Was genau ist Sakana Fugu?
Sakana AI ist ein Tokioter Frontier-Labor, das 2023 von drei ehemaligen Google-Forschern gegründet wurde: CEO David Ha, CTO Llion Jones (einer der acht Co-Autoren des ursprünglichen „Attention Is All You Need" Transformer-Papers) und COO Ren Ito. Im November 2025 erhielt es eine $135M Series-B-Finanzierung bei einer Bewertung von $2,65 Mrd., was es zu einem der wertvollsten KI-Startups Japans macht.
Der Name ist bedeutsam. „Sakana" (魚) bedeutet Fisch und verweist auf die Wette des Labors, dass die Zukunft der KI weniger wie ein einziges riesiges Gehirn aussieht, sondern eher wie ein koordinierter Schwarm kleinerer Spezialisten. Fugu (benannt nach dem Kugelfisch) ist diese These als Produkt. Sakana vermarktet es als „One Model to Command Them All": Frontier-Niveau ohne Abhängigkeit von einem einzelnen Anbieter.
So lässt es sich am besten veranschaulichen: Fugu ist selbst ein Modell, aber anstatt die endgültige Antwort allein zu generieren, stellt es dynamisch ein Team aus einem Pool anderer leistungsstarker Modelle zusammen und koordiniert dieses. Das gesamte System wird Ihnen als ein einziges Modell hinter einer einzigen API präsentiert. Wenn Sie unsere Erklärung zu KI-Agenten vs. Chatbots gelesen haben: Fugu ist die Agenten-Idee auf ihre logische Extremform gebracht – die „Werkzeuge" des Agenten sind andere Frontier-Modelle.
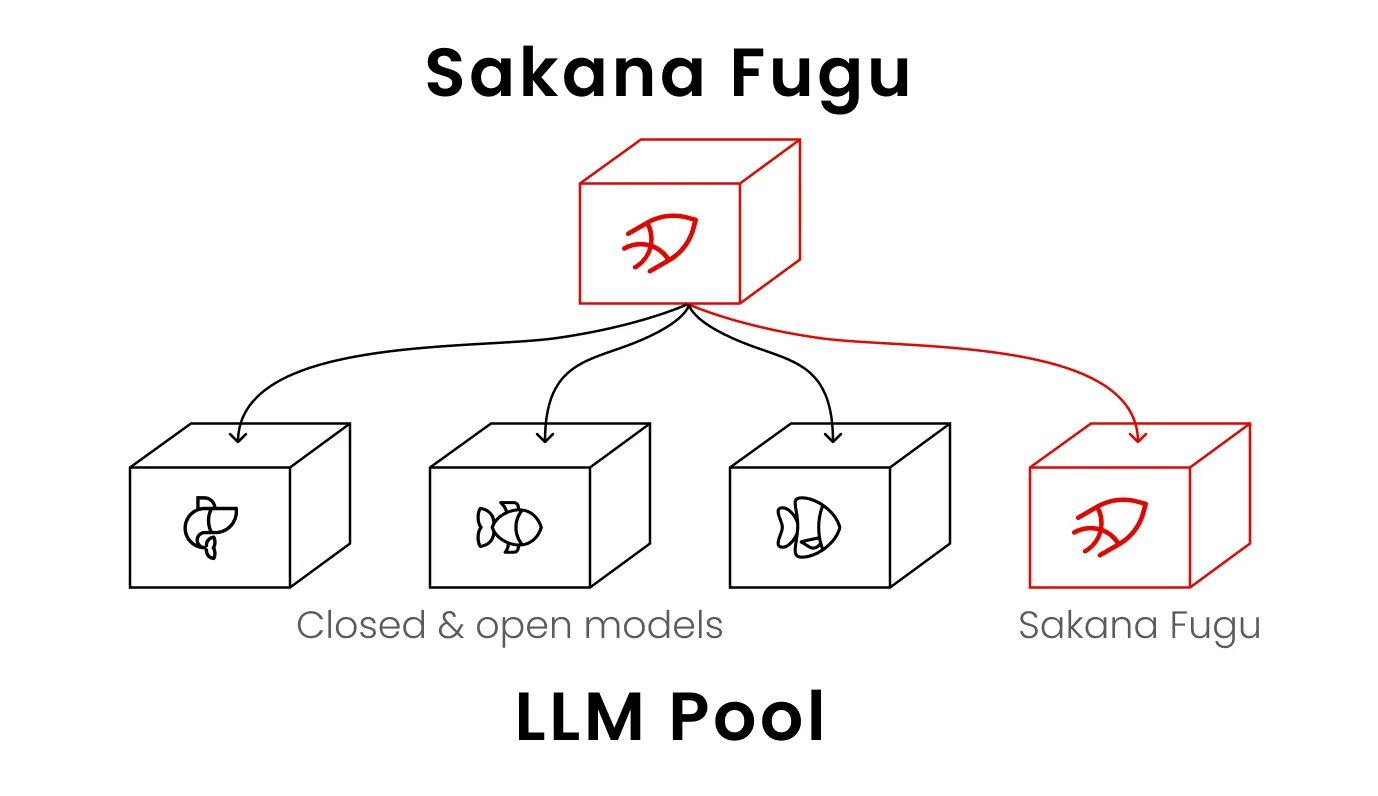
Ein wichtiges Detail, das viele übersehen: Fable 5 und Mythos Preview sind nicht in Fugus Pool enthalten, da sie nicht öffentlich zugänglich sind. Fugu orchestriert nur Modelle, die es tatsächlich aufrufen kann. Wenn Sakana also behauptet, Fugu entspreche Fable 5, bedeutet das, dass ein koordiniertes Team anderer öffentlicher Modelle das Frontier-Niveau erreichen kann – eine interessantere Behauptung, als sie zunächst wirkt.
Wie Fugu unter der Haube wirklich funktioniert
Hier verdient sich Fugu die Verteidigung „nicht nur ein Router". Es basiert auf zwei ICLR-2026-Papers zur erlernten Modell-Orchestrierung, und der Mechanismus ist aufwendiger als das bloße Auswählen eines Modells und Weiterleiten der Anfrage.
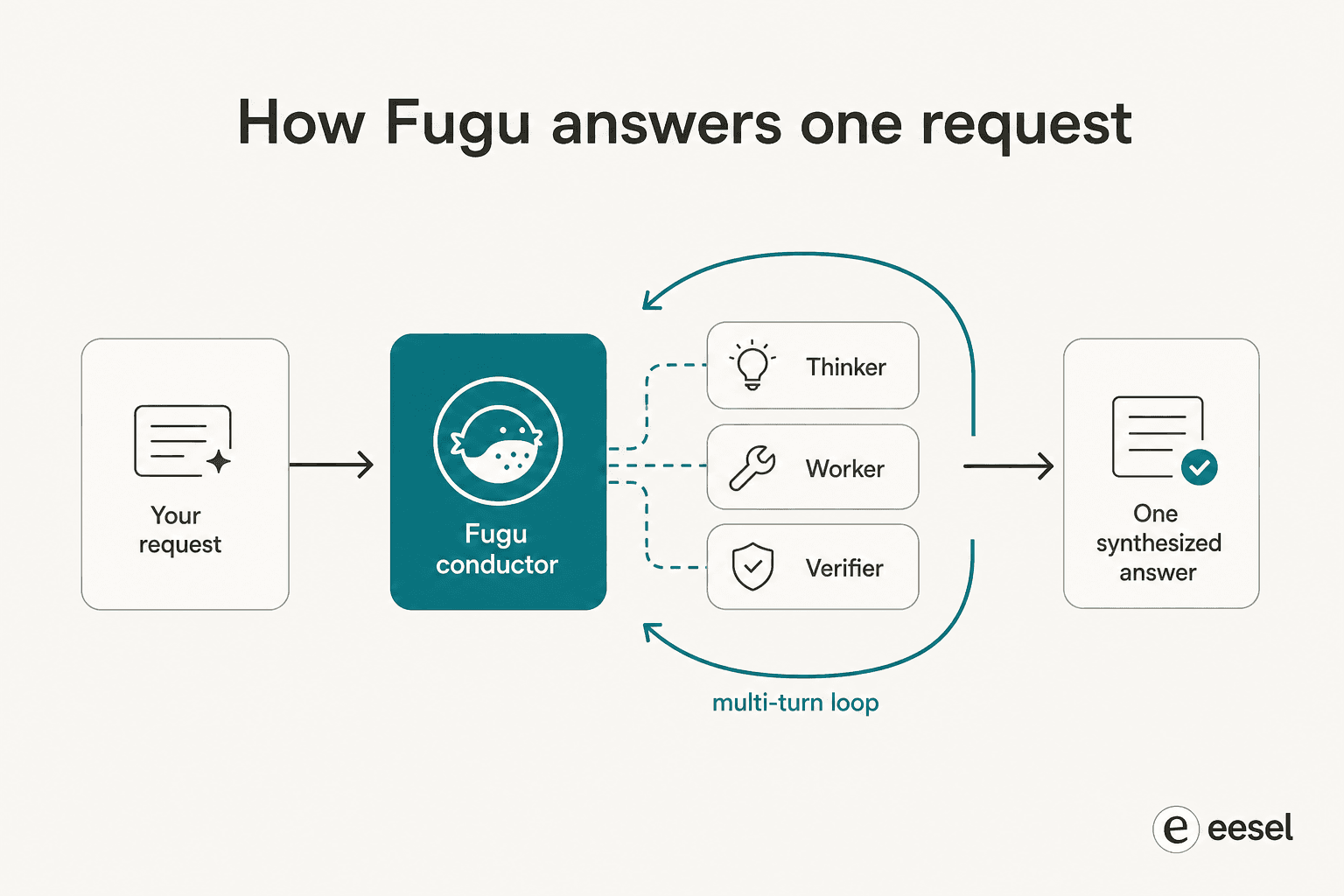
Das erste Paper, TRINITY, verwendet einen leichtgewichtigen, evolvierten Koordinator, der mehrere Modelle über mehrere Runden orchestriert, jedem eine Thinker-, Worker- oder Verifier-Rolle zuweist und die Aufgaben neu delegiert, während sich die Aufgabe entfaltet. Das zweite, der Conductor, wird mit Reinforcement Learning trainiert, um natürlichsprachliche Koordinationsstrategien zu entdecken – im Wesentlichen lernt es, fokussierte Prompts zu schreiben und die Kommunikation der Modelle so zu gestalten, dass der Pool jedes einzelne Mitglied übertrifft.
Die zwei wichtigsten Begriffe sind erlernt und mehrstufig. Fugu folgt keinem menschlich konzipierten Skript „zuerst Modell A, dann Modell B". Es hat durch Evolution und RL nicht offensichtliche Kollaborationsmuster entdeckt und führt Schleifen aus – es überprüft und leitet neu weiter, statt einen einzigen Durchlauf zu machen. Deshalb berichten frühe Nutzer, dass es stundenlang an einer einzelnen Aufgabe arbeitet: 123 Experimente über etwa 14 Stunden bei einem ML-Forschungsproblem oder fast vier Stunden beim autonomen Reproduzieren eines Papers. Es verhält sich sehr ähnlich wie der Agenten-Loop, über den wir beim Aufbau von Support-Automatisierungen diskutieren – nur auf Frontier-Modelle statt auf Tools gerichtet.
Ein jetzt zu erwähnendes Trade-off: Das Routing ist proprietär und bewusst intransparent. Sie können nicht sehen, welches zugrunde liegende Modell eine bestimmte Anfrage beantwortet hat. Für manche Teams ist das akzeptabel; für alle mit Compliance-Anforderungen ist diese Blackbox-vor-Blackbox-Struktur ein echter Faktor.
Fugu vs. Fugu Ultra: Was ist was?
Fugu wird als zwei Modelle geliefert, beide erreichbar über dieselbe OpenAI-kompatible API, sodass Sie zwischen ihnen wechseln können, ohne Ihre Integration anfassen zu müssen. Der Unterschied liegt darin, wie viele Expertenagenten koordiniert werden – das ist der Hebel zwischen Geschwindigkeit und Qualität.
| Fugu | Fugu Ultra | |
|---|---|---|
| Optimiert für | Ausgewogene Leistung und Latenz | Maximale Antwortqualität |
| Agenten-Pool | Koordiniert einen Pool; Modelle können deaktiviert werden | Tieferer, fester Pool; kein Deaktivieren |
| Am besten für | Alltägliches Coding, Code-Review, Chatbots | Schwierige, hochriskante, mehrstufige Probleme |
| Trade-off | Niedrige Latenz, starker Standard | Höhere Qualität auf Kosten der Geschwindigkeit |
Kurz gesagt: Greifen Sie zu Fugu, wenn Sie einen reaktionsschnellen Standard möchten, und zu Fugu Ultra, wenn Sie ein besonders schwieriges Problem haben und bereit sind, für eine bessere Antwort zu warten. Frühe Nutzer setzen Ultra bei Kaggle-Wettbewerben, Paper-Reproduktion, Cybersecurity-Analysen und Patentrecherchen ein – das sagt viel über den beabsichtigten Sweet Spot aus: Tiefe, nicht Durchsatz.
Die Benchmarks: Ist es wirklich auf Augenhöhe mit Fable 5?
Sakanas Hauptaussage lautet, dass Fugu-Modelle „öffentlich zugängliche Frontier-Modelle übertreffen und auf Augenhöhe mit Fable 5 und Mythos Preview liegen" bei Engineering-, Wissenschafts- und Reasoning-Benchmarks. Die Zahlen stützen die engere Behauptung gut.
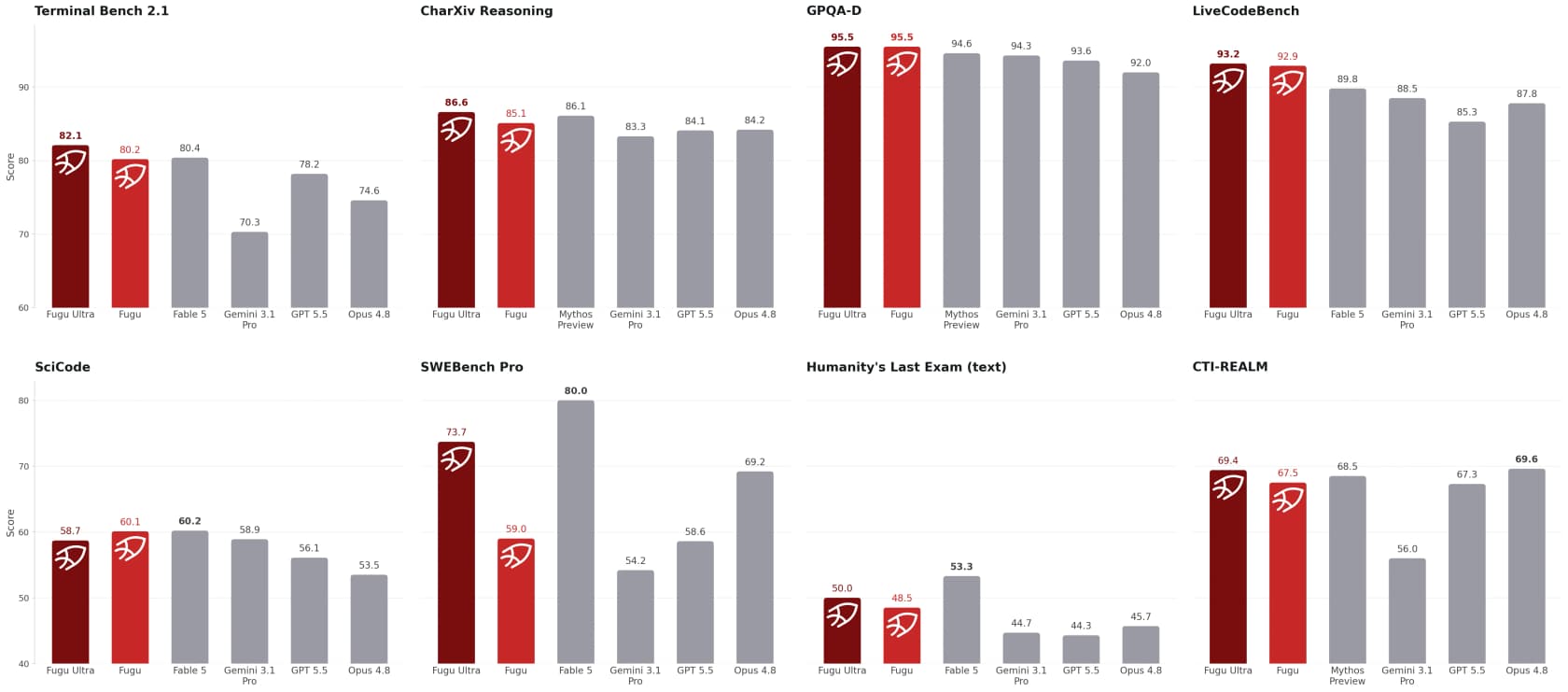
Einige herausragende Werte aus Sakanas Tabelle: Fugu Ultra erreicht 73,7 bei SWE-Bench Pro (vs. 69,2 für Opus 4.8 und 58,6 für GPT-5.5), 93,2 bei LiveCodeBench und 95,5 bei GPQA-Diamond – vor allen gezeigten öffentlichen Vergleichswerten. Die qualitativen Demos sind noch beeindruckender: Fugu hat angeblich drei Frontier-Modelle und eine 2100-Elo-Stockfish-Engine im Blindschach besiegt und in einem Zeitreihen-Handelstest $10.000 auf $11.943 über ein 50-Wochen-Fenster anwachsen lassen – eine mittlere Rendite von +19,43%, besser als alle anderen.
Zwei ehrliche Vorbehalte. Erstens sind dies vom Anbieter gemeldete Benchmarks, und die stärksten Modelle (Fable 5, Mythos) wurden als direkte Konkurrenten aus dem Vergleich ausgeschlossen, statt direkt geschlagen zu werden. Zweitens messen Benchmarks die Spitzenleistung bei schwierigen Problemen, nicht ob das Ding nachmittags angenehm zu bedienen ist. Wie Beta-Nutzer slopdetector auf Hacker News formulierte:
„Ich habe dies während der Beta genutzt. Schlägt GPT-5.5 xhigh bei komplexen Aufgaben. Da es teuer und schwer zu subventionieren ist, nutze es für die schwierigsten Probleme... die Ergebnisse, die ich von fugu-ultra erhielt, waren beeindruckend." - slopdetector auf Hacker News
Was Sakana Fugu kostet (und der Haken, den niemand erwähnt)
Es gibt zwei Zahlungsmöglichkeiten, und beide umfassen Zugang zu Fugu und Fugu Ultra.
| Abonnement-Stufe | Preis | Nutzungsallokation | Für |
|---|---|---|---|
| Standard | $20/Monat | Basis | Leichte tägliche Nutzung |
| Pro | $100/Monat | 10× Standard | Fokussierte Arbeitssitzungen |
| Max | $200/Monat | 30× Standard | Umfangreiche, langandauernde Workloads |
(Anmerkung: Sakanas Preiskarten sagen, Max ist 30× Standard, während eine FAQ-Antwort 20× nennt – prüfen Sie die Allokation vor dem Abschluss.) Es gibt auch einen nutzungsbasierten Token-Tarif, bei dem Fugu Ultra fest bei $5 Eingabe, $30 Ausgabe und $0,50 gecachte Eingabe pro Million Tokens liegt und auf $10 / $45 / $1,00 ansteigt, sobald der Kontext 272K Tokens überschreitet. Und es gibt eine Launch-Aktion: Bis Ende Juli 2026 abonnieren für einen kostenlosen zweiten Monat.
Jetzt der Haken. Fugu wird zum Höchstpreis des Pools berechnet, aus dem es weiterleitet, sodass der Orchestrierungsaufwand sich gegenüber dem direkten Bezahlen für ein Frontier-Modell rechtfertigen muss. Mehrere erfahrene Nutzer fanden das nicht gegeben. Die schärfste Version kam von cortesi auf Hacker News:
„Für $200/Monat bekommt man weniger als 3 Stunden Nutzung pro Woche, die API ist extrem langsam, und die Ausgabequalität liegt in meinen Tests nirgendwo in der Nähe von Fable. Sie ist als tägliches Arbeitspferd absolut nicht brauchbar. Sehr enttäuschend." - cortesi auf Hacker News
Das ist die Erfahrung eines Testers, kein Urteil, aber es deckt sich mit mehreren anderen Berichten, dass das 5-Stunden-Limit schnell aufgebraucht ist. Wenn Sie schon einmal KI-Agenten-Kosten gegen menschliche Agenten abgewogen haben, ist die Lektion vertraut: Aufgelisteter Preis und tatsächliche Kosten pro nützlicher Aufgabe sind unterschiedliche Zahlen.
Hier eine schnelle Eignungsprüfung, ob Fugu überhaupt das richtige Werkzeug für Ihren Zweck ist:
Ist „nur OpenRouter mit extra Schritten" eine berechtigte Kritik?
Die lauteste einzelne Reaktion auf Fugus Launch, unabhängig auf Hacker News, X und Reddit wiederholt, lautete irgendwie: „Ist das nicht einfach OpenRouter?" Das ist ein berechtigter Instinkt, also nehmen wir ihn ernst.
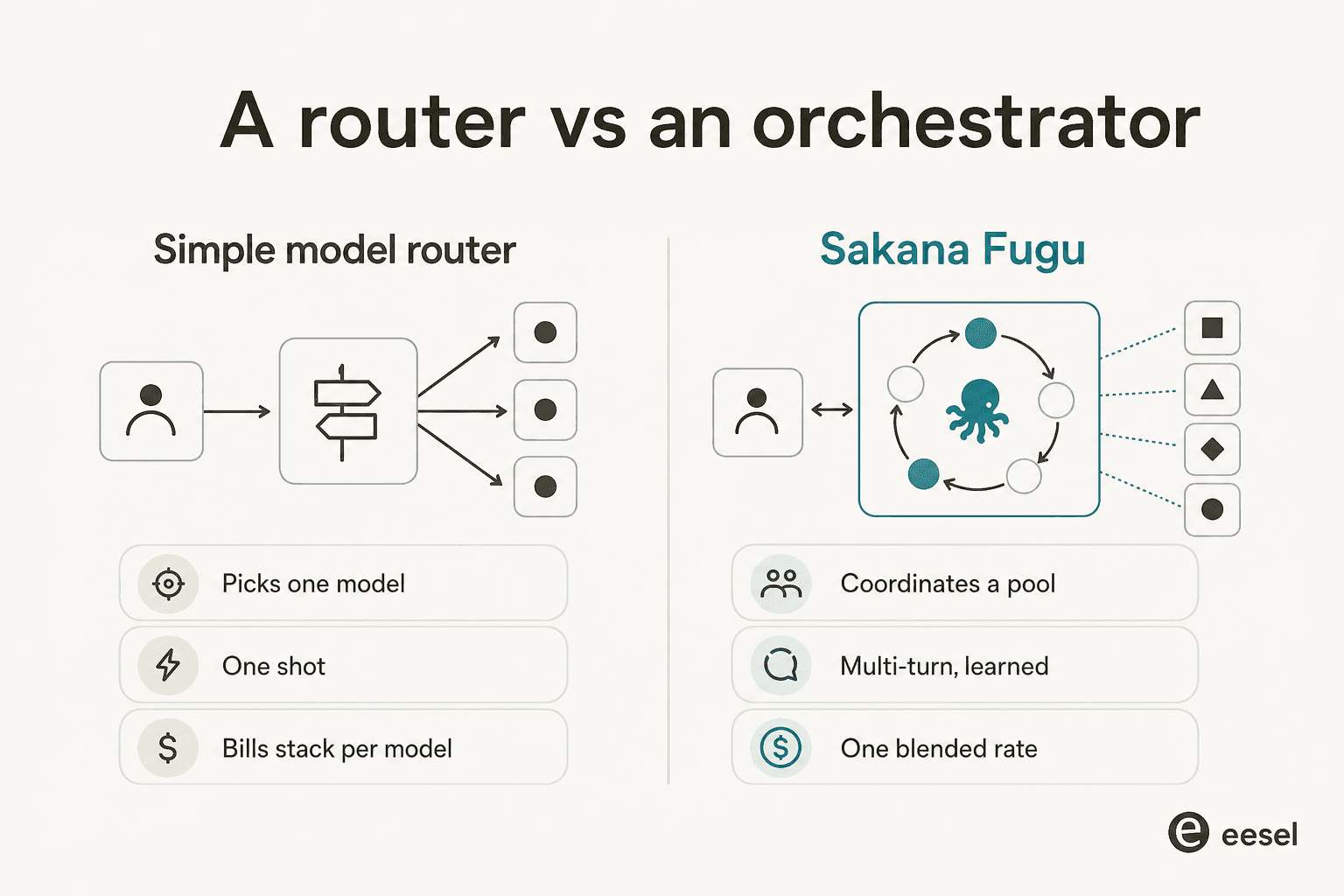
Ein einfacher Router wählt ein Modell aus und leitet Ihre Anfrage einmalig weiter. Fugu tut zumindest auf dem Papier drei Dinge, die ein Router nicht tut: Es führt mehrere Runden durch, lässt Modelle die Arbeit des anderen überprüfen, und es berechnet einen einzigen gemischten Tarif basierend auf dem involvierten Top-Modell, statt jede Modellrechnung aufzustapeln. Die Architektur ist also real, und „erweiterter Router" untertreibt den mehrstufigen, selbstprüfenden Loop.
Aber die Skeptiker landen einen echten Treffer beim Wert, nicht bei der Architektur. Wie chenzhekl direkt fragte:
„Aber es ist genauso teuer wie Frontier-Modelle. Warum zahle ich nicht direkt für Frontier-Modelle?" - chenzhekl auf Hacker News
Das ist die ganze Debatte in einer Zeile. Die Architektur ist mehr als ein Router; die offene Frage ist, ob die extra Koordination genug bringt, um Frontier-Preise dafür zu rechtfertigen. Meine Einschätzung: Bei Ihren schwierigsten Problemen plausibel ja; bei alltäglicher Arbeit wahrscheinlich nicht. Das ist dieselbe Kalkulation wie bei Entscheidungen zwischen KI-Agent und regelbasiertem Chatbot, wo mehr Komplexität nur bei wirklich schwierigen Aufgaben zahlt.
Was Menschen wirklich über Sakana Fugu denken
Die Community-Stimmung ist, fair gelesen, gemischt bis skeptisch, mit einem echten Pro-Lager. Die Befürworter machen das interessanteste Argument: dass das gegenseitige Überprüfen von Modellen schlicht die richtige Wette ist. Wie epsteingpt argumentierte:
„Alle verstehen seit Monaten, dass das gegenseitige Überprüfen durch verschiedene Modelle der beste Weg vorwärts ist... Wenn (großes Wenn) die Nutzungsmechanik stimmt, ist das tatsächlich eine wirklich gute Anti-Großmodell-Strategie. Sie werden für Ihren Erfolg motiviert, nicht für Token-Maximierung für ihre Investoren." - epsteingpt auf Hacker News
Dieser Punkt zur Anreizausrichtung ist treffend, und er ist ein echtes Argument für einen Orchestrator gegenüber einem Monolithen. Es gibt auch einen Strang des Respekts für Sakanas Forschungsweg. Wie quanto anmerkte, hat David Ha einen unkonventionellen Weg in die KI-Forschung genommen, und die früheren Arbeiten des Labors (Evolutionary Model Merge, der AI Scientist, Transformer²) sind durchgehend eigenständig.
Die Skeptiker sind unterdessen nicht reflexartig. Ihre Einwände konzentrieren sich auf Kosten, Latenz und die undurchsichtige „ein Anbieter ersetzt einen anderen Anbieter"-Rahmung. Und einige reale Hinweise, die Sie vor der Registrierung kennen sollten: Fugu ist noch nicht in der EU/EEA verfügbar, und einige Nutzer äußerten Unbehagen über Sakanas Militärverträge. Wenn Sie es gegenüber den besten KI-Agenten für den Produktiveinsatz abwägen, sind das keine Fußnoten.
Warum ein Modell, das Modelle orchestriert, für den Support wichtig ist
Das ist der Teil, der mich am meisten interessiert, weil es mein Beruf ist. Fugus Grundidee – setzen Sie nicht alles auf ein Modell, koordinieren Sie mehrere und lassen Sie sie sich gegenseitig überprüfen – ist genau richtig für hochriskante Automatisierungen wie den Kundensupport. Eine falsche Antwort eines Support-Bots ist kein Leaderboard-Fehler, sondern eine versehentlich ausgestellte Rückerstattung oder ein verärgerte Kunde.
Aber zwischen einer rohen, intransparenten Modell-API und etwas, das Sie sicher Kunden präsentieren können, liegt eine tiefe Kluft. Fugu gibt Ihnen Orchestrierung; es gibt Ihnen nicht Ihr Help Center, Ihre vergangenen Tickets, Ihre Markenstimme, Ihre Eskalationsregeln oder eine Möglichkeit, das System vor dem Go-live zu testen. Das ist die Ebene, die wirklich entscheidet, ob KI für den Kundendienst funktioniert, und deshalb würde ich einen zweckgebundenen KI-Agenten für den Kundendienst gegenüber dem manuellen Verbinden einer Frontier-API bevorzugen. Die Orchestrierungsfrage, über die wir bei Build vs. Buy diskutieren, ist dieselbe, die Fugu beantwortet – nur auf einer anderen Ebene des Stacks.
eesel ausprobieren
eesel nimmt die Lektion, auf der Fugu aufgebaut ist, und wendet sie dort an, wo sie wirklich zuverlässig sein muss: Ihre Support-Queue. Anstatt Ihnen eine Modell-API zu übergeben, ist es ein KI-Agent, der sich in wenigen Minuten in das Helpdesk einbindet, das Sie bereits nutzen (Zendesk, Freshdesk, Help Scout, Slack und mehr), sich auf Ihren vergangenen Tickets und Ihrem Help Center trainiert und in Ihrer Markenstimme antwortet – kein Modell-Orchestrierungs-Klempnerwerk erforderlich.

Das entscheidendste Unterscheidungsmerkmal hier ist das, was Fugu nicht liefern kann: ein Simulationsmodus, der den Agenten gegen Tausende Ihrer historischen Tickets wiedergibt, bevor er jemals einen Live-Kunden berührt, sodass Sie die Lösungsrate und genaue Antworten im Voraus sehen, statt sie im Betrieb zu entdecken. Die Preisgestaltung ist nutzungsbasiert ohne Sitzgebühren, sodass die Kosten mit dem Wert skalieren, nicht mit der Mitarbeiterzahl. Wenn Sie sehen möchten, wie ein Kundendienst-KI aussieht, wenn die Orchestrierung unsichtbar und die Sicherheitsmechanismen eingebaut sind, können Sie es kostenlos ausprobieren.
Häufig gestellte Fragen
Was ist Sakana Fugu in einfachen Worten?
Wie unterscheidet sich Sakana Fugu von OpenRouter?
Was kostet Sakana Fugu?
Ist Sakana Fugu besser als Claude oder GPT-5.5?
Wofür eignet sich Sakana Fugu am besten?
Kann ich Sakana Fugu für den Kundensupport nutzen?
Ist Sakana Fugu überall verfügbar?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








