Então, a IA realmente pode fazer QA de suporte?
Resposta curta: sim, e melhor do que a versão manual na única dimensão que mais importa: cobertura.
Eu construo os agentes de IA que fazem isso, então deixe-me ser preciso sobre o que "sim" significa. O QA de suporte tradicional é um analista selecionando um punhado de tickets por agente por semana, pontuando-os em uma planilha e seguindo em frente. Se sua equipe lida com alguns milhares de conversas por mês, isso é uma revisão de talvez 2% delas, e um 2% tendencioso, porque os revisores gravitam em torno dos tickets mais fáceis de pontuar. O caso extremo incomum que silenciosamente fez um cliente abandonar quase nunca entra na amostra.
A IA inverte isso. Assim que um modelo lê cada conversa em relação à sua rubrica, pontuar 100% das conversas custa aproximadamente o mesmo esforço que pontuar 2%. A cobertura deixa de ser algo que você raciona. O problema é que "ler tudo" e "julgar tudo corretamente" são duas afirmações diferentes. A IA acerta na primeira. Na segunda é onde você mantém um humano no ciclo.
O que a IA faz bem (e as provas)
Aqui está onde o QA com IA é genuinamente forte, e prefiro mostrar números reais a adjetivos.
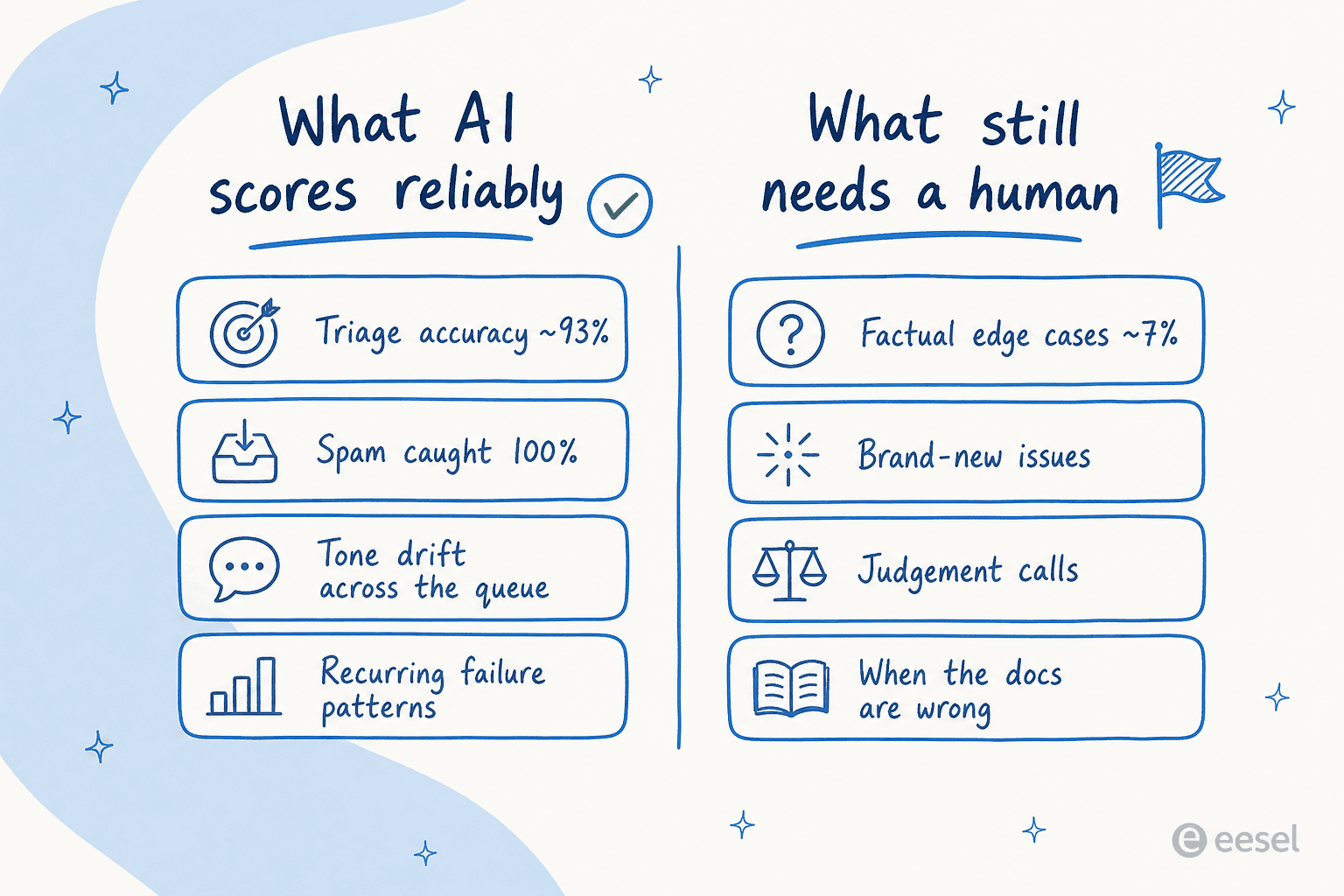
Quando executamos um agente contra o tráfego real do Zendesk de um cliente, ele pontuou cerca de 93% em precisão de triagem e capturou 100% de spam com zero falsos positivos, em uma caixa de entrada que tinha 22% de spam. Categoria por categoria foi ainda mais preciso: rascunhos úteis em devoluções e reembolsos 93,8% das vezes, reclamações de garantia 96,4%, consultas sobre produtos e buscas de status de reembolso 100%. Esses são os tickets repetitivos e cheios de padrões que o QA existe para manter consistentes, e um modelo que leu seu histórico é excelente em detectar onde uma resposta desvia do padrão.
A mesma força se aplica aos seus humanos. A IA é muito boa nas coisas que um revisor cansado perde: tom que escorrega em reembolsos, uma política que um agente continua errando sutilmente, um tópico onde cada resposta pontua baixo porque o documento de ajuda subjacente está desatualizado. Esses são padrões, e padrões são o que um modelo lendo toda a fila encontra que uma amostra de 2% estruturalmente não consegue. Ele também nunca fica entediado no ticket 4.000, o que é mais do que posso dizer sobre qualquer turno de QA humano.
Como a IA realmente pontua uma conversa
Esta é a parte que as pessoas imaginam ser uma caixa preta, e realmente não é. O mecanismo é a mesma rubrica que um revisor humano usaria, apenas aplicada a tudo.
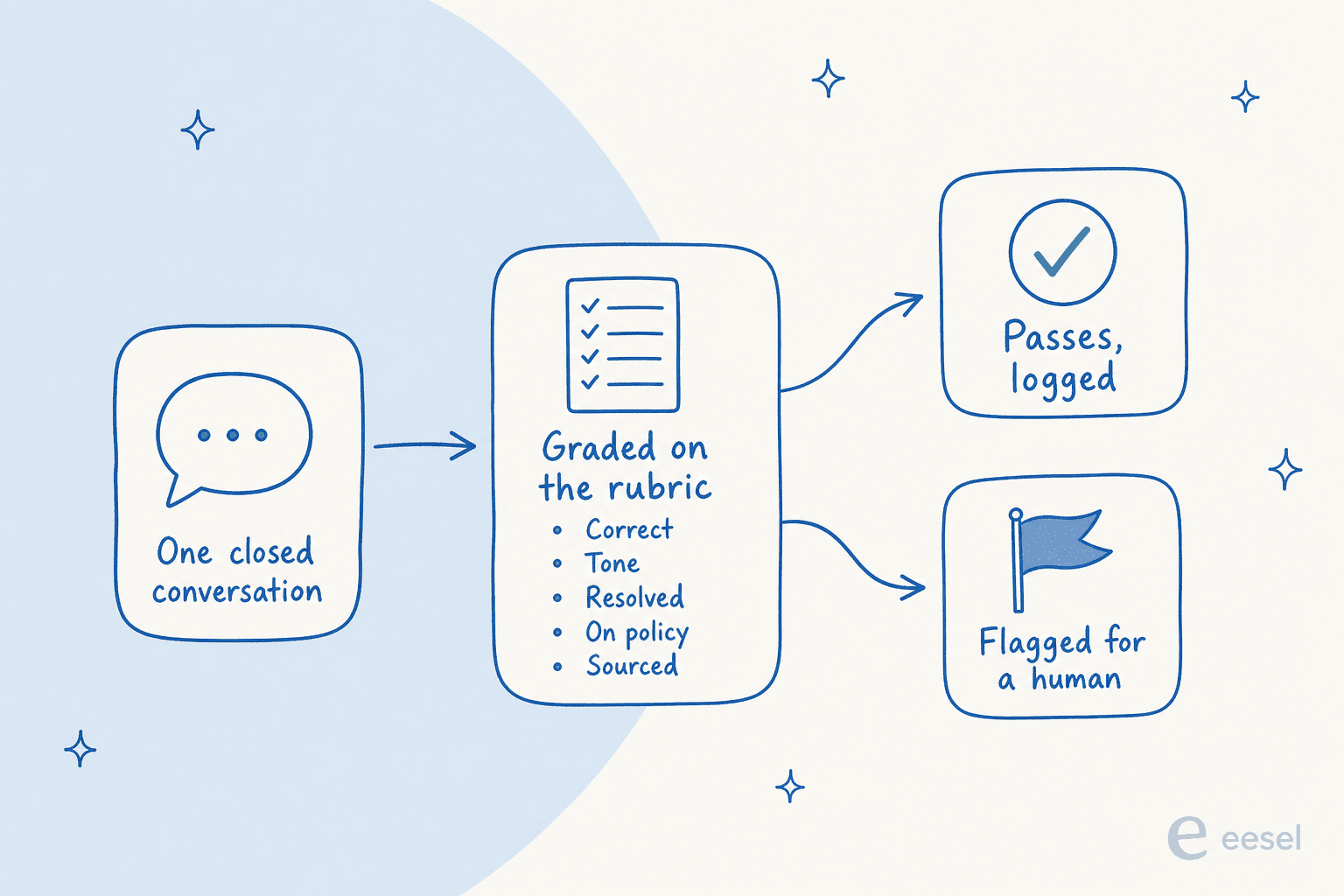
Uma conversa encerrada entra. A IA a avalia em algumas dimensões explícitas: estava factualmente correta, o tom estava certo, ela realmente resolveu o problema, seguiu a política, e citou uma fonte real em vez de inventar algo. As conversas que passam são registradas; as que pontuam baixo são sinalizadas para uma pessoa analisar. O resultado que você quer não é um número, é uma análise que você pode acompanhar ao longo do tempo, para que você possa ver que este lote falhou na mesma política ou que um tópico está puxando suas pontuações para baixo.
Duas coisas determinam o sucesso ou fracasso disso. Primeiro, a rubrica tem que ser explícita, sem "você vai saber quando ver." Cinco dimensões precisas vencem trinta vagas, tanto para a IA quanto para o humano. Segundo, você precisa alimentá-la com as conversas e a base de conhecimento da qual a resposta deveria ter vindo. Uma pontuação de "errado" só é útil se você sabe se o agente estava errado ou se os documentos estavam, e essa distinção é a diferença entre treinar uma pessoa e reescrever um artigo. Se você quiser a construção completa, escrevemos um passo a passo sobre fazer QA de suporte com IA.
Onde o QA com IA ainda precisa de um humano
Agora a outra metade honesta, porque um post de QA que só lista pontos fortes é exatamente o tipo de coisa que o QA com IA deveria capturar.
Voltando àquela auditoria. Os rascunhos do agente estavam na direção certa 88% das vezes, mas apenas 12% eram bons o suficiente para um agente enviar como estavam, e havia uma taxa de erro factual de 7%. Aprofundando na lacuna, é revelador: cerca de 65% das reescritas eram apenas de comprimento e tom (a IA escreveu oito frases onde a equipe envia três), cerca de 20% precisavam de dados que a IA não podia ver (uma busca em ERP ou logística), e apenas cerca de 5% eram a IA simplesmente errando. Portanto, a maior parte do que "precisa de um humano" é corrigível com melhor treinamento, mas aquela última fatia de erro factual é a parte que você nunca automatiza completamente.
O exemplo mais nítido que já observei: a IA de uma equipe dizia com confiança aos clientes "sim, suportamos seu modelo" para produtos que não estavam realmente em seu banco de dados, porque o centro de ajuda dizia "suportamos todos os modelos." A IA não estava alucinando, estava repetindo fielmente um documento que estava errado. Nenhuma quantidade de qualidade do modelo captura isso por conta própria. Um humano lendo o padrão sinalizado captura em cinco minutos. Essa é a verdadeira divisão de trabalho em IA versus suporte humano: a IA lê tudo e expõe o padrão suspeito, uma pessoa decide o que isso significa e corrige a causa raiz.
Portanto, as coisas para manter um humano: problemas novos sem precedente em seu histórico, julgamentos como uma exceção de boa vontade, qualquer coisa que depende de contexto de negócios que vive na cabeça de alguém em vez de nos seus documentos, e a calibração periódica das próprias pontuações da IA. Trate a nota da IA como a opinião de um segundo analista, não como um veredicto final, e você obtém a cobertura sem os pontos cegos.
O teste que a maioria das equipes ignora: a IA pode fazer QA de si mesma?
Aqui está a parte que a maioria dos textos sobre "IA para QA" passa rapidamente, e é a que mais me importa. Se você vai deixar a IA lidar com tickets, essa IA tem que passar no QA antes de tocar um cliente, e a maioria das equipes nunca executa essa verificação.
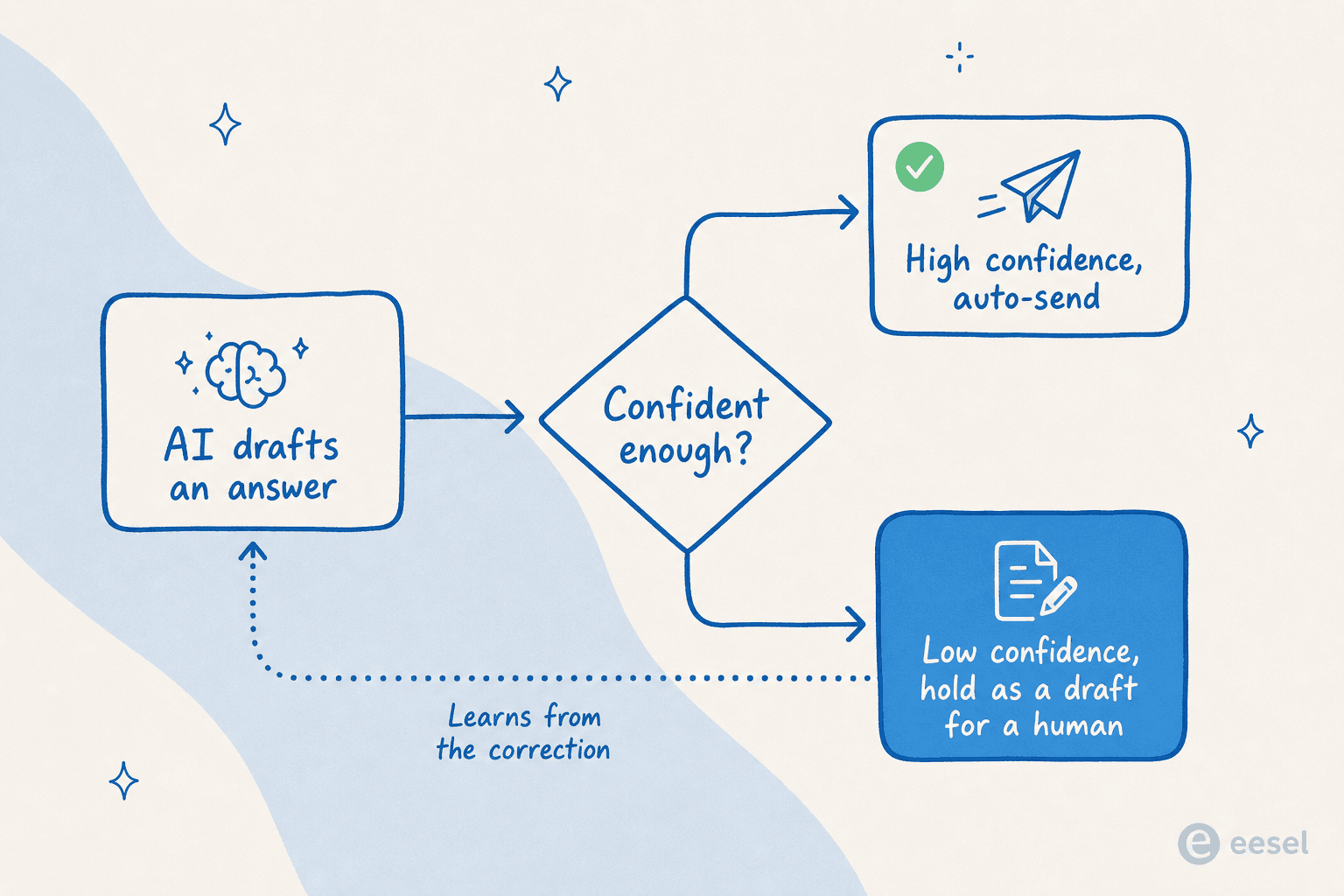
O mecanismo é o roteamento baseado em confiança. O agente apenas envia automaticamente respostas sobre as quais está confiante; qualquer coisa abaixo do limite ele retém como rascunho para um humano, e aprende com a correção para que o mesmo erro pare de se repetir. Um líder de suplementos DTC colocou perfeitamente para nós: uma IA que responde "desculpe, não sei" para tudo é inútil, mas uma IA que adivinha é pior, "porque ninguém pode reler 7.000 tickets para pegar os palpites." O QA é a resposta para ambos.
Então incorporamos a verificação na implementação. Antes de um agente eesel entrar em produção, você o executa em uma simulação contra seus tickets reais anteriores e vê sua qualidade e cobertura por tópico, sem clientes envolvidos. Foi assim que obtivemos os números de 93% e 7% em primeiro lugar, do lado seguro do vidro. Depois de entrar em produção, as mesmas pontuações aparecem em seus analytics do agente, para que o QA na automação nunca realmente pare.

Esta também é a resposta mais honesta para "posso confiar nele?" Você não confia por fé. Você faz QA, configura para rascunho em vez de envio automático onde sua confiança é baixa, e amplia sua autonomia conforme as pontuações justificam. Essa é a linha entre uma demonstração e uma implantação.
Como as equipes realmente usam o QA com IA no dia a dia
Na prática, ele se estabelece em um ciclo, e o ciclo importa mais do que qualquer pontuação individual. A IA pontua cada conversa à medida que ela encerra. Ela expõe os momentos de treinamento que um humano deve analisar, agrupados pelo que têm em comum, em vez de cinco tickets aleatórios. Um líder de equipe age com base nos padrões: treinando os agentes que foram sinalizados, corrigindo os documentos por trás dos erros recorrentes, atualizando as regras de marcação de tickets e escalonamento que um tópico com pontuação baixa expõe. Corrija o documento por trás de um erro recorrente e muitas vezes você reduz o volume de tickets ao mesmo tempo.
Em termos de ferramentas, você tem dois campos. Plataformas de QA dedicadas como Zendesk QA (o produto anteriormente conhecido como Klaus) e MaestroQA pontuam conversas automaticamente e alimentam fluxos de trabalho de treinamento, e são uma boa opção se o QA for uma função independente para você. O outro campo é o software de atendimento ao cliente com IA que inclui o QA junto com o agente fazendo o trabalho, para que o mesmo mecanismo que pontua as conversas da sua equipe seja o que faz o QA dos rascunhos da IA. Uma última barreira que vale mencionar: QA não é CSAT. Um cliente pode avaliar com cinco estrelas uma resposta confidentemente errada, então você quer tanto suas pontuações de QA quanto seu relatório de CSAT, não um substituindo o outro.
Experimente o eesel para QA de suporte
Se você quer QA de suporte com IA sem precisar conectar três ferramentas, é exatamente isso que o agente de helpdesk com IA da eesel foi construído para fazer. Ele se conecta ao seu helpdesk existente, lê suas conversas anteriores e sua base de conhecimento, e permite que você execute uma simulação sobre tickets históricos reais para que você possa ver qualidade e cobertura antes que qualquer coisa entre em produção.

A parte útil para o QA é que o mesmo mecanismo que pontua os rascunhos de um agente de IA é o que lê as conversas da sua equipe, então o QA de humanos e o QA de automação ficam em um único lugar em vez de duas planilhas. Ele se conecta em uma tarde, já conhece seu centro de ajuda, e os preços baseados em uso não cobram por usuário pelo privilégio de revisar seus próprios tickets. Gratuito para experimentar.
Perguntas Frequentes
A IA pode fazer garantia de qualidade no suporte com precisão?
Como o QA de suporte com IA realmente pontua uma conversa?
O que a IA não consegue fazer na garantia de qualidade do suporte?
Quanto do meu volume de suporte o QA com IA pode cobrir?
A IA também pode fazer QA de um agente de suporte com IA?
O QA de suporte com IA substitui meus analistas de QA?
Quais ferramentas podem fazer garantia de qualidade de suporte com IA?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.