Garantia de qualidade no suporte com IA: como realmente confiar no seu agente de IA
Riellvriany Indriawan
Katelin Teen
Última edição June 19, 2026

O que significa garantia de qualidade quando o agente é IA
O QA de suporte tradicional é um jogo de amostragem. Um líder de equipe pega talvez 2–5% dos tickets da semana passada, pontua-os com base em uma rubrica (o agente resolveu? foi gentil? seguiu a política?) e treina os humanos que falharam. Funciona porque os humanos são em sua maioria consistentes e falham de formas previsíveis.
Um agente de IA quebra duas dessas suposições. Ele lida com um volume muito maior do que qualquer processo de amostragem manual foi projetado para cobrir, e falha de maneiras desconhecidas. Um novo funcionário humano raramente inventa uma política de reembolso na hora; uma IA sem base sólida vai inventar, e em uma frase confiante e bem redigida que parece exatamente uma resposta correta. Então o QA deixa de ser "treinar os casos extremos" e passa a ser "verificar o sistema", mais parecido com o tipo de avaliação de agentes de IA que você faria em qualquer pipeline automatizado.
A mudança de perspectiva que importa: a garantia de qualidade de um agente de IA acontece em dois lugares, antes de ir ao ar e depois, não é um relatório mensal que você lê depois que o estrago está feito.
Por que a taxa de deflexão é a métrica que mente para você
Se você vai fazer QA em apenas um número, por favor não seja a taxa de deflexão. Ela conta conversas que não chegaram a um humano, agrupando silenciosamente dois resultados muito diferentes: clientes que a IA realmente ajudou e clientes que desistiram.
Profissionais de suporte sentem isso instintivamente. Uma responsável de operações no r/CustomerExperience descreveu o modo de falha com clareza:
"Meu chefe adora nossos números de deflexão, mas eu não confio neles. Tentei criar um relatório de tickets que foram reabertos em 24 horas, mas os clientes simplesmente abrem OUTRO ticket em vez de usar o fechado. Isso faz parecer que o bot fez um bom trabalho quando na verdade só irritou o cliente."
Uma resposta em um thread relacionado foi ainda mais direta: "Um bot pode 'completar com sucesso' um chat, mas se o usuário enviar um ticket por e-mail 20 minutos depois, esse bot foi horrível."
Esse é o problema todo de otimizar apenas para deflexão de nível 1. Silêncio não é o mesmo que resolução. A métrica que você realmente quer é a resolução combinada com as taxas de reabertura e contato repetido, para que um cliente que saiu frustrado apareça como uma perda em vez de se esconder dentro de um bonito número de dashboard.
As métricas que realmente dizem se o seu suporte com IA é bom
Nenhum número sozinho faz o trabalho. Boas métricas de suporte com IA funcionam como um painel, onde cada uma detecta uma falha que as outras perdem:
- Taxa de resolução é o número principal, mas defina-a honestamente como "problema do cliente resolvido sem um humano", não "conversa encerrada". Este é o número que vale a pena prever e acompanhar ao longo do tempo. A taxa de resolução é a coisa mais próxima de uma única fonte de verdade.
- Taxa de erros factuais é a métrica específica de IA. De uma amostra avaliada, quantas respostas estavam seguramente erradas? Esta é sua verificação de alucinações, e é a métrica que a maioria das equipes esquece de construir.
- Qualidade da escalação pergunta se o agente fez a transferência de forma limpa e no momento certo. Uma transferência para um humano limpa em um ticket difícil é um bom resultado, não uma falha.
- Taxa de reabertura e contato repetido é o detector de mentiras para a deflexão. Se tickets "resolvidos" continuam voltando, não estavam resolvidos.
- CSAT de IA, medido separadamente do CSAT humano. Acompanhe o CSAT de IA de forma independente para que uma boa pontuação do bot não seja sustentada pelos seus melhores agentes humanos, e vice-versa.
Veja como um processo de avaliação real parece quando você coloca números. Quando a equipe fez QA em um piloto — um varejista online alemão de joias com cerca de 1.000 tickets por mês no Zendesk e Shopify — o quadro foi específico em vez de vago: 93% de precisão na triagem, 100% de detecção de spam sem falsos positivos nos 22% da caixa de entrada que era lixo, mas apenas 12% dos rascunhos bons o suficiente para enviar sem tocar e uma taxa de erros factuais de 7%. Essa distribuição diz exatamente onde investir a próxima semana, algo que nenhum número de deflexão jamais poderia.

O mesmo thread do Reddit ao qual continuo voltando tinha alguém que descreveu quase exatamente este painel. Como um praticante do Reddit que havia conversado com muitas equipes de suporte colocou: "A taxa de deflexão fica bem em dashboards, mas esconde problemas de qualidade. Melhores métricas seriam: taxa de resolução automatizada, CSAT de IA vs. humano, tempo de escalação, taxa de reabertura após respostas do bot." Quando as pessoas que executam a automação real do Zendesk e as que a constroem chegam à mesma lista, essa é a lista.
QA antes do go-live: simule contra seus próprios tickets
Esta é a parte que a maioria das equipes pula, e a mais valiosa deste post inteiro. Você não precisa descobrir se a sua IA é boa soltando-a em clientes reais e lendo as respostas furiosas. Você pode descobrir primeiro.
O método é a simulação: pegue o agente, aponte-o para milhares dos seus tickets históricos já resolvidos e faça-o gerar a resposta que ele teria enviado, depois compare com o que seu time humano realmente fez. Como você já sabe a resposta certa, você obtém uma previsão da taxa de resolução, uma lista de tópicos em que a IA tem dificuldades e uma taxa de erros factuais, tudo sem um único cliente real no raio de impacto. É a versão segura de testes adversariais, executada contra seu histórico real de tickets em vez de um conjunto de testes sintético.
Isso não é teórico para nós. A eesel executa um modo de simulação que faz exatamente isso antes de qualquer agente entrar em produção, e a razão de sua existência é cicatrizes. Já vi um bot que soa confiante dar silenciosamente uma resposta errada, e todos que implantaram um também viram. Um dos nossos clientes, um time dinamarquês de telemática veicular no Zendesk, sofreu a versão clássica no início: porque a base de conhecimento deles dizia "oferecemos suporte a todos os modelos", a IA alegremente dizia aos clientes que suportava marcas de carros que na verdade não estavam no banco de dados deles. A única forma confiável de detectar essa classe de bug é ver as respostas erradas antes que os clientes as vejam, contra seus próprios tickets.
QA após o go-live: amostrar, avaliar e ajustar
Uma vez que você está no ar, a garantia de qualidade vira um ritmo. Extraia uma amostra fresca de conversas reais toda semana, avalie-as com base no painel acima e alimente o que você aprendeu de volta para o agente. Seu helpdesk já guarda o material bruto: a maioria das plataformas expõe logs de conversas dos quais você pode extrair uma amostra, e um bom painel de análise transforma isso em uma tendência em vez de uma leitura pontual.

A avaliação em si não precisa ser pesada. Aprove e rejeite respostas com um motivo ("muito formal", "ignorou a política de devolução") e certifique-se de que esse sinal realmente treine o agente em vez de desaparecer no vazio. Um número surpreendente de compradores nos faz exatamente essa pergunta durante a avaliação, alguma versão de "vocês rastreiam se aprovo ou rejeito respostas, e isso muda alguma coisa?" Se o ciclo de feedback for real, cada passagem de QA melhora as respostas da semana seguinte. Se não for, você está avaliando no vácuo.
Uma coisa a observar: como o agente se comporta quando algo quebra, como a API do seu helpdesk sendo limitada no meio de uma conversa. Amogh, fundador da eesel, tem uma frase sobre isso que ficou gravada no nosso time: se uma falha é silenciosa, ela é "da classe de falha silenciosa, a pior classe para a confiança". Uma IA que falha ruidosamente e transfere está fazendo o trabalho do QA por você; uma que falha silenciosamente e adivinha é exatamente o que sua amostra semanal existe para detectar.
A parte mais difícil: confiar que a IA sabe o que não sabe
Todas as métricas acima ficam mais fáceis no momento em que a IA para de tentar responder tudo. Esta é a coisa mais comum que ouço de equipes que nos avaliam, e vale mais do que qualquer atualização de modelo.
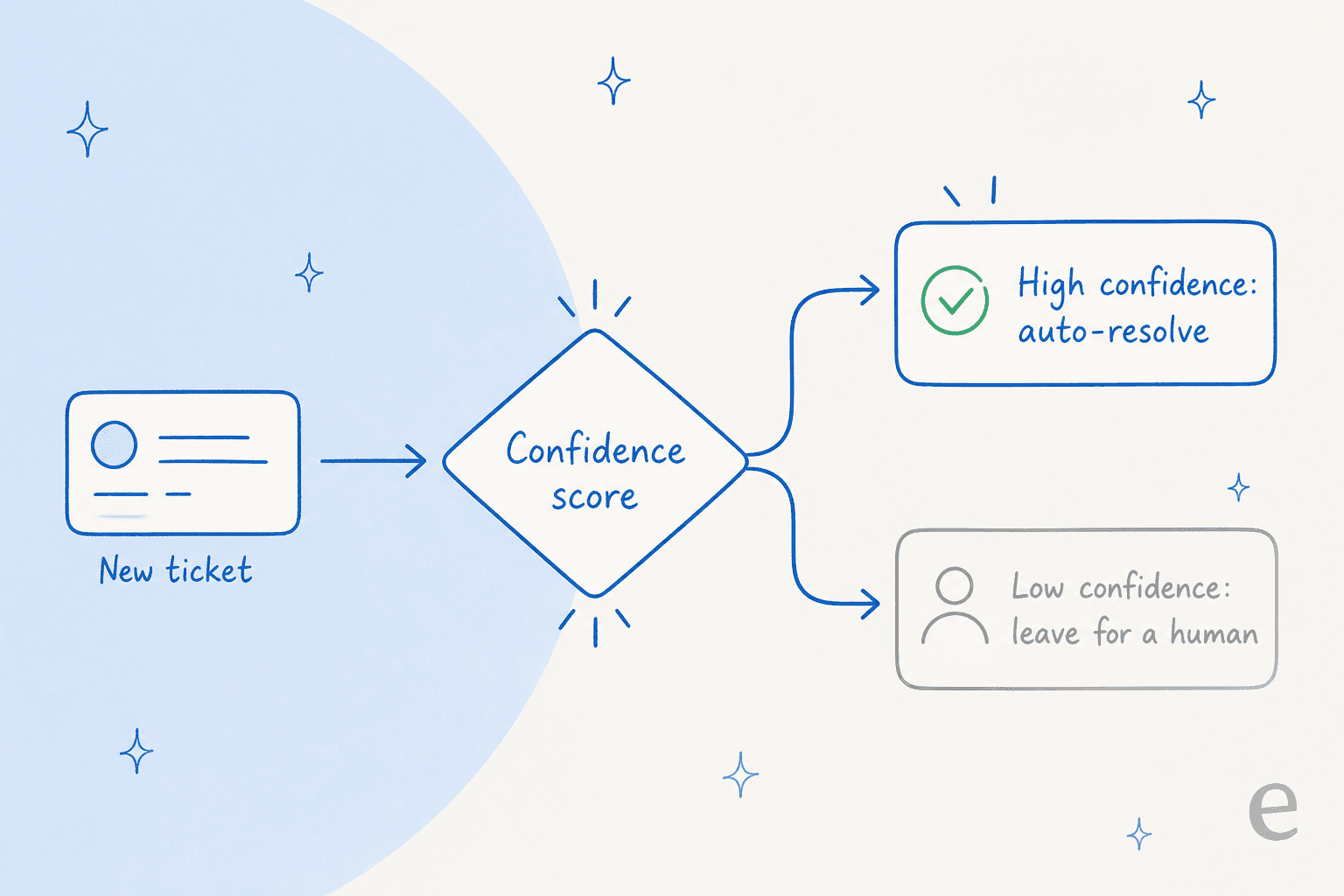
Uma líder de CX em uma marca DTC de suplementos no Gorgias, gerenciando cerca de 7.000 tickets por mês, expressou melhor do que eu jamais poderia: a IA nunca vai responder 100% das perguntas, mas se tentar e simplesmente disser "desculpe, não sei", ninguém pode revisar 7.000 tickets para ver se ela realmente fez um bom trabalho. O que eles queriam era uma IA que "só gerenciasse os tickets para os quais tem confiança e todos os outros deixasse em paz."
Isso é roteamento baseado em confiança, e é o controle de QA de maior impacto que você tem. Quando o agente só fala acima de um limiar de confiança e encaminha silenciosamente o resto para um humano, sua taxa de erros factuais cai, suas escalações se tornam significativas e as respostas que você precisa avaliar são um conjunto menor e de maior qualidade. O mesmo thread do Reddit tinha um aviso certeiro: um praticante lembrou a todos para não "cair na conversa de 'zero alucinações'" enquanto reencadrava toda a conversa em torno de resolução versus deflexão. O roteamento por confiança é como você chega lá honestamente: não alegando que a IA nunca erra, mas mantendo-a quieta quando ela pode errar.
Para equipes reguladas isso não é negociável. Um cofundador de uma empresa de legal-tech nos disse que só conseguiram adotar IA porque podiam "definir limites exatos sobre as fontes e ela sempre fornece citações transparentes", a diferença entre ser útil e cruzar para dar consultoria jurídica. Citações e portões de confiança não são funcionalidades, são o QA.
Um fluxo de trabalho de QA que você realmente consegue executar
Se você quer um ponto de partida concreto, aqui está o ciclo que eu configuraria para qualquer equipe implantando um agente de IA, seja no Zendesk, Freshdesk ou qualquer helpdesk com IA:
- Simule primeiro. Antes do lançamento, reproduza o agente contra alguns milhares de tickets passados e leia uma amostra das respostas hipotéticas. Defina seu critério de go-live na taxa de resolução prevista, não em intuição.
- Lance de forma limitada. Ative o agente para um ou dois tópicos seguros, não para toda a fila de tickets. O roteamento por confiança facilita isso.
- Avalie semanalmente. Amostre conversas reais, pontue-as em resolução, erros factuais e qualidade de escalação, e rejeite respostas ruins com um motivo que treine o agente.
- Observe os detectores de mentiras. Acompanhe as taxas de reabertura e contato repetido ao lado da deflexão para que um cliente frustrado não possa se esconder como uma vitória.
- Alerte sobre desvios. Configure o monitoramento para que uma queda repentina de qualidade te avise entre as revisões.
Execute isso por um mês e você terá algo que a maioria das histórias de "implantamos uma IA" nunca consegue: uma resposta defensável para "como você sabe que é boa?"
Experimente a eesel para um suporte com IA que você realmente consegue avaliar
A maior parte deste post é apenas descrevendo como a eesel funciona, porque a garantia de qualidade é aquilo em torno do qual construímos o produto. Você conecta seu helpdesk e base de conhecimento, a eesel treina nos seus tickets e documentos passados, e antes de ir ao ar seu modo de simulação reproduz o agente em milhares das suas conversas históricas para que você possa prever a taxa de resolução e ler as respostas erradas em privado. Após o lançamento, o roteamento baseado em confiança mantém o agente quieto em qualquer coisa de que não tem certeza, e os relatórios mostram o que avaliar cada semana.

É gratuito experimentar e você pode executar uma simulação completa com seus próprios tickets antes de se comprometer com qualquer coisa, que é o QA mais honesto que existe: veja como teria respondido a seus clientes reais e decida. Experimente a eesel e comece com uma simulação.
Perguntas frequentes
O que é garantia de qualidade no suporte ao cliente com IA?
Como medir a qualidade de um agente de suporte com IA?
A taxa de deflexão é uma boa métrica para a garantia de qualidade no suporte com IA?
Como evitar que um agente de suporte com IA alucine?
Com que frequência deve-se fazer QA no agente de suporte com IA?
É possível testar um agente de suporte com IA antes de ir ao ar?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








