
要点(TL;DR)
Claude Fable 5 は Anthropic の最も強力なモデルであり、「何ができるのか」への短い答えはこうです。各ステップで人間が再指示しなくても数日間にわたって走り続ける、本物の多段階作業です。計画を立て、コードを書いてリリースし、巨大なドキュメントを読み、サブエージェントに委任し、自分の出力を検証します。Anthropic 自身のベンチマークでは一般に利用できる最も強力なモデルであり、初期のテスターは利用可能な最高のコーディングモデルだと評しています。
その隣には2つの正直な注意点があります。遅くて高価です。入力100万トークンあたり10ドル、出力100万トークンあたり50ドル で、Opus 4.8 の2倍です。そして常にフルパワーで回答するわけではありません。安全性レイヤーが一部のプロンプトをひそかに弱いモデルへ差し戻します。
サポートチームや運用チームを率いているなら、実務的な要点はこうです。これほど高性能なモデルはエンジンであって車そのものではありません。実際に展開するのは、その上に構築された AI エージェント で、生のモデルには含まれない知識、ガードレール、テストを備えたものです。
では、Claude Fable 5 は実際に何ができるのか?
Claude Fable 5 は Anthropic の第5世代モデルであり、Claude Opus 4.8 の上に位置する新しい「Mythos クラス」のティアです。Opus 4.8 はさらに Sonnet 4.6 の上に位置します。私たちの Claude 概要 を読んだ方なら、これが新しい天井です。2026年6月9日 にリリースされ、claude.ai、Claude API、Claude Code、AWS、Microsoft Foundry で動作します。
しかし、人々が「何ができるのか」と尋ねるとき、本当に意味しているのはスペックやティアではありません。意味しているのは、「どんな作業を任せて、最後までやり遂げると信頼できるのか」ということです。ここに具体的な能力の正直な見取り図を示し、その後それぞれを順に見ていきます。
数日間にわたって自律的に稼働し、その後自分の成果を検証する
これは Anthropic が実際に Fable 5 を中心に据えて作り上げた能力であり、最も重要なものです。Claude Code や Claude Managed Agents のようなハーネス内で動かせば、Anthropic の言葉を借りると、「数日間ぶっ通しで作業できる。段階をまたいで計画を立て、サブエージェントに委任し、自分の成果を検証する」 ことができます。
その「計画する→委任する→作業する→検証する」というループこそ、本当に新しい部分です。以前のモデルは長く多段階のタスクで筋道を見失っていましたが、これは足場を保ち、決定的なことに、自分の答案を自分で採点します。Anthropic はそれを 「徹底的で、能動的で、自分の成果をテストする」 と表現し、クラウドプロバイダーは組み込まれた 計画・検証・改良のループ を詳しく説明しています。自己修正は、付きっきりで見守る必要のあるエージェントと、一晩中放っておけるエージェントとの違いです。
これが解き放つスケールは本物です。初期テストでは、Stripe が Fable 5 を 5,000万行の Ruby コードベースに向け、プロジェクト全体にわたる移行を1日で実行 し、コミュニティの報告ではコードベース規模の作業のために 最大1,000個の並列サブエージェント を立ち上げるセッションが描かれています。目標を保持し、段階に分解し、それらをこなしていくその能力こそ、AI エージェントとルールベースのチャットボット を分けるものそのものです。一方は仕事を終わらせ、もう一方は次の指示を待ちます。
本番品質のコードを書いてリリースする
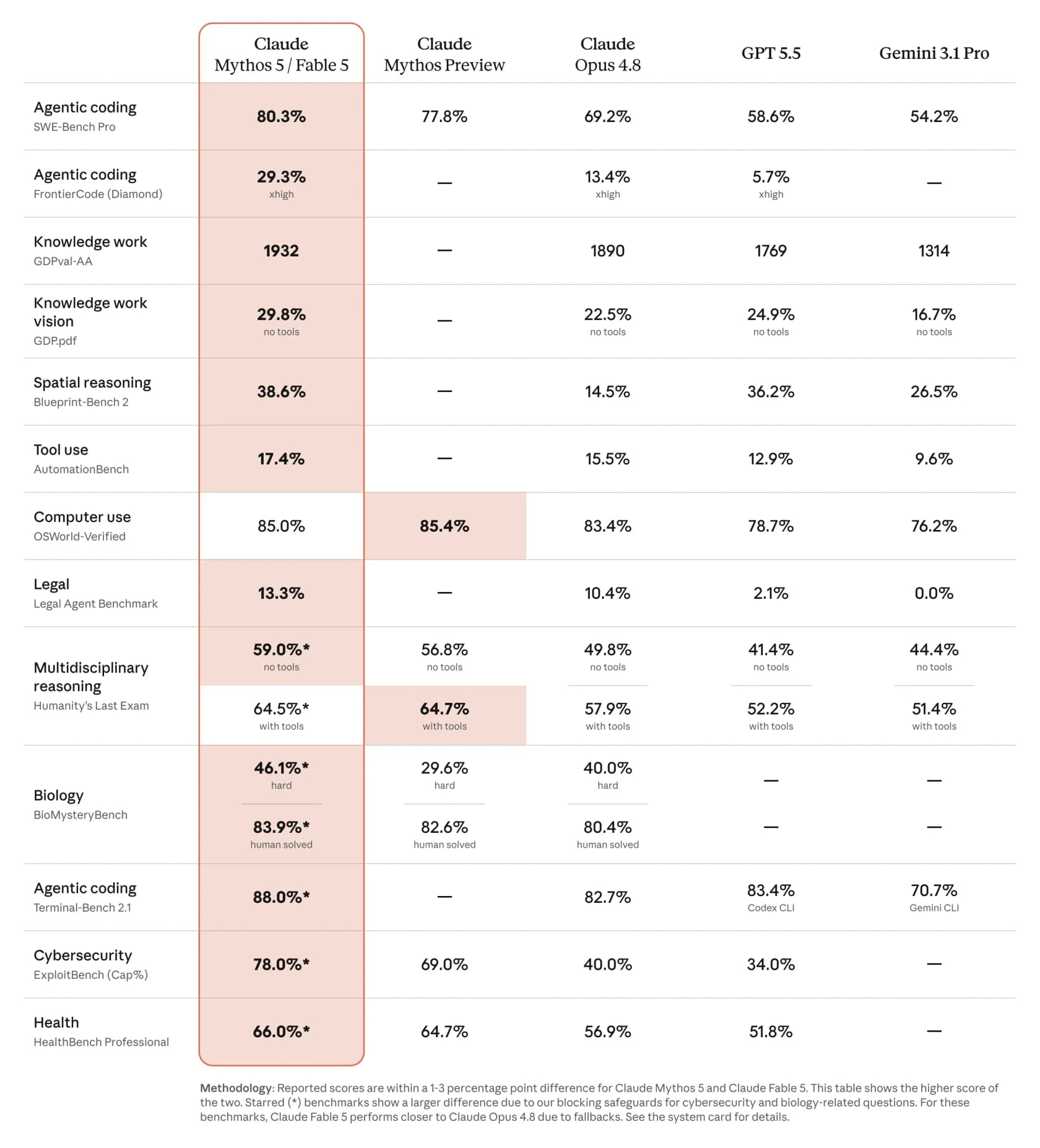
Claude Fable 5 ができる最も派手なことは、実際に動くソフトウェアを書くことです。Anthropic が公開した比較では、エージェント型コーディングで SWE-Bench Pro で 80.3% のスコア を出しており、これは Opus 4.8 の 69.2% に対するもので、GPT 5.5 は 58.6%、Gemini 3.1 Pro は 54.2% でした。より難しい FrontierCode(Diamond)ベンチマークでは、Opus を2倍以上に上回り、13.4% から 29.3% へと飛躍しています。CNBC は、一部のテストでその差を Opus 4.8 より10%以上高い と報じました。
数字は一つの話ですが、丸一日の実作業はまた別の話です。開発者の Simon Willison は Fable を自身のオープンソースの LLM ライブラリ に向け、それは4つの別々の修正を特定して実装し、その後ほぼ全面的にモデルによって書かれた 新しいリリース を出しました。彼の評価は生産性の上限をよく表しています。
「Fable がこれのために組み上げた API 設計、テスト、コード、ドキュメントの品質に本当に感心しました。今日それに数時間費やしましたが、数日分の仕事のように感じます。」- Simon Willison
彼だけではありませんでした。Andrej Karpathy はそれを メジャーバージョンの引き上げに値する飛躍的進歩 と呼び、FrontierCode ベンチマークを走らせたある開発者は印象的な推移を投稿しました。Opus 4.7 が 5.2%、Opus 4.8 が 13.4%、Fable 5 が 29.3% です。他の選択肢と比べてどこに位置するか検討しているなら、私たちの 最高の AI コーディングアシスタントツール と 最高の Claude AI 開発者ツール のまとめが次に読むのに良いでしょう。
すでに手元にある、長く雑然としたドキュメントを読む
ビジネスの作業の多くはコードではなくドキュメントであり、ここで 100万トークンのコンテキストウィンドウ が真価を発揮します。Fable 5 は 「ファイルや PDF に入れ子になった図表、チャート、テーブルを理解する」 もので、Anthropic はこれを財務、法務、分析の作業を中心に位置づけており、そのフルコンテキストを満たすことに価格の追加料金はありません。
具体的な裏付けは、緻密に相互に関連した仕様の50ページの PDF を渡し、何が完了し、部分的に完了し、欠けているかの正しい内訳を受け取った Hacker News のユーザーから得られました。
「かなり緻密で相互に関連した仕様の50ページの PDF を渡し、どれが実装されているか尋ねました…それは何が完了し、何が部分的に完了し、何が欠けているかを正確に特定しました。」- Hacker News のコメント投稿者
契約書、ポリシー文書の山、あるいは広大な ナレッジベース を抱えるどんなチームにとっても、それはコーディングのリーダーボードでもう1点取ることよりも日々の役に立ちます。それはまた、サポートエージェントがヘルプドキュメントや過去のチケットを読んで顧客に回答するときに使うのと同じ筋肉を、内部ドキュメントに向けただけのものです。
これらすべてを行うコスト
ここが熱気を冷ます部分です。上記のすべてはフロンティアツールの価格で動きます。入力100万トークンあたり10ドル、出力100万トークンあたり50ドルで、Opus 4.8 のちょうど2倍です。キャッシュされた入力トークンには 90%の割引 が適用され、米国限定の推論には1.1倍の追加料金がありますが、実感するのは見出しの料金でしょう。Fable 5 がラインナップの他とどう並ぶかについては、私たちの Claude 料金ガイド が各ティアを分解しており、Claude Pro プラン はほとんどの個人が最初に出会う場所です。
| スペック | Claude Fable 5 |
|---|---|
| リリース | 2026年6月9日 |
| モデルクラス | 「Mythos クラス」、Opus 4.8 の1つ上のティア |
| コンテキストウィンドウ | 1,000,000 トークン |
| 最大出力 | 128,000 トークン |
| 知識のカットオフ | 2026年1月 |
| 入力価格 | 100万トークンあたり10ドル(キャッシュ時1ドル) |
| 出力価格 | 100万トークンあたり50ドル |
| ロングコンテキスト追加料金 | なし |
実際にいくら使うかは、どれだけ深く考えさせるかにほぼ完全に依存します。Simon Willison は「自転車に乗ったペリカンを描く」テストを5つの思考努力レベルすべてで走らせ、1枚の画像のコストは 「low」で10セント未満から「max」で約72セント の範囲に及びました。努力レベルはあなたが設定するダイヤルであり、請求額の主要なレバーです。
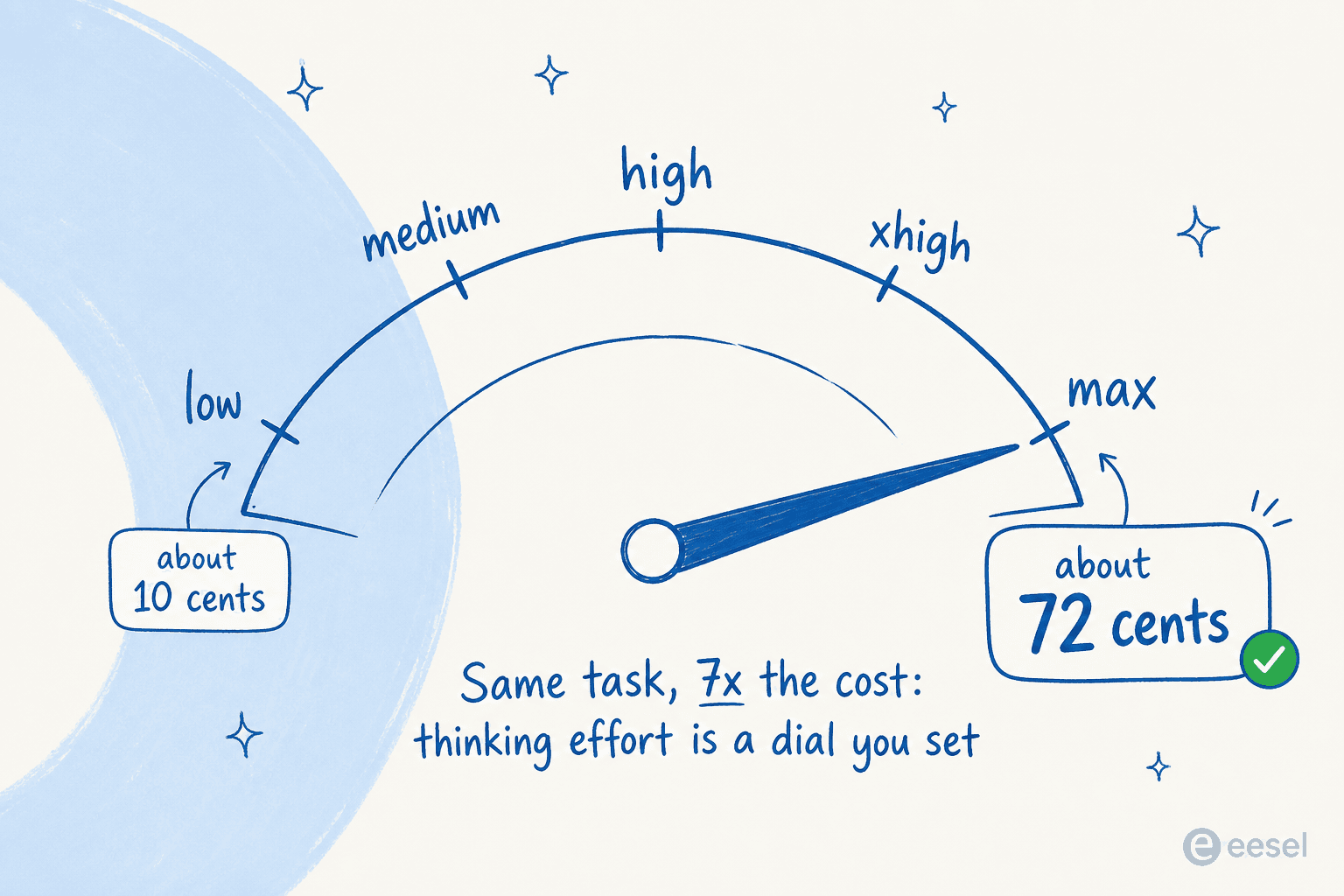
ハイエンドでは請求額が急速に積み上がります。Willison はテストの1日を 110.42ドルのトークン支出 として記録しました。しかし本物の対抗要因があります。Canva の評価リードは、社内のエージェント型ハーネスで Fable が Opus 4.8 の約半分のトークン を使うことを発見しました。つまり、より少ないステップで終える賢いモデルなら、実世界のコストはほぼ同じに着地しうるのです。教訓は「Fable は手が届かない」ではなく、コストは運用の仕方に完全に依存するということです。
Claude Fable 5 がしないこと
能力は両刃の剣であり、Fable 5 が意図的にフルパワーでは行わないことが1つあります。サイバーセキュリティ、生物学、化学、モデル蒸留のプロンプトに対しては、新世代の分類器 がそのトピックを検出し、代わりにあなたの回答を Opus 4.8 へルーティング し、それが起きたことが通知されます。Anthropic は、少なくとも95%のセッション ではフォールバックがまったく発動しないと述べています。
問題は誤検知です。開発者たちは、まったく無害な作業の最中に弱いモデルへ切り替えられたと報告しており、その中には危険な要素が何もない 基本的な液体取り扱いプロトコル で拒否されたユーザーもいました。AI 政策のライターである Nathan Lambert は、フロンティア AI 研究のように見えるプロンプトに対する、より静かな第2のメカニズムを指摘し、そこではモデルが あなたに告げずに効果を落とす ことがあると述べています。実務的なアドバイス:あなたの作業が技術的な業種に当たるなら、本格採用する前にテストしてください。
サポートチームを率いているなら、これらすべてが意味すること
ここは私たちの本拠地なので、具体的にいきましょう。Fable 5 にできることすべてを踏まえて、サポートリーダーは急いでヘルプデスクに組み込むべきでしょうか。たいていの場合、誇大宣伝が示唆するほどではありません。
カスタマーサービス向け AI についての不都合な真実はこうです。ティア1のチケットでは、モデルがボトルネックになることはめったにありません。カスタマーサービスの自動化 を探しているほとんどのチームは、下にどのモデルが座っているかを密かに過大評価しています。よくグラウンディングされた Opus 4.8、あるいは Sonnet 4.6 でさえ、「注文はどこ」「パスワードはどうリセットするの」「返金ポリシーは何」といった質問の圧倒的多数をすでに正しく回答します。それらに回答させるために Fable 5 に2倍払うのは、通学の送り迎えに F1 カーを借りるようなものです。あなたの AI ヘルプデスクエージェント が機能するかどうかを実際に決めるのは、モデルの周りを包むすべてです。それは、どんな AI ヘルプデスクソフトウェア のまとめでも、強力なツールと忘れられるツールを分けるのと同じパターンです。
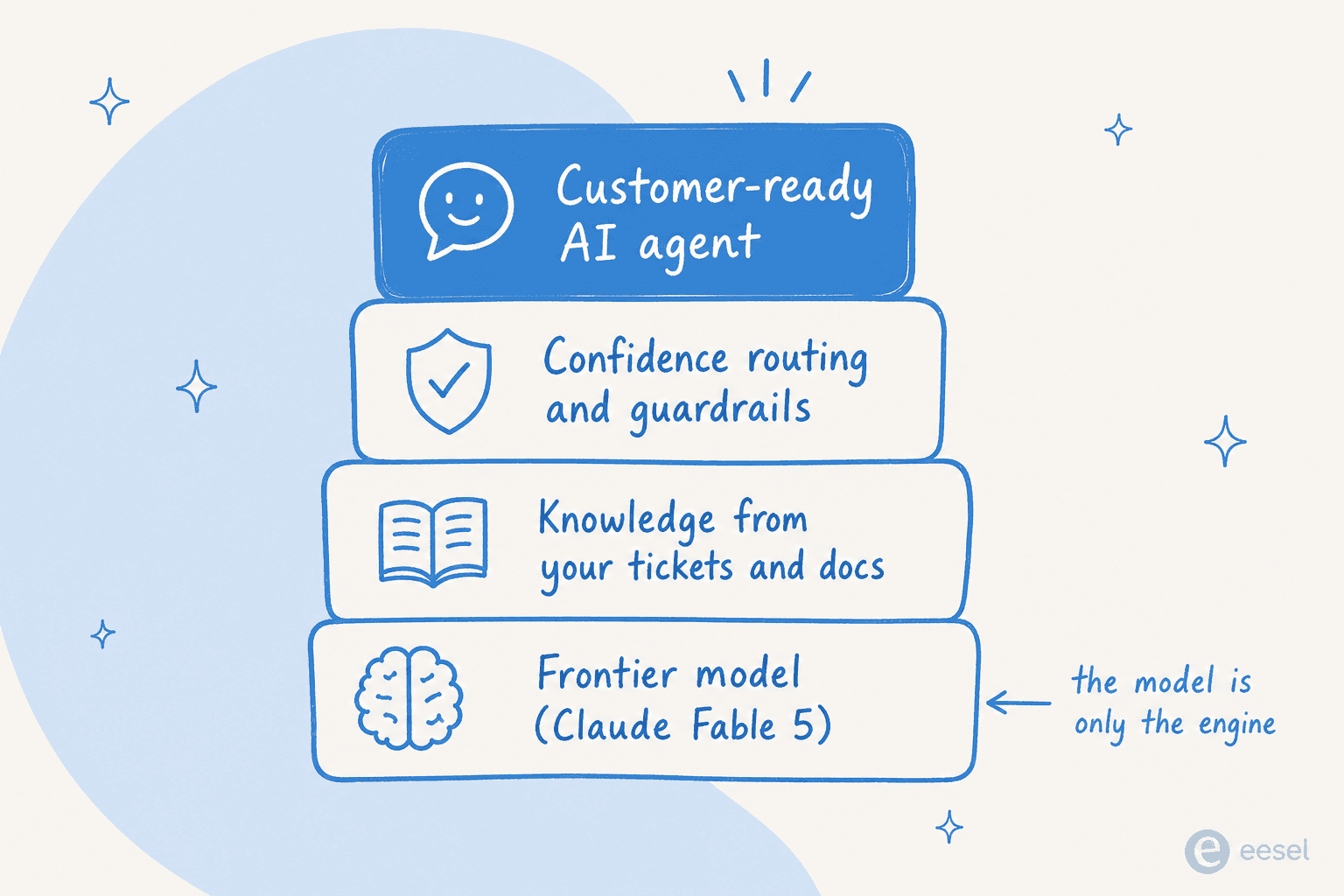
モデルのティアより重要なことが3つあります。第一に、それはあなたのビジネスを知っているか。勝ち筋は、より賢いベースモデルからではなく、あなたの 過去のチケットとヘルプドキュメント での学習から来ます。第二に、いつ黙るべきかを知っているか。生のモデルは間違っているときでも自信満々に回答します。それこそが チャットボットが悪い回答をする理由 です。本番のエージェントには信頼度ベースのルーティングが必要で、それは優れた チケットトリアージ のセットアップの核心であり、低信頼度のチケットは自動送信されず、下書きされるかエスカレーションされます。ある DTC サプリメント企業の CX リードが顧客インタビューで述べたように、AI が質問の100%に回答することは決してないので、彼らが実際に欲しいのは、自信のあるチケットだけを処理し、残りには手を出さないエージェントです。それは製品の能力であって、モデルの能力ではありません。
第三に、本番投入する前にそれを信頼できるか。それは絶えず出てくる、自社開発か購入かという問いを直接指し示します。「Anthropic がちょうど素晴らしいモデルを出したのだから、API の上に自社のサポートボットを作ればいいのでは?」作れます。ただし見た目より大きなプロジェクトでもあります。なぜならモデルは知性を与えてくれますが、ヘルプデスク連携、ガードレール、シミュレーション環境、レポーティングは与えてくれないからです。試した技術チームのいくつかは、代わりに購入へ切り替えました。
「自分たちで LLM アプリケーションを書くこともできましたが、そこに時間を投資したくありませんでした。私たちは、保守しなくて済むものが欲しかったのです。」- Karel, GENERAL BYTES
フロンティアモデルはスタックの最下層であって、スタック全体ではありません。コア製品が AI なら、自社開発しましょう。それ以外で、ただチケットがうまく回答されることを望むだけなら、モデルの上のレイヤーを購入する方が速く、安く、壊れにくいのです。これは、自家製スクリプトより チケット自動化向けの AI を選ぶ背後にあるのと同じロジックです。
eesel を試す
eesel AI は、Claude のようなフロンティアモデルの上に座るレイヤーなので、エンジニアリングプロジェクトなしにその能力を手に入れられます。既存のヘルプデスク(Zendesk、Freshdesk、HubSpot、Gorgias、そして 100以上の連携)に接続し、初日からあなたの過去のチケットとヘルプドキュメントから学習し、トリアージ、下書き、解決にわたって回答します。

差別化要因は、Fable 5 単体ではあなたに与えられない部分です。すなわち、あなたの過去のチケット数千件に対してエージェントを走らせる シミュレーションモード で、1人の顧客が話しかける前に、エージェントがどう回答していたか、そして解決率がどれくらいになるかを正確に確認できます。これによって Gridwise は最初の月でティア1リクエストの73%を解決するに至りました。そして 料金 は解決済みチケット1件あたり0.40ドルの従量課金で、席ごとの料金がないため、予測できないトークンではなく成果に対して支払います。eesel を試す のは、50ドルの利用枠付きで無料、クレジットカードも不要です。
よくある質問
Claude Fable 5 は、旧モデルにできなかった何ができますか?
Claude Fable 5 は自力でコードを書いて実行できますか?
Claude Fable 5 はカスタマーサポートの問い合わせに対応できますか?
Claude Fable 5 の運用にはいくらかかりますか?
Claude Fable 5 にできないことは何ですか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.





