ein Modell nicht selbstsicher eine Rückgaberichtlinie erfinden könnte. Sicherheitsforscher Zack Korman merkte an, dass GLM-5.2 „offenbar sehr gut bei KI-Agent-Sandbox-Ausbrüchen und -Umgehungen ist" – genau das, was man wissen möchte, bevor es Tool-Zugriff auf eigene Systeme hat. Halluzinationen bei einem echten Ticket sind ein Vertrauensproblem, weshalb wir jeden Rollout mit historischen Tickets simulieren, bevor wir live gehen.
- Latenz und Kostenkontrolle. Die schwere Reasoning-Eigenschaft, die GLM-5.2 beim Coding so gut macht, macht es bei
Max-Aufwand pro Antwort langsamer und teurer – was zählt, wenn ein Kunde wartet.
Keines davon ist ein Dealbreaker. Es ist einfach der Unterschied zwischen „das Modell hat gut abgeschnitten" und „ich würde es morgen vor meine Kunden stellen." Die Lösung ist kein besseres Modell, sondern die Schicht rund um es.
GLM-5.2 (oder irgendein Modell) für Support nutzen – die eesel-Methode
Hier ist etwas, worauf ich nach Jahren des Betriebs von KI in Support-Warteschlangen immer wieder zurückkomme: Die Umgebung ist wichtiger als das Modell. Derselbe Punkt taucht in der Community auf – Menschen finden regelmäßig, dass ein weniger fähiges Modell in einem besseren Setup ein stärkeres in einem schlechteren schlägt. Was die Ergebnisse bei echten Tickets entscheidet, ist, ob die KI in Ihrer Wissensbasis verankert ist, ob Sie kontrollieren, wann sie spricht, und ob Sie sie getestet haben, bevor sie live ging. Das ist dieselbe Lektion, die einen echten KI-Support-Agenten von einem regelbasierten Chatbot unterscheidet.
Das ist, was eesel ist. Es ist eine geprüfte Schicht, die über jedem Modell sitzt, das gerade am besten ist, aus vergangenen Tickets und Hilfedokumenten lernt und nur antwortet, wenn es sicher ist – mit allem anderen, das an einen Menschen übergeben wird. Bevor irgendetwas live geht, läuft man es in einer Simulation gegen Tausende echter historischer Tickets, um genau zu sehen, wie es geantwortet hätte – damit man nicht erst in der Produktion herausfindet. Das ist der Teil, den ein roher GLM-5.2-API-Schlüssel nicht liefert, und hier liegt der größte Teil des echten Risikos – dieselbe Lücke, die bei KI im Support über Build versus Buy entscheidet.

Mein ehrliches Fazit: Seien Sie von GLM-5.2 für Ihre Ingenieure begeistert und testen Sie es diese Woche für Coding. Für die kundenseitigen Dinge lassen Sie das Modell ein austauschbares Teil sein und investieren Sie Ihre Energie in die Schicht, die es sicher macht, es einzusetzen. Sie können eesel kostenlos ausprobieren und es auf Ihren eigenen Tickets simulieren, bevor Sie einen Cent ausgeben – das ist die einzige Weise, wie ich je beurteilen würde, ob ein Modell für Ihr Unternehmen bereit ist. Wenn Sie die umfassenderen Kosten des KI-Supports abwägen, ist das die Zahl, die wirklich zählt.
Häufig gestellte Fragen
Ist GLM-5.2 gut genug für den Unternehmenseinsatz?
Wie viel kostet GLM-5.2 für Unternehmen?
Ist GLM-5.2 sicher für Unternehmensdaten?
Kann ich GLM-5.2 für den Kundensupport verwenden?
Ist GLM-5.2 besser als DeepSeek oder GPT-5.5 für Unternehmen?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.