
Claude Fable 5とは何か?
Claude Fable 5はAnthropicの第5世代モデルであり、2モデルのペアの公開側半分です(もう一方のMythos 5は、セーフガードを取り除いた同じモデルで、審査済みの研究パートナーに限定されています)。Anthropicはこれを「あなたの最も野心的で長時間にわたるプロジェクトのために作られたMythosレベルのモデル」として打ち出し、「以前のモデルでは維持できなかった、何日もかかる複雑で非同期のタスク」を扱えるように設計されています。
ローンチ初日の騒ぎを取り除いたあとに重要なのは、次のことです。
- これは梯子の頂点です。 Fable 5はOpus 4.8の上にあり、Opus 4.8はSonnet 4.6の上にあります。私たちのClaude概要をお読みになったなら、これが新しい天井です。
- Opusの2倍の価格です。 入力100万トークンあたり10ドル、出力100万トークンあたり50ドルで、ちょうどOpus 4.8の5ドル / 25ドルの2倍です。キャッシュされた入力トークンには90%の割引があり、米国限定の推論には1.1倍の追加料金がかかります。
- 大きいです。 100万トークンのコンテキストウィンドウ、最大出力128,000トークン、そして2026年1月の知識カットオフです。
- どこにでもあります。 claude.ai、Claude API、Amazon BedrockおよびAWS上のClaude Platform、Microsoft Foundryで利用でき、さらにClaude CodeやClaude Managed Agentsでも使えます。
少なくとも紙の上では、ベンチマークの物語が誇大宣伝を裏付けています。Anthropic自身の比較では、Fable 5はフロンティアの他のモデルを大きく引き離しています。
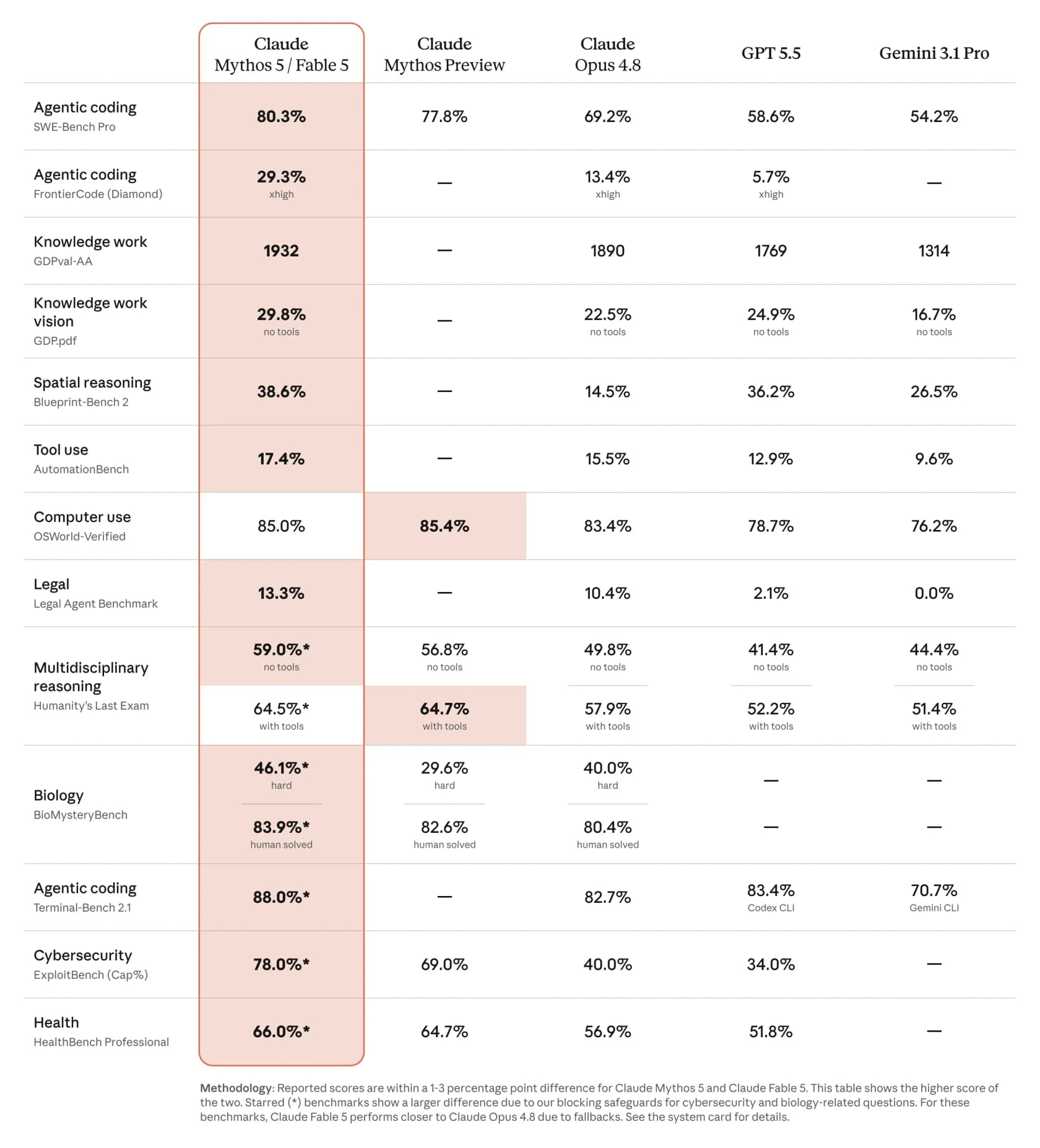
SWE-Bench Pro(エージェント型コーディング)では、Fable 5はOpus 4.8の69.2%に対して80.3%を記録し、GPT 5.5は58.6%、Gemini 3.1 Proは54.2%でした。CNBCは一部のベンチマークでその差を「Claude Opus 4.8より10%以上高い」と報じました。本物の数字、本物のリードです。落とし穴は、それを手に入れるのにいくらかかるかであり、それについては後ほど戻ります。
ビジネスにとって実際に何が違うのか
多くのモデルローンチは、いくつかのベンチマークの数値とプレスリリースにすぎません。Fable 5はもっと具体的なことをやっています。崩れることなく長時間稼働するように作られているのです。それがビジネスが気にかけるべき能力であって、リーダーボードではありません。
数分ではなく、何日も働ける
目玉のユースケースは長期にわたる自律的な作業です。Fable 5をClaude CodeやClaude Managed Agentsのようなエージェントハーネスの中で動かすと、Anthropicの言葉を借りれば「何日も連続で働ける。複数の段階にわたって計画を立て、サブエージェントに委任し、自分の作業をチェックする」のです。Stripeはこれを5,000万行のRubyコードベースに向け、その全体にわたるマイグレーションを1日で実行しました。
そのループ、つまり計画・委任・作業・チェック・繰り返しという部分こそが、本当に新しいところです。以前のモデルは多段階のタスクで力尽きていましたが、これは足場を保ち続けます。
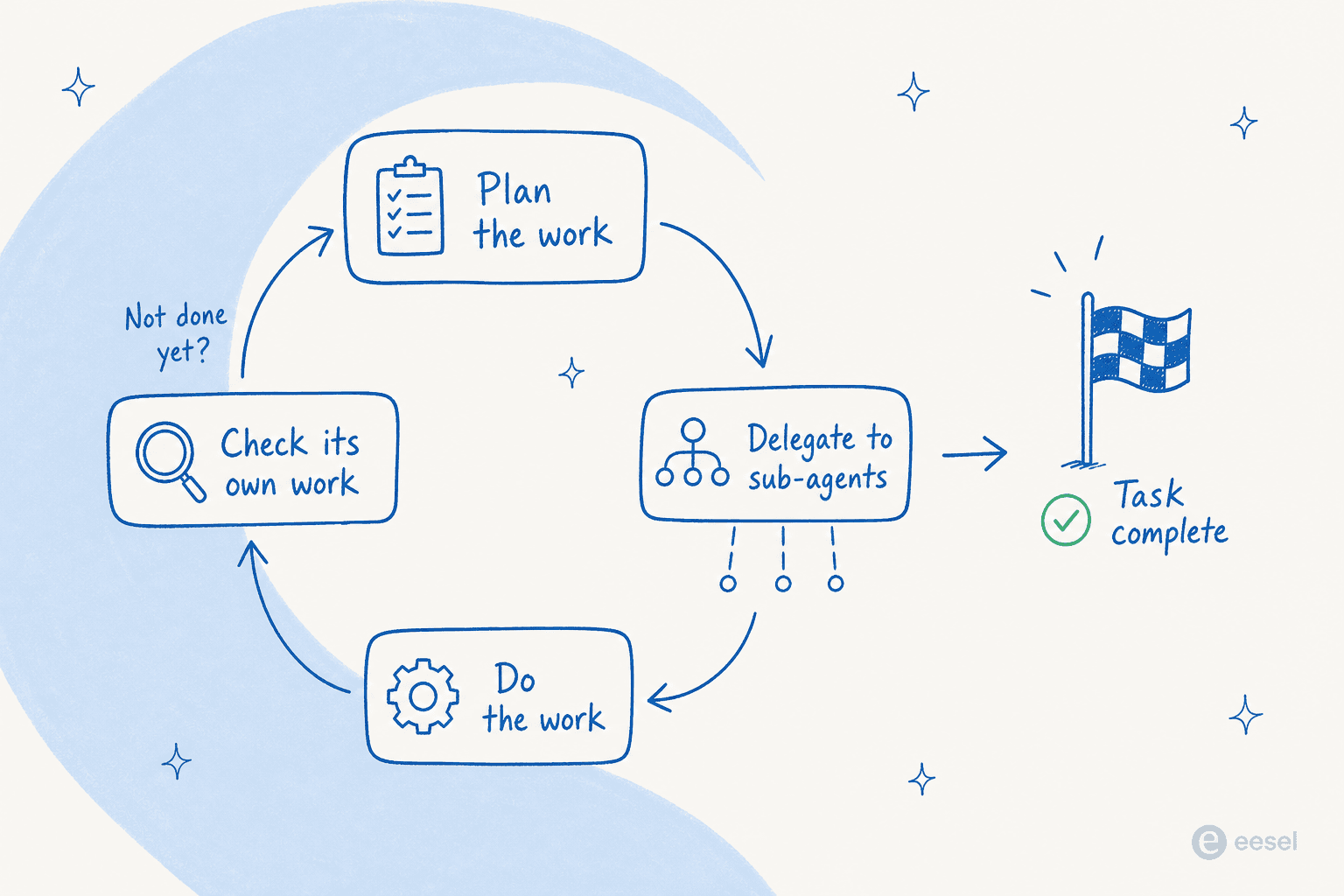
独立したテストはマーケティングと一致しています。開発者のSimon Willisonは5時間半をこれに費やし、こう結論づけました。
"This is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do."
あなたのチームが実際に持っている雑然としたドキュメントを読む
Fable 5は「ファイルやPDFの中に入れ子になった図表、チャート、テーブルを理解する」とされ、Anthropicはこれを財務、法務、分析の業務を中心に位置づけています。あるHacker Newsのユーザーは、50ページにわたる、密で相互に関連した仕様のPDF全体について「完了 / ほぼ完了 / 欠落」を正しく指摘したと報告しています。契約書、仕様書、ポリシー文書の山を抱えるどんなビジネスにとっても、これはコーディングのベンチマークでもう1点取ることよりも役に立ちます。
自分の作業をテストする
AnthropicはFableを「徹底的で、能動的で、自分の作業をテストする」ものとして売り込んでおり、クラウドプロバイダーは組み込まれた計画 / チェック / 改善のループについて述べています。自己修正こそが、あなたが付きっきりで見守らなければならないエージェントと、放っておけるエージェントの違いです。これはまさに、実際の業務を自動化するときに重要なことです。
ランディングページには誰も載せない落とし穴
ここで私たちならブレーキを踏みます。Fable 5は強力ですが、実世界での最初の24時間で、非常に実践的な問題がいくつも表面化しました。そしてそれらはすべてお金がかかります。
予算を急速に焼き尽くします。 Simon Willisonはテストの1日を110.42ドルのトークン消費として記録しました。あるMaxプランのユーザーは1,000個のサブエージェントを動かして20分で5時間の利用上限を使い切りました。別のユーザーは5時間枠まるごとを8分足らずで使い切り、さらに15ドルの超過料金を出しました。モデルが2倍高価で、タスクごとにずっと熱心に働くと、請求額はあっという間に積み上がります。
公平を期すために、心に留めておくべき反対の見方もあります。Canvaの評価責任者は、社内のエージェント型ハーネスにおいてFableがOpus 4.8の約半分のトークンを使ったと判明したと述べており、効率を考慮すれば実世界のコストはおおむね同じあたりに落ち着く可能性があります。教訓は「Fableは手が届かない」ではなく、「あなたのコストは、それをどう動かすかに完全に左右される」ということです。
安全ルーティングが誤作動することがあります。 サイバーセキュリティ、生物学、化学のトピックについて、Fableは分類器を動かし、応答を代わりにこっそりOpus 4.8へルーティングします。Anthropicは少なくとも95%のセッションはフォールバックなしで完全にFable上で動くとしていますが、その5%には偽陽性も含まれます。あるユーザーは、ラボ自動化において、危険な要素が何もない基本的な液体ハンドリングのプロトコルで拒否されました。あなたのビジネスが技術系の業界にあるなら、コミットする前にテストしてください。
今日見えている価格は続かないかもしれません。 FableがPro、Max、Team、seat-Enterpriseの各プランで無料なのは2026年6月22日までだけで、その後は利用クレジットへ移行します。ローンチのプロモではなく、従量制の価格を前提にしてワークフローを組んでください。
これらのどれもがFable 5を悪いモデルにするわけではありません。フロンティアの経済性を持つフロンティアのツールにしているのであって、それは実際にどう導入するかに直接的な影響を及ぼします。
Claude Fable 5はカスタマーサポートにとって何を意味するのか
ここは私たちのホームグラウンドなので、具体的にいきましょう。あなたがサポートチームを運営しているなら、Fable 5を気にかけるべきでしょうか。
ほとんどの場合、誇大宣伝が示唆するほどではありません。カスタマーサービスのためのAIについての不都合な真実はこうです。ティア1のチケットでは、モデルがボトルネックになることはめったにありません。よく基づいたOpus 4.8や、さらにはSonnet 4.6でも、「注文はどこ」「パスワードはどうリセットするの」「返金ポリシーは何」といった質問の圧倒的大多数にすでに正しく答えます。それらに答えさせるためにFable 5に2倍払うのは、子どもの送り迎えにF1カーを借りるようなものです。
あなたのAIヘルプデスクエージェントが機能するかどうかを実際に決めるのは、モデルを取り巻くすべてです。
- あなたのビジネスを知っているか? モデルは、それが何に基づいているか以上には良くなりません。成果は、より賢いベースモデルからではなく、あなたの過去のチケットやヘルプドキュメントで訓練することから生まれます。
- いつ黙るべきかを知っているか? 生のモデルは間違っていても自信たっぷりに答えます。それがまさにチャットボットが悪い回答をする理由です。本番のエージェントには信頼度ベースのルーティングが必要で、信頼度の低い質問は自動送信されず、下書きされるかエスカレーションされます。
- 本番稼働前に信頼できるか? まずあなた自身のチケットでエラー率を確認する必要があり、顧客の前でそれを発見するのではいけません。
その最後の点こそ、購入者が最も気にかけるところです。私たちが話すサポートリーダーたちは、すべてに答えるAIを求めてはいません。自分の限界を知っているAIを求めています。あるDTCサプリメント企業のCXリーダーが顧客インタビューで述べたように、AIが質問の100%に答えることは決してないので、彼らが実際に欲しいのは、確信のあるチケットだけを扱い、残りはそっとしておくエージェントなのです。それはプロダクトの能力であって、モデルの能力ではありません。
Fable 5はそのどれもあなたのために解決してくれません。検索なし、ルーティングなし、テストなしの生のモデルは、あなたの返信ボタンにアクセスできる自信過剰なインターンです。モデルのティアは、あなたの心配事の中で最も小さなものです。
自作か購入か:Fable 5を自前で配線すべきか?
これがビジネスにとっての本当の判断であり、絶えず持ち上がります。「Anthropicがすごいモデルを出したばかりだ、なぜAPIの上に自分たちのサポートボットを作らないんだ?」
作れます。それは見た目より大きなプロジェクトでもあります。モデルは知能を与えてくれます。ヘルプデスクへの接続、ガードレール、シミュレーション環境、レポーティング、継続的なメンテナンスは与えてくれません。それらすべては、あなたが作り、保有するものです。
私たちはこれがどうなるかを見ています。なぜなら「Claude APIの上に自分たちで作ればいい」は、技術チームが購入する前に挙げる最もよくある理由の1つだからです。実際に作る人もいます。試したいくつかのチームはその後、代わりに購入へと切り替えました。自作のLLMアプリを維持することが、誰もやりたがらない仕事だと判明したからです。ある顧客はその計算をこうまとめました。
"We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain."
こう考えるとよいでしょう。フロンティアモデルはスタックの最下層であって、スタック全体ではありません。それを顧客対応可能なエージェントに変えるものはすべてその上に乗っており、そこが時間のかかる部分です。
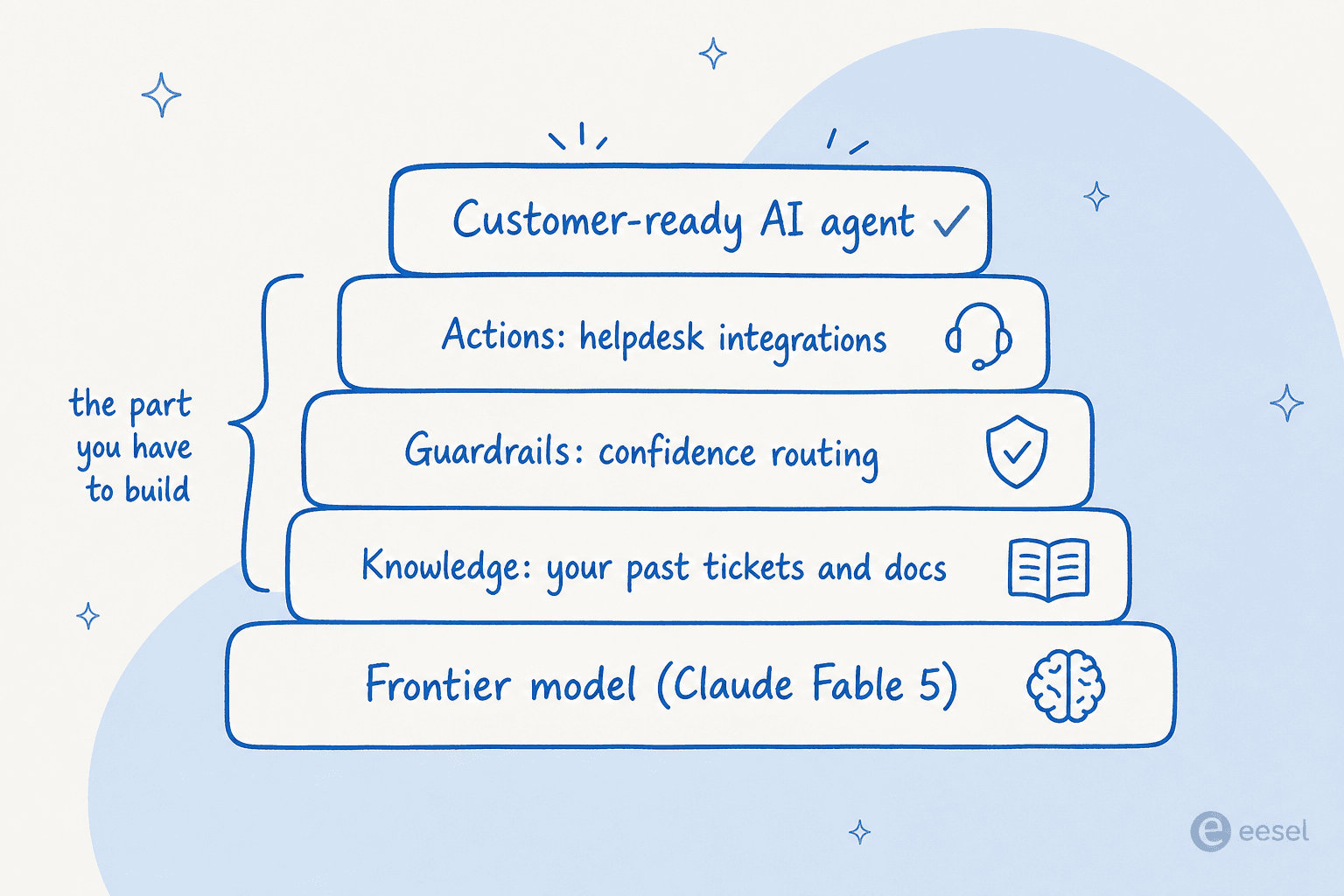
もしあなたのチームのコアプロダクトがAIなら、ぜひ自作してください。コアプロダクトが他の何かで、ただチケットにうまく答えてほしいだけなら、モデルの上の層を購入するほうが、ほぼ常により速く、より安く、より壊れにくいです。それは、あらゆるルールベースのチャットボットよりもAIエージェントを選ぶ理由と同じロジックです。あなたが欲しいのは結果であって、保守契約ではありません。
eeselを試す
eesel AIは、あなたが自分で作らなくて済むように、Claudeのようなフロンティアモデルの上に乗る層です。既存のヘルプデスク(Zendesk、Freshdesk、HubSpot、Gorgias、Front、そして100以上の連携)に接続し、初日からあなたの過去のチケットやヘルプドキュメントから学習し、80以上の言語で回答します。すべて、チケットあたり0.40ドルから始まる従量制の料金で、席ごとの料金はありません。
ここで重要な差別化要素は、まさにFable 5が単独では与えられない部分です。それは、エージェントを何千もの過去のチケットに対して実行するシミュレーションモードで、たった1人の顧客が話しかける前に、エージェントがどう応答していたか、そして解決率がどうなるかを正確に確認できます。これによってGridwiseは初月にティア1リクエストの73%を解決するに至り、その成果は7日間のトライアル中に現れました。

エンジニアリングプロジェクトなしで、フロンティアの知能を手に入れられます。クレジットカード不要、50ドル分の利用付きで無料で始められます。
よくある質問
Claude Fable 5とは何ですか、ビジネスに向いていますか?
Claude Fable 5の料金はいくらですか?
Claude Fable 5のAPI上に自前のサポートエージェントを構築すべきですか?
カスタマーサポートにおいてClaude Fable 5はClaude Opus 4.8より優れていますか?
Claude Fable 5がサポートの質問を間違えたら何が起こりますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








