
Então, o que o Claude Fable 5 realmente consegue fazer?
O Claude Fable 5 é a quinta geração de modelos da Anthropic e um novo nível de «classe Mythos» que fica acima do Claude Opus 4.8, que, por sua vez, fica acima do Sonnet 4.6. Se você leu nossa visão geral do Claude, este é o novo teto. Foi lançado em 9 de junho de 2026 e roda no claude.ai, na API do Claude, no Claude Code, na AWS e no Microsoft Foundry.
Mas especificações e níveis não são realmente o que as pessoas querem dizer quando perguntam o que ele consegue fazer. Elas querem dizer: que trabalho posso entregar a ele e confiar que ele vai concluir? Aqui está o mapa honesto de suas capacidades concretas, e depois passamos por cada uma.
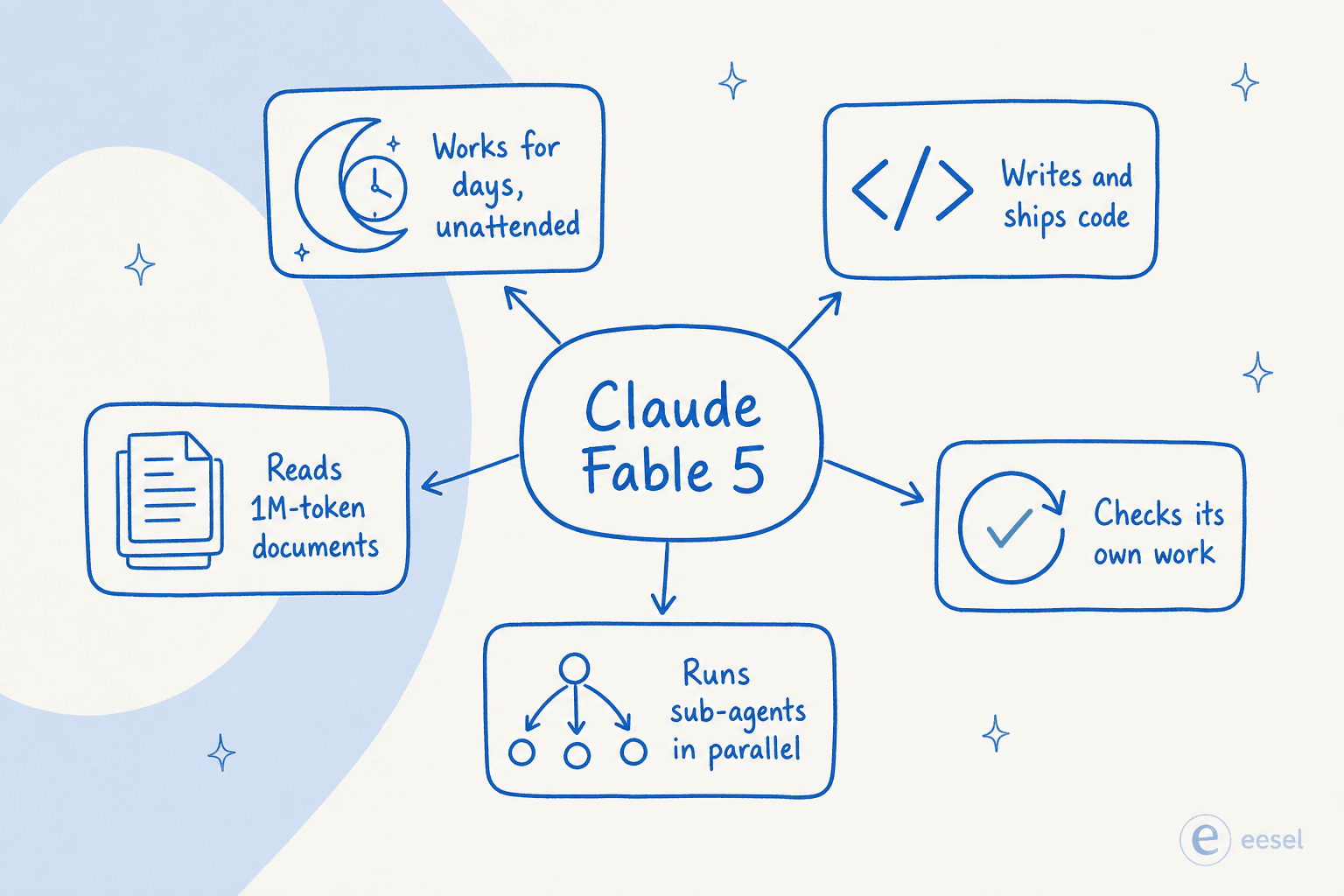
Ele funciona de forma autônoma por dias e depois revisa o próprio trabalho
Esta é a capacidade em torno da qual a Anthropic realmente construiu o Fable 5, e é a que mais importa. Execute-o dentro de um harness como o Claude Code ou os Claude Managed Agents e, nas palavras da Anthropic, ele consegue «trabalhar por dias a fio: planejando ao longo das etapas, delegando a subagentes e revisando o próprio trabalho».
Esse ciclo — planejar, depois delegar, depois trabalhar, depois revisar — é a parte que é realmente nova. Modelos anteriores perdiam o fio em tarefas longas de várias etapas; este mantém o rumo e, crucialmente, corrige a própria lição de casa. A Anthropic o descreve como «minucioso, proativo e revisa o próprio trabalho», e os provedores de nuvem detalham um ciclo de planejar, revisar e refinar embutido. A autocorreção é a diferença entre um agente que você precisa supervisionar e um que você pode deixar rodando a noite toda.
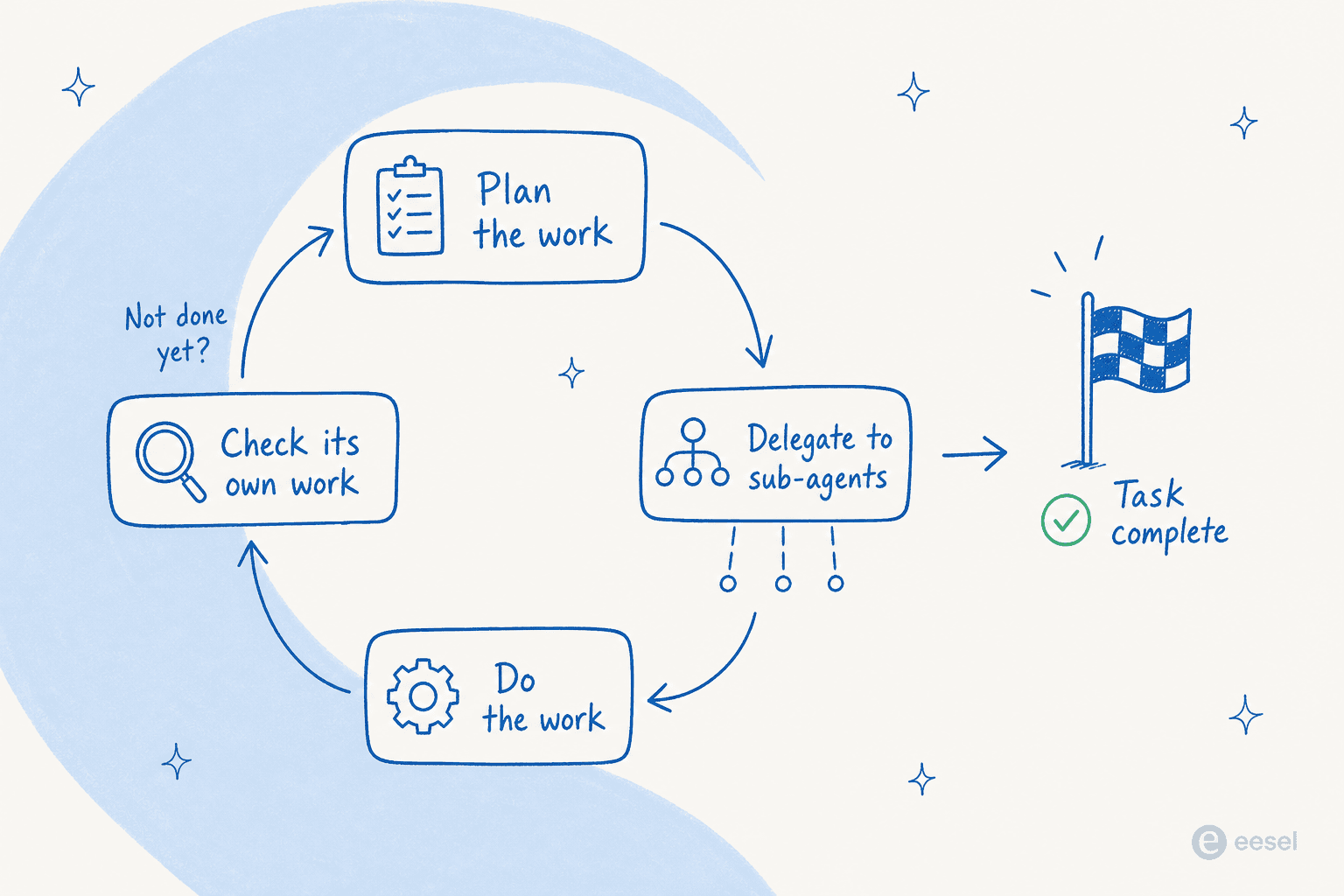
A escala que isso desbloqueia é real. Nos primeiros testes, a Stripe apontou o Fable 5 para uma base de código Ruby de 50 milhões de linhas e executou uma migração em todo o projeto em um dia, e relatos da comunidade descrevem sessões que sobem até 1.000 subagentes em paralelo para trabalho em escala de base de código. Essa capacidade de manter um objetivo, dividi-lo em etapas e avançar por elas é exatamente o que separa um agente de IA de um chatbot baseado em regras: um conclui o trabalho, o outro espera a próxima instrução.
Ele escreve e publica código de nível de produção
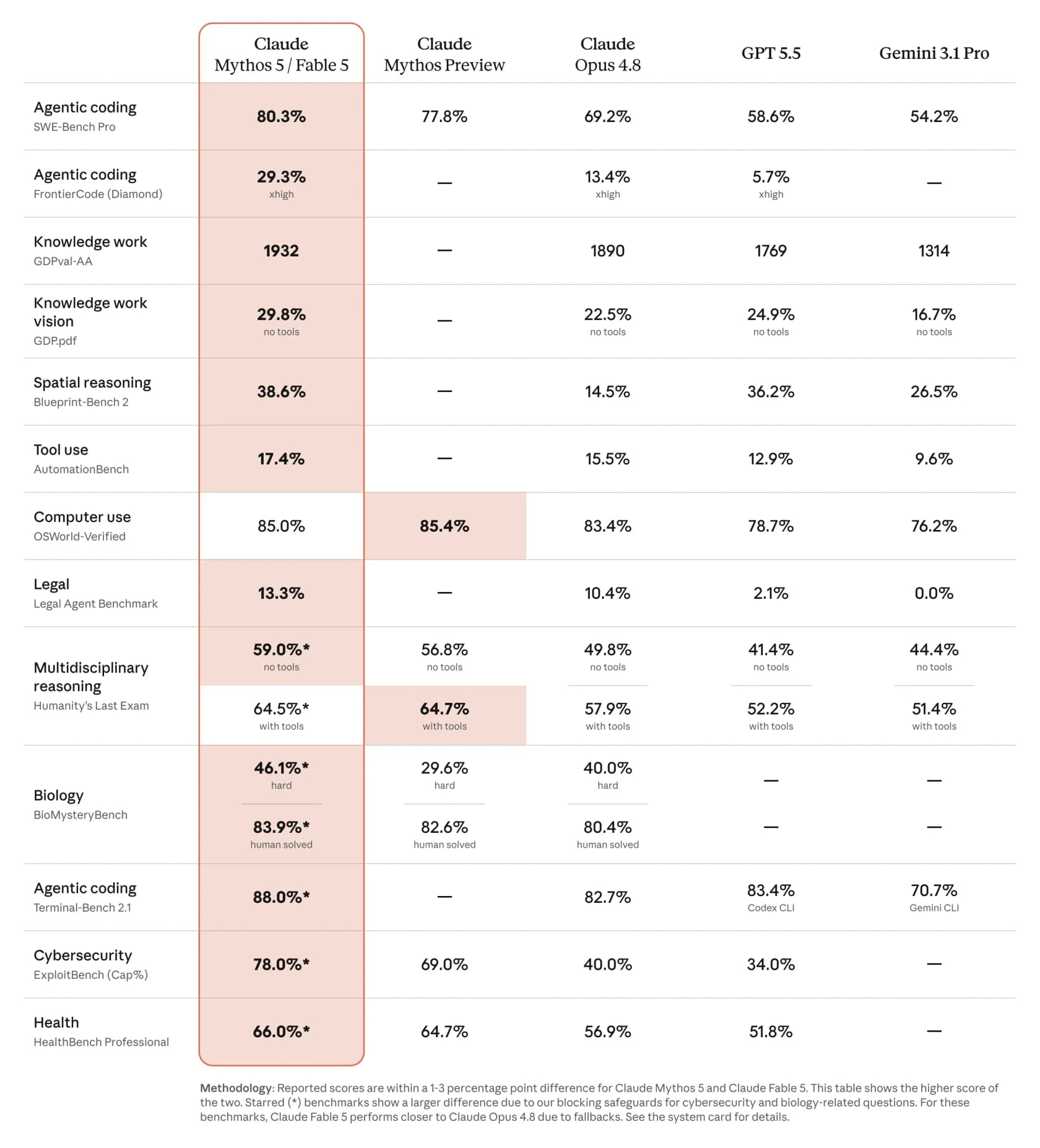
A coisa mais chamativa que o Claude Fable 5 consegue fazer é escrever software que realmente funciona. Na comparação publicada pela Anthropic, ele marca 80,3% no SWE-Bench Pro de codificação agêntica, contra 69,2% do Opus 4.8, com o GPT 5.5 em 58,6% e o Gemini 3.1 Pro em 54,2%. No benchmark mais difícil FrontierCode (Diamond), ele mais que dobra o Opus, saltando para 29,3% a partir de 13,4%. A CNBC relatou a diferença como mais de 10% acima do Opus 4.8 em alguns testes.
Números são uma coisa; um dia inteiro de trabalho real é outra. O desenvolvedor Simon Willison apontou o Fable para sua biblioteca LLM de código aberto, e ele identificou e implementou quatro correções separadas, e depois publicou um novo release escrito quase inteiramente pelo modelo. O veredito dele resume o teto de produtividade:
«Estou realmente impressionado com a qualidade do design da API, dos testes, do código e da documentação que o Fable montou para isso. Passei várias horas nisso hoje, mas parece o equivalente a vários dias de trabalho.» - Simon Willison
Ele não estava sozinho. Andrej Karpathy o chamou de um salto qualitativo que merece um aumento de versão principal, e um desenvolvedor que rodava o benchmark FrontierCode publicou uma progressão impressionante: Opus 4.7 em 5,2%, Opus 4.8 em 13,4%, Fable 5 em 29,3%. Se você está avaliando onde ele se posiciona em relação ao resto do cenário, nossa lista das melhores ferramentas de assistente de codificação com IA e das melhores ferramentas de desenvolvimento com IA do Claude é uma boa próxima leitura.
Ele lê os documentos longos e bagunçados que você já tem
Boa parte do trabalho empresarial não é código, são documentos, e é aqui que a janela de contexto de 1.000.000 de tokens mostra seu valor. O Fable 5 «entende diagramas, gráficos e tabelas aninhados em arquivos e PDFs», algo que a Anthropic enquadra em torno de trabalho financeiro, jurídico e de análise, e não há sobretaxa de preço por preencher esse contexto completo.
A prova concreta veio de um usuário do Hacker News que lhe entregou um PDF de 50 páginas de especificações densas e interconectadas e recebeu de volta um detalhamento correto do que estava feito, parcialmente feito e faltando:
«Eu dei a ele um PDF de 50 páginas de especificações bastante densas e interconectadas e perguntei quais haviam sido implementadas... ele identificou corretamente o que estava feito, o que estava parcialmente feito e o que estava faltando.» - Comentarista do Hacker News
Para qualquer equipe sentada sobre uma pilha de contratos, documentos de políticas ou uma extensa base de conhecimento, isso é mais útil no dia a dia do que mais um ponto em um ranking de codificação. É também o mesmo músculo que um agente de suporte usa quando lê seus documentos de ajuda e tickets anteriores para responder a um cliente, só que apontado para documentos internos.
Quanto custa fazer tudo isso
Aqui está a parte que modera o entusiasmo. Tudo acima roda a preços de ferramenta de fronteira: US$ 10 por milhão de tokens de entrada e US$ 50 por milhão de saída, exatamente o dobro do Opus 4.8. Tokens de entrada em cache recebem um desconto de 90%, e há uma sobretaxa de 1,1x para inferência somente nos EUA, mas a tarifa principal é o que você vai sentir. Para ver como o Fable 5 se compara ao resto da linha, nosso guia de preços do Claude detalha cada nível, e o plano Claude Pro é onde a maioria das pessoas o conhece pela primeira vez.
| Especificação | Claude Fable 5 |
|---|---|
| Lançamento | 9 de junho de 2026 |
| Classe do modelo | «Classe Mythos», um nível acima do Opus 4.8 |
| Janela de contexto | 1.000.000 de tokens |
| Saída máxima | 128.000 tokens |
| Data de corte de conhecimento | Janeiro de 2026 |
| Preço de entrada | US$ 10 / 1 M de tokens (US$ 1 em cache) |
| Preço de saída | US$ 50 / 1 M de tokens |
| Sobretaxa de contexto longo | Nenhuma |
Quanto você realmente gasta depende quase inteiramente de quanto você o deixa pensar. Simon Willison rodou seu teste de «desenhe um pelicano em uma bicicleta» nos cinco níveis de esforço de raciocínio, e o custo de uma única imagem variou de menos de 10 centavos no «low» a cerca de 72 centavos no «max». O nível de esforço é um botão que você ajusta, e é a principal alavanca da sua conta.
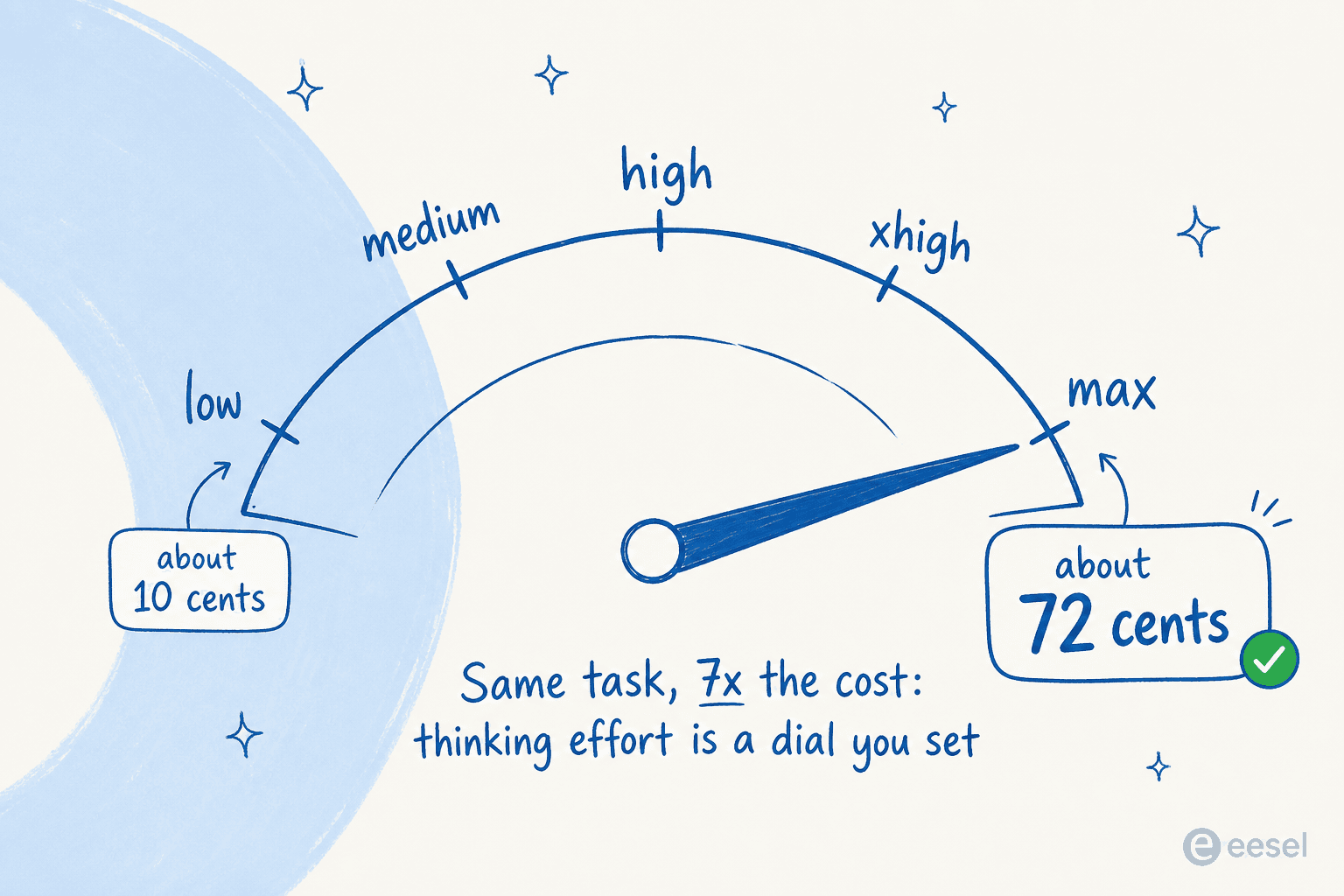
A conta sobe rápido na ponta alta. Willison registrou um único dia de testes com US$ 110,42 de gasto em tokens. Mas há um contrapeso real: o responsável por avaliações da Canva descobriu que o Fable usava cerca de metade dos tokens do Opus 4.8 em seus harnesses agênticos internos, de modo que um modelo mais inteligente que termina em menos passos pode acabar custando aproximadamente o mesmo no mundo real. A lição não é «o Fable é inacessível», é que seus custos dependem inteiramente de como você o executa.
O que o Claude Fable 5 não fará
As capacidades cortam para os dois lados, e há uma coisa que o Fable 5 deliberadamente não fará com força total. Para prompts de cibersegurança, biologia, química e destilação de modelos, uma nova geração de classificadores detecta o tema e roteia sua resposta para o Opus 4.8 no lugar, e você é avisado de que isso aconteceu. A Anthropic diz que pelo menos 95% das sessões nunca acionam nenhum fallback.
O problema são os falsos positivos. Desenvolvedores relataram terem sido trocados para o modelo mais fraco no meio da sessão para trabalho completamente inofensivo, incluindo um usuário que teve um protocolo básico de manipulação de líquidos recusado, sem nada arriscado nele. O escritor de políticas de IA Nathan Lambert apontou um segundo mecanismo, mais silencioso, para prompts que parecem pesquisa de IA de fronteira, em que o modelo pode ficar menos eficaz sem avisar você. O conselho prático: se o seu trabalho está em um vertical técnico, teste antes de se comprometer com ele.
O que tudo isso significa se você lidera uma equipe de suporte
É aqui que vivemos, então vamos ser específicos. Diante de tudo o que o Fable 5 consegue fazer, um líder de suporte deveria se apressar para ligá-lo ao seu helpdesk? Na maioria das vezes, não tanto quanto o hype sugere.
Aqui está a verdade incômoda sobre a IA para atendimento ao cliente: para tickets de nível 1, o modelo raramente é o gargalo. A maioria das equipes em busca de automação de atendimento ao cliente está silenciosamente supervalorizando qual modelo está por baixo. Um Opus 4.8 bem fundamentado ou até o Sonnet 4.6 já responde corretamente a esmagadora maioria das perguntas do tipo «onde está meu pedido», «como redefino minha senha», «qual é a política de reembolso de vocês». Pagar o dobro pelo Fable 5 para respondê-las é como alugar um carro de Fórmula 1 para levar as crianças à escola. O que realmente decide se o seu agente de helpdesk com IA funciona é tudo o que está em torno do modelo. É o mesmo padrão que separa as ferramentas fortes em qualquer lista de software de helpdesk com IA das esquecíveis.
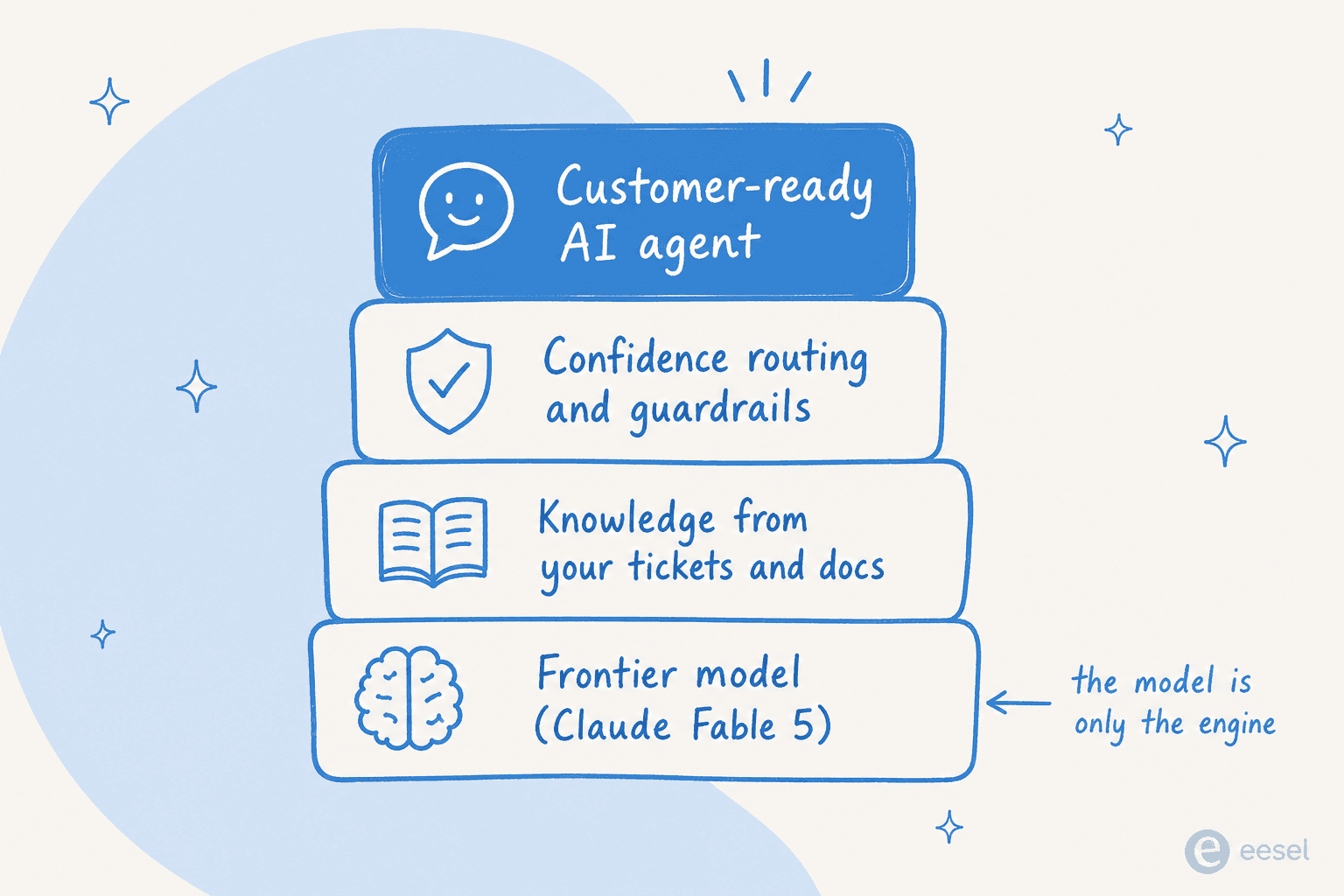
Três coisas importam mais do que o nível do modelo. Primeiro, ele conhece o seu negócio? O ganho vem de treinar com seus tickets anteriores e documentos de ajuda, não de um modelo base mais inteligente. Segundo, ele sabe quando ficar quieto? Modelos brutos respondem com confiança mesmo quando estão errados, que é precisamente por que chatbots dão respostas ruins; agentes de produção precisam de roteamento baseado em confiança, o coração de qualquer boa configuração de triagem de tickets, para que tickets de baixa confiança sejam rascunhados ou escalados, não enviados automaticamente. Como disse o líder de CX de um fornecedor DTC de suplementos em uma entrevista com clientes, a IA nunca responderá 100% das perguntas, então o que eles realmente querem é um agente que lide apenas com os tickets sobre os quais tem confiança e deixe o resto em paz. Isso é uma capacidade de produto, não uma capacidade do modelo.
Terceiro, você pode confiar nele antes de colocá-lo no ar? Isso aponta diretamente para a questão construir-ou-comprar, que surge o tempo todo: «A Anthropic acabou de lançar um modelo incrível, por que não construir nosso bot de suporte sobre a API?». Você pode. Também é um projeto maior do que parece, porque o modelo dá a você inteligência, mas não a conexão com o helpdesk, as proteções, o ambiente de simulação nem os relatórios. Várias equipes técnicas que tentaram acabaram migrando para comprar:
«Poderíamos tentar escrever nosso próprio aplicativo de LLM, mas não queríamos investir nosso tempo nisso. Queríamos algo que não tivéssemos que manter.» - Karel, GENERAL BYTES
Um modelo de fronteira é a camada de baixo do stack, não o stack inteiro. Se o seu produto principal é IA, construa. Se for qualquer outra coisa e você só quer tickets bem respondidos, comprar as camadas acima do modelo é mais rápido, mais barato e menos frágil, a mesma lógica por trás de escolher qualquer IA para automação de tickets em vez de um script caseiro.
Experimente a eesel
A eesel AI é a camada que fica em cima de modelos de fronteira como o Claude, então você obtém a capacidade sem o projeto de engenharia. Ela se conecta ao seu helpdesk existente (Zendesk, Freshdesk, HubSpot, Gorgias e mais de 100 integrações), aprende com seus tickets anteriores e documentos de ajuda já no primeiro dia, e responde em triagem, rascunho e resolução.

O diferencial é a parte que o Fable 5 não consegue dar a você sozinho: um modo de simulação que roda o agente contra milhares dos seus tickets anteriores para que você veja exatamente como ele teria respondido, e qual seria a sua taxa de resolução, antes de um único cliente falar com ele. Foi assim que a Gridwise chegou a 73% das solicitações de nível 1 resolvidas no primeiro mês. E como o preço é baseado em uso, a US$ 0,40 por ticket resolvido e sem taxas por assento, você paga por resultados, não por tokens que não consegue prever. Você pode experimentar a eesel gratuitamente com US$ 50 de uso e sem cartão de crédito.
Perguntas frequentes
O que o Claude Fable 5 consegue fazer que os modelos mais antigos não conseguiam?
O Claude Fable 5 consegue escrever e executar código por conta própria?
O Claude Fable 5 consegue lidar com perguntas de atendimento ao cliente?
Quanto custa rodar o Claude Fable 5?
O que o Claude Fable 5 não consegue fazer?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.





