
まとめ
Claude Opus 4.8はAnthropicのOpusティアのフラグシップモデルであり、ビジネスにとってはOpus 4.7に対する控えめながら実質的なアップグレードです。より誠実で、新しいエフォートダイヤルがあり、同じ$5/$25(100万トークンあたり)の価格です。唯一の実質的な問題は、トークンをより速く消費することです。
ほとんどの「Claude Opus 4.8のビジネス活用」記事が省略している部分があります。3年以上にわたって本番のサポートキューにAIを導入してきた経験から言えることは、モデルはエンジンであり、車ではないということです。より賢いモデルを購入しても、機能するビジネスワークフローは手に入りません。モデルには依然として自社データ、ガードレール、そして顧客に触れる前にテストする手段が必要です。これがまさにeesel AIのようなプラットフォームが埋めるギャップです。
これはオペレーターの視点からの実践的な考察です。実際に何が変わったか、全てを計上したときのコスト、いつAPIで構築し、いつ購入すべきか、そしてフロンティアモデルがチームに何をして(しない)のかを解説します。
実際のサポートキューでAIを導入している私のビジネス視点
ほとんどのモデル解説記事では始まらない場所から始めます。それがOpus 4.8があなたのビジネスに影響を与えるかどうかを決める点だからです。フロンティアモデルが実際の混乱したサポートキューに出会う様子を何年も見てきましたが、教訓は変わりません:モデルが難しい部分であることはほとんどありません。
これを裏付ける数字を2つ挙げます。どちらも当社の実際のデプロイメントからのものです。Gridwiseは最初の月にeeselがティア1リクエストの73%を解決するのを見ました。その結果は7日間のトライアル内で出ています。Smavaは毎月10万件以上のドイツ語チケットを処理する完全自動化されたZendeskエージェントを運用しています。これらの結果はどれも、最も賢いモデルを選んだことから生まれたわけではありません。解決済みチケットでのトレーニング、信頼度によるルーティング、そして本番前の実際の履歴に対するシミュレーションから生まれたのです。
ですから、新しいOpusが登場したとき、ビジネスにとって重要な質問は「ベンチマークでより賢いか」ではありません。「これは顧客の受信箱、またはチームの作業に実際に送るものを変えるか」です。この視点でOpus 4.8を見てみましょう。
ビジネス用語でのClaude Opus 4.8とは
Claude Opus 4.8はAnthropicのOpusファミリーの最新モデルで、Claudeの高性能ティアです。Opus 4.7の後継として2026年5月28日にリリースされ、APIではclaude-opus-4-8として呼び出します。ビジネス視点ではなく一般的な説明が必要な場合は、別途Claude Opus 4.8とは何かという記事を書いています。
購入者にとって重要なスペック:標準価格での100万トークンのコンテキストウィンドウ、最大128kトークンの出力、そしてモデル自身が管理するアダプティブシンキング(拡張思考のトグルは不要)。テキストと画像を読み込み、80以上の言語に対応し、トレーニングデータは2026年1月まで(モデル概要)。AnthropicはAWS Bedrock、Vertex AI、Microsoft Foundryを含む全てのプラットフォームでリリース初日から提供しています。調達チームにすでに好みのクラウドがある場合に重要です。
このジャンプに対するAnthropicの自身のフレーミングは清々しいほど控えめです。発表では「前任者に対する控えめながら実質的な改善」と表現しており、社内での適切な期待値設定です。これは世代的な飛躍ではなく、磨きと修正のリリースであり、修正こそがビジネス価値の所在です。
Opus 4.8で購入者にとって実際に変わったこと
チームの標準を何にするか(単に使うだけでなく)を決めている場合、知っておく価値のある変更点がいくつかあります。
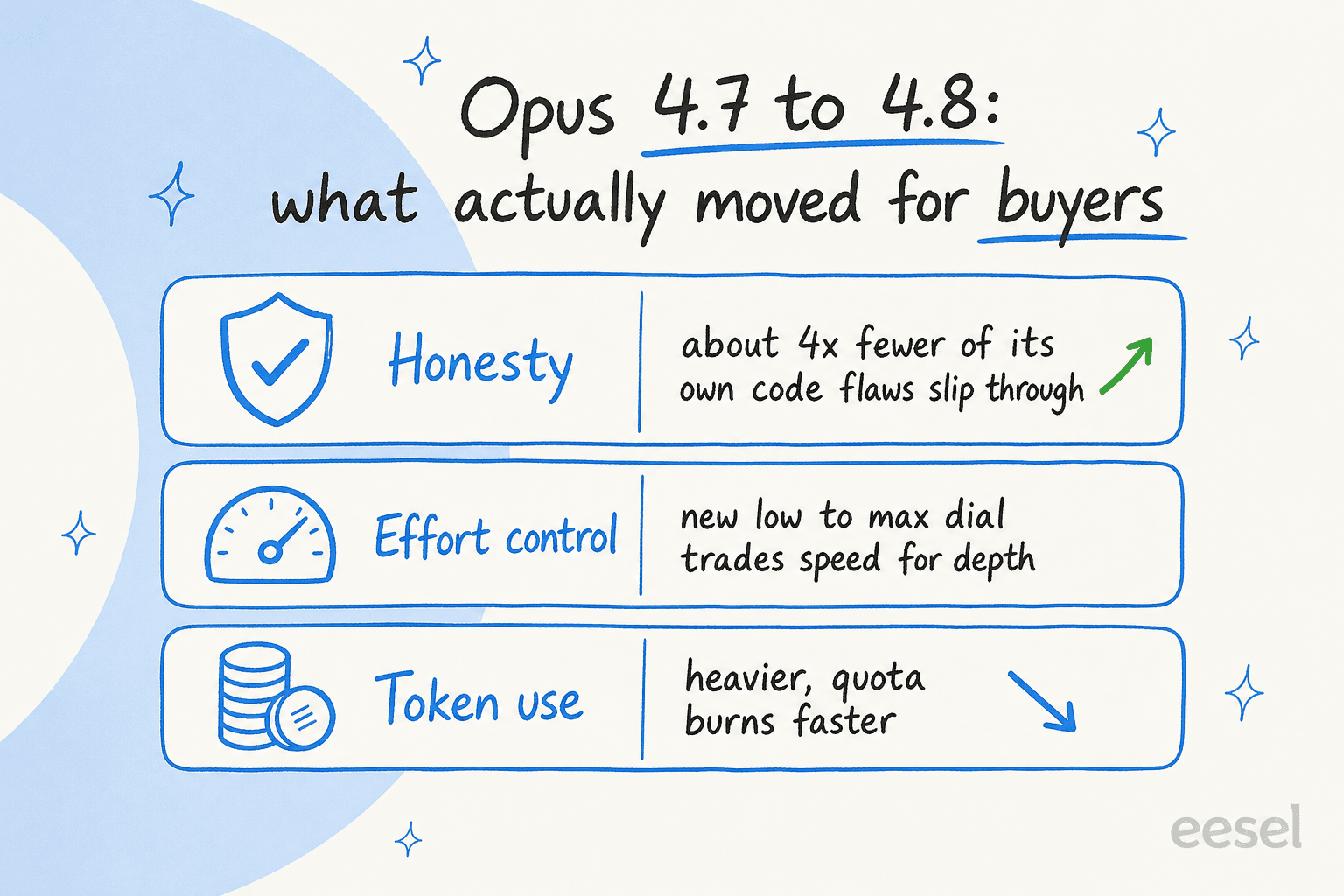
誠実さが実質的に向上しました。 Anthropicはこれを「最も顕著な改善の一つ」と呼んでいます。ビジネス環境では、私が実際に対価を払うのはこの点です。Opus 4.8は4.7と比べて自身のコードの欠陥を見過ごす可能性が約4分の1で、自信を持って答えを作り上げるよりも不確実性を示す姿勢を見せます。間違った答えにコストが伴う場所(金融、法律、規制されたサポート)では、「確信がないときに教えてくれる」という特性がコーディングベンチマークの1点より価値があります。
新しいエフォートコントロール。 モデルの作業量を設定するダイヤルが新たに追加されました。lowからmaxまであり、デフォルトはhighです(発表)。ビジネスにとっては予算レバーです。難しい分析には最大に、速度とコストが重要な定型的な大量タスクには最小にします。
長期エージェント作業。 Claude Codeでは、Opus 4.8はジョブを計画し、1セッションで数百のサブエージェントを並列起動してから報告前に出力を検証することができます。大規模マイグレーションのようなコードベース規模の作業を想定しています(dynamic-workflowsの投稿)。エンジニアリング組織を運営している場合、これが主要なニュースです。System Cardによると、パフォーマンスは「ほぼ全ての評価でOpus 4.7を上回る」とのことです。
問題点:消費量が多い。 コミュニティで最も繰り返される不満は、Opus 4.8が使用量の上限を消費してしまうことです。Opus 4.7以降では新しいトークナイザーを使用しており、"同じ固定テストに対して最大35%多くのトークンを使用する可能性がある"とされています。変わらない表示価格であっても、タスクあたりの実際のコストは上昇する可能性があります。予算に入れておきましょう。
ビジネス向けClaude Opus 4.8の価格
価格は変わらなかったため、簡単な部分です。Opus 4.8は入力トークン100万件あたり$5、出力トークン100万件あたり$25で、Opus 4.7と同一です(価格ページ)。2.5倍の速度で実行するファストモードもあり、Anthropicによると以前のモデルのファストモードより大幅に低コストです。
2026年半ばの現在のラインナップを以下に示します。ワークロードのモデル選択に必要なコンテキストです:
| モデル | 入力/出力(100万トークンあたり) | コンテキスト | 最適な用途 |
|---|---|---|---|
| Claude Fable 5 | $10 / $50 | 1M | Anthropicの最も高性能な広く公開されたモデル |
| Claude Opus 4.8 | $5 / $25 | 1M | トップOpusティア;複雑な推論、長期エージェント |
| Claude Opus 4.7 / 4.6 | $5 / $25 | 1M | 前世代のOpus |
| Claude Sonnet 4.6 | $3 / $15 | 1M | 速度と知性の最適なバランス |
| Claude Haiku 4.5 | $1 / $5 | 200k | 大量の単純タスク向けの最速・最安 |
財務部門に伝えるべき点:トークンあたりの表示価格は実際の請求書で最も小さい行です。本番稼働でモデルを運用するコストのほとんどは、モデルを取り巻く全てにあります。これがビジネスが陥るトラップです。
価格だけが読む理由なら、Claude価格ガイドがティア別に解説しており、Claude Pro価格ではチームがすでに利用中かもしれないシートプランを扱っています。サポート固有の計算には、生のトークンレートよりもAIエージェント対人間エージェントのコストの比較が有用です。
APIで構築するか、プラットフォームを購入するか?
これがOpus 4.8のようなモデルが登場したときにほとんどのビジネスが直面する実際の決断であり、正直な答えは何を構築しているかによります。
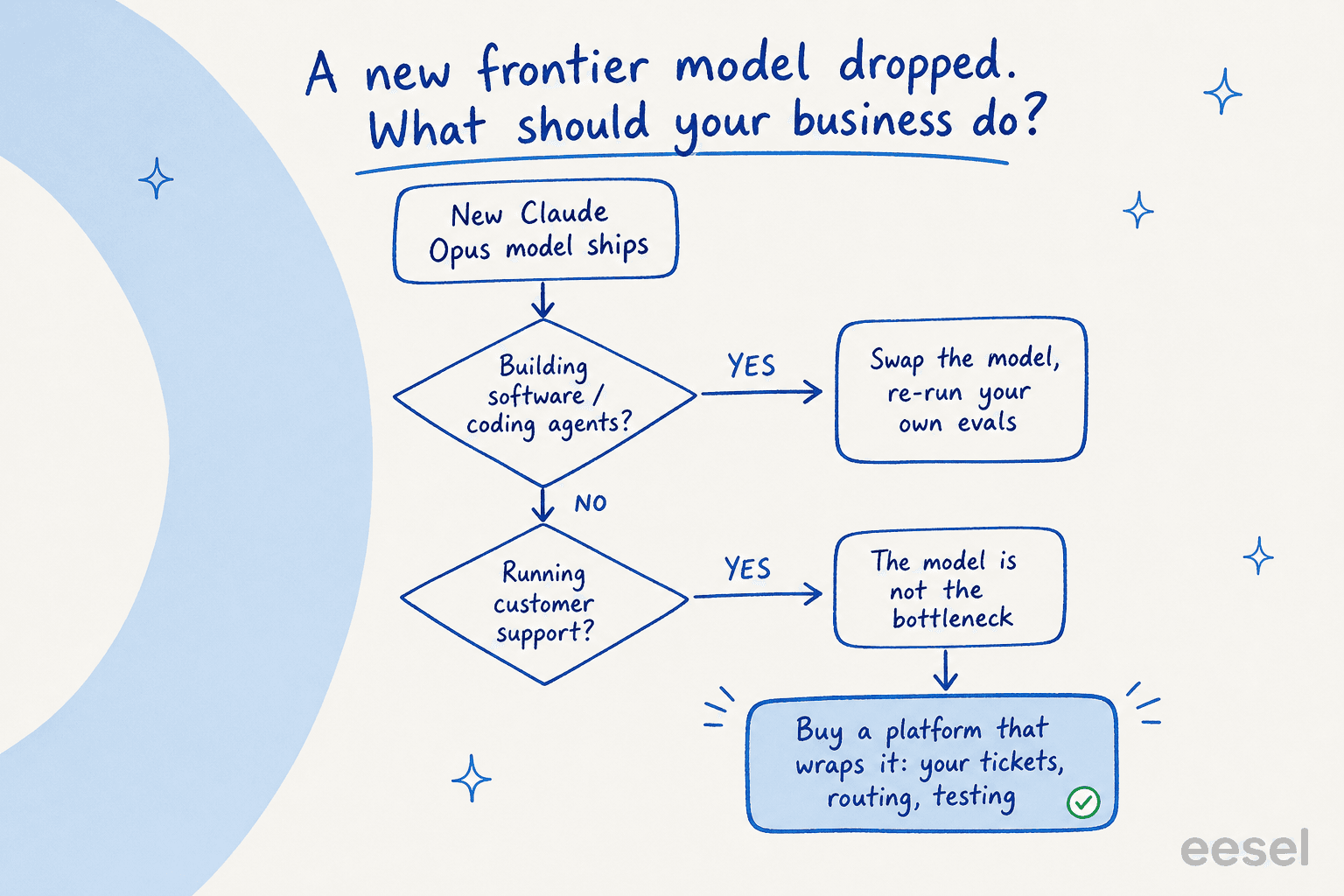
ソフトウェア製品やコーディングワークフローを出荷している場合、Claude APIで直接構築することが多くの場合正しい選択です。新モデルに切り替えて、自分たちの評価を再実行して出荷する。モデルがそこでは製品そのものだからです。
カスタマーサポートのようなビジネスワークフローでは逆です。多くの優秀なチームが苦労しながらこれを学んでいます。Opusがこれほど優れているなら直接呼び出せると考えて、自分たちでClaude APIを接続するために去っていく顧客を見てきました。数ヶ月後、メンテナンスの現実が訪れます。購入を選んだあるエンジニアリングリーダーはこの計算を簡潔に述べました:
「独自のLLMアプリケーションを書こうとすることもできましたが、その時間を投資したくなかったのです。メンテナンスが不要なものが欲しかった。」
これは暗号ハードウェア会社のエンジニアリングチームが構築よりも購入を選んだGENERAL BYTESのケーススタディからの言葉です。最も一般的なパターンです。APIの呼び出しは些細で、検索、ガードレール、維持管理が実際の仕事です。同じパターンはRAG vs. LLMの決断にも現れます。モデルは作業が存在する場所であることはほとんどありません。
より賢いモデルがサポートに対してすること(しないこと)
ここが私が実際に知っていることに到達する部分です。サポートチームを運営している場合、Opus 4.8が登場すると「AIサポートが良くなった」と考える誘惑があります。時にはそうです。しかしAIカスタマーサービスソフトウェアが実際に何で構成されているかについて正確であることは価値があります。フロンティアモデルはその一部に過ぎないからです。
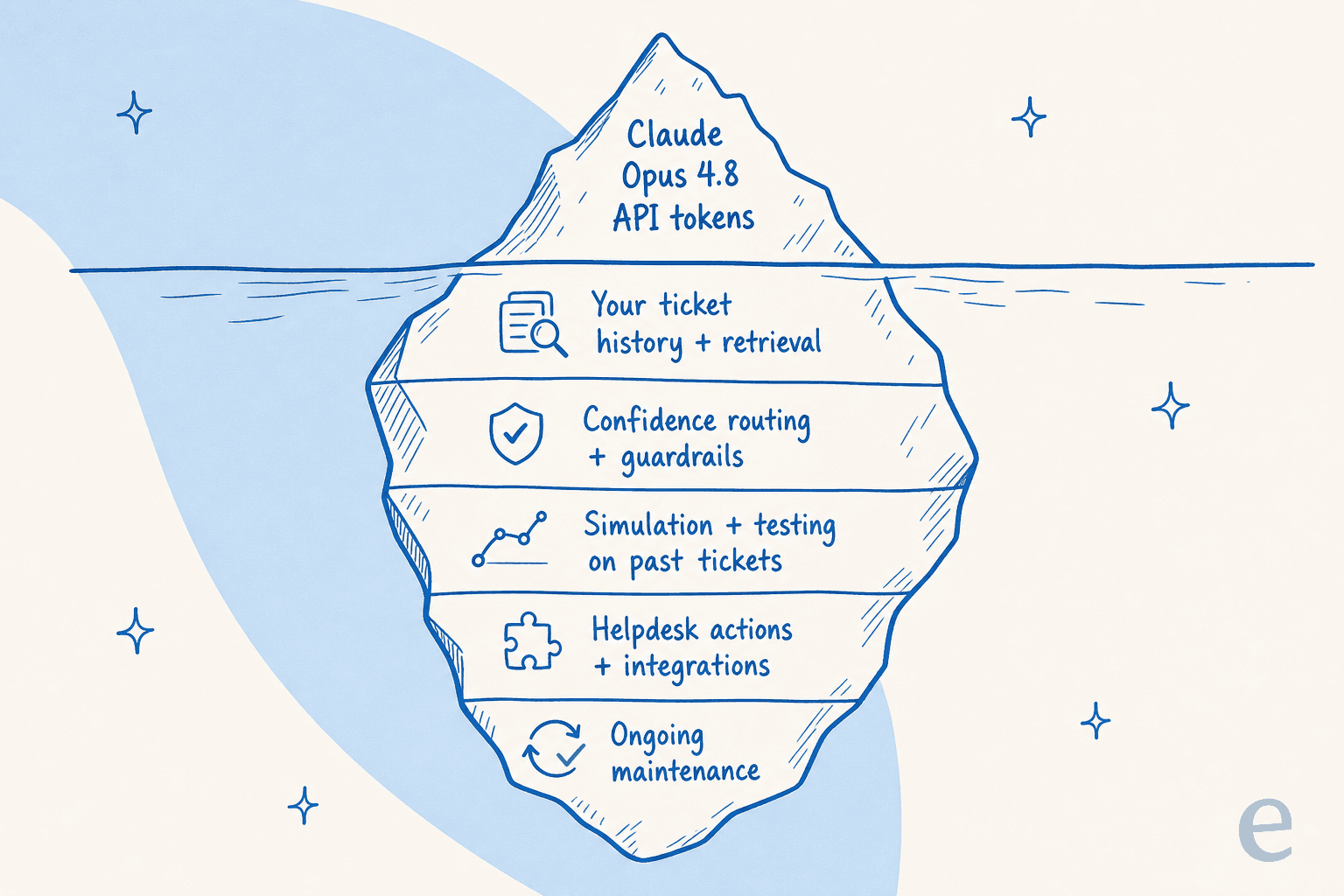
本番サポートエージェントはモデルプラス、Opus 4.8が単純には含まない多くの地味なスキャフォールディングです:
- あなたの知識、モデルのではなく。 Opus 4.8の2026年1月のトレーニングカットオフはあなたの返金ポリシーや先週の障害について何も知りません。有用なエージェントは過去のチケット、ヘルプドキュメント、マクロから学びます。これが一般的な世界知識の盲点です。(RAGとは何かは検索側を扱っています。)
- 信頼度ベースのルーティング。 Opus 4.8の誠実さの向上は本物ですが、モデルが単独でいつライブに返答するかを決めることは依然として望ましくありません。不確かなときは下書きし、確信があるときだけ自動送信するようにしたい。これはシステムレベルのガードレールであり、モデルの設定ではありません。
- 本番前のテスト手段。 1人の顧客がAIの返答を見る前に、何千もの実際の解決済みチケットに対して実行して、どこで正解し、どこで誤答したかを正確に確認したい。新しいモデルではそれはできません。シミュレーションならできます。
- クリーンなエスカレーションとアクション。 タグ付け、トリアージ、注文の確認、人間への引き継ぎ。これはヘルプデスク統合に存在し、生のモデルには存在しません。
だから「どのモデルが最良か」はサポートチームにとって通常は間違った質問です。中位モデル上の適切に構築されたシステムは、スキャフォールディングのない生のフロンティアモデルに勝ることが多いということを発見しています。それがサポートユースケースに最適なLLムの全引数です。Opus 4.8がより誠実であることは良いニュースです。ただし、作業の形を変えたり、単独で解決率を動かしたりはしません。ワークフローのために最良のカスタマーサービスAIを評価したりClaudeの代替案を検討したりしている場合、モデルは安くて簡単な部分です。残りが仕事です。
一つ開示しておきます(公平を期すために):私たちはClaudeのようなフロンティアモデルの上に構築しているので、この議論に利害関係があります。それがまた、モデルが優位性ではないと確信している理由でもあります。カスタマーサービスにAIを使用する数百チームにわたって、適切に構築されたシステムが生む違いを見てきたからです。
eeselを試してみてください
ここまで読んでいるなら、おそらくベンチマークのデルタよりも、AIがチームの作業を安全に引き受けられるかどうかに興味があるでしょう。それがeesel AIが行うことです:Claudeのようなフロンティアモデルの上に座り(配管を所有せずにOpusクラスの推論を得られます)、過去のチケットとヘルプドキュメントから学び、信頼度でルーティングして確信があるときだけ自動返信し、顧客に話す前に実際のチケット履歴でシミュレーションできます。価格は使用量ベースでシートあたりの料金なし。静かな月はより少ないコストになります。

ヘルプデスクを接続して数分でシミュレーションを開始できます。eeselを試してみてください。自社チケットに向けて、実際に何を解決できるかを確認してください。より賢いモデルは必要ありません。
よくある質問
Claude Opus 4.8はビジネス用途に適していますか?
Claude Opus 4.8は企業にとってどのくらいのコストがかかりますか?
Claude Opus 4.8 APIで構築すべきか、プラットフォームを購入すべきか?
Claude Opus 4.8はOpus 4.7と比べて何が変わりましたか?
Claude Opus 4.8は単独でカスタマーサポートを運営できますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








