
私は実際のサポートキューでAIを運用しています――正直な見解
ほとんどのモデル解説が始めない場所から始めます。それが本当に重要な部分だからです。フロンティアモデルが実際の混乱したサポートキューに出会う場面を何年も見てきましたが、パターンは変わりません:モデルが難しい部分であることはまれです。
具体的な数字を示します。あるお客様Gridwiseは、eeselが最初の月にティア1リクエストの73%を解決したのを確認しました(7日間のトライアル中の結果)。別のお客様Smavaは月100,000件以上のドイツ語チケットを処理する完全自動化されたZendesk AIエージェントを運用しています。これらはどれも最も賢いモデルを選んだことからではありません。解決済みチケットでのトレーニング、信頼度によるルーティング、本番稼働前の実際の履歴でのシミュレーションから生まれました。
だから新しいOpusが登場したとき、私が気にする質問は「ベンチマークでより賢いか」ではありません。「これは実際にお客様の受信トレイに送るものを変えるか」です。そのレンズでOpus 4.8を見てみましょう。
Claude Opus 4.8とは
Claude Opus 4.8はAnthropicのOpusファミリーの最新モデルで、Claudeの高性能ティアです。Anthropicは2026年5月28日に公開し、「全ベンチマークにわたる改善でOpus 4.7を発展させた」「より効果的な協力者」として紹介しています。APIではモデルID claude-opus-4-8 で呼び出します。
主要なスペックは簡単にまとめられます:標準価格での1Mトークンのコンテキストウィンドウ、最大128kトークンの出力、モデル自身が制御する適応的思考(個別の拡張思考トグルはなくなりました)。テキストと画像を読み取り、80以上の言語に対応し、トレーニングデータは2026年1月まで(モデル概要)。
Anthropic自身のこの進化の表現は爽やかなほど誇張がありません。発表では「前任者からの控えめながら確かな改善」と呼び、Hacker Newsのスレッドでも同様に名付けられています。大きな世代間ジャンプを覚えているなら、これはそうではありません。磨きと修正のリリースであり、それで十分です。修正が興味深い部分です。
Opus 4.8の新機能
特にチャットだけでなく開発のためにモデルを選ぶ場合、知っておく価値のある変更点がいくつかあります。
誠実性が本当に向上しました。 Anthropicはこれを「最も顕著な改善の一つ」と呼び、私が実際にお金を払う価値があると感じる部分です。Opus 4.8は4.7と比べて自分のコードの欠陥を無言でスルーする可能性が約4分の1に減少したと報告されており、自信を持って答えを作り出す代わりに不確実性を示す傾向が強まっています。誤った回答にコストがかかる環境でAIを展開する人にとって、「確信がない時に教えてくれる」はコーディングベンチマークのもう一点よりも価値があります。
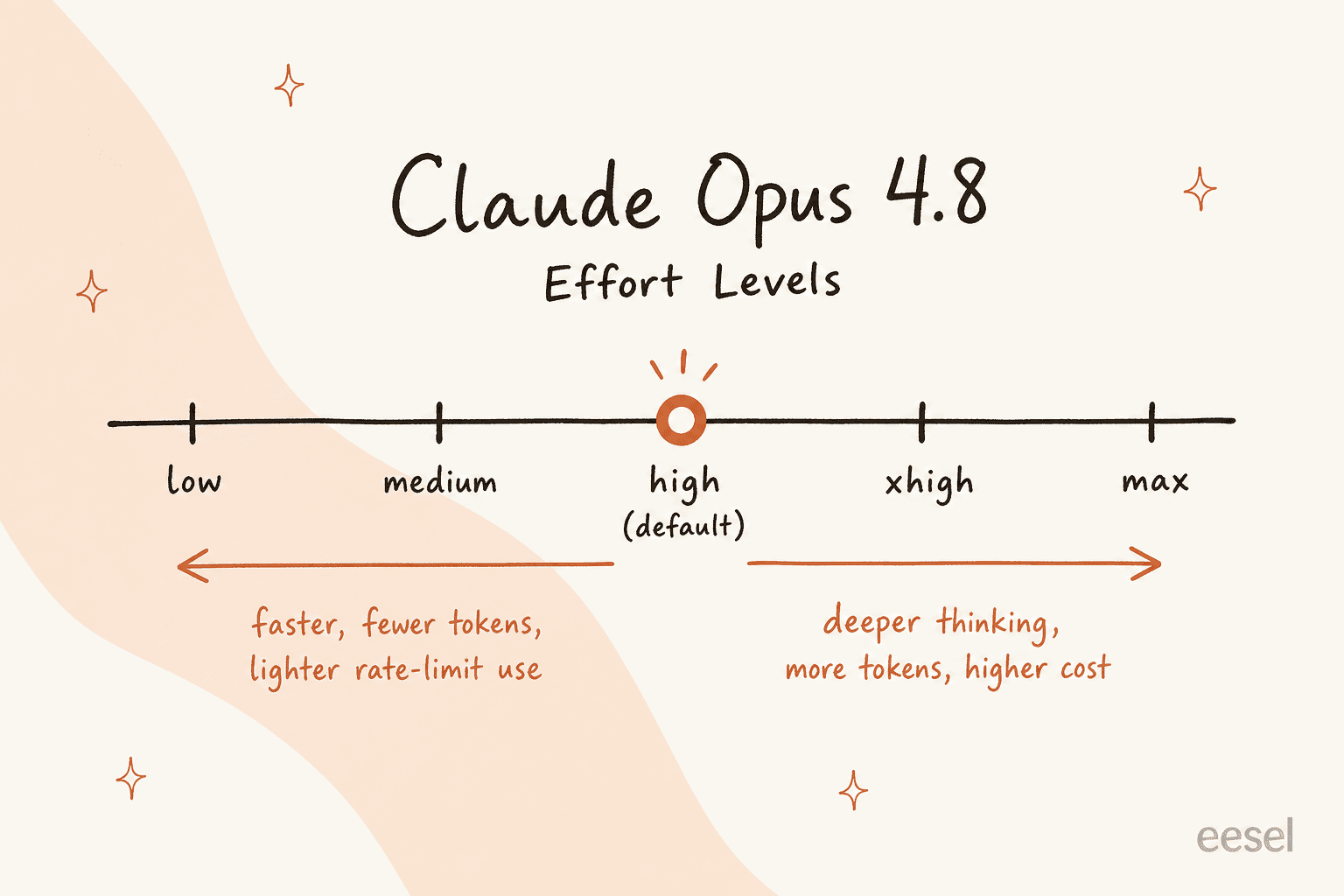
エフォートコントロール。 モデルがレスポンスにどれだけ取り組むかを設定するダイヤルが追加されました。low から max まで(high と max の間には xhigh があります)。デフォルトは high です。より深い推論には上げ、速度と軽い使用には下げます。トレードオフは現実的で、何かに組み込む前に理解する価値があります。
Claude Codeでの動的ワークフロー。 Claude Codeでは、Opus 4.8がジョブを計画し、1セッションで何百もの並列サブエージェントを展開し、報告前にその出力を検証できます。数十万行にわたる移行などのコードベース規模の作業を対象としています。Claude Codeのサブエージェントを使っているなら、試すべき機能です。
タスク途中でのシステム命令。 開発者向けに、Messages APIはメッセージ配列内に system エントリを受け付けるようになりました。プロンプトキャッシュを壊さずに命令、権限、トークン予算を途中で更新できます。小さな変更ですが、エージェントを構築している場合に本当に便利です。
より温かみのある声。 初期テスターはより協力しやすく、長いセッションでもコンテキストとスタイルを維持するのが得意と表現しています。その裏側は以下のコミュニティの反応に現れています。
Claude Opus 4.8の価格設定と位置づけ
価格は変わっていないので簡単です。Opus 4.8は入力トークン100万件あたり5ドル、出力トークン100万件あたり25ドルで、Opus 4.7と全く同じです(価格ページ)。2.5倍の速度で動作する高速モードもあり、Anthropicによると以前のモデルの高速モードより大幅に安いです。
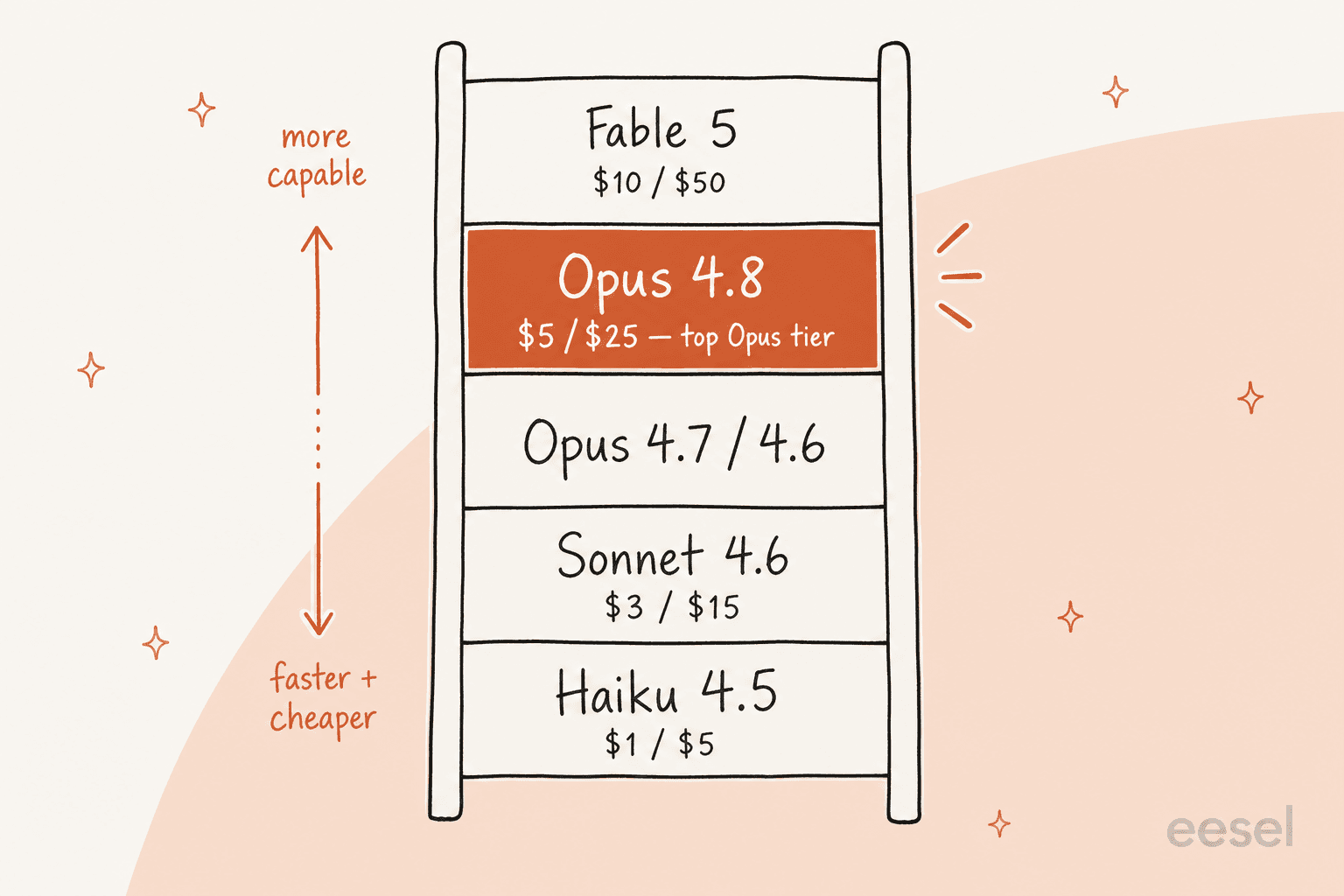
2026年半ば時点のClaude全ラインナップを示します。モデルを実際に選択するために必要なコンテキストです:
| モデル | 入力/出力(100万トークンあたり) | コンテキスト | 最適用途 |
|---|---|---|---|
| Claude Fable 5 | $10 / $50 | 1M | Anthropicの最高性能の広く公開されたモデル |
| Claude Opus 4.8 | $5 / $25 | 1M | 最高Opusティア;複雑な推論、長期エージェント |
| Claude Opus 4.7 / 4.6 | $5 / $25 | 1M | 前世代のOpus |
| Claude Sonnet 4.6 | $3 / $15 | 1M | 速度と知性の最良のバランス |
| Claude Haiku 4.5 | $1 / $5 | 200k | 高ボリュームの単純タスクに最速最安 |
注目点:Opus 4.8は最強のOpusティアモデルですが、スタック全体のトップではなくなりました。ローンチから約2週間後にAnthropicがClaude Fable 5を最も高性能な広く利用可能なモデルとして2倍の価格でリリースしました。つまりOpus 4.8は賢明な高性能デフォルト、Fable 5は「お金は問題ない、絶対最高のものを」オプションです。前世代の比較はGemini 3 Pro vs Claude Opus 4.6でAnthropicのモデルの立ち位置が分かります。
驚く人が多いコストの落とし穴を一つ:Opus 4.7以降は「同じ固定テストに対して最大35%多くのトークンを使用する可能性がある」新しいトークナイザーを使用しています。つまり表示価格が変わらなくても、古いモデルと比べてタスクあたりの実際のコストは上がる可能性があります。この詳細がコミュニティの不満の多くを説明しています。次の部分に続きます。(価格設定が読む理由全体であれば、Claudeの価格ガイドがティア別に詳述しています。)
人々が実際に言っていること
コミュニティの反応の最も明確な読み取りは、Opus 4.8は人々が公然と不満を持っていた4.7の修正版だということです。「フォームへの回帰」という評価があちこちにあり、長期的なClaudeレビューとも一致しています。r/ClaudeAIでのテスト数時間後のある開発者はうまく表現しています:
「4.8は正確で、速く考え、何もハルシネートしていない。何かを知らない時は、何かを作り上げる代わりに直接聞いてくる。4.6が進化すべきだったものの感じがする。」
これはAnthropicの誠実性の主張と一致し、最も繰り返されるポジティブな評価です。しかし二つの正直な緊張関係は指摘する価値があります。マーケティングページが教えないような内容だからです。
第一に、消費が多い。最も一般的な不満はOpus 4.8が使用制限を速く消費することで、新しいトークナイザーのせいもあります。GPT-5.5と比較するスレッドで一人のユーザーが指摘したように:
「Opus 4.8はビーストで、4.7より実行面でもデザイン面でもはるかに優れていると思う。本当の問題はトークン。はるかに多くのトークンを消費し、最大サブスクリプション内で初めて制限に達した。」
第二に、自律性は魔法ではありません。長くて難しいタスクを実行するパワーユーザーは、Opus 4.8にはまだ明確なスコーピングが必要と報告しており、あるクオンツシステムアーキテクトは「Opus 4.8を効果的に使うには、人間がまだ多くを考える必要がある。より多くを定義し、より多くを導き、コンテキストをより多く自分で維持する必要がある」と指摘しています。称賛された誠実性向上の裏側は、声高な少数派がオープンなクリエイティブな作業には慎重すぎる、または謝りすぎると感じていることです。これはどれも非難ではありません。単に調整された像です:明確な指示を与えるほど良くなる、強力で誠実でトークンを消費するモデル。
より賢いモデルがカスタマーサポートにとって実際に何を意味するか
これが私が実際に知っていることです。サポートチームを運営しているなら、Opus 4.8のようなモデルが登場したときの誘惑は「良かった、AIサポートが改善された」と思うことです。時にはそうです。しかしモデルはエンジンであって、車ではありません。AIカスタマーサービスソフトウェアが実際に何で作られているかを正確に理解することは価値があります。
技術的に優秀な多くのチームが同じ結論に辛い道で至るのを見てきました。OpusがこれほBlé良いなら直接呼び出せるとの考えでClaude APIを自分で統合するために去るお客様を見てきました。数か月後、保守の現実が訪れます。購入を選んだあるエンジニアリングリードは計算を簡潔にまとめました:独自のLLMアプリを書けるが、「そこに時間を投資したくない」し、「保守不要なもの」が欲しかったと。
それは本番サポートエージェントがモデルに加えて多くの地味な足場を必要とするからです:
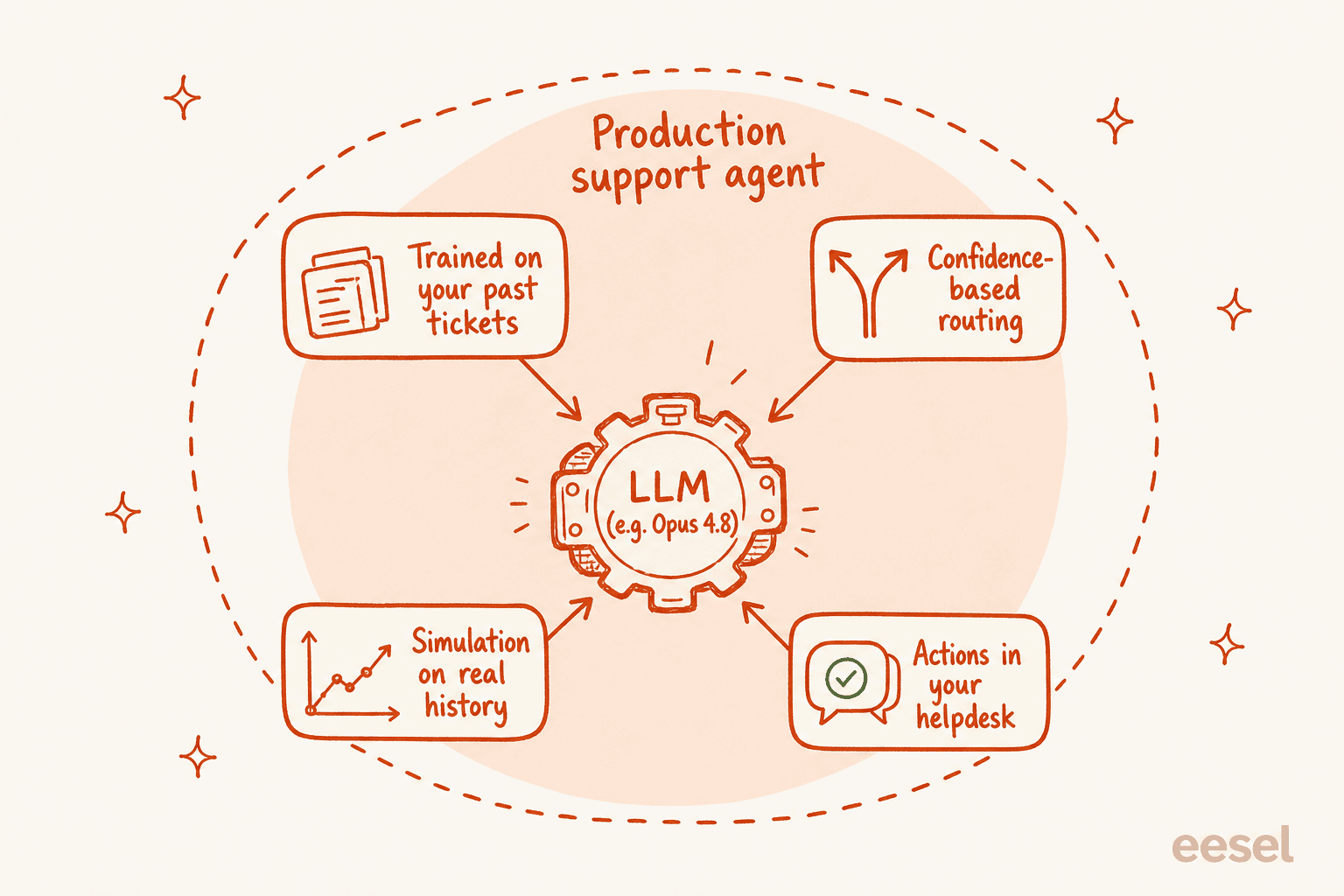
- モデルではなくあなたの知識。 Opus 4.8の2026年1月のトレーニングカットオフは、あなたの返金ポリシーや先週の障害について何も知りません。有用なエージェントは世界の一般知識ではなく、過去のチケット、ヘルプドキュメント、マクロから学習します。
- 信頼度ベースのルーティング。 Opus 4.8の誠実性向上は現実のものですが、モデルがいつライブで返信するかを自分で決めることは望ましくありません。確信がない時は下書きし、確信がある時だけ自動送信するようにしたい。これはモデルの設定ではなくシステムレベルのガードレールです。
- 本番稼働前のテスト方法。 一人の顧客がAIの返信を見る前に、実際の解決済みチケット数千件に対してシステムを実行し、どこで正解または不正解だったかを正確に確認したいでしょう。新しいモデルを選んでもそれは得られません;シミュレーションが提供します。
- 回答だけでなくアクション。 タグ付け、トリアージ、注文の照会、人間への適切なエスカレーション。これらはすべてヘルプデスクインテグレーションに存在し、生のモデルにはありません。
これはまた「どのモデルが最良か」がサポートには間違った質問である理由です。中程度のモデルの上に構築されたよく作られたシステムは、通常足場なしのフロンティアモデルを上回ります。これがサポートユースケースに最適なLLMについての私たちの記事の核心です。Opus 4.8がより誠実であることは良いニュースです。ただ仕事の形は変えません。独自のAIサポートを構築する対プラットフォームを購入するを検討しているなら、モデルは安くて簡単な部分です。残りが本当の仕事です。
eeselを試す
ここまで読んだなら、おそらくベンチマークデルタよりも、AIがチームのチケットを安全に引き受けられるかに興味があるでしょう。それがまさにeesel AIが行うことです。Claudeのようなフロンティアモデルの上に位置し(インフラを持たずにOpusクラスの推論を得られる)、過去のチケットとヘルプドキュメントから学習し、確信がある時だけ自動返信するよう信頼度でルーティングし、顧客と話す前に実際のチケット履歴でシミュレーションできます。価格は使用量ベースでシートごとの料金なしのため、静かな月は同じではなく安くなります。

ヘルプデスクを接続して数分でシミュレーションを実行できます。eeselを試して、自分のチケットに向けて実際に解決できるものを確認してください。
よくある質問
Claude Opus 4.8とは何ですか?
Claude Opus 4.8のコストはいくらですか?
Claude Opus 4.8とOpus 4.7の違いは何ですか?
Claude Opus 4.8はカスタマーサポートに適していますか?
Claude Opus 4.8 APIで独自のサポートAIを構築すべきですか?
Claude Opus 4.8はAnthropicのラインナップのどこに位置していますか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.





