O que e o MiniMax M3?
O MiniMax M3 e um grande modelo de linguagem de proposito geral que a MiniMax descreve como „um modelo de programacao e agentico frontier construido sobre uma arquitetura de atencao nova (MSA) com 1M de contexto." Ele substitui a linha M2 anterior (M2, M2.1, M2.5, M2.7), que permanecem disponiveis, e e o primeiro modelo da MiniMax treinado para ser multimodal desde o primeiro passo, aceitando entradas de imagem e video e podendo ate operar um computador desktop.
A propria MiniMax e um laboratorio de IA chines cujo lema e "Intelligence with everyone", com uma linha de produtos que vai muito alem do texto, incluindo video (Hailuo), voz e musica. O M3 e o carro-chefe de texto e agentes dessa linha. Se voce tem acompanhado a onda de modelos fortes vinda da China, o M3 esta na mesma conversa que o Qwen e o Kimi K2.5, e e um dos lancamentos open-weight mais interessantes do ano.
O lancamento oficial apresentou a proposta claramente na conta X da MiniMax:
"Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities... Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1... MiniMax Sparse Attention scales context to 1M... Natively Multimodal from Step Zero"
Uma nota sobre o nome antes de prosseguirmos: nao ha nenhum modelo chamado literalmente "MiniMax 3." O nome oficial e MiniMax M3, e e isso que este guia cobre.
Como o MiniMax M3 funciona: atencao esparsa e uma janela de 1M de tokens
A coisa mais interessante sobre o M3 nao e um benchmark, e a arquitetura que permite que ele leia um milhao de tokens sem que o custo exploda. Esta e a parte que acho genuinamente engenhosa, entao vou explicar como funciona.
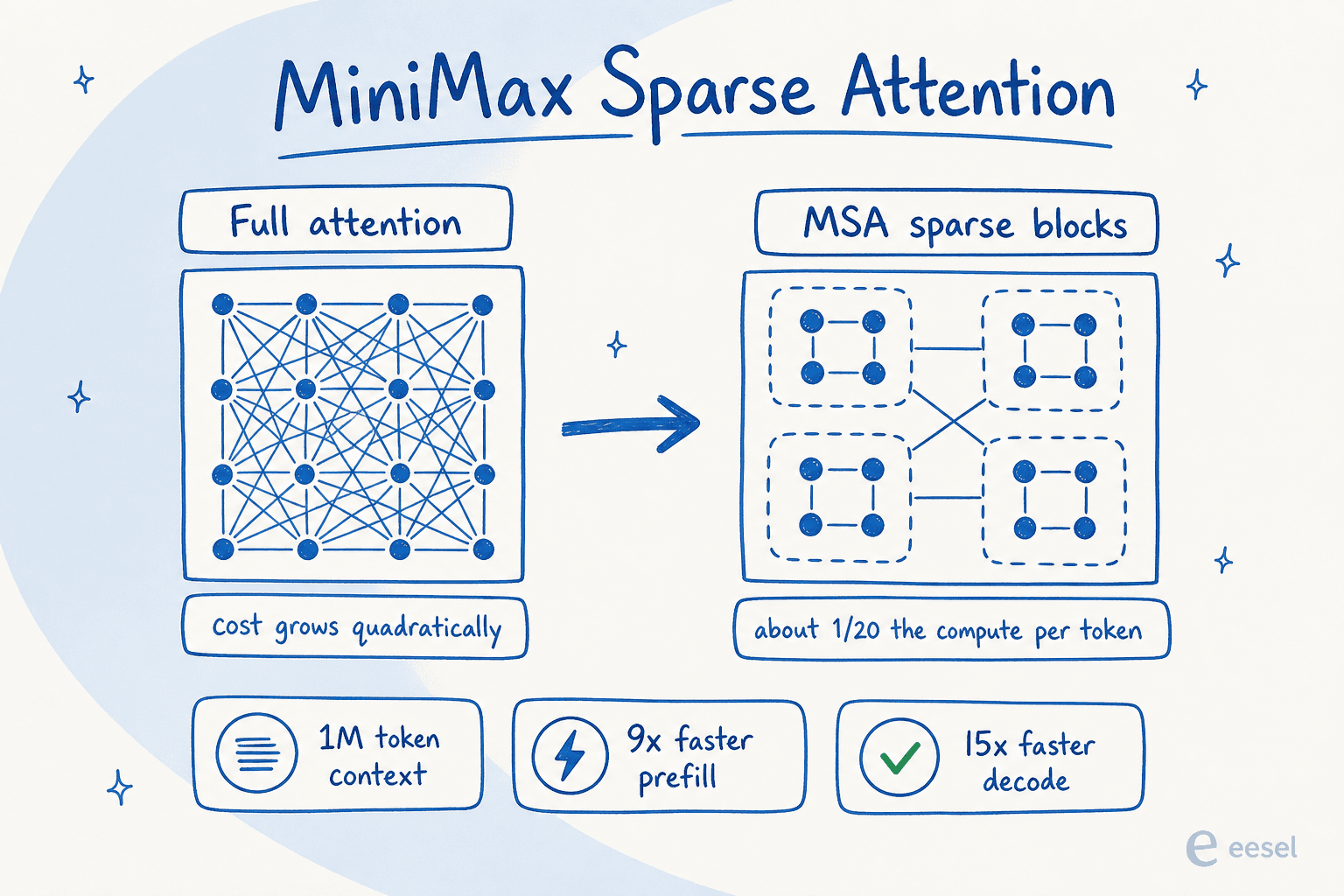
Por baixo do capo, o M3 e um modelo Mixture-of-Experts com cerca de 428B parametros totais e aproximadamente 23B ativados por token, entao ele so executa uma fracao de si mesmo em qualquer solicitacao. Sobre isso esta o verdadeiro destaque: MiniMax Sparse Attention (MSA), um novo design de atencao que divide o contexto em blocos e atende apenas aos relevantes em vez de comparar cada token com todos os outros.
Isso importa porque a atencao normal fica quadraticamente mais cara conforme o contexto cresce, razao pela qual janelas de contexto longas geralmente sao lentas e caras. A MiniMax relata que o MSA reduz o computo por token para cerca de 1/20, com mais de 9 vezes mais velocidade de prefilling e 15 vezes mais de decoding com 1M de contexto em comparacao ao M2, mantendo o desempenho de atencao completa na maioria das capacidades em suas ablacoes. O resultado e uma janela de contexto de 1.000.000 tokens (com um minimo garantido de 512K), em comparacao aos 204.800 da linha M2.
Algumas outras coisas que vale a pena saber sobre como o M3 se comporta:
- Modos de raciocinio. Um parametro
thinkingpermite definir o raciocinio comoenabled,adaptive(o modelo decide) oudisabledpara baixa latencia, e ambos os modos compartilham o mesmo preco. - Multimodalidade nativa. Como foi treinado com texto, imagem e video entrelaçados "desde o Passo 0," o M3 fusiona as modalidades mais profundamente do que um modelo com visao adicionada posteriormente.
- Construido para trabalho de longo horizonte. Nas proprias demos da MiniMax, o M3 funcionou autonomamente por quase 12 horas para reproduzir um artigo de pesquisa, e passou cerca de 24 horas otimizando um kernel CUDA ao longo de 147 submissoes de benchmark e 1.959 chamadas de ferramentas.
O metodo completo esta no relatorio tecnico do M3 se voce quiser a profundidade.
Quao bom e o MiniMax M3? Os benchmarks
A MiniMax posiciona o M3 como atingindo a fronteira em engenharia de software e execucao de terminal, e o compara a modelos fechados como GPT-5.5, Gemini 3.1 Pro e Claude Opus. Aqui estao as pontuacoes publicadas do anuncio:
| Benchmark | O que mede | MiniMax M3 |
|---|---|---|
| SWE-Bench Pro | Correcoes de software do mundo real | 59,0% |
| Terminal-Bench 2.1 | Tarefas agenticas de linha de comando | 66,0% |
| MCP Atlas | Uso de ferramentas sobre o protocolo agente | 74,2% |
| SWE-fficiency | Alteracoes de codigo eficientes | 34,8% |
| KernelBench Hard | Otimizacao de kernels GPU | 28,8% |
| PostTrainBench | Treinamento autonomo de modelos | 37,1 (#3) |
| Video-MME (512 frames) | Compreensao de video | 84,6 |
Um pouco de honestidade sobre o que isso significa. No benchmark de treinamento autonomo de modelos PostTrainBench, o M3 ficou em terceiro lugar, ligeiramente atras do Claude Opus 4.7 (42,4) e GPT-5.5 (39,3), mas a frente de todo o resto. Esse e o padrao geral: O M3 e excelente para um modelo open-weight e competitivo em programacao, mas nao lidera a fronteira fechada. A anterior familia M2 ja havia empurrado as pontuacoes open-weight mais alto em indices independentes, e o M3 e um claro passo a frente disso.
Se voce quiser o contexto mais amplo de como esses modelos se comparam, nossos guias sobre alternativas ao Claude e alternativas ao Gemini cobrem o lado dos modelos fechados da comparacao.
Quanto custa o MiniMax M3?
E aqui que o M3 ganha sua reputacao. O preco e a razao pela qual os desenvolvedores continuam mencionando-o.
A MiniMax vende o M3 de duas formas. A primeira e um Token Plan de assinatura, atualizado no lancamento em tres niveis, onde texto, imagem, voz e musica todos consomem de um unico pool de uso compartilhado:
| Token Plan | Preco / mes | Aprox. tokens M3 / mes |
|---|---|---|
| Plus | $20 | ~1,7B tokens |
| Max | $50 | ~5,1B tokens |
| Ultra | $120 | ~9,8B tokens |
A MiniMax enquadra o nivel de entrada como "$20 = 10x Claude Pro" em throughput, o que e marketing, mas diz muito sobre o angulo: maximos tokens por dolar. E o mesmo posicionamento de baixo custo que voce ve nos precos do Qwen e no resto do grupo open-weight.
A segunda forma e a API de pagamento por uso, com preco por comprimento de entrada. Chamadas com menos de 512K tokens de entrada recebem a tarifa padrao; qualquer coisa acima e faturada a uma tarifa de contexto longo mais alta para trabalho com repositorios completos e documentos ultra-longos. O raciocinio ativado ou desativado custa o mesmo, e um nivel de servico priority esta disponivel para cargas de trabalho sensiveis a latencia. Desenvolvedores em r/LLMDevs relatam a tarifa por token no lancamento de $0,60/$2,40 por milhao ate 512K, colocando-os, em suas palavras, em "territorio DeepSeek."
A outra metade da historia de custos e a licenca. O M3 e open-weight sob a MiniMax Community License: gratuito para uso nao comercial, com o uso comercial exigindo um credito visivel "Built with MiniMax M3" e, para receitas acima de $20M/ano, autorizacao previa por escrito. Entao e open-weight, nao open source — uma distincao que a comunidade rapidamente aponta. Para uma comparacao de custos pura com outras opcoes pagas, nossa lista de ferramentas de IA baratas e o guia de precos do Kimi K2.5 sao pontos de referencia uteis.
O que os desenvolvedores realmente dizem sobre o MiniMax M3
Os benchmarks publicados so dizem tanto. O sinal mais util vem de desenvolvedores executando o M3 em trabalho real, e o veredicto e consistente: uma opcao de otima relacao custo-beneficio, nao um substituto para os modelos frontier.
A versao mais clara do argumento de valor vem de alguem que mudou para o predecessor M2.7, em r/openclaw:
"claude is a slightly better model. better reasoning, better depth on hard problems. that's just how it is. but minimax m2.7 delivers exceptionally well for what i actually use it for, at a fraction of the cost... sometimes good enough is actually great when it's reliable and affordable."
Sobre o M3 especificamente, um desenvolvedor em r/opencode expressou assim apos testar outros modelos chines primeiro:
"I started using Kimi 2.6, then GLM 51, then DeepSeek4. But now after trying minimax m3 I am really impressed. It seems to think very deeply and really do a good job following directions... It seems to have flown a lot under the radar."
Isso corresponde aproximadamente a onde o M3 se situa no mercado: pesos abertos, capacidade proxima ao nivel Sonnet, a precos de nivel value.
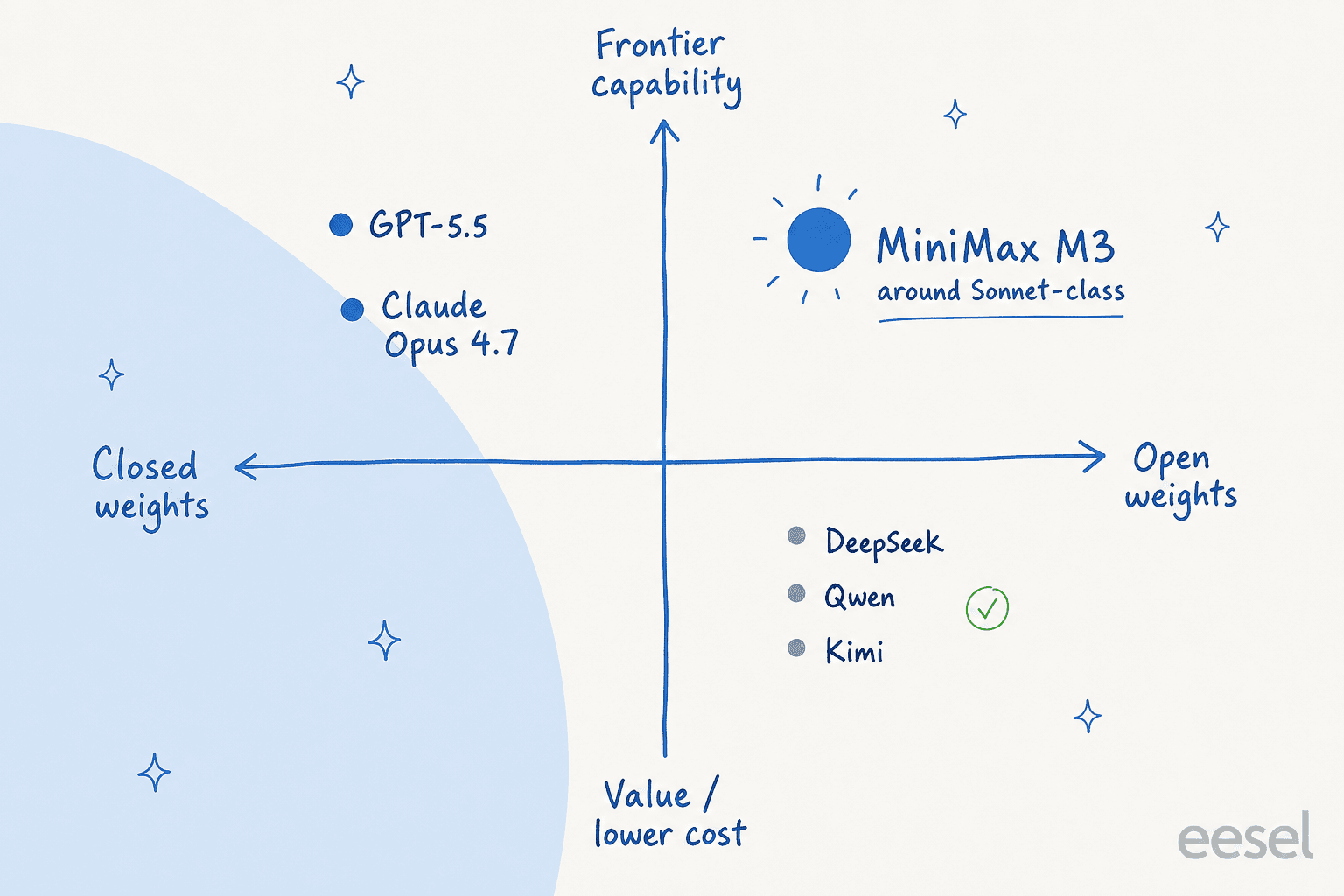
Nao sao so elogios, porem, e a critica merece ser levada a serio se voce esta pensando em producao. A reclamacao mais comum e a confiabilidade sob pressao. Um testador em r/hermesagent achou o M3 erratico:
"I feel like it is much more chaotic and verbose, as well as hallucinations being more common. Now it just suddenly keeps stopping mid action... Right now I wouldn't use it in production."
Tambem ha uma preocupacao recorrente sobre retencao de dados sobre a API hospedada, com usuarios observando que nao conseguiram encontrar uma opcao clara para que os dados do prompt nao sejam usados no treinamento. Esse e exatamente o tipo de coisa que importa mais para dados de clientes do que para um projeto de hobby, e e uma razao importante pela qual a comunidade de auto-hospedagem aprecia que os pesos estejam no Hugging Face.
O porem: um otimo modelo ainda nao e um agente de suporte
Aqui esta o reenquadramento com o qual quero que voce saia, porque e o que as pessoas perdem quando um novo modelo brilhante e lancado. Um modelo como o M3 e um motor fantastico. Mas um motor nao e um carro, e um modelo bruto nao e um agente de suporte ao cliente.
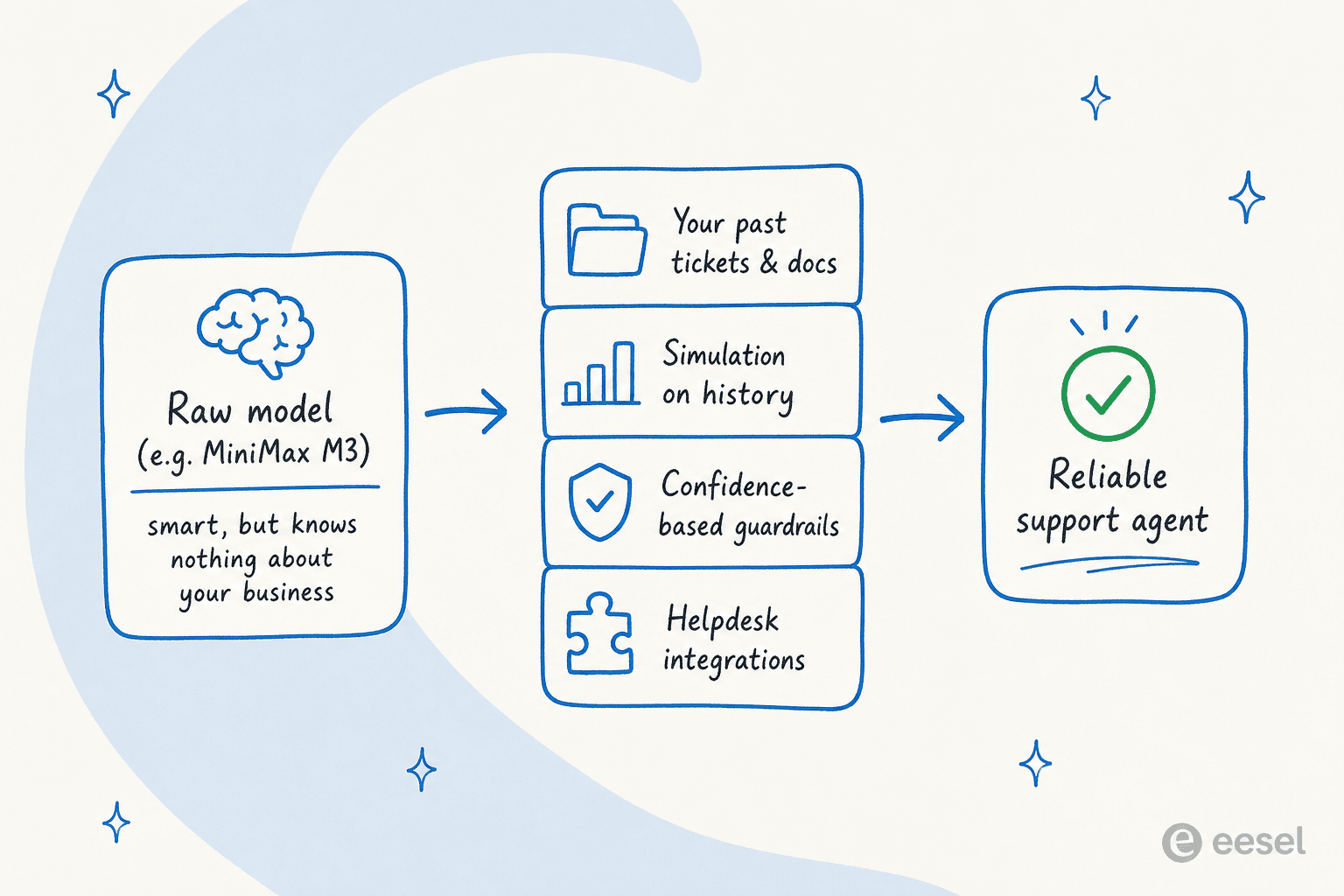
Passei os ultimos anos na eesel observando o que acontece quando voce aponta um modelo de linguagem para uma fila de suporte ao vivo, e o modo de falha e sempre o mesmo: o modelo soa confiante e erra nos detalhes, porque nao conhece sua politica de reembolso, seus ultimos 50.000 tickets resolvidos ou qual resposta e segura enviar sem que um humano a leia primeiro. O modelo mais inteligente no ranking ainda alucina seu prazo de envio se ninguem o ensinou. Por isso cada implantacao da eesel roda em simulacao contra tickets historicos antes de responder a qualquer cliente.
Entao as perguntas relevantes para o suporte nao sao "o que o M3 pontuou no SWE-Bench." Sao: ele pode aprender com meus tickets e documentos reais, posso testa-lo com seguranca antes de ir ao ar, e o que o impede de enviar com confianca uma resposta errada? Essas sao perguntas de produto, nao de modelo, e sao as que nosso resumo do melhor IA para servico ao cliente foi construido em torno.
O mesmo ponto surge sempre que um chatbot responde incorretamente, e e por isso que o custo de um agente de IA versus um humano depende muito mais de como ele resolve tickets de forma confiavel do que do preco por token do modelo.
eesel: a camada que transforma um modelo em um parceiro de suporte
E exatamente essa lacuna que a eesel foi construida para fechar. Em vez de pedir que voce escolha um modelo e torça, a eesel fica em cima do seu helpdesk como um parceiro de IA que aprende com seus tickets passados, documentos de ajuda e ferramentas desde o primeiro dia, depois rascunha, triaga e resolve o trabalho de nivel 1 com as barreiras que o tornam seguro para deixar funcionando.

O diferencial concreto e o modo de simulacao: voce executa o agente contra milhares de seus tickets reais passados, ve exatamente o que ele teria respondido e onde estao as lacunas, preenche-as e so entao vai ao ar, com roteamento baseado em confianca mantendo respostas de baixa confianca como rascunhos em vez de envios. E assim que equipes como a Smava executam um agente Zendesk totalmente automatizado com mais de 100.000 tickets alemaes por mes, e como o Gridwise atingiu 73% de resolucao de nivel 1 em seu primeiro mes. Ele se conecta a mais de 100 integracoes, responde em mais de 80 idiomas e funciona com precos baseados em uso de $0,40 por ticket sem taxas por assento.
Se voce veio aqui escolhendo um modelo para suporte, o melhor ponto de partida e a camada, nao o ranking. Voce pode experimentar a eesel gratuitamente, sem cartao de credito, e ver como ela resolve seus proprios tickets em simulacao antes de tocar em um unico cliente. E a mesma licao por tras de cada implantacao de IA de servico ao cliente que vi funcionar: o modelo e intercambivel, a confiabilidade nao.
Perguntas frequentes
O que é o MiniMax M3 em termos simples?
O MiniMax M3 e realmente open source?
Quanto custa o MiniMax M3?
O MiniMax M3 e bom para programacao?
Posso usar o MiniMax M3 para suporte ao cliente?
Como o MiniMax M3 lida com um contexto de 1 milhao de tokens?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.