
Was ist Claude Fable 5?
Claude Fable 5 ist Anthropics fünfte Modellgeneration und die öffentliche Hälfte eines Zwei-Modell-Paars (das andere, Mythos 5, ist dasselbe Modell mit entfernten Schutzmechanismen, beschränkt auf geprüfte Forschungspartner). Anthropic bewirbt es als „ein Modell auf Mythos-Niveau, gebaut für Ihre ehrgeizigsten, langlaufenden Projekte“, entworfen, um „tagelange, komplexe und asynchrone Aufgaben zu bewältigen, die frühere Modelle nicht durchhalten konnten.“
Hier ist, was zählt, sobald man den Lärm des Launch-Tags ausblendet:
- Es steht an der Spitze der Leiter. Fable 5 steht über Opus 4.8, das über Sonnet 4.6 steht. Wenn Sie unseren Claude-Überblick gelesen haben: Dies ist die neue Obergrenze.
- Es kostet doppelt so viel wie Opus. 10 $ pro Million Input-Token, 50 $ pro Million Output, genau 2x von Opus 4.8s 5 $ / 25 $. Zwischengespeicherte Input-Token erhalten einen Rabatt von 90 %, und US-only-Inferenz trägt einen Aufschlag von 1,1x.
- Es ist groß. Ein Kontextfenster von 1.000.000 Token, 128.000 maximale Output-Token und ein Wissensstand bis Januar 2026.
- Es ist überall. Verfügbar auf claude.ai, der Claude API, Amazon Bedrock und Claude Platform on AWS und Microsoft Foundry, dazu Claude Code und Claude Managed Agents.
Die Benchmark-Geschichte untermauert den Hype, zumindest auf dem Papier. Anthropics eigener Vergleich stellt Fable 5 weit vor den Rest der Frontier:
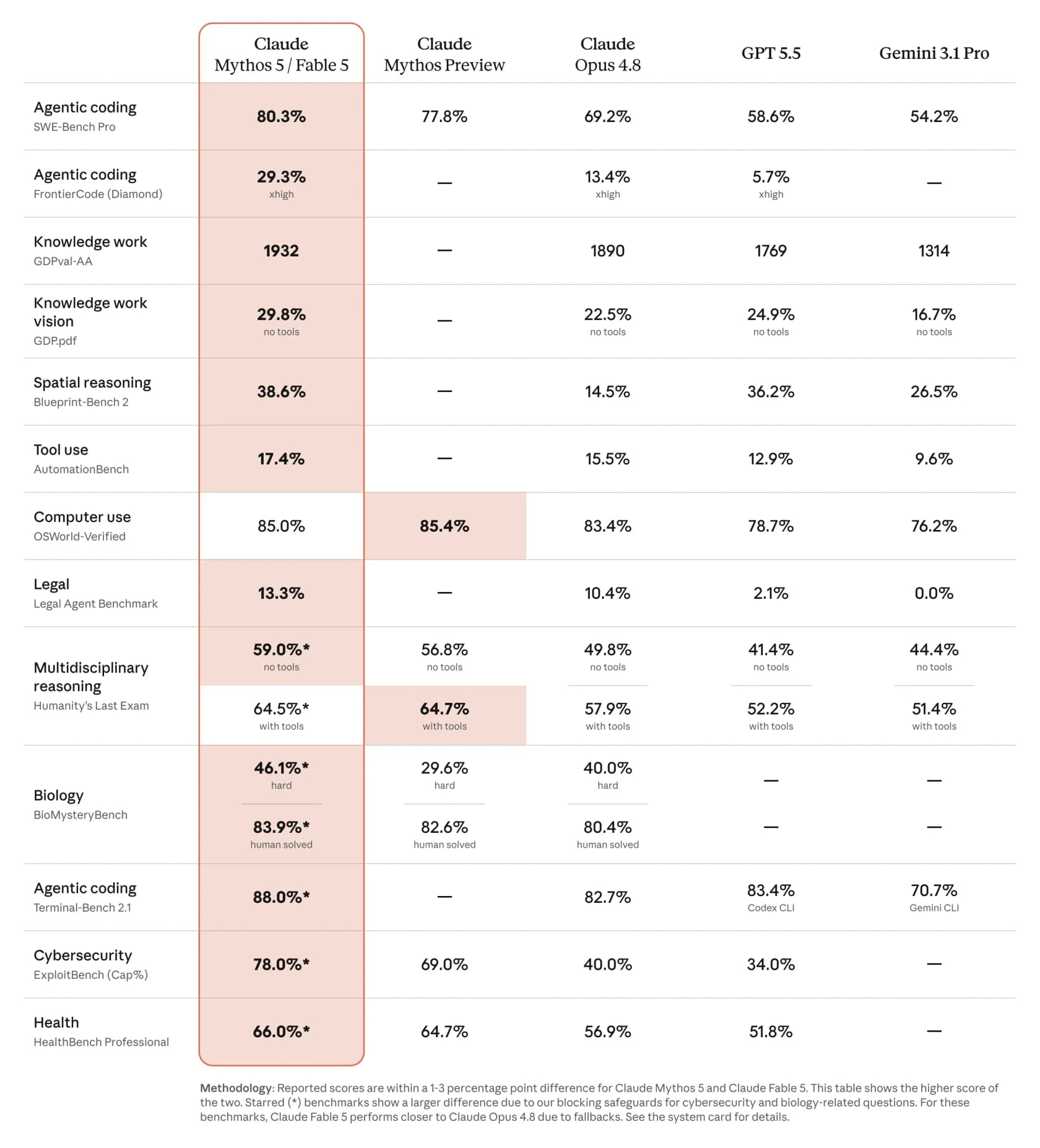
Bei SWE-Bench Pro (agentisches Coding) erreicht Fable 5 80,3 % gegenüber Opus 4.8s 69,2 %, mit GPT 5.5 bei 58,6 % und Gemini 3.1 Pro bei 54,2 %. CNBC bezifferte den Abstand bei einigen Benchmarks als „mehr als 10 % höher als Claude Opus 4.8“. Echte Zahlen, echter Vorsprung. Der Haken ist, was es kostet, sie zu bekommen, worauf wir noch zurückkommen.
Was es für Unternehmen tatsächlich anders macht
Viele Modell-Launches sind ein paar Benchmark-Punkte und eine Pressemitteilung. Fable 5 macht etwas Spezifischeres: Es ist gebaut, um lange zu laufen, ohne auseinanderzufallen. Das ist die Fähigkeit, die für Unternehmen zählen sollte, nicht das Leaderboard.
Es kann tagelang arbeiten, nicht minutenlang
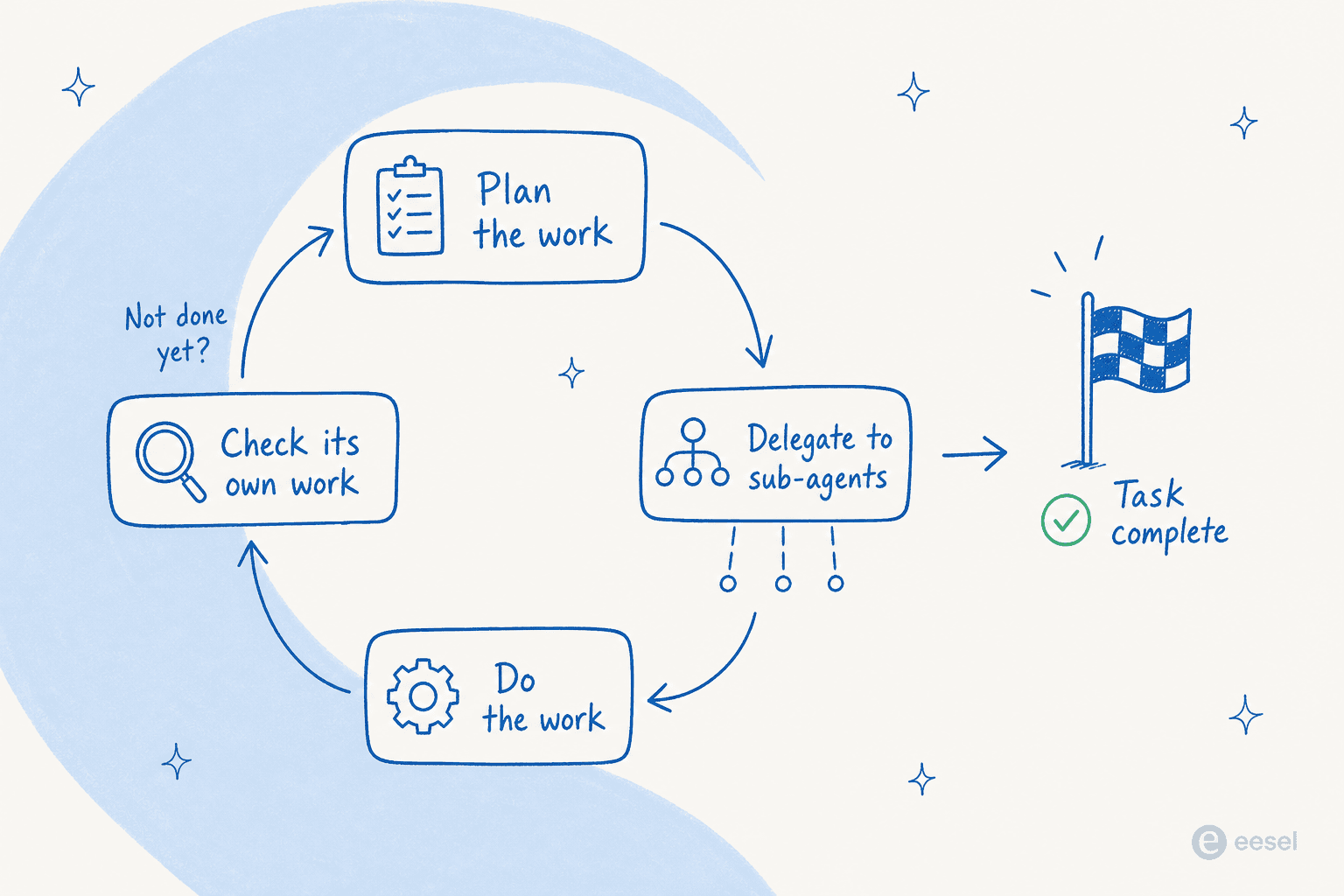
Der zentrale Anwendungsfall ist langfristige autonome Arbeit. Lassen Sie Fable 5 in einem Agenten-Harness wie Claude Code oder Claude Managed Agents laufen, und in Anthropics Worten „kann es tagelang am Stück arbeiten: über Phasen hinweg planen, an Sub-Agenten delegieren und seine eigene Arbeit überprüfen.“ Stripe richtete es auf eine 50 Millionen Zeilen umfassende Ruby-Codebasis und führte an einem Tag eine Migration über das Ganze durch.
Diese Schleife — planen, delegieren, arbeiten, überprüfen, wiederholen — ist der Teil, der wirklich neu ist. Frühere Modelle gaben bei mehrstufigen Aufgaben auf; dieses hält die Spur.
Unabhängige Tests bestätigen das Marketing. Der Entwickler Simon Willison verbrachte fünfeinhalb Stunden damit und kam zu dem Schluss:
„This is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do.“
Es liest die unübersichtlichen Dokumente, die Ihr Team tatsächlich hat
Fable 5 „versteht Diagramme, Charts und Tabellen, die in Dateien und PDFs verschachtelt sind,“ was Anthropic rund um Finanz-, Rechts- und Analysearbeit positioniert. Ein Hacker-News-Nutzer berichtete, dass es über ein 50-seitiges PDF mit dichten, miteinander verbundenen Spezifikationen korrekt „erledigt / teilweise erledigt / fehlend“ markierte. Für jedes Unternehmen, das auf einem Stapel von Verträgen, Spezifikationsblättern oder Richtliniendokumenten sitzt, ist das nützlicher als ein weiterer Punkt auf einem Coding-Benchmark.
Es testet seine eigene Arbeit
Anthropic bewirbt Fable als „gründlich, proaktiv und testet seine eigene Arbeit,“ und die Cloud-Anbieter beschreiben eine eingebaute Plan- / Check- / Refine-Schleife. Selbstkorrektur ist der Unterschied zwischen einem Agenten, den Sie bewachen müssen, und einem, den Sie allein lassen können, was genau das ist, was zählt, wenn Sie echte Arbeit automatisieren.
Der Haken, den niemand auf die Landingpage schreibt
Hier würden wir auf die Bremse treten. Fable 5 ist leistungsstark, aber die ersten 24 Stunden des realen Einsatzes brachten einige sehr praktische Probleme zum Vorschein, und sie kosten alle Geld.
Es verbrennt Budget schnell. Simon Willison verzeichnete einen einzigen Testtag mit 110,42 $ an Token-Ausgaben. Ein Nutzer mit Max-Plan schöpfte sein 5-Stunden-Nutzungslimit in 20 Minuten aus, während er 1.000 Subagenten laufen ließ; ein anderer verbrauchte ein ganzes 5-Stunden-Fenster in unter 8 Minuten plus 15 $ Überschreitung. Wenn ein Modell doppelt so teuer ist und pro Aufgabe viel härter arbeitet, summiert sich die Rechnung schnell.
Fairerweise gibt es auch eine Gegen-Erzählung, die man im Kopf behalten sollte: Der Evaluierungsleiter von Canva stellte fest, dass Fable etwa die Hälfte der Token von Opus 4.8 in ihren internen agentischen Harnessen verbrauchte, sodass die realen Kosten ungefähr gleich landen können, sobald man die Effizienz berücksichtigt. Die Lehre ist nicht „Fable ist unbezahlbar“, sondern „Ihre Kosten hängen vollständig davon ab, wie Sie es betreiben“.
Sein Sicherheits-Routing kann fehlzünden. Bei Themen aus Cybersicherheit, Biologie und Chemie betreibt Fable Klassifikatoren, die die Antwort stillschweigend stattdessen an Opus 4.8 umleiten. Anthropic sagt, dass mindestens 95 % der Sitzungen vollständig auf Fable ohne jeglichen Fallback laufen, aber die 5 % umfassen auch falsch-positive Treffer — ein Nutzer in der Laborautomatisierung wurde bei einem grundlegenden Flüssigkeitshandhabungsprotokoll abgewiesen, obwohl nichts Riskantes daran war. Wenn Ihr Unternehmen in einer technischen Branche tätig ist, testen Sie, bevor Sie sich festlegen.
Der Preis, den Sie heute sehen, hält vielleicht nicht. Fable ist auf den Plänen Pro, Max, Team und seat-Enterprise nur bis zum 22. Juni 2026 kostenlos, danach wechselt es zu Nutzungs-Credits. Bauen Sie Ihren Workflow unter Annahme des gemessenen Preises auf, nicht der Launch-Aktion.
Nichts davon macht Fable 5 zu einem schlechten Modell. Es macht es zu einem Frontier-Werkzeug mit Frontier-Werkzeug-Ökonomie, und das hat direkte Konsequenzen dafür, wie man es tatsächlich einsetzen würde.
Was Claude Fable 5 für den Kundensupport bedeutet
Hier sind wir zu Hause, also seien wir konkret. Wenn Sie ein Support-Team leiten, sollten Sie sich für Fable 5 interessieren?
Größtenteils: nicht so sehr, wie der Hype suggeriert. Hier ist die unbequeme Wahrheit über KI für den Kundenservice: Bei Tier-1-Tickets ist das Modell selten der Flaschenhals. Ein gut verankertes Opus 4.8 oder sogar Sonnet 4.6 beantwortet bereits die überwältigende Mehrheit der Fragen wie „wo ist meine Bestellung“, „wie setze ich mein Passwort zurück“, „wie lautet Ihre Rückerstattungsrichtlinie“ korrekt. Das Doppelte für Fable 5 zu zahlen, um sie zu beantworten, ist, als würde man einen Formel-1-Wagen für die Fahrt zur Schule mieten.
Was tatsächlich darüber entscheidet, ob Ihr KI-Helpdesk-Agent funktioniert, ist alles rund um das Modell:
- Kennt es Ihr Unternehmen? Ein Modell ist nur so gut wie das, worin es verankert ist. Der Gewinn kommt vom Training auf Ihren vergangenen Tickets und Hilfedokumenten, nicht von einem klügeren Basismodell.
- Weiß es, wann es schweigen soll? Rohe Modelle antworten selbstbewusst, auch wenn sie falsch liegen, was genau der Grund ist, warum Chatbots schlechte Antworten geben. Produktionsreife Agenten brauchen ein konfidenzbasiertes Routing, damit Fragen mit niedriger Konfidenz entworfen oder eskaliert und nicht automatisch gesendet werden.
- Können Sie ihm vertrauen, bevor es live geht? Sie müssen die Fehlerrate auf Ihren eigenen Tickets zuerst sehen, nicht vor den Augen der Kunden entdecken.
Dieser letzte Punkt ist derjenige, der den Käufern am wichtigsten ist. Die Support-Verantwortlichen, mit denen wir sprechen, fragen nicht nach einer KI, die alles beantwortet; sie fragen nach einer, die ihre Grenzen kennt. Wie es eine CX-Leiterin eines DTC-Nahrungsergänzungsmittel-Unternehmens in einem Kundeninterview ausdrückte: Die KI wird nie 100 % der Fragen beantworten, also wollen sie eigentlich einen Agenten, der nur die Tickets bearbeitet, bei denen er sich sicher ist, und den Rest in Ruhe lässt. Das ist eine Produktfähigkeit, keine Modellfähigkeit.
Fable 5 löst nichts davon für Sie. Ein rohes Modell ohne Retrieval, ohne Routing und ohne Tests ist ein selbstbewusster Praktikant mit Zugriff auf Ihren Antwort-Button. Die Modellstufe ist Ihre geringste Sorge.
Build vs. Buy: Sollten Sie Fable 5 selbst einbinden?
Das ist die eigentliche Entscheidung für ein Unternehmen, und sie kommt ständig auf. „Anthropic hat gerade ein unglaubliches Modell veröffentlicht, warum bauen wir unseren Support-Bot nicht einfach auf der API?“
Sie können. Es ist auch ein größeres Projekt, als es aussieht. Das Modell gibt Ihnen Intelligenz. Es gibt Ihnen nicht die Verbindung zu Ihrem Helpdesk, die Schutzmechanismen, die Simulationsumgebung, die Berichte oder die laufende Wartung. All das ist Ihre Sache, sie zu bauen und zu besitzen.
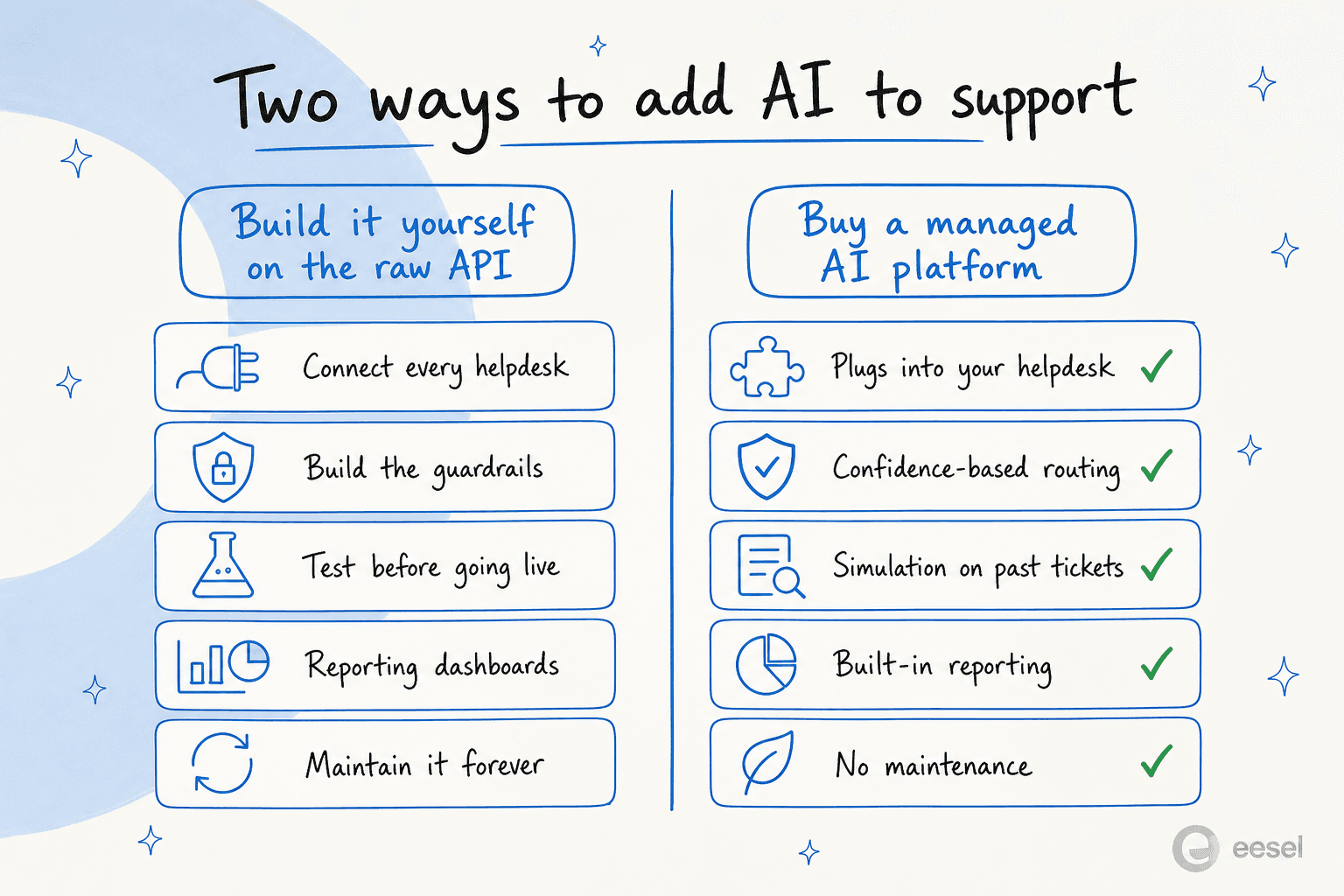
Wir sehen, wie das ausgeht, denn „wir bauen es einfach auf der Claude API“ ist einer der häufigsten Gründe, die technische Teams nennen, bevor sie kaufen. Einige tun es tatsächlich. Mehrere, die es versuchten, sind später stattdessen aufs Kaufen umgestiegen, weil die Wartung einer selbstgebauten LLM-App sich als Aufgabe herausstellte, die niemand wollte. Ein Kunde fasste die Rechnung zusammen:
„We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain.“
So sollte man darüber denken: Ein Frontier-Modell ist die unterste Schicht des Stacks, nicht der ganze Stack. Alles, was es in einen kundenreifen Agenten verwandelt, liegt obendrauf, und das ist der Teil, der die Zeit kostet.
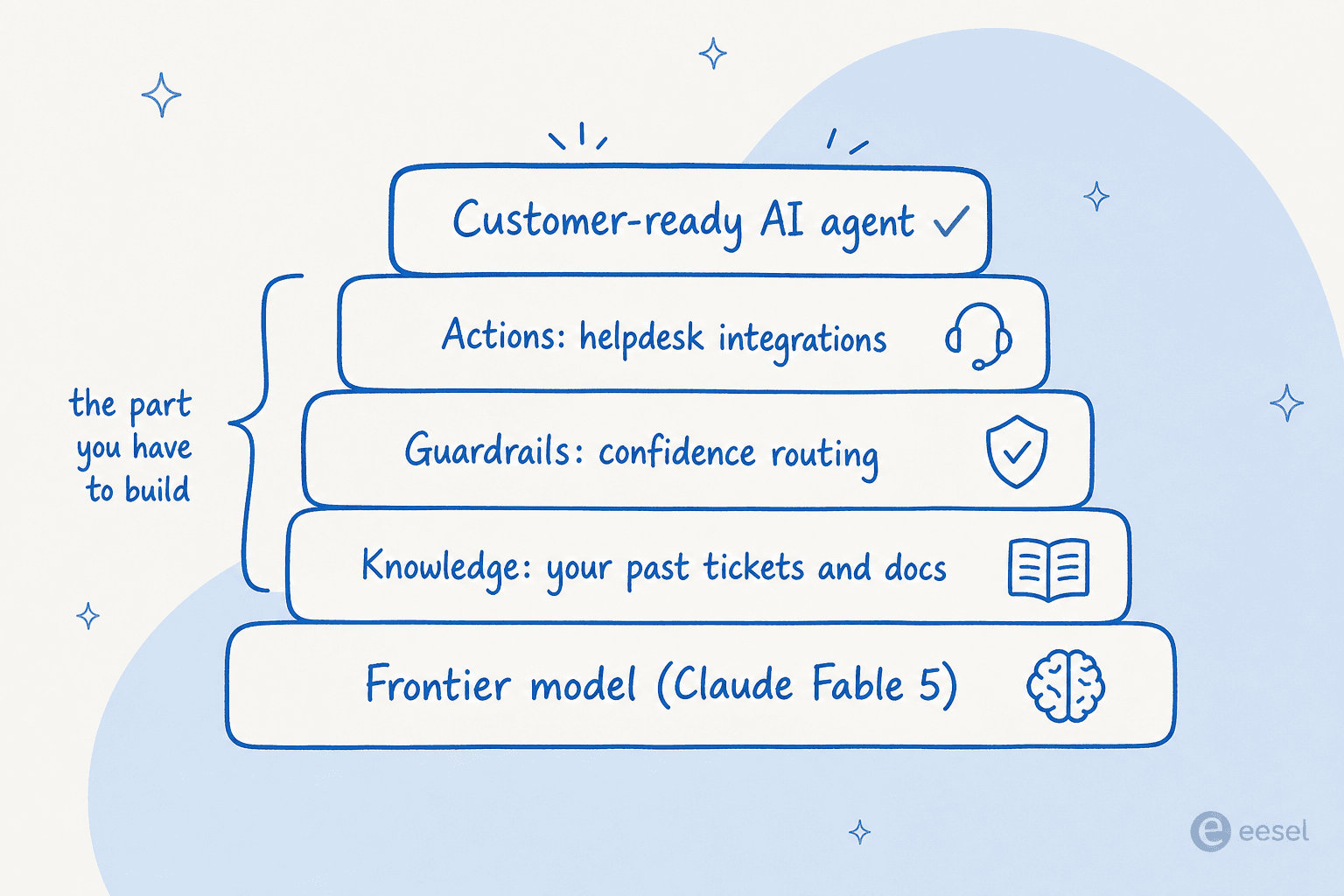
Wenn das Kernprodukt Ihres Teams KI ist, dann bauen Sie unbedingt. Wenn Ihr Kernprodukt etwas anderes ist und Sie einfach nur wollen, dass Tickets gut beantwortet werden, ist es fast immer schneller, günstiger und weniger fragil, die Schichten über dem Modell zu kaufen. Es ist dieselbe Logik wie bei der Wahl eines beliebigen KI-Agenten gegenüber einem regelbasierten Chatbot: Sie wollen das Ergebnis, nicht den Wartungsvertrag.
eesel ausprobieren
eesel AI ist die Schicht, die auf Frontier-Modellen wie Claude aufsetzt, damit Sie sie nicht selbst bauen müssen. Es lässt sich in Ihren bestehenden Helpdesk einbinden (Zendesk, Freshdesk, HubSpot, Gorgias, Front und 100+ Integrationen), lernt vom ersten Tag an aus Ihren vergangenen Tickets und Hilfedokumenten und antwortet in über 80 Sprachen, alles bei nutzungsbasierten Preisen, die bei 0,40 $ pro Ticket beginnen, ohne Gebühren pro Platz.
Der Unterschied, der hier zählt, ist genau der Teil, den Fable 5 Ihnen nicht von allein geben kann: ein Simulationsmodus, der den Agenten gegen Tausende Ihrer vergangenen Tickets laufen lässt, sodass Sie genau sehen, wie er geantwortet hätte und wie hoch Ihre Lösungsquote wäre, bevor ein einziger Kunde mit ihm spricht. So erreichte Gridwise im ersten Monat 73 % der gelösten Tier-1-Anfragen, mit Ergebnissen, die sich während eines 7-tägigen Tests zeigten.

Sie erhalten die Intelligenz der Frontier, ohne das Engineering-Projekt. Sie können kostenlos starten mit 50 $ Nutzungsguthaben und ohne Kreditkarte.
Häufig gestellte Fragen
Was ist Claude Fable 5 und ist es gut für Unternehmen?
Wie viel kostet Claude Fable 5?
Sollte ich meinen eigenen Support-Agenten auf der Claude-Fable-5-API aufbauen?
Ist Claude Fable 5 besser als Claude Opus 4.8 für den Kundensupport?
Was passiert, wenn Claude Fable 5 eine Support-Frage falsch beantwortet?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








