AIサポートエージェントの幻覚を防ぐには?
Alicia Kirana Utomo
Katelin Teen
最終更新 June 19, 2026

サポートエージェントにとって「幻覚」が本当に意味すること
幻覚とは、モデルが正しいことを述べるのと同じ確信度で誤ったことを述べる場合のことです。大規模言語モデルは最も確率の高い次の単語を予測することで機能するため、本当の回答が手元にない場合でも止まりません。流暢で尤もらしく、完全に作り上げられた回答を生成します。これはパッチで修正できるバグではなく、基礎となる技術の仕組みです。
汎用チャットボットでは幻覚は煩わしい程度ですが、サポートでは高コストです。あなたのAIカスタマーサービスソフトウェアはあなたの会社を代表して、顧客に、しばしばお金やアカウント、あるいは今後守らなければならない約束について話しています。私は自信満々に聞こえるボットが、単純に私たちのポリシーではなかったことを顧客に静かに伝えるのを見てきました。コストは誤った文章ではなく、フォローアップチケット、信頼へのダメージ、そしてそれを修正しなければならなかった人間でした。
デンマークの車両テレマティクスチームがZendesk上でサポートを運営していた顧客の一つが、この最も明確なバージョンを経験しました。彼らのナレッジベースには「すべてのモデルをサポート」と書いてあったため、顧客がデータベースに実際には存在しない車のブランドについて尋ねた際、エージェントは楽しそうにそれを確認しました。モデルは壊れていませんでした。与えられたものを読んで自信を持って回答したのです。問題は何を読むことが許可されていたか、そして情報源について正直であることを強制されていたかどうかにありました。
それがすべてのゲームであり、この記事の残りがモデルではなく設定について述べる理由です。
正直な回答:モデルが考えることを止めるのではなく、誤った回答の送信を止める
ほとんどの「AI幻覚を止める方法」のアドバイスが見落とすのはこの視点転換です。誤ったトークンを決して生成しないモデルは手に入りません。それを追い求めることは負け戦です。絶対にできることは、誤った回答が送信される前に捕まえられるよう、一連のゲートを構築することです。
これを多層防御として考えてください。モデルが何かを草稿します。その草稿が顧客が読む返信になる前に、グラウンディング、引用チェック、信頼度チェック、そして必要に応じて人間を通過します。どのゲートでも問題を捕まえれば十分です。
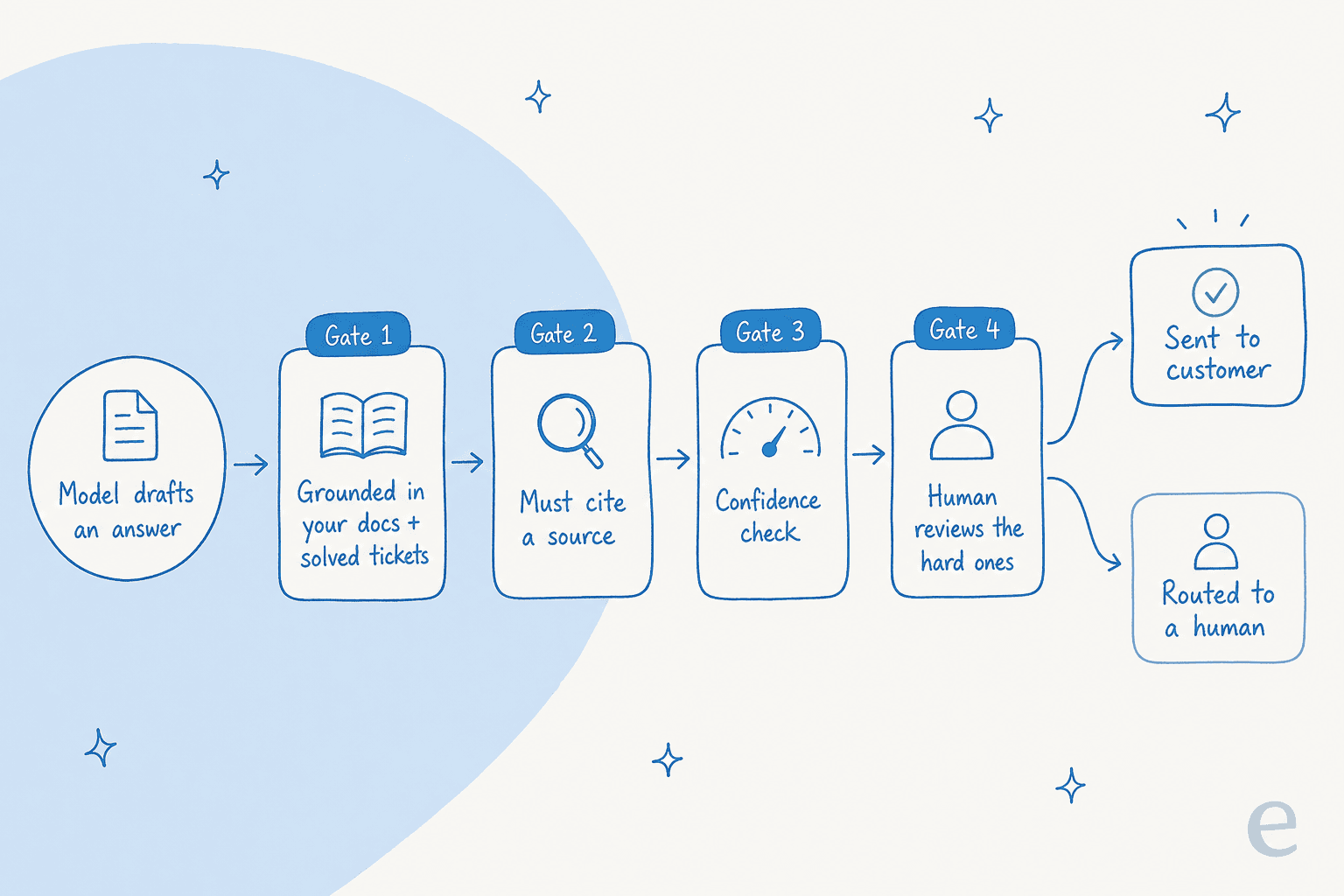
なぜこれが重要か:明らかに誤った回答が1つあるだけで、残りがどれほど優れていても、エージェントの他のすべての回答に対する顧客の信頼が崩れます。ですから目標は完璧なモデルではなく、最悪のケースが「AIが何も言わない」であり、「AIが間違ったことを言う」ではないシステムです。それを構築しましょう。
サポートAIが実際に幻覚を起こさないようにする設定
オープンインターネットではなく、実際の回答で学習させる
最初で最大のレバーはグラウンディングです:エージェントは事前学習で吸収したものからではなく、あなた自身の知識からのみ回答すべきです。つまり、ヘルプセンター、社内ドキュメント、マクロ、そして理想的には解決済みチケットの履歴に接続し、そのマテリアルに制限することです。
解決済みチケットはここで過小評価されている情報源です。ヘルプセンターはエージェントに製品がすべきことを伝えますが、解決済みチケットはチームがカスタマーサービスワークフローの中で実際に顧客にどう答えているか、エッジケースも含めて示します。両方から学ぶAIナレッジベースチャットボットは、マーケティングページだけでトレーニングされたものよりも、はるかにコースから外れにくいです。
グラウンディングされていない場合の実態を確認できます。Agentforceをレビューしたセールスフォースのコンサルタントは率直に述べています:
「さらに、幻覚が本当にひどいです。私たちはトレーニングしておらず、汎用モデルで動作しているため、時々私たちのものではない情報を提供します。」
Arjun G., G2でのSalesforce Agentforceのレビュー
「私たちのものではない情報」がその証拠です。修正方法は、利用可能な唯一の情報があなたの情報であることを確認することです。ただしグラウンディングの裏面は古さなので、情報源を最新に保ちましょう。同じツールファミリーの別のレビュアーは警告しています:
「Content Versionファイル(ナレッジ記事)が2021年以降更新されていない場合、AIエージェントは古い情報を自信を持って顧客に伝えます。」
Muhammad O., G2でのAgentforce Serviceのレビュー
グラウンディングされているが古いのは、それ自体が別の種類の誤った回答です。だからこそナレッジベースでAIをトレーニングすることは一度限りのインポートではなく継続的な作業であり、よく管理されたナレッジベースがAI以上の効果をもたらす理由でもあります。
すべての回答に情報源を引用させる
グラウンディングはエージェントが読めるものを制限します。引用は実際に何かを読んだことを証明させます。エージェントが回答の根拠となった特定のドキュメントやチケットを添付しなければならない場合、2つの良いことが起こります:レビュアーはワンクリックで回答を確認でき、エージェントは即興している時に隠れる場所がありません。
私が主張するパターン:情報源なし、回答なし。 エージェントが回答を裏付けるパッセージを指し示せない場合、返信を送るべきではなく、エスカレーションすべきです。私たちが協力している法律テック企業の共同創業者は、なぜこれが彼らの世界で交渉の余地がないかを説明しました:役立つことと法律アドバイスへの踏み込みの間には細い線があり、AIが顧客に近づくことを許す唯一の方法は、情報源に関する正確なガードレールとすべての返答への透明な引用でした。これは高いハードルですが、規制産業だけでなく、すべての人に正しいデフォルト設定です。
信頼度閾値を設定してルーティングする
これが最も重要なものであり、「信じてください」を実際の安全メカニズムに変えるゲートです。ティア1デフレクションを拡大する前に正しく設定する価値のある、放置できるデフレクションツールと常時監視が必要なものの違いです。エージェントは確信を持ち情報源がある場合にのみ自動返信し、それ以外はすべて人間用に草稿を作成するか引き渡します。
月に約7,000件のGorgiaチケットを処理するDTCサプリメントブランドのCXリードが、私よりうまく論理を説明しました:
AIは質問の100%に答えることはないと彼は言いました。しかし、すべてに挑戦して顧客に「申し訳ありませんが、わかりません」と書くだけなら、数千件のチケットをレビューして良い仕事をしたかどうかを確認できません。自信がある場合のチケットのみ対応し、残りはそのままにするAIが必要でした。これが一文での信頼度ベースのルーティングであり、彼の評価の決定的な要因でした。
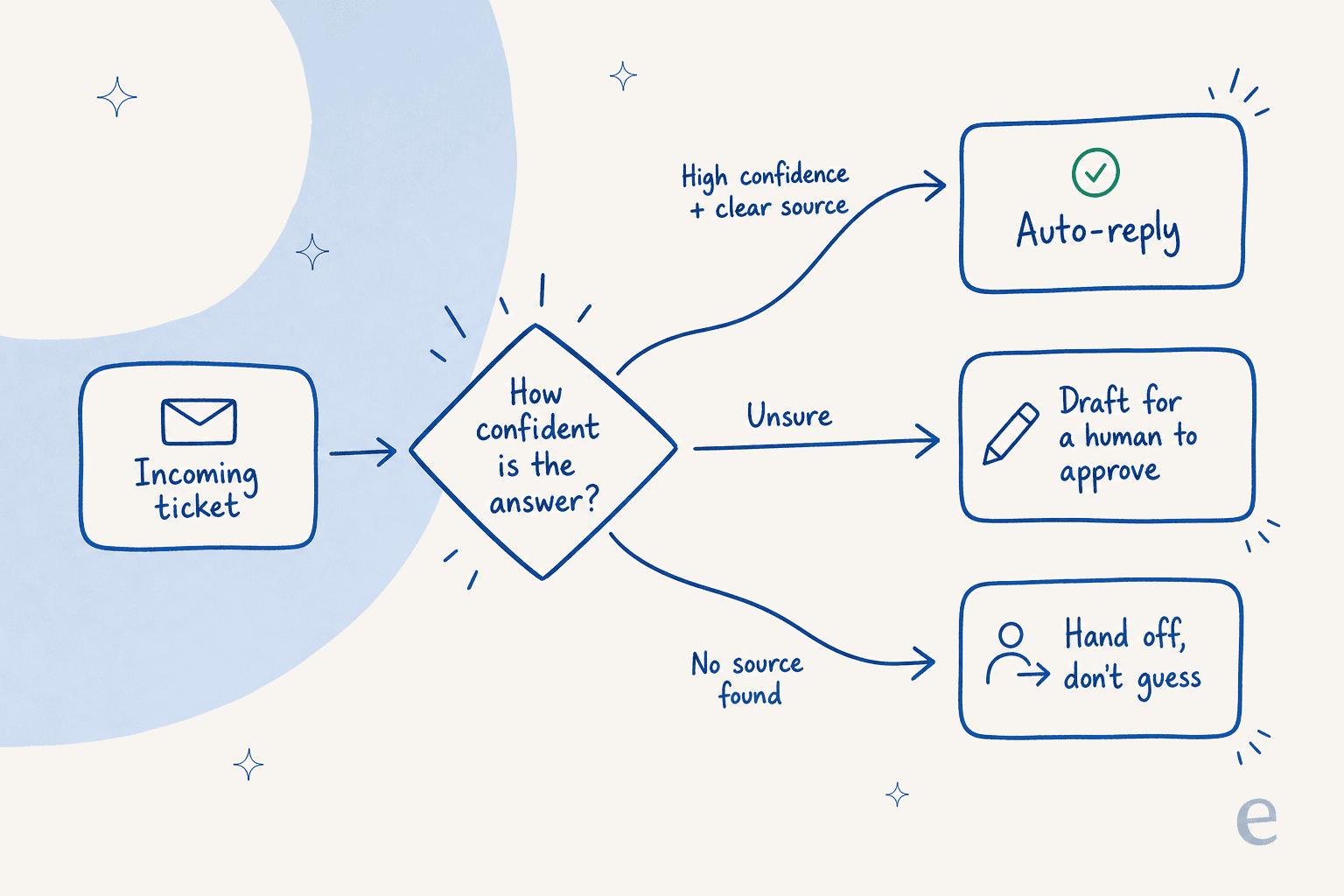
実践的なバージョン:信頼度バーを設定し、それ以下のものはすべて自動返信ではなく草稿として人間に送り、バーを高く始めます。特定のチケットタイプでエージェントを信頼したら常に下げることができます。これは良いAIチャットエスカレーションが価値を発揮するところでもあります。なぜなら自信のある「人間を呼びます」は毎回自信のある誤った回答に勝るからです。これを古いテクノロジーと比較すると、AIエージェントとルールベースのチャットボットの最も明確な境界線です。
絶対に触れてはいけないトピックを囲い込む
一部のチケットはサポート自動化に近づけるべきではなく、それは制限ではなく機能です。閾値を超えた返金、アカウント削除、法的なもの、エスカレーションの最中の怒っている顧客。それらのカテゴリを人間のみに保つための明示的な制御が必要です。
これは人々が実際にデプロイしたい方法において常に登場します。あるサポートリードは、特定のチケットはまったくAIを通したくないとはっきり言いました。あるeコマースマネージャーの主な心配は、AIが事実を誤るのではなく、過剰な約束をすることでした:「顧客に対応します、と言うのを止めてください、あなたにはわかりません。」どちらも実際には同じリクエストです。つまり、エージェントがどれだけうまく行うかだけでなく、何をすることが許可されているかの制御です。良いAIヘルプデスクエージェントは最初からそれらの除外を切り出し、何を約束できるかについての確固たるガードレールを設定できます。Breezeのエスカレーションとガードレールのアプローチのように。
顧客と話す前に過去チケットでシミュレーションする
上記のすべてのゲートは、テストするまでは仮説にすぎません。チームが犯すミスは、実際の顧客でエージェントをライブにして問題が起きるのを見守ることです。はるかに安全な方法は、まず数千の過去チケットに対してシミュレーションで実行することです。
シミュレーションは、正しい結果がすでにわかっているチケットに対してエージェントがどう答えたかを再現します。トピック別のカバレッジを得て、幻覚やエスカレーションをどこで起こしていたかを正確に確認し、ライブ会話に触れる前にナレッジのギャップを修正します。その後、一度に1つのチケットタイプずつ、段階的にライブに移行します。
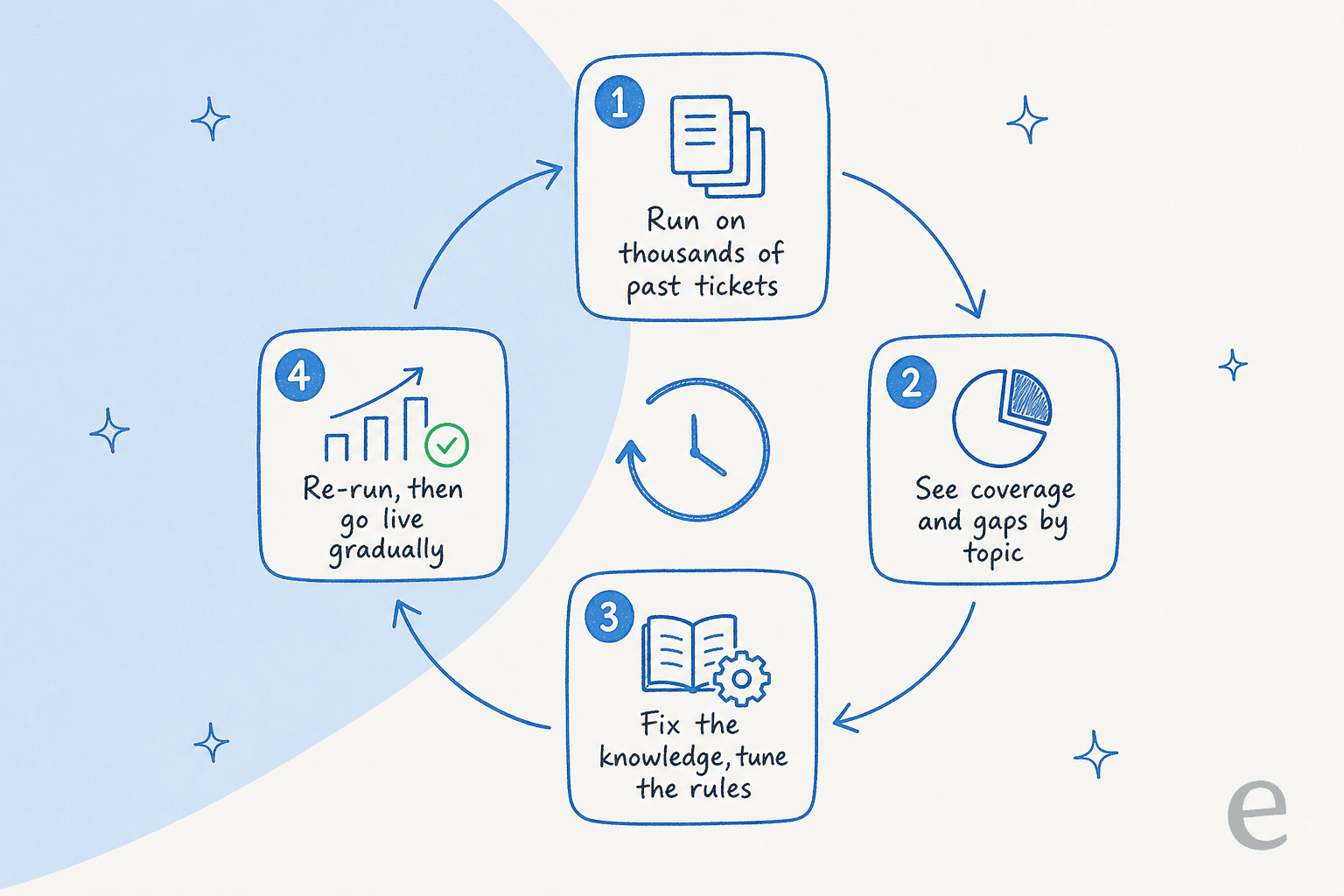
これは顧客なしに出荷しないステップです。なぜなら、エージェントが正確であることを望むことと、ローンチ前にカバレッジ数を知ることの違いだからです。また、前述の車両テレマティクスチームが「すべてのモデルをサポート」問題を、顧客がそうした後ではなく、顧客の前に発見できた理由でもあります。
ループを閉じる:すべての修正がトレーニングデータ
最後のゲートはローンチ後に機能します。人間が草稿を編集または拒否すると、そのシグナルは同じ間違いが再発しないようにエージェントに直接フィードバックされるべきです。評価者は常にこれについて尋ねます。通常は「承認または拒否した際に実際にトラッキングしていますか?」という何らかのバリエーションで。答えは常にイエスであるべきです。なぜなら、修正から学ぶエージェントは毎週より正確になり、学ばないものは月曜日に捕まえた幻覚を金曜日にまた犯すからです。エージェントパフォーマンスの定期評価と組み合わせれば、ドリフトするのではなく時間とともに改善するシステムが手に入ります。
実際に機能していることを確認する方法
測定しないガードレールは良い意図にすぎません。いくつかの数字がエージェントが誠実かどうかを教えてくれます:
- 封じ込め率または解決率:実際に回答したチケットについて。低いエスカレーションでの高い解決率は良いです。再オープン率が上昇している高い解決率は、本来すべきでないものを自信を持って閉じていることを意味します。孤立して考えるのではなく、封じ込め率とエスカレーション品質を一緒に考える方法をご覧ください。
- トピック別エスカレーション率:健全なエージェントは曖昧なカテゴリではより多くエスカレーションし、単純なものでは少なくします。すべてにわたってエスカレーションがフラットな場合、信頼度閾値はおそらく何もしていません。
- AI処理チケットと人間処理チケットの再オープンとCSAT:より広いAIカスタマーサービスメトリクスの一部として追跡します。
これを見る目的は、信頼度が精度を超えた瞬間を見つけ、閾値を下げることです。正しく行われれば、エージェントの「わかりません」率は隠そうとするものではなく、誇りを持てる機能になります。
eeselを試してみる
私はそれを構築するのを助けているので偏っていますが、eesel AIヘルプデスクエージェントはこのまさにそのような設定の周りに設計されています。初日から過去チケットとヘルプドキュメントから学習し、情報源を引用し、確信がある場合にのみ自動返信して残りをチームに静かに引き渡す信頼度ベースのルーティングを使用します。最初に指摘したいのはシミュレーションです:数千の過去チケットにわたって実行し、1人の顧客が関与する前に実際のカバレッジと精度を確認できます。ライブで発見するのではなく。
その慎重さが報われます。あるロジスティクス顧客に対して最初の月にティア1リクエストの73%を解決しました(eesel AIヘルプデスクエージェント)。そしてそれは、エージェントが触れるべきでないチケットを放置するからこそ機能します。Zendesk、Freshdesk、Gorgias、その他に接続し、使用量ベースの料金でループに人間を置くためのシート料金を支払いません。無料で試してシミュレーションから始められます。

よくある質問
AIサポートエージェントはなぜ幻覚を起こすのですか?
AIサポートエージェントの幻覚を完全に止めることはできますか?
AIサポートエージェントの信頼度ベースのルーティングとは何ですか?
AIサポートエージェントを顧客への対応前にテストするには?
AIサポートエージェントを安全に運用するコストは?
AIエージェントをナレッジベースに根付かせるだけで幻覚を止められますか?
AIサポートエージェントから遠ざけるべきチケットの種類は?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








