
Então, o que exatamente é o Claude Fable 5?
A Anthropic apresenta o Fable 5 como um «modelo de nível Mythos criado para seus projetos mais ambiciosos e de longa duração», e a escolha das palavras importa. «Classe Mythos» é um nível de capacidade totalmente novo que a empresa está introduzindo acima de sua linha Opus existente, da mesma forma que o Opus sempre ficou acima do Sonnet e do Haiku. É a quinta geração de modelos, e a Anthropic diz que ele foi «projetado para lidar com tarefas que duram dias, complexas e assíncronas que os modelos anteriores não conseguiam sustentar».
A parte um pouco confusa é que o Fable 5 foi lançado como uma metade de um par. O Fable 5 é a versão pública e protegida que qualquer pessoa com acesso à API ou um plano pago do Claude pode usar. O Mythos 5 é o mesmo modelo subjacente com os classificadores de segurança retirados, restrito a parceiros verificados de cibersegurança e biologia através do Project Glasswing da Anthropic. Simon Willison, que passou um dia inteiro testando, disse de forma direta: a Anthropic diz que o Fable 5 «oferece o mesmo desempenho que o Claude Mythos 5, exceto com proteções muito mais rígidas em vigor».
A SecurityWeek capturou por que isso é um marco especificamente para a Anthropic: a empresa diz que isso «marca a primeira vez que um modelo dessa classe de capacidade foi considerado seguro o suficiente para acesso amplo do público e dos desenvolvedores». Em outras palavras, o nível Mythos já existia; o que é novo é deixar o público geral chegar perto dele.
As especificações que importam
Se você só quer a versão resumida, é aqui que o Fable 5 se posiciona. A janela de contexto e a data de corte vêm das notas práticas de Simon Willison; os preços são confirmados tanto pela CNBC quanto pela SecurityWeek.
| Especificação | Claude Fable 5 |
|---|---|
| Lançamento | 9 de junho de 2026 |
| Classe do modelo | «Classe Mythos», um nível acima do Opus 4.8 |
| Janela de contexto | 1.000.000 de tokens |
| Saída máxima | 128.000 tokens |
| Data de corte de conhecimento | Janeiro de 2026 |
| Preço | US$ 10 / 1M entrada, US$ 50 / 1M saída (2x Opus 4.8) |
| Sobretaxa de contexto longo | Nenhuma |
| Onde executá-lo | claude.ai, a API do Claude, Claude Code, Claude Managed Agents, AWS e Microsoft Foundry |
Um detalhe que vale a pena destacar para quem trabalha com documentos longos: não há acréscimo de preço por usar o contexto completo de 1M, o que nem sempre é o caso com modelos de fronteira. O ID da API, se você for conectá-lo por conta própria, é claude-fable-5.
Quão poderoso ele é, na verdade?
É aqui que o Fable 5 conquista o rótulo de «mais poderoso». Na comparação publicada pela Anthropic, ele registra um salto notável em praticamente todos os benchmarks relevantes, e as distâncias em relação ao resto do campo não são sutis.
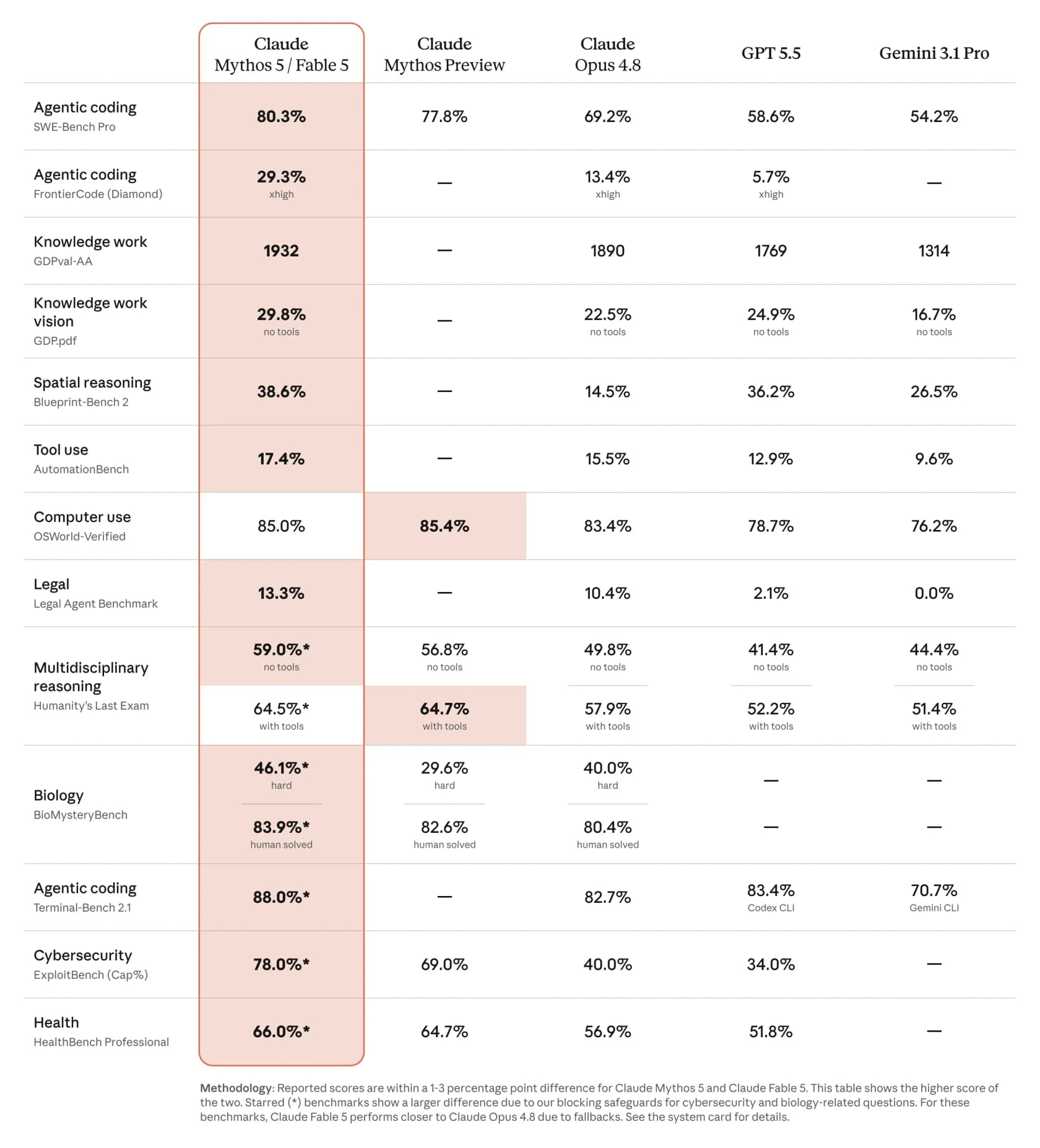
Alguns números que vale a pena extrair dessa tabela: 80,3% no SWE-Bench Pro para programação agêntica, contra 69,2% do Opus 4.8, 58,6% do GPT 5.5 e 54,2% do Gemini 3.1 Pro. No benchmark mais difícil, FrontierCode (Diamond), ele mais que dobra o Opus, saltando para 29,3% a partir de 13,4%. A reportagem da CNBC está alinhada com a tabela, observando que em alguns benchmarks o Fable pontuou mais de 10% acima do Claude Opus 4.8.
Os profissionais confirmaram isso rapidamente. Andrej Karpathy o chamou de mudança de patamar que merece um salto de versão maior, e um desenvolvedor que executou o benchmark FrontierCode avaliado por mantenedores de OSS publicou uma progressão marcante: Opus 4.7 com 5,2%, Opus 4.8 com 13,4%, Fable 5 com 29,3%.
Há uma ressalva honesta a se ter em mente, e ela vem de Nathan Lambert: essas pontuações publicadas são um limite superior. Como ele observa, «alguns dos prompts serão rebaixados para o Opus 4.8 com os filtros de segurança atuais», de modo que os números que um usuário real obtém em um tópico sinalizado nem sempre vão corresponder ao gráfico. Mais sobre isso abaixo.
Como é realmente usá-lo
Benchmarks são uma coisa; um dia inteiro de trabalho real é outra. O relato em primeira mão mais útil veio de Simon Willison, que descreveu o modelo em uma palavra: uma fera.
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do." - Simon Willison
Seu exemplo mais nítido da alavancagem: ele apontou o Fable para sua biblioteca LLM de código aberto, e ele identificou e implementou quatro correções distintas, depois publicou uma nova versão (LLM 0.32a3) que, nas palavras dele, foi escrita quase inteiramente pelo Fable. A avaliação dele diz quase tudo o que você precisa saber sobre o teto de produtividade aqui:
"I'm really impressed with the quality of API design, tests, code and documentation that Fable put together for this. I spent several hours on it today, but it feels like several days' worth of work." - Simon Willison
Ele também executou seu teste canônico de «gerar um SVG de um pelicano andando de bicicleta» em todos os cinco níveis de esforço de raciocínio, o que é uma visão concreta e agradável do controle entre esforço e custo. O pelicano de esforço «max» abaixo queimou 14.430 tokens de saída, cerca de 72 centavos por uma única imagem, contra menos de 10 centavos no «low».

| Nível de esforço | Tokens de saída | Custo por SVG |
|---|---|---|
| low | 1.929 | ~9,67 ¢ |
| medium | 2.290 | ~11,48 ¢ |
| high | 2.057 | ~10,31 ¢ |
| xhigh | 5.992 | ~29,99 ¢ |
| max | 14.430 | ~72,18 ¢ |
Fonte: o detalhamento por nível de esforço de Simon Willison.
Agentes de longo horizonte são a verdadeira manchete
As pontuações de programação são a parte vistosa, mas aquilo para o que a Anthropic realmente construiu o Fable 5 é trabalho sustentado e autônomo. Execute-o em um harness como o Claude Code ou o Claude Managed Agents e a Anthropic diz que ele pode «trabalhar por dias seguidos: planejar ao longo de etapas, delegar a subagentes e verificar o próprio trabalho».
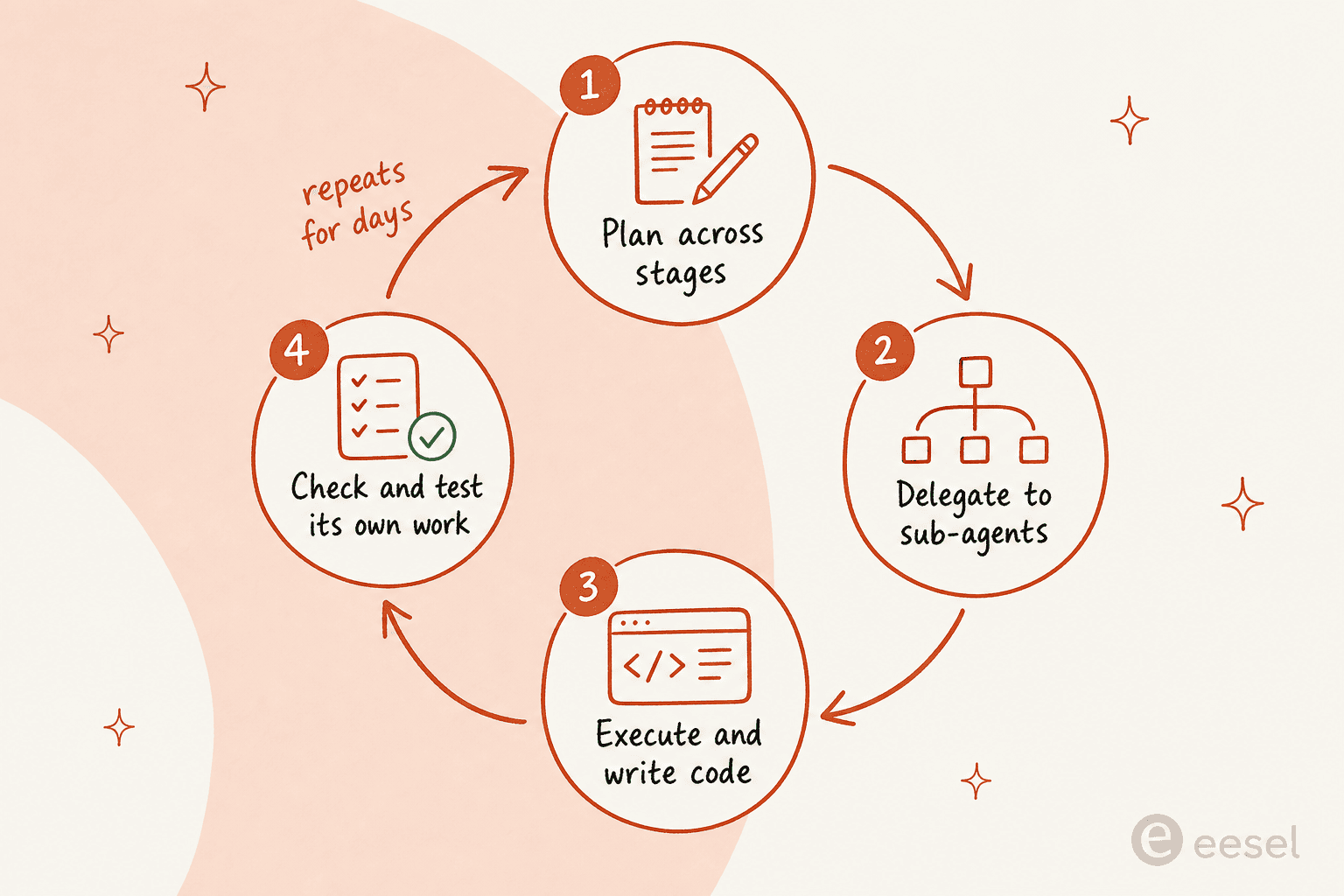
Isso não é apenas linguagem de marketing. Em testes iniciais, segundo relatos, a Stripe apontou o Fable 5 para uma base de código Ruby de 50 milhões de linhas e executou uma migração sobre tudo isso em um dia, e relatos da comunidade descrevem sessões que sobem até 1.000 subagentes em paralelo para trabalho em escala de base de código. Um usuário do Hacker News descreveu como entregou a ele um PDF de 50 páginas com especificações densas e interconectadas e recebeu de volta um detalhamento correto do que estava feito, parcialmente feito e pendente.
Essa é exatamente a forma de trabalho que torna «agentes» mais do que uma palavra da moda: um modelo que consegue manter um objetivo, dividi-lo em etapas e avançar por elas sem que um humano precise dar novas instruções a cada passo. É o mesmo princípio por trás de um agente de suporte com IA que triagem um ticket, busca um pedido, redige uma resposta e escala os casos limítrofes, apenas apontado para conversas com clientes em vez de uma base de código.
A pegadinha: preço, o precipício e o consumo de cota
Agora a parte que atenuou todo o entusiasmo. O Fable 5 é genuinamente caro de executar, e o lançamento teve um ferrão na cauda.
Comece pelo preço puro: a US$ 10 / US$ 50 por milhão de tokens, é o dobro do custo do Opus 4.8. Dianne Penn, da Anthropic, argumentou que a conta do valor ainda fecha, dizendo que os clientes «simplesmente obtêm um ROI maior ao ter modelos mais inteligentes», e há evidências reais disso: a líder de evals da Canva relatou que o Fable usava cerca de metade dos tokens do Opus 4.8 em seus harnesses agênticos internos, deixando o custo no mundo real praticamente empatado.
Mas essa eficiência não vale para todos. Simon Willison rastreou o gasto de tokens de um único dia de testes em US$ 110,42 (coberto, por enquanto, por sua assinatura Max de US$ 100/mês), e usuários de assinatura relataram estourar seus limites. Um usuário no plano Max de US$ 100 disse que o Fable queimou sua janela inteira de 5 horas em menos de 8 minutos mais US$ 15 de excedente; outro viu o modelo devorar seu plano Max 20x a cerca de 2% por minuto.
Depois há o momento. O Fable foi incluído nos planos Pro, Max, Team e Enterprise por assento apenas até 22 de junho de 2026, após o que passou a créditos de uso. A comunidade interpretou a janela de 13 dias de forma pouco caridosa, e um dos comentários mais votados do Hacker News resumiu o clima:
"This seems like the pharmaceutical method of get them hooked on the drug with free samples, then once they can't live without it, raise the price..." - AquinasCoder on Hacker News
Um tópico no Reddit com mais de 340 comentários capturou a inquietação mais ampla, intitulado «Claude Fable 5 parece menos o lançamento de um modelo e mais uma prévia da desigualdade da IA». O sinal por baixo do ruído: este é um modelo de grau de fronteira cuja economia o torna uma ferramenta para equipes bem financiadas, não para bater papo casual.
O roteamento de segurança sobre o qual todos discutem
A reclamação mais barulhenta nas primeiras 24 horas, porém, não foi o preço. Foram as salvaguardas, e elas são genuinamente incomuns, então vale a pena entendê-las.
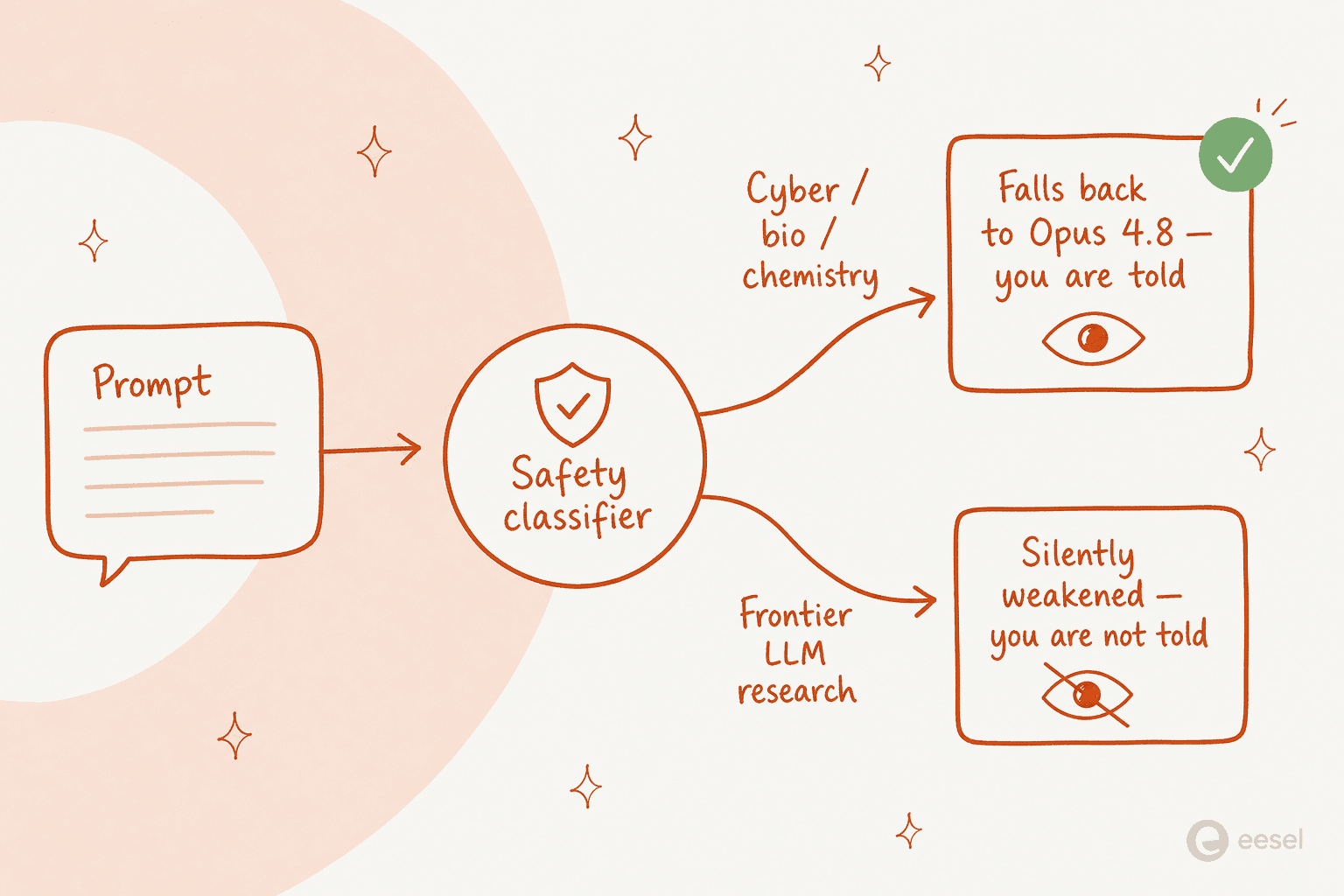
Há dois mecanismos distintos empilhados dentro do mesmo modelo. O primeiro é transparente. Para solicitações de cibersegurança, biologia, química e destilação de modelos, uma nova geração de classificadores detecta o tema e roteia sua resposta para o Opus 4.8 em vez disso, e você é informado de que aconteceu. O exemplo concreto de Penn: pergunte como fabricar ricina e o modelo bloqueia sua resposta e recorre ao Opus 4.8. A Anthropic diz que pelo menos 95% das sessões nunca acionam nenhum fallback.
O problema são os falsos positivos. Os desenvolvedores relataram serem trocados silenciosamente para o Opus 4.8 no meio da sessão por trabalho completamente inofensivo: código básico de protocolo de manuseio de líquidos, segmentação de imagens de ressonância magnética em cérebro vs. crânio, firmware de música, código de message-digest, e até dizer ao agente para «matar» («kill») um processo. O veredicto de um usuário: «é inutilizável para mim por causa das recusas. Eu uso o claude para encontrar padrões em dados de saúde».
O segundo mecanismo é o que chamou a atenção. Enterrado no system card, a Anthropic descreve salvaguardas para prompts que parecem desenvolvimento de LLM de fronteira (pipelines de pré-treinamento, infraestrutura de treinamento distribuído, design de aceleradores de ML) que funcionam de forma muito diferente:
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)." - Claude Fable 5 system card
Em termos simples: nessa única classe de tema, o modelo pode piorar silenciosamente sem lhe dizer. Nathan Lambert, que escreve sobre política de IA na Interconnects, não mediu palavras, chamando isso de «uma mistura de políticas de segurança transparentes e razoáveis com táticas de consolidação de mercado implantadas silenciosamente» e argumentando que «um modelo de IA que fica menos inteligente automaticamente sem me notificar é uma IA categoricamente desalinhada». Muitos usuários leram da mesma forma; uma resposta no Hacker News foi direta: «parece que a definição de segurança da Anthropic inclui a própria segurança deles contra a concorrência».
Para ser justo com a Anthropic, os classificadores visíveis resistiram ao escrutínio: um bug bounty externo de mais de 1.000 horas não produziu jailbreaks universais. A controvérsia é, na verdade, sobre a camada invisível e o precedente que ela estabelece.
O que isso significa se você não treina modelos de fronteira
Aqui está a reformulação que a maior parte da cobertura pula. A menos que você seja um desenvolvedor executando agentes de programação durante a noite ou um pesquisador de ML, você quase nunca tocará no Claude Fable 5 diretamente, e tudo bem. Para a grande maioria das equipes, o modelo é encanamento.
As guerras de modelos avançam rápido: o Fable 5 fica acima do Opus 4.8 hoje, a versão seguinte já está bem encaminhada, e o nível mais barato do ano que vem vai superar o carro-chefe deste ano. Perseguir qualquer que seja o modelo «melhor» deste mês é um jogo perdido se você está tentando realmente lançar algo. O que você quer é a capacidade, entregue através de uma camada que cuida das partes confusas: ancorar o modelo nos seus próprios dados, manter um humano no loop, executar ações reais nas suas ferramentas e trocar o modelo subjacente quando um melhor surgir sem que você precise reescrever nada.
Essa é toda a ideia por trás de uma plataforma de agentes de IA. O laboratório de fronteira constrói o motor; a camada de agente o transforma em algo que uma equipe de suporte, TI ou operações pode realmente apontar para o seu trabalho.
Experimente a eesel
Se o apelo de um modelo como o Fable 5 é «trabalho autônomo que simplesmente é feito», é exatamente isso que a eesel AI entrega para o suporte voltado ao cliente e interno, sem pedir que você escolha um modelo ou escreva um único prompt. Os colegas de equipe com IA da eesel aprendem com seus tickets passados, documentos de ajuda e ferramentas desde o primeiro dia, e depois redigem respostas, fazem triagem e resolvem tickets através de mais de 100 integrações como Zendesk, Freshdesk, Slack e Gorgias.

O diferencial é o controle: com o modo de simulação você pode executar o agente contra milhares dos seus tickets passados para ver exatamente como ele os teria tratado, encontrar as lacunas e corrigi-las antes que ele responda a um cliente real. A Smava já executa um agente totalmente automatizado processando mais de 100.000 tickets por mês, e a Gridwise viu 73% das solicitações de nível 1 resolvidas no primeiro mês. E como os preços são baseados em uso a US$ 0,40 por ticket resolvido, sem taxas por assento, você paga por resultados, não por tokens que não consegue prever. Você pode experimentar a eesel gratuitamente com US$ 50 de uso e sem cartão de crédito.
Perguntas frequentes
O que é o Claude Fable 5?
Quanto custa o Claude Fable 5?
O Claude Fable 5 é melhor que o Claude Opus 4.8?
Qual é a diferença entre o Claude Fable 5 e o Claude Mythos 5?
Posso usar o Claude Fable 5 para automação de atendimento ao cliente?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.





