
O que o Claude Sonnet 5 realmente é
Eu construo integrações e APIs para viver, então quando um novo modelo é lançado, leio a documentação antes do thread de lançamento. Aqui está o que a própria documentação da Anthropic diz que o Claude Sonnet 5 é, sem o verniz de marketing.

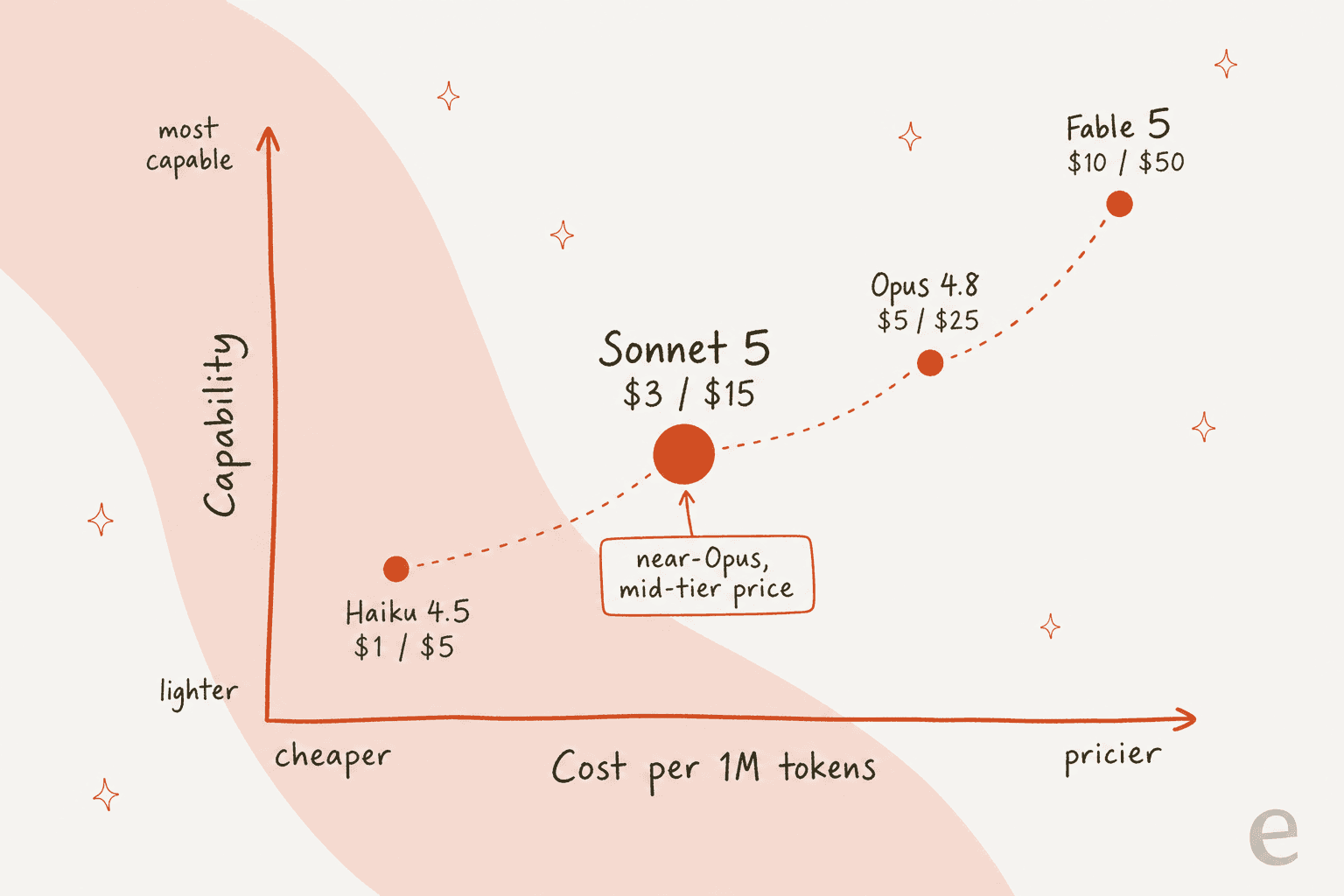
A Anthropic anunciou o Sonnet 5 no final de junho de 2026 como "nosso Sonnet mais agêntico até agora", e o tornou o padrão desde o primeiro dia para usuários gratuitos e Pro do Claude. É o nível equilibrado da família Claude 5. Ele opera com uma janela de contexto de 1M de tokens e até 128K tokens de saída, o mesmo teto do nível Opus. A proposta é que ele alcança qualidade próxima do Opus especificamente em tarefas de codificação e agênticas, o tipo de trabalho de múltiplas etapas e uso de ferramentas que um agente de suporte realiza, enquanto custa muito menos para operar. A comparação aproximada da Anthropic é que o Sonnet 5 no esforço medium é comparável ao antigo Sonnet 4.6 no high, e o Sonnet 5 no high é comparável ao 4.6 no max. Em outras palavras, você obtém mais pela mesma configuração.
Onde ele se posiciona na família é a verdadeira história. A Anthropic agora oferece quatro níveis públicos, e o Sonnet 5 é o que a maioria das equipes realmente vai colocar em produção.
Algumas coisas são novas por debaixo do capô, e importam mais do que o número da versão sugere:
- O raciocínio adaptativo está ativado por padrão. Você não define mais um "orçamento de raciocínio" fixo em tokens. O modelo decide quanto raciocinar por requisição, e você o ajusta com um dial de
effortem vez disso. - O esforço
xhighchega ao nível Sonnet. O Sonnet 5 é o primeiro modelo Claude de nível equilibrado com a configuraçãoxhigh, que a Anthropic recomenda para as execuções de codificação e agênticas mais difíceis. É o mesmo dial em que o Claude Code se apoia. - Visão em alta resolução. O Sonnet 5 lê imagens de até 2576px no lado mais longo, útil se seus fluxos de suporte envolvem capturas de tela ou recibos.
- Um novo tokenizador. Mais sobre isso abaixo, porque ele muda discretamente sua fatura.
Preço do Claude Sonnet 5
Aqui está a parte que todo mundo realmente veio buscar. O preço da API do Sonnet 5 é de US$ 3 por milhão de tokens de entrada e US$ 15 por milhão de saída, com tarifas promocionais de US$ 2/US$ 10 vigentes até 31 de agosto de 2026. No lado do consumidor, o Sonnet é o nível "equilibrado" dentro de uma assinatura do Claude.
Comparado com seus irmãos, o caso de valor é claro:
| Modelo | Entrada ($/1M) | Saída ($/1M) | Contexto | Melhor para |
|---|---|---|---|---|
| Haiku 4.5 | $1 | $5 | 200K | Tarefas rápidas, baratas e simples |
| Claude Sonnet 5 | $3 (promo $2) | $15 (promo $10) | 1M | Codificação e trabalho agêntico em escala |
| Opus 4.8 | $5 | $25 | 1M | O trabalho autônomo mais difícil e de longo horizonte |
| Fable 5 | $10 | $50 | 1M | O raciocínio mais exigente |
Portanto, o Sonnet 5 é cerca de 40% mais barato que o Opus 4.8 tanto na entrada quanto na saída, enquanto reivindica a maior parte de sua capacidade nas tarefas que um agente de suporte executa. Para uma fila que processa milhões de tokens por mês, essa diferença se acumula rapidamente.
Mas há uma pegadinha que não aparece na tabela de preços. O Sonnet 5 usa um novo tokenizador que conta cerca de 30% mais tokens para o mesmo texto do que o Sonnet 4.6 contava. O preço por token é mais baixo, mas cada conversa agora tem mais tokens, então seu custo real por ticket resolvido pode ficar em um lugar diferente do que uma estimativa rápida sugere.
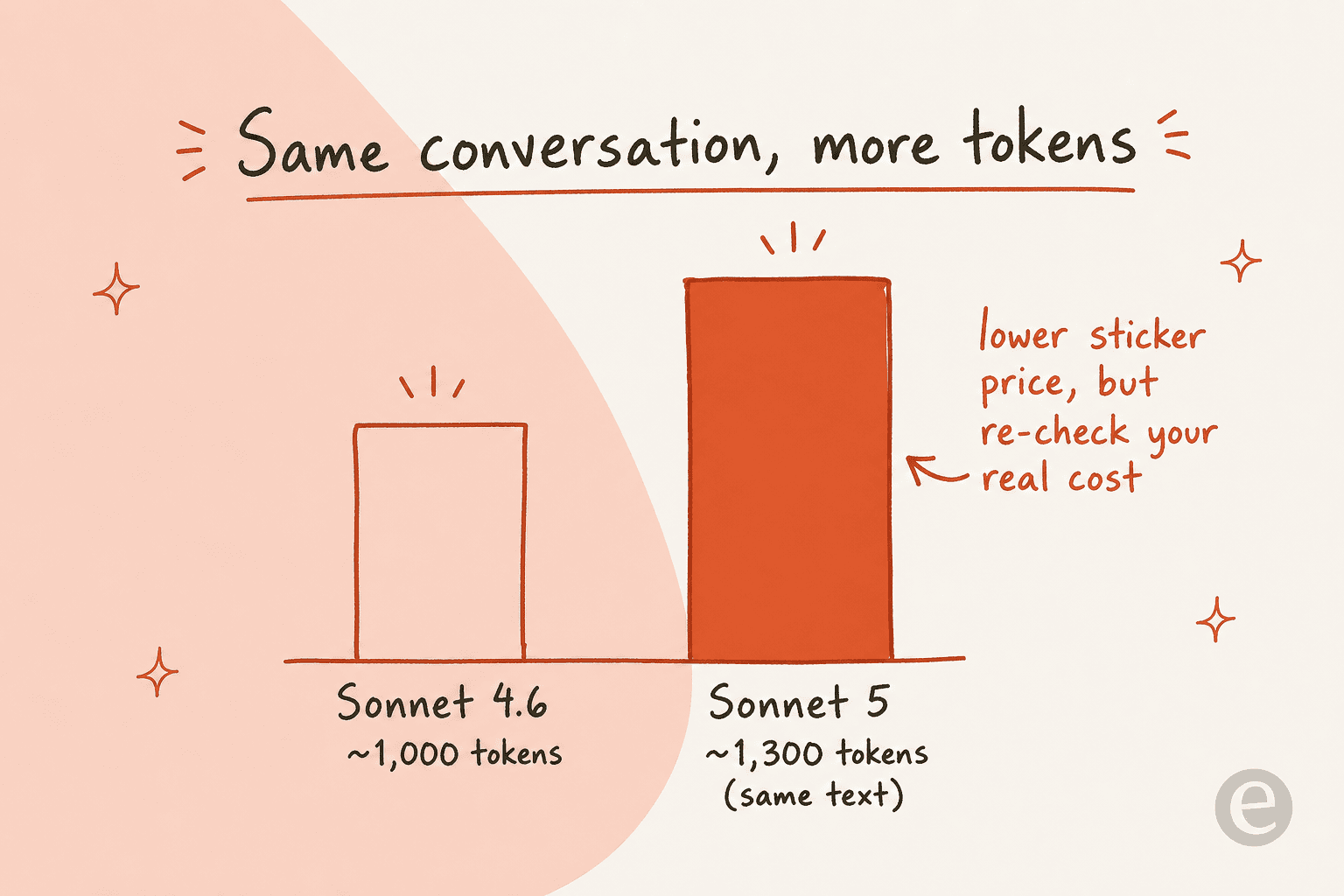
Este já é o debate ativo sobre o Sonnet 5. Os entusiastas o chamam de trabalho no nível do Opus a preços de Sonnet, mas análises mais críticas no X apontam que, uma vez que o desconto promocional termina e você opera com esforço alto, o custo por tarefa pode na verdade ficar acima do Opus 4.8 em índices independentes. Ambos podem ser verdadeiros: o preço de tabela é menor, a contagem de tokens é maior, e o esforço ajusta o total de um jeito ou de outro.
As reações práticas seguem na mesma linha. Em um thread de primeiras impressões no r/ClaudeAI (mais de 90 comentários em poucas horas do lançamento), um desenvolvedor abriu com exatamente a troca sobre a qual todo este post trata:
"Estou usando o Sonnet 5 no esforço [xhigh] há cerca de 30 minutos, principalmente em tarefas que eu delegaria ao Opus 4.8..."
thread de primeiras impressões, r/ClaudeAI
Esse é o sinal que vale a pena observar: pessoas recorrendo ao Sonnet 5 para trabalho que antes entregavam ao Opus. Se isso se sustenta nos seus tickets é uma pergunta que um benchmark não consegue responder, que é exatamente o ponto da próxima seção.
O movimento prático: meça o uso de tokens nos seus próprios tickets contra o claude-sonnet-5 em vez de reutilizar um número que você tinha para um modelo mais antigo. Se você está tentando modelar o custo total de propriedade especificamente para suporte, a análise de custo de um agente de suporte com IA é um ponto de partida melhor do que a matemática bruta por token, porque a maior parte do custo de um agente de suporte nunca é o modelo.
O que mudou desde o Sonnet 4.6
Se você está atualizando uma integração existente em vez de começar do zero, quatro coisas vale a pena saber antes de trocar a string do modelo:
- O raciocínio funciona de forma diferente. O antigo controle fixo
budget_tokensdesapareceu no Sonnet 5. Omitir a configuração de raciocínio agora executa o raciocínio adaptativo automaticamente, enquanto antes ele rodava com o raciocínio desativado. Se você nunca tocou nisso, suas requisições vão começar a raciocinar mais silenciosamente (e usar mais do seu orçamento de saída), então dê uma margem extra aomax_tokens. - O esforço é seu dial principal. Mantenha
highcomo padrão e recorra aoxhighnas execuções agênticas mais difíceis. Reduza paramediumoulowem tarefas baratas e sensíveis à latência, como rotulagem de tickets ou classificação de intenção. - A mudança no tokenizador é real. Como mencionado acima, reajuste sua contagem de tokens de referência. Essa é a forma mais comum de uma migração pegar uma equipe financeira de surpresa.
- A visão ficou mais nítida. A entrada de imagem em alta resolução é automática. Útil se você triagem tickets que chegam como capturas de tela.
Nada disso é dramático se você já opera na API do Claude. É uma troca de string de modelo mais um reajuste, não uma reescrita. A plataforma de desenvolvedores do Claude mantém o mesmo formato de requisição que tinha para a família Opus 4.x.
O que o Sonnet 5 significa se você administra uma equipe de suporte
Aqui é onde um modelo mais barato e mais inteligente se torna genuinamente interessante, e genuinamente enganoso.
Toda vez que um modelo forte é lançado, uma onda de equipes pensa a mesma coisa: o modelo está tão bom e tão barato agora, deveríamos simplesmente construir nosso próprio bot de suporte na API e pular o fornecedor. Eu entendo. Como alguém que desenvolve esse tipo de código, conectar uma chamada do Sonnet 5 que responde a uma pergunta de suporte é uma tarde satisfatória.
A armadilha é que a chamada ao modelo é os 20% fáceis. Tudo que torna uma IA segura para apontar para clientes reais fica abaixo da linha d'água, e nada disso vem na resposta da API.

Não estou apenas supondo isso. Já vi clientes saírem para construir internamente na API do Claude diretamente, e o padrão é consistente: a demonstração funciona em uma semana, e então a longa cauda de recuperação de dados, controle de alucinação, roteamento e escalonamento consome os seis meses seguintes. Um líder de engenharia que optou por comprar em vez de construir colocou isso claramente:
"Poderíamos tentar escrever nossa própria aplicação LLM, mas não queríamos investir nosso tempo nisso. Queríamos algo que não precisássemos manter."
Karel, líder de engenharia na GENERAL BYTES
O modo de falha mais assustador não é que um modelo bruto dê uma resposta errada. É que ele dá uma resposta errada com confiança. Em mais de três anos colocando IA em filas de suporte reais, o piores padrão que já vi é um bot que parece seguro de si e discretamente conta ao cliente algo falso, ou narra um trabalho que nunca realmente fez. É exatamente por isso que qualquer implementação séria deve ser simulada contra seus tickets históricos primeiro, para que você veja os números de precisão e cobertura antes que um cliente real os veja, não depois. Um benchmark de modelo diz que o motor é rápido; não diz nada sobre como seu bot específico se comporta nos seus tickets específicos.
Então a leitura honesta sobre o Sonnet 5 para suporte: ele torna o motor mais barato e melhor, o que é ótimo, e não muda quase nada nos difíceis 80%. Se você construir ou comprar, reserve tempo para as partes que a API não entrega, roteamento, guardrails, escalonamento para humanos, e testes, porque é ali que a confiança do cliente é realmente ganha ou perdida.
Experimente o eesel
Se a conclusão honesta é "eu quero qualidade de nível Sonnet 5 nos meus tickets sem construir os outros 80%", essa é exatamente a lacuna que o eesel preenche. Ele funciona como um novo integrante de suporte que se conecta ao Zendesk, Freshdesk, Gorgias, Help Scout ou Intercom em poucos minutos e já conhece seu help center e seus tickets anteriores.
A parte que mais importa dado tudo o que foi dito acima: o eesel permite simular sobre milhares dos seus tickets históricos reais antes de ir ao ar, para que você veja os números de resolução e cobertura antecipadamente em vez de descobri-los com um cliente real. O roteamento baseado em confiança mantém a IA nos tickets que ela consegue lidar e passa o restante para um humano, que é o guardrail que transforma um modelo inteligente em um colega de confiança. Isso não é um benchmark que o eesel está perseguindo; é por isso que equipes como a Gridwise resolveram 73% das solicitações de nível 1 no primeiro mês.

O preço é baseado em uso, cerca de US$ 0,40 por ticket atendido, sem taxas por assento e sem mínimo de plataforma, e você pode experimentar o eesel gratuitamente. Qualquer que seja o modelo por baixo, seja o Sonnet 5 hoje ou seu sucessor no próximo ano, o trabalho em torno dele é o que realmente resolve o ticket.
Perguntas Frequentes
O que é o Claude Sonnet 5?
Quanto custa o Claude Sonnet 5?
O Claude Sonnet 5 é melhor que o Opus 4.8?
Posso construir um agente de atendimento ao cliente com o Claude Sonnet 5?
Qual é a diferença entre o Claude Sonnet 5 e o Sonnet 4.6?
xhigh, atualiza para visão em alta resolução e usa um novo tokenizador que conta cerca de 30% mais tokens para o mesmo texto. Esse último ponto é importante para o orçamento, então reconfira seu custo real por conversa em vez de reutilizar estimativas antigas. Mais sobre a escolha de modelo no guia melhor chatbot de IA.
Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.







