
Ich betreibe KI auf echten Support-Queues – hier meine ehrliche Einschätzung
Ich beginne an einem Punkt, den die meisten Modell-Erklärungen auslassen, weil er derjenige ist, auf den es wirklich ankommt. Ich beobachte seit Jahren, wie Frontier-Modelle auf echte, unübersichtliche Support-Queues treffen, und das Muster ändert sich nie: Das Modell ist selten das Schwierige.
Einige Zahlen aus unseren eigenen Deployments zur Veranschaulichung. Ein Kunde, Gridwise, sah, wie eesel 73 % ihrer Tier-1-Anfragen im ersten Monat löste, mit Ergebnissen innerhalb eines 7-Tage-Tests. Ein anderer, Smava, betreibt einen vollautomatisierten Zendesk-Agenten, der über 100.000 deutschsprachige Tickets pro Monat verarbeitet. Nichts davon kam von der Wahl des cleveren Modells. Es kam vom Training auf gelösten Tickets, vom konfidenzbasierten Routing und von der Simulation auf echten Verlaufsdaten vor dem Go-live.
Wenn also ein neues Opus erscheint, interessiert mich nicht „Ist es auf einem Benchmark klüger?" Mich interessiert: „Ändert das, was ich tatsächlich in den Posteingang eines Kunden schicken würde?" Schauen wir uns Opus 4.8 durch diese Linse an.
Was ist Claude Opus 4.8?
Claude Opus 4.8 ist das neueste Modell in Anthropics Opus-Familie, dem High-Capability-Tier von Claude. Anthropic veröffentlichte es am 28. Mai 2026 und beschreibt es als einen „effektiveren Kollaborateur", der „auf Opus 4.7 aufbaut, mit Verbesserungen über alle Benchmarks hinweg." In der API rufen Sie es mit der Modell-ID claude-opus-4-8 auf.
Die wichtigsten Spezifikationen lassen sich leicht zusammenfassen: ein 1M-Token-Kontextfenster zum Standardpreis, bis zu 128k Token Ausgabe und adaptives Denken, das das Modell selbst steuert (es gibt keinen separaten Extended-Thinking-Schalter mehr). Es verarbeitet Text und Bilder, unterstützt über 80 Sprachen, und seine Trainingsdaten reichen bis Januar 2026 (Modellübersicht).
Anthropics eigene Formulierung des Sprungs ist erfrischend unaufgebauscht. Die Ankündigung nennt es eine „bescheidene, aber spürbare Verbesserung gegenüber seinem Vorgänger", was auch der Hacker-News-Thread so betitelt. Wenn Sie sich an die größeren Generationssprünge erinnern – das ist keiner davon. Es ist ein Pflege-und-Fix-Release, und das ist in Ordnung; die Fixes sind der interessante Teil.
Was ist neu in Opus 4.8
Einige Änderungen sind es wert, bekannt zu sein, besonders wenn Sie ein Modell für die Entwicklung und nicht nur zum Chatten auswählen.
Ehrlichkeit wurde wirklich verbessert. Anthropic nennt dies „eine der auffälligsten Verbesserungen", und das wäre mir tatsächlich etwas wert. Opus 4.8 soll etwa viermal seltener als 4.7 Fehler im eigenen Code unkommentiert lassen und ist eher bereit, Unsicherheiten zu kennzeichnen, anstatt selbstsicher eine Antwort zu erfinden. Für alle, die KI in einem Kontext einsetzen, in dem eine falsche Antwort Kosten verursacht: „Sagt Ihnen, wenn es sich nicht sicher ist" ist mehr wert als ein weiterer Punkt auf einem Coding-Benchmark.
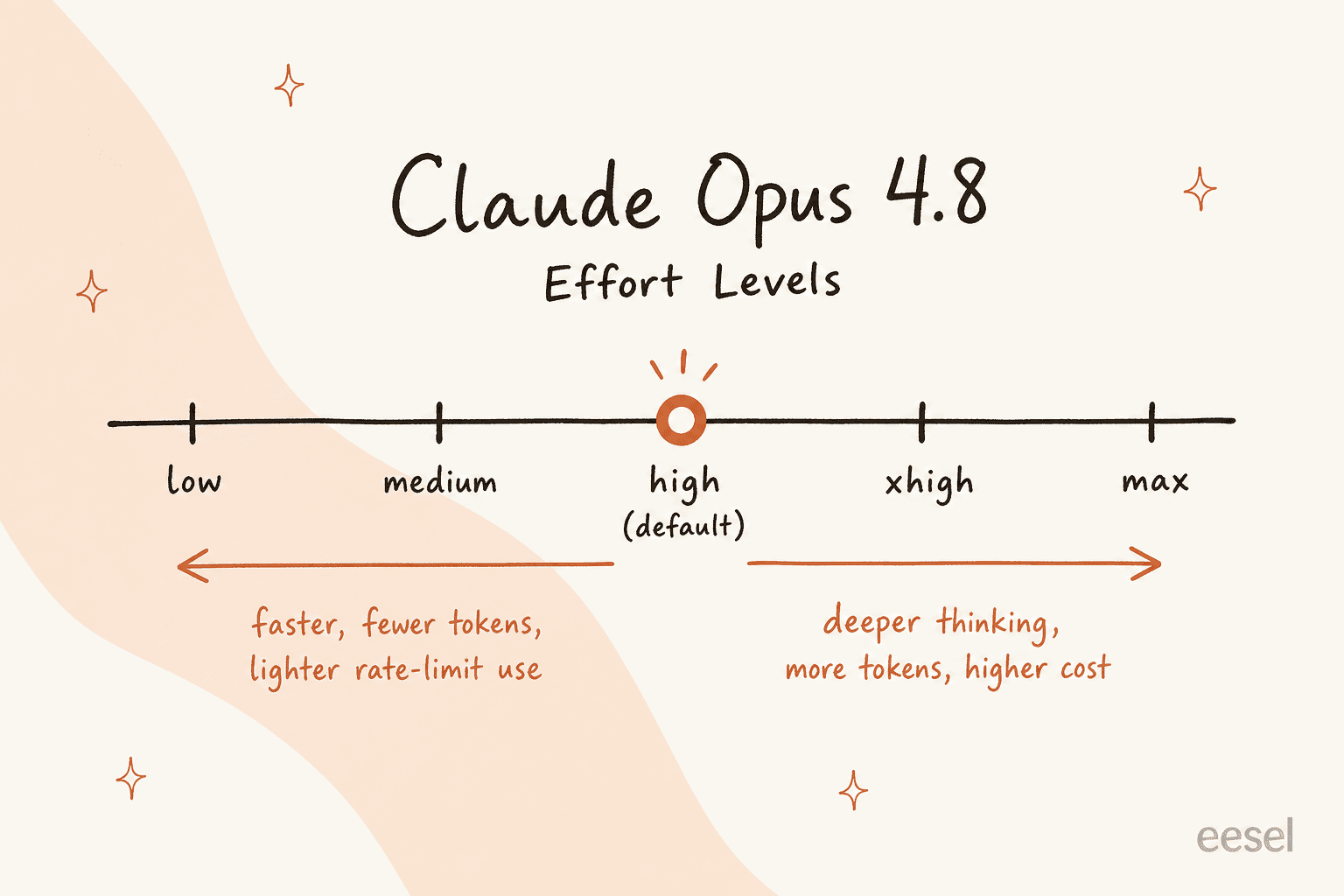
Eine Aufwandssteuerung. Es gibt jetzt einen Regler, der festlegt, wie intensiv das Modell an einer Antwort arbeitet – von low bis max (mit xhigh zwischen high und max). Der Standard ist high. Hochdrehen für tieferes Denken, Runterdrehen für Geschwindigkeit und geringere Nutzung. Der Kompromiss ist real und es lohnt sich, ihn zu verstehen, bevor Sie es in irgendetwas einbauen.
Dynamische Workflows in Claude Code. In Claude Code kann Opus 4.8 einen Auftrag planen, Hunderte paralleler Subagenten in einer Sitzung ausfahren und dann deren Ausgabe verifizieren, bevor es zurückmeldet – ausgerichtet auf Codebase-skalierte Arbeit wie Migrationen über Hunderttausende von Zeilen. Wenn Sie mit Claude Code Subagenten arbeiten, ist das das Feature zum Ausprobieren.
System-Anweisungen mitten in einer Aufgabe. Für Entwickler akzeptiert die Messages API jetzt system-Einträge innerhalb des Messages-Arrays, sodass Sie Anweisungen, Berechtigungen oder Token-Budgets mittendrin aktualisieren können, ohne Ihren Prompt-Cache zu unterbrechen. Kleine Änderung, sehr praktisch, wenn Sie Agenten bauen.
Eine wärmere Stimme. Frühe Tester beschreiben es als leichter zu kollaborieren und besser darin, Kontext und Stil über eine lange Sitzung hinweg beizubehalten. Die Kehrseite zeigt sich in der Community-Reaktion weiter unten.
Claude Opus 4.8 Preise und Einordnung
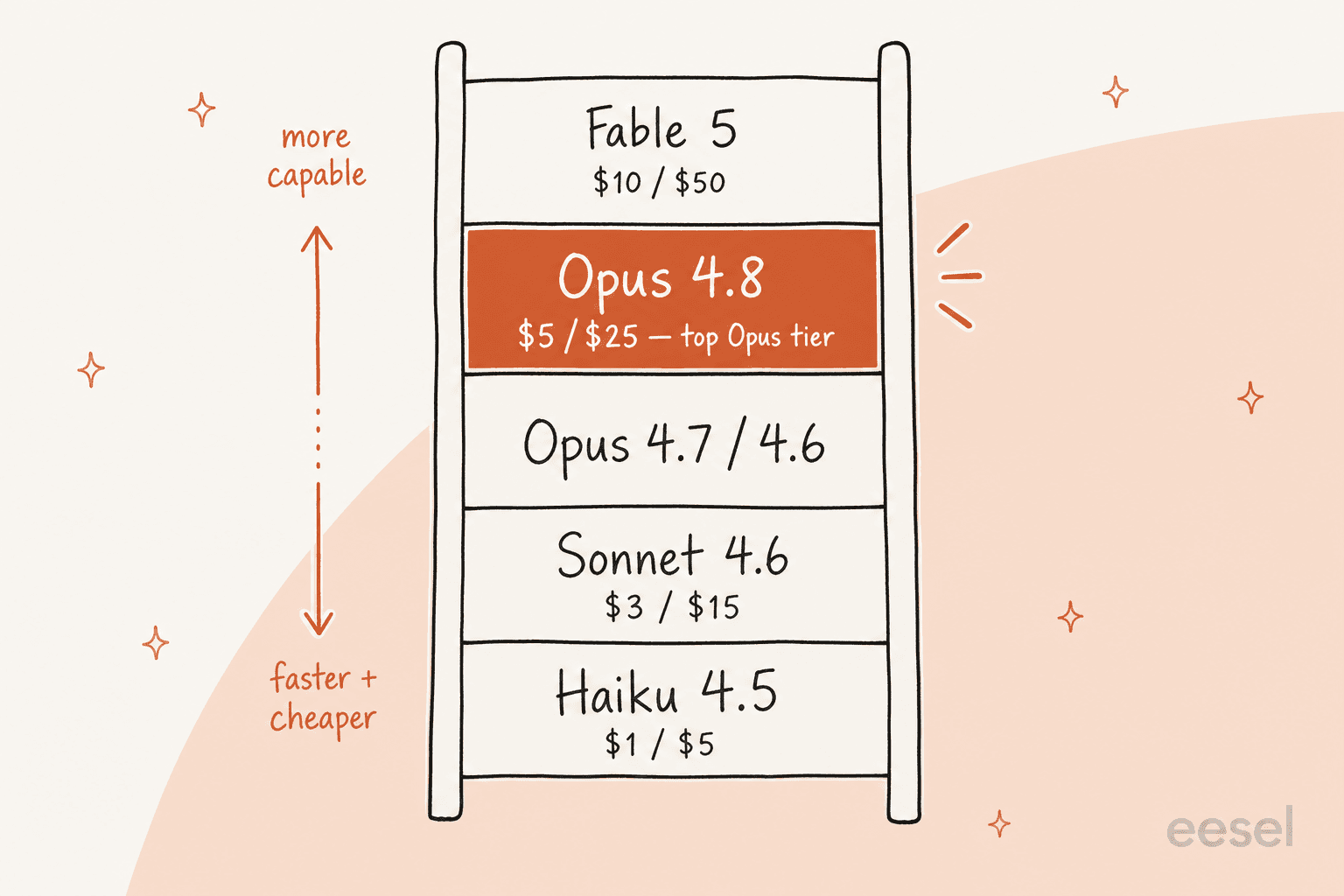
Die Preisgestaltung ist der einfache Teil, denn sie hat sich nicht verändert. Opus 4.8 kostet 5 $ pro Million Eingabe-Token und 25 $ pro Million Ausgabe-Token, genau wie Opus 4.7 (Preisseite). Es gibt auch einen schnellen Modus, der mit 2,5-facher Geschwindigkeit läuft und laut Anthropic deutlich weniger kostet als der schnelle Modus bei früheren Modellen.
Hier ist das breitere Claude-Lineup, Stand Mitte 2026 – das ist der Kontext, den Sie für eine echte Modellauswahl benötigen:
| Modell | Eingabe / Ausgabe (pro 1M Token) | Kontext | Am besten geeignet für |
|---|---|---|---|
| Claude Fable 5 | 10 $ / 50 $ | 1M | Anthropics leistungsfähigstes breit verfügbares Modell |
| Claude Opus 4.8 | 5 $ / 25 $ | 1M | Top Opus-Tier; komplexes Denken, langfristige Agenten |
| Claude Opus 4.7 / 4.6 | 5 $ / 25 $ | 1M | Die vorherigen Opus-Generationen |
| Claude Sonnet 4.6 | 3 $ / 15 $ | 1M | Bestes Gleichgewicht aus Geschwindigkeit und Intelligenz |
| Claude Haiku 4.5 | 1 $ / 5 $ | 200k | Schnellstes und günstigstes Modell für einfache Aufgaben mit hohem Volumen |
Zu beachten: Opus 4.8 ist das stärkste Opus-Tier-Modell, aber nicht mehr das Spitzenmodell des gesamten Stacks. Etwa zwei Wochen nach seinem Launch veröffentlichte Anthropic Claude Fable 5 als das leistungsfähigste breit verfügbare Modell zum doppelten Preis. Opus 4.8 ist der vernünftige High-Capability-Standard; Fable 5 ist die Option „Geld spielt keine Rolle, ich will das Allerbeste." Wir haben die vorherige Generation in Gemini 3 Pro vs. Claude Opus 4.6 direkt verglichen, wenn Sie einen Eindruck davon bekommen möchten, wie Anthropics Modelle abschneiden.
Ein Kostenfallstrick, den es wert ist, zu erwähnen, weil er Menschen überrascht: Opus 4.7 und später verwenden einen neuen Tokenizer, der „für denselben festen Text bis zu 35 % mehr Token verwenden kann." Selbst bei einem unveränderten Listenpreis können also Ihre tatsächlichen Kosten pro Aufgabe gegenüber einem älteren Modell steigen. Dieses Detail erklärt viel vom Gemurren in der Community – dazu mehr im nächsten Abschnitt. (Wenn die Preisgestaltung Ihr eigentlicher Grund zum Lesen ist, geht unser Claude-Preisleitfaden Tier für Tier vor.)
Was die Menschen tatsächlich sagen
Die klarste Einschätzung der Community-Reaktion ist, dass Opus 4.8 die Korrektur eines 4.7 ist, das die Menschen offen ablehnten. Die „Rückkehr zur Form"-Einschätzungen sind überall und decken sich mit unserem langjährigen Claude-Review. Ein Entwickler, ein paar Stunden nach dem Test auf r/ClaudeAI, brachte es gut auf den Punkt:
„4.8 ist präzise, denkt schnell und hat noch nichts halluziniert. Wenn es etwas nicht weiß, fragt es mich direkt, anstatt sich etwas auszudenken. Es fühlt sich an wie das, zu dem 4.6 hätte weiterentwickelt werden sollen."
Das stimmt mit Anthropics Ehrlichkeits-Ansprüchen überein und ist das am häufigsten wiederholte Positive. Aber zwei ehrliche Spannungen verdienen es, angesprochen zu werden, weil sie die Art von Dingen sind, die eine Marketing-Seite Ihnen nicht sagen wird.
Erstens ist es hungriger. Die häufigste Beschwerde ist, dass Opus 4.8 die Nutzungslimits schnell aufbraucht, teils dank des neuen Tokenizers. Wie ein Nutzer in einem Thread, der es mit GPT-5.5 vergleicht, anmerkte:
„Opus 4.8 ist ein Beast, weit besser als 4.7 in der Ausführung, aber auch im Design, finde ich; das eigentliche Problem sind die Token – es verbraucht viel mehr Token, und zum ersten Mal habe ich ein Limit innerhalb meines maximalen Abonnements erreicht."
Zweitens ist die Autonomie keine Magie. Power-User, die lange, schwierige Aufgaben ausführen, berichten, dass Opus 4.8 immer noch eine enge Eingrenzung benötigt, wobei ein Quant-Systems-Architekt anmerkt, dass man zum effektiven Einsatz von Opus 4.8 immer noch viel selbst nachdenken muss: mehr definieren, mehr führen und mehr Kontext selbst aufrechterhalten. Die Kehrseite der gefeierten Ehrlichkeitsgewinne ist, dass eine laute Minderheit es zu vorsichtig oder zu entschuldigend für offene kreative Arbeit findet. Das alles ist nicht vernichtend. Es ist nur das kalibrierte Bild: ein starkes, ehrliches, Token-hungriges Modell, das klare Anweisungen belohnt.
Was ein intelligenteres Modell für den Kundensupport wirklich bedeutet
Hier komme ich zu dem, was ich wirklich kenne. Wenn Sie ein Support-Team leiten, ist die Versuchung, wenn ein Modell wie Opus 4.8 erscheint, zu denken: „Toll, KI-Support ist gerade besser geworden." Manchmal schon. Aber das Modell ist der Motor, nicht das Auto, und es lohnt sich, präzise darüber zu sein, woraus KI-Kundensupport-Software wirklich besteht.
Ich habe gesehen, wie viele technisch kompetente Teams auf die harte Tour zur gleichen Schlussfolgerung kommen. Wir haben Kunden gesehen, die gegangen sind, um die Claude API selbst einzubinden, mit der Überlegung, dass sie sie bei einem so guten Opus direkt aufrufen können. Ein paar Monate später tritt die Wartungsrealität ein. Ein Engineering Lead, der sich für Kaufen entschieden hat, fasste die Kalkulation prägnant zusammen: Er könnte seine eigene LLM-Anwendung schreiben, wollte aber „keine Zeit darin investieren" und wollte „etwas, das wir nicht warten müssten."
Das liegt daran, dass ein produktiver Support-Agent das Modell plus viel unglamouröses Gerüst ist:
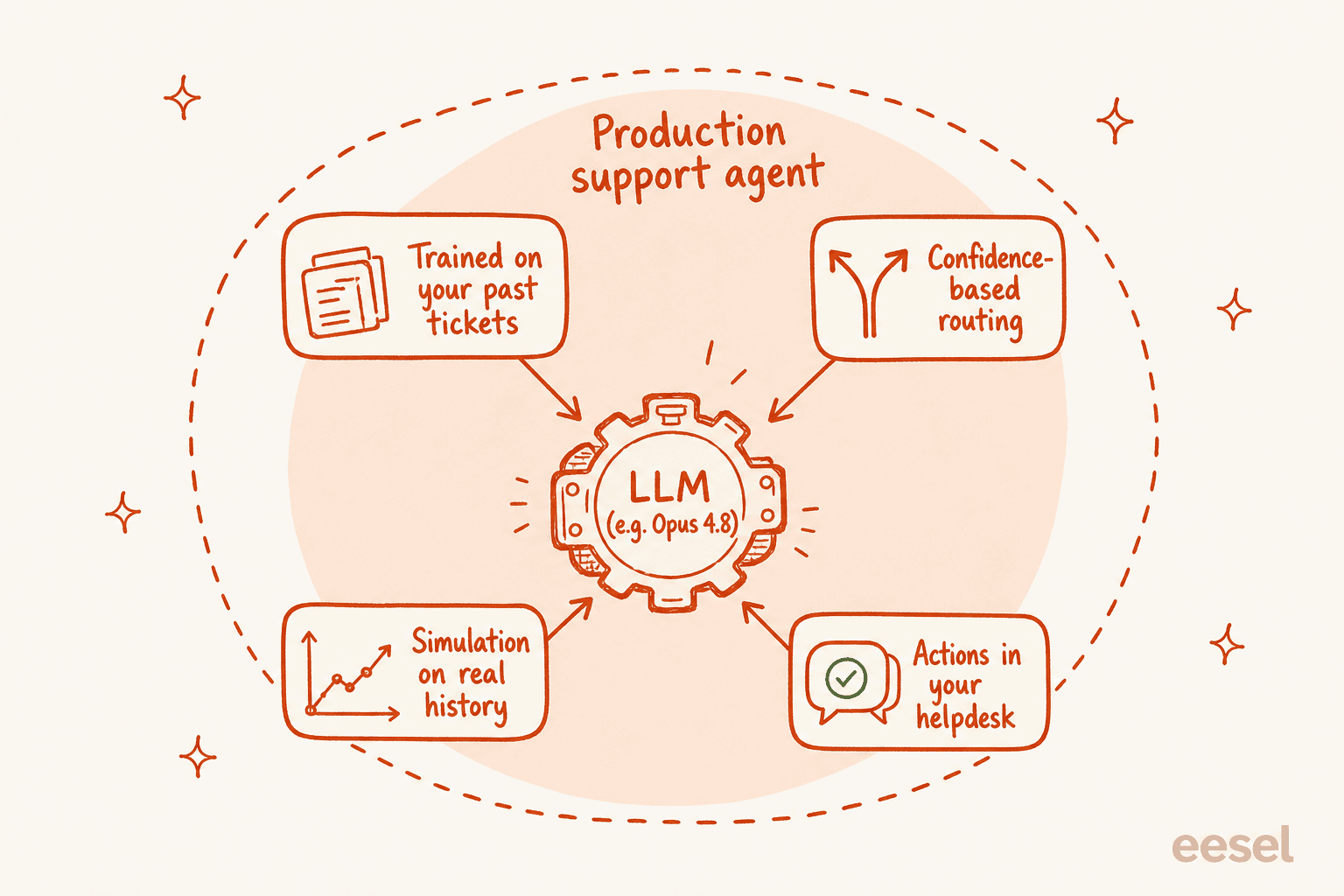
- Ihr Wissen, nicht das des Modells. Der Trainingsdatenschnitt von Opus 4.8 bis Januar 2026 weiß nichts über Ihre Rückerstattungsrichtlinie oder den Ausfall letzte Woche. Ein nützlicher Agent lernt aus Ihren vergangenen Tickets, Hilfedokumenten und Makros – nicht aus allgemeinem Weltwissen.
- Konfidenzbasiertes Routing. Die Ehrlichkeitsgewinne in Opus 4.8 sind real, aber Sie möchten trotzdem nicht, dass ein Modell selbst entscheidet, wann es live antwortet. Sie möchten, dass es entwirft, wenn es sich unsicher ist, und nur automatisch sendet, wenn es zuversichtlich ist – das ist ein systemseitiges Guardrail, keine Modelleinstellung.
- Eine Möglichkeit zum Testen vor dem Go-live. Bevor ein einziger Kunde eine KI-Antwort sieht, möchten Sie das System gegen Tausende Ihrer echten, gelösten Tickets laufen lassen und genau sehen, wo es richtig oder falsch gelegen hätte. Ein neueres Modell zu wählen gibt Ihnen das nicht; die Simulation schon.
- Aktionen, nicht nur Antworten. Markieren, Priorisieren, eine Bestellung nachschlagen, sauber an einen Menschen eskalieren. Das alles lebt in Ihren Helpdesk-Integrationen, nicht im Rohmodell.
Das ist auch der Grund, warum „welches Modell ist am besten" die falsche Frage für Support ist. Wir haben festgestellt, dass ein gut aufgebautes System auf einem mittleren Modell in der Regel ein rohes Frontier-Modell ohne Gerüst schlägt – das ist der ganze Punkt unseres Artikels über welches LLM für Support-Anwendungsfälle am besten geeignet ist. Dass Opus 4.8 ehrlicher ist, sind gute Nachrichten – es ändert nur nicht die Form der Arbeit. Wenn Sie abwägen, Ihren eigenen KI-Support aufzubauen versus eine Plattform zu kaufen: Das Modell ist der billige, einfache Teil. Der Rest ist die eigentliche Aufgabe.
Probieren Sie eesel aus
Wenn Sie bis hierher gelesen haben, interessieren Sie sich wahrscheinlich weniger für Benchmark-Deltas und mehr dafür, ob KI sicher Tickets von Ihrem Team nehmen kann. Genau das macht eesel AI: Es sitzt auf Frontier-Modellen wie Claude (sodass Sie das Opus-Klassen-Denken erhalten, ohne sich um die Infrastruktur zu kümmern), lernt aus Ihren vergangenen Tickets und Hilfedokumenten, routet nach Konfidenz, sodass es nur automatisch antwortet, wenn es sicher ist, und lässt Sie auf Ihrem echten Ticket-Verlauf simulieren, bevor es jemals mit einem Kunden spricht. Die Preisgestaltung ist nutzungsbasiert ohne Platz-Gebühren, sodass ein ruhigerer Monat weniger kostet und nicht gleichviel.

Sie können Ihren Helpdesk anschließen und eine Simulation in wenigen Minuten zum Laufen bringen. Probieren Sie eesel aus und richten Sie es auf Ihre eigenen Tickets, um zu sehen, was es tatsächlich lösen würde.
Häufig gestellte Fragen
Was ist Claude Opus 4.8?
Wie viel kostet Claude Opus 4.8?
Was ist der Unterschied zwischen Claude Opus 4.8 und Opus 4.7?
Ist Claude Opus 4.8 gut für den Kundensupport?
Sollte ich meinen eigenen Support-KI auf der Claude Opus 4.8 API aufbauen?
Wo steht Claude Opus 4.8 in Anthropics Lineup?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.





