
Ich setze KI auf echten Support-Queues ein – das ist meine Einschätzung für Unternehmen
Ich beginne dort, wo die meisten Modell-Artikel nicht beginnen, weil es die entscheidende Frage ist: Macht Opus 4.8 wirklich einen Unterschied für Ihr Unternehmen? Ich beobachte seit Jahren, wie Frontier-Modelle auf echte, unordentliche Support-Queues treffen – und die Erkenntnis ändert sich nie: Das Modell ist selten der schwierige Teil.
Zwei Zahlen zur Veranschaulichung, beide aus unseren eigenen Deployments. Gridwise sah, wie eesel 73 % ihrer Tier-1-Anfragen im ersten Monat löste, mit Ergebnissen innerhalb eines 7-Tage-Tests. Smava betreibt einen vollautomatisierten Zendesk-Agenten, der monatlich über 100.000 deutschsprachige Tickets bearbeitet. Keines dieser Ergebnisse entstand durch die Wahl des cleversten Modells. Sie entstanden durch Training auf gelösten Tickets, Routing nach Konfidenz und Simulation gegen echte Verlaufsdaten vor dem Go-live.
Wenn also ein neues Opus erscheint, ist die für Unternehmen relevante Frage nicht „Ist es bei Benchmarks klüger?", sondern „Ändert das, was ich tatsächlich in den Posteingang eines Kunden oder auf den Schreibtisch meines Teams schicken würde?". Betrachten wir Opus 4.8 mit dieser Linse.
Was Claude Opus 4.8 in Unternehmensbegriffen ist
Claude Opus 4.8 ist das neueste Modell in Anthropics Opus-Familie – der leistungsstarken Stufe von Claude. Es erschien am 28. Mai 2026 als Nachfolger von Opus 4.7, und in der API rufen Sie es als claude-opus-4-8 auf. Wenn Sie die rein erklärende Übersicht statt der Unternehmensbetrachtung suchen, haben wir einen separaten Artikel Was ist Claude Opus 4.8 verfasst.
Die für Käufer relevanten Spezifikationen: ein 1M-Token-Kontextfenster zum Standardpreis, bis zu 128k Output-Token und adaptives Denken, das das Modell selbst steuert (kein erweiterter Denk-Schalter zu verwalten). Es liest Texte und Bilder, unterstützt über 80 Sprachen, und sein Training reicht bis Januar 2026 (Modellübersicht). Anthropic macht es ab Tag eins überall verfügbar – einschließlich AWS Bedrock, Vertex AI und Microsoft Foundry – was relevant ist, wenn Ihr Einkaufsteam bereits eine bevorzugte Cloud hat.
Anthropics eigene Rahmung des Sprungs ist erfrischend unaufgeregt. Die Ankündigung bezeichnet es als „bescheidene, aber spürbare Verbesserung gegenüber dem Vorgänger" – das ist die richtige Erwartungshaltung für interne Kommunikation. Das ist ein Verbesserungs- und Fehlerkorrektur-Release, kein generationaler Sprung, und die Korrekturen sind der Unternehmenswert.
Was sich für Käufer in Opus 4.8 tatsächlich verändert hat
Einige Änderungen sind wissenswert, wenn Sie entscheiden, worauf Sie Ihr Team standardisieren – nicht nur, wenn Sie damit chatten.
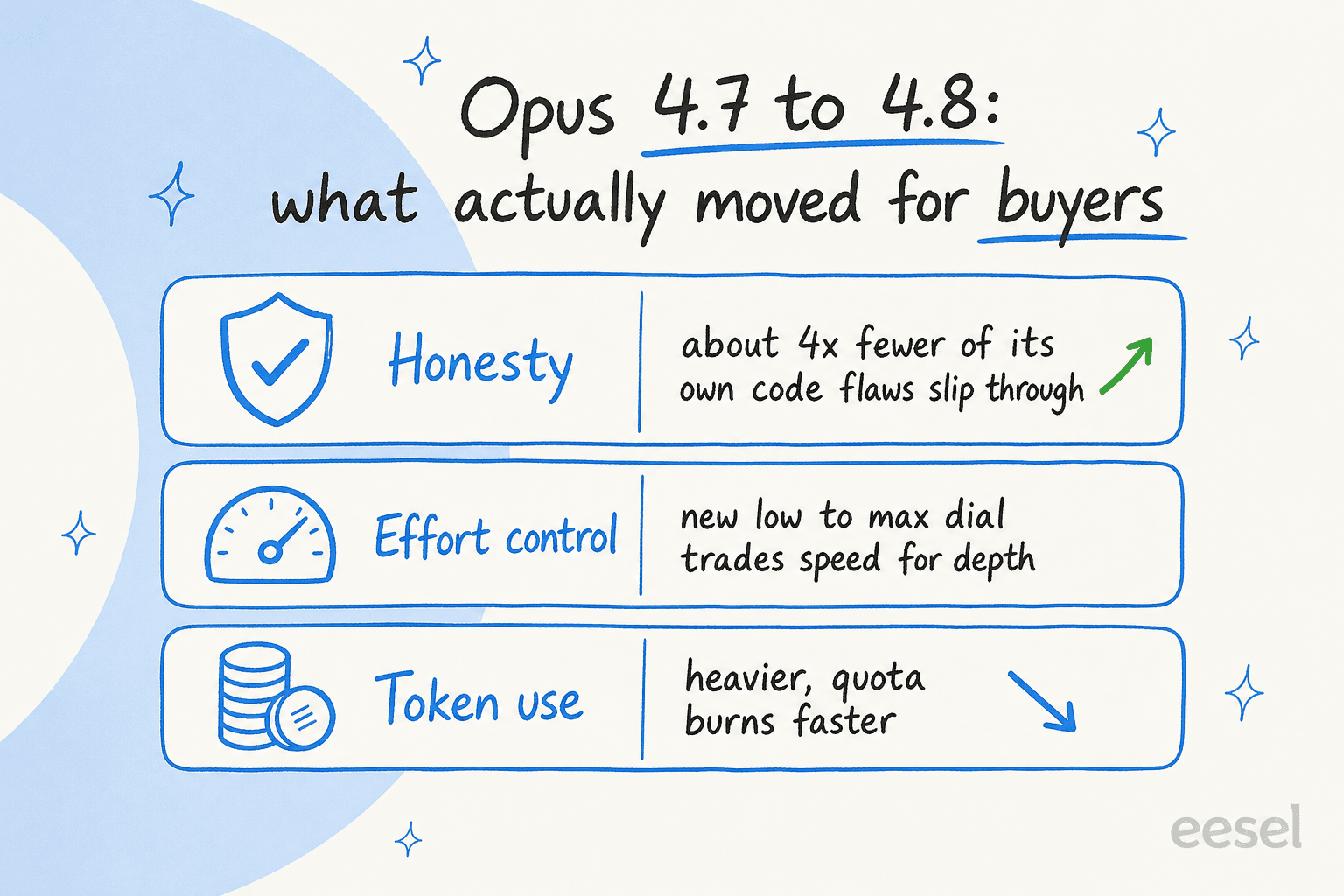
Ehrlichkeit hat ein echtes Upgrade erhalten. Anthropic bezeichnet dies als „eine der prominentesten Verbesserungen" – und das ist die Eigenschaft, für die ich im Unternehmenskontext tatsächlich zahlen würde. Opus 4.8 soll etwa viermal seltener als 4.7 Fehler im eigenen Code unkommentiert durchgehen lassen und ist eher bereit, Unsicherheit zu kennzeichnen, als selbstsicher eine Antwort zu erfinden. Überall dort, wo eine falsche Antwort Kosten verursacht – in Finanzen, Recht, reguliertem Support – schlägt „sagt Ihnen, wenn es sich nicht sicher ist" einen weiteren Punkt auf einem Coding-Benchmark.
Eine neue Aufwandssteuerung. Es gibt jetzt einen Regler, der festlegt, wie intensiv das Modell arbeitet – von low bis max, mit high als Standard (Ankündigung). Für Unternehmen ist das ein Budget-Hebel: für schwierige Analysen nach oben drehen, für Routineaufgaben mit hohem Volumen, bei denen Geschwindigkeit und Kosten wichtiger sind als Tiefe, nach unten.
Langfristige agentische Arbeit. In Claude Code kann Opus 4.8 einen Job planen, in einer Sitzung Hunderte paralleler Unteragenten ausführen und dann die Ausgabe prüfen, bevor es zurückmeldet – ausgelegt auf Arbeit im Codebase-Maßstab wie große Migrationen (dynamic-workflows-Post). Wenn Sie eine Engineering-Organisation leiten, ist das die Hauptnachricht. Die System Card besagt, die Leistung sei „Opus 4.7 in fast allen Auswertungen überlegen".
Der Haken: Es ist hungrig. Die meistgenannte Community-Beschwerde ist, dass Opus 4.8 Nutzungslimits aufbraucht, teilweise weil Opus 4.7 und spätere Versionen einen neuen Tokenizer verwenden, der „bis zu 35 % mehr Token für denselben festen Text verwenden kann". Selbst bei unverändertem Listenpreis können Ihre realen Kosten pro Aufgabe steigen. Planen Sie dafür.
Claude Opus 4.8 Preise für Unternehmen
Die Preisgestaltung ist der einfache Teil, denn sie hat sich nicht verändert. Opus 4.8 kostet 5 $ pro Million Eingabe-Token und 25 $ pro Million Ausgabe-Token – identisch mit Opus 4.7 (Preisseite). Es gibt auch einen Schnellmodus, der 2,5-fache Geschwindigkeit bietet und laut Anthropic deutlich weniger kostet als der Schnellmodus früherer Modelle.
Hier ist das breitere Angebot, wie es Mitte 2026 steht – der Kontext, den Sie benötigen, um tatsächlich ein Modell für eine Arbeitslast auszuwählen:
| Modell | Eingabe / Ausgabe (pro 1 Mio. Token) | Kontext | Am besten für |
|---|---|---|---|
| Claude Fable 5 | 10 $ / 50 $ | 1M | Anthropics fähigstes breit verfügbares Modell |
| Claude Opus 4.8 | 5 $ / 25 $ | 1M | Top Opus-Stufe; komplexes Schlussfolgern, langfristige Agenten |
| Claude Opus 4.7 / 4.6 | 5 $ / 25 $ | 1M | Die früheren Opus-Generationen |
| Claude Sonnet 4.6 | 3 $ / 15 $ | 1M | Bestes Gleichgewicht aus Geschwindigkeit und Intelligenz |
| Claude Haiku 4.5 | 1 $ / 5 $ | 200k | Am schnellsten und günstigsten für einfache Aufgaben mit hohem Volumen |
Der Hinweis für die Finanzabteilung: Der Listenpreis pro Token ist die kleinste Zeile in Ihrer tatsächlichen Rechnung. Der größte Teil der Kosten für den Produktionsbetrieb eines Modells entfällt auf alles, was drumherum gebaut wird. Das ist die Falle, in die ich Unternehmen immer wieder tappen sehe.
Wenn Preisgestaltung Ihr einziger Lesegrund ist, geht unser Claude-Preisleitfaden Stufe für Stufe vor, und Claude Pro-Preise behandelt die Pro-Sitz-Pläne, auf denen Ihr Team möglicherweise bereits ist. Für die support-spezifische Rechnung ist KI-Agent vs. menschlicher Agent-Kosten der nützlichere Vergleich als eine rohe Token-Rate.
Auf der API aufbauen oder eine Plattform kaufen?
Das ist die eigentliche Entscheidung, vor der die meisten Unternehmen stehen, wenn ein Modell wie Opus 4.8 erscheint – und die ehrliche Antwort hängt davon ab, was Sie bauen.
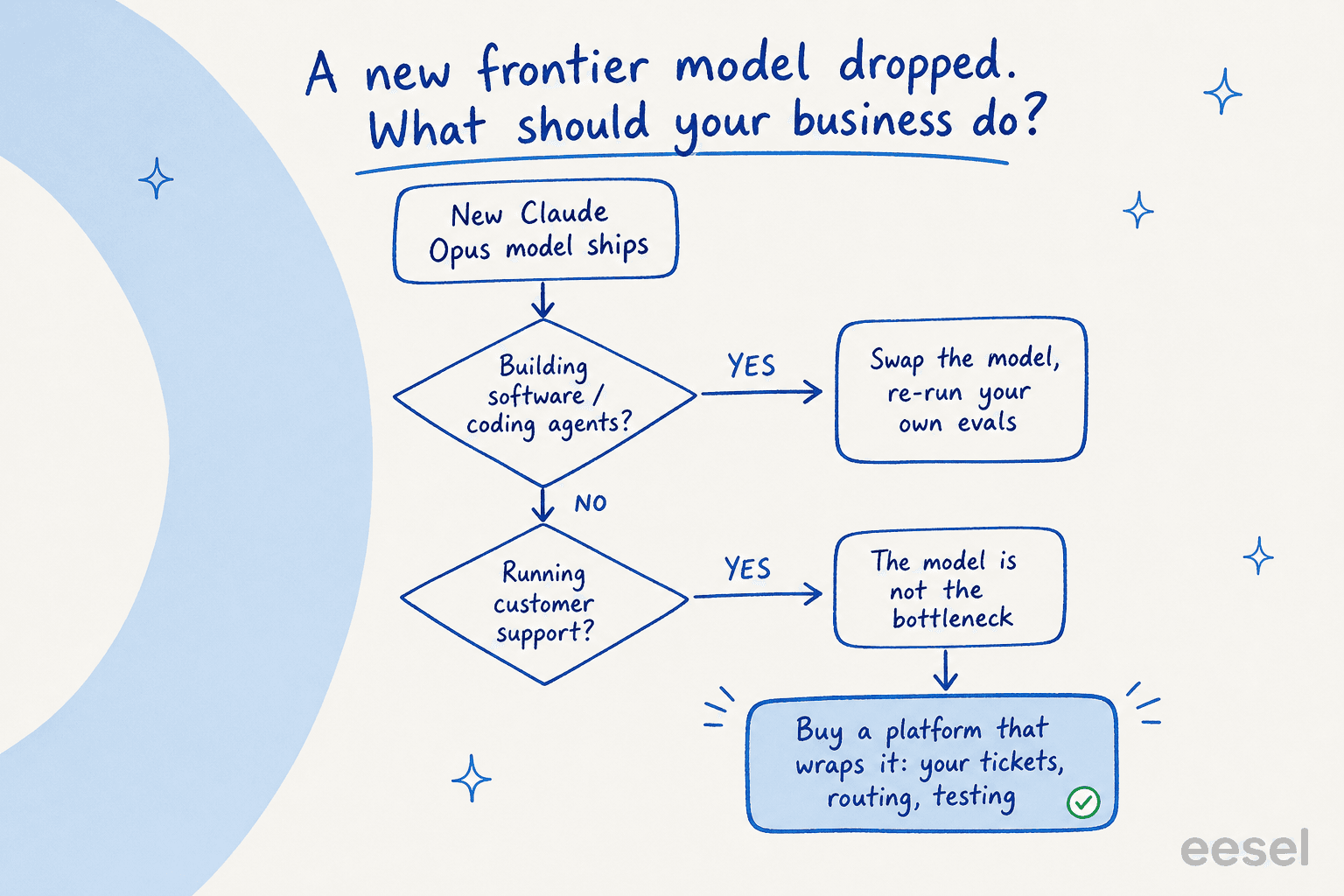
Wenn Sie ein Software-Produkt oder einen Coding-Workflow ausliefern, ist das direkte Aufbauen auf der Claude API oft die richtige Entscheidung – neues Modell einsetzen, eigene Evaluierungen neu ausführen, ausliefern. Das Modell ist dort das Produkt.
Für einen Unternehmens-Workflow wie Kundensupport ist es das Gegenteil. Ich habe viele fähige Teams beobachtet, die das auf die harte Tour herausfanden. Wir haben Kunden gesehen, die gegangen sind, um die Claude API selbst zu verkabeln, in der Annahme, dass sie bei einem so guten Opus direkt aufrufen können. Ein paar Monate später wird die Wartungsrealität deutlich. Ein Engineering-Lead, der sich für den Kauf entschied, brachte die Kalkulation auf den Punkt:
„Wir hätten versuchen können, unsere eigene LLM-Anwendung zu schreiben, aber wir wollten unsere Zeit nicht darin investieren. Wir wollten etwas, das wir nicht warten müssen."
Das stammt aus der GENERAL BYTES-Fallstudie – einem Engineering-Team bei einem Krypto-Hardware-Unternehmen, das sich für Kauf statt Eigenbau entschied. Es ist die häufigste Version der Geschichte: Der API-Aufruf ist trivial, und Retrieval, Leitplanken und Wartung sind die eigentliche Arbeit. Das gleiche Muster zeigt sich bei RAG vs. LLM-Entscheidungen – das Modell ist selten dort, wo die Arbeit liegt.
Was ein intelligenteres Modell für den Support tut (und nicht tut)
Hier komme ich zu dem, was ich tatsächlich kenne. Wenn Sie ein Support-Team leiten, liegt die Versuchung nahe, wenn Opus 4.8 erscheint, zu denken: „Toll, KI-Support ist jetzt besser." Manchmal stimmt das. Aber es lohnt sich, präzise zu sein, woraus KI-Kundenservice-Software wirklich besteht, denn ein Frontier-Modell ist nur ein Teil davon.
Ein produktiver Support-Agent ist das Modell plus viel unspektakuläres Gerüst, das Opus 4.8 schlicht nicht enthält:
- Ihr Wissen, nicht das des Modells. Opus 4.8s Trainings-Cutoff im Januar 2026 weiß nichts über Ihre Rückerstattungsrichtlinie oder den letzten Ausfall. Ein nützlicher Agent lernt aus Ihren vergangenen Tickets, Hilfedokumenten und Makros – was allgemeines Weltwissen nicht leisten kann. (Was ist RAG behandelt die Retrieval-Seite.)
- Konfidenzbasiertes Routing. Die Ehrlichkeitsgewinne in Opus 4.8 sind real, aber Sie möchten trotzdem nicht, dass ein Modell selbst entscheidet, wann es live antwortet. Sie wollen, dass es bei Unsicherheit entwirft und nur automatisch sendet, wenn es sicher ist – das ist eine systemseitige Leitplanke, keine Modelleinstellung.
- Eine Möglichkeit zum Testen vor dem Live-Betrieb. Bevor ein einziger Kunde eine KI-Antwort sieht, möchten Sie sie gegen Tausende Ihrer echten, gelösten Tickets laufen lassen und genau sehen, wo sie richtig oder falsch gelegen hätte. Ein neueres Modell gibt Ihnen das nicht; Simulation tut es.
- Saubere Eskalation und Aktionen. Tagging, Triaging, Bestellungen nachschlagen, an einen Menschen übergeben. Das liegt in Ihren Helpdesk-Integrationen, nicht im rohen Modell.
Deshalb ist „Welches Modell ist das beste?" meist die falsche Frage für ein Support-Team. Wir haben festgestellt, dass ein gut aufgebautes System auf einem mittleren Modell oft ein rohes Frontier-Modell ohne Gerüst übertrifft – das ist das gesamte Argument in welcher LLM ist der beste für Support-Anwendungsfälle. Dass Opus 4.8 ehrlicher ist, ist gute Neuigkeit – es ändert nur nicht die Form der Arbeit oder bewegt die Lösungsrate von allein. Wenn Sie zwischen der besten KI für Kundenservice abwägen oder sich Claude-Alternativen für einen Workflow ansehen, ist das Modell der günstige, einfache Teil. Der Rest ist die eigentliche Arbeit.
Eine Offenlegung, da es nur fair ist: Wir bauen auf Frontier-Modellen wie Claude auf, also habe ich hier ein Eigeninteresse. Das ist auch der Grund, warum ich sicher bin, dass das Modell nicht der entscheidende Vorteil ist – ich habe den Unterschied gesehen, den ein gut aufgebautes System bei Hunderten von Teams, die KI für Kundendienst nutzen, macht.
eesel ausprobieren
Wenn Sie bis hierher gelesen haben, interessieren Sie sich wahrscheinlich weniger für Benchmark-Deltas und mehr dafür, ob KI sicher Arbeit von den Schultern Ihres Teams nehmen kann. Das ist es, was eesel AI leistet: Es sitzt auf Frontier-Modellen wie Claude auf (damit Sie Opus-Klasse-Reasoning erhalten, ohne die Infrastruktur zu besitzen), lernt aus Ihren vergangenen Tickets und Hilfedokumenten, routet nach Konfidenz, sodass es nur automatisch antwortet, wenn es sicher ist, und ermöglicht Ihnen, auf Ihrem echten Ticket-Verlauf zu simulieren, bevor es jemals mit einem Kunden spricht. Die Preisgestaltung ist nutzungsbasiert ohne Pro-Sitz-Gebühren, sodass ein ruhigerer Monat weniger kostet.

Sie können Ihren Helpdesk verbinden und innerhalb von Minuten eine Simulation laufen lassen. Probieren Sie eesel und zeigen Sie es auf Ihre eigenen Tickets, um zu sehen, was es tatsächlich lösen würde – kein klügeres Modell erforderlich.
Häufig gestellte Fragen
Ist Claude Opus 4.8 für den Unternehmenseinsatz geeignet?
Was kostet Claude Opus 4.8 für ein Unternehmen?
Sollte mein Unternehmen auf der Claude Opus 4.8 API aufbauen oder eine Plattform kaufen?
Was hat sich in Claude Opus 4.8 gegenüber Opus 4.7 geändert?
Kann Claude Opus 4.8 meinen Kundensupport eigenständig abwickeln?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








