
Was Claude Sonnet 5 tatsächlich ist
Ich baue seit Jahren Integrationen und APIs, deshalb lese ich bei einem neuen Modell zuerst die Dokumentation, noch vor dem Launch-Thread. Hier ist, was Anthropics eigene Dokumentation über Claude Sonnet 5 sagt, abzüglich Marketing-Glanz.

Anthropic kündigte Sonnet 5 Ende Juni 2026 als "unser agentischstes Sonnet bisher" an und machte es zur Standardeinstellung ab dem ersten Tag für Free- und Pro-Nutzer von Claude. Es ist die ausgewogene Stufe der Claude-5-Familie. Es läuft mit einem 1-Mio.-Token-Kontextfenster und bis zu 128K Token Output, derselben Obergrenze wie die Opus-Stufe. Der Anspruch ist, speziell bei Coding- und Agenten-Aufgaben, also der Art von mehrstufiger, werkzeugnutzender Arbeit, die ein Support-Agent verrichtet, eine Qualität nahe an Opus zu erreichen, während der Betrieb weit weniger kostet. Anthropics grobe Einordnung: Sonnet 5 mit Aufwand medium ist vergleichbar mit dem vorherigen Sonnet 4.6 mit high, und Sonnet 5 mit high ist vergleichbar mit 4.6 auf max. Anders gesagt: Man bekommt mehr für dieselbe Einstellung.
Wo es sich in der Familie einordnet, ist die eigentliche Geschichte. Anthropic bietet inzwischen vier öffentliche Stufen an, und Sonnet 5 ist diejenige, die die meisten Teams tatsächlich in Produktion einsetzen werden.
Ein paar Dinge sind unter der Haube neu, und sie sind wichtiger, als die Versionsnummer vermuten lässt:
- Adaptives Denken ist standardmäßig aktiv. Man legt kein festes "Denkbudget" in Token mehr fest. Das Modell entscheidet selbst, wie viel es pro Anfrage nachdenkt, gesteuert wird das über einen
effort-Regler. xhighals Aufwandsstufe kommt in die Sonnet-Stufe. Sonnet 5 ist das erste Claude-Modell der ausgewogenen Stufe mit derxhigh-Einstellung, die Anthropic für die anspruchsvollsten Coding- und Agenten-Durchläufe empfiehlt. Es ist derselbe Regler, auf den auch Claude Code setzt.- Hochauflösendes Sehen. Sonnet 5 liest Bilder bis zu 2576px an der langen Seite, nützlich, wenn Support-Abläufe Screenshots oder Belege einbeziehen.
- Ein neuer Tokenizer. Mehr dazu weiter unten, denn er ändert die Rechnung im Stillen.
Claude Sonnet 5 Preise
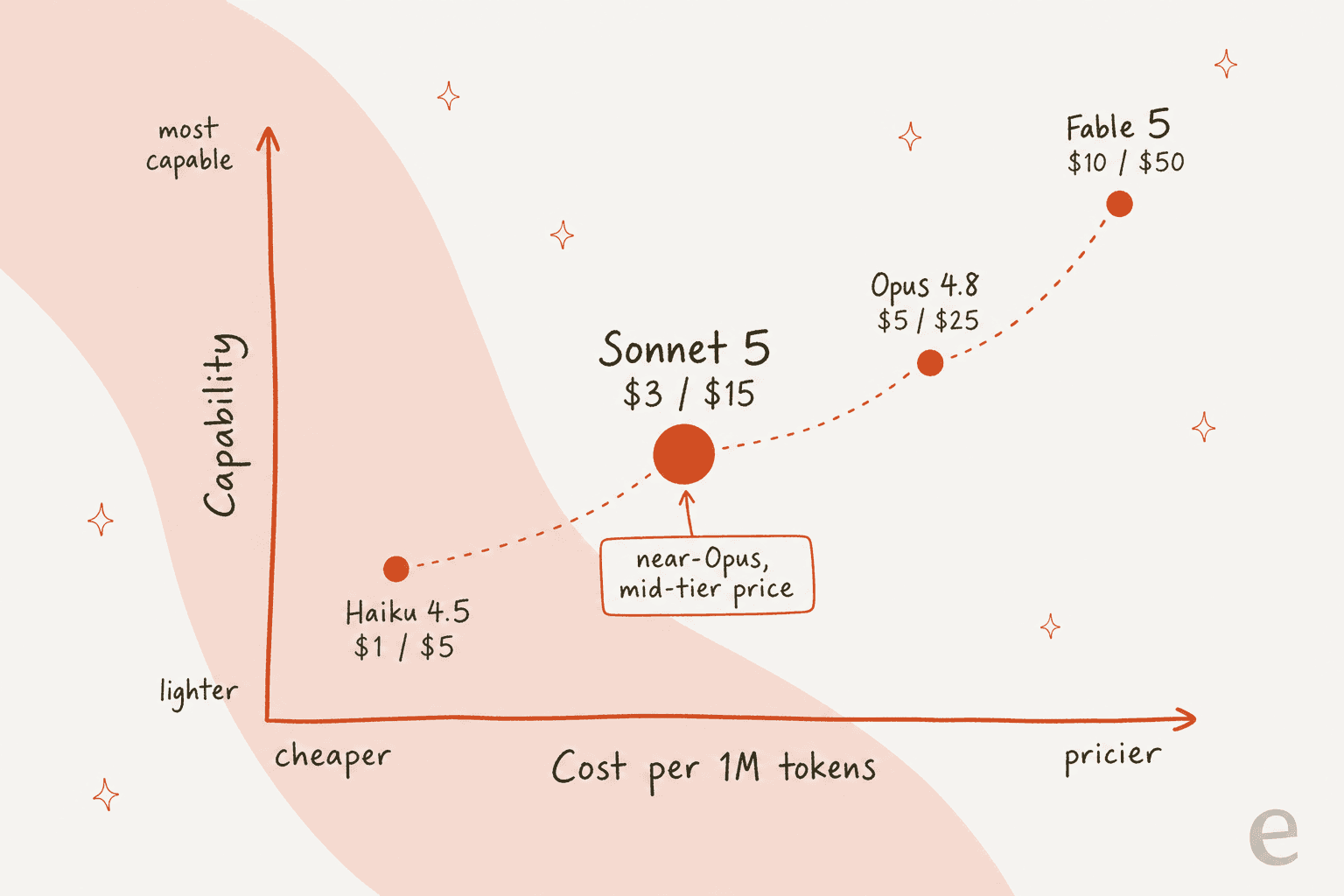
Hier kommt der Teil, für den alle eigentlich hier sind. Die API-Preise von Sonnet 5 liegen bei 3 $ pro Million Input-Token und 15 $ pro Million Output-Token, mit Einführungspreisen von 2 $/10 $ bis zum 31. August 2026. Auf der Verbraucherseite ist Sonnet die "ausgewogene" Stufe innerhalb eines Claude-Abonnements.
Im Vergleich zu seinen Geschwistern ist das Preis-Leistungs-Argument klar:
| Modell | Input ($/1M) | Output ($/1M) | Kontext | Am besten für |
|---|---|---|---|---|
| Haiku 4.5 | $1 | $5 | 200K | Schnelle, günstige, einfache Aufgaben |
| Claude Sonnet 5 | $3 (Einführung $2) | $15 (Einführung $10) | 1M | Coding und Agenten-Arbeit im großen Maßstab |
| Opus 4.8 | $5 | $25 | 1M | Anspruchsvollste, langwierige autonome Arbeit |
| Fable 5 | $10 | $50 | 1M | Das anspruchsvollste Reasoning |
Sonnet 5 ist also sowohl bei Input als auch bei Output rund 40 % günstiger als Opus 4.8, während es für die Aufgaben, die ein Support-Agent erledigt, den Großteil dessen Leistungsfähigkeit für sich beansprucht. Bei einer Warteschlange mit Millionen von Token pro Monat summiert sich diese Lücke schnell.
Es gibt jedoch einen Haken, der nicht auf der Preisliste steht. Sonnet 5 verwendet einen neuen Tokenizer, der für denselben Text rund 30 % mehr Token zählt als Sonnet 4.6. Der Preis pro Token ist niedriger, aber jede Konversation besteht jetzt aus mehr Token, sodass die tatsächlichen Kosten pro gelöstem Ticket anders ausfallen können, als eine grobe Überschlagsrechnung nahelegt.
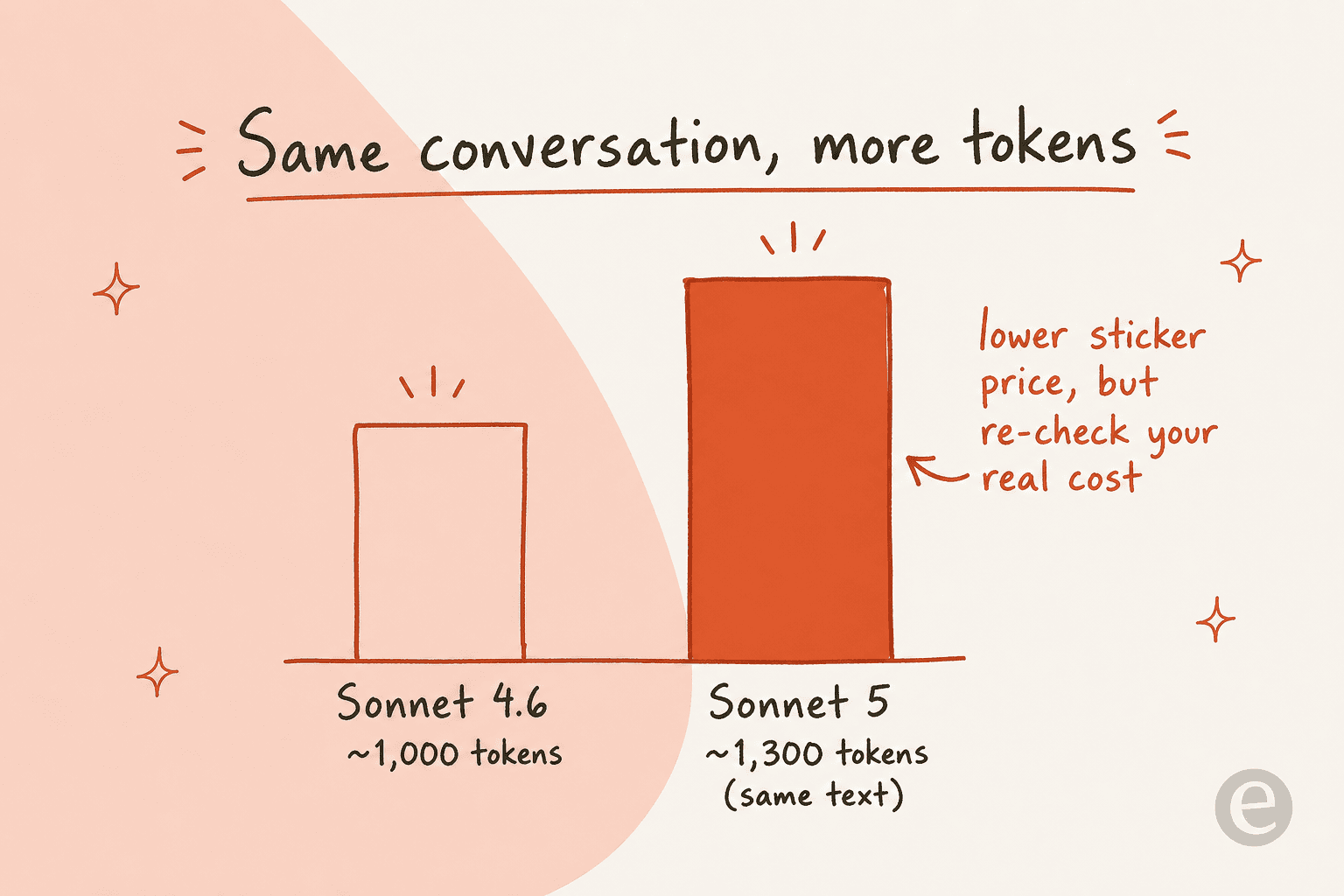
Das ist bereits die aktuelle Debatte um Sonnet 5. Befürworter nennen es Opus-Niveau zu Sonnet-Preisen, aber schärfere Einschätzungen auf X weisen darauf hin, dass die Kosten pro Aufgabe, sobald der Einführungsrabatt endet und man mit hohem Aufwand arbeitet, auf unabhängigen Indizes tatsächlich über denen von Opus 4.8 liegen können. Beides kann gleichzeitig wahr sein: Der Listenpreis ist niedriger, die Token-Zahl ist höher, und der Aufwand-Regler bestimmt die Gesamtsumme in beide Richtungen.
Die Reaktionen aus der Praxis gehen in dieselbe Richtung. In einem Thread mit frühen Eindrücken auf r/ClaudeAI (über 90 Kommentare innerhalb von Stunden nach dem Launch) eröffnete ein Entwickler genau mit dem Trade-off, um den es in diesem Beitrag geht:
"Nutze Sonnet 5 mit [xhigh]-Aufwand seit etwa 30 Minuten, hauptsächlich für Aufgaben, die ich normalerweise an Opus 4.8 delegieren würde..."
Thread mit frühen Eindrücken, r/ClaudeAI
Das ist das Signal, das man beobachten sollte: Menschen greifen bei Aufgaben zu Sonnet 5, die sie früher an Opus gegeben hätten. Ob sich das bei Ihren Tickets bestätigt, ist eine Frage, die kein Benchmark beantworten kann, und genau darum geht es im nächsten Abschnitt.
Der praktische Rat: Messen Sie den Token-Verbrauch an Ihren eigenen Tickets mit claude-sonnet-5, statt eine Zahl weiterzuverwenden, die für ein älteres Modell galt. Wer die Gesamtbetriebskosten speziell für Support modellieren will, findet im Leitfaden zu den Kosten eines AI-Support-Agenten einen besseren Ausgangspunkt als die reine Token-Rechnung, denn der Großteil der Kosten eines Support-Agenten liegt nie im Modell.
Was sich gegenüber Sonnet 4.6 geändert hat
Wer eine bestehende Integration aktualisiert, statt neu zu starten, sollte vier Dinge wissen, bevor der Modell-String umgestellt wird:
- Denken funktioniert anders. Die alte feste
budget_tokens-Steuerung gibt es bei Sonnet 5 nicht mehr. Wird die Denk-Einstellung weggelassen, läuft jetzt automatisch adaptives Denken, wo zuvor mit deaktiviertem Denken gearbeitet wurde. Wer die Einstellung nie berührt hat, wird feststellen, dass Anfragen still und heimlich mehr nachdenken (und mehr vom Output-Budget verbrauchen), also sollte man beimax_tokensetwas Spielraum einplanen. - Aufwand ist der wichtigste Regler.
highals Standard behalten und für die anspruchsvollsten Agenten-Durchläufe zuxhighgreifen. Für günstige, latenzsensible Aufgaben wie Ticket-Tagging oder Intent-Klassifizierung aufmediumoderlowreduzieren. - Die Tokenizer-Umstellung ist real. Wie oben beschrieben: Token-Zählungen neu basieren. Das ist die häufigste Art, wie eine Migration ein Finance-Team überrascht.
- Sehen wurde schärfer. Hochauflösende Bildeingabe erfolgt automatisch. Praktisch, wenn Tickets als Screenshots eingehen und triagiert werden.
Nichts davon ist dramatisch, wenn man bereits auf der Claude-API läuft. Es ist ein Austausch des Modell-Strings plus Nachjustierung, kein Neuschreiben. Die Claude Developer Platform behält dieselbe Anfragestruktur, die sie bei der Opus-4.x-Familie hatte.
Was Sonnet 5 bedeutet, wenn Sie ein Support-Team betreiben
Hier wird ein günstigeres, klügeres Modell wirklich interessant, und wirklich irreführend zugleich.
Jedes Mal, wenn ein starkes Modell erscheint, denkt eine Welle von Teams denselben Gedanken: Das Modell ist so gut und so günstig geworden, wir sollten einfach unseren eigenen Support-Bot auf der API bauen und den Anbieter überspringen. Verständlich. Als jemand, der solchen Code selbst schreibt: Einen Sonnet-5-Aufruf zu bauen, der eine Support-Frage beantwortet, ist ein zufriedenstellender Nachmittag.
Die Falle ist, dass der Modellaufruf die leichten 20 % sind. Alles, was eine AI wirklich sicher für den Einsatz bei echten Kunden macht, liegt unter der Wasseroberfläche, und nichts davon steckt in der API-Antwort.

Das ist keine Vermutung. Ich habe zugesehen, wie Kunden gingen, um direkt auf der Claude API inhouse zu bauen, und das Muster ist immer gleich: Die Demo funktioniert innerhalb einer Woche, und dann fressen sich Retrieval, Hallucination-Kontrolle, Routing und Eskalation über die nächsten sechs Monate durch. Ein technischer Lead, der sich für Kauf statt Eigenbau entschied, brachte es klar auf den Punkt:
"Wir hätten versuchen können, unsere eigene LLM-Anwendung zu schreiben, aber wir wollten unsere Zeit nicht darin investieren. Wir wollten etwas, das wir nicht selbst warten müssen."
Karel, Engineering Lead bei GENERAL BYTES
Der beängstigendste Fehlermodus ist nicht, dass ein rohes Modell eine falsche Antwort gibt. Es ist, dass es eine selbstbewusste falsche Antwort gibt. In über drei Jahren, in denen ich AI auf echten Support-Warteschlangen eingesetzt habe, ist das schlimmste Muster ein Bot, der sich seiner Sache sicher klingt und dabei still und heimlich etwas Falsches an einen Kunden weitergibt oder Arbeit erzählt, die er nie wirklich erledigt hat. Genau deshalb sollte jeder ernsthafte Rollout zunächst gegen die eigenen historischen Tickets simuliert werden, damit man die Genauigkeits- und Abdeckungszahlen sieht, bevor ein echter Kunde sie zu spüren bekommt, nicht danach. Ein Modell-Benchmark zeigt, dass die Engine schnell ist; er sagt nichts darüber aus, wie sich der eigene Bot bei den eigenen Tickets verhält.
Die ehrliche Einschätzung zu Sonnet 5 für den Support lautet also: Es macht die Engine günstiger und besser, was großartig ist, und es ändert fast nichts an den schwierigen 80 %. Ob man baut oder kauft, man sollte Zeit für die Teile einplanen, die die API nicht mitliefert: Routing, Leitplanken, Eskalation an Menschen und Tests, denn genau dort wird Kundenvertrauen tatsächlich gewonnen oder verloren.
eesel ausprobieren
Wenn die ehrliche Schlussfolgerung lautet "ich möchte Qualität auf Sonnet-5-Niveau bei meinen Tickets, ohne die restlichen 80 % selbst zu bauen", genau diese Lücke schließt eesel. Es funktioniert wie eine neue Support-Kraft, die sich in wenigen Minuten in Zendesk, Freshdesk, Gorgias, Help Scout oder Intercom einbindet und bereits Ihr Help Center und vergangene Tickets kennt.
Der Teil, der angesichts alles oben Genannten am meisten zählt: eesel lässt Sie an Tausenden Ihrer echten historischen Tickets simulieren, bevor es live geht, sodass Sie Lösungs- und Abdeckungszahlen vorab sehen, statt sie an einem echten Kunden zu entdecken. Konfidenzbasiertes Routing hält die AI bei den Tickets, die sie bewältigen kann, und übergibt den Rest an einen Menschen, das ist die Leitplanke, die aus einem cleveren Modell einen vertrauenswürdigen Teamkollegen macht. Das ist kein Benchmark, den eesel jagt; es ist der Grund, warum Teams wie Gridwise im ersten Monat 73 % der Tier-1-Anfragen gelöst haben.

Die Preisgestaltung ist nutzungsbasiert, bei etwa 0,40 $ pro bearbeitetem Ticket, ohne Kosten pro Sitzplatz und ohne Plattform-Mindestbetrag, und Sie können eesel kostenlos testen. Welches Modell auch darunterliegt, ob es heute Sonnet 5 ist oder nächstes Jahr sein Nachfolger, die Arbeit rund darum ist es, die das Ticket tatsächlich löst.
Häufig gestellte Fragen
Was ist Claude Sonnet 5?
Wie viel kostet Claude Sonnet 5?
Ist Claude Sonnet 5 besser als Opus 4.8?
Kann ich einen Kundensupport-Agenten auf Basis von Claude Sonnet 5 bauen?
Was ist der Unterschied zwischen Claude Sonnet 5 und Sonnet 4.6?
xhigh hinzu, bringt ein Upgrade auf hochauflösendes Sehen und verwendet einen neuen Tokenizer, der für denselben Text rund 30 % mehr Token zählt. Letzterer Punkt ist wichtig für die Budgetplanung, daher lohnt es sich, die tatsächlichen Kosten pro Konversation neu zu prüfen, statt alte Schätzungen weiterzuverwenden. Mehr zur Modellauswahl im Leitfaden bester AI-Chatbot.
Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.







