
Was genau ist Gemma 4?
Ich entwickle die KI-Agenten bei eesel und habe die letzten Jahre damit verbracht, zu beobachten, wie offene Modelle von „lustig zum Ausprobieren" zu „gut genug für zahlende Kunden" geworden sind. Wir betreiben täglich Agenten auf Live-Support-Warteschlangen; ein Kunde, Smava, verarbeitet monatlich über 100.000 deutschsprachige Tickets über einen automatisierten Agenten. Wann immer Google ein neues offenes Modell veröffentlicht, lese ich es durch eine Linse: Könnte man diesem Modell wirklich vertrauen, ohne menschliche Aufsicht auf Kundenfragen zu antworten?
Gemma 4 ist die interessanteste Antwort auf diese Frage, die ich von einem offenen Modell gesehen habe.
Einfach ausgedrückt ist Gemma die Linie offener Modelle von Google DeepMind – die kleineren, herunterladbaren Cousins der geschlossenen Gemini-Modelle. Gemma 4 wurde „aus derselben erstklassigen Forschung und Technologie wie Gemini 3 entwickelt, um die Intelligenz pro Parameter zu maximieren", laut Googles Launch-Post. Das Schlüsselwort ist Open-Weight: Google veröffentlicht die eigentlichen Modelldateien, sodass man sie auf dem eigenen Laptop, Server oder Smartphone ohne API-Aufruf betreiben kann.
Es ist auch multimodal. Jedes Modell verarbeitet Text- und Bildeingaben, die kleineren fügen nativen Audio-Input hinzu, und die Modellkarte nennt einen Trainings-Cutoff von Januar 2025 mit Unterstützung für über 140 Sprachen. Wer unseren Artikel zu RAG versus LLMs gelesen hat: Gemma 4 ist die „LLM"-Hälfte dieses Bildes – die Reasoning-Engine, die man auf das eigene Wissen ausrichten würde.
Die fünf Größen und welche die richtige ist
Gemma 4 ist nicht ein Modell, sondern fünf – sortiert nach dem Einsatzort. Das ist der Teil, den man zuerst verstehen sollte, denn die falsche Größe zu wählen ist der häufigste Fehler, den ich sehe.
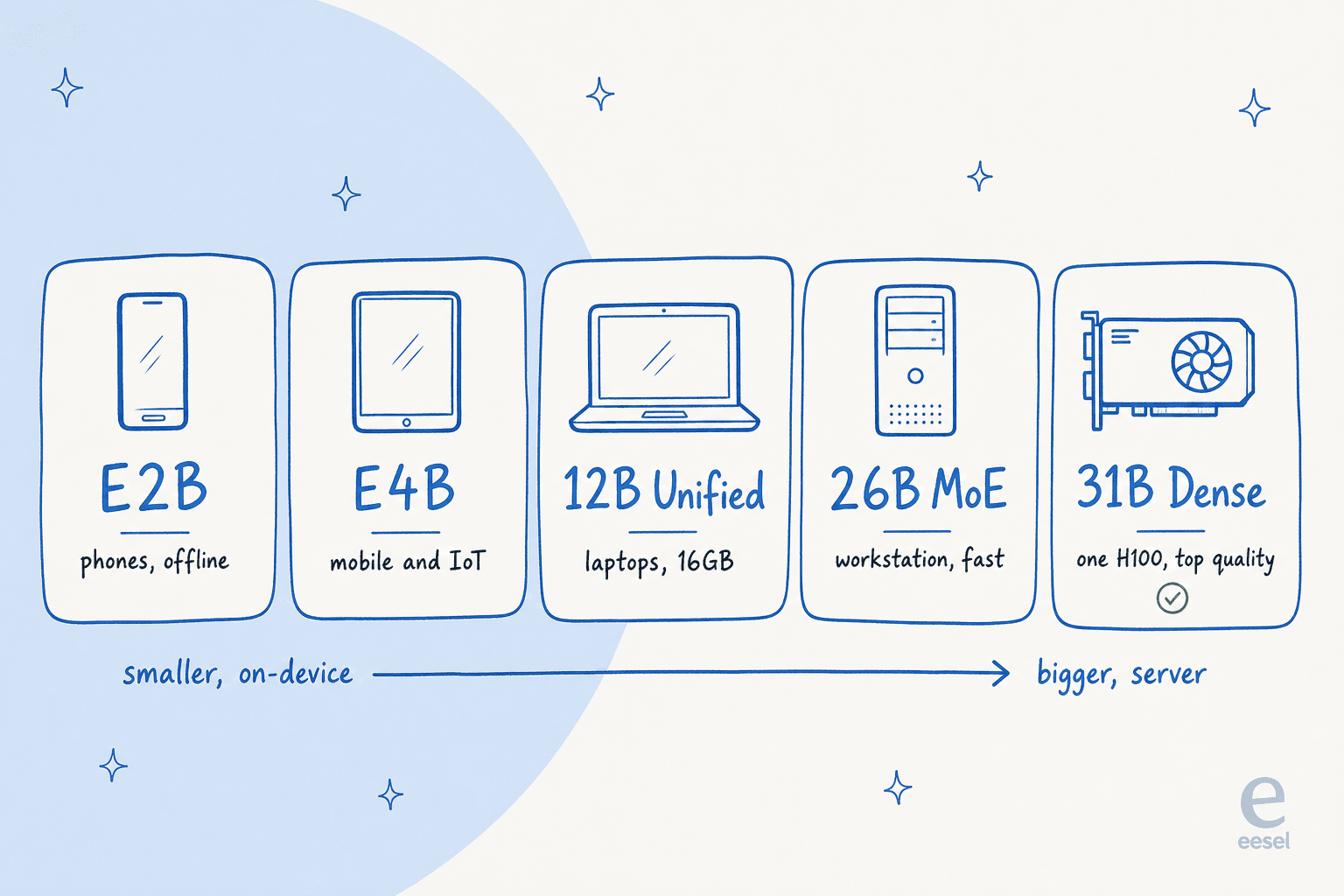
Hier ist die Übersicht mit den Spezifikationen direkt aus der Modellkarte:
| Modell | Effektive Parameter | Kontext | Modalitäten | Läuft auf |
|---|---|---|---|---|
| E2B | 2,3B (5,1B mit Embeddings) | 128K | Text, Bild, Audio | Smartphones, Raspberry Pi, Edge |
| E4B | 4,5B (8B mit Embeddings) | 128K | Text, Bild, Audio | High-End-Smartphones, IoT |
| 12B Unified | 11,95B | 256K | Text, Bild, Audio | Laptops (~16 GB) |
| 26B A4B (MoE) | 25,2B gesamt, 3,8B aktiv | 256K | Text, Bild | Workstation, latenzkritisch |
| 31B Dense | 30,7B | 256K | Text, Bild | Ein 80-GB-H100, beste Qualität |
Das „E" in E2B und E4B steht für effektive Parameter. Diese Modelle verwenden einen Trick namens Per-Layer Embeddings, um den Speicherbedarf klein zu halten – so kann ein Smartphone sie offline mit nahezu null Latenz betreiben. Google hat sie zusammen mit dem Pixel-Team sowie Qualcomm und MediaTek entwickelt, sie sind also für echtes Mobile-Silizium optimiert, nicht nur für eine Demo.
Das 12B Unified ist der Neuling, am 3. Juni 2026 hinzugefügt. Es ist das „Laptop-taugliche" Modell und Googles erstes mittelgroßes Modell mit nativem Audio-Input. Das 31B Dense ist das Flaggschiff für maximale Qualität und die Basis, auf der alle feinabstimmen.
Das mittlere Modell, das 26B, ist das Cleverste der Gruppe. Es verdient einen eigenen Abschnitt.
Wie ein 26B-Modell mit Modellen mithalten kann, die 20x größer sind
Das 26B ist ein Mixture-of-Experts (MoE)-Modell, und es zu verstehen ist der beste Weg, zu begreifen, warum Gemma 4 so bedeutsam ist.
Ein normales „dichtes" Modell aktiviert jeden Parameter für jedes verarbeitete Token. Ein MoE-Modell teilt seine Parameter in viele kleine „Experten" auf und schaltet für jedes Token nur die wenigen ein, die wirklich benötigt werden. So sieht das aus:
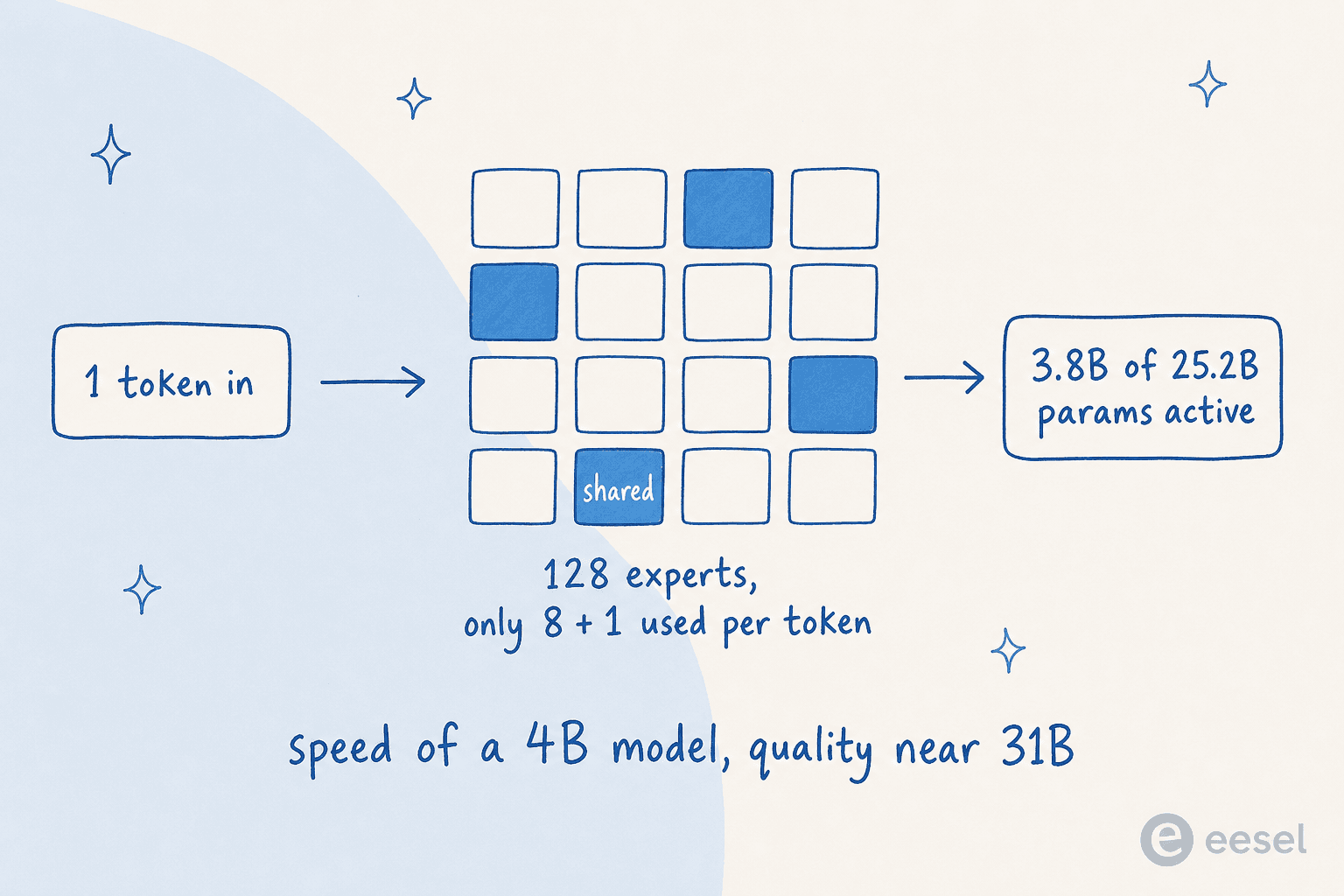
Gemma 4s 26B hat 25,2B Gesamtparameter, aber nur 3,8B aktive pro Token, die durch 8 von 128 Experten plus einem geteilten Experten geleitet werden. Das praktische Ergebnis: Es läuft etwa so schnell wie ein 4B Dense-Modell, antwortet aber näher an der Qualität des 31B. (Ein Vorbehalt: Alle 25,2B Parameter müssen für das Routing noch in den Speicher geladen werden, MoE spart also Rechenleistung, nicht RAM.)
Warum ist das wichtig? Weil es die alte Annahme bricht, dass „intelligenter" auch „größer und langsamer" bedeutet. Man sehe, wo die mittelgroßen Gemma-4-Modelle in Googles eigenem Leistungs-versus-Größe-Diagramm landen:
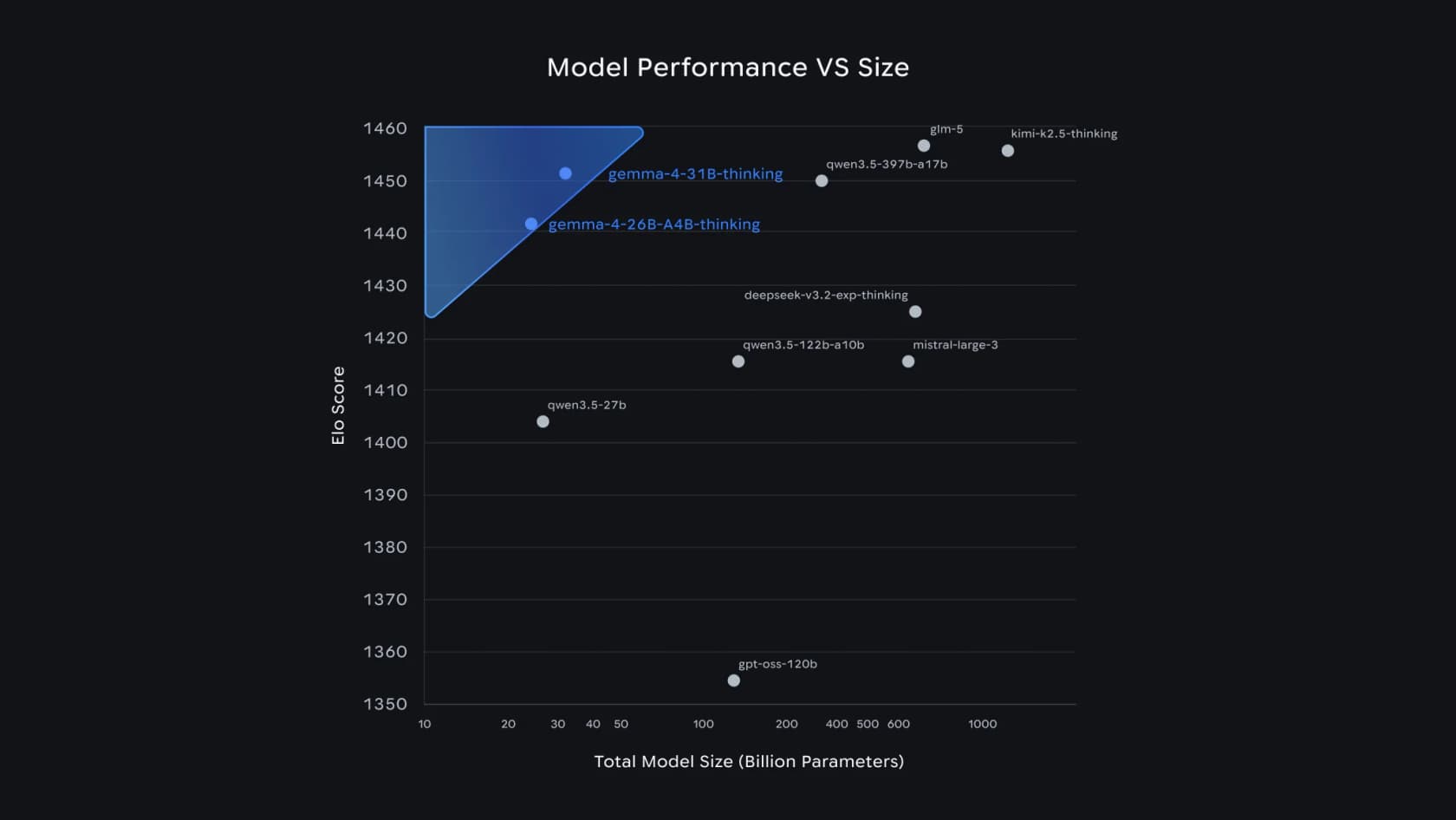
Das 31B ist das #3-offene Modell in Arena AIs Text-Bestenliste, und das 26B MoE belegt Platz #6 – so kann Google behaupten, Gemma 4 „übertrifft Modelle, die 20x größer sind". Für ein Support-Team ist die Erkenntnis nicht das Bestenlisten-Ranking, sondern dass diese Qualität auf eigener Hardware läuft.
Was „Open Weights" wirklich bedeutet (und warum sich die Lizenz geändert hat)
„Open" wird oft ungenau verwendet – hier möchte ich präzise sein, denn hier hat Gemma 4 seinen größten Schritt gemacht.
Frühere Gemma-Modelle wurden unter benutzerdefinierten „Gemma Nutzungsbedingungen" veröffentlicht. Gemma 4 wechselte zu einer standardmäßigen Apache-2.0-Lizenz. In Googles Worten ist sie „kommerziell freizügig" und gewährt „vollständige Kontrolle über Daten, Infrastruktur und Modelle". Hugging Faces CEO Clément Delangue bezeichnete diesen Schritt als „einen riesigen Meilenstein".
Das ist der Unterschied, den diese Lizenz in der Praxis macht:
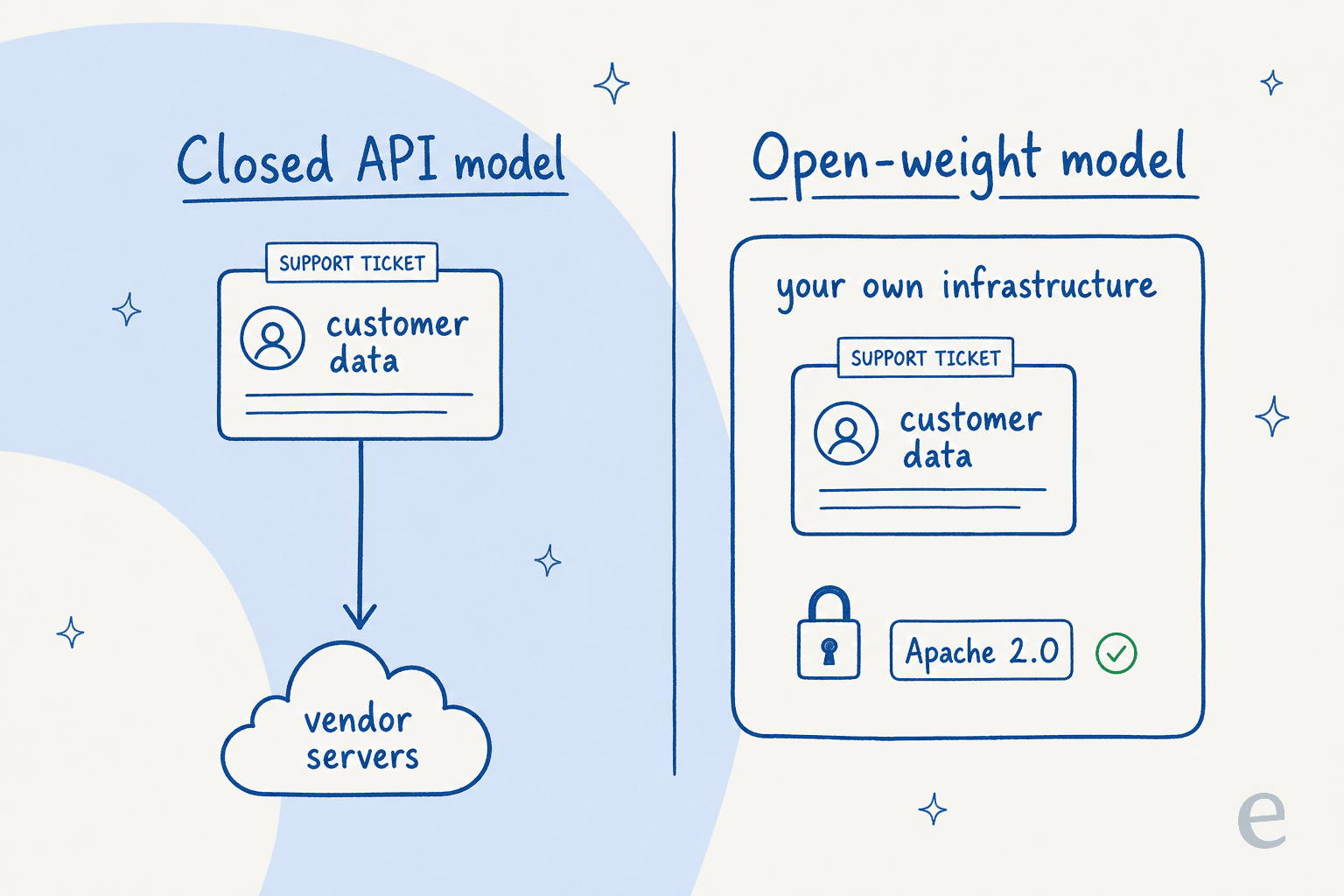
Mit einem geschlossenen API-Modell wird jede verarbeitete Kundennachricht an die Server des Anbieters gesendet. Mit einem Open-Weight-Modell unter Apache 2.0 kann alles innerhalb der eigenen Infrastruktur betrieben werden – on-premises oder in der eigenen Cloud – und die Daten verlassen sie nie. Für alle in regulierten Branchen ist diese Datenhaltungskontrolle der einzige Grund, sich für offene Modelle zu interessieren. Aus demselben Grund greifen Menschen zu Open-Source-Ticketing-Systemen und Open-Source-Chatbot-Plattformen.
Um es zu skalieren, bietet Google Gemma 4 über Vertex AI, Cloud Run und GKE an, und es funktioniert von Anfang an mit den Tools, die Self-Hoster bereits verwenden, wie Ollama, llama.cpp, vLLM und LM Studio.
Die Benchmarks und wo Gemma 4 wirklich glänzt
Nun zu den Zahlen. Google veröffentlicht eine vollständige Benchmark-Tabelle, die die instruction-tuned Gemma-4-Modelle mit der vorherigen Generation Gemma 3 27B vergleicht:
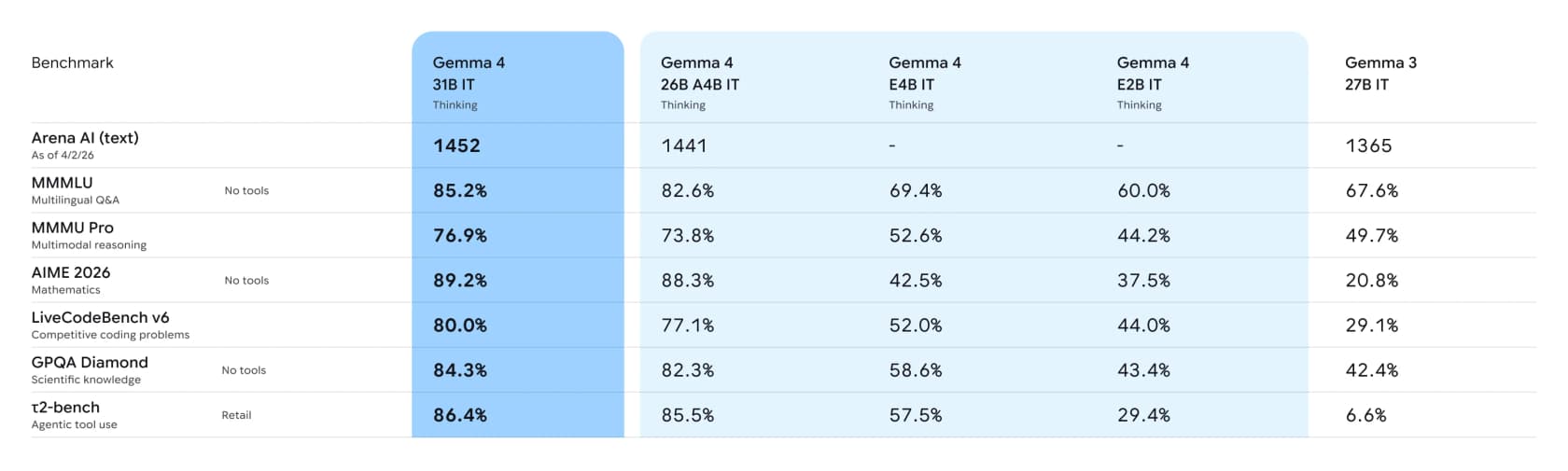
Die eine Zeile, die ich hervorheben würde, ist der agentische Tool-Use. Im τ2-Bench-Retail-Benchmark, der testet, ob ein Modell tatsächlich Tools aufrufen kann, um eine Aufgabe abzuschließen, erzielt das 31B-Modell 86,4% gegenüber Gemma 3s 6,6%. Das ist keine inkrementelle Verbesserung, sondern ein Generationssprung – und diese Fähigkeit verwandelt einen Chatbot in etwas, das wirklich arbeiten kann.
Es hält auch gegenüber den geschlossenen Giganten stand. Bei Arena Elo liegt das 31B mit 1452 knapp hinter Modellen mit 15–35x mehr Parametern:
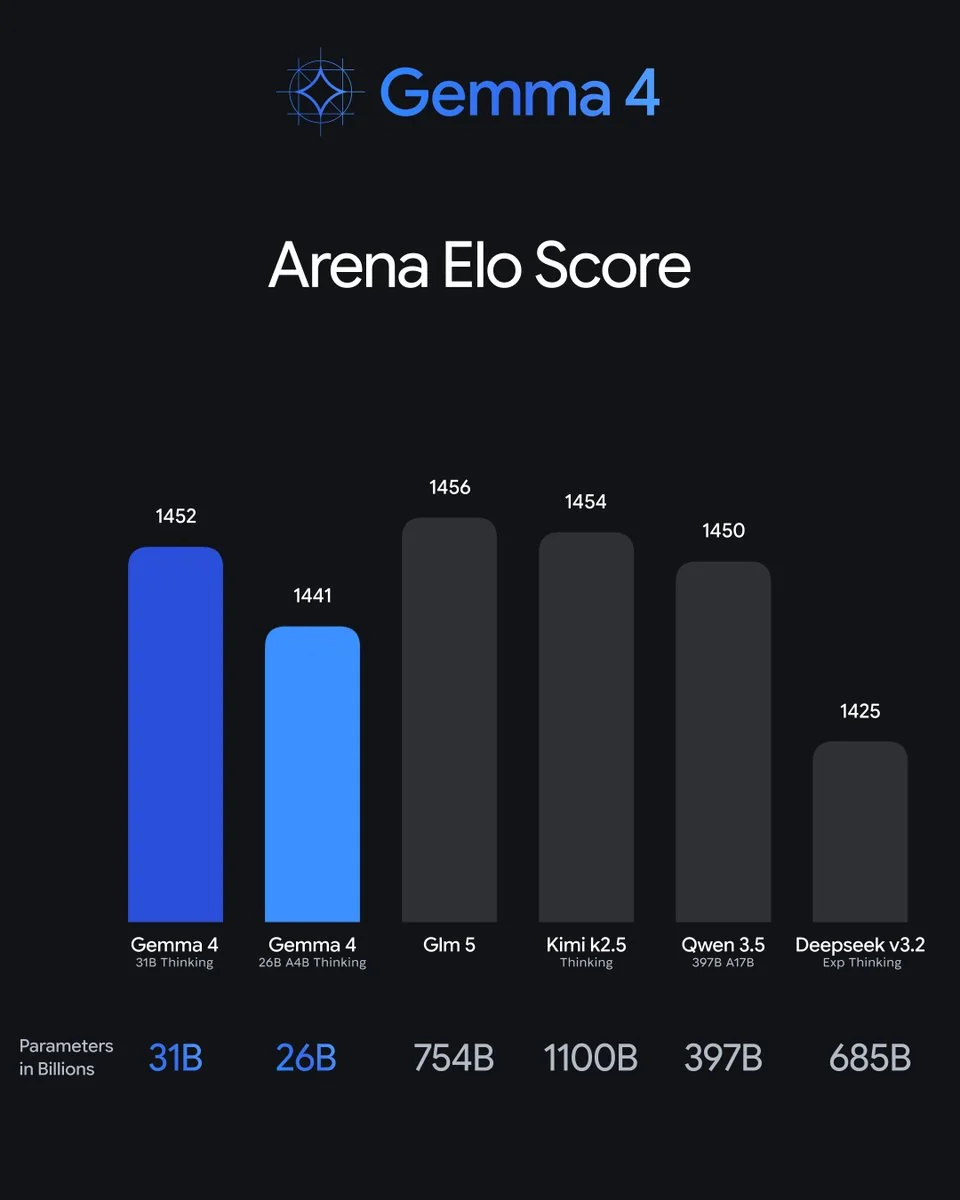
Architektonisch ist die interessante Anmerkung aus Sebastian Raschkas Analyse, dass Gemma 4 unter der Haube „ziemlich unverändert" gegenüber Gemma 3 ist, sodass der Sprung „wahrscheinlich auf das Trainingsset und das Rezept zurückzuführen ist". Mit anderen Worten: Google hat diesen Sprung durch bessere Daten erreicht, nicht durch eine neue Architektur – was eine leise beeindruckende Leistung ist.
Wie es sich im Betrieb anfühlt
Benchmarks sind das eine. Was sagen Menschen, die Gemma 4 täglich betreiben? Ich habe mich in den Local-Model-Communities umgesehen, denn dort findet man die ungeschminkten Meinungen.
Das Lob ist einheitlich: schnell, speicherschonend und nicht langatmig.
„Schnell wie die Hölle auf einem M4Max, und verdammt schlau für seine Geschwindigkeit. Zerstört nicht die Speicherlast. Denkt nicht stundenlang nach (und frisst das gesamte Token-Budget beim Reasoning) wie Qwen... Es ist perfekt für openclaw, hermes, claude code usw. Ich LIEBE dieses Modell lokal. Es ist jetzt mein Standardmodell." – u/styles01 auf r/LocalLLaMA
Der Punkt „denkt nicht stundenlang nach" taucht immer wieder auf. Ein Self-Hoster, der das 26B und 31B für einen multimodalen Anwendungsfall betreibt, hat echte Zahlen geliefert und berichtet von etwa 149 Token/Sek. beim 31B und 88 beim 26B und ergänzt, dass „die Benchmarks wirklich nicht erfassen, wie wenig es im Vergleich zu größeren Modellen quasselt".
Aber hier ist die ehrliche Einschränkung, und sie ist der Grund, warum ich Gemma 4 nicht unbeaufsichtigt auf eine Live-Warteschlange lassen würde:
„Ich stimme zu, es ist bei allem viel besser, außer beim Coding. [...] Es leidet jedoch erheblich, wenn Gewichte oder KV-Cache auf einer anderen Quantisierung als der nativen sind." – u/fragment_me auf r/LocalLLM
Die Community-Einschätzung lautet also: Gemma 4 ist ein ausgezeichnetes Chat- und Instruction-Following-Modell, das weit über seinem Gewicht schlägt, mit zwei Vorbehalten – Coding und agentische Workflows sind schwächere Bereiche, und es verschlechtert sich merklich, wenn es auf einer anderen als der nativen Quantisierung betrieben wird. Gut zu wissen, bevor man es für eine Aufgabe auswählt.
Was das für den Kundensupport bedeutet
Hier wird es für alle, die ein Support-Team leiten, praktisch. Ein offenes Modell wie Gemma 4 ist eine fantastische Zutat. Es ist allein kein Support-Agent.
Ein rohes Modell hat keine Ahnung, was die Rückgaberichtlinie lautet, kann vergangene Tickets nicht einsehen und ist nicht mit dem Helpdesk verbunden. Es unbeaufsichtigt vor Kunden zu stellen, führt genau zu dem Fehlermodus, gegen den wir jahrelang entwickelt haben: Ein selbstsicherer Bot, der leise falsche Antworten gibt. Das Modell ist der Motor; das eigentliche Produkt ist alles darum herum – das Wissen, das sichere Routing, die Verbindung zu den eigenen Tools und die Fähigkeit, es vor dem Go-Live zu testen.
Diese Lücke ist der einzige Grund, warum Plattformen wie unsere existieren. Die Open-Weight-Bewegung gibt die Kontrolle über die Modellschicht, aber die meisten Support-Teams möchten nicht auch zu einem ML-Ops-Team werden. Die bessere Antwort für die meisten ist, die Datenkontroll- und Lernvorteile zu erhalten, ohne die Infrastruktur selbst aufzubauen – das ist die Grenze, die ich zwischen einem Modell und einer KI-Kundenservice-Plattform ziehen würde.
eesel für KI-Support ausprobieren
Wenn die Lektüre über Gemma 4 den Gedanken weckte „Ich möchte KI, die meine Tickets beantwortet, aber zu meinen Bedingungen" – genau das Problem löst eesel.
Eesels KI-Helpdesk-Agent integriert sich in die bereits genutzten Tools – Zendesk, Freshdesk, Gorgias, Slack und über 100 andere – und lernt ab Tag eins aus vergangenen Tickets und Hilfsdokumentationen, sodass jahrelanges Wissen sofort verfügbar wird. Der Teil, der direkt auf die eingangs gestellte Frage „Kann man ihm vertrauen?" einzahlt: Der Agent kann gegen tausende historischer Tickets simuliert werden, um zu sehen, wie er geantwortet hätte – bevor ein einziger Kunde ihn sieht. So hat Gridwise im ersten Monat 73% der Tier-1-Anfragen gelöst.

Es ist nutzungsbasiert, ab 0,40 $ pro Ticket ohne Sitzplatz-Gebühren, und der Start ist mit 50 $ kostenlosem Guthaben ohne Kreditkarte möglich. Egal ob das zugrunde liegende Modell Gemma 4 oder ein anderes ist – das eigentlich Gewünschte ist ein Agent, dem man auf der eigenen Warteschlange vertrauen kann. eesel ausprobieren und sehen, wie er damit umgeht.
Häufig gestellte Fragen
Was ist Gemma 4?
Ist Gemma 4 kostenlos nutzbar?
Welche Modellgrößen gibt es bei Gemma 4?
Kann Gemma 4 auf einem Laptop oder Smartphone laufen?
Ist Gemma 4 gut für den Kundensupport?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








