Was ist MiniMax M3?
MiniMax M3 ist ein allgemeines Large Language Model, das MiniMax als „ein Frontier-Coding- und agentisches Modell beschreibt, das auf einer neuen Attention-Architektur (MSA) mit 1M-Kontext aufgebaut ist.“ Es löst die frühere M2-Reihe (M2, M2.1, M2.5, M2.7) ab, die alle weiterhin verfügbar bleiben, und es ist das erste MiniMax-Modell, das von Anfang an multimodal trainiert wurde – es verarbeitet also Bild- und Videoeingaben und kann sogar einen Desktop-Computer bedienen.
MiniMax selbst ist ein chinesisches KI-Labor mit dem Motto „Intelligence with everyone“, dessen Angebot weit über Text hinausgeht – mit Video (Hailuo), Sprache und Musik. M3 ist das Text- und Agent-Flaggschiff dieser Produktlinie. Wer die Welle starker Modelle aus China verfolgt, findet M3 im selben Gespräch wie Qwen und Kimi K2.5, und es ist eines der interessanteren Open-Weight-Launches des Jahres.
Der offizielle Launch legte das Versprechen klar auf dem X-Account von MiniMax dar:
„Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities... Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1... MiniMax Sparse Attention scales context to 1M... Natively Multimodal from Step Zero“
Ein Namenshinweis vorab: Es gibt kein Modell, das buchstäblich „MiniMax 3“ heißt. Der offizielle Name ist MiniMax M3, und das ist es, was dieser Leitfaden behandelt.
Wie MiniMax M3 funktioniert: Sparse Attention und ein 1M-Token-Fenster
Das Interessanteste an M3 ist nicht ein Benchmark, sondern die Architektur, die es ermöglicht, eine Million Token zu lesen, ohne dass die Kosten explodieren. Das ist der Teil, den ich wirklich clever finde, also lassen Sie mich erklären, wie es funktioniert.
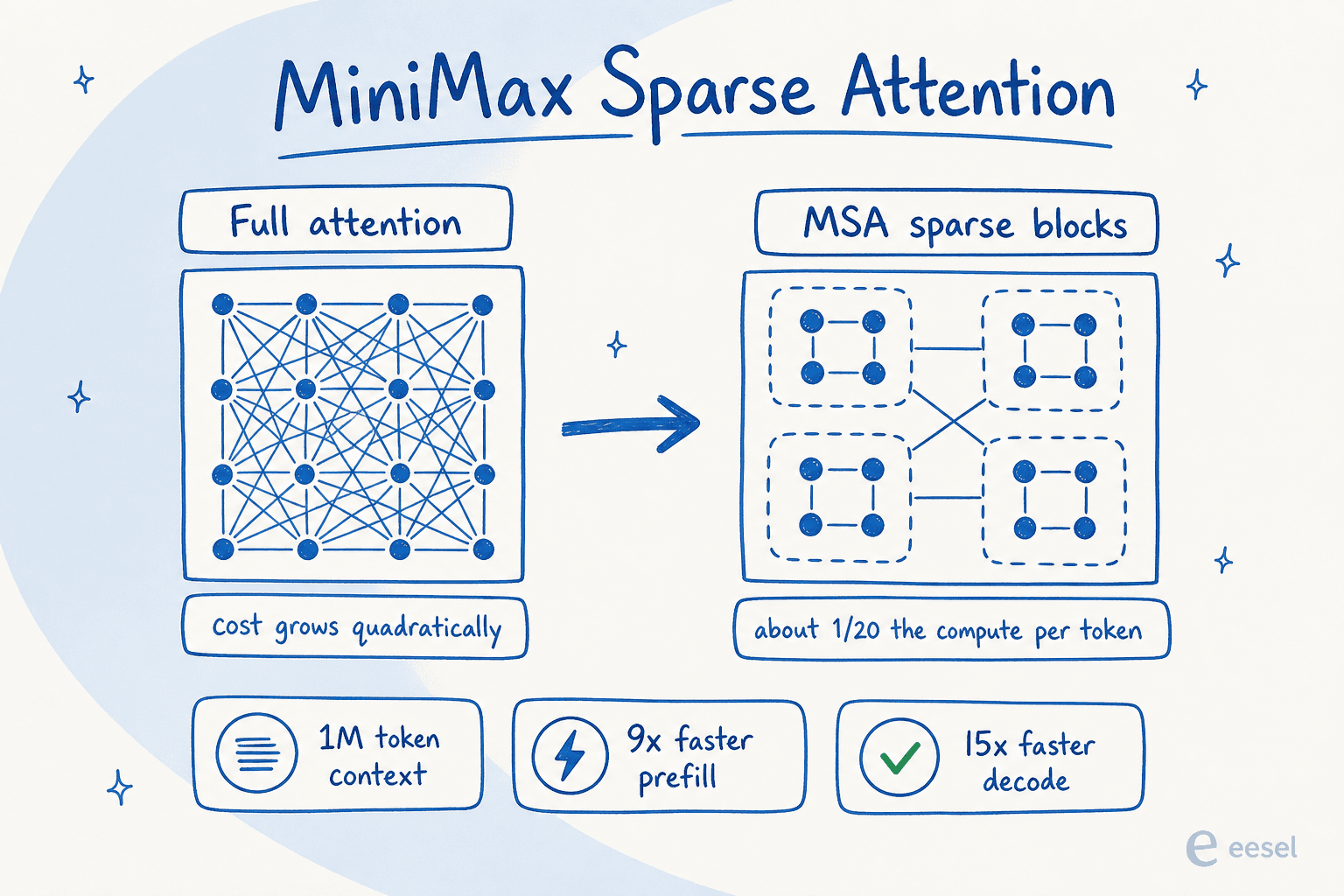
Unter der Haube ist M3 ein Mixture-of-Experts-Modell mit rund 428B Gesamtparametern und etwa 23B aktivierten Parametern pro Token, das bei jeder Anfrage nur einen Bruchteil von sich selbst ausführt. Darüber sitzt das eigentliche Highlight: MiniMax Sparse Attention (MSA), ein neues Attention-Design, das den Kontext in Blöcke aufteilt und nur auf die relevanten achtet, anstatt jedes Token mit jedem anderen zu vergleichen.
Das ist wichtig, weil normale Attention quadratisch teurer wird, wenn der Kontext wächst, weshalb lange Kontextfenster normalerweise langsam und kostspielig sind. MiniMax berichtet, dass MSA den Rechenaufwand pro Token auf etwa 1/20 reduziert, mit mehr als 9-fach schnellerem Prefilling und 15-fach schnellerem Decoding bei einem 1M-Kontext im Vergleich zu M2, während in ihren Ablationen die volle Attention-Leistung bei den meisten Fähigkeiten erhalten bleibt. Das Ergebnis ist ein 1.000.000-Token-Kontextfenster (mit einem garantierten Minimum von 512K), gegenüber 204.800 bei der M2-Reihe.
Ein paar weitere wissenswerte Details zum Verhalten von M3:
- Denkmodi. Ein
thinking-Parameter ermöglicht es, Reasoning aufenabled,adaptive(das Modell entscheidet) oderdisabledfür niedrige Latenz zu setzen, und beide Modi teilen dieselbe Preisstruktur. - Native Multimodalität. Da es von Anfang an auf verschränktem Text, Bild und Video trainiert wurde, fusioniert M3 die Modalitäten tiefer als ein Modell, bei dem Vision nachträglich hinzugefügt wurde.
- Gebaut für langfristige Arbeit. In MiniMaxs eigenen Demos lief M3 fast 12 Stunden autonom, um ein Forschungspapier zu reproduzieren, und verbrachte etwa 24 Stunden damit, einen CUDA-Kernel über 147 Benchmark-Einreichungen und 1.959 Tool-Aufrufe hinweg zu optimieren.
Die vollständige Methode finden Sie im M3 Technical Report, wenn Sie die Tiefe wollen.
Wie gut ist MiniMax M3? Die Benchmarks
MiniMax positioniert M3 als Frontier-Modell für Software-Engineering und Terminal-Ausführung und vergleicht es mit geschlossenen Modellen wie GPT-5.5, Gemini 3.1 Pro und Claude Opus. Hier sind die veröffentlichten Werte aus der Ankündigung:
| Benchmark | Was gemessen wird | MiniMax M3 |
|---|---|---|
| SWE-Bench Pro | Software-Fixes in der realen Welt | 59,0 % |
| Terminal-Bench 2.1 | Agentische Kommandozeilen-Aufgaben | 66,0 % |
| MCP Atlas | Tool-Nutzung über das Agent-Protokoll | 74,2 % |
| SWE-fficiency | Effiziente Code-Änderungen | 34,8 % |
| KernelBench Hard | GPU-Kernel-Optimierung | 28,8 % |
| PostTrainBench | Autonomes Modell-Training | 37,1 (#3) |
| Video-MME (512 Frames) | Video-Verständnis | 84,6 |
Ein bisschen Ehrlichkeit darüber, was das bedeutet. Beim autonomen Modelltraining-Benchmark PostTrainBench landete M3 auf dem dritten Platz, knapp hinter Claude Opus 4.7 (42,4) und GPT-5.5 (39,3), aber vor allem anderen. Das ist das Muster insgesamt: M3 ist ausgezeichnet für ein Open-Weight-Modell und konkurrenzfähig beim Coding, aber es führt nicht die geschlossene Frontier an. Die frühere M2-Familie hatte die Open-Weight-Werte auf unabhängigen Indizes bereits erhöht, und M3 ist ein klarer Schritt darüber hinaus.
Wenn Sie den weiteren Kontext zum Vergleich dieser Modelle möchten, decken unsere Leitfäden zu Claude-Alternativen und Gemini-Alternativen die Seite der geschlossenen Modelle des Vergleichs ab.
Was kostet MiniMax M3?
Hier liegt M3s Ruf begründet. Die Preisgestaltung ist der Grund, warum Entwickler es immer wieder erwähnen.
MiniMax verkauft M3 auf zwei Wegen. Der erste ist ein Abonnement-Token-Plan, der beim Launch auf drei Stufen aktualisiert wurde, wobei Text, Bild, Sprache und Musik alle aus einem gemeinsamen Nutzungspool schöpfen:
| Token-Plan | Preis / Monat | Ungefähre M3-Token / Monat |
|---|---|---|
| Plus | 20 $ | ~1,7B Token |
| Max | 50 $ | ~5,1B Token |
| Ultra | 120 $ | ~9,8B Token |
MiniMax bezeichnet die Einstiegsstufe als „$20 = 10x Claude Pro“ beim Durchsatz, was Marketing ist, aber die Ausrichtung zeigt: maximale Token pro Dollar. Es ist dieselbe Niedrigpreis-Positionierung, die Sie bei Qwen-Preisen und dem Rest der Open-Weight-Gruppe sehen.
Der zweite Weg ist die Pay-as-you-go-API, abgerechnet nach Eingabelänge. Anfragen unter 512K Eingabe-Token erhalten den Standardtarif; alles darüber wird zu einem höheren Long-Context-Tarif für vollständige Repositories und ultra-lange Dokumente abgerechnet. Thinking an oder aus kostet dasselbe, und ein priority-Service-Tier ist für latenzempfindliche Workloads verfügbar. Entwickler auf r/LLMDevs berichten vom Launch-Preis pro Token von 0,60 $/2,40 $ pro Million bis 512K, was sie in „DeepSeek-Territory“ einordnet.
Die andere Hälfte der Kostengeschichte ist die Lizenz. M3 ist Open-Weight unter der MiniMax Community License: kostenlos für nicht-kommerzielle Nutzung, wobei kommerzielle Nutzung einen sichtbaren „Built with MiniMax M3“-Hinweis erfordert und bei Umsätzen über 20 Mio. USD/Jahr eine vorherige schriftliche Genehmigung. Also Open-Weight, nicht Open Source – ein Unterschied, den die Community schnell hervorhebt. Für einen reinen Kostenvergleich mit anderen kostenpflichtigen Optionen sind unsere Liste der günstigen KI-Tools und der Kimi K2.5 Preisleitfaden nützliche Referenzpunkte.
Was Entwickler wirklich über MiniMax M3 sagen
Die veröffentlichten Benchmarks sagen nur so viel. Das nützlichere Signal kommt von Entwicklern, die M3 bei echter Arbeit einsetzen, und das Urteil ist einheitlich: eine starke Wahl beim Preis-Leistungs-Verhältnis, kein Frontier-Ersatz.
Die klarste Version des Wertarguments kommt eigentlich von jemandem, der zum M2.7-Vorgänger gewechselt ist, auf r/openclaw:
„claude is a slightly better model. better reasoning, better depth on hard problems. that's just how it is. but minimax m2.7 delivers exceptionally well for what i actually use it for, at a fraction of the cost... sometimes good enough is actually great when it's reliable and affordable.“
Zu M3 speziell äußerte sich ein Entwickler auf r/opencode nach dem Ausprobieren anderer chinesischer Modelle so:
„I started using Kimi 2.6, then GLM 51, then DeepSeek4. But now after trying minimax m3 I am really impressed. It seems to think very deeply and really do a good job following directions... It seems to have flown a lot under the radar.“
Das deckt sich in etwa damit, wo M3 im Markt steht: Open-Weight, in etwa Sonnet-Klasse-Fähigkeit, zu Value-Tier-Preisen.
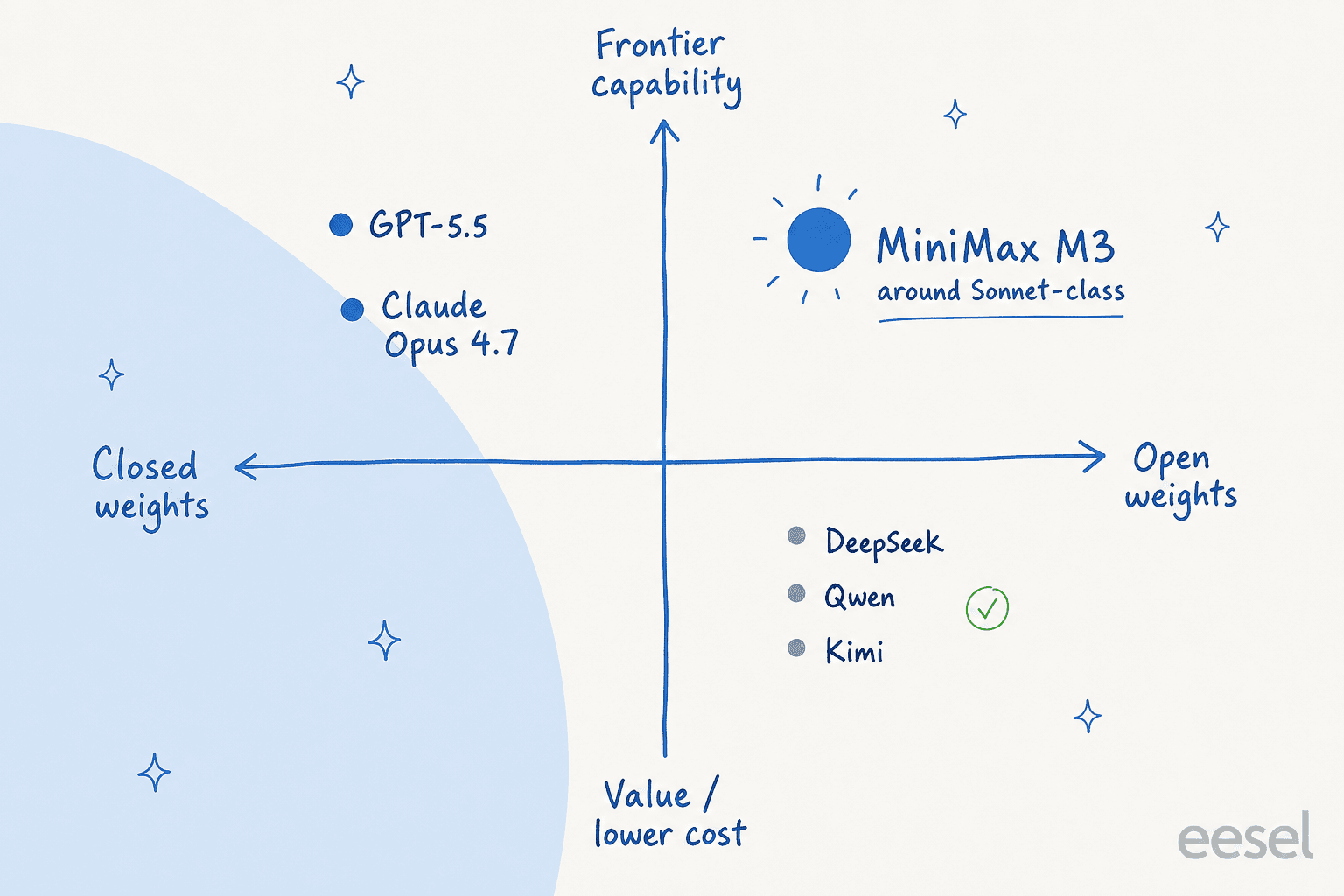
Es ist aber nicht nur Lob, und die Kritik sollte ernst genommen werden, wenn man an Produktion denkt. Die häufigste Beschwerde ist die Zuverlässigkeit unter Druck. Ein Tester auf r/hermesagent fand M3 unberechenbar:
„I feel like it is much more chaotic and verbose, as well as hallucinations being more common. Now it just suddenly keeps stopping mid action... Right now I wouldn't use it in production.“
Es gibt auch eine wiederkehrende Datenschutzsorge rund um die gehostete API, wobei Nutzer darauf hinweisen, dass sie kein klares Opt-out dafür finden konnten, dass Prompt-Daten für das Training verwendet werden. Genau das ist der Typ von Thema, der bei Kundendaten mehr zählt als bei einem Hobbyprojekt, und das ist ein wesentlicher Grund, warum die Self-Hosting-Community schätzt, dass die Gewichte auf Hugging Face verfügbar sind.
Der Haken: Ein tolles Modell ist noch kein Support-Agent
Hier ist die Neubewertung, mit der ich Sie entlassen möchte, denn das ist das, was Menschen übersehen, wenn ein glänzendes neues Modell erscheint. Ein Modell wie M3 ist ein fantastischer Motor. Aber ein Motor ist kein Auto, und ein rohes Modell ist kein Kundensupport-Agent.
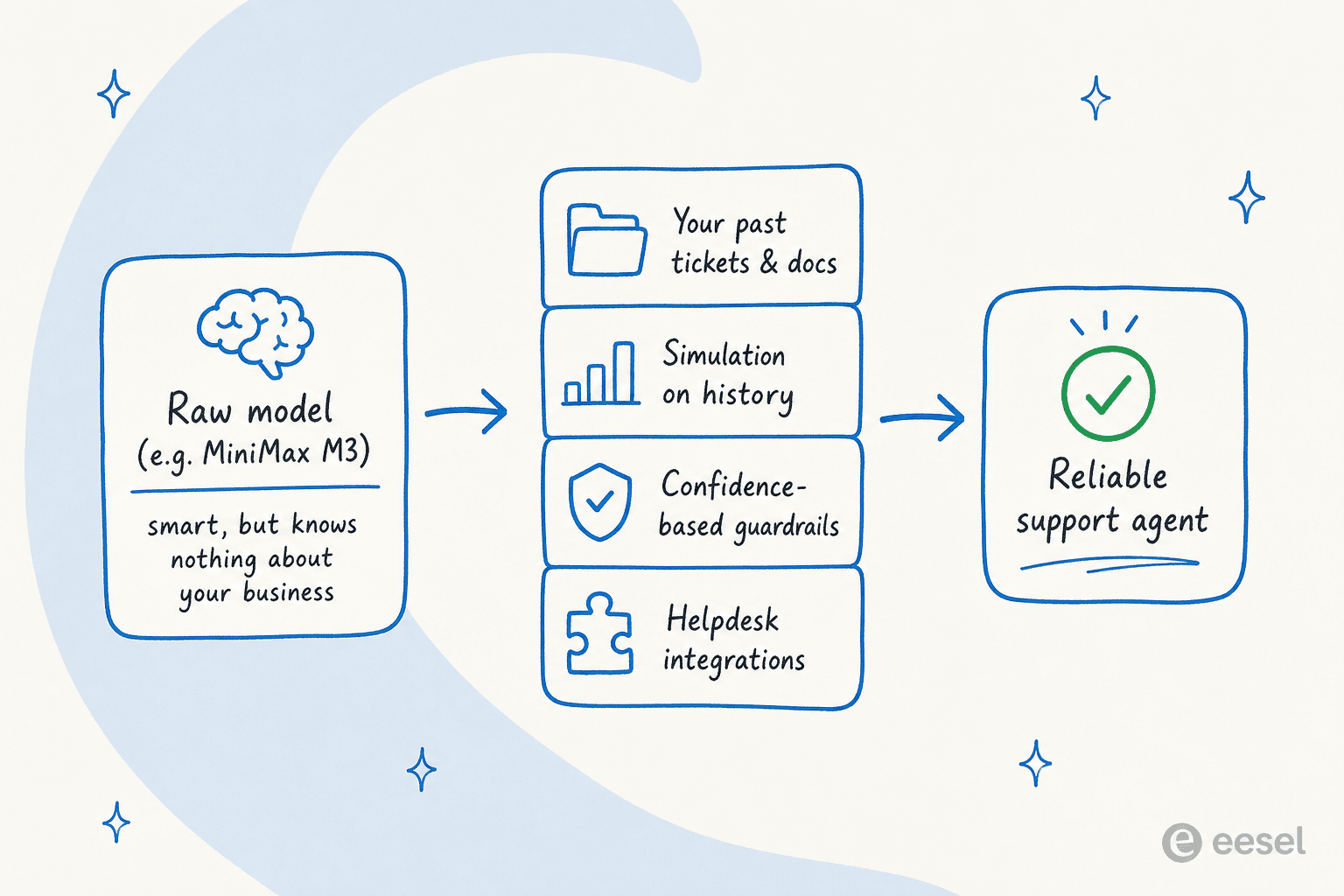
Ich habe die letzten Jahre bei eesel damit verbracht, zu beobachten, was passiert, wenn man ein Sprachmodell auf eine Live-Support-Warteschlange zeigt, und das Fehlermuster ist immer dasselbe: Das Modell klingt zuversichtlich und liegt bei den Besonderheiten falsch, weil es Ihre Rückerstattungsrichtlinien nicht kennt, Ihre letzten 50.000 gelösten Tickets, oder welche Antwort sicher zu senden ist, ohne dass ein Mensch sie zuerst liest. Das klügste Modell der Bestenliste halluziniert Ihren Versand-Cutoff, wenn niemand es das gelehrt hat. Deshalb läuft jede eesel-Implementierung in der Simulation gegen historische Tickets, bevor sie jemals einem Kunden antwortet.
Die relevanten Fragen für den Support sind also nicht „Was hat M3 auf SWE-Bench erzielt“. Sie lauten: Kann es aus meinen tatsächlichen Tickets und Dokumenten lernen, kann ich es sicher testen, bevor es live geht, und was hält es davon ab, eine falsche Antwort selbstsicher zu senden? Das sind Produktfragen, keine Modellfragen, und sie sind es, um die unsere Übersicht über die besten KI für den Kundendienst aufgebaut ist.
Derselbe Punkt taucht immer auf, wenn ein Chatbot falsch antwortet, und er ist der Grund, warum die Kosten eines KI-Agenten gegenüber einem Menschen viel mehr davon abhängen, wie zuverlässig er Tickets löst, als vom Preis pro Token des Modells.
eesel: Die Schicht, die ein Modell in einen Support-Teammitarbeiter verwandelt
Genau diese Lücke ist es, die eesel schließen soll. Anstatt Sie ein Modell auswählen und beten zu lassen, sitzt eesel als KI-Teammitglied auf Ihrem Helpdesk, lernt von Tag eins an aus Ihren vergangenen Tickets, Hilfe-Dokumenten und Tools und entwirft, triage und löst Tier-1-Arbeit mit den Leitplanken, die es sicher machen, es laufen zu lassen.

Das konkrete Unterscheidungsmerkmal ist der Simulationsmodus: Sie führen den Agenten gegen Tausende Ihrer echten vergangenen Tickets aus, sehen genau, was er beantwortet hätte und wo die Lücken sind, füllen sie und gehen erst dann live, wobei konfidenzbasiertes Routing Antworten mit geringer Konfidenz als Entwürfe statt als Sendungen behandelt. So führen Teams wie Smava einen vollständig automatisierten Zendesk-Agenten mit über 100.000 deutschen Tickets pro Monat durch, und so hat Gridwise in seinem ersten Monat 73 % Tier-1-Auflösung erreicht. Es verbindet sich mit 100+ Integrationen, antwortet in 80+ Sprachen und läuft auf nutzungsbasierter Preisgestaltung zu 0,40 $ pro Ticket ohne Sitzplatzgebühren.
Wenn Sie hierherkamen, um ein Modell für den Support auszuwählen, ist der bessere Ausgangspunkt die Schicht, nicht die Bestenliste. Sie können eesel ausprobieren – kostenlos, keine Kreditkarte –, und zusehen, wie es Ihre eigenen Tickets in der Simulation löst, bevor es einen einzigen Kunden berührt. Das ist die Lehre aus jedem Kundendienst-KI-Rollout, den ich erfolgreich gesehen habe: Das Modell ist austauschbar, die Zuverlässigkeit nicht.
Häufig gestellte Fragen
Was ist MiniMax M3 in einfachen Worten?
Ist MiniMax M3 wirklich Open Source?
Was kostet MiniMax M3?
Ist MiniMax M3 gut für Coding?
Kann ich MiniMax M3 für den Kundensupport verwenden?
Wie bewältigt MiniMax M3 einen 1-Millionen-Token-Kontext?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.