Kurz gesagt
Claude Fable 5 ist Anthropics leistungsstärkstes Modell, und die kurze Antwort auf „Was kann es?" lautet: echte, mehrstufige Arbeit, die tagelang läuft, ohne dass ein Mensch bei jedem Schritt neu nachfragen muss. Es plant, schreibt und liefert Code aus, liest riesige Dokumente, delegiert an Sub-Agenten und prüft seine eigene Ausgabe. In Anthropics eigenen Benchmarks ist es das stärkste Modell, das die Öffentlichkeit nutzen kann, und frühe Tester nennen es das beste verfügbare Coding-Modell.
Zwei ehrliche Einschränkungen stehen daneben. Es ist langsam und teuer, mit 10 $ pro Million Input-Tokens und 50 $ pro Million Output, doppelt so viel wie Opus 4.8. Und es antwortet nicht immer mit voller Stärke: Eine Sicherheitsschicht leitet manche Prompts unbemerkt an ein schwächeres Modell weiter.
Wenn Sie ein Support- oder Operations-Team leiten, ist die praktische Erkenntnis: Ein so leistungsfähiges Modell ist der Motor, nicht das Auto. Was Sie tatsächlich einsetzen, ist ein KI-Agent, der darauf aufbaut, mit dem Wissen, den Leitplanken und dem Testen, die das rohe Modell nicht enthält.
Was kann Claude Fable 5 also wirklich?
Claude Fable 5 ist Anthropics fünfte Modellgeneration und eine neue „Mythos-Klasse", die über Claude Opus 4.8 angesiedelt ist, das wiederum über Sonnet 4.6 steht. Wenn Sie unseren Claude-Überblick gelesen haben: Das ist die neue Obergrenze. Es wurde am 9. Juni 2026 veröffentlicht und läuft auf claude.ai, der Claude API, Claude Code, AWS und Microsoft Foundry.
Aber Specs und Tiers sind nicht wirklich das, was Menschen meinen, wenn sie fragen, was es kann. Sie meinen: Welche Arbeit kann ich ihm übergeben und darauf vertrauen, dass es sie zu Ende bringt? Hier ist die ehrliche Übersicht seiner konkreten Fähigkeiten, dann gehen wir jede einzeln durch.
Es arbeitet tagelang autonom und prüft dann seine eigene Arbeit
Das ist die Fähigkeit, um die Anthropic Fable 5 tatsächlich gebaut hat, und es ist die, die am meisten zählt. Lassen Sie es in einem Harness wie Claude Code oder Claude Managed Agents laufen, und in Anthropics Worten kann es „tagelang am Stück arbeiten: über Phasen hinweg planen, an Sub-Agenten delegieren und seine eigene Arbeit prüfen."
Diese Schleife – planen, dann delegieren, dann arbeiten, dann prüfen – ist der Teil, der wirklich neu ist. Frühere Modelle verloren bei langen, mehrstufigen Aufgaben den Faden; dieses behält den Überblick und korrigiert entscheidend seine eigenen Hausaufgaben. Anthropic beschreibt es als „gründlich, proaktiv und prüft seine eigene Arbeit," und die Cloud-Anbieter beschreiben eine eingebaute Plan-, Prüf-, Verfeinerungs-Schleife. Selbstkorrektur ist der Unterschied zwischen einem Agenten, den man babysitten muss, und einem, den man über Nacht laufen lassen kann.
Die Größenordnung, die das ermöglicht, ist real. In frühen Tests richtete Stripe Fable 5 auf eine 50 Millionen Zeilen umfassende Ruby-Codebasis und führte an einem Tag eine Migration über das gesamte Projekt durch, und Community-Berichte beschreiben Sessions mit bis zu 1.000 parallelen Sub-Agenten für Arbeit in Codebasis-Größe. Diese Fähigkeit, ein Ziel festzuhalten, es in Phasen zu zerlegen und sich durchzuarbeiten, ist genau das, was einen KI-Agenten von einem regelbasierten Chatbot unterscheidet: Der eine bringt die Aufgabe zu Ende, der andere wartet auf die nächste Anweisung.
Es schreibt und liefert produktionsreifen Code aus
Das Spektakulärste, was Claude Fable 5 kann, ist Software zu schreiben, die tatsächlich funktioniert. In Anthropics veröffentlichtem Vergleich erreicht es 80,3 % auf SWE-Bench Pro beim agentischen Coding, gegenüber 69,2 % für Opus 4.8, mit GPT 5.5 bei 58,6 % und Gemini 3.1 Pro bei 54,2 %. Beim härteren FrontierCode-(Diamond-)Benchmark verdoppelt es Opus mehr als und springt von 13,4 % auf 29,3 %. CNBC berichtete von einem Abstand von mehr als 10 % über Opus 4.8 bei einigen Tests.
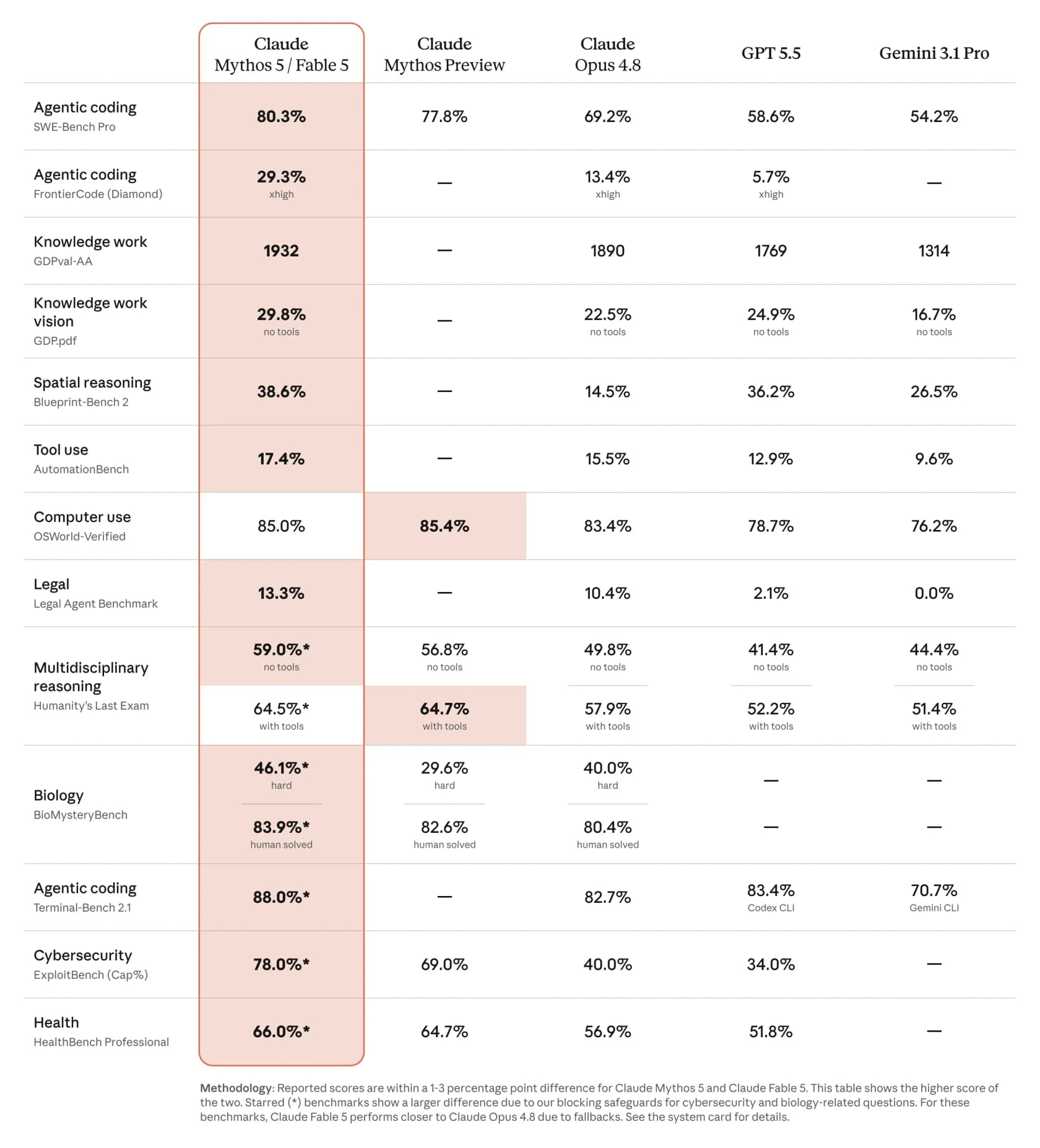
Zahlen sind eine Sache; ein ganzer Tag echter Arbeit eine andere. Der Entwickler Simon Willison richtete Fable auf seine Open-Source-LLM-Library, und es identifizierte und implementierte vier separate Fixes und lieferte dann ein neues Release aus, das fast vollständig vom Modell geschrieben wurde. Sein Urteil fasst die Produktivitätsobergrenze zusammen:
„Ich bin wirklich beeindruckt von der Qualität des API-Designs, der Tests, des Codes und der Dokumentation, die Fable dafür zusammengestellt hat. Ich habe heute mehrere Stunden daran gearbeitet, aber es fühlt sich an wie mehrere Tage Arbeit." - Simon Willison
Er war nicht allein. Andrej Karpathy nannte es einen Sprung, der einen Major-Version-Bump wert ist, und ein Entwickler, der den FrontierCode-Benchmark laufen ließ, postete eine eindrucksvolle Entwicklung: Opus 4.7 bei 5,2 %, Opus 4.8 bei 13,4 %, Fable 5 bei 29,3 %. Wenn Sie abwägen, wo es im Vergleich zum Rest des Feldes steht, sind unsere Übersicht der besten KI-Coding-Assistenten und der besten Claude-KI-Entwickler-Tools eine gute nächste Lektüre.
Es liest die langen, unübersichtlichen Dokumente, die Sie bereits haben
Viel Geschäftsarbeit ist kein Code, sondern Dokumente, und hier verdient sich das Kontextfenster von 1.000.000 Tokens seinen Lohn. Fable 5 „versteht Diagramme, Charts und Tabellen, die in Dateien und PDFs verschachtelt sind," was Anthropic rund um Finanz-, Rechts- und Analyse-Arbeit positioniert, und es gibt keinen Preisaufschlag für das Füllen dieses vollen Kontexts.
Der konkrete Beweis kam von einem Hacker-News-Nutzer, der ihm ein 50-seitiges PDF mit dichten, miteinander verbundenen Spezifikationen übergab und eine korrekte Aufschlüsselung dessen zurückbekam, was erledigt, teilweise erledigt und fehlend war:
„Ich gab ihm ein 50-seitiges PDF mit ziemlich dichten und miteinander verbundenen Spezifikationen und fragte, welche umgesetzt worden waren... es identifizierte korrekt, was erledigt, was teilweise erledigt und was fehlend war." - Hacker-News-Kommentator
Für jedes Team, das auf einem Stapel von Verträgen, Richtliniendokumenten oder einer weitläufigen Wissensdatenbank sitzt, ist das im Tagesgeschäft nützlicher als ein weiterer Punkt auf einem Coding-Leaderboard. Es ist auch derselbe Muskel, den ein Support-Agent nutzt, wenn er Ihre Hilfe-Dokumente und vergangenen Tickets liest, um einem Kunden zu antworten – nur auf interne Dokumente gerichtet.
Was all das kostet
Hier ist der Teil, der die Begeisterung dämpft. Alles oben Genannte läuft zu Frontier-Tool-Preisen: 10 $ pro Million Input-Tokens und 50 $ pro Million Output, genau doppelt so viel wie Opus 4.8. Gecachte Input-Tokens erhalten einen 90-%-Rabatt, und es gibt einen 1,1-fachen Aufschlag für US-only-Inferenz, aber der Schlagzeilen-Tarif ist das, was Sie spüren werden. Wie sich Fable 5 gegen den Rest der Reihe schlägt, schlüsselt unser Claude-Pricing-Leitfaden für jede Stufe auf, und der Claude-Pro-Plan ist der Ort, an dem die meisten Einzelpersonen ihm zuerst begegnen.
| Spezifikation | Claude Fable 5 |
|---|---|
| Veröffentlicht | 9. Juni 2026 |
| Modellklasse | „Mythos-Klasse", eine Stufe über Opus 4.8 |
| Kontextfenster | 1.000.000 Tokens |
| Max. Output | 128.000 Tokens |
| Wissensstand | Januar 2026 |
| Input-Preis | 10 $ / 1 Mio. Tokens (1 $ gecacht) |
| Output-Preis | 50 $ / 1 Mio. Tokens |
| Long-Context-Aufschlag | Keiner |
Wie viel Sie tatsächlich ausgeben, hängt fast ausschließlich davon ab, wie intensiv Sie es denken lassen. Simon Willison ließ seinen Test „zeichne einen Pelikan auf einem Fahrrad" über alle fünf Denkaufwand-Stufen laufen, und die Kosten für ein einzelnes Bild reichten von unter 10 Cent bei „low" bis etwa 72 Cent bei „max". Die Aufwandsstufe ist ein Regler, den Sie einstellen, und sie ist der Haupthebel für Ihre Rechnung.
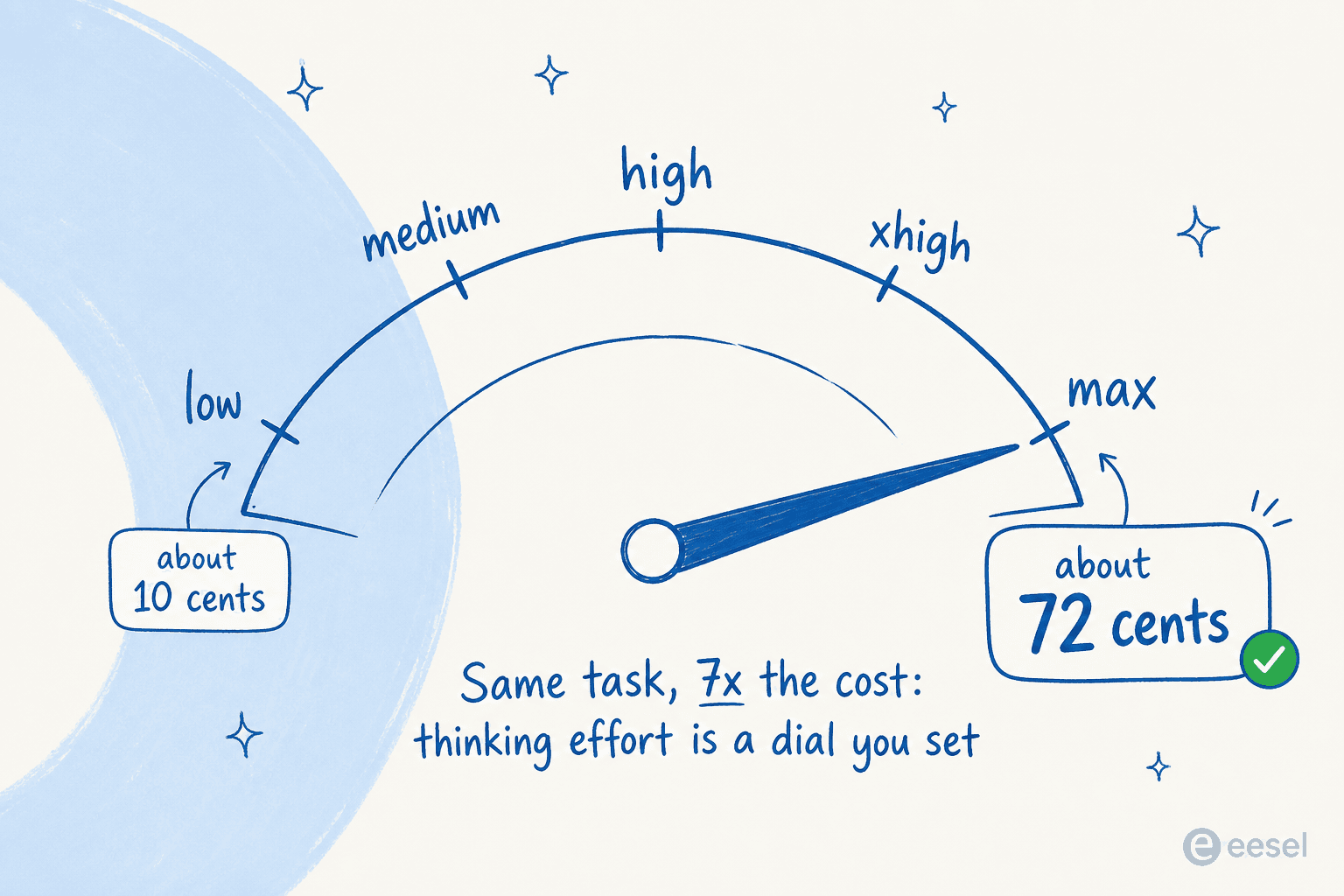
Die Rechnung läuft am oberen Ende schnell auf. Willison verfolgte einen einzigen Testtag mit 110,42 $ Token-Ausgaben. Aber es gibt ein echtes Gegengewicht: Canvas Evaluations-Leiter stellte fest, dass Fable etwa die Hälfte der Tokens von Opus 4.8 in ihren internen agentischen Harnesses verbrauchte, sodass ein klügeres Modell, das in weniger Schritten fertig wird, bei ungefähr denselben realen Kosten landen kann. Die Lektion ist nicht „Fable ist unbezahlbar", sondern dass Ihre Kosten vollständig davon abhängen, wie Sie es betreiben.
Was Claude Fable 5 nicht tun wird
Fähigkeiten schneiden in beide Richtungen, und es gibt eine Sache, die Fable 5 bewusst nicht mit voller Stärke tun wird. Bei Prompts zu Cybersicherheit, Biologie, Chemie und Modell-Distillation erkennt eine neue Generation von Klassifikatoren das Thema und leitet Ihre Antwort stattdessen an Opus 4.8 weiter, und Sie werden darüber informiert. Anthropic sagt, mindestens 95 % der Sessions lösen nie einen Fallback aus.
Der Haken sind die False Positives. Entwickler berichteten, mitten in der Session bei völlig harmloser Arbeit auf das schwächere Modell umgeschaltet worden zu sein, darunter ein Nutzer, dem ein grundlegendes Flüssigkeits-Handhabungs-Protokoll verweigert wurde, an dem nichts Riskantes war. Der KI-Politik-Autor Nathan Lambert wies auf einen zweiten, leiseren Mechanismus für Prompts hin, die wie Frontier-KI-Forschung aussehen, bei dem das Modell weniger effektiv werden kann, ohne es Ihnen zu sagen. Der praktische Rat: Wenn Ihre Arbeit in einer technischen Vertical liegt, testen Sie, bevor Sie sich darauf festlegen.
Was all das bedeutet, wenn Sie ein Support-Team leiten
Hier sind wir zu Hause, also lassen Sie uns konkret werden. Sollte ein Support-Verantwortlicher angesichts all dessen, was Fable 5 kann, es überstürzt in seinen Helpdesk einbinden? Meistens nicht so sehr, wie der Hype suggeriert.
Hier ist die unbequeme Wahrheit über KI für den Kundenservice: Bei Tier-1-Tickets ist das Modell selten der Engpass. Die meisten Teams, die nach Kundenservice-Automatisierung suchen, überbewerten leise, welches Modell darunter sitzt. Ein gut geerdetes Opus 4.8 oder sogar Sonnet 4.6 beantwortet bereits die überwältigende Mehrheit der Fragen wie „Wo ist meine Bestellung", „Wie setze ich mein Passwort zurück", „Was ist Ihre Rückerstattungsrichtlinie" korrekt. Das Doppelte für Fable 5 zu zahlen, um sie zu beantworten, ist, als würde man einen Formel-1-Wagen für die Fahrt zur Schule mieten. Was tatsächlich darüber entscheidet, ob Ihr KI-Helpdesk-Agent funktioniert, ist alles, was um das Modell herum gewickelt ist. Es ist dasselbe Muster, das die starken Tools in jeder Übersicht zu KI-Helpdesk-Software von den vergesslichen unterscheidet.
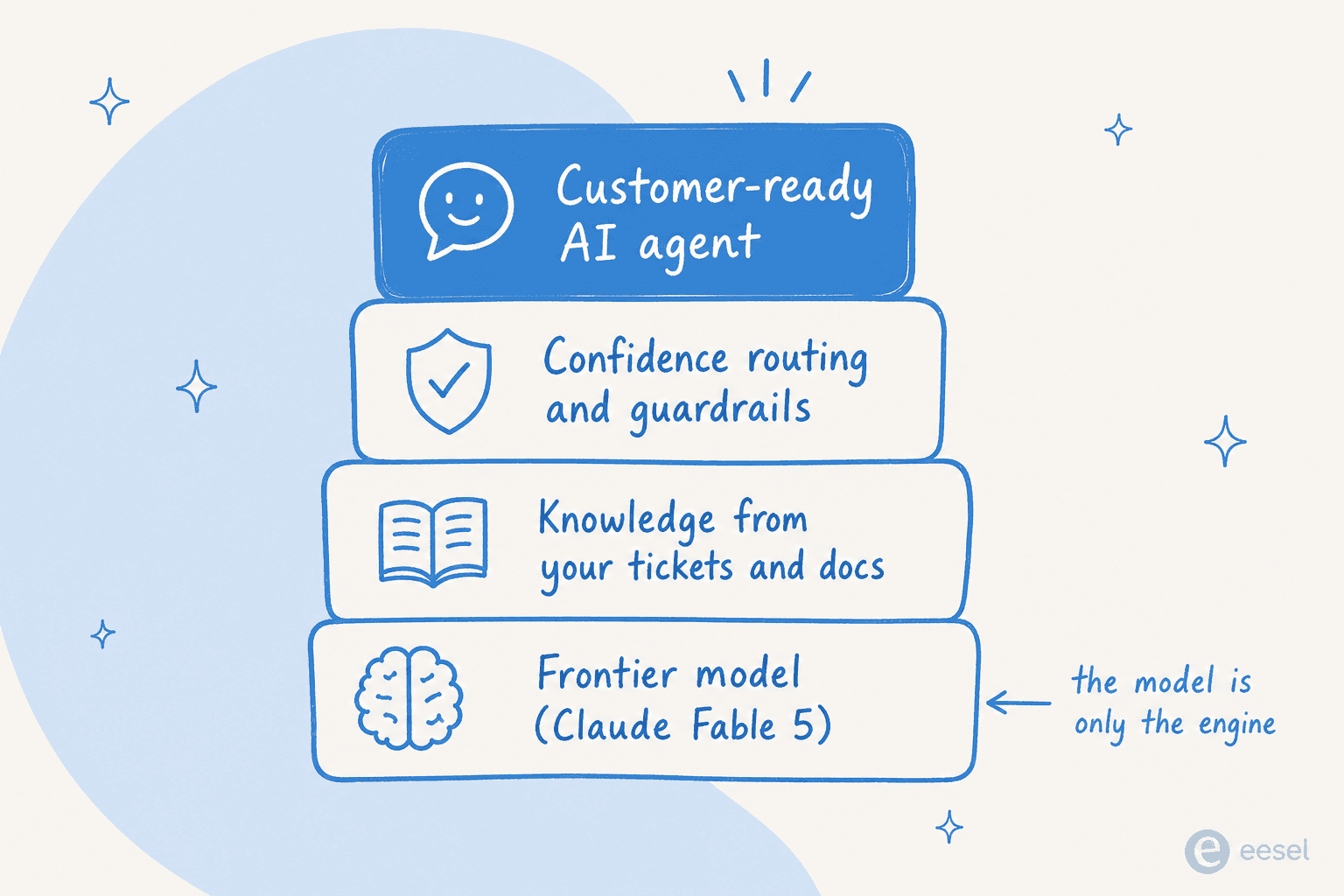
Drei Dinge sind wichtiger als die Modellstufe. Erstens: Kennt es Ihr Geschäft? Der Gewinn kommt vom Training auf Ihren vergangenen Tickets und Hilfe-Dokumenten, nicht von einem klügeren Basismodell. Zweitens: Weiß es, wann es schweigen soll? Rohe Modelle antworten selbstbewusst, auch wenn sie falsch liegen, was genau der Grund ist, warum Chatbots schlechte Antworten geben; Produktions-Agenten brauchen konfidenzbasiertes Routing, das Herzstück jedes guten Ticket-Triage-Setups, damit Tickets mit niedriger Konfidenz entworfen oder eskaliert und nicht automatisch gesendet werden. Wie es ein CX-Leiter eines DTC-Nahrungsergänzungsmittel-Anbieters in einem Kundeninterview formulierte: Die KI wird nie 100 % der Fragen beantworten, also wollen sie eigentlich einen Agenten, der nur die Tickets bearbeitet, bei denen er sich sicher ist, und den Rest in Ruhe lässt. Das ist eine Produktfähigkeit, keine Modellfähigkeit.
Drittens: Können Sie ihm vertrauen, bevor es live geht? Das führt direkt zur Build-versus-Buy-Frage, die ständig aufkommt: „Anthropic hat gerade ein unglaubliches Modell ausgeliefert, warum nicht unseren Support-Bot auf der API bauen?" Können Sie. Es ist auch ein größeres Projekt, als es aussieht, denn das Modell gibt Ihnen Intelligenz, aber nicht die Helpdesk-Anbindung, die Leitplanken, die Simulationsumgebung oder das Reporting. Mehrere technische Teams, die es versuchten, stiegen stattdessen auf Kaufen um:
„Wir hätten versuchen können, unsere eigene LLM-Anwendung zu schreiben, aber wir wollten unsere Zeit nicht darin investieren. Wir wollten etwas, das wir nicht warten müssen." - Karel, GENERAL BYTES
Ein Frontier-Modell ist die unterste Schicht des Stacks, nicht der ganze Stack. Wenn Ihr Kernprodukt KI ist, bauen Sie. Wenn es etwas anderes ist und Sie einfach nur Tickets gut beantwortet haben wollen, ist der Kauf der Schichten über dem Modell schneller, günstiger und weniger fragil – dieselbe Logik, die hinter der Wahl jeder KI für Ticket-Automatisierung gegenüber einem selbstgebauten Skript steckt.
Probieren Sie eesel aus
eesel AI ist die Schicht, die auf Frontier-Modellen wie Claude aufsitzt, sodass Sie die Fähigkeit ohne das Engineering-Projekt bekommen. Es lässt sich in Ihren bestehenden Helpdesk einbinden (Zendesk, Freshdesk, HubSpot, Gorgias und über 100 Integrationen), lernt am ersten Tag aus Ihren vergangenen Tickets und Hilfe-Dokumenten und antwortet über Triage, Entwurf und Lösung hinweg.

Das Unterscheidungsmerkmal ist der Teil, den Fable 5 Ihnen allein nicht geben kann: ein Simulationsmodus, der den Agenten gegen Tausende Ihrer vergangenen Tickets laufen lässt, sodass Sie genau sehen, wie er reagiert hätte und wie hoch Ihre Lösungsrate wäre, bevor ein einziger Kunde mit ihm spricht. So erreichte Gridwise im ersten Monat eine Lösungsquote von 73 % der Tier-1-Anfragen. Und weil das Pricing nutzungsbasiert bei 0,40 $ pro gelöstem Ticket ohne Pro-Platz-Gebühren liegt, zahlen Sie für Ergebnisse, nicht für Tokens, die Sie nicht vorhersagen können. Sie können eesel kostenlos mit 50 $ Nutzungsguthaben und ohne Kreditkarte ausprobieren.
Häufig gestellte Fragen
Was kann Claude Fable 5, was ältere Modelle nicht konnten?
Kann Claude Fable 5 selbstständig Code schreiben und ausführen?
Kann Claude Fable 5 Kundensupport-Fragen bearbeiten?
Wie viel kostet der Betrieb von Claude Fable 5?
Was kann Claude Fable 5 nicht?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.