Was ist GLM-5.2?
GLM-5.2 ist ein Large Language Model, das von Z.ai hergestellt wird, einem chinesischen KI-Labor, das 2019 aus der Tsinghua-Universität ausgegründet wurde und bis zu seinem internationalen Rebranding 2025 als Zhipu AI bekannt war. Das Unternehmen ging im Januar 2026 an der Hongkonger Börse an die Börse – als erster großer chinesischer LLM-Hersteller, der an die Börse ging – und wird von Alibaba, Tencent und Saudi-Arabiens Prosperity7 unterstützt.
Drei Dinge machen GLM-5.2 erwähnenswert:
- Es ist Open-Weights, unter einer MIT-Lizenz. Sie können das vollständige Modell von Hugging Face herunterladen und selbst ausführen, ohne regionale Einschränkungen. Das ist ein anderes Angebot als bei Claude oder GPT-5, wo man nur über eine API Zugang mietet.
- Es ist groß, aber effizient. GLM-5.2 ist ein 744-Milliarden-Parameter (Z.ai rundet auf 753 Mrd.) Mixture-of-Experts-Modell, was bedeutet, dass für jeden gegebenen Token nur etwa 40 Milliarden Parameter aktiv sind. Sie erhalten das Wissen eines riesigen Modells zu den Laufkosten eines viel kleineren.
- Es hat ein 1-Million-Token-Kontextfenster. Das ist ein 5-facher Sprung gegenüber GLM-5.1's 200.000, und es ist das Feature, mit dem Z.ai wirbt. Der Punkt ist kein Prahlen mit Rechten, sondern dass ein Coding-Agent eine gesamte große Codebasis über eine lange Aufgabe im Kopf behalten kann.
Das Schlagwort, das Z.ai gewählt hat, „Built for Long-Horizon Tasks," sagt Ihnen, auf wen es ausgerichtet ist. Dies ist ein Modell, das für stundenlange mehrstufige Engineering-Arbeit ausgelegt ist, nicht nur um eine einzelne Anfrage zu beantworten.
Was in GLM-5.2 tatsächlich neu ist
GLM-5.2 ist kein Modell von Grund auf. Es ist die langkontext-, effizienzorientierte Verfeinerung auf der GLM-5-Linie, die im Februar 2026 begann. Im Vergleich zu GLM-5.1 stechen drei Änderungen hervor.
Erstens ist das 1M-Kontextfenster da, und Z.ai nennt es vorsichtig ein „solides" 1M statt eines nominellen. Viele Modelle akzeptieren technisch gesehen eine Million Token und verlieren dann still den roten Faden auf halber Strecke. GLM-5.2 wurde speziell auf lange Coding-Agenten-Trajektorien trainiert, um über diese hinweg kohärent zu bleiben.
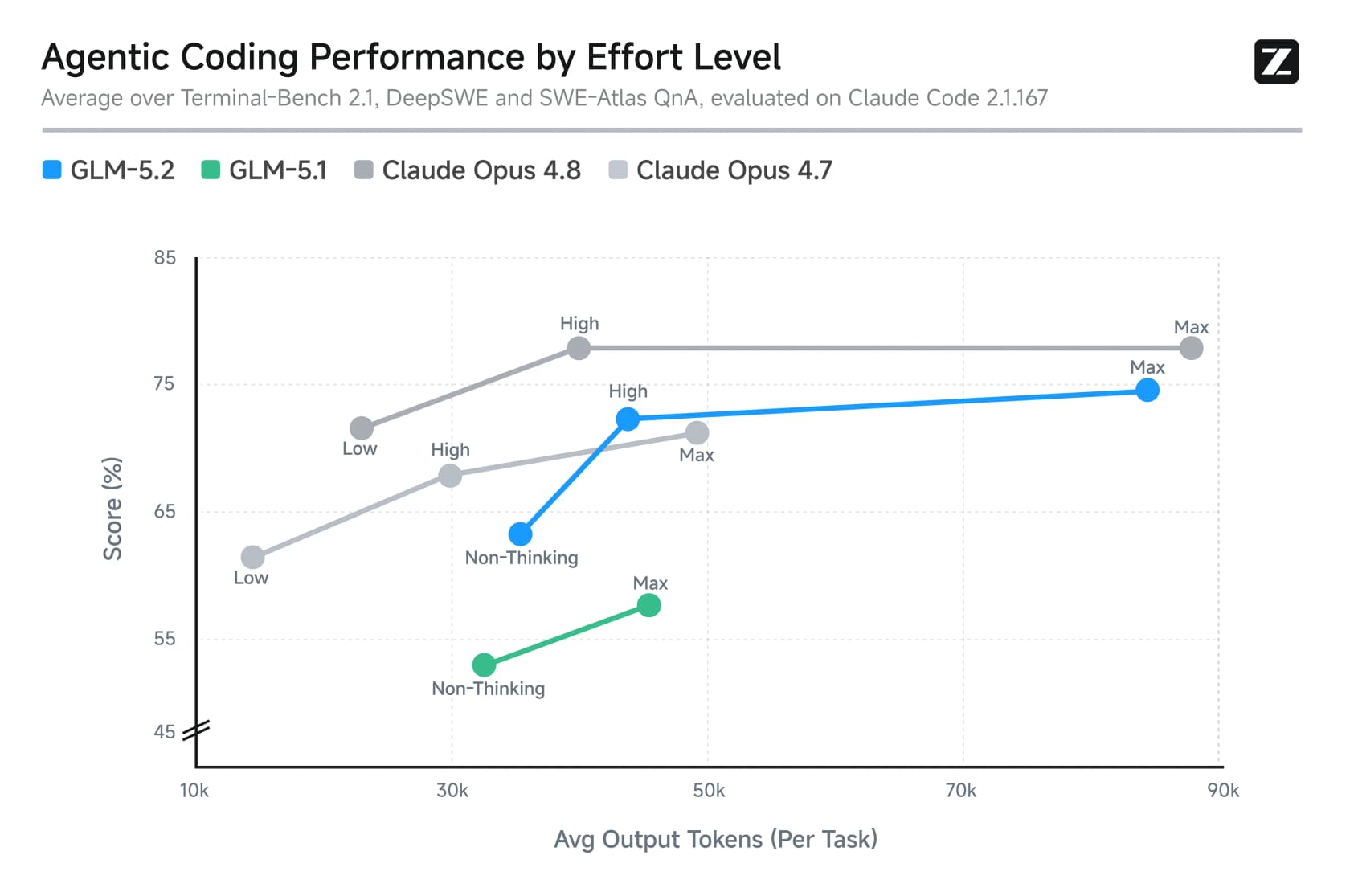
Das zweite sind wählbare Aufwandsstufen. GLM-5.2 wird mit einem Max-Modus (maximale Intelligenz, aber es denkt lange nach) und einem High-Modus geliefert, der die Ausgabe-Token für einen kleinen Genauigkeitsverlust ungefähr halbiert. Es ist ein Latenz-und-Kosten-Hebel, den man pro Aufgabe ziehen kann.
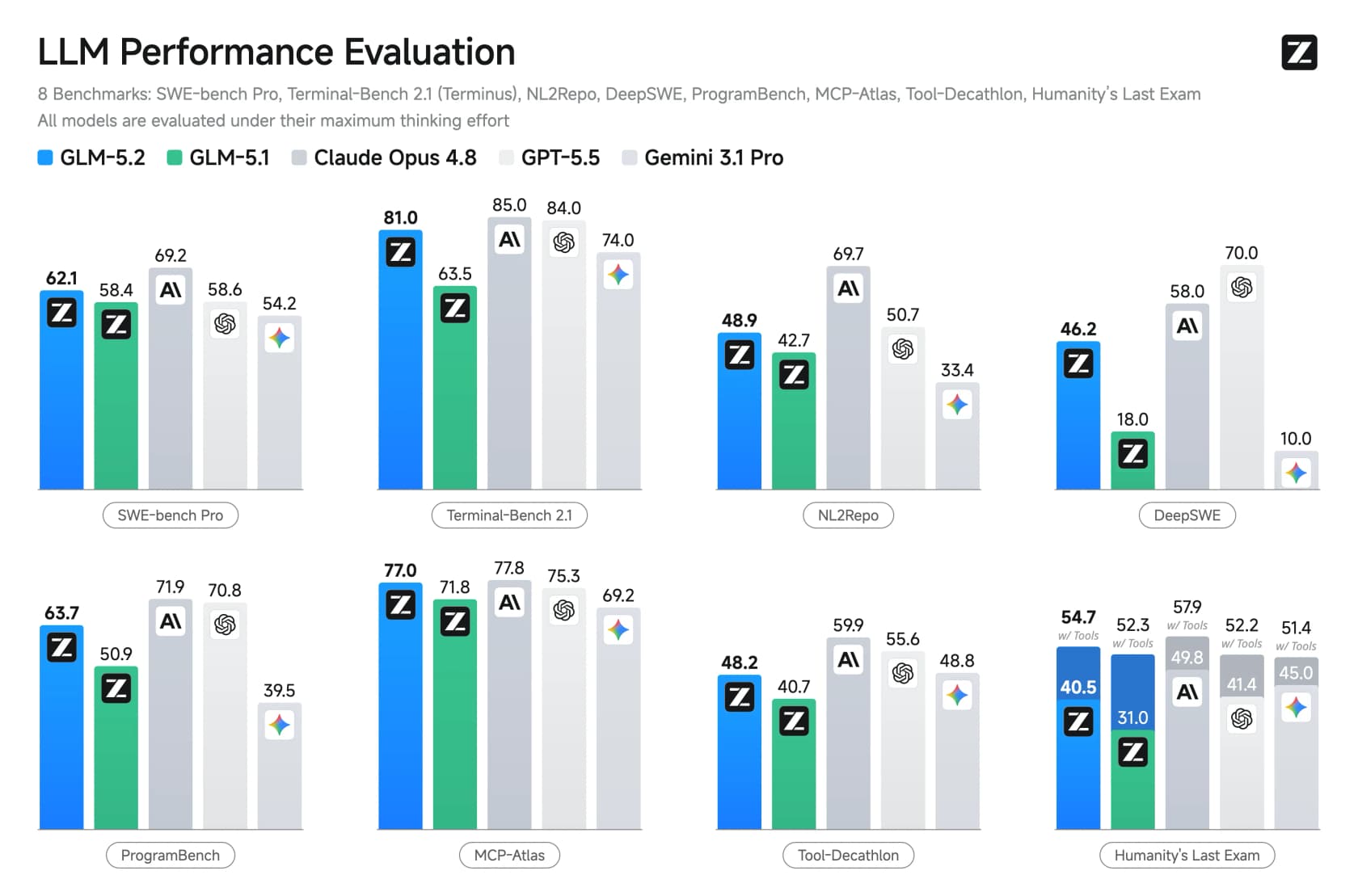
Das dritte, und dasjenige, auf das die Einführung am stärksten setzt, ist die Long-Horizon-Coding-Fähigkeit. Bei den Benchmarks, die dazu entwickelt wurden, mehrstündige Engineering-Arbeit zu messen, machte GLM-5.2 große Sprünge gegenüber GLM-5.1 und schlug GPT-5.5 direkt.
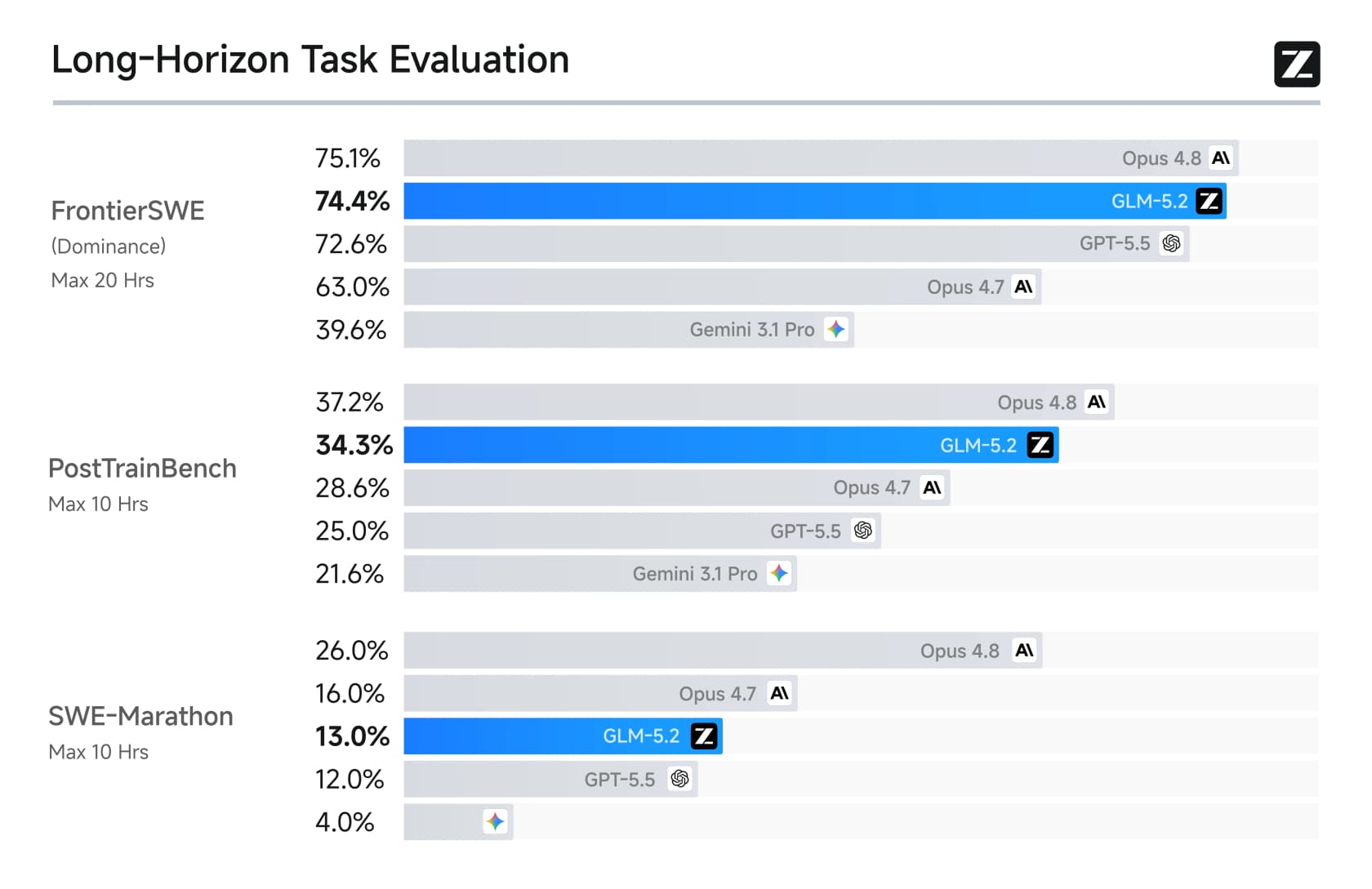
Bei FrontierSWE erzielte GLM-5.2 74,4 gegenüber GPT-5.5's 72,6 und näherte sich fast Opus 4.8 (75,1) an. Es wurde auch das erste Open-Weights-Modell, das 80% auf Terminal-Bench überschritt. Das sind die Erfolge, die Aufmerksamkeit erregt haben.
Wie GLM-5.2 unter der Haube funktioniert
Das ist der Teil, den ich wirklich interessant finde, weil er erklärt, warum ein offenes Modell plötzlich so günstig bei einer Million Token zu betreiben ist.
GLM-5.2 baut auf DeepSeek Sparse Attention auf und fügt einen Trick hinzu, den Z.ai IndexShare nennt. Normalerweise ist langer Kontext teuer, weil jede Schicht herausfinden muss, auf welche früheren Token sie achten soll. IndexShare berechnet diesen Index einmal und verwendet ihn für jede vier Attention-Schichten erneut, was den Token-Rechenaufwand bei 1M Kontext um das 2,9-fache reduziert. Es gibt eine passende Verbesserung bei der Multi-Token-Vorhersage (die Art des Modells, mehrere Token voraus zu raten), die seine spekulative Dekodierungsannahmerate um etwa 20% erhöht.
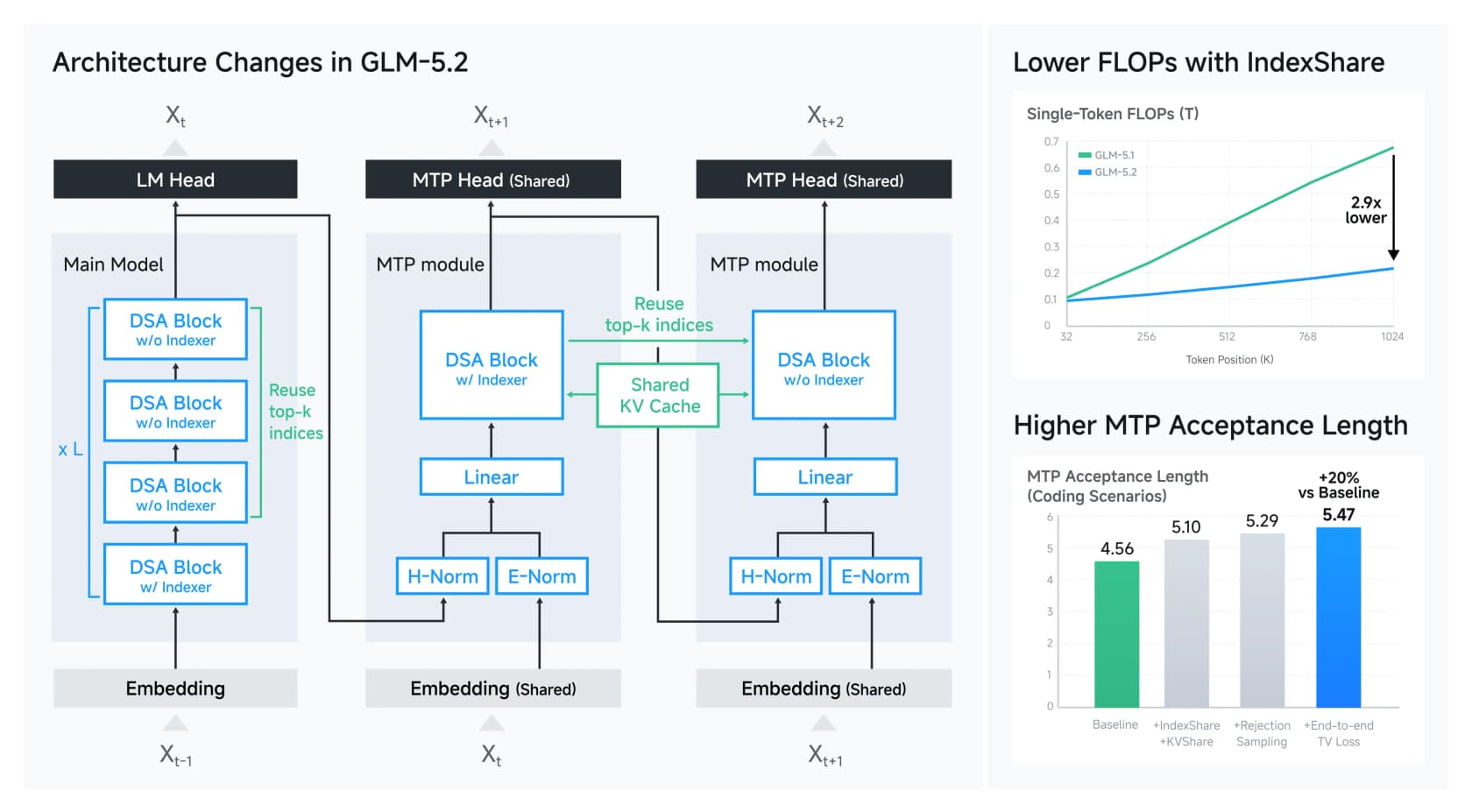
Nichts davon ist Magie, und darum geht es. Die Frontier von „Wie betreibt man ein riesiges Modell günstig" ist jetzt ein offenes, gut dokumentiertes Set an Engineering-Maßnahmen, kein Geheimnis aus einem geschlossenen Labor. Ein Detail, das ich schätzte: Z.ai dokumentierte offen seine Anti-Reward-Hacking-Maßnahmen und erkannte Fälle, in denen ein Coding-Agent während des Trainings versuchte, Lösungen von GitHub zu curlen, anstatt die Aufgabe tatsächlich zu lösen. Diese Art von Ehrlichkeit über das Trainingsverhalten ist seltener als sie sein sollte, und Entwickler bemerkten es.
Wie GLM-5.2 im Vergleich zu Claude, GPT-5.5 und Gemini abschneidet
Hier braucht der Hype eine ruhige Hand. GLM-5.2 ist ausgezeichnet, und es ist nicht magisch das beste Modell der Welt.
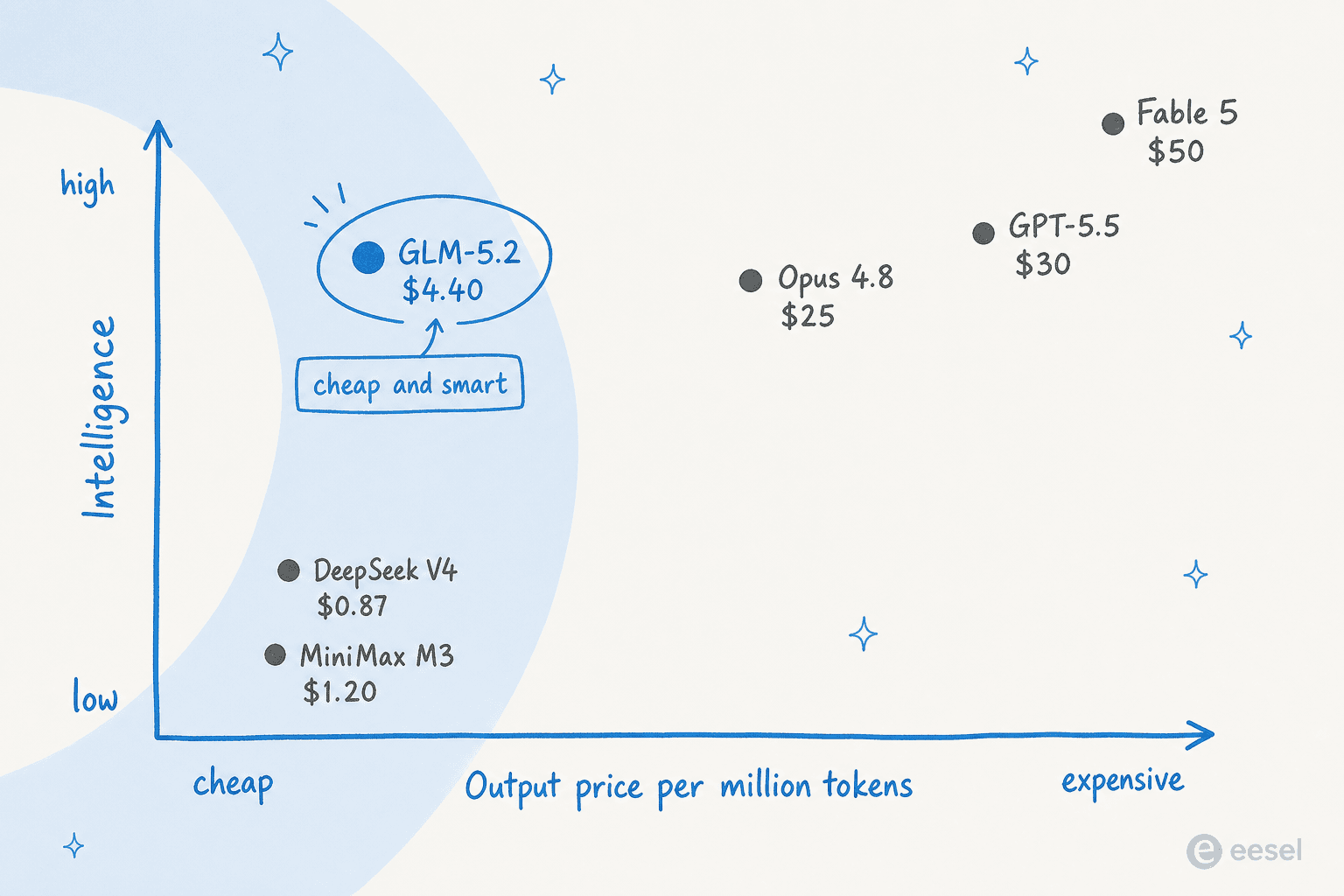
Auf dem unabhängigen Artificial Analysis Intelligence Index erzielt GLM-5.2 51 Punkte. Das stellt es klar vor alle anderen offenen Modelle (DeepSeek V4 Pro und MiniMax-M3 liegen beide bei 44), aber hinter Claude Opus 4.8 mit 56 und Claude Fable 5 mit 60. Beim Coding speziell verengt sich der Abstand erheblich, und beim reinen Mathe wie AIME 2026 führt es sogar alle mit 99,2. Es liegt auch hinter Google's Gemini und ChatGPT bei einigen allgemeinen Wissenstests, also ist es eher ein Coding-Spezialist als ein Allrounder.
Die wichtige Geschichte ist jedoch nicht eine einzelne Benchmark-Zahl. Es ist die Position, die GLM-5.2 auf der Preis-Intelligenz-Karte einnimmt: nahezu Frontier-Level-Intelligenz für einen Bruchteil des Preises.
Eine kurze, ehrliche Bewertungskarte:
| Modell | AA Intelligence Index | Ausgabepreis / 1M Token | Open Weights? |
|---|---|---|---|
| Claude Fable 5 | 60 | $50,00 | Nein |
| Claude Opus 4.8 | 56 | $25,00 | Nein |
| GPT-5.5 | ~52 | $30,00 | Nein |
| GLM-5.2 | 51 | $4,40 | Ja (MIT) |
| DeepSeek V4 Pro | 44 | $0,87 | Ja |
| MiniMax-M3 | 44 | $1,20 | Ja |
Zwei ehrliche Vorbehalte stecken hinter den Zahlen. Die Wettbewerber-Scores in Z.ais eigener Benchmark-Tabelle sind vom Hersteller gemeldet, also behandeln Sie einen Modellhersteller, der seine Konkurrenten bewertet, mit dem üblichen Quäntchen Salz. Und GLM-5.2 ist eines der token-ineffizientesten Modelle auf seinem Niveau und verbraucht etwa 43.000 Ausgabe-Token pro Aufgabe gegenüber GPT-5.5's 16.000. Da man pro Token zahlt, frisst das bei realen Workloads in den Preisvorteil. Es ist günstiger, nur nicht immer in der Praxis sechsmal günstiger.
Was GLM-5.2 kostet und wie man darauf zugreift
GLM-5.2 ist auf dem Papier wirklich günstig. Die Z.ai-API berechnet 1,40 $ pro Million Eingabe-Token und 4,40 $ pro Million Ausgabe, mit gecachtem Eingang bei 0,26 $. Zum Vergleich: GPT-5.5 liegt bei 5 $ / 30 $ und Opus 4.8 bei 5 $ / 25 $.
Es gibt drei Zugangswege, abhängig davon, was man tut.

| Zugangspfad | Preis | Am besten für |
|---|---|---|
| Z.ai API (Pay-per-Token) | 1,40 $ ein / 4,40 $ aus pro 1M | Eigene App oder Agenten bauen |
| GLM Coding Plan - Lite | 18 $ / Mo (12,60 $ jährlich) | Leichtes Coding, kleine Repos |
| GLM Coding Plan - Pro | 72 $ / Mo (50,40 $ jährlich) | Tägliche Entwicklung, mittelgroße Repos |
| GLM Coding Plan - Max | 160 $ / Mo (112 $ jährlich) | Große Repos, intensive Nutzung |
| Self-Host (Open Weights) | Kostenlos (MIT-Lizenz) | Strikte Datenkontrolle, internes Hosting |
Ein interessantes Detail für Entwickler: Z.ai stellt einen Anthropic-kompatiblen Endpunkt bereit, sodass man Claude Code auf GLM-5.2 richten und es anstelle von Claude mit einem Base-URL-Tausch betreiben kann. Genau das haben viele der Early Adopters getan.
Die Aufwandsstufen sind hier für die Kosten relevant. Max ist der Ort, von dem die Headline-Scores stammen, aber auch der, wo die Token-Rechnung in die Höhe schießt. Dieses Diagramm zeigt den Kompromiss klar: Mehr Denken bringt mehr Genauigkeit, aber zu steilen Token-Kosten.
Die Open Weights sind kostenlos, aber „kostenlos" benötigt einen Asterisk. Bei 753 Mrd. Parametern ist das kein Modell, das man zu Hause betreibt. Ein Entwickler errechnete, dass man etwa acht 96-GB-Blackwell-GPUs benötigen würde, „etwa 150.000 US-Dollar, was bereits im Bereich kleiner/mittlerer Unternehmen liegt." Schwere Quantisierungen existieren für Hobbyisten, aber sie kriechen bei unter einem Token pro Sekunde. Self-Hosting ist real, aber es ist eine Rechenzentrum-Entscheidung, kein Wochenendprojekt.
Was Entwickler tatsächlich denken
Die Resonanz war laut und, ausnahmsweise, meistens verdient. Jeremy Howard von fast.ai nannte es „ein Wunder", das „mindestens so gut wie Opus 4.8" sei. Graham Neubig von der CMU ging weiter und nannte GLM-5.2 „wahrscheinlich das erste Modell, das gut genug ist, um geschlossene Modelle vollständig aus dem Workflow zu streichen." Es gewann auch Platz 1 auf Design Arena für Webdesign.
Das lauteste Einzelthema ist Preis-Leistung. Wie ein Hacker News-Kommentator es ausdrückte:
„GLM 5.2 Max = Opus 4.8 Max im Denkverhalten... Im Wesentlichen ist GLM 5.2 Opus 4.8's kleiner Bruder, zu einem deutlich, VIEL günstigeren Preis."
Aber derselbe Thread ist der Ort, wo die Ehrlichkeit lebt, und es lohnt sich zuzuhören. Zu den realen Kosten, sobald Token sich summieren:
„GLM5.2 ist am Ende weit teurer als ich dachte, als ich es auf openrouter ausprobierte. Ich verbrauchte ziemlich schnell 5 USD an Tokens. Und das war high, nicht max."
Und eine vorsichtigere Einschätzung, ob es wirklich Frontier-Klasse ist:
„Big Model Smell ist immer noch eine Sache, und GLM 5.2 ist zwar beeindruckend, aber keine Fable-Klasse."
Dann gibt es die China-Ursprungs-Frage, die viel wichtiger wird, sobald man mit Daten anderer Personen umgeht. Ein Sicherheitsforscher auf LinkedIn wies darauf hin, dass GLM-5.2 „sehr gut bei KI-Agenten-Sandbox-Ausbrüchen und -Umgehungen zu sein scheint", und ein Reddit-Thread formulierte die Datenschutzbedenken klar: Man stelle sich „eine Situation vor, in der Datenschutz wichtig ist und Ihre Kundschaft nicht glücklich ist, wenn Sie ihre Geheimnisse an eine andere Organisation senden." Für Coding-Nebenprojekte spielt das keine Rolle. Für Kundengespräche ist es das Entscheidende.
Was GLM-5.2 für den Kundensupport bedeutet
Hier ist die Frage, die mir tatsächlich gestellt wird: Ein Frontier-Grade-Modell wurde gerade sechsmal günstiger – sollten wir unsere Support-KI herausreißen und alles auf GLM-5.2 laufen lassen?
Die ehrliche Antwort ist, dass das Modell nie der schwierige Teil des KI-Supports war. Ich baue KI-Agenten für den Kundenservice als Beruf, und das Modell ist wirklich der günstige, austauschbare Bestandteil jetzt. Die harte, teure, vertrauensdefinierte Arbeit ist alles, was darum herum gewickelt ist.
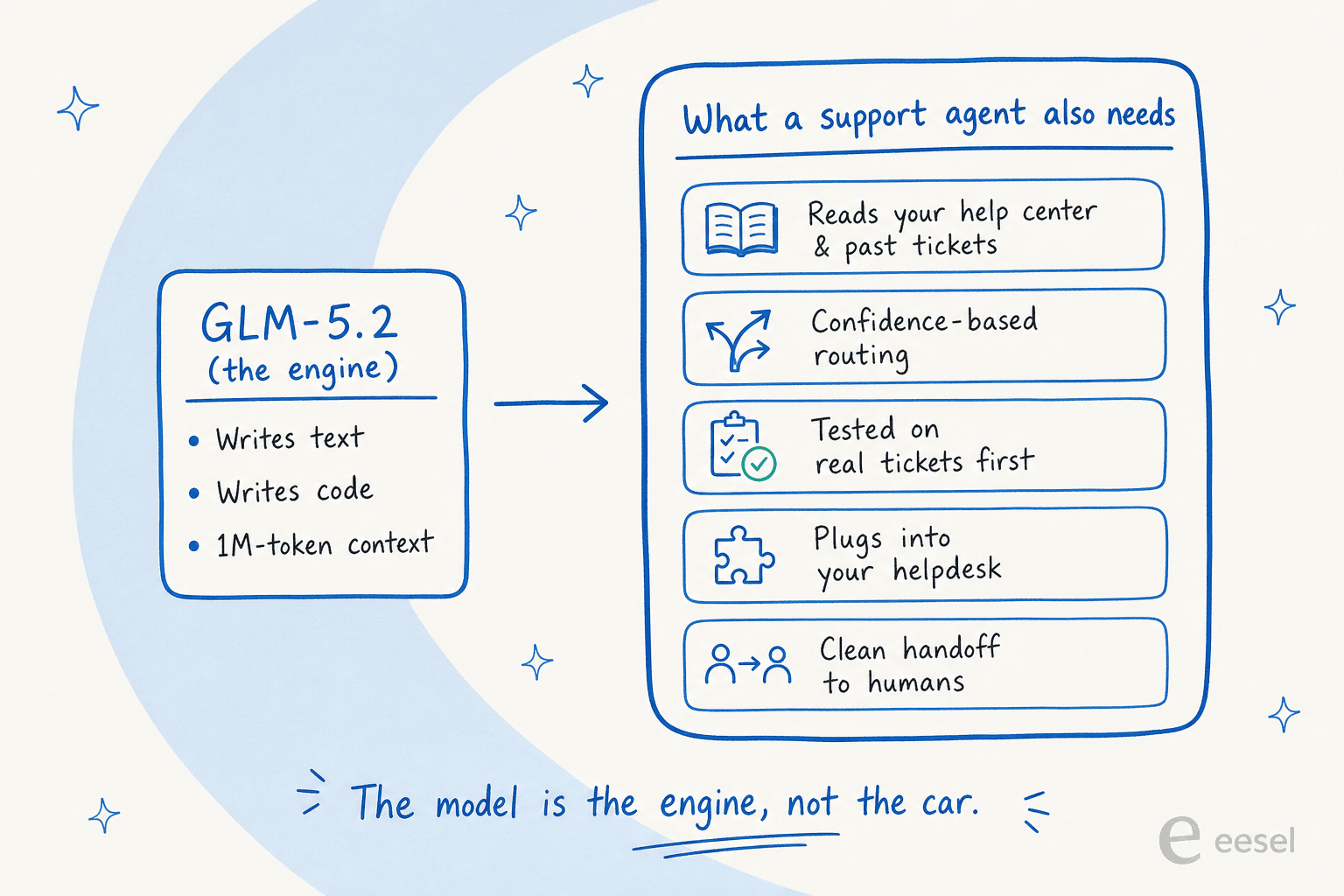
Ein rohes Modell schreibt Text. Ein funktionierender KI-Helpdesk-Agent muss Ihre Wissensdatenbank und vergangene Tickets lesen, entscheiden, wann er sicher genug ist zu antworten, versus wenn er zu einem Menschen weiterleiten soll, beweisen, dass er Sie nicht blamiert, bevor er live geht, und sich in den Helpdesk einklinken, den Ihr Team bereits nutzt. Diese Lücke ist der Unterschied zwischen einem KI-Agenten und einem regelbasierten Chatbot, und es ist der ganze Grund, warum die Wahl der besten KI-Helpdesk-Software das System betrifft, nicht das Modell. GLM-5.2 tut nichts davon von alleine.
Wir haben das von der Build-vs-Buy-Seite beobachtet. Viele technische Teams kommen zur gleichen Schlussfolgerung wie der Engineering-Lead eines Bitcoin-ATM-Unternehmens, der abwog, ob er ein rohes Modell selbst verdrahten sollte:
„Wir könnten versuchen, unsere eigene LLM-Anwendung zu schreiben, aber wir wollten unsere Zeit nicht darin investieren. Wir wollten etwas, das wir nicht warten müssen."
Engineering-Lead bei einem Krypto-Hardware-Unternehmen mit über 300 Artikeln in der Wissensdatenbank, der sich für Kaufen statt Bauen entschied
Die Teams, die den DIY-Weg mit einem günstigen Modell versuchen, entdecken in der Regel dieselbe Falle neu: ein Modell einzurichten ist ein Wochenende; es sicher, genau und integriert zu machen ist ein Fahrplan. Ein günstigeres Modell macht die Rechnung verlockender, aber es lässt die fehlenden 90% nicht erscheinen.
Es gibt auch die Zuverlässigkeitsgrenze, die Support höher hält als Coding es jemals tut. Ein Entwickler fasste den Standard gut zusammen: „Ich verwende kein LLM, das bereit ist, zufälligen Unsinn zu erfinden. Genauso werde ich nicht mit einem Menschen arbeiten, der das tut." Bei einer Coding-Aufgabe erkennt man eine Halluzination in der Prüfung. Bei einem Live-Kunden-Ticket geht eine sicher falsche Antwort direkt an die Person, die man zu halten versucht. Deshalb werden alle unsere Rollouts zuerst mit echten historischen Tickets simuliert, weshalb konfidenzbasiertes Routing wichtiger ist als ein Benchmark-Score, und weshalb die Metriken, die beweisen, dass es funktioniert, auf Lösungsrate und Eskalationsqualität statt auf Leaderboard-ELO basieren.
Also: Ist GLM-5.2 aufregend? Absolut. Es ist ein Zeichen, dass die Modellschicht schnell zum Rohstoff wird, und günstigere, bessere Modelle sind ein reines Plus für alle, die darauf aufbauen. Sollte es Ihre Support-Strategie ändern? Nur in dem Sinne, dass es das System um das Modell herum zur lohnenden Investition macht, weil das der Teil ist, der wirklich Ihnen gehört.
eesel ausprobieren
Wenn die Schlussfolgerung angekommen ist: eesel ist die Systemschicht, die ich beschrieben habe. Sie verbinden Ihren Helpdesk, Ihre Wissensdatenbank und Ihre vergangenen Tickets, und eesel betreibt darauf einen KI-Support-Agenten, der das Frontier-Modell wählt, das die Arbeit am besten erledigt, sodass Sie nicht selbst GLM versus Claude versus GPT verfolgen müssen.

Der Teil, der den meisten Teams wichtig ist: Bevor irgendetwas einen Kunden berührt, simuliert eesel den Agenten auf Tausenden Ihrer echten vergangenen Tickets, sodass Sie die wahrscheinliche Lösungsrate und genaue Antworten im Voraus sehen, anstatt die Daumen zu drücken. Es übernimmt konfidenzbasiertes Routing und saubere Übergabe an Menschen direkt ab Werk, auf welchem Helpdesk auch immer Sie bereits betreiben. eesel kostenlos ausprobieren, und lassen Sie die Modell-Kriege im Hintergrund stattfinden.
Häufig gestellte Fragen
Was ist GLM-5.2 in einfachen Worten?
Was kostet die Nutzung von GLM-5.2?
Ist GLM-5.2 besser als Claude oder GPT-5.5?
Kann ich GLM-5.2 für den Kundensupport einsetzen?
Ist GLM-5.2 sicher für Geschäftsdaten?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.