O que é QA de suporte de verdade e por que a versão manual está quebrada
QA de suporte é garantia de qualidade para conversas com clientes. Você usa uma rubrica (a resposta foi correta? o tom foi adequado? o problema foi realmente resolvido?) e avalia conversas com base nela, depois usa o que encontra para treinar agentes e corrigir lacunas. Bem feito, é assim que uma equipe de suporte melhora em vez de apenas ficar mais rápida, e está ligado a tudo, desde a gestão de SLA até a redução de custos de suporte.
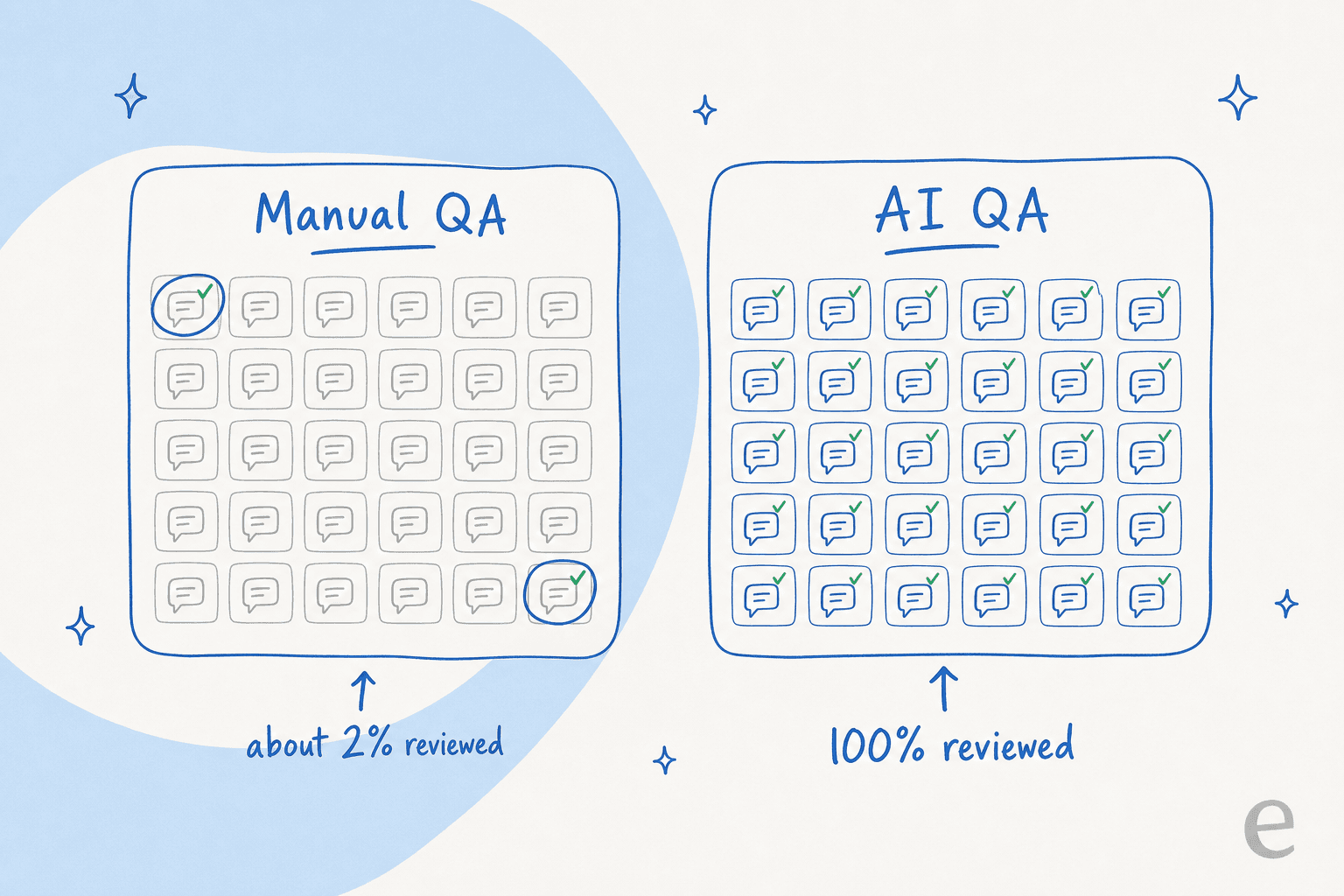
O problema que já vivi na fila é este: a versão manual só olha para uma fatia minúscula. Um analista de QA seleciona alguns tickets por agente por semana, os pontua em uma planilha e segue em frente. Se sua equipe atende alguns milhares de conversas por mês, você está revisando talvez 2% delas. Os 98% que você não abriu podem estar cheios de respostas educadas, confiantes e completamente erradas, e o seu programa de QA nunca ficaria sabendo.
Essa fatia não é apenas pequena, é tendenciosa. Os analistas gravitam em direção aos tickets mais fáceis de pontuar, os mais recentes ou os que já foram sinalizados. O caso realmente incomum, aquele que silenciosamente fez um cliente abandonar o serviço, raramente entra na amostra. Então você acaba treinando agentes com base em 2% aleatórios enquanto os padrões que realmente movem o CSAT ficam escondidos na parte que ninguém lê.
O QA manual também é lento e inconsistente. Dois revisores pontuam a mesma conversa de forma diferente. Quando um feedback de coaching chega, o agente já atendeu mais 400 tickets. Nada disso é culpa do analista — é um problema matemático: humanos não conseguem ler tudo, então leem uma amostra, e uma amostra não pode te dizer nada sobre toda a sua fila.
O que muda quando a IA conduz o seu QA
A mudança é simples de enunciar e difícil de subestimar: pontuar 100% das conversas custa aproximadamente o mesmo esforço que pontuar 2%. Quando uma IA lê todas as conversas com base na sua rubrica, a cobertura deixa de ser algo que você precisa racionar.
Três coisas mudam ao mesmo tempo. Primeiro, o viés da amostragem desaparece, porque não há amostra — a IA avalia toda a fila com uma rubrica consistente. Segundo, o ciclo de feedback se estreita: uma conversa pode ser pontuada minutos após ser encerrada, não ao final de um ciclo de revisão. Terceiro, o QA deixa de ser uma verificação pontual e se torna uma métrica de suporte que você pode acompanhar ao longo do tempo, por agente, por tópico, por canal.
O que não muda: o julgamento ainda pertence às pessoas. A IA lê tudo e sinaliza o que parece errado; um humano decide o que fazer a respeito. Essa divisão de trabalho é a mesma que faz a combinação de IA e suporte humano funcionar em outros contextos, máquinas para o volume, pessoas para as decisões que exigem discernimento. É também por isso que o QA se encaixa tão naturalmente ao lado de um copiloto de IA no seu fluxo de trabalho de suporte: os mesmos dados de conversa alimentam ambos.
Como fazer QA de suporte com IA, passo a passo
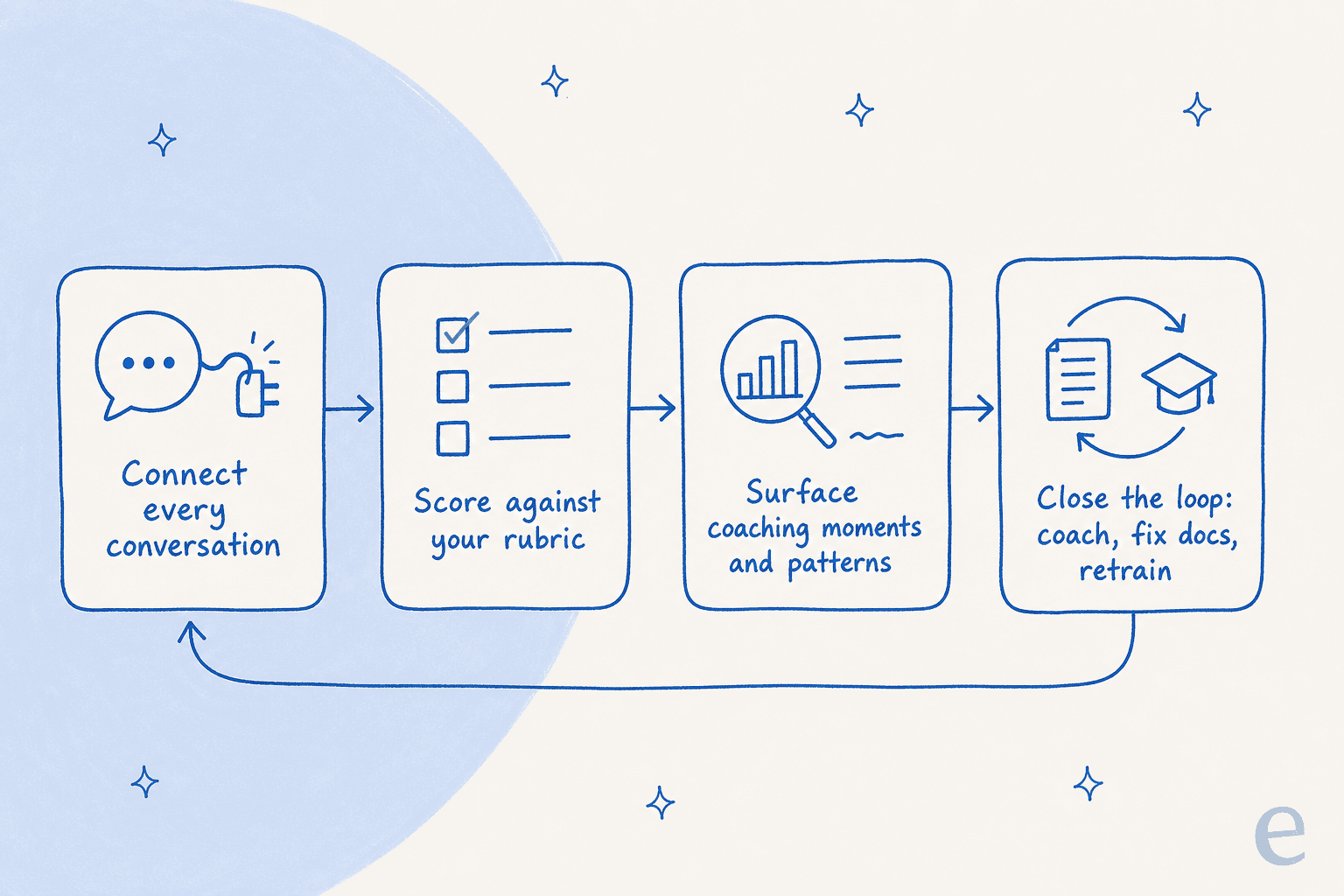
Fazer isso bem é basicamente usar IA e automação em suporte voltados para qualidade em vez de volume, e você não precisa de uma equipe de dados para isso. O processo todo tem cinco etapas, e o ciclo importa tanto quanto as etapas, porque o QA só vale a pena se os resultados retornam para o trabalho.
Etapa 1: Escreva o que "bom" significa
O QA é tão bom quanto a sua rubrica, e uma rubrica para IA precisa ser explícita — sem "você saberá quando ver". Especifique os poucos critérios pelos quais cada resposta será avaliada. Na prática, são cerca de cinco dimensões: foi factualmente correta, o tom foi adequado, o problema foi resolvido, seguiu a política e citou uma fonte real em vez de inventar algo.
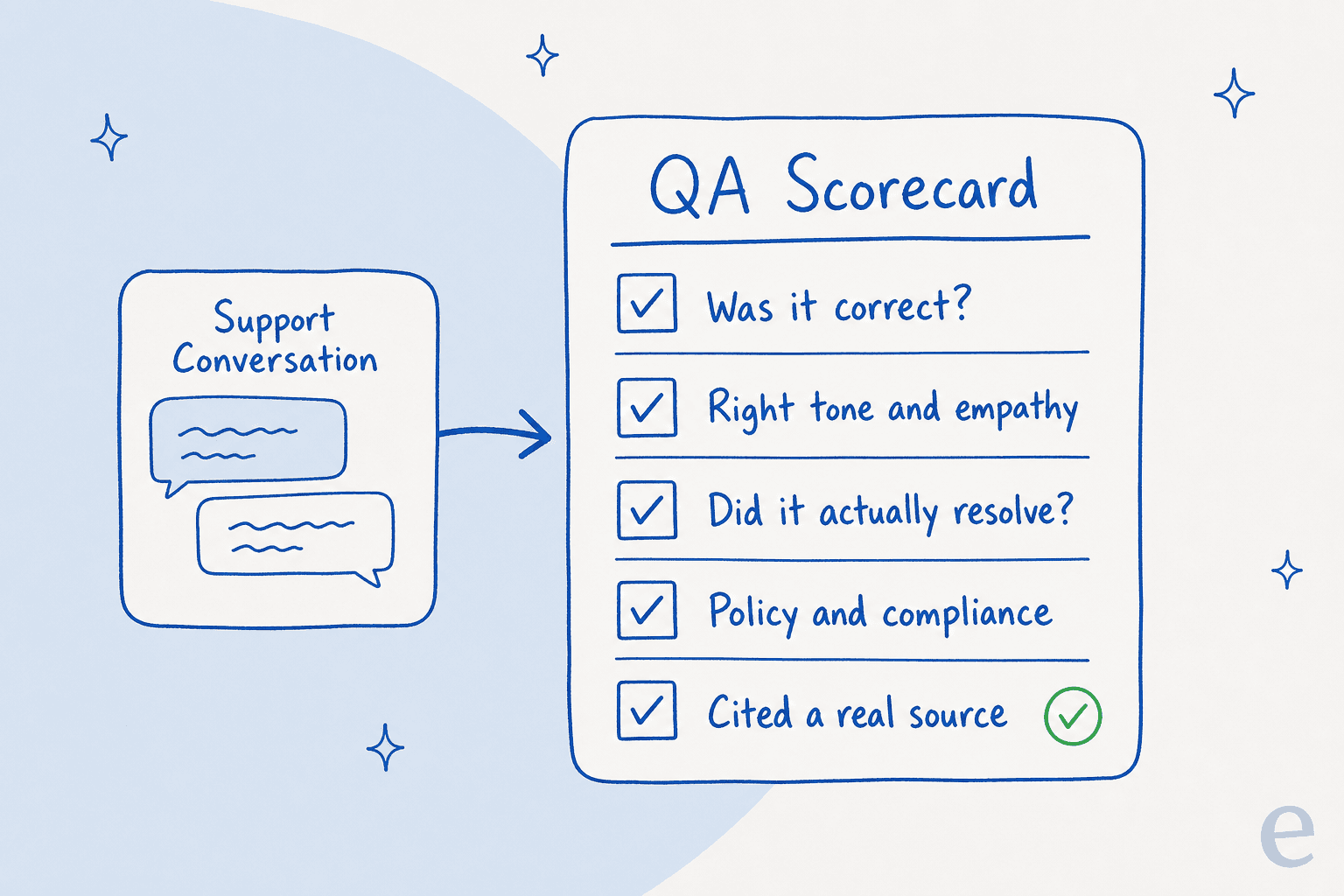
Mantenha-a enxuta. Uma rubrica com 30 critérios é uma rubrica que ninguém aplica de forma consistente, seja humano ou IA. O critério de fonte importa mais do que as pessoas esperam: uma resposta confiante sem fonte por trás é exatamente o tipo de coisa que parece bem numa planilha e se revela uma alucinação quando você verifica.
Etapa 2: Conecte todas as conversas, não uma amostra
Aponte a IA para todo o seu histórico de conversas, não para uma exportação dos tickets sinalizados da semana passada. Isso geralmente significa conectar seu helpdesk diretamente para que as conversas encerradas entrem automaticamente, seja no Zendesk, Freshdesk, Gorgias ou Help Scout.

É aqui que sua base de conhecimento entra. Uma pontuação de QA de "errado" só é útil se você souber se foi o agente que errou ou a documentação. Alimentar a IA tanto com as conversas quanto com o material de referência que deveria ter sido usado permite que ela diferencie os dois casos, o que é a diferença entre treinar uma pessoa e corrigir um artigo de chatbot de base de conhecimento.
Etapa 3: Pontuação automática com base na rubrica
Agora a IA lê cada conversa e a pontua nas suas dimensões. O que você quer como resultado não é um único número, mas um detalhamento: esta conversa teve pontuação baixa em resolução, esta acertou a resposta mas o tom foi inadequado, este lote inteiro falhou na mesma política. As tendências importam mais do que qualquer nota individual.

Trate a primeira semana de pontuações como calibração, não como verdade absoluta. Leia uma parte das notas da IA com seu próprio julgamento e ajuste a rubrica onde ela for muito rígida ou muito permissiva. Após algumas rodadas, as pontuações se estabilizam e você passará a confiar nelas como confiaria em um segundo analista, com verificações pontuais ocasionais. Esta é a mesma disciplina por trás do acompanhamento do tempo de primeira resposta ou de qualquer outra métrica de suporte: a métrica só é útil quando você acredita nela.
Etapa 4: Identifique momentos de coaching e padrões
Pontuar tudo não tem sentido se o resultado for uma parede de números. O benefício real é que a IA consegue extrair as conversas que um humano realmente deveria analisar: os três tickets desta semana em que um agente prometeu algo fora da política, o tópico em que todas as respostas tiveram pontuação baixa, o novo colaborador cujo tom escorrega nas solicitações de reembolso.
Essa é a camada de coaching, e é onde o QA se justifica. Em vez de "aqui estão cinco tickets aleatórios que avaliei", o líder da equipe recebe "aqui estão os momentos específicos que merecem uma conversa, agrupados pelo que têm em comum". Os padrões recorrentes também alimentam diretamente o restante da sua operação: um tópico que continua com pontuação baixa geralmente é uma lacuna de triagem de tickets ou de escalonamento, não um problema de pessoas. Corrija o documento ou a regra de classificação de tickets por trás disso e muitas vezes você reduz o volume de tickets ao mesmo tempo.
Etapa 5: Feche o ciclo
QA que não muda nada é teatro. O último passo é devolver os resultados ao trabalho: treine os agentes sinalizados pela IA, reescreva os documentos por trás dos erros recorrentes e atualize a rubrica conforme seu produto e suas políticas mudam.

Quando parte do seu suporte é automatizada, fechar o ciclo também significa corrigir a própria IA. As boas ferramentas aprendem com essas correções, então uma correção que você faz uma vez impede que o mesmo erro se repita. Isso transforma o QA de um boletim retrospectivo em algo que melhora ativamente a automação do atendimento ao cliente semana após semana.
A parte que todos esquecem: fazer QA da própria IA
Aqui está o ponto que a maioria dos posts sobre "IA para QA" ignora, e é o que mais me importa depois de mais de três anos colocando agentes de IA em filas de suporte ao vivo. Se você vai deixar a IA atender tickets, essa IA precisa passar pelo QA antes de tocar em um cliente, e a maioria das equipes nunca faz essa verificação.
Já vi um bot com tom confiante responder uma pergunta de forma errada com total convicção. Um responsável por uma marca DTC de suplementos nos colocou o risco de forma direta: uma IA que responde "desculpe, não sei" a tudo é inútil, mas uma IA que chuta é pior, porque ninguém consegue reler 7.000 tickets para encontrar os chutes. A resposta para ambos é o QA: o agente só deve atender o que tem confiança para responder, e você deve estar pontuando seu trabalho da mesma forma que pontua o de um humano.
Então construímos essa verificação. Antes de um agente eesel entrar em produção, você pode executá-lo em uma simulação contra seus tickets passados reais e ver sua qualidade e cobertura por tópico, sem envolver nenhum cliente. Quando auditamos um agente com o tráfego real do Zendesk de um cliente, ele atingiu cerca de 93% de precisão na triagem e detectou 100% de spam sem falsos positivos, mas as respostas preliminares estavam factualmente corretas em apenas 88% das vezes, com uma taxa de erro factual de 7%. Esses 7% são o motivo exato pelo qual você faz QA da IA: parece ótimo no agregado e ainda precisa de um limite de confiança e de um humano no loop para os casos difíceis. As mesmas pontuações aparecem em tempo real nos seus dados analíticos do agente, então o QA da IA nunca realmente para.
Esta é também a resposta mais honesta para "posso confiar nela?" Você não confia por fé — você faz QA, configura para rascunho em vez de envio automático onde a confiança é baixa, e amplia a autonomia conforme as pontuações justificam. Essa é a diferença entre uma demonstração e uma implantação.
Erros comuns a evitar
Algumas armadilhas nas quais vejo equipes caírem quando migram o QA para IA:
- Tratar a pontuação da IA como definitiva. É uma primeira passagem, não um veredicto. Verifique-a pontualmente, especialmente no início, da mesma forma que calibraria um novo analista.
- Uma rubrica grande demais. Trinta critérios parece rigoroso e pontua de forma inconsistente. Cinco dimensões bem definidas superam trinta vagas.
- Pontuar conversas sem fechar o ciclo. Se nada muda (sem coaching, sem correções de documentos, sem atualizações de rubrica), você construiu um relatório muito detalhado que ninguém age.
- Esquecer de fazer QA da automação. Se a IA está respondendo tickets, ela é o "agente" com o maior volume de toda a sua operação. Não pontuá-la é o maior ponto cego de todos.
- Confundir QA com CSAT. Um cliente pode dar cinco estrelas a uma conversa depois de receber uma resposta errada com confiança. O QA verifica se a resposta estava de fato correta, por isso você quer tanto suas pontuações de QA quanto seu relatório de CSAT do Gorgias ou CSAT do Freshdesk, e não um substituindo o outro.
Experimente o eesel para QA de suporte
Se você quer fazer QA de suporte com IA sem ter que juntar três ferramentas diferentes, é exatamente para isso que o agente de helpdesk com IA da eesel foi desenvolvido. Ele se conecta ao seu helpdesk e base de conhecimento existentes, lê suas conversas passadas e (esta é a parte que importa para o QA) permite que você execute uma simulação sobre tickets históricos reais para que você possa ver a qualidade e a cobertura antes de qualquer coisa entrar em produção.

No que diz respeito a softwares de atendimento ao cliente com IA, a parte útil para o QA é que o mesmo mecanismo que pontua os rascunhos de um agente de IA é o que lê as conversas da sua equipe, então o QA de humanos e o QA da automação ficam em um único lugar em vez de duas planilhas. Funciona como um colega de equipe que se integra em uma tarde e já conhece a sua central de ajuda, com preços baseados em uso que não cobram por assento pelo privilégio de revisar seus próprios tickets. Gratuito para experimentar.
Perguntas Frequentes
O que é QA de suporte e como o QA de suporte com IA é diferente?
A IA consegue pontuar conversas de suporte com precisão?
Qual porcentagem do meu volume de suporte devo colocar em QA com IA?
O QA de suporte com IA substitui meus analistas de QA?
Como faço QA de um agente de suporte com IA?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.