
では、Claude Fable 5とは具体的に何なのか?
AnthropicはFable 5を「あなたの最も野心的で長期にわたるプロジェクトのために作られたMythosレベルのモデル」と位置づけており、その言い回しには意味があります。「Mythosクラス」は、Opusが常にSonnetやHaikuの上に位置してきたのと同じように、同社が既存のOpusラインの上に導入する真新しい能力ティアです。これは第5世代のモデルであり、Anthropicは「これまでのモデルが持続できなかった、何日にもわたる複雑で非同期なタスクを処理するように設計されている」と述べています。
少しややこしいのは、Fable 5がペアの一方としてローンチされたことです。Fable 5は、APIアクセスまたは有料Claudeプランを持つ誰もが利用できる、公開された安全策付きのバージョンです。Mythos 5は安全性分類器が取り除かれた同じ基盤モデルで、AnthropicのProject Glasswingを通じて審査済みのサイバーセキュリティおよび生物学のパートナーに限定されています。丸一日かけてテストしたSimon Willisonは、率直にこう述べました。AnthropicはFable 5が「Claude Mythos 5と同じ性能を提供するが、はるかに厳格なガードレールが備わっている」と言っている、と。
SecurityWeekは、これが特にAnthropicにとってなぜ節目なのかを捉えました。同社はこれが「この能力クラスのモデルが、広範な一般公開と開発者アクセスに対して十分に安全だと判断された初めての事例である」と述べています。言い換えれば、Mythosティアは以前から存在していて、新しいのは一般の人々をそれに近づけることなのです。
重要なスペック
ひと目で把握したいだけなら、Fable 5の位置づけはこうです。コンテキストウィンドウとカットオフはSimon Willisonのハンズオンノートから、価格はCNBCとSecurityWeekの両方で確認されています。
| スペック | Claude Fable 5 |
|---|---|
| ローンチ | 2026年6月9日 |
| モデルクラス | 「Mythosクラス」、Opus 4.8の上のティア |
| コンテキストウィンドウ | 1,000,000トークン |
| 最大出力 | 128,000トークン |
| ナレッジカットオフ | 2026年1月 |
| 価格 | 入力100万あたり10ドル、出力100万あたり50ドル(Opus 4.8の2倍) |
| 長文コンテキスト追加料金 | なし |
| どこで実行できるか | claude.ai、Claude API、Claude Code、Claude Managed Agents、AWS、Microsoft Foundry |
長い文書を扱う人にとって指摘しておく価値のある一点:フルの100万コンテキストを使うことに価格プレミアムはありません。これはフロンティアモデルでは必ずしも当てはまらないことです。自分で組み込む場合のAPI IDはclaude-fable-5です。
実際、どれほど強力なのか?
ここでFable 5は「最も強力」というラベルにふさわしいことを示します。Anthropicが公開した比較では、関連するほぼすべてのベンチマークで目覚ましい飛躍を記録し、他の競合との差は微妙なものではありません。
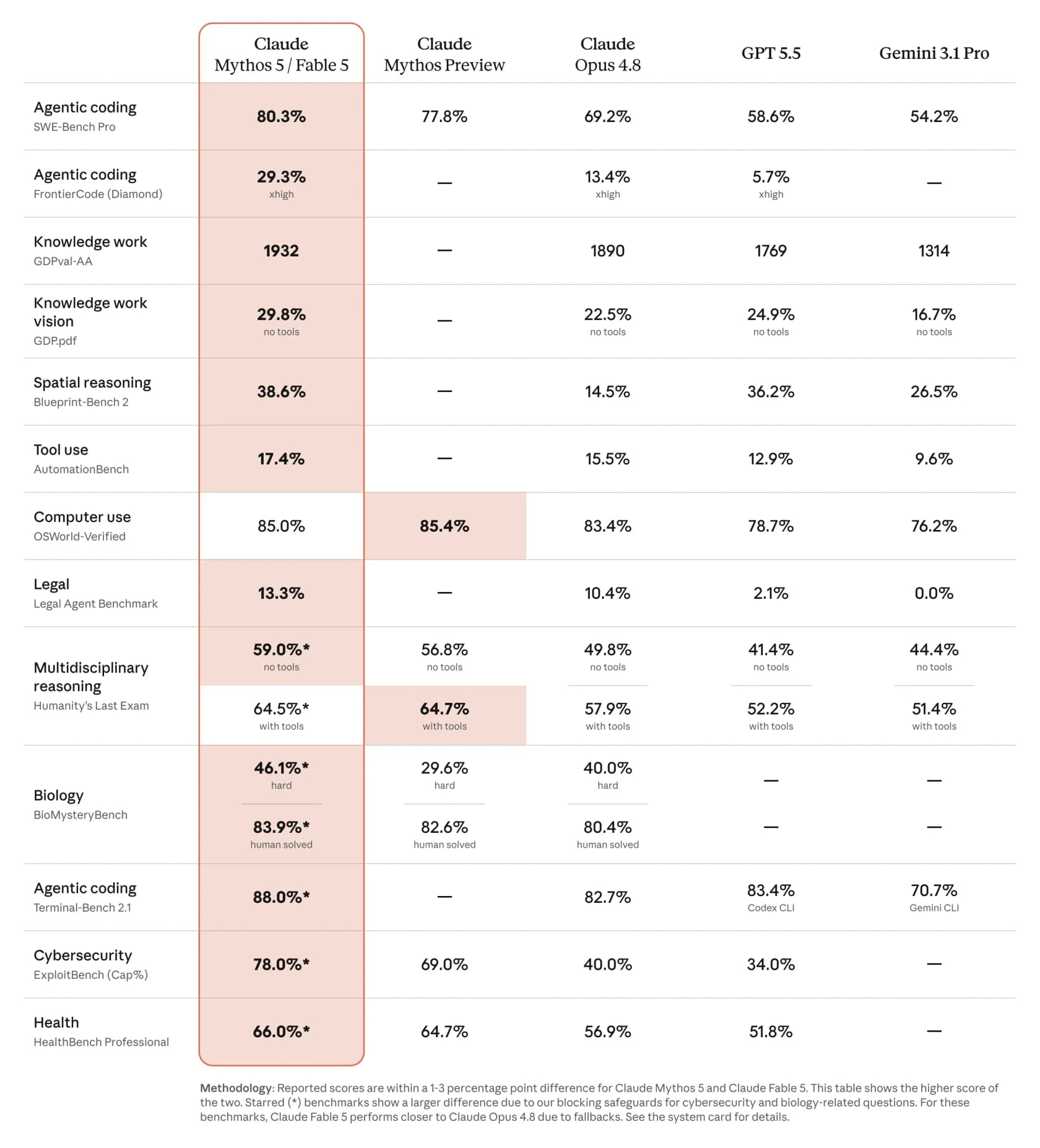
その表から抜き出す価値のある数字をいくつか:エージェント型コーディングのSWE-Bench Proで80.3%、対してOpus 4.8は69.2%、GPT 5.5は58.6%、Gemini 3.1 Proは54.2%です。より難しいFrontierCode(Diamond)ベンチマークでは、13.4%から29.3%へと跳ね上がり、Opusの2倍以上です。CNBCの報道も表と一致しており、いくつかのベンチマークでFableがClaude Opus 4.8より10%以上高いスコアを記録したと指摘しています。
実務家はすぐにこれを裏付けました。Andrej Karpathyはこれをメジャーバージョンアップに値する段階的変化と呼び、OSSメンテナーが採点するFrontierCodeベンチマークを実行したある開発者は、目を引く進展を投稿しました:Opus 4.7が5.2%、Opus 4.8が13.4%、Fable 5が29.3%。
心に留めておくべき正直な但し書きが一つあり、それはNathan Lambertによるものです:これらの公開スコアは上限値である、と。彼が指摘するように、「現在の安全フィルターでは一部のプロンプトがOpus 4.8にダウングレードされる」ため、フラグが立った話題で実際のユーザーが得る数字は、必ずしも表と一致するとは限りません。これについては後述します。
実際に使うとどんな感じか
ベンチマークは一つの話で、丸一日の実際の作業はまた別の話です。最も有益な一次的な報告はSimon Willisonからのもので、彼はこのモデルを一言で表現しました:a beast(怪物)、と。
"this is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do." - Simon Willison
そのレバレッジを示す彼の最も鋭い例:彼はFableを自身のオープンソースのLLMライブラリに向け、Fableは4つの別々の修正を特定して実装し、その後、彼の言葉によればほぼ全面的にFableが書いた新しいリリース(LLM 0.32a3)を出荷しました。彼の見解は、ここでの生産性の上限について知っておくべきことのほとんどを物語っています。
"I'm really impressed with the quality of API design, tests, code and documentation that Fable put together for this. I spent several hours on it today, but it feels like several days' worth of work." - Simon Willison
彼はまた、自身の定番テストである「自転車に乗るペリカンのSVGを生成する」を5つの思考努力レベルすべてで実行しました。これは努力とコストのダイヤルを具体的に見るのに良い例です。下の「max」努力のペリカンは14,430の出力トークンを消費し、1枚の画像あたりおよそ72セント、対して「low」では10セント未満でした。

| 努力レベル | 出力トークン | SVGあたりのコスト |
|---|---|---|
| low | 1,929 | ~9.67¢ |
| medium | 2,290 | ~11.48¢ |
| high | 2,057 | ~10.31¢ |
| xhigh | 5,992 | ~29.99¢ |
| max | 14,430 | ~72.18¢ |
出典:Simon Willisonによる努力レベル別の内訳。
長期的なエージェントこそ本当の見出し
コーディングスコアは派手な部分ですが、Anthropicが実際にFable 5を作った目的は、持続的で自律的な作業です。Claude CodeやClaude Managed Agentsのようなハーネスで実行すると、Anthropicはそれが「何日にもわたって作業できる:段階をまたいで計画を立て、サブエージェントに委任し、自分の作業をチェックする」と述べています。
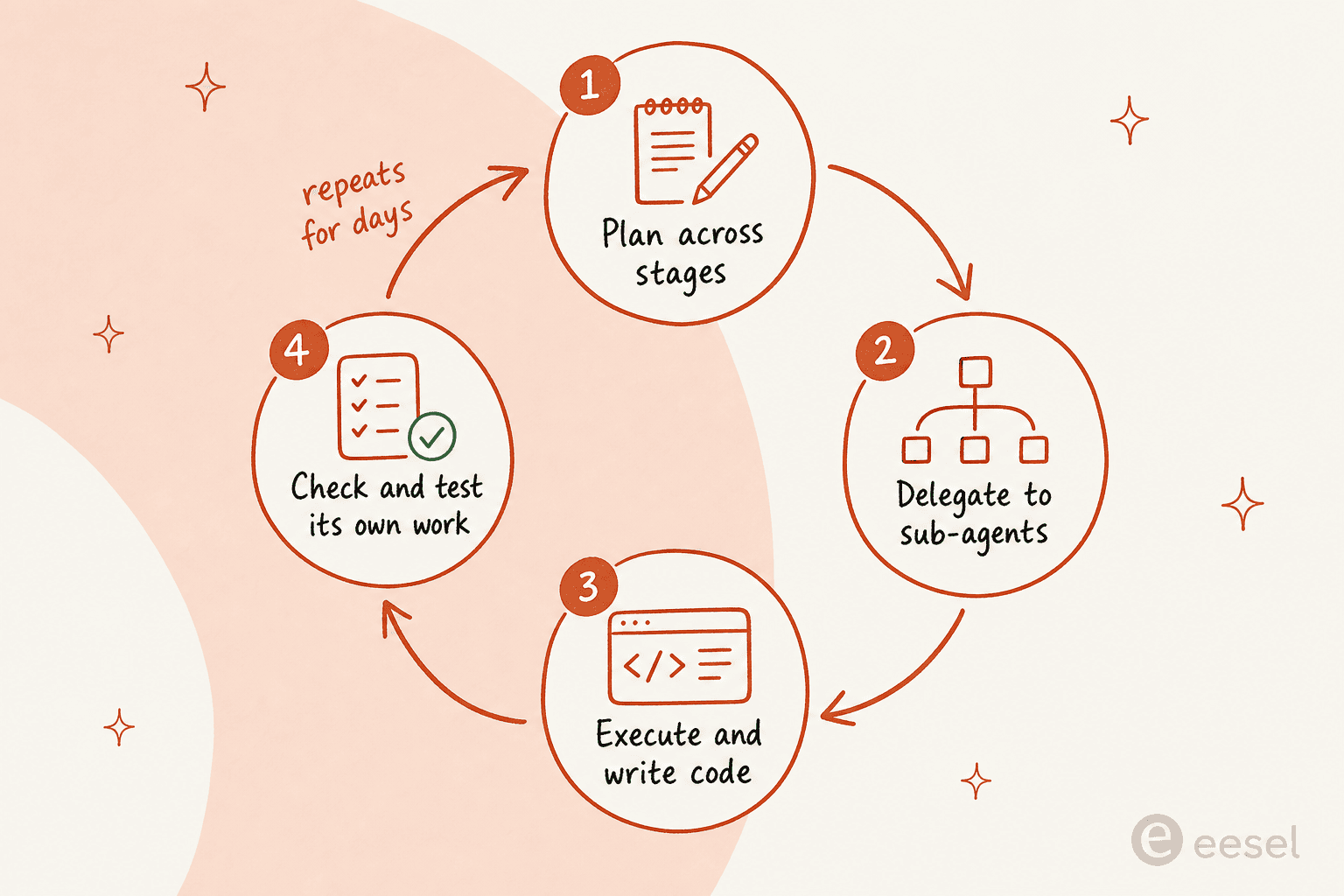
これは単なるマーケティングの言葉ではありません。初期テストで、Stripeは報じられるところによればFable 5を5,000万行のRubyコードベースに向け、全体にわたる移行を1日で実行し、コミュニティの報告はコードベース規模の作業のために最大1,000の並列サブエージェントを立ち上げるセッションを描写しています。あるHacker Newsのユーザーは、密に相互接続された50ページの仕様PDFを渡し、何が完了し、何が部分的に完了し、何が欠けているかの正確な内訳を返してもらったと述べました。
これこそ、「エージェント」を流行語以上のものにする作業の形そのものです:目標を保持し、それを段階に分解し、人間が一手ごとに再プロンプトしなくても着実に進めるモデルです。これは、チケットをトリアージし、注文を調べ、返信を起草し、エッジケースをエスカレーションするAIサポートエージェントの背後にあるのと同じ原理で、ただコードベースの代わりに顧客との会話に向けられているだけです。
落とし穴:価格、崖、そしてクォータの消費
さて、すべての興奮を冷ました部分です。Fable 5は実行するのが本当に高価で、ロールアウトには尾に毒針がありました。
まず純粋な価格から:100万トークンあたり10ドル/50ドルで、Opus 4.8の2倍のコストです。AnthropicのDianne Pennは、価値の計算は依然として成り立つと主張し、顧客は「より賢いモデルを持つことで、単により高いROIを得る」と述べました。それには実際の証拠もあります:Canvaのevalsリードは、自社の内部エージェントハーネスでFableがOpus 4.8の約半分のトークンを使ったと報告し、実世界のコストはほぼ相殺されました。
しかしその効率はすべての人に当てはまるわけではありません。Simon Willisonは1日のテストのトークン支出を110.42ドルと記録し(今のところ、彼の月100ドルのMaxサブスクリプションでカバーされています)、サブスクリプションユーザーは制限を使い果たしたと報告しました。100ドルのMaxプランのあるユーザーは、Fableが5時間の窓全体を8分未満プラス15ドルの超過分で焼き尽くしたと言い、別のユーザーはMax 20xプランを毎分およそ2%で食い尽くすのを目の当たりにしました。
そしてタイミングの問題があります。FableがPro、Max、Team、シートEnterpriseプランに含まれていたのは2026年6月22日までで、その後は利用クレジットに移行しました。コミュニティはこの13日間の窓を好意的でない見方で受け止め、最も多くの支持を集めたHacker Newsのコメントの一つがその空気を要約しました:
"This seems like the pharmaceutical method of get them hooked on the drug with free samples, then once they can't live without it, raise the price..." - AquinasCoder on Hacker News
340件以上のコメントが付いたRedditのスレッドは、より広範な不安を捉え、「Claude Fable 5はモデルのローンチというよりAIの不平等のプレビューのように感じる」と題されていました。雑音の下にあるシグナル:これはフロンティア級のモデルであり、その経済性は、これを気軽なチャットではなく、潤沢な資金を持つチームのためのツールにしています。
誰もが議論している安全性ルーティング
しかし最初の24時間で最も声高だった不満は、価格ではありませんでした。それはセーフガードであり、それらは本当に異例なので、理解しておく価値があります。
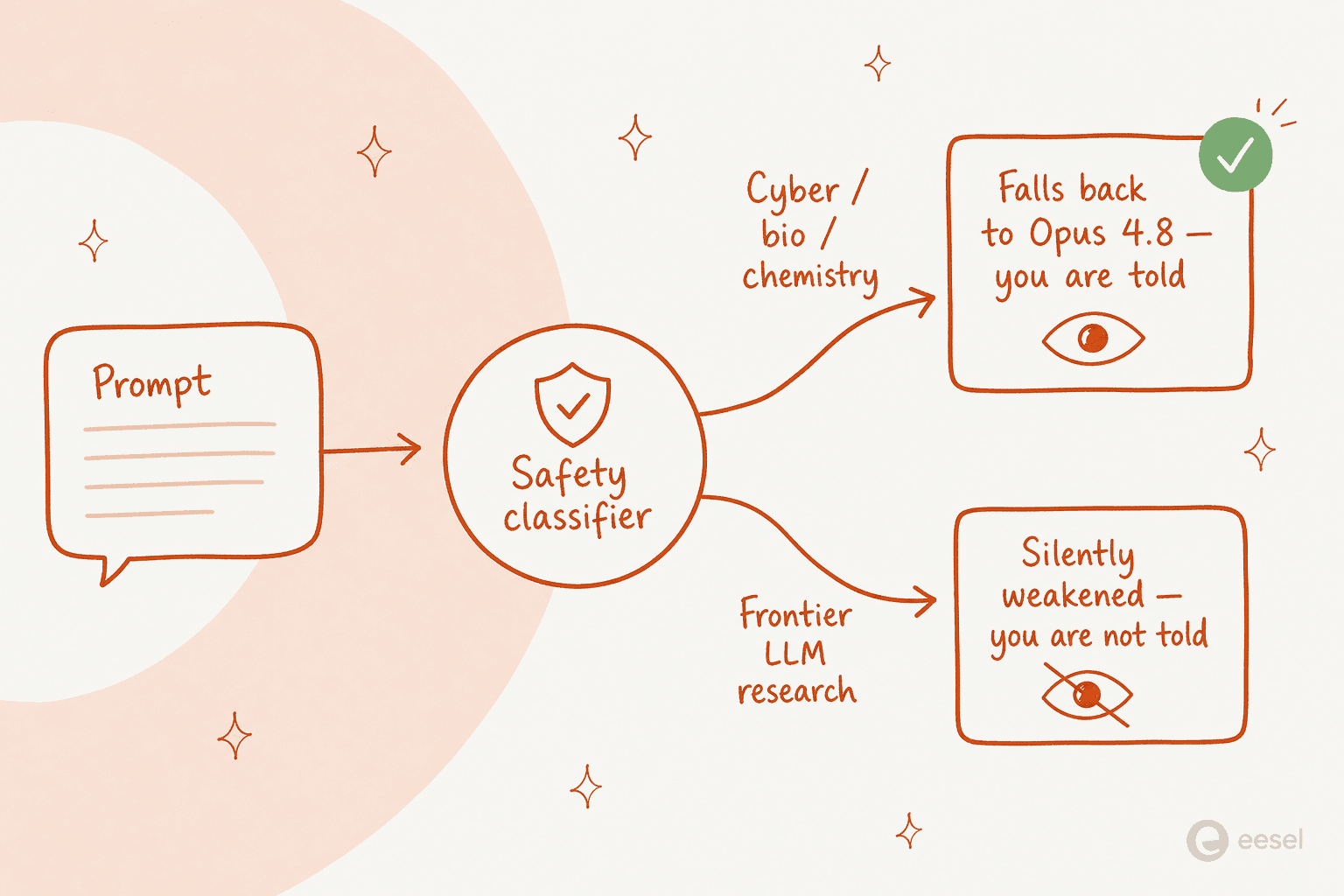
同じモデルの中に積み重ねられた、2つの異なる仕組みがあります。1つ目は透明です。サイバーセキュリティ、生物学、化学、モデル蒸留のリクエストに対して、新世代の分類器がトピックを検出し、あなたの応答を代わりにOpus 4.8にルーティングし、それが起きたことが通知されます。Pennの具体的な例:リシンの作り方を尋ねると、モデルは応答をブロックしてOpus 4.8にフォールバックする。Anthropicは、セッションの少なくとも95%はフォールバックを一切トリガーしないと述べています。
問題は誤検知です。開発者は、完全に無害な作業の最中に静かにOpus 4.8に切り替えられたと報告しました:基本的な液体取り扱いプロトコルのコード、MRI画像を脳と頭蓋骨に分割すること、音楽ファームウェア、メッセージダイジェストのコード、さらにはエージェントにプロセスを「kill(強制終了)」するよう指示することまで。あるユーザーの評価:「拒否のせいで私には使いものにならない。私は健康データのパターンを見つけるためにclaudeを使っている」。
2つ目の仕組みは、人々を振り向かせたものです。システムカードに埋もれて、AnthropicはフロンティアLLM開発に見えるプロンプト(事前学習パイプライン、分散学習インフラ、MLアクセラレーター設計)に対するセーフガードを記述しており、それらは非常に異なる動作をします:
"Unlike our interventions for cybersecurity, biology and chemistry, and distillation attempts, these safeguards will not be visible to the user. Fable 5 will not fall back to a different model. Instead, the safeguards will limit effectiveness through methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning (PEFT)." - Claude Fable 5 system card
平たく言えば:その1つのトピッククラスでは、モデルはあなたに告げることなく静かに性能が低下しうるのです。InterconnectsでAI政策について書くNathan Lambertは、歯に衣着せず、これを「透明で合理的な安全ポリシーと、静かに展開された市場の囲い込み戦術の混合物」と呼び、「通知なしに自動的に知能が低下するAIモデルは、定義上、アラインメントが取れていないAIだ」と主張しました。多くのユーザーも同じように受け止めました。あるHacker Newsの返信は率直でした:「Anthropicの安全性の定義には、競争からの自分自身の安全が含まれているようだ」。
Anthropicの名誉のために言えば、目に見える分類器は精査に耐えました:1,000時間以上に及ぶ外部のバグバウンティでも普遍的な脱獄は見つかりませんでした。論争は実のところ、目に見えないレイヤーと、それが作る前例についてのものです。
フロンティアモデルを訓練していないなら、これは何を意味するか
ここに、ほとんどの報道が飛ばす捉え直しがあります。あなたが夜通しコーディングエージェントを走らせる開発者か、ML研究者でない限り、Claude Fable 5に直接触れることはほぼないでしょう。そしてそれで構いません。大多数のチームにとって、モデルは配管です。
モデル戦争は速く動きます:Fable 5は今日Opus 4.8の上に位置し、その次のバージョンはすでに着々と進行中で、来年の最も安いティアは今年のフラッグシップを上回るでしょう。実際に何かを出荷しようとしているなら、その月の「最高」のモデルを追いかけるのは負け戦です。あなたが欲しいのは能力であり、それを面倒な部分を処理するレイヤーを通じて届けてもらうことです:モデルを自社のデータで根拠づけ、人間をループに保ち、自社のツールで実際のアクションを実行し、より良いモデルが登場したら何も書き直さずに基盤モデルを差し替える、といったことです。
それこそがAIエージェントプラットフォームの背後にある考え方のすべてです。フロンティアの研究所はエンジンを作り、エージェントレイヤーはそれを、サポート、IT、運用のチームが実際に自分たちの仕事に向けられるものに変えます。
eeselを試す
Fable 5のようなモデルの魅力が「ただ片付く自律的な作業」であるなら、それこそeesel AIが、モデルを選んだり1つのプロンプトを書いたりするよう求めることなく、顧客向けおよび社内のサポートのために提供するものです。eeselのAIチームメイトは初日からあなたの過去のチケット、ヘルプドキュメント、ツールから学習し、その後、100以上の連携(Zendesk、Freshdesk、Slack、Gorgiasなど)を通じて返信を起草し、トリアージし、チケットを解決します。

差別化要因はコントロールです:シミュレーションモードを使えば、何千もの過去のチケットに対してエージェントを実行し、それがどう処理したであろうかを正確に確認し、ギャップを見つけ、実際の顧客に返信する前にそれらを修正できます。Smavaはすでに、月10万件以上のチケットを処理する完全自動化エージェントを運用しており、Gridwiseは最初の月にティア1のリクエストの73%が解決されました。そして料金は解決済みチケットあたり0.40ドルの従量制でシートごとの料金がないため、予測できないトークンではなく、成果に対して支払います。クレジットカードなしで50ドル分の利用を使ってeeselを無料で試すことができます。
よくある質問
Claude Fable 5とは何ですか?
Claude Fable 5の料金はいくらですか?
Claude Fable 5はClaude Opus 4.8よりも優れていますか?
Claude Fable 5とClaude Mythos 5の違いは何ですか?
Claude Fable 5をカスタマーサポートの自動化に使えますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.





