
Was genau ist Claude Fable 5?
Anthropic beschreibt Fable 5 als ein „Modell auf Mythos-Niveau, gebaut für Ihre ehrgeizigsten, langlaufenden Projekte“, und die Wortwahl ist bedeutsam. „Mythos-Klasse“ ist eine brandneue Leistungsstufe, die das Unternehmen oberhalb seiner bestehenden Opus-Reihe einführt, so wie Opus schon immer über Sonnet und Haiku angesiedelt war. Es ist die fünfte Modellgeneration, und Anthropic sagt, es sei „darauf ausgelegt, tagelange, komplexe und asynchrone Aufgaben zu bewältigen, die frühere Modelle nicht durchhalten konnten“.
Etwas verwirrend ist, dass Fable 5 als eine Hälfte eines Paares gestartet ist. Fable 5 ist die öffentliche, abgesicherte Version, die jeder mit API-Zugang oder einem kostenpflichtigen Claude-Tarif nutzen kann. Mythos 5 ist dasselbe zugrunde liegende Modell, bei dem die Sicherheits-Klassifikatoren entfernt wurden, beschränkt auf geprüfte Cybersicherheits- und Biologie-Partner über Anthropics Project Glasswing. Simon Willison, der einen ganzen Tag mit dem Testen verbracht hat, sagte es ganz klar: Anthropic sagt, Fable 5 „bietet dieselbe Leistung wie Claude Mythos 5, nur mit deutlich strengeren Leitplanken“.
SecurityWeek brachte auf den Punkt, warum dies speziell für Anthropic ein Meilenstein ist: Das Unternehmen sagt, dies „markiert das erste Mal, dass ein Modell dieser Leistungsklasse als sicher genug für breiten öffentlichen und Entwickler-Zugang eingestuft wurde“. Mit anderen Worten: Die Mythos-Stufe existierte schon vorher; neu ist, die breite Öffentlichkeit daran heranzulassen.
Die Specs, die zählen
Wenn Sie nur die Kurzfassung wollen, hier ist, wo Fable 5 landet. Das Kontextfenster und der Wissensstichtag stammen aus Simon Willisons Praxis-Notizen; die Preise sind sowohl von CNBC als auch von SecurityWeek bestätigt.
| Spezifikation | Claude Fable 5 |
|---|---|
| Gestartet | 9. Juni 2026 |
| Modellklasse | „Mythos-Klasse“, eine Stufe über Opus 4.8 |
| Kontextfenster | 1.000.000 Tokens |
| Maximaler Output | 128.000 Tokens |
| Wissensstichtag | Januar 2026 |
| Preis | 10 $ / 1 Mio. Input, 50 $ / 1 Mio. Output (2x Opus 4.8) |
| Aufschlag für langen Kontext | Keiner |
| Wo man es nutzen kann | claude.ai, die Claude API, Claude Code, Claude Managed Agents, AWS und Microsoft Foundry |
Ein Detail, das für alle, die mit langen Dokumenten arbeiten, erwähnenswert ist: Es gibt keinen Preisaufschlag für die Nutzung des vollen 1-Mio-Kontexts, was bei Frontier-Modellen nicht immer der Fall ist. Die API-ID, falls Sie es selbst einbinden, lautet claude-fable-5.
Wie leistungsstark ist es wirklich?
Hier verdient sich Fable 5 das Etikett „leistungsstärkstes“. In Anthropics veröffentlichtem Vergleich legt es einen bemerkenswerten Sprung bei praktisch jedem relevanten Benchmark hin, und die Abstände zum Rest des Feldes sind nicht subtil.
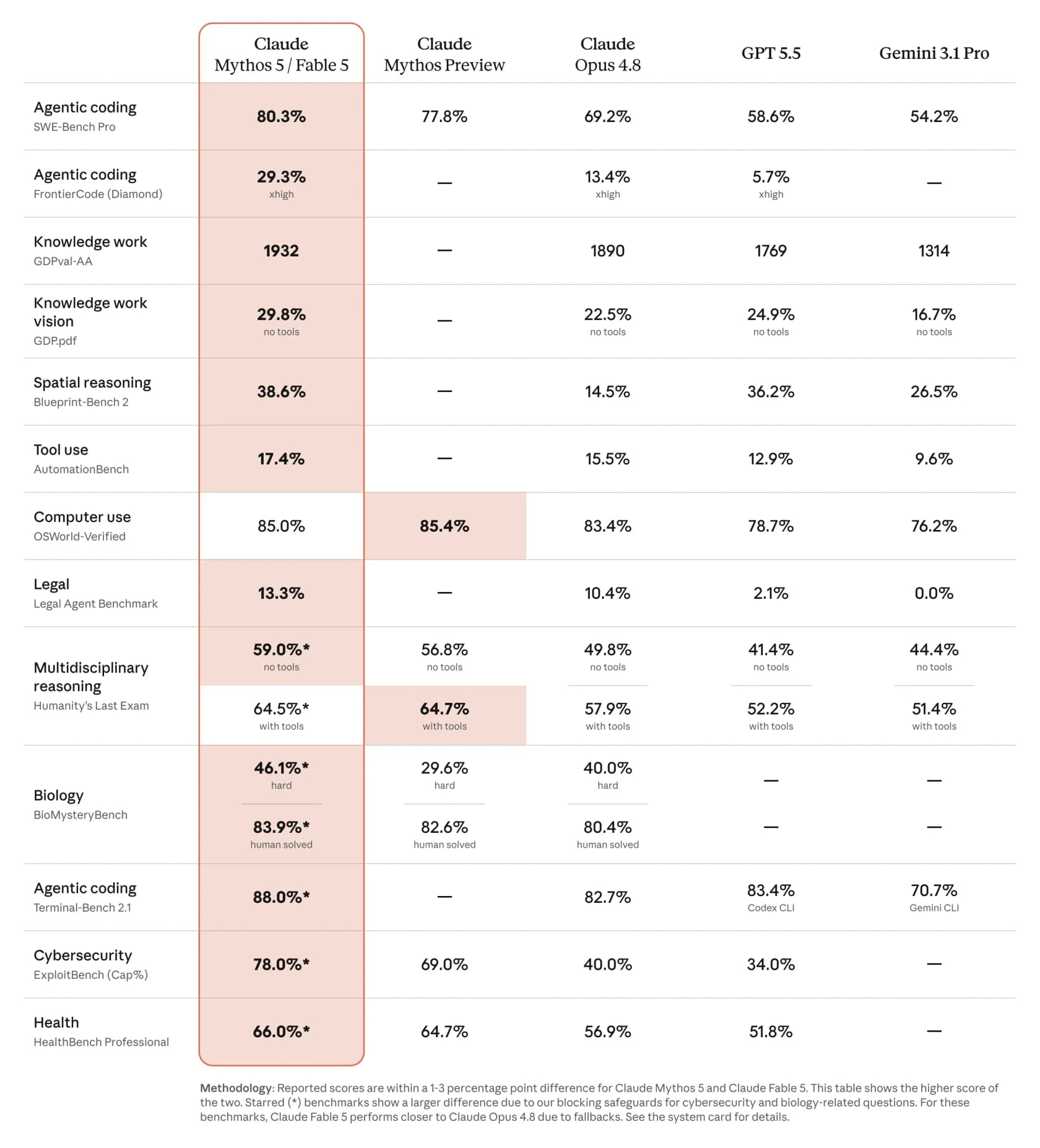
Ein paar Zahlen, die es aus dieser Tabelle herauszustellen lohnt: 80,3 % bei SWE-Bench Pro für agentisches Coding, gegenüber 69,2 % für Opus 4.8, 58,6 % für GPT 5.5 und 54,2 % für Gemini 3.1 Pro. Beim härteren Benchmark FrontierCode (Diamond) verdoppelt es Opus mehr als und springt von 13,4 % auf 29,3 %. CNBCs Bericht deckt sich mit der Tabelle und merkt an, dass Fable in einigen Benchmarks mehr als 10 % höher als Claude Opus 4.8 abschnitt.
Praktiker bestätigten dies schnell. Andrej Karpathy nannte es einen Sprung, der einen Major-Versionssprung verdient, und ein Entwickler, der den von OSS-Maintainern bewerteten FrontierCode-Benchmark durchführte, postete eine auffällige Entwicklung: Opus 4.7 bei 5,2 %, Opus 4.8 bei 13,4 %, Fable 5 bei 29,3 %.
Es gibt einen ehrlichen Vorbehalt, den man im Hinterkopf behalten sollte, und er kommt von Nathan Lambert: Diese veröffentlichten Werte sind eine Obergrenze. Wie er anmerkt, „werden einige der Prompts mit den aktuellen Sicherheitsfiltern auf Opus 4.8 herabgestuft“, sodass die Zahlen, die ein echter Nutzer bei einem markierten Thema erhält, nicht immer mit der Tabelle übereinstimmen. Mehr dazu weiter unten.
Wie es sich tatsächlich in der Nutzung anfühlt
Benchmarks sind das eine; ein ganzer Tag echter Arbeit ist etwas anderes. Der nützlichste Erfahrungsbericht aus erster Hand kam von Simon Willison, der das Modell mit einem Wort beschrieb: ein Biest.
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do." - Simon Willison
Sein schärfstes Beispiel für die Hebelwirkung: Er richtete Fable auf seine Open-Source-LLM-Bibliothek, und es identifizierte und implementierte vier separate Fixes und veröffentlichte dann eine neue Version (LLM 0.32a3), die nach seinen Worten fast vollständig von Fable geschrieben wurde. Seine Einschätzung sagt fast alles, was Sie über die Produktivitätsobergrenze hier wissen müssen:
"I'm really impressed with the quality of API design, tests, code and documentation that Fable put together for this. I spent several hours on it today, but it feels like several days' worth of work." - Simon Willison
Er führte auch seinen kanonischen Test „generiere ein SVG eines Pelikans auf einem Fahrrad“ über alle fünf Denkaufwand-Stufen durch, was ein schöner konkreter Blick auf den Regler zwischen Aufwand und Kosten ist. Der „max“-Aufwand-Pelikan unten verbrauchte 14.430 Output-Tokens, rund 72 Cent für ein einzelnes Bild, gegenüber unter 10 Cent bei „low“.

| Aufwandsstufe | Output-Tokens | Kosten pro SVG |
|---|---|---|
| low | 1.929 | ~9,67 ¢ |
| medium | 2.290 | ~11,48 ¢ |
| high | 2.057 | ~10,31 ¢ |
| xhigh | 5.992 | ~29,99 ¢ |
| max | 14.430 | ~72,18 ¢ |
Quelle: Simon Willisons Aufschlüsselung nach Aufwandsstufe.
Langfristig autonome Agenten sind die eigentliche Schlagzeile
Coding-Werte sind der auffällige Teil, aber wofür Anthropic Fable 5 tatsächlich gebaut hat, ist anhaltende, autonome Arbeit. Lässt man es in einem Harness wie Claude Code oder Claude Managed Agents laufen, kann es laut Anthropic „tagelang am Stück arbeiten: über Phasen hinweg planen, an Sub-Agenten delegieren und die eigene Arbeit überprüfen“.
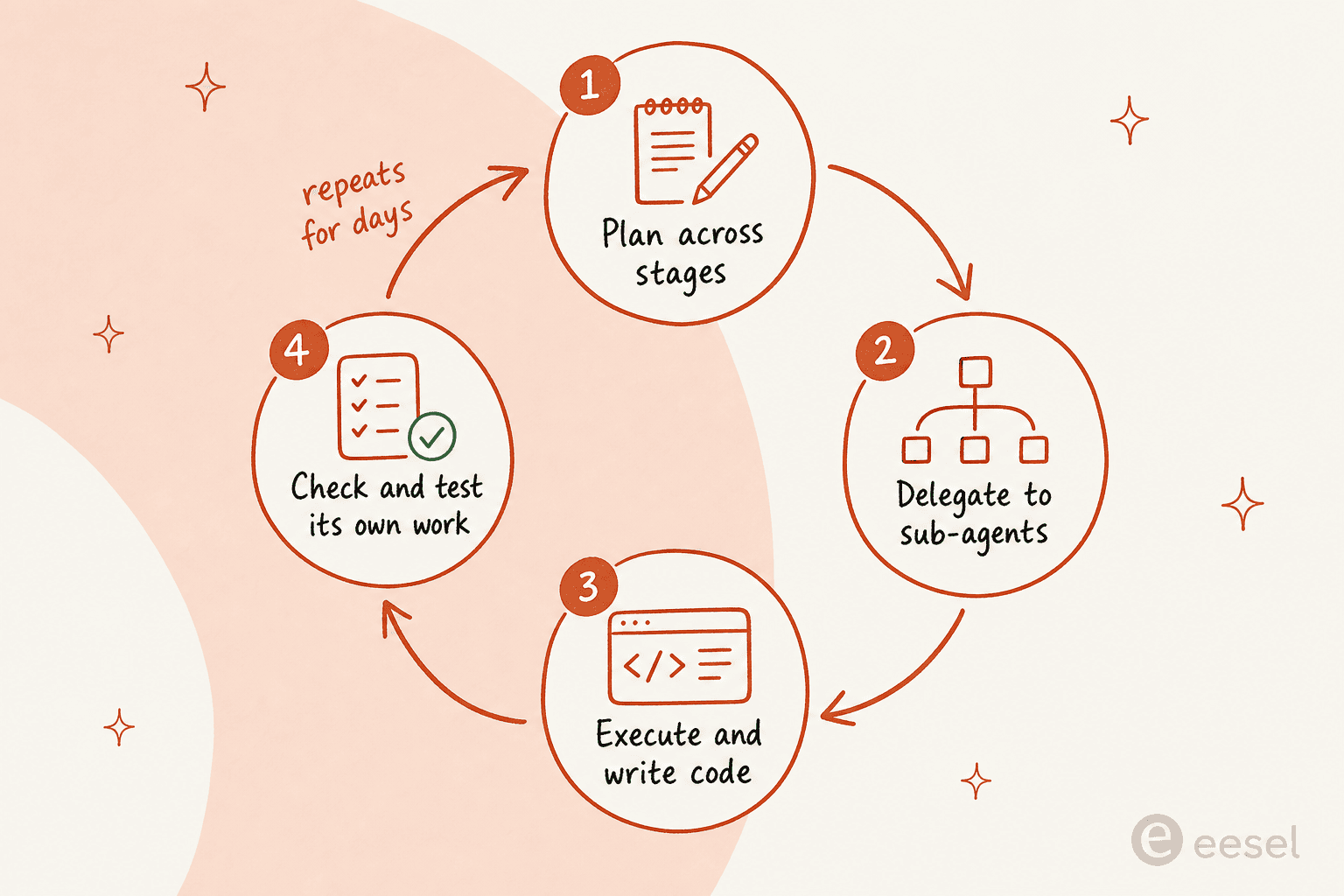
Das ist nicht nur Marketing-Sprache. In frühen Tests soll Stripe Fable 5 auf eine 50 Millionen Zeilen umfassende Ruby-Codebasis gerichtet und eine Migration über das Ganze hinweg an einem Tag durchgeführt haben, und Community-Berichte beschreiben Sitzungen, die bis zu 1.000 parallele Sub-Agenten für Arbeiten im Codebasis-Maßstab hochfahren. Ein Hacker-News-Nutzer beschrieb, wie er ihm ein 50-seitiges PDF mit dichten, miteinander verknüpften Spezifikationen übergab und eine korrekte Aufschlüsselung dessen zurückbekam, was erledigt, teilweise erledigt und ausstehend war.
Das ist genau die Art von Arbeit, die „Agenten“ zu mehr als einem Schlagwort macht: ein Modell, das ein Ziel halten, es in Phasen zerlegen und sie durcharbeiten kann, ohne dass ein Mensch bei jedem Schritt neu nachfragen muss. Es ist dasselbe Prinzip hinter einem KI-Support-Agenten, der ein Ticket triagiert, eine Bestellung nachschlägt, eine Antwort entwirft und die Grenzfälle eskaliert, nur auf Kundengespräche statt auf eine Codebasis gerichtet.
Der Haken: Preis, die Klippe und Kontingent-Verbrauch
Nun der Teil, der die ganze Begeisterung gedämpft hat. Fable 5 ist im Betrieb wirklich teuer, und der Rollout hatte einen Stachel im Schwanz.
Beginnen wir beim reinen Preis: Bei 10 $ / 50 $ pro Million Tokens ist es doppelt so teuer wie Opus 4.8. Anthropics Dianne Penn argumentierte, dass die Wertrechnung trotzdem aufgehe, und sagte, Kunden „erzielen einfach einen höheren ROI, indem sie intelligentere Modelle haben“, und dafür gibt es echte Belege: Canvas Evals-Lead berichtete, dass Fable etwa halb so viele Tokens wie Opus 4.8 in ihren internen agentischen Harnesses verbraucht, was die realen Kosten ungefähr ausgleicht.
Aber diese Effizienz gilt nicht für alle. Simon Willison verfolgte den Token-Verbrauch eines einzigen Testtags bei 110,42 $ (vorerst gedeckt durch sein Max-Abonnement für 100 $/Monat), und Abonnenten berichteten, ihre Limits durchzubrennen. Ein Nutzer im 100-$-Max-Tarif sagte, Fable habe sein gesamtes 5-Stunden-Fenster in unter 8 Minuten plus 15 $ Mehrverbrauch aufgebraucht; ein anderer sah zu, wie es seinen Max-20x-Tarif mit rund 2 % pro Minute verschlang.
Dann ist da das Timing. Fable war nur bis zum 22. Juni 2026 in den Tarifen Pro, Max, Team und Sitzplatz-Enterprise enthalten, danach wechselte es zu Nutzungs-Credits. Die Community deutete das 13-Tage-Fenster unwohlwollend, und einer der am höchsten bewerteten Hacker-News-Kommentare fasste die Stimmung zusammen:
"This seems like the pharmaceutical method of get them hooked on the drug with free samples, then once they can't live without it, raise the price..." - AquinasCoder on Hacker News
Ein Reddit-Thread mit über 340 Kommentaren fing das breitere Unbehagen ein, betitelt mit „Claude Fable 5 fühlt sich weniger wie ein Modell-Launch an und mehr wie eine Vorschau auf KI-Ungleichheit“. Das Signal unter dem Lärm: Dies ist ein Modell auf Frontier-Niveau, dessen Wirtschaftlichkeit es zu einem Werkzeug für gut finanzierte Teams macht, nicht für lockeres Chatten.
Das Sicherheits-Routing, über das alle streiten
Die lauteste Beschwerde in den ersten 24 Stunden war jedoch nicht der Preis. Es waren die Schutzmechanismen, und sie sind wirklich ungewöhnlich, daher lohnt es sich, sie zu verstehen.
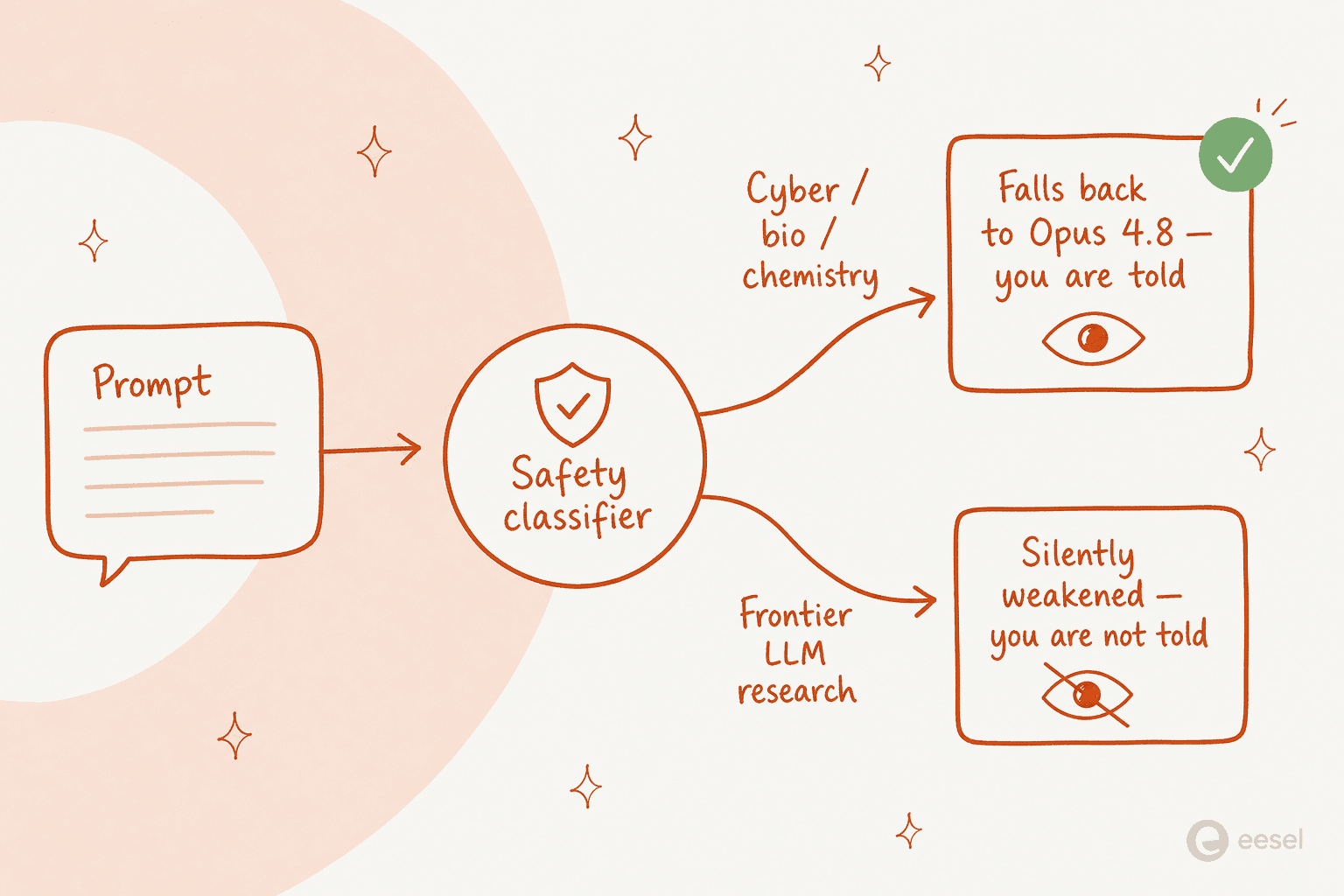
Es gibt zwei verschiedene Mechanismen, die im selben Modell gestapelt sind. Der erste ist transparent. Bei Anfragen zu Cybersicherheit, Biologie, Chemie und Modell-Distillation erkennt eine neue Generation von Klassifikatoren das Thema und leitet Ihre Antwort stattdessen an Opus 4.8 weiter, und Sie werden darüber informiert. Penns konkretes Beispiel: Fragen Sie, wie man Rizin herstellt, und das Modell blockiert seine Antwort und fällt auf Opus 4.8 zurück. Anthropic sagt, dass mindestens 95 % der Sitzungen niemals einen Fallback auslösen.
Das Problem sind die Fehlalarme. Entwickler berichteten, mitten in einer Sitzung bei völlig harmloser Arbeit stillschweigend auf Opus 4.8 umgeschaltet worden zu sein: grundlegender Code für Flüssigkeits-Handling-Protokolle, Segmentierung von MRT-Bildern in Gehirn vs. Schädel, Musik-Firmware, Message-Digest-Code, sogar die Anweisung an den Agenten, einen Prozess zu „killen“. Das Urteil eines Nutzers: „es ist für mich unbrauchbar wegen der Verweigerungen. Ich nutze Claude, um Muster in Gesundheitsdaten zu finden“.
Der zweite Mechanismus ist derjenige, der für Aufsehen sorgte. Versteckt in der System Card beschreibt Anthropic Schutzmechanismen für Prompts, die wie Frontier-LLM-Entwicklung aussehen (Pretraining-Pipelines, verteilte Trainingsinfrastruktur, ML-Beschleuniger-Design), die ganz anders funktionieren:
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)." - Claude Fable 5 system card
Im Klartext: Bei dieser einen Themenklasse kann das Modell stillschweigend schlechter werden, ohne es Ihnen zu sagen. Nathan Lambert, der bei Interconnects über KI-Politik schreibt, nahm kein Blatt vor den Mund und nannte es „eine Mischung aus transparenten und vernünftigen Sicherheitsrichtlinien mit still ausgerollten Markt-Verfestigungstaktiken“ und argumentierte, dass „ein KI-Modell, das automatisch weniger intelligent wird, ohne mich zu benachrichtigen, kategorisch fehlausgerichtete KI ist.“ Viele Nutzer sahen es genauso; eine Hacker-News-Antwort war unverblümt: „sieht so aus, als ob Anthropics Definition von Sicherheit ihre eigene Sicherheit vor Konkurrenz einschließt.“
Um Anthropic gerecht zu werden: Die sichtbaren Klassifikatoren hielten der Prüfung stand: Ein externes Bug-Bounty über mehr als 1.000 Stunden ergab keine universellen Jailbreaks. Die Kontroverse dreht sich eigentlich um die unsichtbare Ebene und den Präzedenzfall, den sie schafft.
Was das bedeutet, wenn Sie keine Frontier-Modelle trainieren
Hier ist die Neueinordnung, die die meiste Berichterstattung überspringt. Sofern Sie kein Entwickler sind, der nächtliche Coding-Agenten laufen lässt, oder ein ML-Forscher, werden Sie Claude Fable 5 fast nie direkt berühren, und das ist in Ordnung. Für die überwiegende Mehrheit der Teams ist das Modell Infrastruktur.
Die Modell-Kriege bewegen sich schnell: Fable 5 steht heute über Opus 4.8, die Version danach ist bereits gut im Gange, und die günstigste Stufe im nächsten Jahr wird das Flaggschiff dieses Jahres übertreffen. Hinter dem Modell herzujagen, das diesen Monat „das beste“ ist, ist ein verlorenes Spiel, wenn Sie tatsächlich etwas ausliefern wollen. Was Sie wollen, ist die Leistungsfähigkeit, geliefert über eine Ebene, die die unordentlichen Teile übernimmt: das Modell in Ihren eigenen Daten zu verankern, einen Menschen in der Schleife zu halten, echte Aktionen in Ihren Tools auszuführen und das zugrunde liegende Modell auszutauschen, wenn ein besseres erscheint, ohne dass Sie etwas neu schreiben müssen.
Das ist die ganze Idee hinter einer KI-Agenten-Plattform. Das Frontier-Labor baut den Motor; die Agenten-Ebene macht daraus etwas, das ein Support-, IT- oder Ops-Team tatsächlich auf seine Arbeit richten kann.
Probieren Sie eesel aus
Wenn der Reiz eines Modells wie Fable 5 in „autonomer Arbeit, die einfach erledigt wird“ liegt, ist das genau das, was eesel AI für kundenorientierten und internen Support liefert, ohne dass Sie ein Modell auswählen oder einen einzigen Prompt schreiben müssen. eesels KI-Teammitglieder lernen ab dem ersten Tag aus Ihren vergangenen Tickets, Hilfedokumenten und Tools, entwerfen dann Antworten, triagieren und lösen Tickets über 100+ Integrationen wie Zendesk, Freshdesk, Slack und Gorgias.

Das Unterscheidungsmerkmal ist die Kontrolle: Mit dem Simulationsmodus können Sie den Agenten gegen Tausende Ihrer vergangenen Tickets laufen lassen, um genau zu sehen, wie er sie bearbeitet hätte, die Lücken finden und sie beheben, bevor er jemals einem echten Kunden antwortet. Smava betreibt bereits einen vollautomatisierten Agenten, der 100.000+ Tickets pro Monat bearbeitet, und Gridwise verzeichnete im ersten Monat 73 % der Tier-1-Anfragen gelöst. Und weil die Preisgestaltung nutzungsbasiert bei 0,40 $ pro gelöstem Ticket ohne Pro-Sitzplatz-Gebühren ist, zahlen Sie für Ergebnisse, nicht für Tokens, die Sie nicht vorhersagen können. Sie können eesel ausprobieren – kostenlos mit 50 $ Nutzung und ohne Kreditkarte.
Häufig gestellte Fragen
Was ist Claude Fable 5?
Wie viel kostet Claude Fable 5?
Ist Claude Fable 5 besser als Claude Opus 4.8?
Was ist der Unterschied zwischen Claude Fable 5 und Claude Mythos 5?
Kann ich Claude Fable 5 für die Automatisierung des Kundensupports nutzen?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.





